文章目錄
- ==有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主==
- 項目介紹
- 總結
- 每文一語
有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主
項目介紹
隨著短視頻行業的高速發展,尤其是以抖音為代表的平臺不斷壯大,每日吸引著大量用戶上傳視頻內容以記錄生活、表達觀點。在此過程中,不僅有海量普通用戶的參與,也出現了諸如內容營銷機構、流量運營團隊等專業化群體,他們通過構建流量矩陣、內容優化等方式,實現賬號曝光度與影響力的持續增長。
本研究以用戶是否對短視頻作品點贊為目標變量,深入挖掘影響其行為決策的關鍵因素。為此,我們在和鯨數據、CSDN 以及 Kaggle 等數據平臺上采集了與短視頻點贊行為相關的多個數據集,樣本總量約為170萬條。數據內容涵蓋用戶的觀看行為特征、作者的基礎屬性、以及作品維度等多個方面,具備較強的代表性與多樣性。
在數據預處理環節,首先對重復記錄與缺失值進行了清洗和補全,同時統一字段格式與類型。隨后將原始數據劃分并構建為三大類特征數據集,分別為用戶行為特征集、作品屬性特征集與作者基本信息特征集。基于這些結構化數據,展開深入的分析與可視化研究。
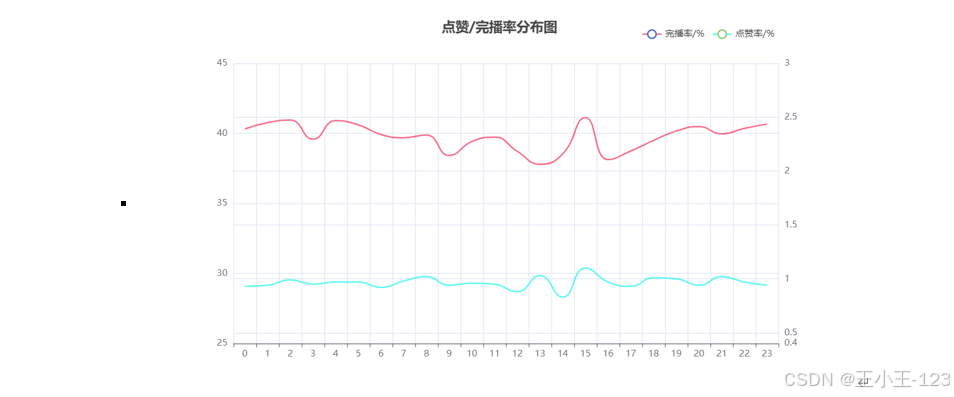
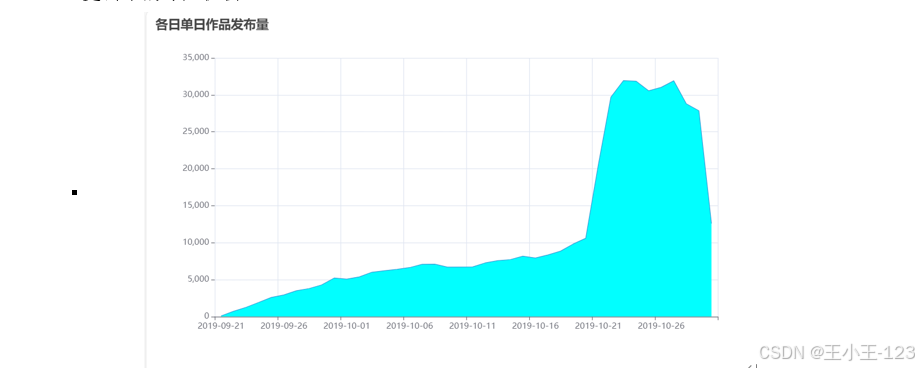
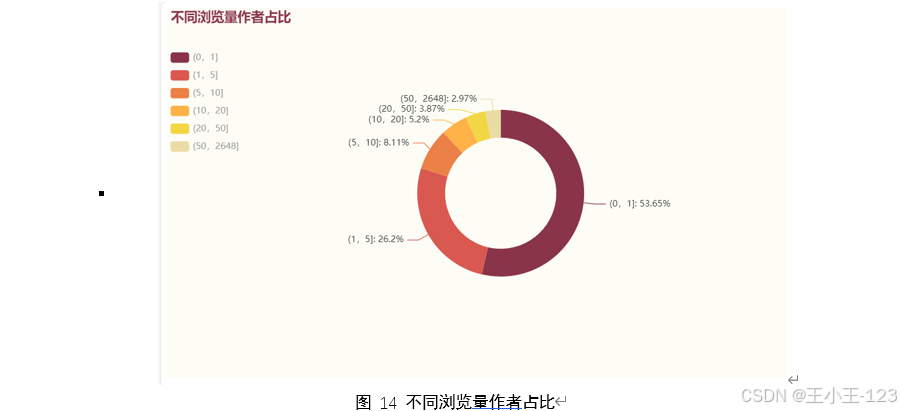
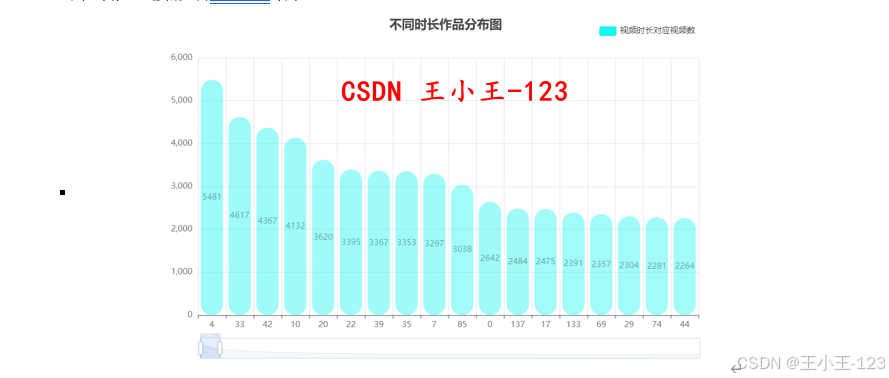
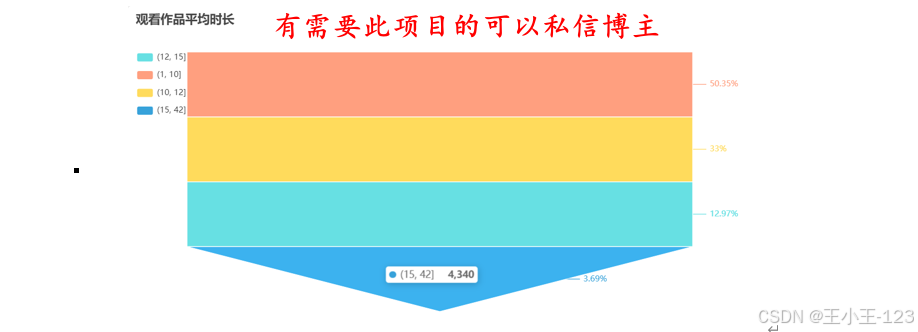
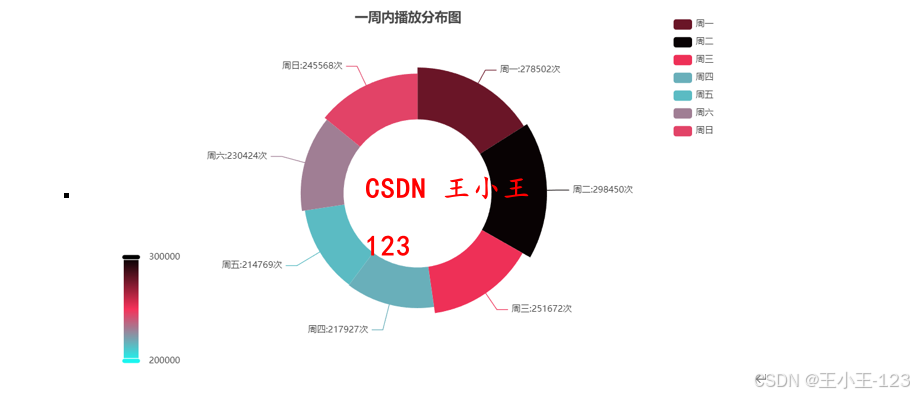
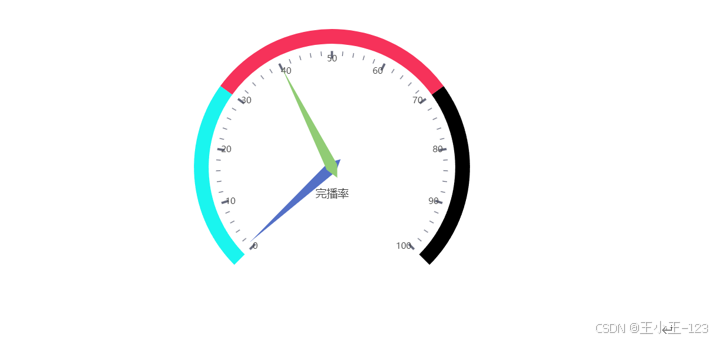
在數據分析方面,采用了 Pyecharts 可視化工具,對各類維度進行統計分析與畫像建模。例如,在用戶行為分析中,關注用戶瀏覽量分布、完整播放率、平均觀看時長等指標;在作者特征分析中,探討作者瀏覽量分布、城市地域分布與創作活躍度等維度;在作品維度中,分析點贊量、播放量、使用背景音樂頻率、作品發布時間與發布城市等內容。
此外,研究還對短視頻平臺的整體畫像進行了刻畫,如不同地域用戶分布、時間段播放行為、點贊率與完播率的時間趨勢、一周內播放變化、作品時長與PV/UV等關鍵指標的統計分布。為進一步理解用戶和作者群體特征,本文還應用聚類算法對其進行分群,挖掘不同群體在互動行為上的差異。
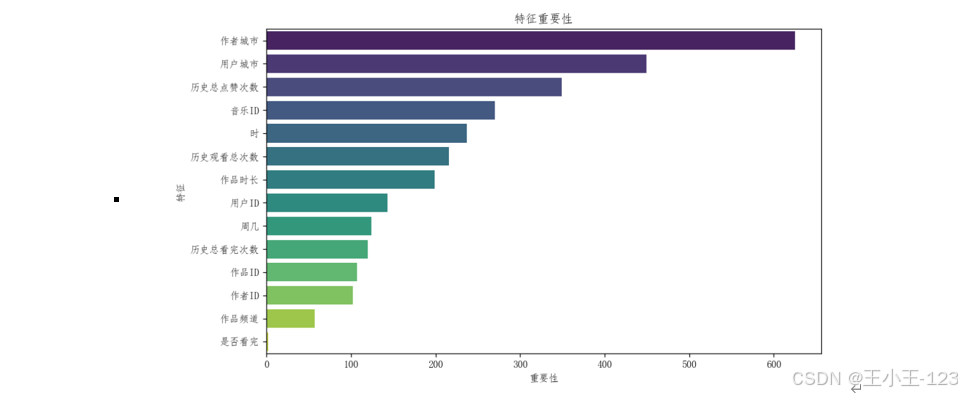
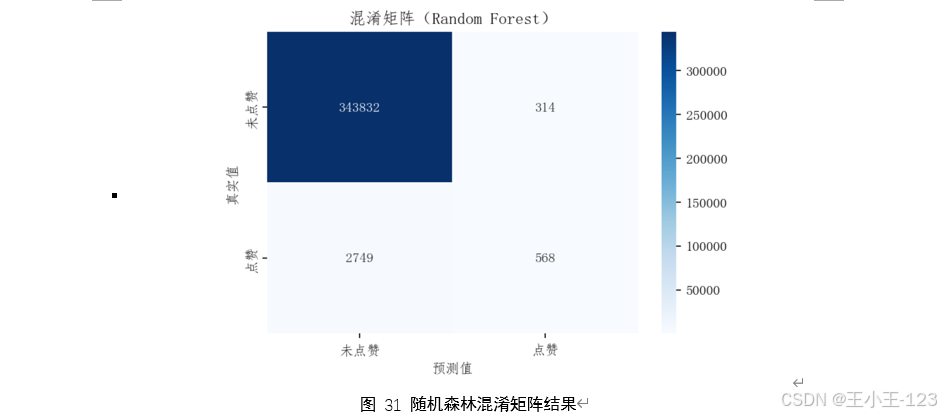
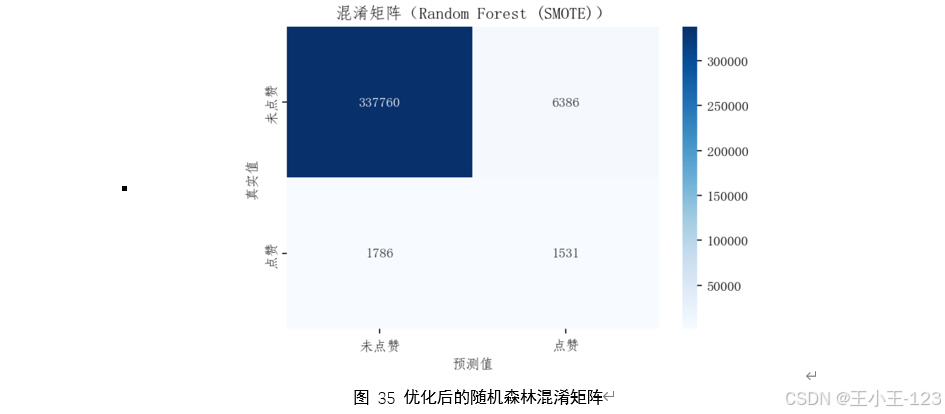
在建模部分,基于用戶是否點贊這一標簽,結合前述多維特征,構建了多種二分類預測模型。采用的機器學習算法包括 LightGBM、XGBoost 與隨機森林,并針對樣本不平衡問題引入 SMOTE 過采樣技術進行處理。模型訓練過程中,通過網格搜索等方法對參數進行調優。最終,使用準確率、召回率、F1 分數、混淆矩陣等評估指標,對模型效果進行全面評估,并結合特征重要性排序,深入探究影響用戶點贊行為的關鍵驅動因素。
本研究不僅為理解短視頻用戶的點贊行為提供數據支持,也為內容創作者、平臺運營者在優化內容策略、提升用戶互動率等方面提供理論依據與實踐參考。

總結
本研究的創新性主要體現在三個方面:數據選取的廣度與多源融合、特征工程的深度構建與維度創新、以及模型優化策略的針對性與實用性。
在數據采集方面,本研究首次聯合整合來自國內外多個主流數據平臺(如和鯨數據、CSDN、Kaggle等)的短視頻用戶行為數據,構建了一個包含約170萬條記錄的大規模數據集。該數據集不僅覆蓋了用戶的觀看行為、作者屬性與作品特征,還具有廣泛的地域代表性。這種多源融合的數據策略顯著提升了研究數據的廣度與多樣性,更貼近真實的用戶互動行為,為后續分析提供堅實的數據基礎。
在特征構建環節,研究在傳統用戶行為特征(如瀏覽量、點贊數等)基礎上,進一步引入了一系列具有辨識度的新型特征。例如:用戶曾觀看過的作者數量、瀏覽作品所覆蓋的城市數量、作品的完整觀看比例等。這些新增維度能夠更精準地描繪用戶在平臺上的行為軌跡,有助于挖掘點贊行為背后的潛在動機和傾向。同時,針對作者側的分析也引入了如作品發布時間的跨度、配樂使用的數量與頻次等變量,從時間序列和內容豐富度角度量化創作活躍度和穩定性,從而更全面地刻畫創作者畫像。
在模型構建與優化方面,本研究針對點贊行為標簽在數據集中分布極度不平衡的實際問題,引入了SMOTE過采樣算法以增強少數類樣本,提高模型在識別“點贊”行為方面的敏感性和泛化能力。在此基礎上,研究還采用了系統化的參數調優策略,對LightGBM、XGBoost等多種集成學習算法進行了性能對比與優化。最終模型在保持整體準確率的同時,實現了召回率的顯著提升,有效緩解了實際應用場景中“易漏檢、難預測”的問題。
綜上所述,本研究在短視頻用戶行為預測領域的多個關鍵環節均實現了方法創新,不僅提升了模型預測能力,也為短視頻平臺在提升內容分發效率、優化推薦算法及提升用戶體驗等方面提供了理論依據與實踐路徑。
每文一語
如果人可以預知未來,可能這是一件很悲觀的事情














解決ZDT1問題)
--智能體管理)



)