一.為什么需要RAG(AI幻覺)
大模型LLM在某些情況下給出的回答很可能錯誤的,涉及虛構甚至是故意欺騙的信息。
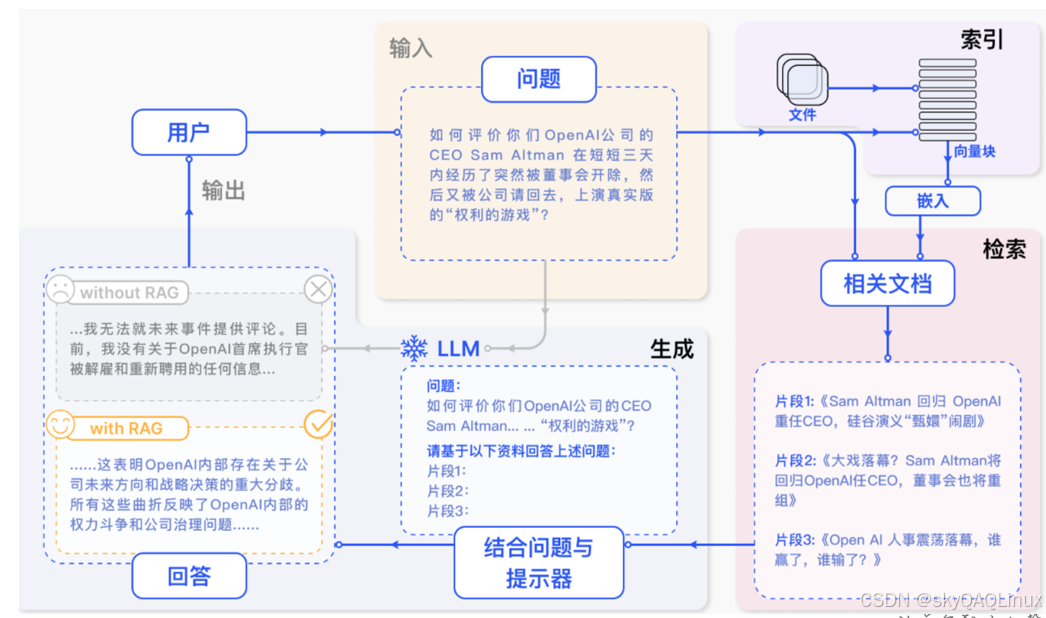
二.什么是RAG
RAG是一種結合“信息檢索”和“文本生成”的技術,旨在提升生成式AI模型的準確性和可靠性。它通過以下兩個核心步驟工作:
1.?信息檢索(Retrieval)
當收到用戶提問時,RAG首先從外部知識庫(如數據庫、文檔或網頁)中檢索與問題相關的信息片段,而不是僅依賴模型訓練時學到的知識。
2..文本生成(Generation)
將檢索到的相關信息和用戶問題一起輸入生成模型,生成更精準、基于事實的答案。
三.RAG的分塊策略
?按照字符數來切分
?按固定字符數 結合overlapping window
?按照句子來切分
?遞歸方法 RecursiveCharacterTextSplitter
四.RAG向量和向量檢索
1.Embeddings向量化
(1)向量檢索
????????根據用戶的輸入,與向量數據庫中存放的文本向量進行相似度計算匹配,并檢索返回最為相似的內容
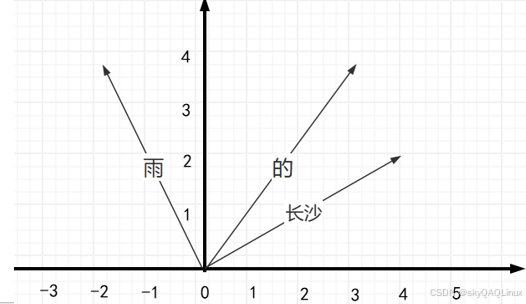
(2)數據內容轉為向量(目前的向量模型可實現)
2.本地大模型
????????Ollama向量模型本地部署:官方網址:https://ollama.com/
3.向量間的相似度計算
常用的向量相似度計算方法包括:
????????-余弦相似度Cosine:基于兩個向量夾角的余弦值來衡量相似度。
????????-歐式距離L2:通過計算向量之間的歐幾里得距離來衡量相似度。
????????-點積:計算兩個向量的點積,適合歸一化后的向量
4.“top-k”語義檢索
????????在根據向量相似度檢索向量時,能夠找出的相似向量一般是多個,如果我們不需要這么多或者要控制相似度的大小,top-k 語義檢索就派上了用場。

Crypto節點、js timestamp代碼、Crypto node)






: 論文解讀)









)
)