前言
這篇里的東西可以說了解了解就行了。
一、哈希函數均勻性展示
原本讓deepseek轉了一下老師的java代碼,但發現復刻起來太麻煩了。又因為這個理解就好,競賽不會有,所以就直接貼老師的java代碼了……
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.security.Security;
import java.nio.charset.StandardCharsets;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;public class hash {// 哈希函數實例public static class Hash {private MessageDigest md;// 打印支持哪些哈希算法public static void showAlgorithms() {for (String algorithm : Security.getAlgorithms("MessageDigest")) {System.out.println(algorithm);}}// 用具體算法名字構造實例public Hash(String algorithm) {try {md = MessageDigest.getInstance(algorithm);} catch (NoSuchAlgorithmException e) {e.printStackTrace();}}// 輸入字符串返回哈希值public String hashValue(String input) {byte[] hashInBytes = md.digest(input.getBytes(StandardCharsets.UTF_8));BigInteger bigInt = new BigInteger(1, hashInBytes);String hashText = bigInt.toString(16);return hashText;}}public static List<String> generateStrings(char[] arr, int n) {char[] path = new char[n];List<String> ans = new ArrayList<>();f(arr, 0, n, path, ans);return ans;}public static void f(char[] arr, int i, int n, char[] path, List<String> ans) {if (i == n) {ans.add(String.valueOf(path));} else {for (char cha : arr) {path[i] = cha;f(arr, i + 1, n, path, ans);}}}public static void main(String[] args) {System.out.println("支持的哈希算法 : ");Hash.showAlgorithms();System.out.println();String algorithm = "MD5";Hash hash = new Hash(algorithm);String str1 = "zuochengyunzuochengyunzuochengyun1";String str2 = "zuochengyunzuochengyunzuochengyun2";String str3 = "zuochengyunzuochengyunzuochengyun3";String str4 = "zuochengyunzuochengyunZuochengyun1";String str5 = "zuochengyunzuoChengyunzuochengyun2";String str6 = "zuochengyunzuochengyunzuochengyUn3";String str7 = "zuochengyunzuochengyunzuochengyun1";System.out.println("7個字符串得到的哈希值 : ");System.out.println(hash.hashValue(str1));System.out.println(hash.hashValue(str2));System.out.println(hash.hashValue(str3));System.out.println(hash.hashValue(str4));System.out.println(hash.hashValue(str5));System.out.println(hash.hashValue(str6));System.out.println(hash.hashValue(str7));System.out.println();char[] arr = { 'a', 'b' };int n = 20;System.out.println("生成長度為n,字符來自arr,所有可能的字符串");List<String> strs = generateStrings(arr, n);
// for (String str : strs) {
// System.out.println(str);
// }System.out.println("不同字符串的數量 : " + strs.size());HashSet<String> set = new HashSet<>();for (String str : strs) {set.add(hash.hashValue(str));}
// for (String str : set) {
// System.out.println(str);
// }System.out.println("不同哈希值的數量 : " + strs.size());System.out.println();int m = 13;int[] cnts = new int[m];System.out.println("現在看看這些哈希值,% " + m + " 之后的余數分布情況");BigInteger mod = new BigInteger(String.valueOf(m));for (String hashCode : set) {BigInteger bigInt = new BigInteger(hashCode, 16);int ans = bigInt.mod(mod).intValue();cnts[ans]++;}for (int i = 0; i < m; i++) {System.out.println("余數 " + i + " 出現了 " + cnts[i] + " 次");}}}直接cv的,咱也不研究寫法,直接看結果吧。
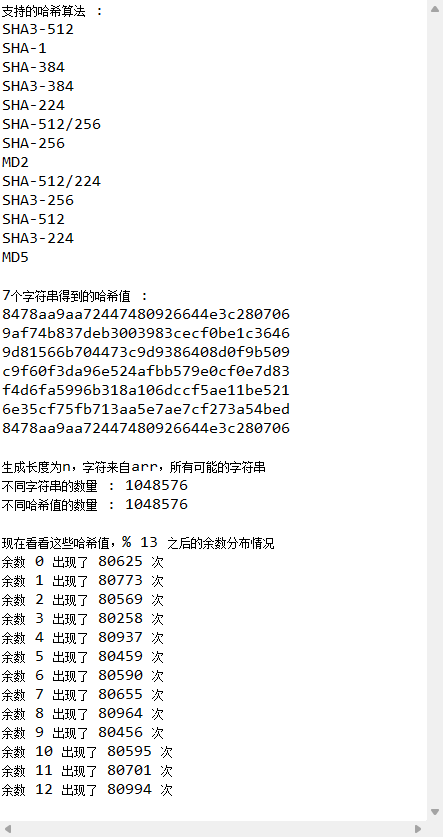
可以發現,雖然那幾個字符串相似度很高,但映射出來的哈希值差別非常大,這就完美體現了哈希函數的均勻性。同時,第一個字符串和最后一個字符串完全一樣,所以第一個和最后一個的哈希值也完全一樣。
接著,生成大量相似的字符串后,將其存到set里,可以發現數量能對得上,說明沒有發生哈希碰撞。之后再將所有的哈希值模13分組,可以發現每個結果的出現次數非常相近,這也能體現哈希函數的均勻性。
二、利用均勻性解決問題
問題描述:
一臺機器上硬盤空間很大,但內存空間很少,只有4G。給定100億個字符串的文件,每行是一個長100字節的字符串,統計哪個字符串出現次數最多。
問題解決:
這個第一眼就是用個map存個數,但再分析可以想到,如果字符串相同的話,進map其實只會增加對應的值,這是不太占用內存的。但如果最差情況下,即所有字符串都不同,那么map就需要開100億個鍵去存,這就會占用大量的空間了,估算一下是1T。
反推一下,假設4G的內存都用來存,那么map最多可以存3700萬個鍵,再保守一下當成1000萬個。之后先用100億除以這1000萬得到1000,那就可以在讀取每條字符串時先用哈希函數計算其哈希值。接著再把這個哈希值模上1000分組,然后把這條字符串分到其余數對應的文件里。因為哈希函數的特性,相同的字符串不可能分到兩個文件里。此時,雖然從個數上說,1000個文件里的數量不一定相同,但種類一定是均勻的。那么最后只需要關于每個文件用map統計最大詞頻的字符串,再統計這1000個文件的最大詞頻即可。
其實,很多工程上的問題都是利用哈希函數把大量的數據均勻分散到多個組里分別解決的。
三、哈希表原理
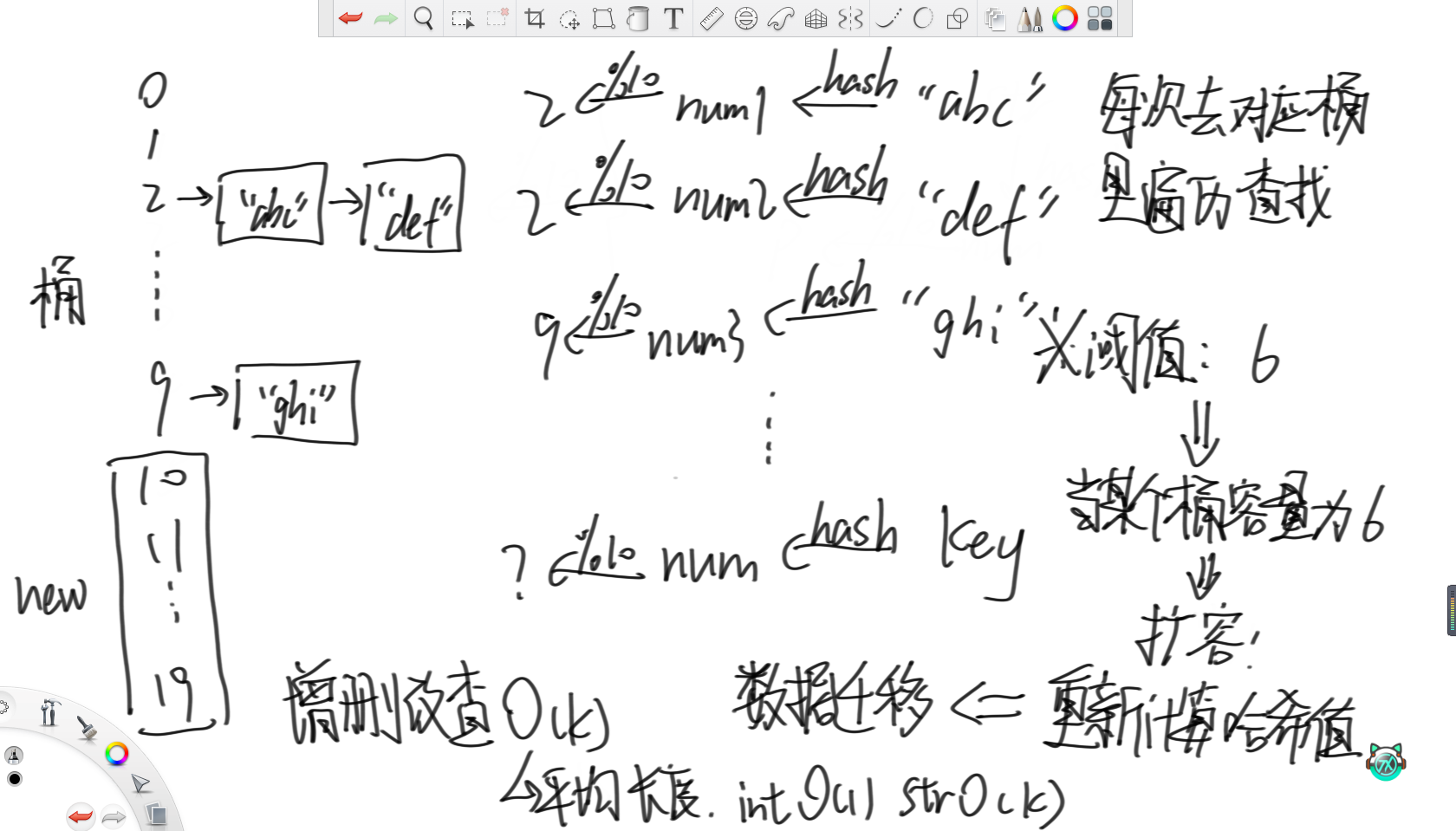
哈希表利用的就是上面寫的哈希函數的均勻性。首先,哈希表會初始準備若干個桶,這里假設10個。之后對于每一個要存入的字符串,都先用哈希函數計算出一個數值,然后模上桶的個數對其進行分組,再根據分好的組將其放入對應的桶里。那么如果要查某一個字符串的話,就可以先計算出其哈希值并取模,然后去對應的桶里遍歷查找即可。
因為哈希函數的均勻性,所以各個桶里的字符串數量應該是差不多的。所以當某個桶里字符串的個數達到了某個閾值,那么就可以認為所有桶里的個數都接近了這個閾值。此時就認為每次遍歷查找的代價過高,所以就考慮增加桶的數量,這里選擇將桶的個數翻倍。然后重新計算之前所有入桶的字符串的哈希值并重新分組,這稱為“數據遷移”。
所以,哈希表增刪改查的時間復雜度為O(k),若存儲的是數字,那么時間復雜度就是O(1),若是字符串,那么時間復雜度就是O(k),其中k為字符串的平均長度。
不難看出,可以通過設置哈希表的初始桶數、閾值、擴容因子、哈希函數和桶的結構來提高哈希表的性能。其中,擴容因子就是一次增加的桶的個數,桶的結構可以用數組實現、鏈表實現或者更高級的紅黑樹實現。
四、布隆過濾器

布隆過濾器可以理解為一個黑名單系統。其特點是可以保證在這個黑名單系統里的對象會被完全排除掉,但缺點是有可能排除不在黑名單里的對象。
首先,布隆過濾器需要準備一個位圖。位圖雖然本質上就是一個整型變量,但其十進制數字不代表任何含義,是用其32個二進制位來表示對應位的數字存在或不存在。之后,對于每個要進入這個布隆過濾器的id,用k個哈希函數將其轉化成數字,再將這幾個數字模上位圖的長度m,然后在位圖上將這幾個數字對應的位置全部涂黑即可。每當有一個id到來時,就用同樣的方法計算出其在位圖上的對應位置,若全是黑的就說明需要被排除掉。
所以根據哈希函數必然存在哈希碰撞的原理,布隆過濾器一定存在誤報的情況。那么就能得出,位圖長度越大,失誤率就越低。而隨著哈希函數的個數k的增大,失誤率會先下降,達到最低后會上升,因為會快速占滿整個位圖。
五、一致性哈希
1.經典存儲結構

在講述一致性哈希前,先講一下經典的存儲結構。
假設有三個機器用來存儲,對于每一個要存儲的key,都通過哈希函數轉化成一個數值,然后對其模3分組,存到對應的機器里。但很明顯,這種存儲結構存在兩個問題。
首先就是當傳來的key的數量不是很多,且對其查詢的頻率存在高低差異時,會導致機器的負載不均衡。舉個例子,對于所有國家名稱的詞條,肯定“中國”和“美國”的搜索頻率遠高于其他國家,甚至可能高于其他國家的總和。這時,假如這倆詞條被分到同一個機器里,那么這個機器的負載必然遠大于其他兩個機器。
第二個問題就是,假如到了節假日,搜索的頻率大大增加時,此時肯定需要通過增加機器來維持運營。那么就需要把里面存在的所有詞條都拿出來重新計算哈希值分組,這樣數據遷移的代價就非常大了。
2、一致性哈希
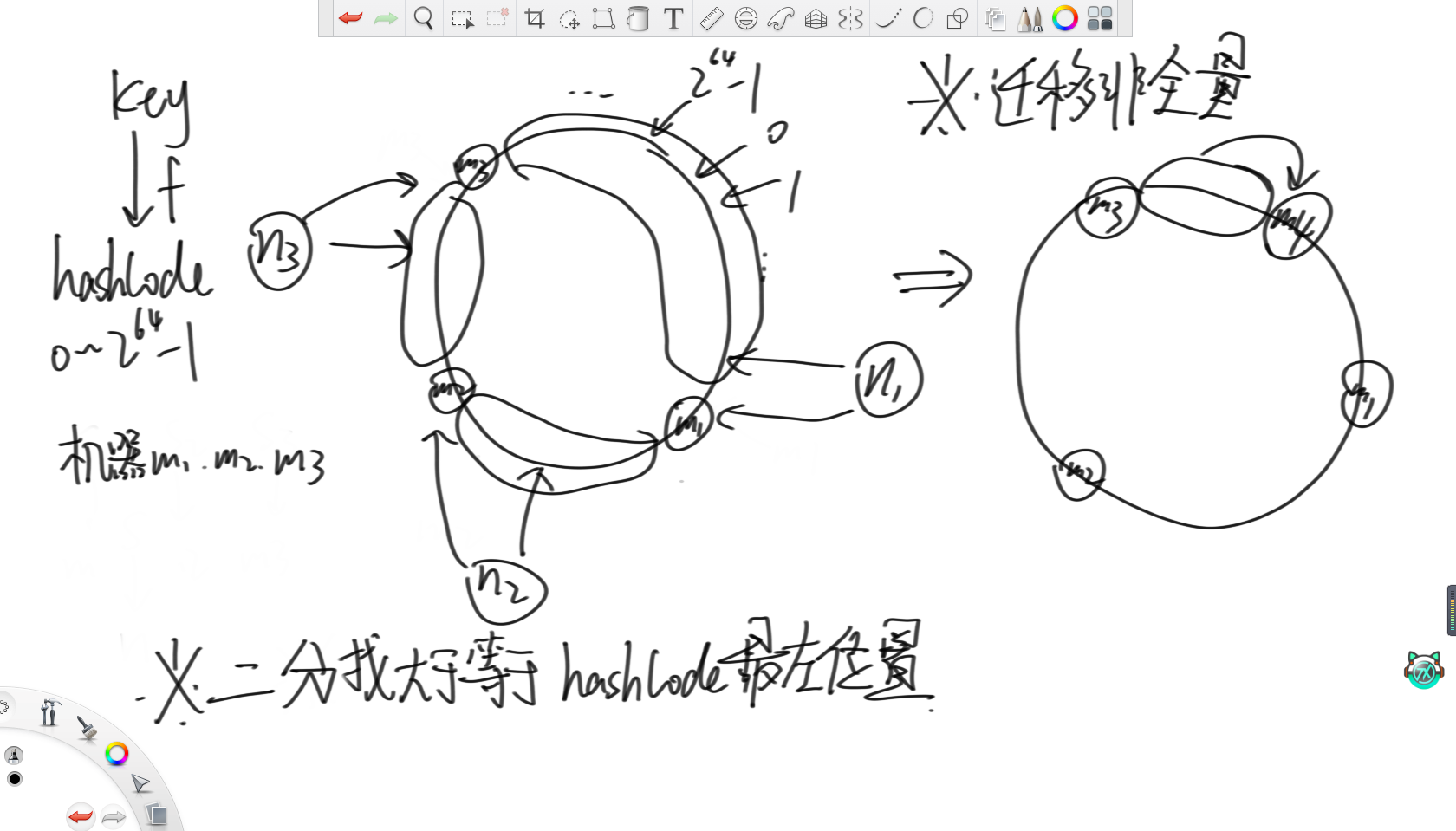
一致性哈希就是將哈希值的范圍0~2的64次方-1看成一個環,然后先用哈希值將三臺機器的id轉化出一個哈希值,然后打到這個環上的三個點。之后,對于每個到來的key,在計算出其哈希值后,讓它們也打到環上。然后根據這三個機器在環上的位置將環分為三組,每個機器負責打在自己組里的key,那么體現到代碼上就是每次在所有機器的哈希值里二分找大于等于key的哈希值的最左位置即可。這樣,當要增加機器時,只需要對部分數據進行遷移即可,此時數據遷移的代價就不是全量的了。
3.一致性哈希的缺陷
觀察這個過程不難發現,一致性哈希也存在一個缺陷,那就是依然無法解決負載不均的問題。當這幾個機器id的哈希值打在環上的位置無法把環等分,那么依然會存在一臺機器負責大多數key的情況。
4.改進方法——虛擬節點技術

基于這個問題,就出現了虛擬節點技術。虛擬節點技術說的是,既然原本因為機器數較少,不能很好地體現哈希函數的均勻性,從而導致負載不均,那么現在考慮對每個機器都增設虛擬節點。在上圖例子中,就對分別三臺機器增加了1000個虛擬節點,然后讓這3000個虛擬節點去搶環,這樣3000個點就比3個點更能體現哈希函數的均勻性,就能實現三臺機器負載均衡。之后,再按照上述分配key的方法分配到對應的虛擬節點上,再由虛擬節點映射到機器上即可。
當需要增加或減少節點數,就可以再來1000個虛擬節點,那么遷移的代價依然不是全量的。而對于性能有差異的機器,可以讓性能好的機器負載更多的key,那么就可以通過設置每臺機器虛擬節點數,讓高性能的機器多分節點,從而實現合理管理機器的負載。
六、一些有趣的工程算法
1.蓄水池采樣
假設有一個不停吐出球的機器,每次吐出1號球、2號球、3號球……有一個袋子只能裝下10個球,每次機器吐出的球,要么放入袋子,要么永遠扔掉。如何做到機器吐出每一個球后,所有吐出的球都等概率地被放進袋子。

這個題的思路就很巧妙了。
對于前m個球,那沒啥好說的,直接放入袋子。之后,每次對于第i號球,都以m/i的概率決定要還是不要。如果要的話,那么就需要等概率地淘汰袋子中的某個球。
在上述例子中,假設m等于10,那么當第11號球來到時,那么要的概率就是10/11。對于第12號球,要的概率就是10/12。

所以,對于第3號球,當吐出第11號球時,這顆球被淘汰的概率就是11號球要,且選中3號球淘汰的概率,那么就是1/10乘以10/11,等于1/11,所以3號球留下的概率就是10/11。同理,當吐出12號球時,3號球留下的概率為11/12。所以3號球最終留下的概率就是所有留下的概率相乘,那么約分完就等于10/n。由此可得所有球留下的概率均相等。
拓展問題:如何設計一個抽獎系統,讓一天內所有首次登錄的用戶都有均等的抽獎機會,中獎人數一共100人。
這個問題就和蓄水池采樣很類似了,就是讓前一百個人直接選中,之后每來一個人都按100/i的概率決定要還是不要即可。
2.內存限制類問題
32位無符號整數的范圍是0~4,294,967,295,現在有一個正好包含40億個無符號整數的文件。可以使用最多1G的內存,如何找到出現次數最多的數。
這個跟前面利用哈希函數均勻性的題一樣,重點是在這個情境下延伸出的其他問題。
(1)內存只有1G,如何找到所有沒出現過的數字。
內存只有1G,那么肯定不可能開個數組記錄出沒出現過,又因為只需要判斷出沒出現過,所以就考慮使用位圖表示一個數是否出現過即可。
(2)內存只有1G,如何找到所有出現了兩次的數
因為要找到所有出現兩次的數,既然同樣不能直接開個數組,那么同樣考慮使用位圖,但現在不用一位表示出沒出現過,而是用兩位表示一個數表示這個數出現幾次。那么00就是沒出現過,01就是出現一次,10就是出現兩次,11出現三次,大于三的情況直接不改了即可。最后只需要統計有幾個10狀態即可。
(3)內存只有3KB,如何只找到一個沒出現過的數

首先,3KB大約相當于3000位,大約就是750個int,而最接近750的2的冪是512。所以考慮將一個無符號int能表示的范圍分為512組,所以一組里就有2的32次方除以512,即8388608個數。然后用512個int變量,表示范圍內數字的出現次數。在上面例子中,a變量就負責統計0~8388607范圍上的數字的詞頻。那么對于缺失的數字,詞頻必然不夠8388608個,那么就再將這個范圍分為512組繼續統計詞頻即可。
(4)內存只有幾個變量的空間,如何只找到一個沒出現過的數
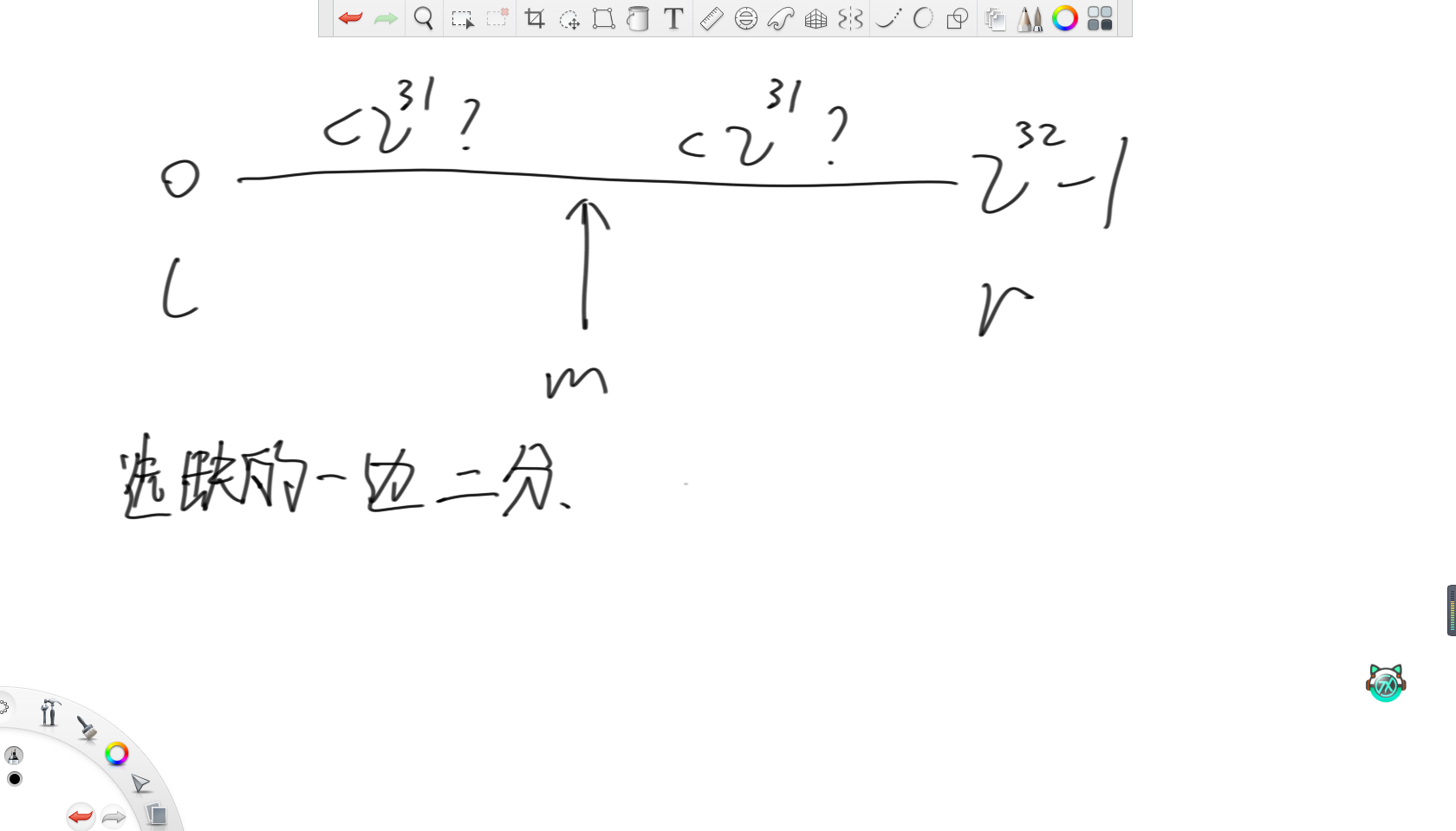
因為只需要找到一個沒出現過的數,那么直接將整型的范圍分別兩半,用兩個變量分別記錄每一邊的詞頻,然后每次選詞頻不滿的去二分即可。
(5)內存只有3KB,如何找到這40億個數字的中位數
如果是偶數長度,這里中位數認為是兩個數中較小的那個。
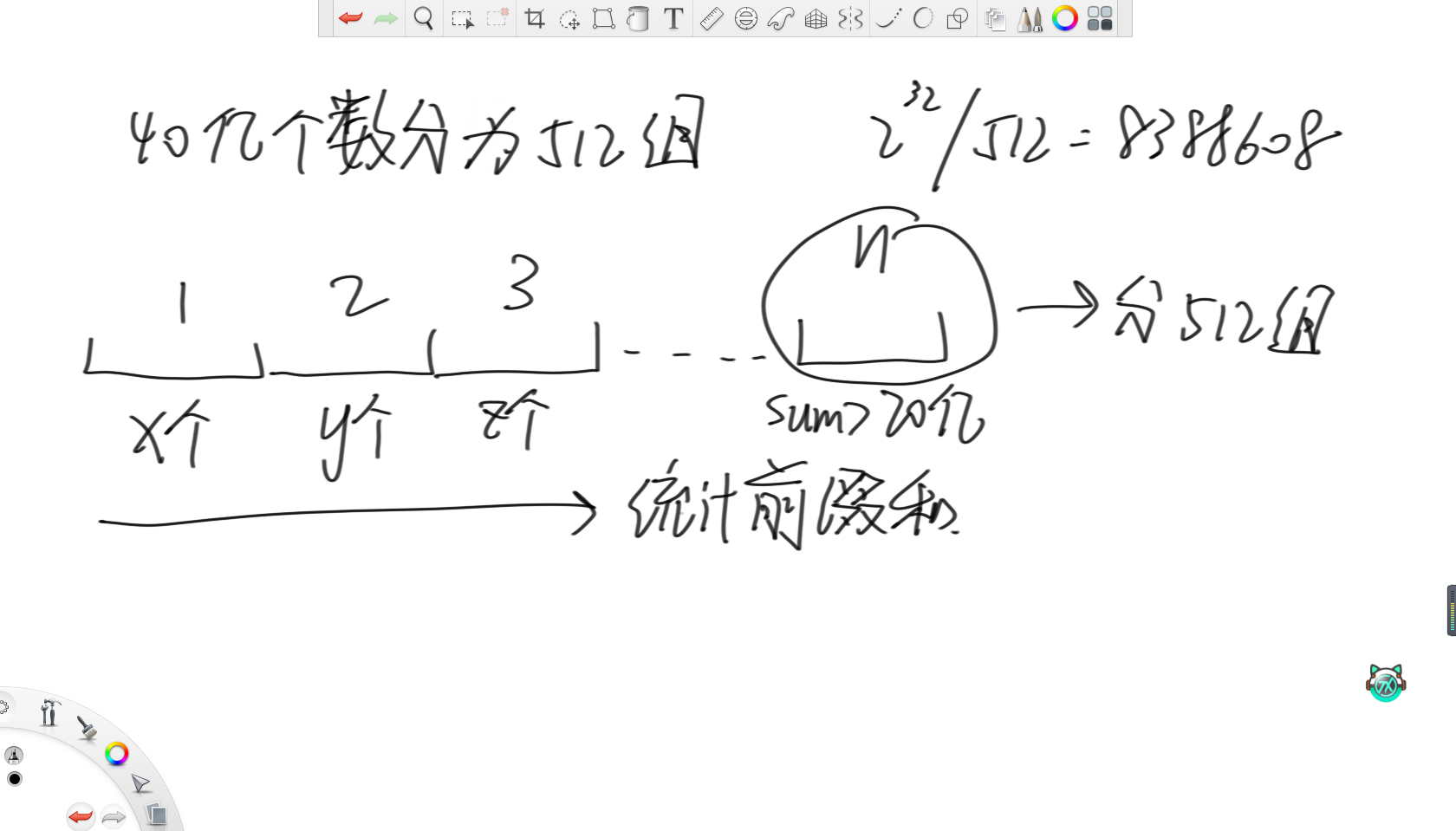
和問題(3)類似,還是將這40億個數分為512組,每一組負責8388608個數。因為有40億個數,那么要求的中位數就是第20億個數,所以在統計完這512個變量的詞頻后,統計其前綴和。當前綴和大于20億了,那么就說明第20億個數來自這8388608個數范圍內,那么就直接把這8388608個數分成512組,再統計詞頻即可。
3.文件排序問題
32位無符號整數的范圍是0~4,294,967,295。有一個10G大小的文件,每一行都裝著這種類型的數字,整個文件無序。給你5G的內存,請輸出一個為10G大小的為原文件排序后的文件。
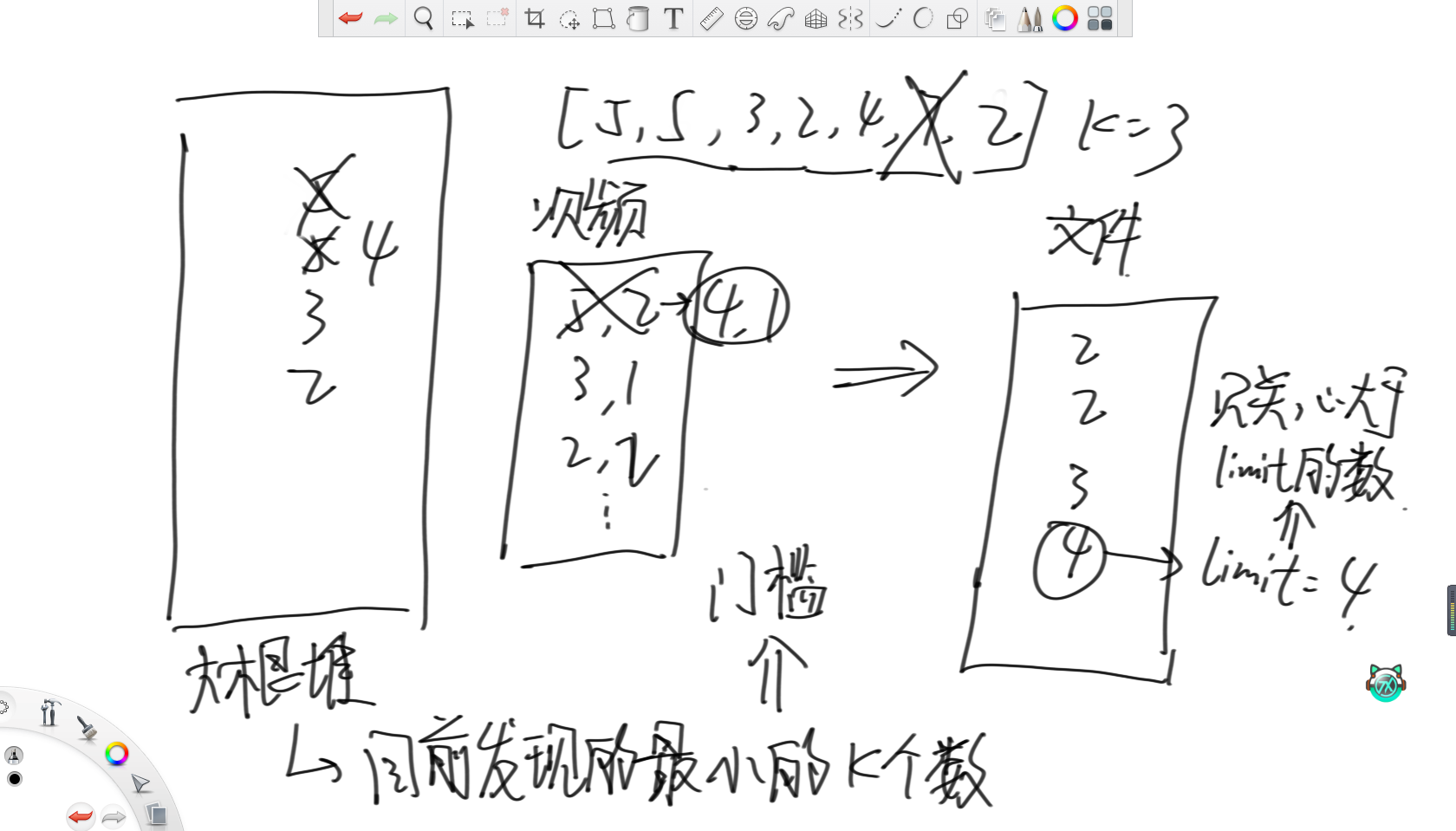
這個問題的思路是,設置一個大根堆,維護目前為止最小的k個數。其次,再設置一個map統計堆內數字的詞頻,這樣大根堆里就不會放重復的數字。之后的操作就是遍歷一遍文件,更新大根堆和這個map,然后往新文件里輸出按照詞頻全部輸出,接著用一個變量limit記錄此時的最大值。那么之后再遍歷文件時,就只關注大于limit的數,然后重復上述過程即可。
4.熱詞問題
某搜索公司一天的用戶搜索詞匯是100億規模的數據量,每個搜索詞匯不超過64字節。請設計一種每天從凌晨12點開始重新統計,當天任何時刻都能快速顯示Top100高頻詞的方法。
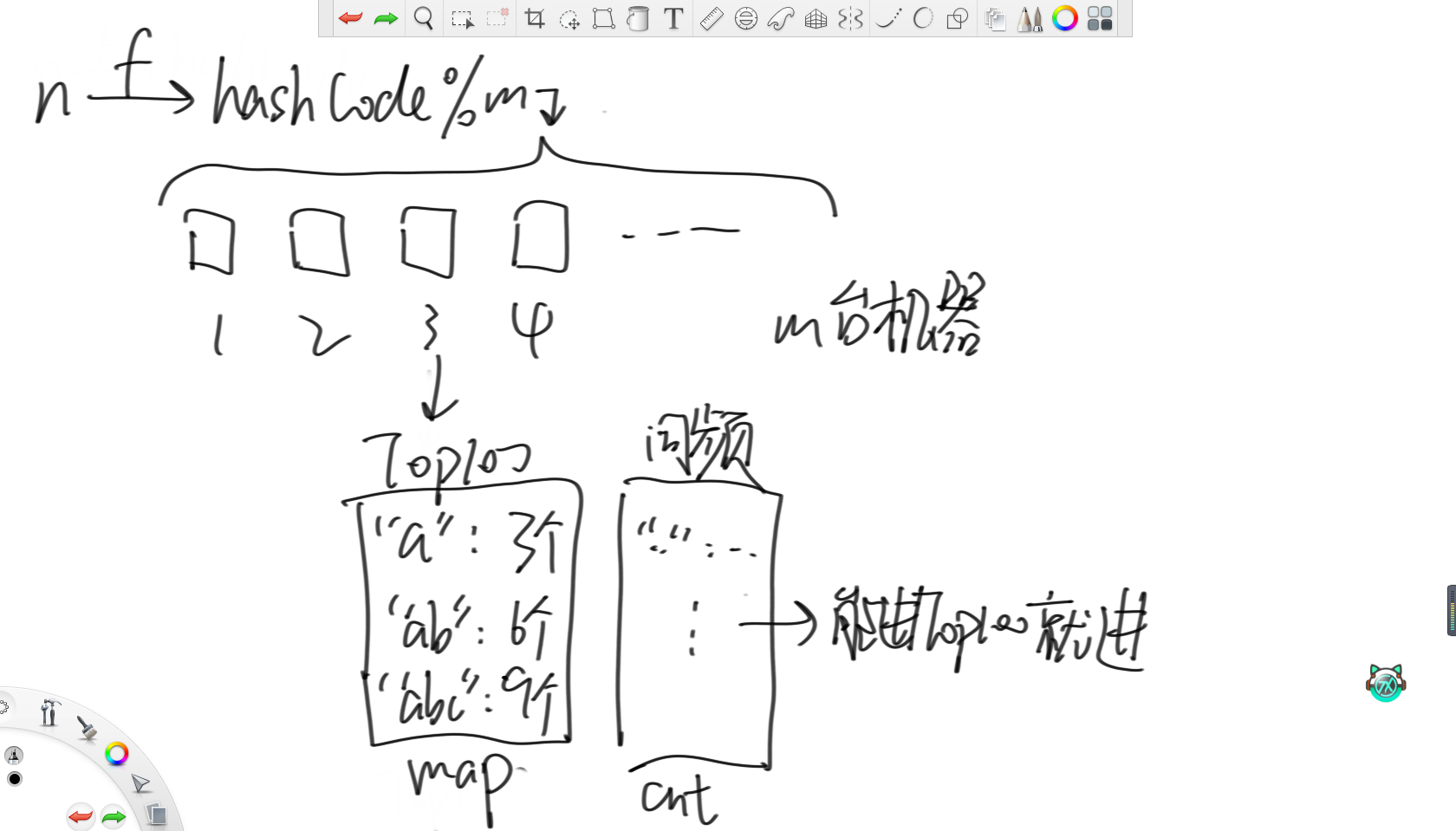
首先,對于搜索的詞n,先用哈希函數轉化成哈希值。之后,因為有m臺機器,那么就將這個哈希值模上m分到相應的機器里。其中,每臺機器里都設置一個大根堆維護詞頻最大的100個單詞和對應的詞頻,每當有一個能進前100單詞的詞就更新。
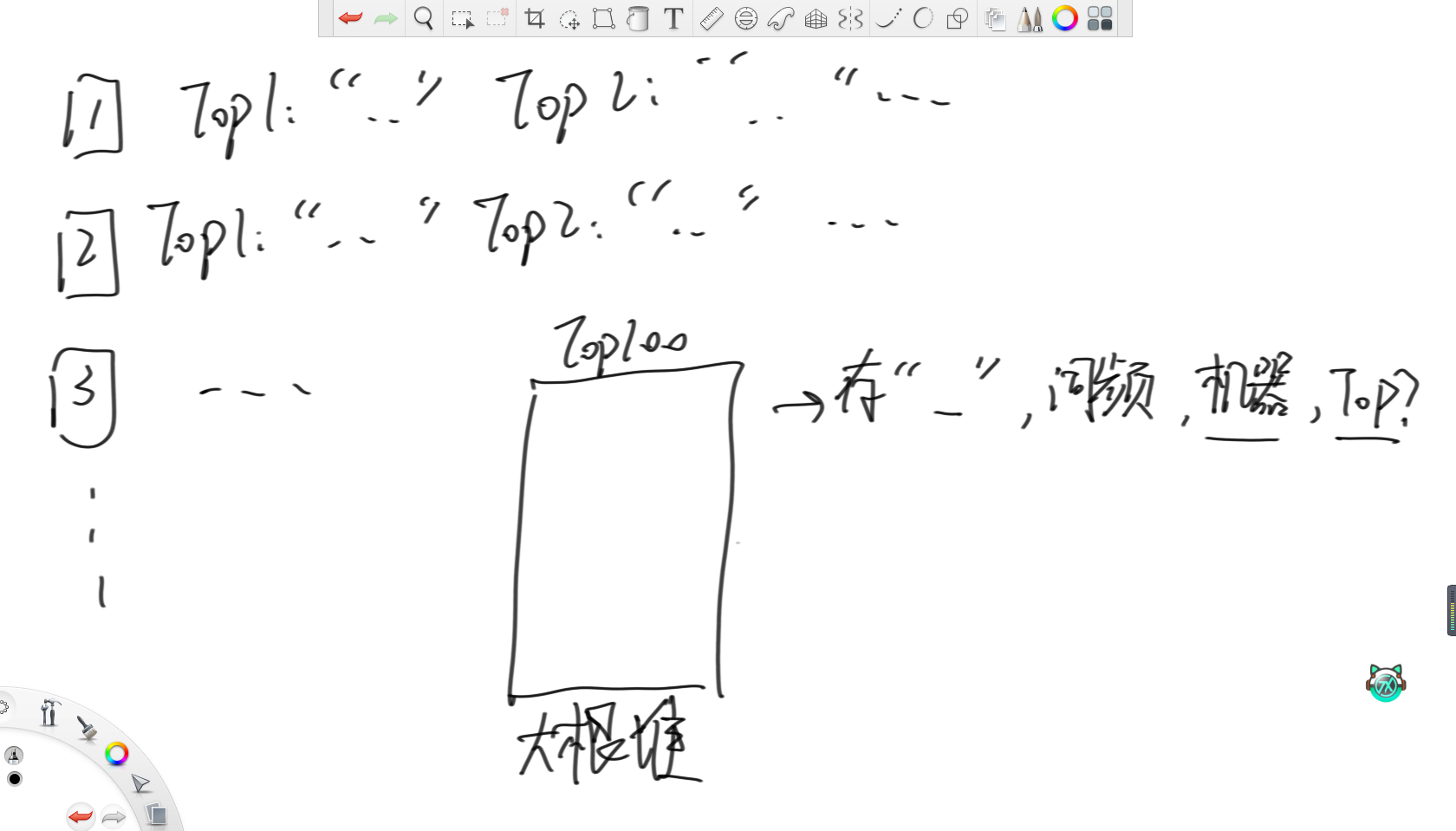
?這樣,每臺機器都存在自己的Top100熱詞。之后,設置一個大根堆維護詞頻,同時記錄單詞,詞頻,來自的機器和在自己機器里的排名。然后,每次彈出堆頂元素作為整體Top100的單詞,然后去彈出的這條記錄的機器里,把下一名的單詞加入大根堆,直到收集完整體的Top100單詞。
5.多線程任務分配問題
給定一個存著字符串的list,每個字符串長度在1~1000之間,字符串數量20億。每個字符串類似“hello,world,hello,cpp”,由兩個hello一個world一個cpp組成。請設計一種多線程的處理方案,統計list中每個字符串切分出的單詞數量,并且匯總。最終返回一個map表示每個字符串在list中的出現次數。機器資源允許最多開100個線程,使得速度盡可能快。
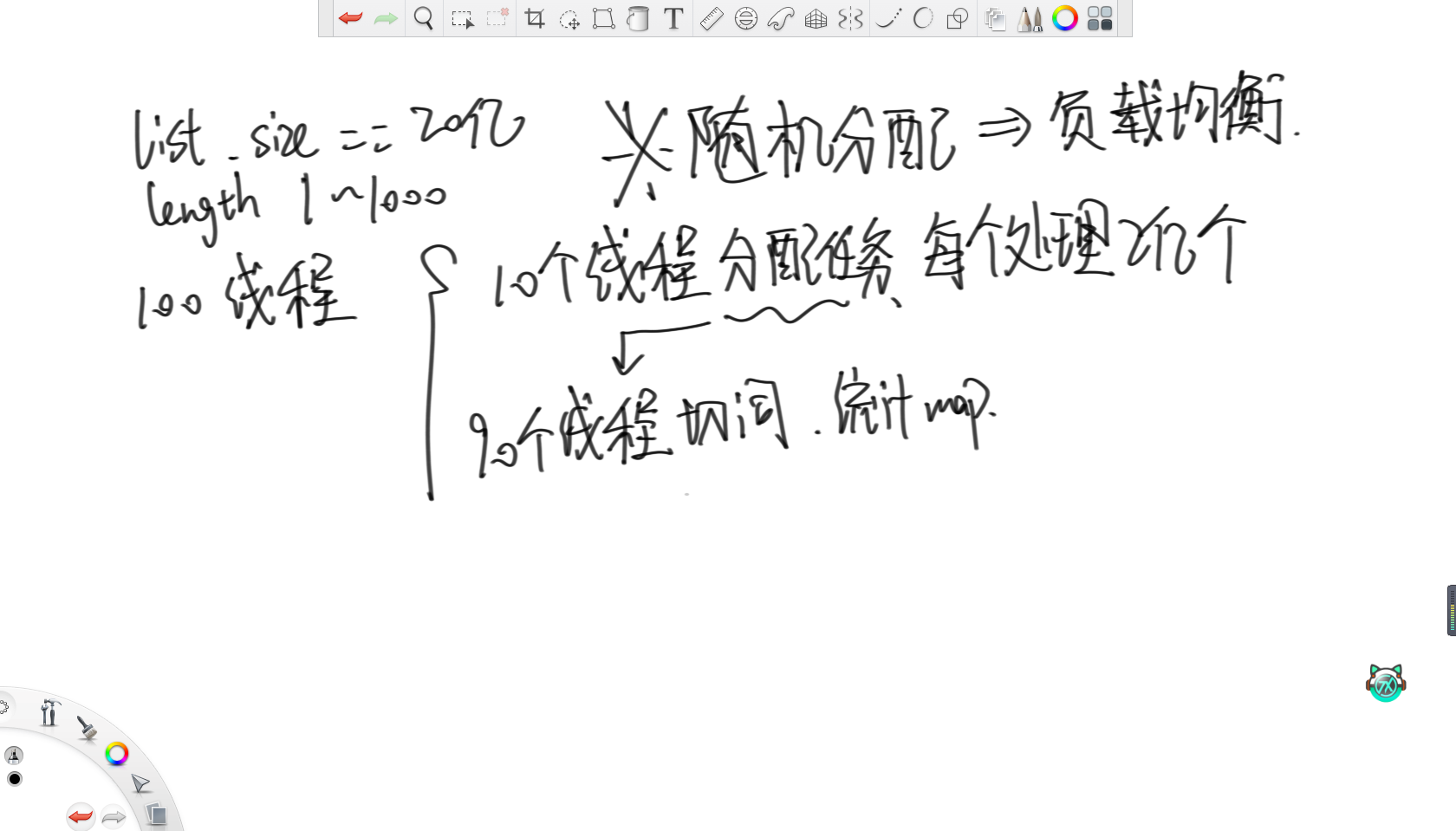
這個題的思路就比較巧妙了。
思路是就讓10個線程分配任務,所以每個線程只負責讀取自己范圍內2億個字符串。接著讓剩余90個線程負責切詞,并統計詞頻map。之后就是重點了,不管負載如何,純隨機給90個線程分配任務,這樣不管字符串是長是短,都會隨機地分配給這90個線程,所以就可以認為這90個線程的負載是均衡的。
6.設計全球的uuid系統
請設計一個只生成uuid的系統,要求理論上絕不出現相同的id,需要每秒數百萬億級別的并發,請問如何設計。
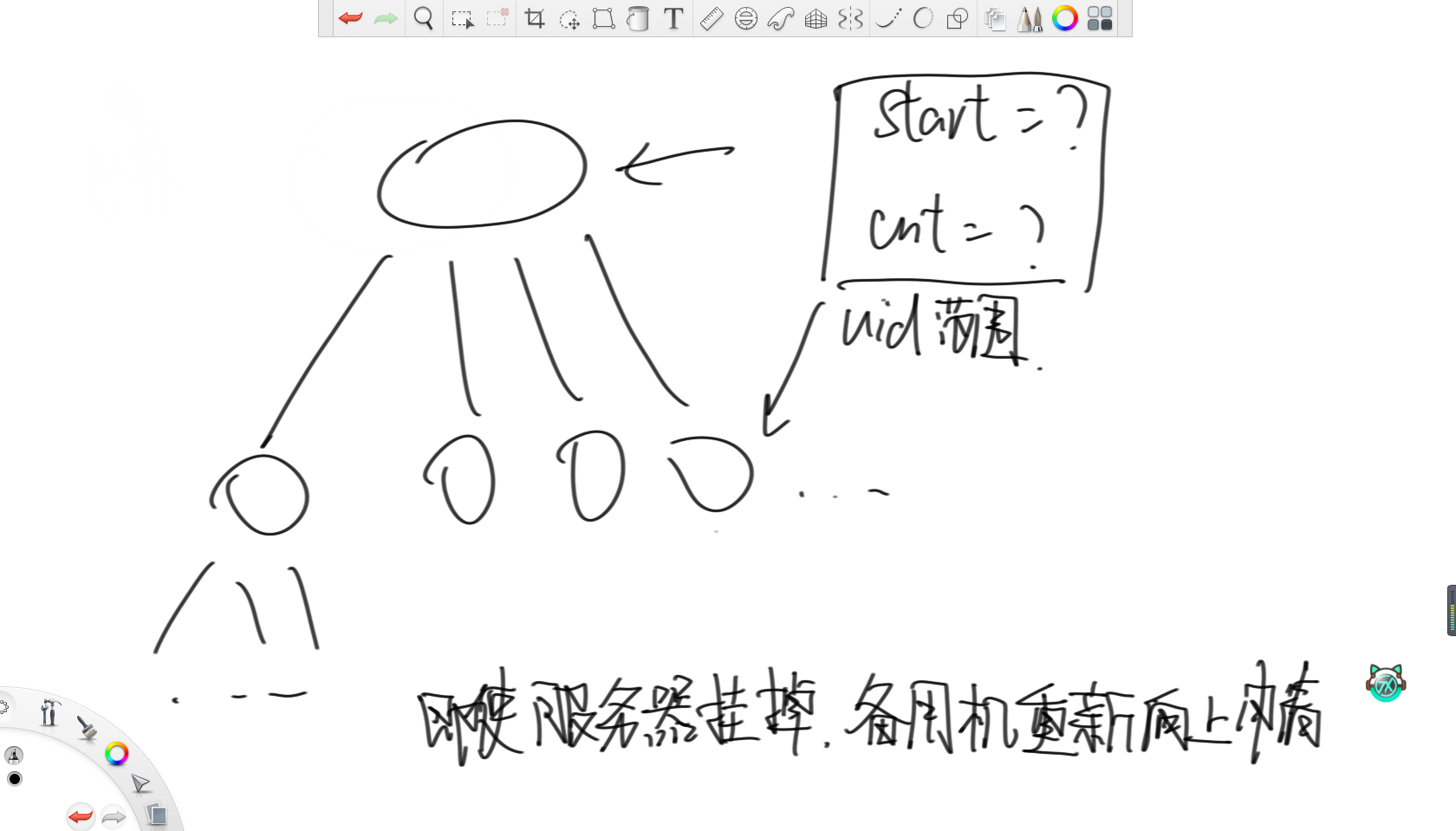
首先,頂端是世界服務器,下面有若干大洲服務器,接下來是國家服務器。對于世界服務器,設置一個start變量和cnt變量,分別記錄uuid的開始值和數量,每次分配完start往后跳cnt個。之后,每次向下分配時,都傳start和cnt這兩個變量,通過這兩個變量確認uuid的范圍。同理,大洲服務器也這樣向國家服務器分配,只要不夠了就向上級申請。
這樣設計的好處是,假如有一臺服務器突然出問題了,那么當備用服務器頂上時,根本不需要進行同步,直接向上申請新的一批uuid即可。
7.囚徒生存問題
有100個犯人被關在監獄,犯人編號0~99,監獄長準備了100個盒子,盒子編號0~99。這100個盒子排成一排,放在一個房間里面,盒子編號從左往右有序排列最開始時,每個犯人的編號放在每個盒子里,兩種編號一一對應,監獄長構思了一個處決犯人的計劃。
監獄長打開了很多盒子,并交換了盒子里犯人的編號。交換行為完全隨機,但依然保持每個盒子都有一個犯人編號。監獄長規定,每個犯人單獨進入房間,可以打開50個盒子,尋找自己的編號。該犯人全程無法和其他犯人進行任何交流,并且不能交換盒子中的編號,只能打開查看。尋找過程結束后把所有盒子關上,走出房間,然后下一個犯人再進入房間,重復上述過程。監獄長規定,每個犯人在嘗試50次的過程中,都需要找到自己的編號。如果有任何一個犯人沒有做到這一點,100個犯人全部處決。所有犯人在一起交談的時機只能發生在游戲開始之前,游戲一旦開始直到最后一個人結束都無法交流。請盡量制定一個讓所有犯人存活概率最大的策略。

很明顯可以想到,如果純隨機的話,那么活下來的概率就是二分之一的一百次方,這就很渺茫了。
正確的策略是,根據下標循環打開盒子。首先進來,每個人先打開自己編號的盒子,然后根據里面的編號,去打開和這個編號相同的盒子,所以這就是在繞圈。因為編號不重復,所以一定可以找到最終自己的編號。而因為每人只能開五十個箱子,那么其實就是在賭最大環的大小小于等于50。
之后通過計算,可以得到,按照這種策略進行,最終活下來的概率是31%,這就比純隨機開盒子的二分之一的一百次方要高的多了。
總結
有意思捏。







路徑屬性)
)









 視頻教程 - 微博輿情數據可視化分析-熱詞情感趨勢樹形圖)
