1. 什么是knn算法
knn算法全名叫做k-近鄰算法(K-Nearest Neighbors,簡稱KNN),看到名字是不是能想到是算距離的,第一個k是指超參數的意思,就是可以認為設置的意思,這里是指最近的k個樣本。
2. 為什么有這個算法
如果我們要給一些數據分類,是不是通過它的一些相似的特征或者都有的特征,我們就將它分為一類,那我們怎么判別數據相不相似是不是可以通過算距離的方法,數據特征都是可以量化為數字的。knn算法就是可以干這個的算距離的。
算距離的方式
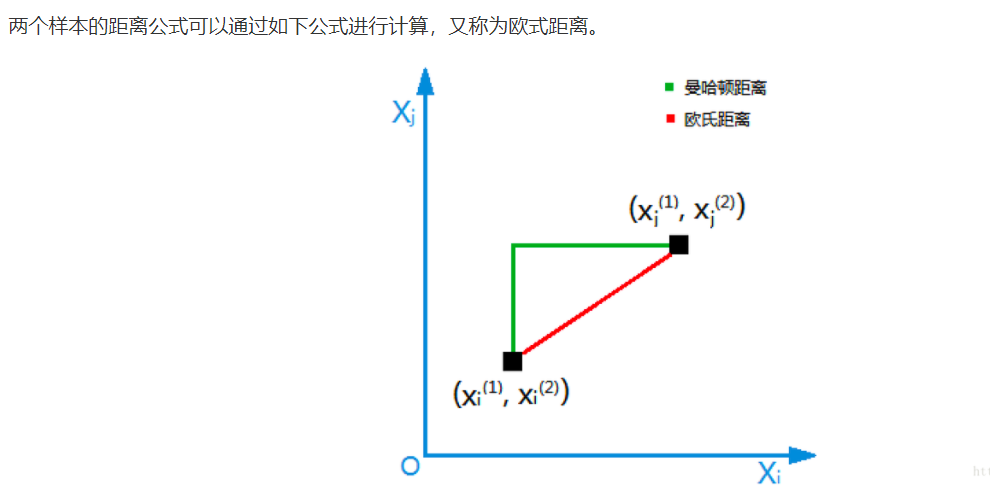
3. knn的原理
knn處理的數據是帶有標簽的,在使用訓練集訓練模型的時候,前面說了knn是通過算樣本之間的距離的,所有訓練模型的時候其實什么也沒有干就只是保存了數據集,當測試數據的時候才會執行通過算每個樣本和測試數據的特征距離,算好以后再排個序(由小到大),然后這里就需要自己傳入的k值了,排序完后,就選擇前k個數據,k個里面占比最高的類別是什么測試數據就屬于什么。
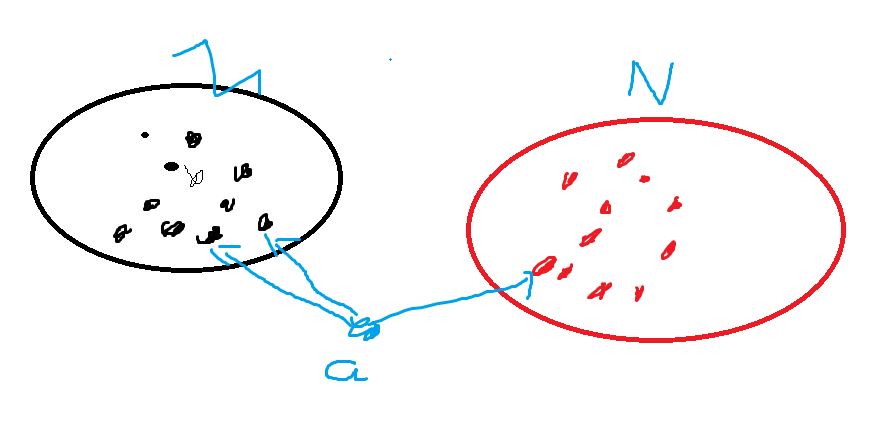
假如黑色的點歸為M,紅色的點為N,現在有一個a,k為3,那么就找最近的三個點,這里黑色的點有兩個雖有將a劃分為M。
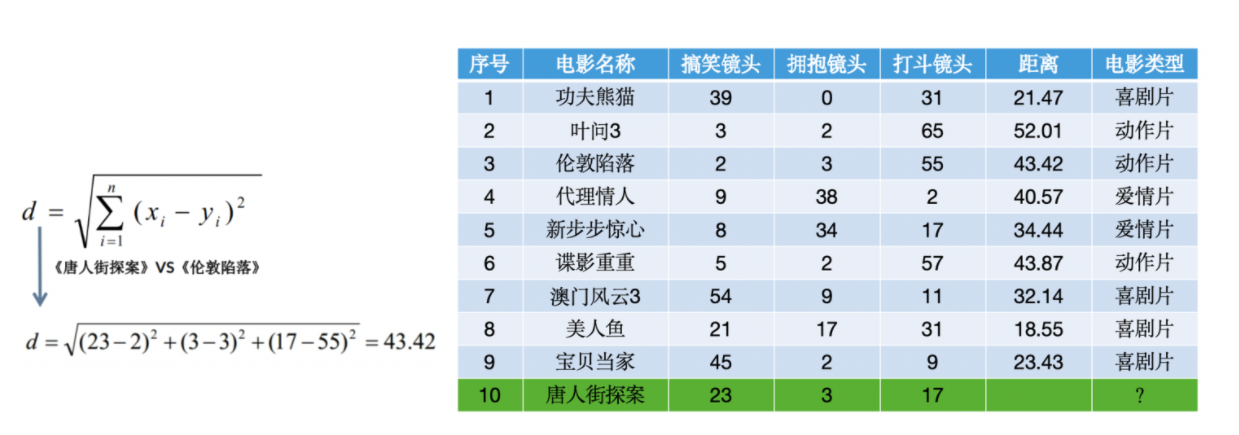
舉個例子:我們這里測試集有1-9條,然后我們需要判斷出10條什么電影類型的,假如k為3,那么前三條最近的就是8,1,9,全是喜劇片所以我們就推斷10也是喜劇片,原理就這么簡單。
4. api實現
KNeighborsClassifier(n_neighbors=5, algorithm='auto')
參數: ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
(1)n_neighbors:?
int, default=5, 默認情況下用于kneighbors查詢的近鄰數,就是K
方法:
(1) fit(x, y)?
使用X作為訓練數據和y作為目標數據 ?
(2) predict(X)?? ?預測提供的數據,得到預測數據 ? ??
# 用KNN算法對鳶尾花進行分類
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier# 1)獲取數據
x,y = load_iris(return_X_y=True)
# 2)劃分數據集
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=42)
# 3)特征工程:標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)KNN算法預估器, k=7表示找7個鄰近來判斷自身類型.
estimator = KNeighborsClassifier(n_neighbors=7)
estimator.fit(x_train, y_train)#該步驟就是estimator根據訓練特征和訓練目標在自己學習,讓它自己變聰敏
# 5)模型評估 測試一下聰敏的estimator能力# 方法1:直接比對真實值和預測值,
y_predict = estimator.predict(x_test) #y_predict預測的目標結果
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)# 方法2:計算準確率,
score = estimator.score(x_test, y_test)# 里面會自己預測y值,然后和y_test作比較,相等的個數/總數
print("準確率為:\n", score) #1.0準確率100了,過度擬合了,這樣反而是不好的,后面會講到的。
5. knn的缺點
對于大規模數據集,計算量大,因為需要計算測試樣本與所有訓練樣本的距離。
我們這里沒什么感覺是應為數據集只有100多條,但是實際開發中的數據都是幾百萬上千萬的數據,那這個都算一遍就哼恐怖了。
對于高維數據,距離度量可能變得不那么有意義,這就是所謂的“維度災難”
就是那種算出來的距離為99999999912,99999999914,這樣的他們的特征也不一樣,但是這么數據太大了比較就有沒有意義了。
需要選擇合適的k值和距離度量,這可能需要一些實驗和調整。
k值過大過小是不是都會影響準確率,k值太大假如接近全部樣本的數量了,是不是根本就不用測我們直接統計誰的種類多就好了。
但是knn在實際應用開發中應用的好少,是應為他是訓練的時候才去預測的,我們訓練時時間花長一點都是沒事的,但預測的時候太長,那客戶使用的時候且不是要等好久才能有一個結果。


易視TV is-E4-G-全志A20芯片-安卓4-燒寫卡刷工具及教程)
順序表實現-增刪查改)















