寫這一篇的緣由一是因為我也在摸索如何降低?AI?幻覺提升?AI?工具使用效率,二是因為前兩周在MIT學習時老師講的一節課,剛好也解釋了這個問題,所以一并做個總結,分享給大家。
近幾年,大型語言模型(LLM)如?ChatGPT、Claude、Gemini?等快速走進公眾視野。它們能生成結構完整、邏輯清晰的長文本,甚至可以進行代碼編寫、法律文書撰寫、醫學咨詢等高難度任務。然而,我們也越來越頻繁地聽到一個術語:AI幻覺。簡單說,它指的是模型“說得像真的,但其實是錯的”。
本文將嘗試解釋三個問題:
-
什么是?AI?幻覺?為什么語言模型會產生幻覺?
-
GPT-4?等新一代模型是否真的減少了幻覺?
-
如何盡可能減少幻覺帶來的誤導?

一、語言模型不是在“理解”,而是在“預測”
GPT?的全稱是?Generative?Pre-trained?Transformer,其核心任務是:給定一段輸入,預測下一個最可能出現的詞(token)。這種機制的本質是統計語言模式,而不是基于事實的知識回憶或理解。
舉個例子,輸入“喬布斯和馬斯克在球場上”,模型會續寫出“展開了一場激烈的籃球比賽”,盡管這從未真實發生。這不是模型有意捏造,而是它識別出“人名?+?球場”常出現在比賽語境中,于是生成符合語言習慣的句子。
這類“幻覺”即來自其構建方式:模型的目標不是還原事實,而是生成“在訓練語料中最常見或最自然”的文本。也就是說,它輸出的是“語言上的合理”,而非“世界中的真實”。
這也是幻覺的來源:在不知道答案時,模型仍然會“給出一個聽起來合理的回答”。
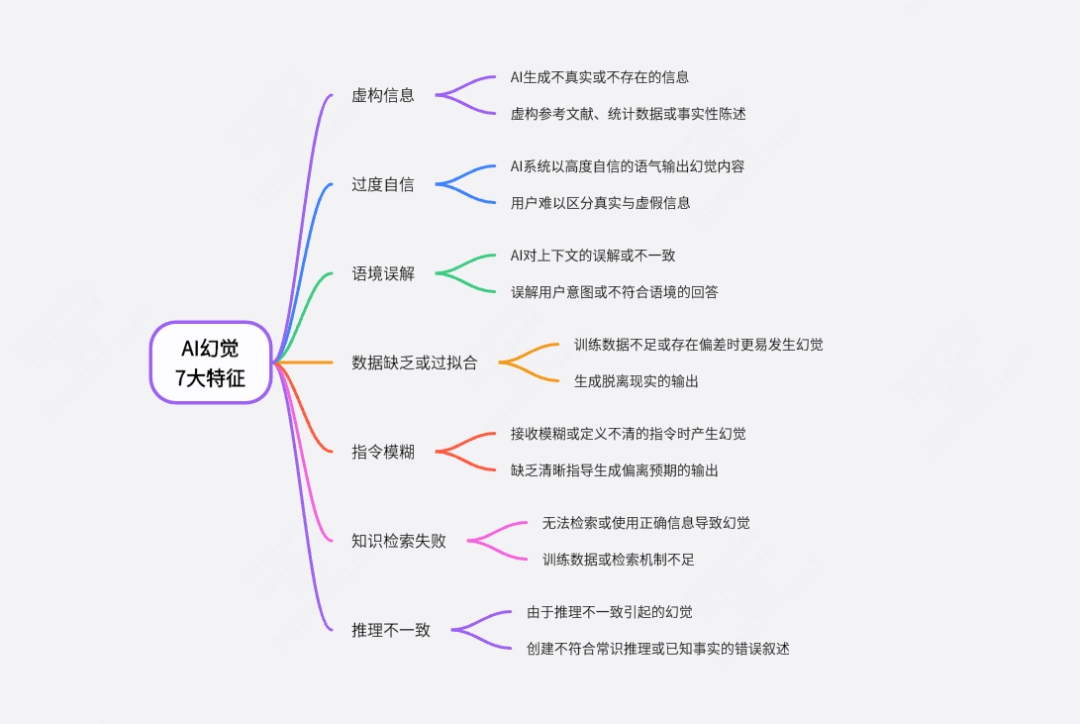

二、幻覺的技術根源:訓練機制、知識覆蓋與任務設定
-
訓練機制決定幻覺傾向:GPT?采用的是無監督學習方法,即在大規模互聯網文本上訓練模型,其唯一目標是最大化下一個詞出現的概率,而不是核查事實。這種機制天然就傾向于生成“似是而非”的內容。
-
語料中的事實不等于知識庫:模型并不保存某種結構化知識圖譜或數據庫,它記住的是“什么詞經常和什么詞一起出現”,而不是“誰獲得了?2022?年冬奧會金牌”這種事實信息。
在?MIT?的課上,教授舉了一個例子:
“問?GPT?3.5:‘誰贏得了?2022?年冬奧會冰壺金牌?’——模型回答錯誤,稱韓國女隊獲勝,而實際上是英國隊。”
原因在于:GPT?3.5?的訓練數據截止于?2021?年,不包含?2022?年的事實。因此只能“模仿出一個合理答案”,而不是“查找真實答案”。
-
Prompt?的誘導效應:用戶的提問方式對模型結果有很強導向性。例如:“請寫一篇關于愛因斯坦和馬斯克辯論環保問題的稿件”,這個語句默認了事件的真實性,模型不會去驗證事實,只會按“劇本”生成。
-
缺乏世界建模能力:GPT?不理解時間、空間或因果關系。即便在邏輯上存在沖突,模型也不會主動識別,而是依賴文本連貫性生成語言。


三、GPT-4?相較?GPT-3.5?幻覺減少了嗎?為什么?
整體來看,GPT-4?的幻覺率相較?GPT-3.5?有所下降,背后有以下幾點改進:
(來源:OpenAI.?:GPT-4?Technical?Report.?2023)
1.?更大的訓練數據集:覆蓋更多領域與長尾知識,減少“知識空白”導致的猜測;
2.?更強的上下文理解能力:GPT-4?的?context?window?擴大至?32k?token,使其能記住更多上下文,減少斷章取義和語義漂移;
3.?引入人類反饋強化學習(RLHF):在模型微調階段,使用人類標注反饋強化“承認不知道”優于“胡編亂造”的行為;(之前介紹的?Scale?AI?做的就是這個生意)
每天一個?FUN?AI|Scale?AI:AI?產業鏈的“隱形軍火商”
4.?微調策略優化:特別針對幻覺問題,引入了對輸出置信度的判斷機制,使模型在低置信度時更傾向于給出模糊或保守的回答。
不過,即使如此,幻覺依然存在,尤其在以下場景更容易觸發:
-
冷門專業領域(如罕見病、邊緣法律問題);
-
問題提示模糊或含有虛構前提;
-
用戶詢問的是未來或最新事件;

四、如何最大限度減少?AI?幻覺?用戶與系統端的協同策略
1.?用戶端優化:
-
使用明確提示語,例如:
“如果你不知道,就說不知道”
“基于我上傳的文檔回答”
-
使用結構化?Prompt?限制模型的自由發揮范圍,如“請分三點說明”“用表格列出”;
-
避免誘導性或假設前提問題,尤其是在高風險領域;
2.?系統端優化:
-
檢索增強生成(RAG):給模型增加一個“查資料”模塊,讓它回答前先查外部數據庫或網頁;
-
插件與聯網設計:如?Wolfram?Alpha(做計算)和?Bing?Search?插件(查新聞)已集成至?GPT?產品中,提升事實查驗能力;
-
多階段生成機制:將“任務理解、信息檢索、生成內容”分階段執行,避免一次性完成的單步誤導;
-
專業模型精調:在醫學、金融、法律等專業領域,訓練專門子模型來提供更安全、準確的答案。
最后:語言的流暢,不等于事實的可靠
幻覺是當前大型語言模型的結構性副產物,它既不是“錯誤”,也不是“欺騙”,而是模型生成機制與真實世界之間的落差,是語言模型當前能力邊界的自然結果。
理解這一點,是我們理性使用?GPT?和類?AI?工具的基礎,也提醒我們:生成式語言的“像真度”,并不等于它的真實性。
未來,隨著外部工具接入、Agent?機制完善、責任機制明確,幻覺問題會被進一步緩解。但在那之前,任何看起來“說得頭頭是道”的?AI?回答,我們都應保留驗證的習慣。
周一,祝大家今天開心。
封面和摘要
深度解析?|?AI?幻覺的形成和應對路徑

--字符分類函數,字符轉換函數,strlen,strcpy,strcat函數的使用和模擬實現)
質數時間)


![[Windows]Postman-app官方歷史版本下載方法](http://pic.xiahunao.cn/[Windows]Postman-app官方歷史版本下載方法)













