- textRank的工具包實現
- 其他可能的實現方法,對比結果
- 查找分類的相關算法
目錄
1. 關鍵詞提取TF-IDF + TextRank
1.1. TF-IDF算法
1.2. TextRank算法
1.3. 雙算法提取關鍵詞
2. 問題分類
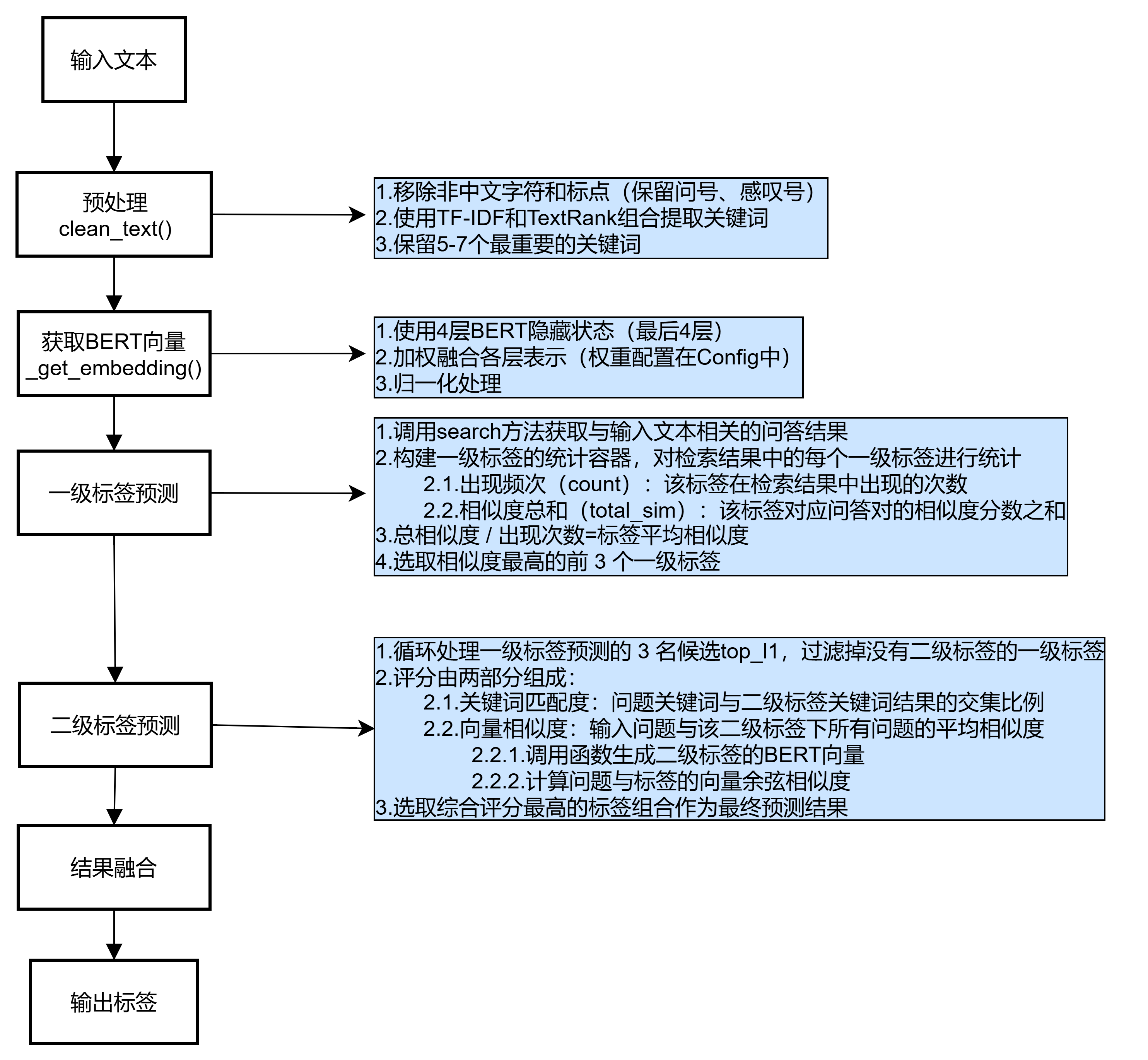
2.1. 預處理
2.2. 獲取BERT向量
2.3. 一級標簽預測
2.4. 二級標簽預測
3. 測試
3.1. 關鍵詞匹配度未發揮作用
3.2. 預測結果對比表
1. 關鍵詞提取TF-IDF + TextRank
1.1. TF-IDF算法
是一種統計方法,評估一個詞語在文檔中的重要程度。
TF-IDF 值
- TFIDF(t,d,D)=TF(t,d)×IDF(t,D)
- TF(詞頻)
- 詞語在當前文檔中出現的頻率,高頻詞重要
- TF(t,d)=詞語 t 在文檔 d 中出現的次數 / 文檔d的總詞數
- IDF(逆文檔頻率)
- 詞語在整個語料庫中的稀有程度,全局重要性,語料庫中出現越少的詞權重越高,稀有詞區分度高
- IDF(t,D)=log?(語料庫中文檔總數 N / (包含詞語 t 的文檔數+1))
- 加1避免分母為零
缺點
- 忽略語義:無法捕捉詞語間的語義關系(如"深度學習"和"神經網絡"的關聯)、同義詞
- 稀疏性問題:長尾詞可能被過度加權
- 依賴語料庫:受限于訓練語料的覆蓋范圍,專業領域新詞可能權重異常
1.2. TextRank算法
特點:
- 圖模型:將文本轉化為圖結構,詞語為節點,關系為邊
- 迭代計算:基于PageRank思想,通過投票機制計算節點重要性
- 上下文感知:考慮詞語的局部窗口共現關系
優點:
- 語義感知:能捕捉詞語間的關聯性,如"機器學習"和"算法"
- 無需訓練:直接處理單文檔,適合動態文本
- 短語提取:可識別復合詞,如"自然語言處理"
1.3. 雙算法提取關鍵詞
特殊字符過濾
text = re.sub(r"[^\w\u4e00-\u9fa5??!!]", "", text)TF-IDF 提取:
jieba.analyse.extract_tags(text,topK=10, # 提取前10個關鍵詞withWeight=False, # 不返回權重allowPOS=('n', 'v', 'a', 'nr', 'ns', 'nz') # 僅保留名詞、動詞、形容詞等
)- 原理:基于詞頻 - 逆文檔頻率,強調在當前文本中出現頻繁但在語料庫中不常見的詞
- 詞性篩選:保留名詞(n)、動詞(v)、形容詞(a)、人名(nr)、地名(ns)、其他專有名詞(nz),過濾虛詞、副詞等無實際意義的詞
TextRank 提取:
jieba.analyse.textrank(text,topK=10,withWeight=False,allowPOS=('n', 'v', 'a', 'nr', 'ns', 'nz')
)- 原理:基于圖模型,通過詞與詞的共現關系計算重要性
- 優勢:能捕捉文本內部語義關聯
關鍵詞合并與篩選
combined = []seen = set()for kw in tfidf_kws + textrank_kws:if kw not in seen:seen.add(kw)combined.append(kw)# 保留前5-7個關鍵詞return " ".join(combined[:7]) if combined else ""- 去重邏輯:通過
seen集合合并兩種算法的結果,優先保留先出現的關鍵詞,去重 - 長度控制:保留前 5-7 個關鍵詞,用空格拼接為字符串
- 邊界處理:若未提取到關鍵詞,返回空字符串
2. 問題分類
實現問答數據的自動分類(自動標注一級、二級標簽)
2.1. 預處理
調用clean_text()函數
- 移除非文本字符,保留中文字符、基本標點和重要詞匯結合
- TF-IDF 和 TextRank 算法提取關鍵詞
- 合并去重后保留前 7 個關鍵詞作為核心特征
2.2. 獲取BERT向量
調用_get_embedding()函數
- 加載預訓練 BERT 模型和分詞器
- 取模型最后 4 層的隱藏狀態
- 按預設權重([0.15, 0.25, 0.35, 0.25])融合各層 CLS 向量
- 對融合向量進行歸一化處理
2.3. 一級標簽預測
search_results = self.search(text) # 統計一級標簽出現頻率和平均相似度
l1_stats = defaultdict(lambda: {'count': 0, 'total_sim': 0.0})
for result in search_results:l1 = result['tags']['level1']l1_stats[l1]['count'] += 1l1_stats[l1]['total_sim'] += result['similarity']# 計算每個一級標簽的平均相似度l1_scores = {l1: stat['total_sim']/stat['count'] for l1, stat in l1_stats.items()}if not l1_scores:return {'level1': '其他', 'level2': '無'}# 取相似度最高的前3個候選
top_l1 = sorted(l1_scores.items(), key=lambda x: x[1], reverse=True)[:3]- 通過
search方法獲取與輸入文本相關的問答結果,包含問題、答案、相似度、標簽 - 用
defaultdict構建一級標簽的統計容器,對檢索結果中的每個一級標簽進行統計- 出現頻次(
count):該標簽在檢索結果中出現的次數 - 相似度總和(
total_sim):該標簽對應問答對的相似度分數之和
- 出現頻次(
- 總相似度 / 出現次數=標簽平均相似度
- 選取相似度最高的前 3 個一級標簽
2.4. 二級標簽預測
keywords = set(cleaned.split())
best_score = -1
best_tags = {'level1': top_l1[0][0], 'level2': '無'}for l1, l1_score in top_l1:if l1 not in self.tag_config.LEVEL2:continuefor l2 in self.tag_config.LEVEL2[l1]:# 關鍵詞匹配l2_cleaned = clean_text(l2) l2_keywords = set(jieba.lcut(l2_cleaned)) kw_score = len(keywords & l2_keywords) / max(len(l2_keywords), 1)# 向量相似度l2_vec = self._get_embedding(l2_cleaned) vec_score = np.dot(query_vec, l2_vec) # 綜合評分total_score = 0.6 * vec_score + 0.4 * kw_scoreif total_score > best_score:best_score = total_scorebest_tags = {'level1': l1, 'level2': l2}- 按空格分割預處理后的
cleaned,得到關鍵詞集合,初始化最佳評分、標簽結果 - 循環處理一級標簽預測的 3 名候選
top_l1,過濾掉沒有二級標簽的一級標簽 - 評分由兩部分組成:
- 關鍵詞匹配度
kw_score(40% ):問題關鍵詞與二級標簽關鍵詞結果的交集比例 - 向量相似度
vec_score(60% ):輸入問題與該二級標簽下所有問題的平均相似度- 調用函數生成二級標簽的BERT向量
- 計算問題與標簽的向量余弦相似度
- 關鍵詞匹配度
- 選取綜合評分最高的標簽組合作為最終預測結果
3. 測試
3.1. 關鍵詞匹配度未發揮作用
根據調試結果,關鍵詞部分的匹配度始終為0,未發揮作用
處理問題: 什么是佛教中的四圣諦?
預處理完成: 圣諦 佛教
向量維度: (768,)
候選一級標簽: [('道理', 0.6594605436445109), ('修行', 0.6436407618586859), ('生活', 0.6339292906486615)]
二級標簽'道理/人生'評分: 0.58 (向量:0.96, 關鍵詞:0.00)
二級標簽'道理/天道'評分: 0.58 (向量:0.97, 關鍵詞:0.00)
最終預測: {'level1': '道理', 'level2': '天道'}
二級標簽'修行/佛家'評分: 0.59 (向量:0.99, 關鍵詞:0.00)
二級標簽'修行/儒家'評分: 0.58 (向量:0.96, 關鍵詞:0.00)
二級標簽'修行/道家'評分: 0.58 (向量:0.97, 關鍵詞:0.00)
最終預測: {'level1': '修行', 'level2': '佛家'}
二級標簽'生活/健康'評分: 0.57 (向量:0.96, 關鍵詞:0.00)
二級標簽'生活/教育'評分: 0.58 (向量:0.96, 關鍵詞:0.00)
二級標簽'生活/食品'評分: 0.57 (向量:0.96, 關鍵詞:0.00)
最終預測: {'level1': '修行', 'level2': '佛家'}
預測結果: {'level1': '修行', 'level2': '佛家'}
3.2. 預測結果對比表
| 測試問題 | 實際預測 | 理想預測 |
| 什么是佛教中的四圣諦? | 修行,佛家 | 修行,佛家 |
| 孔子說的'己所不欲勿施于人'如何實踐? | 修行,儒家 | 修行,儒家 |
| 莊子講的'逍遙游'是什么境界? | 修行,道家 | 修行,道家 |
| 每天快走30分鐘有什么健康益處? | 生活,健康 | 生活,健康 |
| 如何培養孩子的閱讀習慣? | 道理,人生 | 生活,教育 |
| 隔夜菜到底能不能吃? | 生活,教育 | 生活,食品 |
| 如何面對生活中的重大挫折? | 生活,教育 | 道理,人生 |
| 為什么說'善惡終有報'? | 道理,天道 | 道理,天道 |
準確率統計
| 指標 | 數量 | 比例 |
| 完全正確 | 5 | 62.5% |
| 一級標簽正確 | 1 | 12.5% |
| 完全錯誤 | 2 | 25% |
對于修行一級標簽預測較好,另外兩個一級標簽較差;初步分析可能與數據源的樣本數量有關,心法問答.csv的標簽分布如下:
| 一級標簽 | 二級標簽 | 數量 |
| 修行33 | 儒家 | 24 |
| 道家 | 8 | |
| 佛家 | 1 | |
| 生活25 | 教育 | 22 |
| 健康 | 2 | |
| 食品 | 1 | |
| 道理18 | 人生 | 10 |
| 天道 | 8 |




 視頻教程 - 微博輿情數據可視化分析-熱詞情感趨勢樹形圖)

單鏈表專題2.單鏈表的應用)

)
)




——繼承(一)繼承的理解,實現,特點……)
更新)



