文章目錄
- 先言
- 一、什么是機器學習
- 1.機器學習的定義以及核心思想
- 2.機器學習的四大類型
- 2.1監督學習(Supervised Learning)
- 2.2半監督學習(Midsupervised Learning)
- 2.3無監督學習(Unsupervised Learning)
- 2.4強化學習(Reinforcement Learning)
- 3.機器學習的基本流程
- 4.機器學習工具庫sklearn的安裝
- 二、數據集:機器學習的“燃料”
- 1.數據集的組成(特征、標簽)
- 2.獲取數據集(Sklearn庫本地獲取、網絡下載、文本數據)
- 2.1sklearn加載玩具數據集(紅酒、乳腺癌)
- 2.2sklearn加載現實網絡數據集
- 2.3pandas實現本地數據的創建和訪問
- 3.數據集的劃分(train_test_split)
- 結語
先言
人工智能(AI)正在重塑我們的世界,而 機器學習(Machine Learning, ML) 作為其核心驅動力,讓計算機能夠從數據中自動學習規律,并做出智能決策。無論是人臉識別、推薦系統,還是自動駕駛,機器學習技術都發揮著關鍵作用。
本文將從 機器學習的定義入手,介紹其基本概念,并深入探討 數據集 的組成、類型及預處理方法。通過這篇文章,你將理解機器學習的基本框架,并學會如何準備高質量的數據集,為后續的模型訓練打下堅實基礎。
一、什么是機器學習
1.機器學習的定義以及核心思想
機器學習(Machine Learning)是一種通過算法和模型使計算機從數據中自動學習并進行預測或決策的技術,屬于人工智能的一個分支。其核心目標是讓計算機在沒有明確編程指令的情況下,通過對大量數據的分析,識別模式和規律,從而構建適應新數據的模型。機器學習廣泛應用于圖像識別、自然語言處理、推薦系統和自動駕駛等領域,具備自適應、自動化和泛化能力,是數據驅動的技術創新。
機器學習的本質是讓計算機自己在數據中學習規律,并根據所得到的規律對未來數據進行預測。
機器學習包括如聚類、分類、決策樹、貝葉斯、神經網絡、深度學習(Deep Learning)等算法。
機器學習的基本思路是模仿人類學習行為的過程,如我們在現實中的新問題一般是通過經驗歸納,總結規律,從而預測未來的過程。
2.機器學習的四大類型
2.1監督學習(Supervised Learning)
監督學習(Supervised Learning)是從有標簽的訓練數據中學習模型,然后對某個給定的新數據利用模型預測它的標簽。如果分類標簽精確度越高,則學習模型準確度越高,預測結果越精確。
監督學習主要用于回歸和分類。
常見算法包括線性回歸、支持向量機、決策樹和神經網絡。監督學習廣泛應用于分類(如圖像、文本分類)與回歸(如房價、股價預測)任務,適用于金融、醫療、電子商務等多個領域。其性能高度依賴于標注數據的數量與質量。
2.2半監督學習(Midsupervised Learning)
半監督學習(Semi-Supervised Learning)是利用少量標注數據和大量無標注數據進行學習的模式。
半監督學習側重于在有監督的分類算法中加入無標記樣本來實現半監督分類。
常見的半監督學習算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch無監督學習適用于客戶細分、異常檢測、推薦系統、數據壓縮和基因分析等場景,尤其在數據標注困難或成本高的領域中具有重要價值。等。
2.3無監督學習(Unsupervised Learning)
無監督學習(Unsupervised Learning)是從未標注數據中尋找隱含結構的過程。
無監督學習主要用于關聯分析、聚類和降維。
常見的無監督學習算法有稀疏自編碼(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等
2.4強化學習(Reinforcement Learning)
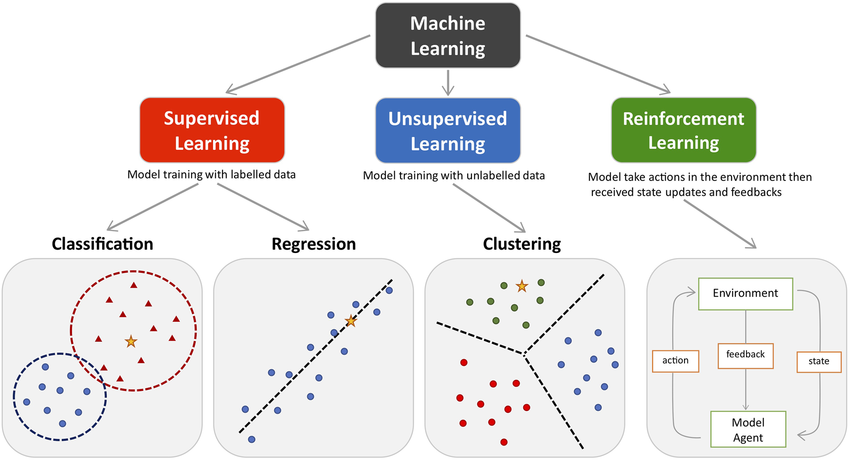
強化學習(Reinforcement Learning)類似于監督學習,但未使用樣本數據進行訓練,是是通過不斷試錯進行學習的模式。
在強化學習中,有兩個可以進行交互的對象:智能體(Agnet)和環境(Environment),還有四個核心要素:策略(Policy)、回報函數(收益信號,Reward Function)、價值函數(Value Function)和環境模型(Environment Model),其中環境模型是可選的。
強化學習常用于機器人避障、棋牌類游戲、廣告和推薦等應用場景中。
3.機器學習的基本流程
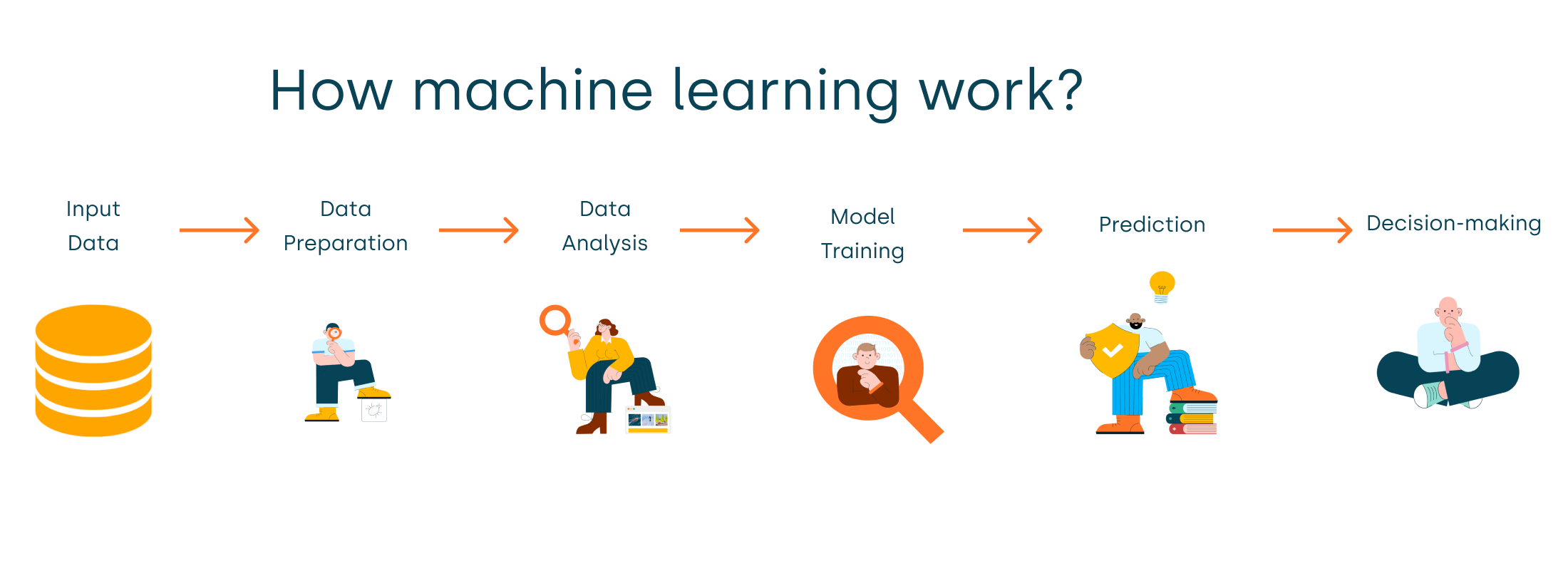
有5個基本步驟用于執行機器學習任務:
- 收集數據:無論是來自excel,access,文本文件等的原始數據,這一步(收集過去的數據)構成了未來學習的基礎。相關數據的種類,密度和數量越多,機器的學習前景就越好。
- 準備數據:任何分析過程都會依賴于使用的數據質量如何。人們需要花時間確定數據質量,然后采取措施解決諸如缺失的數據和異常值的處理等問題。探索性分析可能是一種詳細研究數據細微差別的方法,從而使數據的質量迅速提高。
- 練模型:此步驟涉及以模型的形式選擇適當的算法和數據表示。清理后的數據分為兩部分 - 訓練和測試(比例視前提確定); 第一部分(訓練數據)用于開發模型。第二部分(測試數據)用作參考依據。
- 評估模型:為了測試準確性,使用數據的第二部分(保持/測試數據)。此步驟根據結果確定算法選擇的精度。檢查模型準確性的更好測試是查看其在模型構建期間根本未使用的數據的性能。
- 提高性能:此步驟可能涉及選擇完全不同的模型或引入更多變量來提高效率。這就是為什么需要花費大量時間進行數據收集和準備的原因。
無論是任何模型,這5個步驟都可用于構建技術,當我們討論算法時,您將找到這五個步驟如何出現在每個模型中!
4.機器學習工具庫sklearn的安裝
根據之前我們所有環境都是利用conda創建的,這里我們可以創建一個新環境
(在conda終端):
conda create -n sklearn python=3.12
activate sklearn
在此環境下下載scikit-learn包執行下面代碼:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
之后通過conda list指令查看環境就可以看到scikit-learn庫就安裝成功了

二、數據集:機器學習的“燃料”
數據集是 Sklearn 最基本的概念之一。
機器學習的核心任務是從數據中學習模式,數據的表示方式至關重要。
數據集(Dataset)
在 scikit-learn 中,數據通常通過兩個主要的對象來表示: 特征矩陣 和 目標向量。
特征矩陣(Feature Matrix):每一行代表一個數據樣本,每一列代表一個特征(即輸入變量)。它是一個二維的數組或矩陣,通常使用 NumPy 數組或 pandas DataFrame 來存儲。
1.數據集的組成(特征、標簽)
-
特征(Features):是數據集中用于訓練模型的輸入變量。在上面的例子中,X 是特征矩陣,包含了所有的輸入變量。
-
標簽(Labels):是機器學習模型的目標輸出。在監督學習中,標簽是我們希望模型預測的結果。在上面的例子中,y 是標簽或目標向量,包含了每個樣本的類別。
2.獲取數據集(Sklearn庫本地獲取、網絡下載、文本數據)
2.1sklearn加載玩具數據集(紅酒、乳腺癌)
通過導入sklearn庫包獲取本地數據
from sklearn.datasets import load_wine
from sklearn.datasets import load_breast_cancer
#加載數據集
#紅酒數據集
wine =load_wine()
#紅酒的全部數據
print(wine.data)
#返回的是紅酒的品種
print(wine.target)
#獲取紅酒特征的描述
print(wine.feature_names)
#獲取紅酒標簽(品種)的描述
print(wine.target_names)
#加載乳腺癌病數據集
breast_data = load_breast_cancer()
print(breast_data.feature_names)紅酒特征向量含義以及標簽含義:
#紅酒和特征向量含義
wine_feature_descriptions = {'alcohol': '酒精含量','malic_acid': '蘋果酸含量','ash': '灰分含量','alcalinity_of_ash': '灰分堿度','magnesium': '鎂含量','total_phenols': '總酚含量','flavanoids': '黃酮類化合物含量','nonflavanoid_phenols': '非黃酮類酚類化合物含量','proanthocyanins': '原花青素含量','color_intensity': '顏色強度','hue': '色調','od280/od315_of_diluted_wines': '稀釋葡萄酒的OD280/OD315吸光度比值','proline': '脯氨酸含量'
}
#標簽含義
wine_target_dict = {'class_0': 'Cv品種','class_1': 'Ec品種','class_2': 'Sc品種'
}
乳腺癌中的特征向量以及標簽含義:
#特征含義
breast_feature_descriptions='''
均值特征 (Mean features)
mean radius: 半徑均值(從中心到邊緣的平均距離)
mean texture: 紋理均值(灰度值的標準差)
mean perimeter: 周長均值
mean area: 面積均值
mean smoothness: 平滑度均值(半徑變化的局部變化)
mean compactness: 緊湊度均值(周長2/面積 - 1.0)
mean concavity: 凹度均值(輪廓凹陷的嚴重程度)
mean concave points: 凹點均值(輪廓上的凹點數量)
mean symmetry: 對稱度均值
mean fractal dimension: 分形維度均值(海岸線近似值 - 1)
標準誤差特征 (Standard error features)
radius error: 半徑標準誤差
texture error: 紋理標準誤差
perimeter error: 周長標準誤差
area error: 面積標準誤差
smoothness error: 平滑度標準誤差
compactness error: 緊湊度標準誤差
concavity error: 凹度標準誤差
concave points error: 凹點標準誤差
symmetry error: 對稱度標準誤差
fractal dimension error: 分形維度標準誤差
最差值特征 (Worst features)
worst radius: 最大半徑(最差區域的半徑)
worst texture: 最差紋理
worst perimeter: 最大周長
worst area: 最大面積
worst smoothness: 最差平滑度
worst compactness: 最差緊湊度
worst concavity: 最大凹度
worst concave points: 最大凹點數
worst symmetry: 最差對稱度
worst fractal dimension: 最差分形維度
'''
#標簽含義
breast_target_dict='''
malignant:惡性腫瘤,表示該腫瘤具有侵襲性,可能會擴散到身體其他部位
benign:良性腫瘤,表示該腫瘤不具有侵襲性,通常不會擴散到身體其他部位
'''
這里給出特征和標簽含義是為了方便對數據集的理解,可以讓你快速熟悉數據集的特征和標簽的含義
2.2sklearn加載現實網絡數據集
對現實網絡20條新聞數據進行下載保存
from sklearn.datasets import fetch_20newsgroups
from sklearn import datasets
import pandas as pd
#獲取現實數據存放路徑
download_file_path = datasets.get_data_home()
print(download_file_path)
#獲取現實數據斌保存到指定的路勁
news = fetch_20newsgroups(subset='all',data_home="./src/20news-bydate_py3.pkz")
#保存后news可以對數據進行訪問
print(len(news.data)) #18846
print(news.target.shape) #(18846,)
print(len(news.target_names)) #20
print(len(news.filenames)) #18846
2.3pandas實現本地數據的創建和訪問
數據創建
創建csv文件:打開計事本,寫出如下數據,數據之間使用英文下的逗號, 保存文件后把后綴名改為csv
數據訪問
使用pandas的read_csv(“文件路徑”)函數可以加載csv文件,得到的結果為數據的DataFrame形式
#導入pandas模塊
import pandas as pd
#調用pandas方法訪問文件
pd.read_csv("./src/ss.csv")
注:csv文件可以使用excel打開
3.數據集的劃分(train_test_split)
在實際應用中,通常需要將數據集分割成訓練集和測試集。
scikit-learn 提供了一個方便的函數 train_test_split() 來實現這一點。
劃分函數:
sklearn.model_selection.train_test_split(*arrays,**options)
參數
(1) *array
這里用于接收1到多個"列表、numpy數組、稀疏矩陣或padas中的DataFrame"。
(2) **options, 重要的關鍵字參數有:
test_size 值為0.0到1.0的小數,表示劃分后測試集占的比例
random_state 值為任意整數,表示隨機種子,使用相同的隨機種子對相同的數據集多次劃分結果是相同的。否則多半不同
strxxxx 分層劃分,填y
2 返回值說明
返回值為列表list, 列表長度與形參array接收到的參數數量相關聯, 形參array接收到的是什么類型,list中對應被劃分出來的兩部分就是什么類型
示例代碼如下:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- 以上代碼調用 train_test_split 函數,并將結果賦值給四個變量:
X_train、X_test、y_train 和 y_test。 - X 和 y 是傳入 train_test_split 函數的參數,它們分別代表特征數據集和目標變量(標簽)。通常 X 是一個二維數組,y 是一個一維數組。
test_size=0.3參數指定了測試集的大小應該是原始數據集的 30%。這意味著 70% 的數據將被用作訓練集,剩下的 30% 將被用作測試集。random_state=42參數是一個隨機數種子,用于確保每次分割數據集時都能得到相同的結果。這在實驗和模型驗證中非常有用,因為它確保了結果的可重復性。
結語
機器學習的世界浩瀚而精彩,而 數據 是這一切的起點。本文介紹了機器學習的基本概念,并詳細講解了數據集的組成與預處理方法,幫助你邁出 AI 開發的第一步。
🔍 動手實踐建議:嘗試加載一個公開數據集(如 sklearn.datasets.load_iris),并用 pandas 進行初步分析,觀察特征分布情況!
🚀 下期預告:我們將深入探討 特征工程,學習如何從原始數據中提取更有價值的特征,讓模型表現更上一層樓!
 資源規劃)
)





與Metasploit(MSF)聯動)











