點擊藍字

關注我們
AI TIME歡迎每一位AI愛好者的加入!
01
Compress Any Segment Anything Model (SAM)
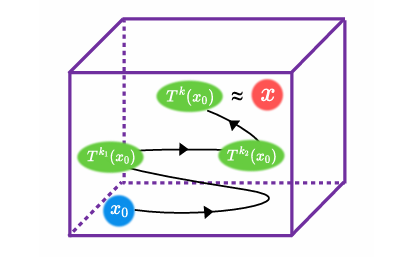
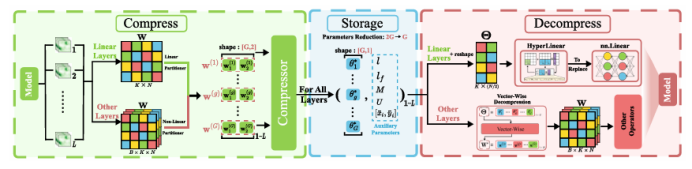
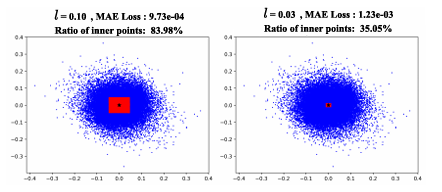
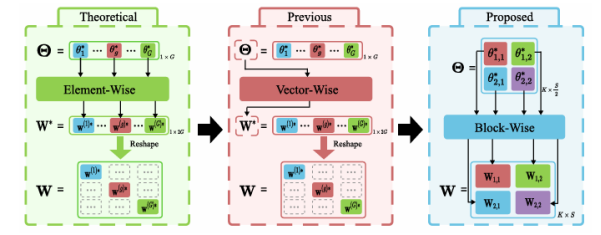
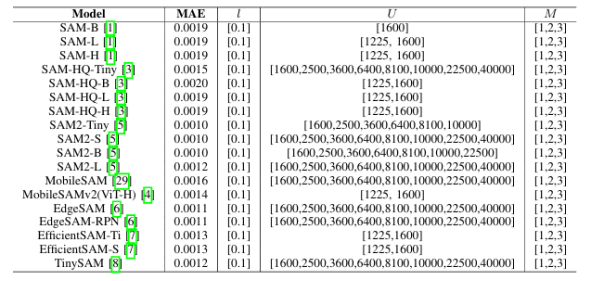
受SAM在零樣本分割任務上卓越表現的驅動,其各類變體已被廣泛應用于醫療、智能制造等場景。然而,SAM系列模型體量巨大,嚴重限制了在資源受限環境中的部署效率。本文提出了一種名為Birkhoff的新型無數據壓縮算法,旨在對SAM及其變體進行高效壓縮。與傳統剪枝、量化、蒸餾等方法不同,Birkhoff具備跨模型通用、部署迅捷、忠實原模型、體積緊湊四大優勢。其核心創新是引入“超壓縮”機制:通過尋找稠密軌跡,將高維參數向量映射為低維標量。此外,本文設計了專用線性算子HyperLinear,將解壓縮與矩陣乘法融合,顯著提升壓縮模型的推理速度。在COCO、LVIS、SA-1B三大數據集上對18個SAM變體的實驗表明,Birkhoff在壓縮時間、壓縮率、壓縮后性能及推理速度上均表現優異。例如,在SAM2-B上實現5.17倍壓縮率,性能下降不足1%,且無需任何微調數據,壓縮全程在60秒內完成。
文章鏈接:
https://arxiv.org/pdf/2507.08765
02
Compactor: Calibrated Query-Agnostic KV Cache Compression with Approximate Leverage Scores
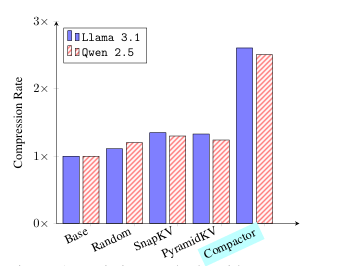
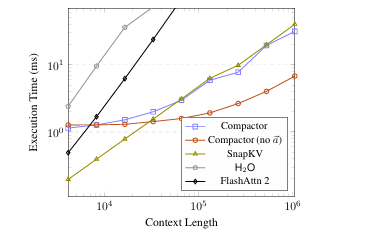
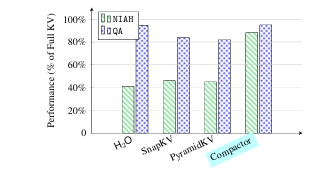
現代大語言模型(LLM)已能支持極長上下文,但在實際部署中,KV 緩存隨序列長度線性增長的內存開銷成為主要瓶頸。本文提出 Compactor——一種無需查詢信息、完全無參數的 KV 緩存壓縮策略。該方法利用近似統計杠桿分數衡量 token 重要性,并結合非因果注意力分數,共同決定保留哪些 token。實驗表明,Compactor 在 27 項合成與真實長文本任務(RULER、Longbench)上,僅用 50% 的 KV 緩存即可達到與完整緩存相當的性能,且計算開銷極低。此外,本研究引入“上下文校準壓縮”機制,可在推理階段為任意文本動態估計最大可壓縮比例,在 Longbench 上平均減少 63% 的 KV 內存,同時保持與全緩存一致的性能。作者在 Qwen2.5 與 Llama3.1 系列模型上驗證了方法的通用性與有效性。
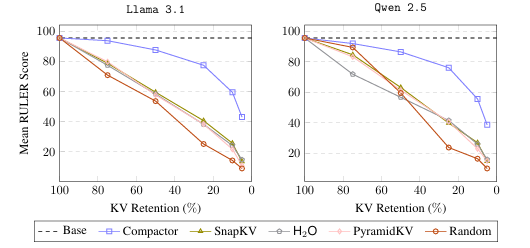
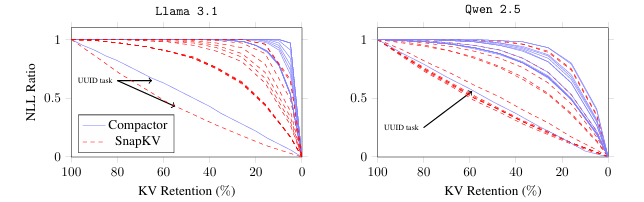
文章鏈接:
https://arxiv.org/pdf/2507.08143
03
Integrating External Tools with Large Language Models (LLM) to Improve Accuracy
大語言模型(LLM)在缺乏相關上下文時容易產生幻覺或給出低質量回答。為緩解這一問題,本文提出Athena框架,通過調用外部API及計算工具(如計算器、日歷、Wolfram Alpha、ArXiv、搜索引擎等)為模型提供實時、精確的信息與計算能力。Athena采用Schema化工具注冊機制,使模型可自動識別何時調用何種工具,并解析參數、整合結果。在MMLU數學與科學推理數據集上的評估顯示,Athena在數學任務上達到83%準確率,在科學任務上達到88%,顯著優于GPT-4o、LLaMA-Large、Mistral-Large、Phi-Large及GPT-3.5等基線(最佳基線分別為67%與79%)。實驗表明,工具整合帶來的增益可彌補模型規模擴張的不足,為構建圍繞LLM的復雜計算生態系統提供了可行路徑。
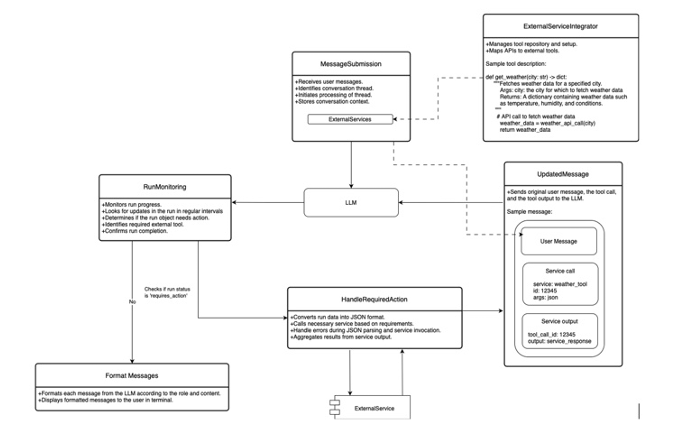

文章鏈接:
https://arxiv.org/pdf/2507.08034
04
Unveiling Effective In-Context Configurations for Image Captioning: An External & Internal Analysis
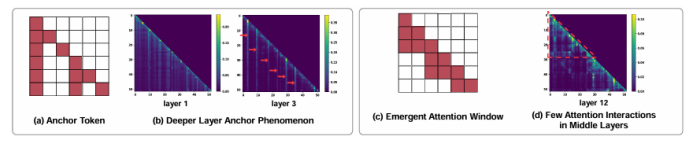
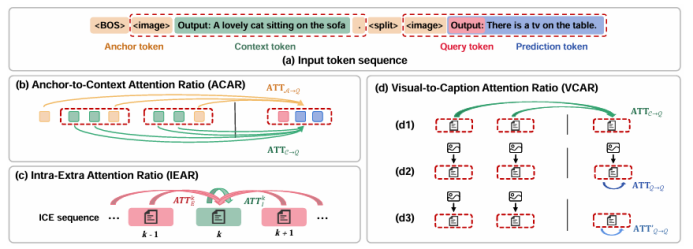
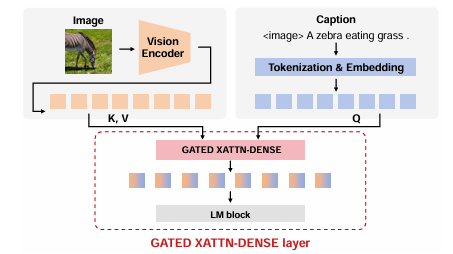
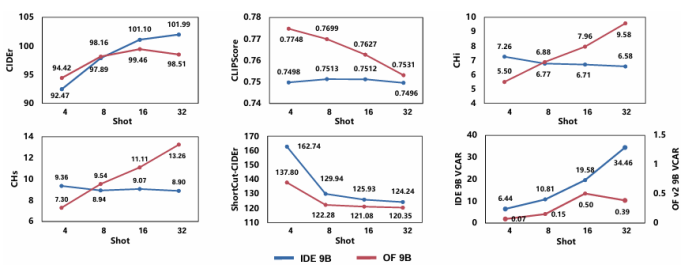
隨著大模型的發展,上下文學習(ICL)已被成功從自然語言處理推廣到視覺-語言多模態任務。然而,如何為多模態ICL設計合適的示例配置仍缺乏系統研究,且模型內部機制亦未得到充分解釋。本文以圖像描述任務為切入點,從“外部配置”與“內部機理”兩個維度開展全面探究。外部方面,作者系統探索了示例數量、圖像檢索策略及文本描述質量三個因素,利用多種評價指標總結其影響規律;內部方面,作者深入分析大視覺-語言模型的注意力分布,提出錨定標記、涌現注意力窗口和描述捷徑三種典型模式,并設計對應注意力指標進行量化。實驗表明,隨著示例數量增加,語言連貫性提高,但視覺-文本對齊可能下降;低質量描述會在多示例場景下放大噪聲,而相似圖像檢索易誘發“描述抄襲”捷徑行為。此外,作者發現即使架構相同,預訓練數據差異也會導致模型行為顯著不同,并據此提出基于錨定標記的輕量化推理加速方法,可在幾乎不損失性能的前提下降低50% KV緩存。
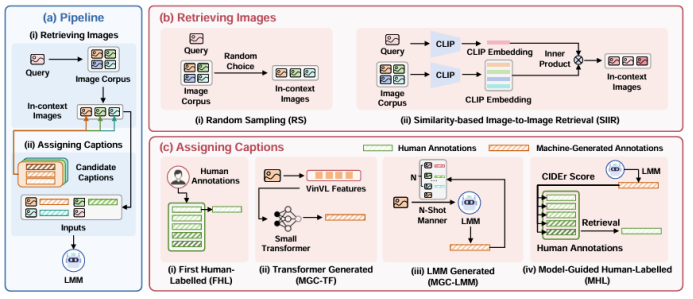
文章鏈接:
https://arxiv.org/pdf/2507.08021
05
Introspection of Thought Helps AI Agents
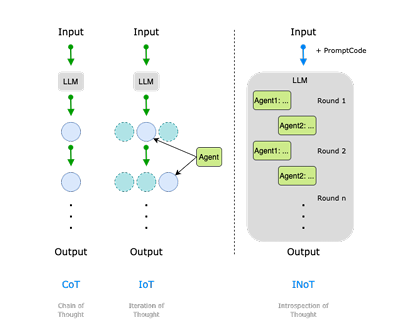
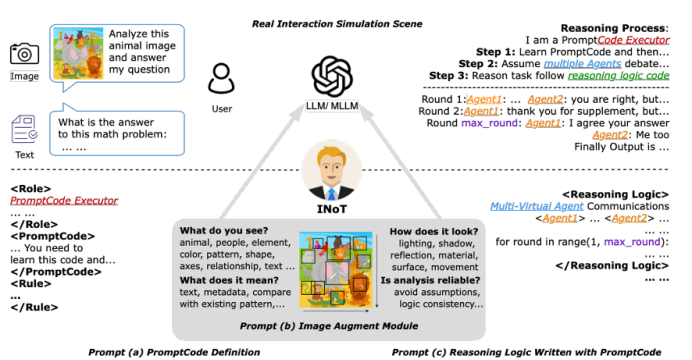
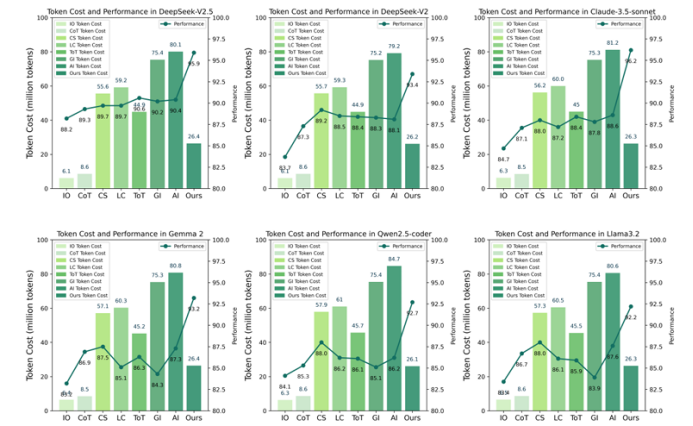
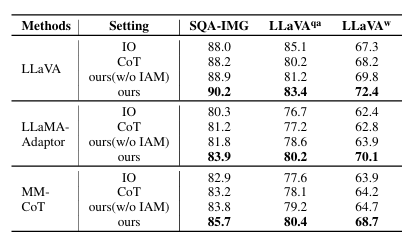
大語言模型(LLM)與多模態大模型(MLLM)已成為 AI Agent 的核心推理引擎,但僅依靠提示工程或外部迭代框架仍受限于模型自身的語言理解局限,且多輪交互帶來高昂 token 成本。為此,本文提出 Introspection of Thought(INoT)框架,通過在提示中嵌入“PromptCode”——一種融合 Python 與自然語言的可讀代碼,使模型在單次調用內部即可完成多輪辯論、自我否定與反思。INoT 將傳統外部多 Agent 的迭代過程壓縮進 LLM 內部,顯著減少 token 開銷。在數學、代碼、問答 6 個基準及 3 個圖像問答數據集上的實驗表明,INoT 平均提升 7.95% 性能,token 成本較最佳基線降低 58.3%,并展現了良好的跨模型通用性與多模態適應性。
文章鏈接:
https://arxiv.org/pdf/2507.08664
06
DatasetAgent: A Novel Multi-Agent System for Auto-Constructing Datasets from Real-World Images
傳統圖像數據集的構建高度依賴人工收集與標注,耗時低效;而純合成數據又難以覆蓋真實世界的多樣性。針對這一矛盾,本文提出 DatasetAgent——一個由四個專業化智能體(需求分析、圖像處理、數據標注、監督協調)協同工作的多模態系統。該系統僅需用戶提供高層需求或現有數據集,即可自動完成圖像檢索、質量優化、清洗與多任務標注(分類、檢測、分割),全程使用真實世界圖像,避免合成數據的缺陷。在擴展 CIFAR-10、STL-10、PASCAL VOC 與 CamVid 以及從零構建新數據集的實驗中,DatasetAgent 輸出的數據集在類別平衡、視覺質量、標注可靠性等六項指標上均達到或超越人工基準,且下游模型在分類、檢測、分割任務上平均準確率提升 0.4–3.9 個百分點。
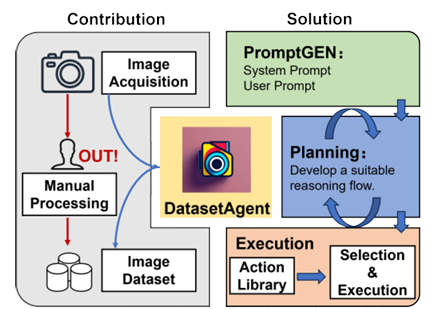
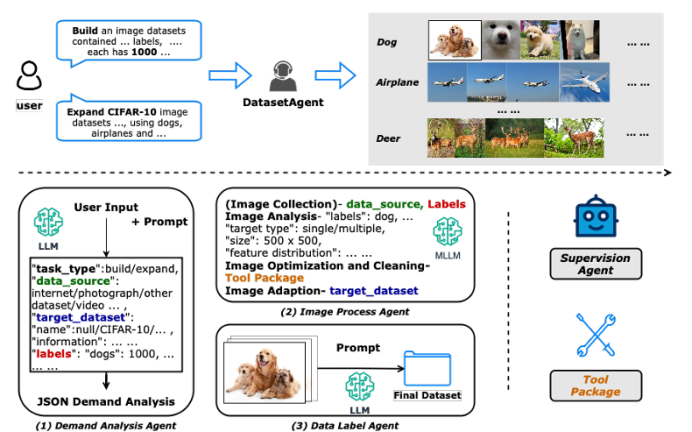
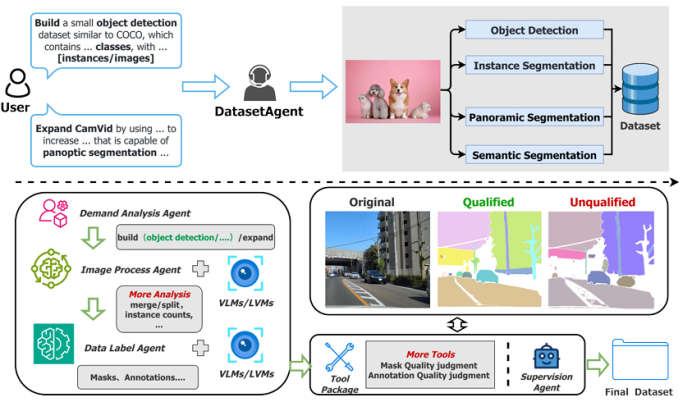
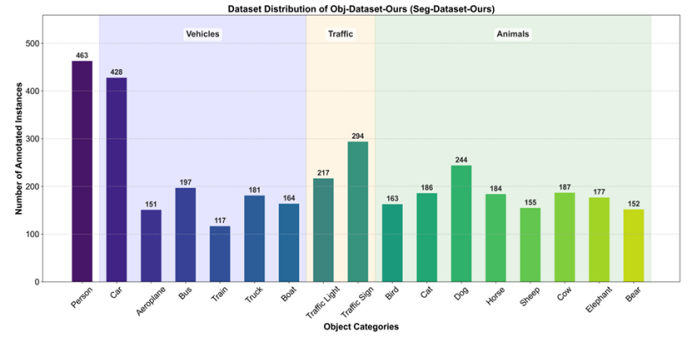
文章鏈接:
https://arxiv.org/pdf/2507.08648 07 From Language to Logic: A Bi-Level Framework for Structured Reasoning 當前大語言模型在結構化推理任務中仍依賴非結構化的鏈式思考,易出現冗長、不可解釋且易錯的問題。本文提出 Lang2Logic——一種雙層推理框架,將自然語言問題先抽象為包含變量、約束與目標的結構化模型,再生成可執行的 Python 邏輯程序并運行以得到最終答案。該框架采用“優化引導形式化”與“邏輯生成”兩級 LLM 協作,并通過雙層強化學習算法聯合優化,實現跨領域(因果、邏輯、數學、時空推理等)的模塊化、可解釋推理。在 9 個挑戰性基準上的實驗表明,Lang2Logic 相比最佳基線平均提升 10% 以上,在復雜任務中最高提升 40%,同時顯著降低推理鏈長度與幻覺風險。

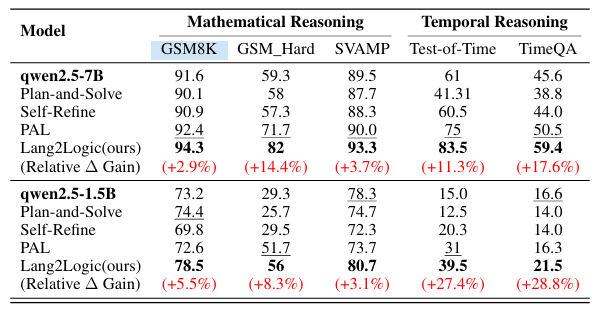
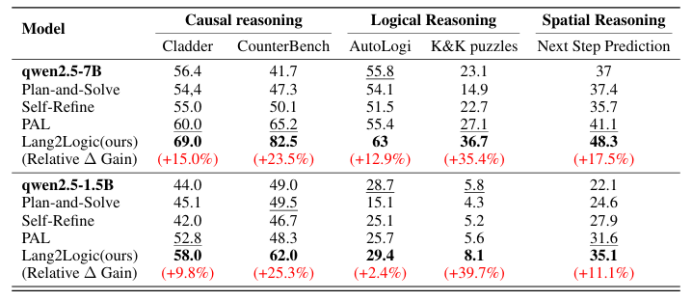
文章鏈接:
https://arxiv.org/pdf/2507.08501
本期文章由陳研整理
近期活動分享
?關于AI TIME?
AI TIME源起于2019年,旨在發揚科學思辨精神,邀請各界人士對人工智能理論、算法和場景應用的本質問題進行探索,加強思想碰撞,鏈接全球AI學者、行業專家和愛好者,希望以辯論的形式,探討人工智能和人類未來之間的矛盾,探索人工智能領域的未來。
迄今為止,AI TIME已經邀請了2000多位海內外講者,舉辦了逾800場活動,超1000萬人次觀看。

我知道你?
在看
提出觀點,表達想法,歡迎?
留言

點擊?閱讀原文?查看更多!
Linux、(內網)Windows)



)
)








)




