文章目錄
- C# 使用iText獲取PDF的trailer數據
- iText 核心概念
- C# 代碼示例
- 步驟 1: 確保已安裝 iText
- 步驟 2: C# 代碼
- 程序運行效果
- 解讀 Trailer 的輸出
- 總結
C# 使用iText獲取PDF的trailer數據
開發程序debug的時候,看到了PDF有個trailer數據,挺有意思,于是考慮用代碼把它讀出來,那么就用到我們常用的iText框架了。
實際上,使用 iText 獲取 PDF 的 trailer 數據是一個稍微底層一些的操作,但完全可以實現。trailer 是 PDF 文件結構的核心部分,它告訴解析器如何找到文件的關鍵部分,比如交叉引用表 (xref)、文檔信息字典 (/Info) 和文檔根對象 (/Root)。
在 iText 中,這個操作被很好地封裝了。本文將詳細說明能從 trailer 中獲得什么信息。
iText 核心概念
- 高級抽象 vs. 底層訪問: iText 提供了高級的類,如
PdfDocumentInfo和PdfCatalog,來方便地訪問trailer指向的內容。例如,pdfDocument.GetDocumentInfo()會自動找到trailer中的/Info條目并解析它。 - 直接訪問: 同時,iText 也允許你直接獲取
trailer本身,它是一個PdfDictionary對象。這對于需要檢查非標準字段或進行底層分析的程序員來說非常有用。
C# 代碼示例
這個示例將演示如何打開一個 PDF 文件,并同時使用高級方法和底層方法來檢查 trailer 相關的數據。
步驟 1: 確保已安裝 iText
請在你的項目中通過 NuGet 包管理器安裝 itext。
Install-Package itext
步驟 2: C# 代碼
using System;
using System.IO;
using iText.Kernel.Pdf;public class PdfTrailerInspector
{public static void InspectPdfTrailer(string filePath){if (!File.Exists(filePath)){Console.WriteLine($"錯誤:文件不存在 '{filePath}'");return;}try{// 使用 PdfReader 和 PdfDocument 打開 PDF 文件using (var pdfReader = new PdfReader(filePath))using (var pdfDocument = new PdfDocument(pdfReader)){Console.WriteLine($"--- 正在分析文件: {Path.GetFileName(filePath)} ---");// --- 方法 1: 使用高級 API 訪問 Trailer 指向的內容 (推薦的常規做法) ---Console.WriteLine("\n=== 通過高級 API 獲取 Trailer 指向的信息 ===");// GetDocumentInfo() 會讀取 trailer 的 /Info 字典PdfDocumentInfo docInfo = pdfDocument.GetDocumentInfo();Console.WriteLine($"信息字典 (來自 /Info): Creator = {docInfo.GetCreator()}, Producer = {docInfo.GetProducer()}");// GetCatalog() 會讀取 trailer 的 /Root 字典,這是文檔的入口點PdfCatalog catalog = pdfDocument.GetCatalog();Console.WriteLine($"文檔目錄 (來自 /Root): 頁面模式 = {catalog.GetPageMode()}, 頁面布局 = {catalog.GetPageLayout()}");// --- 方法 2: 直接訪問和遍歷 Trailer 字典本身 (底層操作) ---Console.WriteLine("\n=== 直接訪問 Trailer 字典的原始鍵值對 ===");// 使用 GetTrailer() 直接獲取 Trailer 字典對象PdfDictionary trailer = pdfDocument.GetTrailer();if (trailer != null){// 遍歷 Trailer 字典中的所有條目foreach (var key in trailer.KeySet()){PdfObject value = trailer.Get(key); // 值 (可能是數字、引用等)Console.WriteLine($"鍵: {key}, 值: {value}, 值的類型: {value.GetType().Name}");}// 你也可以直接獲取特定的鍵Console.WriteLine("\n--- 單獨獲取 Trailer 中的關鍵值 ---");PdfObject size = trailer.Get(PdfName.Size);PdfObject root = trailer.Get(PdfName.Root);PdfObject info = trailer.Get(PdfName.Info);PdfObject id = trailer.Get(PdfName.ID);Console.WriteLine($"大小 (Size): {size}");Console.WriteLine($"根對象引用 (Root): {root}");Console.WriteLine($"信息字典引用 (Info): {info}");Console.WriteLine($"文件ID (ID): {id}");}else{Console.WriteLine("無法獲取 Trailer 字典。");}}}catch (Exception ex){Console.WriteLine($"讀取 PDF 時發生錯誤: {ex.Message}");}}public static void Main(string[] args){// 請將 "C:\\path\\to\\your\\document.pdf" 替換為你的 PDF 文件路徑string pdfPath = "C:\\path\\to\\your\\document.pdf"; InspectPdfTrailer(pdfPath);}
}
程序運行效果
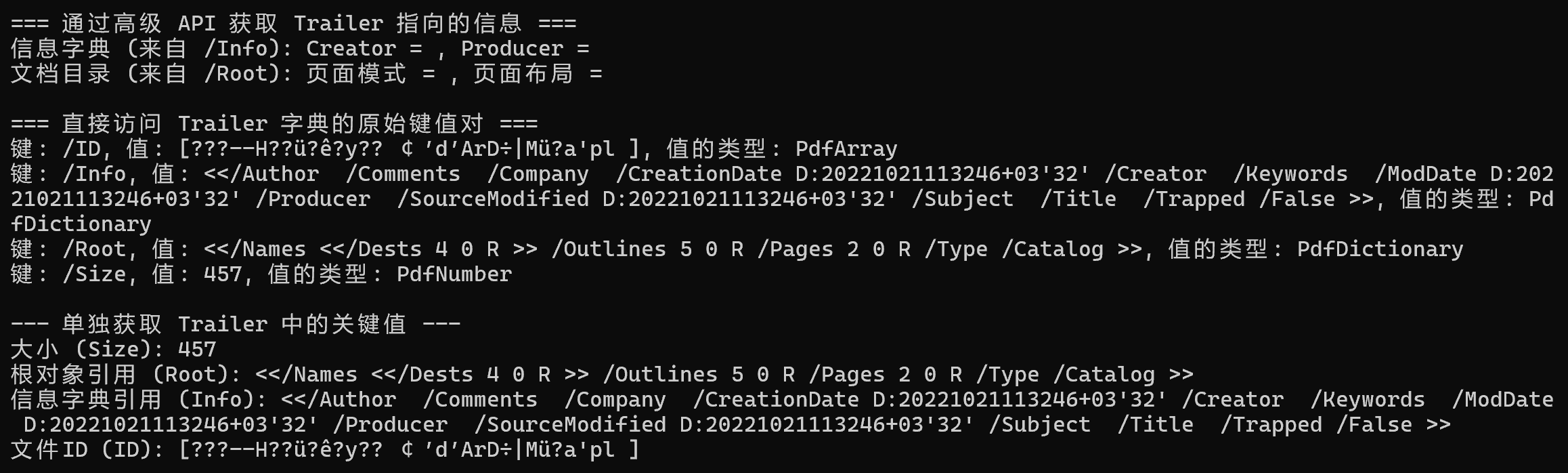
解讀 Trailer 的輸出
當你運行上面的代碼并查看“直接訪問 Trailer 字典”部分的輸出時,你會看到類似下面的內容:
鍵: /Size, 值: 25, 值的類型: PdfNumber
鍵: /Root, 值: 23 0 R, 值的類型: PdfIndirectReference
鍵: /Info, 值: 1 0 R, 值的類型: PdfIndirectReference
鍵: /ID, 值: [<0DDB5968...>, <F3C3B2A6...>], 值的類型: PdfArray
這里是對這些關鍵條目的解釋:
/Size: (類型:PdfNumber) 表示 PDF 文件中對象的總數(大約值)。/Root: (類型:PdfIndirectReference) 這是一個間接引用,指向文檔的根對象(Catalog字典)。23 0 R的意思是“第 23 號對象,第 0 代”。iText 使用這個引用來找到文檔的所有頁面和其他核心內容。pdfDocument.GetCatalog()就是幫你完成了這個查找過程。/Info: (類型:PdfIndirectReference) 同樣是一個間接引用,指向文檔的信息字典(包含作者、標題等元數據)。1 0 R指向第 1 號對象。pdfDocument.GetDocumentInfo()會自動解析這個引用。/ID: (類型:PdfArray) 這是一個包含兩個字符串的數組,用于唯一標識該 PDF 文件。第一個字符串在文件創建時生成,并且永不改變。第二個字符串在每次保存文件時都會更新。這對于追蹤文件的版本非常有用。/Prev(可選): 如果文件是增量更新的,這個鍵會指向前一個版本的交叉引用表的位置。/Encrypt(可選): 如果文件被加密,這個鍵會指向加密字典。
總結
- 常規需求: 如果我們只是想獲取作者、標題、頁面內容等信息,使用 iText 的高級 API(
GetDocumentInfo(),GetCatalog(),GetPage()等)就足夠了,它們在后臺為你處理了trailer的解析。 - 底層分析: 如果你需要檢查
trailer的所有原始條目,或者查找可能存在的非標準字段,或者想驗證 PDF 結構,那么使用pdfDocument.GetTrailer()是最直接和強大的方法。
上面的代碼提供了兩種,我們可以根據具體需求選擇使用。




)
)

零基礎入門到精通,收藏這一篇就夠了)

![Document Picture-in-Picture API擁抱全新浮窗體驗[參考:window.open]](http://pic.xiahunao.cn/Document Picture-in-Picture API擁抱全新浮窗體驗[參考:window.open])
:安全運維工程師)
)







