目錄
- 引用
- 內聯函數
- (C++11)
- auto關鍵字
- 基于范圍的for循環
- 指針空值---nullptr
引用
引用:指將變量以另一個名稱來展現的。它并非是一個新變量而是一個別名,它們同指一塊內存空間。就如古時那些有字的人,亦或者是周樹人,你說魯迅是不是周樹人呢?
引用的形式:類型& 引用變量名(對象名) = 引用實體;
常引用: const 類型& 引用變量名(對象名) = 引用實體;
用常引用時要注意,他是常數的這個特性。
void TestRef()
{int a = 10;int& ra = a;//注意引用的類型要與引用的對象的類型一致!!!printf("%p\n", &a);printf("%p\n", &ra);
//常引用const int a = 10;//int& ra = a; // 該語句編譯時會出錯,a為常量const int& ra = a;// int& b = 10; // 該語句編譯時會出錯,b為常量const int& b = 10;double d = 12.34;//int& rd = d; // 該語句編譯時會出錯,類型不同const int& rd = d;
}
引用的特點:
1.引用一定要初始化。
2.一個變量可以有多個引用。
3.一個引用不能指向多個變量。
引用的意義:
1.做參數。
2.做返回值。
對于引用做返回值有它的注意點:
#include<iostream>int& Add(int a, int b)
{int c=a+b;return c;
}
int main()
{int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :"<< ret <<endl;return 0;
}
你們認為結果是什么?其實是一個不可預測的值。
Add 函數里的 c 是局部變量,函數執行結束后,c 占用的內存會被釋放。返回 c 的引用(int&)后,main 里的 ret 會變成懸空引用(指向已釋放的內存 未定義行為)。后續調用 Add(3,4) 可能覆蓋這片內存, 把 ret 原本指向的無效內存數據改掉 ,導致 ret 輸出異常。
禁止返回局部變量的引用,否則會引發未定義行為;使用懸空引用 就是未定義行為 一切皆有可能。
做參數和返回值時 值與引用是有效率上的區別的:
#include<iostream>
#include <time.h>
using namespace std;
struct A { int a[10000]; };
void TestFunc1(A a) {
}
void TestFunc2(A& a)
{}
// 值返回
A TestFunc3(A a) { return a; }
// 引用返回
A& TestFunc4(A& a) { return a; }
int main()
{A a;// 以值作為函數參數size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作為函數參數size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分別計算兩個函數運行結束后的時間cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;A b;A& B =b;// 以值作為函數的返回值類型size_t begin3 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc3(b);size_t end3 = clock();// 以引用作為函數的返回值類型size_t begin4 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc4(B);size_t end4 = clock();// 計算兩個函數運算完成之后的時間cout << "TestFunc3 time:" << end3 - begin3 << endl;cout << "TestFunc4 time:" << end4 - begin4 << endl;return 0;
}
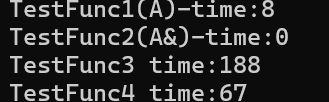
通過上述代碼的比較,發現傳值和指針在作為傳參以及返回值類型上效率相差很大。
傳值:簡單直接,但拷貝大型對象時效率低。
傳引用:避免拷貝,效率更高,適合傳遞大對象或需修改實參的場景。
實際開發中,優先用傳引用(或 const 引用) 處理復雜類型,減少不必要的性能損耗。
你們可能聽說引用其實就是指針,這是有一定來由的。
在語法概念上引用就是一個別名,沒有獨立空間,和其引用實體共用同一塊空間。
在底層實現上實際是有空間的,因為引用是按照指針方式來實現的。
引用和指針的不同點:
- 引用概念上定義一個變量的別名,指針存儲一個變量地址。
- 引用在定義時必須初始化,指針沒有要求。
- 引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何
一個同類型實體。 - 沒有NULL引用,但有NULL指針。
- 在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32
位平臺下占4個字節)。 - 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小。
- 有多級指針,但是沒有多級引用。
- 訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理。
- 引用比指針使用起來相對更安全。
內聯函數
內聯函數:以inline修飾的函數叫做內聯函數(在函數的返回值類型前面加inline)編譯時C++編譯器會在調用內聯函數的地方展開(用函數體替換函數的調用),沒有函數調用建立棧幀的開銷,內聯函數提升程序運行的效率。
查看普通函數與內聯函數的區別方法:
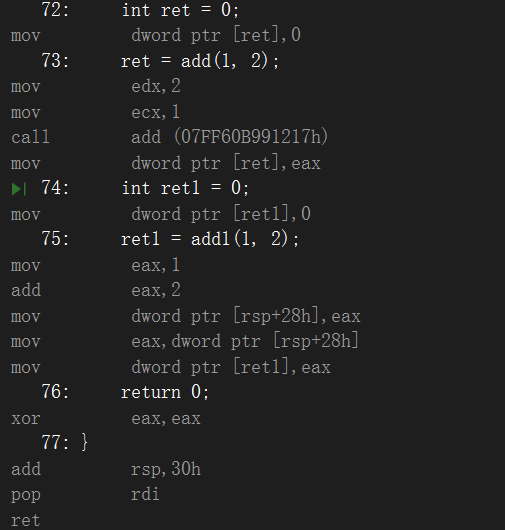
- 在release模式下,查看編譯器生成的匯編代碼中是否存在call Add。
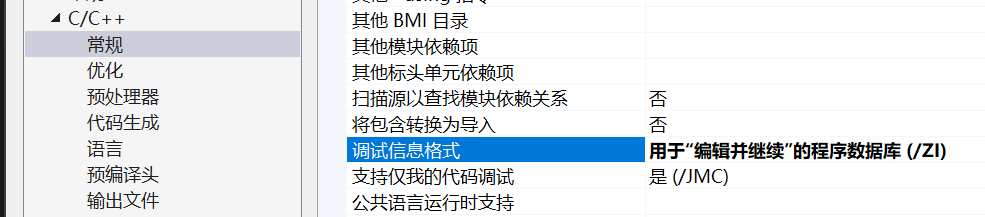
- 在debug模式下,需要對編譯器進行設置,否則不會展開(因為debug模式下,編譯器默認不
會對代碼進行優化,以下給出vs2013的設置方式)
debug模式下設置:
開始:
改變后:

開始:
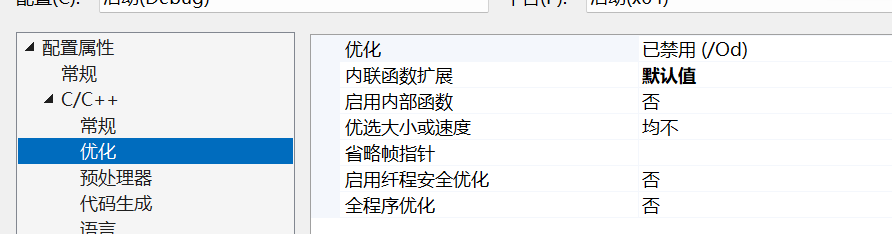
改變后:
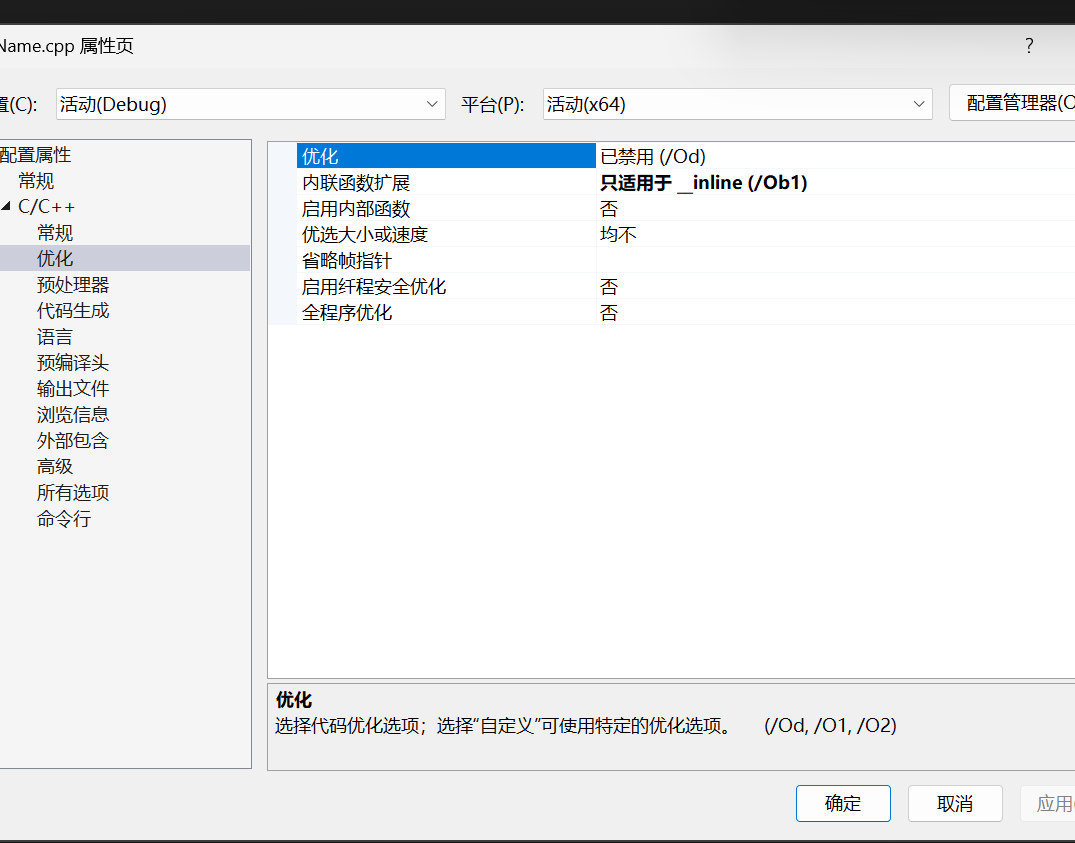
匯編代碼:
內聯函數:
特性本質:以空間換時間,編譯階段用函數體替換調用,減少調用開銷、提升效率,但可能使目標文件變大。
編譯器處理:inline 是給編譯器的建議,編譯器可選擇忽略,通常規模小、非遞歸、頻繁調用的函數建議用,遞歸等情況編譯器可能忽略該特性 。
適用與限制:用于優化規模小、流程直接、頻繁調用函數,多數編譯器不支持內聯遞歸函數,75 行這類較長函數也難在調用點內聯展開 。
inline 函數應該聲明和定義不分開。因為inline被展開,就沒有函數地址了,鏈接就會找不到。
inline函數其實還可以替代宏,那么我開始回憶宏的優缺點。
優點:
1.增強代碼的復用性。
2.提高性能。
缺點:
1.不方便調試宏。(因為預編譯階段進行了替換)
2.導致代碼可讀性差,可維護性差,容易誤用。
3.沒有類型安全的檢查 。
而我們可以在C++用這兩種方法來代替宏。
- 常量定義 換用const enum
- 短小函數定義 換用內聯函數
(C++11)
auto關鍵字
在我們做的程序變得越來越大,我們所用的類型名稱也會變得越來越難寫(復雜)和含義不明確導致容易出錯。對此我們之前可以用typedef來縮短名稱,然而typedef 讓類型別名和 const 的組合語義變得不直觀,容易坑人。
typedef char* pstring;
int main()
{const pstring p1; // 編譯成功還是失敗?const pstring* p2; // 編譯成功還是失敗?return 0;
}
在早期C/C++中auto的含義是:使用auto修飾的變量,是具有自動存儲器的局部變量,但遺憾的
是一直沒有人去使用它,因為局部變量默認就是自動存儲類型,使用 auto 修飾屬于多余操作, 其修飾效果和不修飾一樣,因此無人使用。
C++11中,標準委員會賦予了auto全新的含義即:auto不再是一個存儲類型指示符,而是作為一
個新的類型指示符來指示編譯器,auto聲明的變量必須由編譯器在編譯時期推導而得。
在編譯階段編譯器需要根據初始化表達式來推導auto的實際類型。因此auto并非是一種類型的聲明,而是一個類型聲明時的占位符,編譯器在編譯期會將auto替換為變量實際的類型。因此使用auto定義變量時必須對其進行初始化。
auto 使用的細則:
1.auto 與指針和引用的注意事項:auto對于指針可以用auto或auto*,auto對于引用必須要加&:auto&。
2.auto對于同一行有多個變量的定義,他會先通過識別第一個變量類型,再用第一個變量類型賦給接下來的變量。因此要多個變量的類型一致。
3.auto不能用的場景:做函數參數,不能用在數組。
4. 為了避免與C++98中的auto發生混淆,C++11只保留了auto作為類型指示符的用法
5. auto在實際中最常見的優勢用法就是跟C++11提供的新式for循環,還有lambda表達式等進行配合使用。
基于范圍的for循環
這個改動是為了對于一個有范圍的集合而言,由程序員來說明循環的范圍是多余的,有時候還會容易犯錯誤。因此C++11中引入了基于范圍的for循環。for循環后的括號由冒號“ :”分為兩部分:第一部分是范圍內用于迭代的變量,第二部分則表示被迭代的范圍。
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for(auto& e : array)//第一部分:auto& e,第二部分:arraye *= 2;
for(auto e : array)cout << e << " ";
return 0;
}
與普通循環類似,可以用continue來結束本次循環,也可以用break來跳出整個循環。
基于范圍的for循環使用條件:
1.因為是基于范圍的,所以對于遍歷的對象都要知其范圍。
2.迭代的對象要實現++和==的操作
指針空值—nullptr
在C++98中的指針空值:NULL,NULL實際是一個宏,NULL可能被定義為字面常量0,或者被定義為無類型指針(void*)的常量。
那么就會出現問題:
void f(int)
{cout<<"f(int)"<<endl;
}
void f(int*)
{cout<<"f(int*)"<<endl;
}
int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}
這里是想通過f(NULL)調用指針版本的f(int*)函數,但是由于NULL被定義成0,因此與程序的
初衷相悖。
在C++98中,字面常量0既可以是一個整形數字,也可以是無類型的指針(void*)常量,但是編譯器
默認情況下將其看成是一個整形常量,如果要將其按照指針方式來使用,必須對其進行強轉(void
*)0。
對于nullptr有下面的注意:
- 在使用nullptr表示指針空值時,不需要包含頭文件,因為nullptr是C++11作為新關鍵字引入
的。 - 在C++11中,sizeof(nullptr) 與 sizeof((void*)0)所占的字節數相同。
- 為了提高代碼的健壯性,在后續表示指針空值時建議最好使用nullptr。









)








)
