目錄
1.遞歸實現歸并排序的思想及圖解
2.遞歸實現歸并排序的代碼邏輯
2.1嵌套子函數
2.2遞歸過程
2.3遞歸結束條件
2.4歸并及拷貝過程?
3.非遞歸實現歸并排序的思想及圖解
4.非遞歸實現歸并排序的代碼邏輯
4.1邊歸并邊拷貝
4.2某一gap下歸并完成才進行拷貝
5.歸并排序的時間復雜度與空間復雜度
以升序為例
1.遞歸實現歸并排序的思想及圖解
兩兩數組有序,借助一個臨時數組就可將有序兩數組合并成一個新的有序數組,這就叫歸并
對于給定的待排序數組,我們運用遞歸策略,不斷地將其對半拆分,直到被拆分的子數組只有一個元素時(此時認為子數組有序),我們開始進行歸并操作,......最終使數組有序
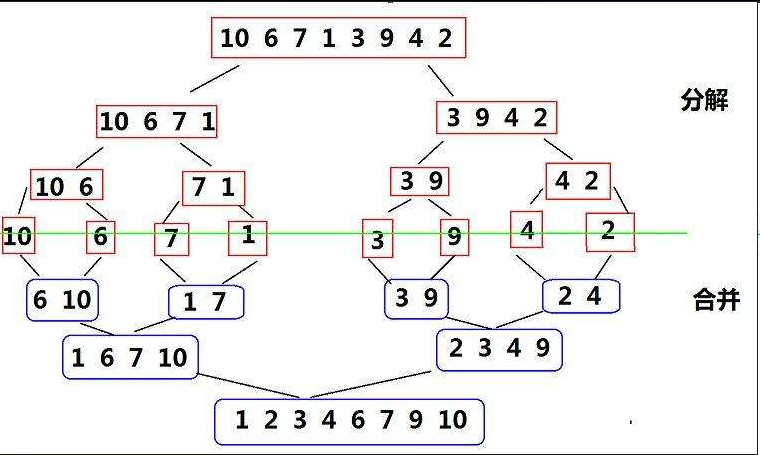
2.遞歸實現歸并排序的代碼邏輯
2.1嵌套子函數
為了避免遞歸頻繁創造臨時數組而造成空間消耗,此時需要嵌套子函數
void _MergeSort(int* a, int left, int right, int* tmp);
void MergeSort(int* a, int n);void MergeSort(int* a, int n){int* tmp = (int*)malloc(sizeof(int) * n);if (!tmp){perror("malloc fail");return;}//對[0, n - 1]這段區間進行排序_MergeSort(a, 0, n - 1, tmp);free(tmp);tmp = NULL;
}歸并排序的遞歸操作類似于二叉樹的后序遍歷(左子樹、右子樹、根)
因為只有當原數組的兩部分數組都有序后,才能通過歸并使整個數組有序
void _MergeSort(int* a, int left, int right, int* tmp)
{//結束條件//遞歸過程//歸并區間//歸并到臨時數組的對應位置//拷貝}2.2遞歸過程
遞歸過程類似于后序遍歷
int midi = left + (right - left) / 2;
//[left, midi][midi + 1, right]
_MergeSort(a, left, midi, tmp);
_MergeSort(a, midi + 1, right, tmp);
//開始歸并此時中間值midi的取法是向下取整,且具有防溢出的特性,使得 left <= midi < right
所以,終止條件 left >= right 合乎情理
標準的左右區間的劃分[left, midi][midi + 1, right]
使子區間不重疊,遞歸范圍嚴格縮小,合并時覆蓋了整個區間
當數組只有兩個數,下標從0到1并進行遞歸劃分時,midi = 0,
此時左區間[left, midi]?遞歸可以停止,右區間同理
int mid = left + (right - left + 1) / 2; // 向上取整
//[left, midi - 1][midi, right]mergeSort(arr, left, mid - 1); // 左子區間mergeSort(arr, mid, right); // 右子區間
//開始歸并向上取整有風險
此時區間需要做調整
當數組只有兩個數,下標從0到1并進行遞歸劃分時,midi = 1,
此時左區間如果是[left, midi]?將造成無限遞歸,所以更改為[left, midi - 1][midi, right]
2.3遞歸結束條件
根據思想,我們可以知道區間長度等于1時就停止遞歸,那么
//結束條件 if (left >= right)return;且向下取整得到 midi 的做法使得 left 不會大于 right
2.4歸并及拷貝過程?
以升序為例
遞歸返回后區間所對應的數組就有序了,此時就可以進行歸并操作
1.先確定兩有序數組的邊界? ?begin.? end.是對應數組的首元素下標、尾元素下標
2.從前往后順次比較兩有序數組,數組元素小的先放到臨時數組中,一個數組結束后,再歸并另一數組
3.圖解
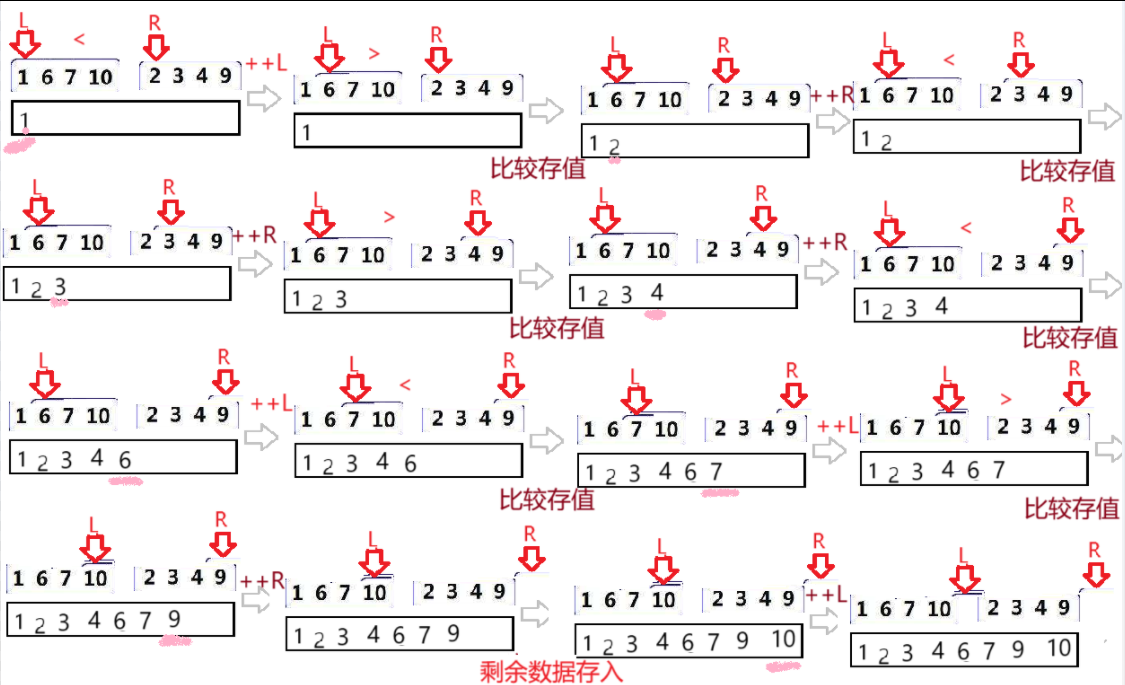
//開始歸并
int begin1 = left, end1 = midi;
int begin2 = midi + 1, end2 = right;
//歸并到臨時數組的對應位置
int i = left;
while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2])tmp[i++] = a[begin1++];else tmp[i++] = a[begin2++];
}while (begin1 <= end1)tmp[i++] = a[begin1++];while (begin2 <= end2)tmp[i++] = a[begin2++];//拷貝
memcpy(a + left, tmp + left, sizeof(int) * (right - left + 1));歸并區間不一定從0開始,而是從 left 開始的
兩個begin下標都未到尾才繼續比較存值,否則就跳出循環
此時常規思路就是是由if else語句判斷到底哪一個begin下標未到尾然后再存值,
但上述做法直接利用while循環進行判斷,這種做法更簡潔
最后再將臨時數組的歸并內容拷貝會原數組,原數組對應位置就有序啦
通過遞歸使得數組最終都有序了
3.非遞歸實現歸并排序的思想及圖解
遞歸實現歸并排序總是先遞歸到小規模數組,再從底層向上開始歸并,即先是一個元素與一個元素進行歸并,再是兩個元素與兩個元素進行歸并.....這顯然也可以是一種雙重循環
外層循環是每組元素的個數,內存循環就是數組歸并的過程

4.非遞歸實現歸并排序的代碼邏輯
4.1邊歸并邊拷貝
(1)歸并顯然要借助臨時數組
void MergeSortNonR1(int* a, int n)
{//臨時數組int* tmp = (int*)malloc(sizeof(int) * n);if (!tmp){perror("malloc fail");return;}//歸并過程free(tmp);tmp = NULL;
}(2)特定gap(確定的每組個數)下的歸并過程
int gap;
for (int i = 0; i < n; i += 2 * gap){//表示區間int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2*gap - 1;//修正邊界//開始歸并int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2])tmp[j++] = a[begin1++];else tmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];//邊歸并邊拷貝memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}(3) 區間表示
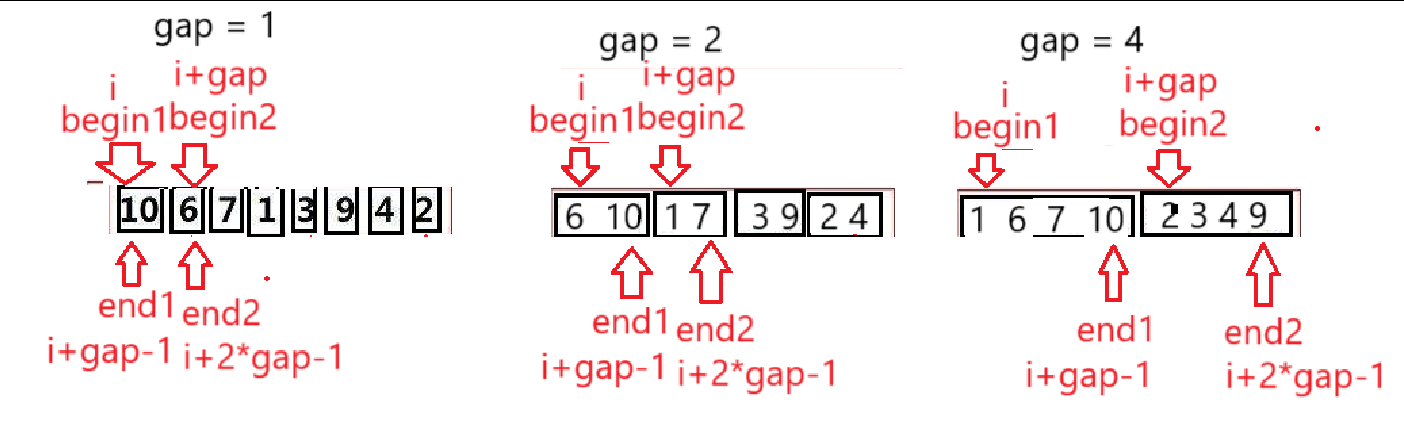
上述圖解的gap與數組個數成倍數關系,萬一有奇數個元素,是否會越界呢?
(4)修正邊界
printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);打印確定gap下的區間幫助我們觀察越界情況
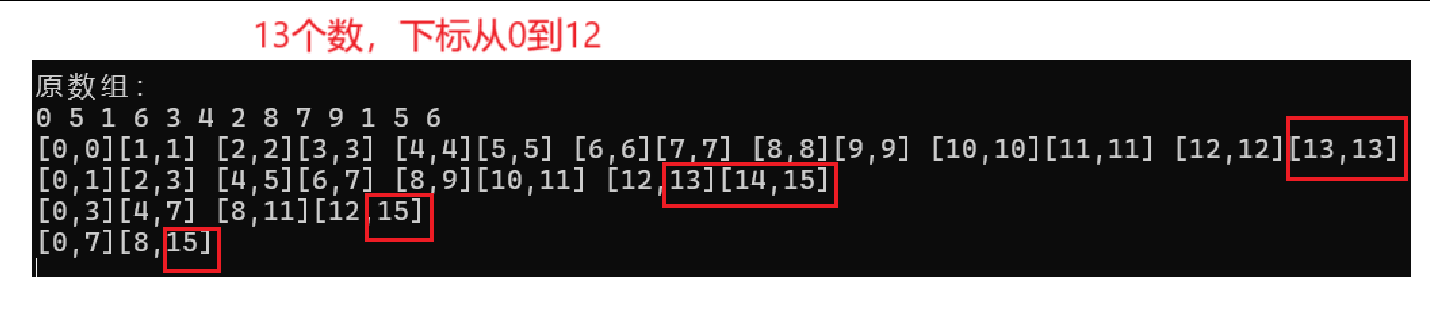
從打印結果來看,end1、begin2、end2都存在越界的可能
而for循環中的i控制了小于n的情況,所以begin1不存在越界訪問的說法
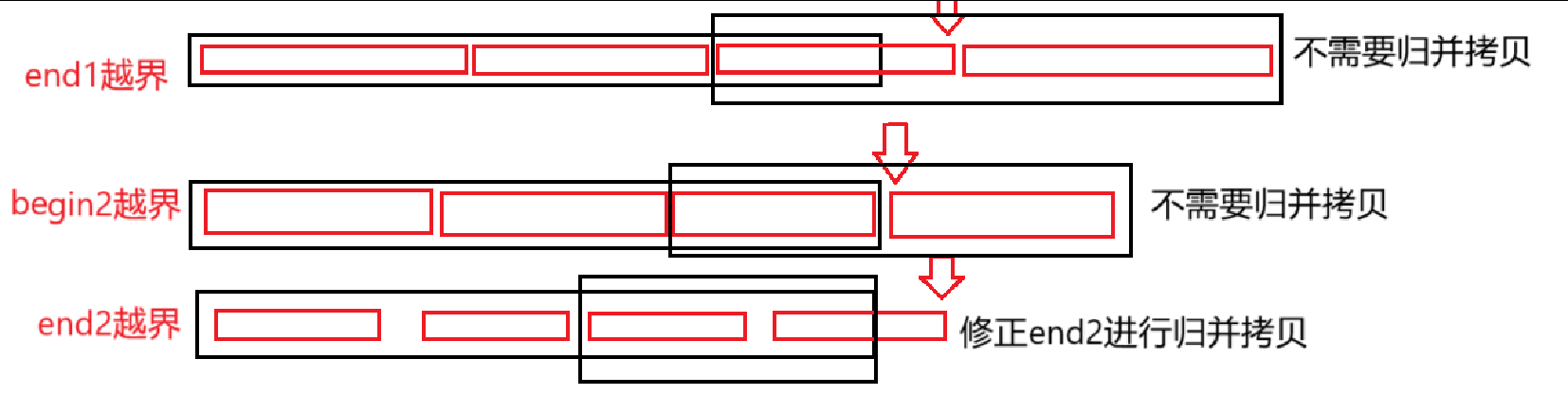
邊歸并邊拷貝過程中,當end1越界之后,begin2、end2肯定也越界了,此時第一部分沒有存入臨時數組再拷貝回原數組的必要,而當begin2越界而end1沒越界時,第一部分也不需要歸并拷貝
//修正邊界if (end1 >= n || begin2 >= n)break;else if (end2 >= n)end2 = n - 1;只有end2越界時,第二部分的部分需要與第一部分進行歸并拷貝,此時將end2修正為 n - 1
再次打印邊界,對比發現不合理的區間都已跳過
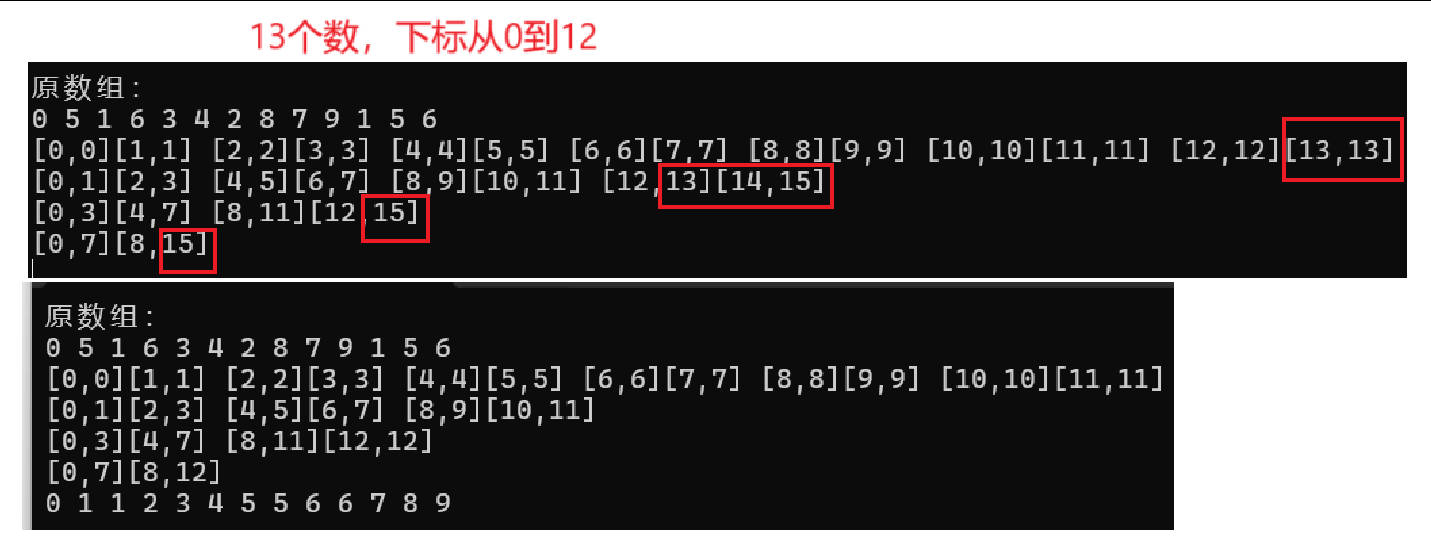
最后控制gap逐漸增大即可
void MergeSortNonR1(int* a, int n){int* tmp = (int*)malloc(sizeof(int) * n);if (!tmp){perror("malloc fail");return;}//每組中的個數int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){//表示區間int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2*gap - 1;//修正邊界if (end1 >= n || begin2 >= n)break;else if (end2 >= n)end2 = n - 1;//查看邊界越界情況需要//printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);//開始歸并int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2])tmp[j++] = a[begin1++];else tmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];//邊歸并邊拷貝memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}//printf("\n");//查看邊界越界情況需要gap *= 2;}free(tmp);tmp = NULL;
}
4.2某一gap下歸并完成才進行拷貝
void MergeSortNonR2(int* a, int n){int* tmp = (int*)malloc(sizeof(int) * n);if (!tmp){perror("malloc fail");return;}//每組中的個數int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){//表示區間int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//修正邊界//查看越界情況才需要printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);//開始歸并int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2])tmp[j++] = a[begin1++];else tmp[j++] = a[begin2++];while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];}//查看越界情況才需要printf("\n");//全部歸并完成后一次性拷貝memcpy(a, tmp, sizeof(int) * n);gap *= 2;}free(tmp);tmp = NULL;
}打印邊界

同樣只有begin1不會越界,但是因為我們最終是將臨時數組全部拷貝到原數組中去,所以
我們要確保不進行歸并的部分也存入了臨時數組,防止臨時數組全部拷貝到原數組中去的過程中對原數據造成覆蓋
if (end1 >= n)
{end1 = n - 1;begin2 = n;end2 = n - 1;
}
else if (begin2 >= n)
{begin2 = n;end2 = n - 1;
}
else if (end2 >= n)end2 = n - 1;end1越界要將end1修改為 n - 1,使得第一部分能夠存入臨時數組,并且將第二部分的區間改為不存在,即 begin2 > end2 ,這樣才能避免第二部分的越界存值
end1未越界,begin2越界,此時將第二部分的區間改為不存在,即 begin2 > end2 ,避免第二部分的越界存值即可
只有end2越界,此時將其修改為 n - 1 即可,這樣可以保證一二部分進行歸并存值操作
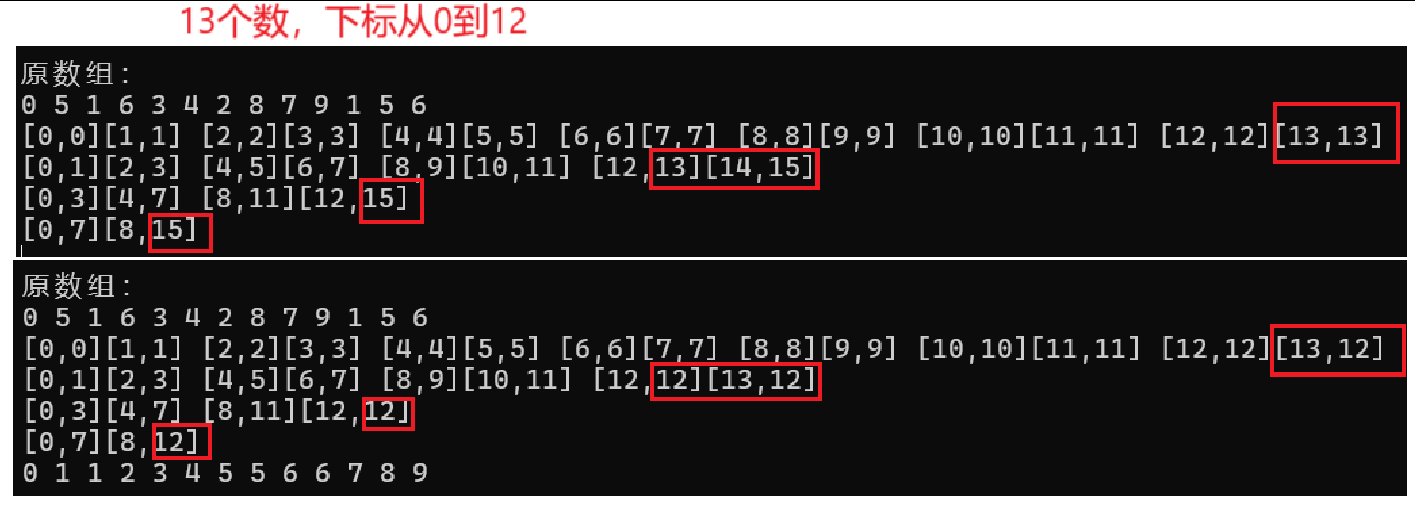
最終區間合理
5.歸并排序的時間復雜度與空間復雜度
遞歸實現歸并排序需要遞歸 logN 層,每層進行遍歷歸并,即每一層遍歷N次
所以時間復雜度為O(N*logN)
int gap = 1; while (gap < n){for (int i = 0; i < n; i += 2 * gap){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//........}gap *= 2; }非遞歸實現歸并排序時,外層while循環要循環 logN 次,內層for循環中需要遍歷數組中的每個元素,所以時間復雜度為O(N*logN)
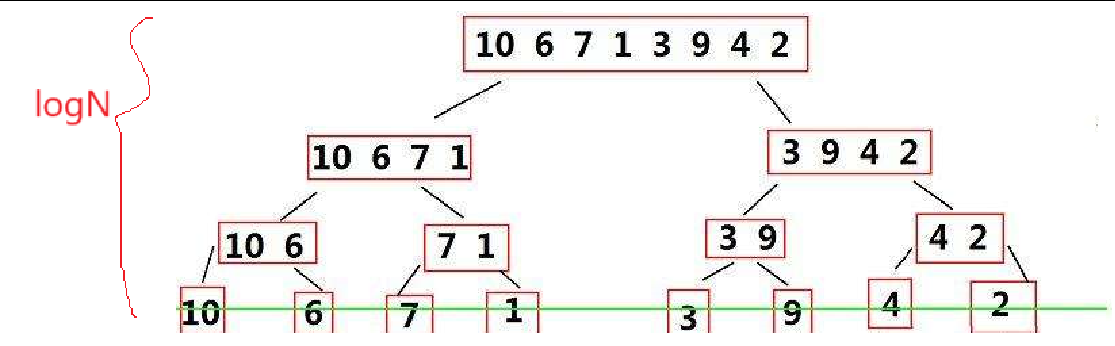
遞歸實現歸并排序需要遞歸 logN 層,所以遞歸棧的空間復雜度為?O(logN)
又預先在最外層創建了臨時數組tmp,臨時數組的空間復雜度為?O(N)
由于?O(N)?的增長速度遠快于?O(logN),因此?O(N)?是主導項
所以? ?空間復雜度為 O(logN) + O(N) 約等于 O(N)??
非遞歸實現歸并排序創建了一個臨時數組tmp,空間復雜度為O(N)








常用類)




主頻和時鐘配置實驗(1))
創建型:生成器模式詳解)




