本教程僅用于技術研究,請確保遵守目標網站的服務條款。實際使用前應獲得官方授權,避免高頻請求影響服務器,否則可能承擔法律責任。
此腳本僅攔截公開評論接口,不涉及用戶私密數據。請勿修改代碼監聽其他請求。
分享一下爬某抖評論的爬蟲學習,有一定的風險(代理部署導致瀏覽器連接斷開,但有解決方案,需要認真學習)
首先,需要的軟件:nodejs與mitmproxy可以先下載,避免后面斷檔了(問deepseek),最好下載個vscode(編輯代碼和終端都有,參考deepseek,給他這些代碼讓他去教你把文件放到同一個文件夾里面)
然后直接發腳本代碼:
文件名(不能修改):server.js,如下:
const http = require('http');
const fs = require('fs');
const path = require('path');
const PORT = 3000;// 存儲所有視頻評論數據
const allVideoComments = {};// 啟動服務器
const server = http.createServer((req, res) => {if (req.method === 'POST') {let body = '';req.on('data', chunk => body += chunk);req.on('end', () => {try {const params = new URLSearchParams(body);const fullUrl = params.get('url');const responseRaw = params.get('response');console.log('📥 收到評論請求副本 URL:', fullUrl);console.log(params,'params')if (!responseRaw || responseRaw.trim().length === 0) {console.warn('?? 副本中沒有包含評論響應內容');res.writeHead(200);return res.end('空響應');}// 打印部分原始內容console.log('📦 原始評論內容預覽:');console.log(responseRaw.slice(0, 300));const response = JSON.parse(responseRaw);const awemeId = new URL(fullUrl).searchParams.get('aweme_id');const videoUrl = `https://www.douyin.com/video/${awemeId}`;if (!response.comments) {console.warn('?? 評論數據中無 comments 字段');res.writeHead(200);return res.end('無評論字段');}// 初始化數據結構if (!allVideoComments[videoUrl]) {allVideoComments[videoUrl] = {video_id: awemeId,comments: []};}// 格式化評論const formattedComments = response.comments.map(comment => ({user_id: comment.user?.uid || '未知用戶',user_nickname: comment.user?.nickname || '匿名用戶',comment_content: comment.text,comment_date: new Date(comment.create_time * 1000).toISOString(),like_count: comment.digg_count,ip_region: comment.ip_label,is_hot: comment.is_hot,reply_count: comment.reply_comment_total}));allVideoComments[videoUrl].comments.push(...formattedComments);saveToFile(allVideoComments);res.writeHead(200, { 'Content-Type': 'application/json' });res.end(JSON.stringify({video_url: videoUrl,comment_count: formattedComments.length,comments: formattedComments}, null, 2));console.log(`? 已保存 ${formattedComments.length} 條評論(${videoUrl})`);} catch (err) {console.error('? 錯誤:', err);res.writeHead(500);res.end('解析失敗');}});} else {res.writeHead(200);res.end('請通過 POST 發送副本數據');}
});// 寫入 JSON 文件
function saveToFile(data) {const filePath = path.join(__dirname, 'douyin_comments.json');fs.writeFileSync(filePath, JSON.stringify(data, null, 2), 'utf8');console.log(`💾 已保存評論數據到:${filePath}`);
}// 啟動監聽
server.listen(PORT, () => {console.log(`🚀 本地服務已啟動:http://localhost:${PORT}`);console.log('📡 等待mitmproxy發送副本...');
});
文件名(不能修改):dup_forward.py,如下:
from mitmproxy import http
import requestsdef response(flow: http.HTTPFlow):if "/aweme/v1/web/comment/list/" in flow.request.pretty_url:try:requests.post("http://127.0.0.1:3000", # 發送給本地 Node.jsdata={"url": flow.request.pretty_url,"response": flow.response.get_text()},timeout=3)print("? 已轉發副本:", flow.request.pretty_url)except Exception as e:print("? 副本發送失敗:", e)
文件名(不能修改):comment.js
const XLSX = require('xlsx');
const fs = require('fs');// 1. 讀取 JSON 文件
const jsonData = JSON.parse(fs.readFileSync('douyin_comments.json', 'utf8'));// 2. 準備所有評論數據(帶視頻鏈接)
const allComments = [];// 遍歷每個視頻
Object.keys(jsonData).forEach(videoUrl => {const videoData = jsonData[videoUrl];const videoId = videoData.video_id;// 遍歷當前視頻的評論videoData.comments.forEach(comment => {allComments.push({"視頻鏈接": videoUrl, // 新增:標記評論所屬視頻"視頻ID": videoId, // 可選:方便篩選"用戶ID": comment.user_id,"用戶昵稱": comment.user_nickname,"評論內容": comment.comment_content,"評論日期": comment.comment_date,"點贊數": comment.like_count,"IP屬地": comment.ip_region,"是否熱門": comment.is_hot ? "是" : "否","回復數": comment.reply_count});});
});// 3. 創建 Excel 工作簿
const workbook = XLSX.utils.book_new();
const worksheet = XLSX.utils.json_to_sheet(allComments);// 4. 導出文件
XLSX.utils.book_append_sheet(workbook, worksheet, "某抖評論數據");
XLSX.writeFile(workbook, 'douyin_comments.xlsx');console.log('? 數據已導出至 douyin_comments.xlsx');文件名(不能修改):comment50.js
const XLSX = require('xlsx');
const fs = require('fs');// 1. 讀取 JSON 文件
const jsonData = JSON.parse(fs.readFileSync('douyin_comments.json', 'utf8'));// 2. 準備所有評論數據(帶視頻鏈接)
const allComments = [];// 每個視頻只保留前 50 條評論
const MAX_COMMENTS_PER_VIDEO = 50;Object.keys(jsonData).forEach(videoUrl => {const videoData = jsonData[videoUrl];const videoId = videoData.video_id;// 取前 50 條評論(如果不足 50 條則取全部)const topComments = videoData.comments.slice(0, MAX_COMMENTS_PER_VIDEO);topComments.forEach(comment => {allComments.push({"視頻鏈接": videoUrl,"視頻ID": videoId,"用戶ID": comment.user_id,"用戶昵稱": comment.user_nickname,"評論內容": comment.comment_content,"評論日期": comment.comment_date,"點贊數": comment.like_count,"IP屬地": comment.ip_region,"是否熱門": comment.is_hot ? "是" : "否","回復數": comment.reply_count});});
});// 3. 創建 Excel 工作簿
const workbook = XLSX.utils.book_new();
const worksheet = XLSX.utils.json_to_sheet(allComments);// 4. 導出文件
XLSX.utils.book_append_sheet(workbook, worksheet, "某抖評論數據");
XLSX.writeFile(workbook, 'douyin_comments.xlsx');console.log('? 每個視頻最多導出 50 條評論,已寫入 douyin_comments.xlsx');
package.json
{"dependencies": {"@alicloud/pop-core": "^1.8.0","@google/genai": "^1.9.0","@google/generative-ai": "^0.24.1","axios": "^1.10.0","dotenv": "^17.2.0","http-proxy": "^1.18.1","https-proxy-agent": "^7.0.6","xlsx": "^0.18.5"}
}
用隨便編輯器把他們幾個文件放在同一個目錄之下
類似這樣(我這里有點亂):
然后你們需要在vscode里面打開終端:
 重復上述操作,因為要開兩個終端,還是這個操作
重復上述操作,因為要開兩個終端,還是這個操作
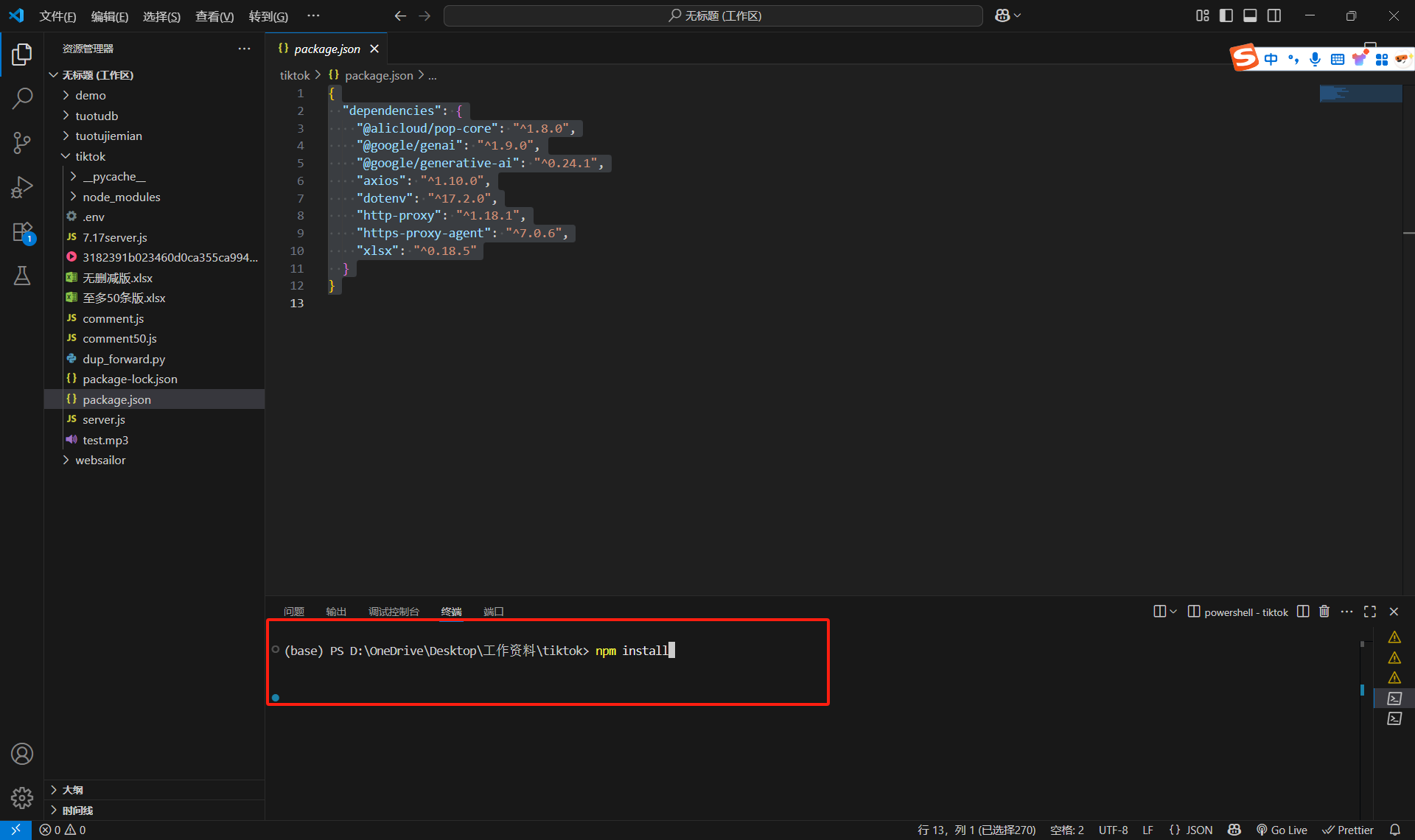
然后結果如下:你們會發現下面有一個欄,然后這個欄的右邊是兩個終端的按鈕(一會需要切換) 然后先在終端執行代碼,npm install,按一下空格。就會自動安裝包依賴了(前提是你們前面已經下載了nodejs)
然后先在終端執行代碼,npm install,按一下空格。就會自動安裝包依賴了(前提是你們前面已經下載了nodejs)
 然后你們就會多一個node_modules這個東西,說明已經下載成功了。
然后你們就會多一個node_modules這個東西,說明已經下載成功了。
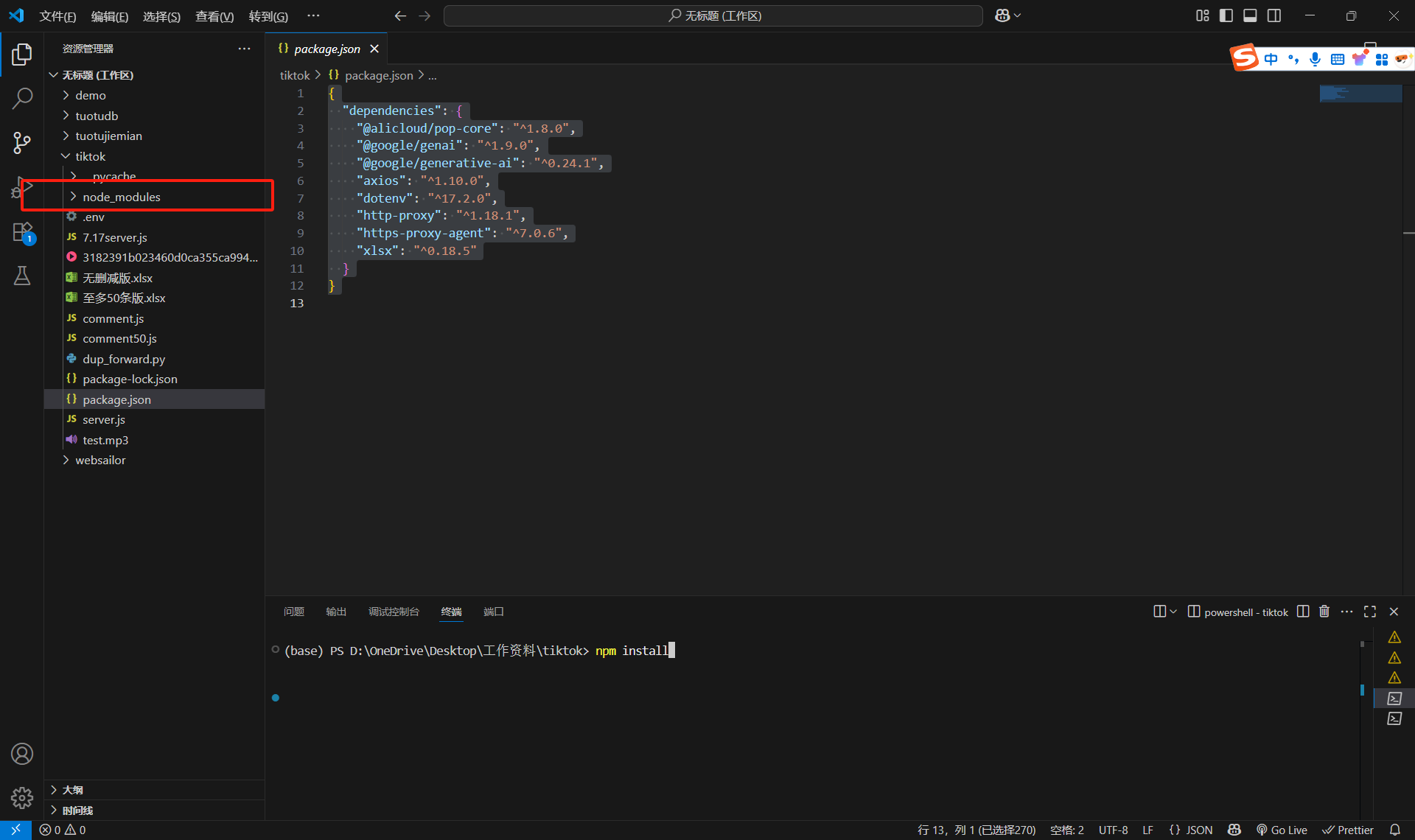 然后就是開始部署代碼了:
然后就是開始部署代碼了:
終端輸入node server.js,然后按空格,就會彈出本地服務已啟動。
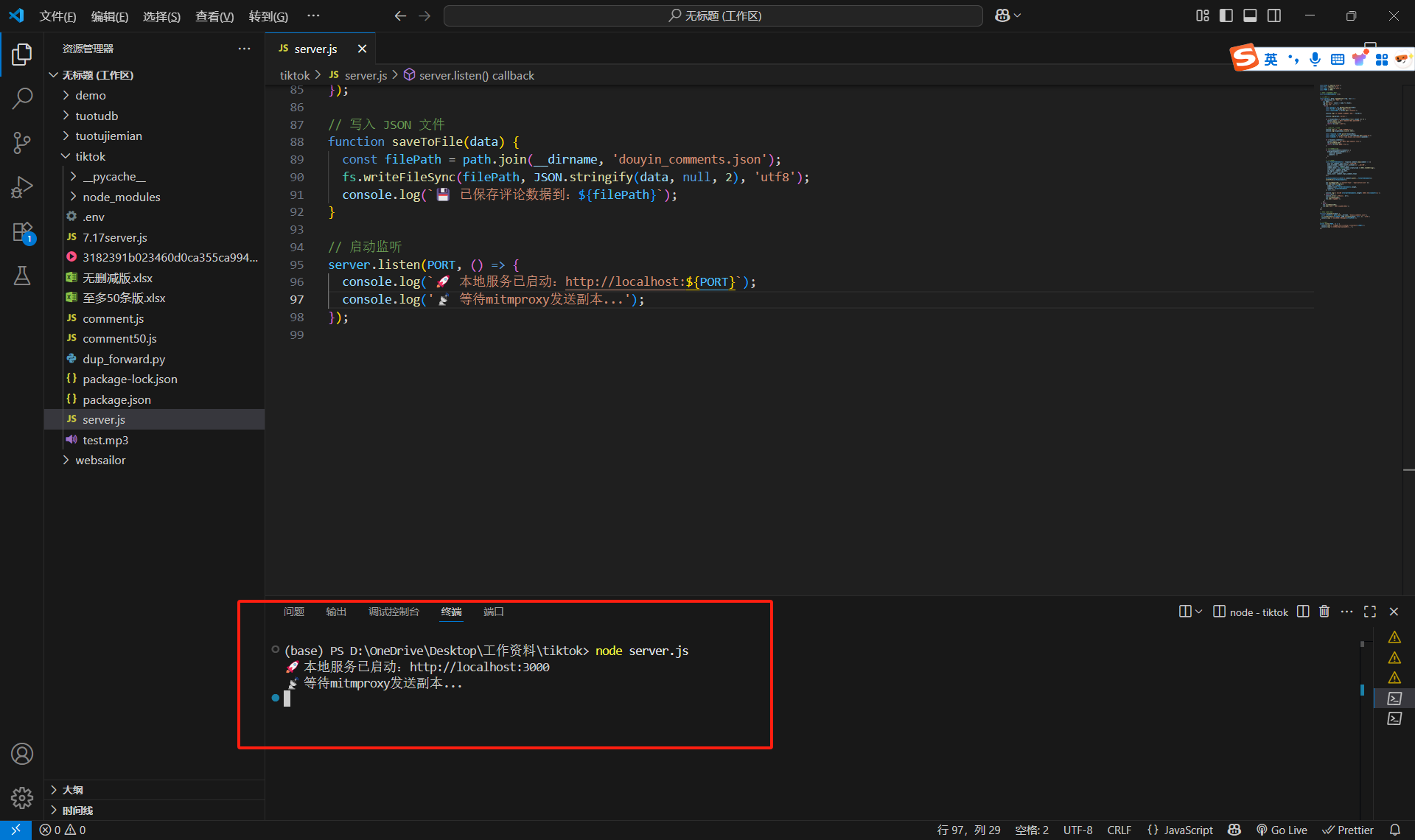
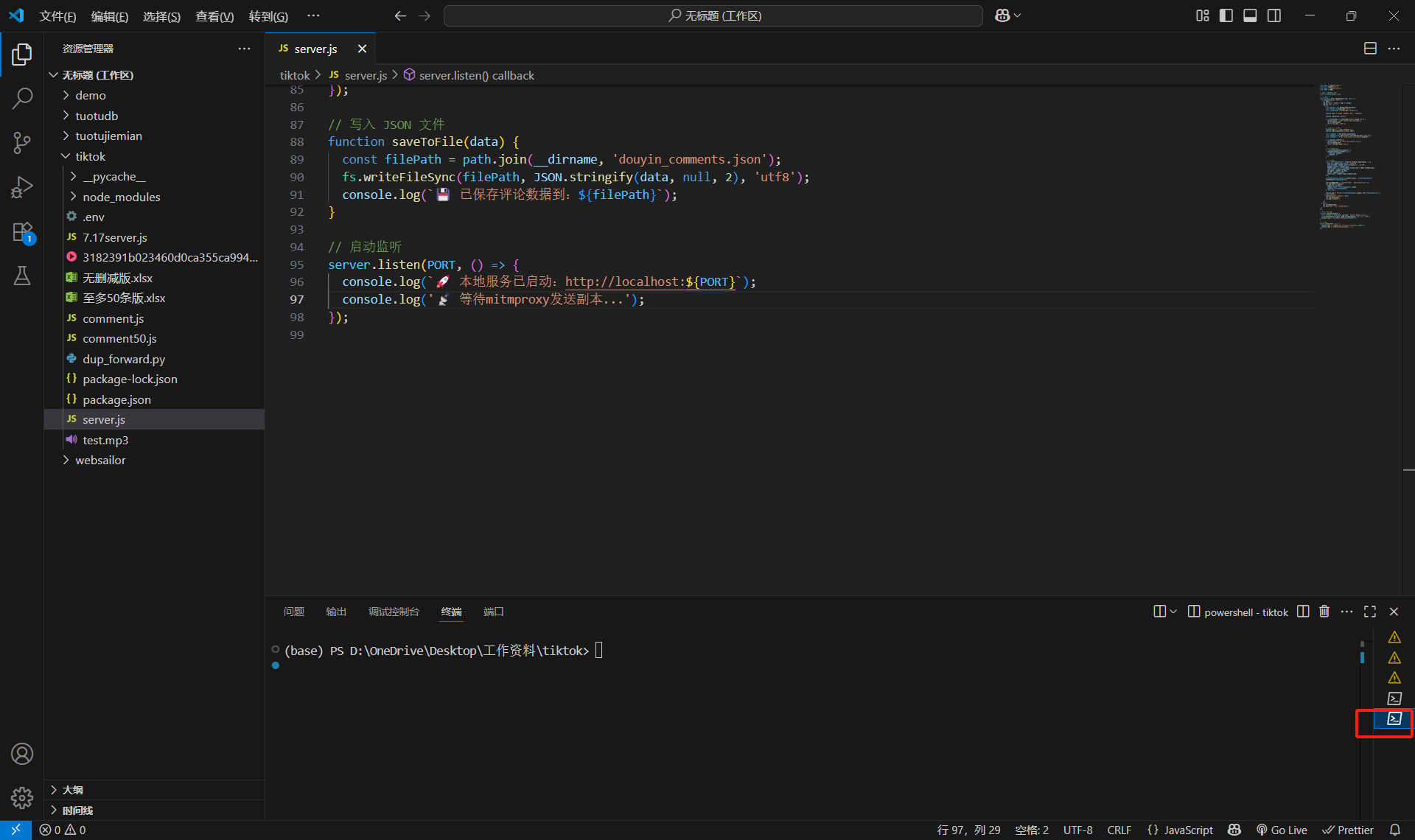
然后切換終端(注意!點紅色的地方,這時候已經切換到第二個終端了)
然后終端輸入mitmproxy -s dup_forward.py,點擊空格(一定要先下載mitmproxy,不然沒用)
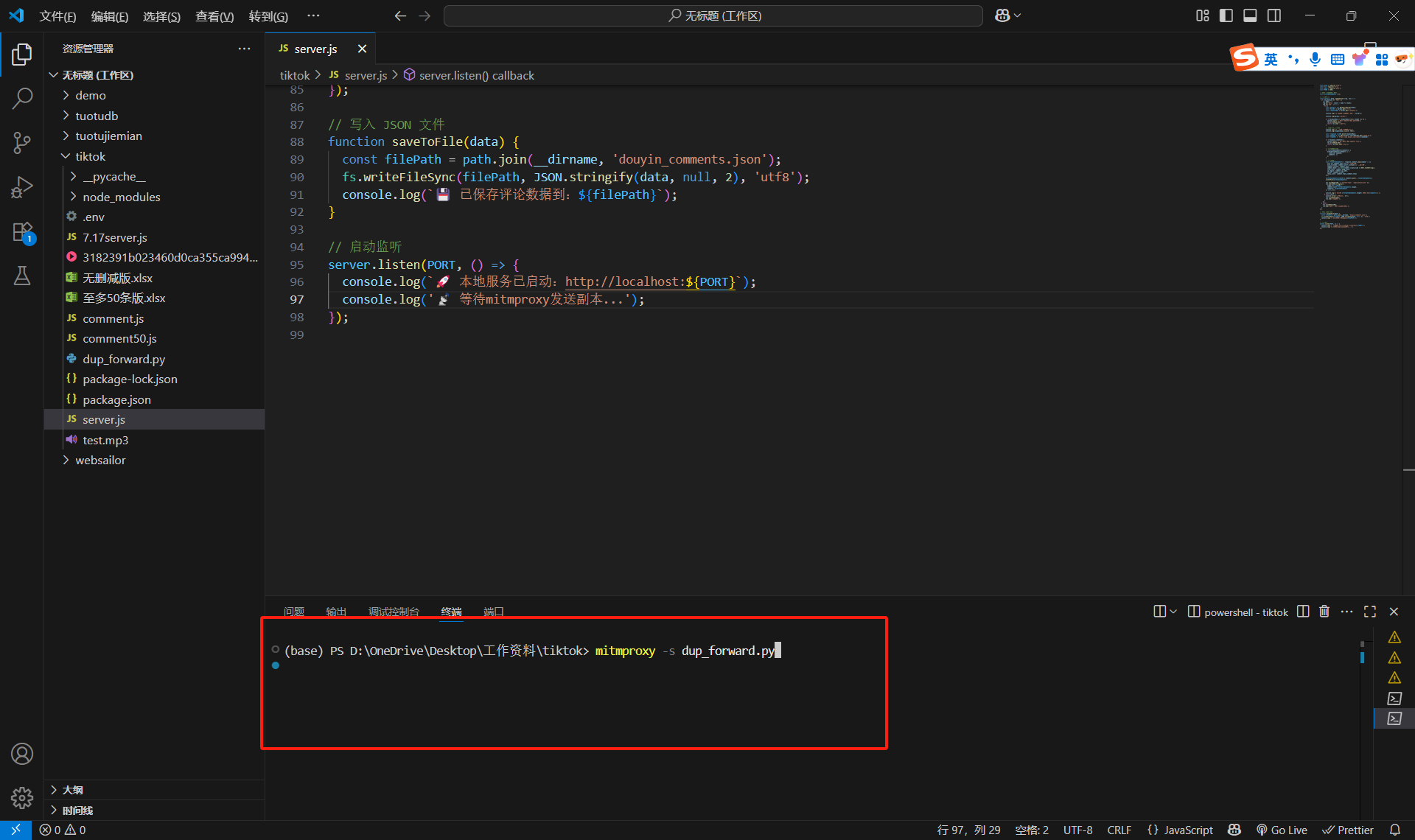 然后出現如下場景,才算成功:
然后出現如下場景,才算成功:
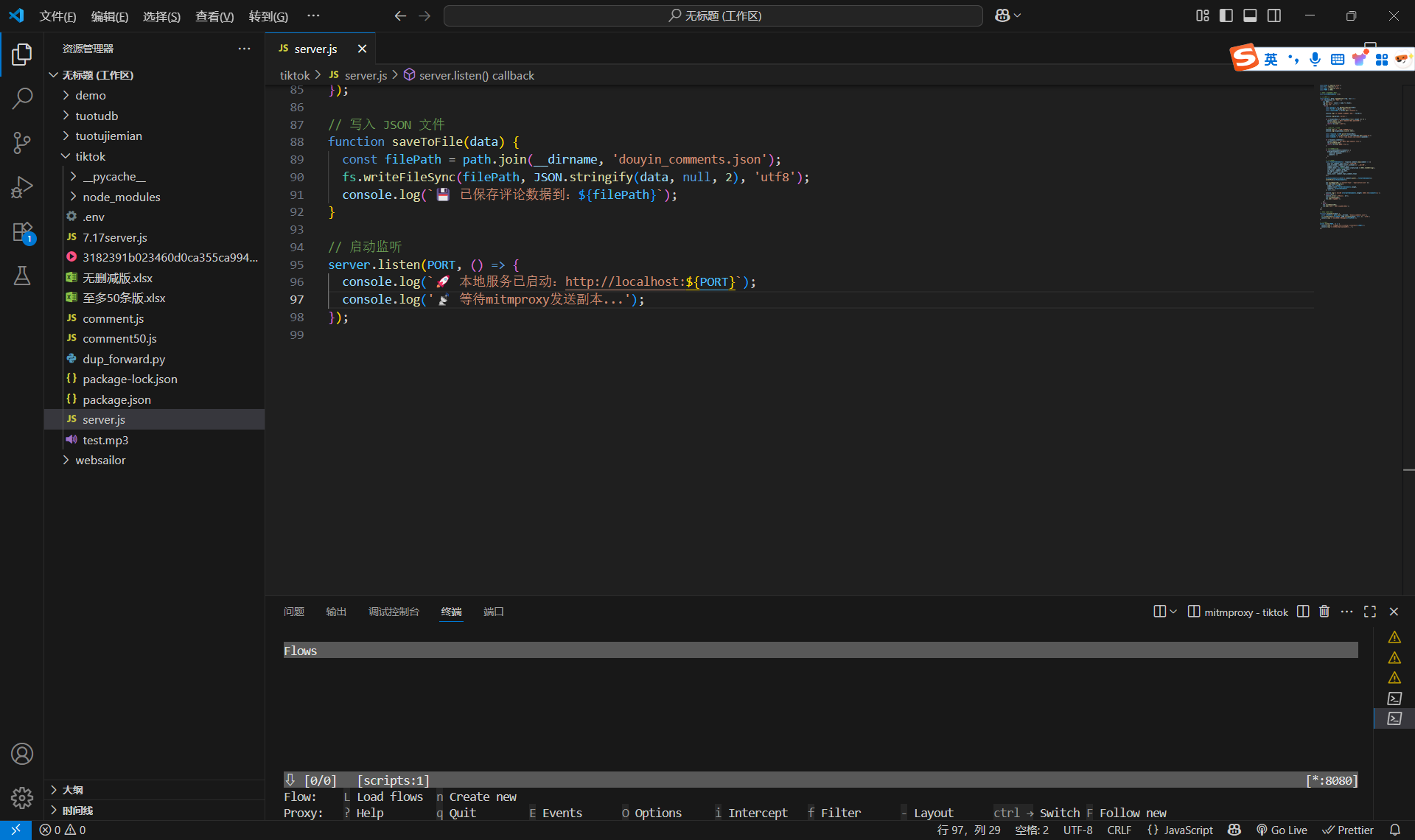 這個時候已經部署好兩個服務器了,server.js是處理抓包數據的腳本,dup_forward.py是抓包腳本。
這個時候已經部署好兩個服務器了,server.js是處理抓包數據的腳本,dup_forward.py是抓包腳本。
這個時候dup_forward.py監聽的是8080端口,我們需要抓包某抖的評論,就需要讓瀏覽器打開鏈接的時候請求走8080端口代理,這樣我們就可以偷偷抓包了。所以下一步修改代理:
博主是windows11,如果是其他電腦可以問問deepseek怎么切換代理的端口(此操作有風險,可以提前看一下下面的注意事項)
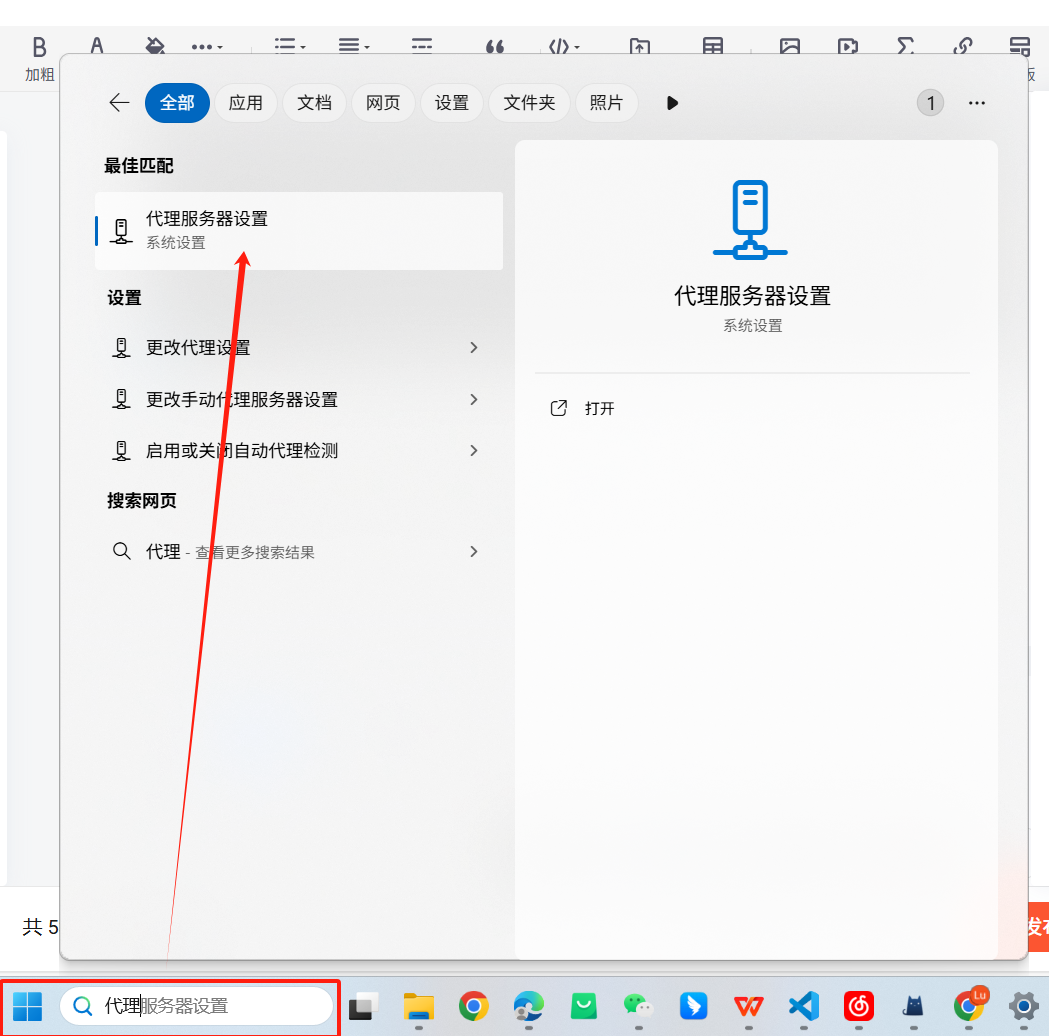
點擊編輯:
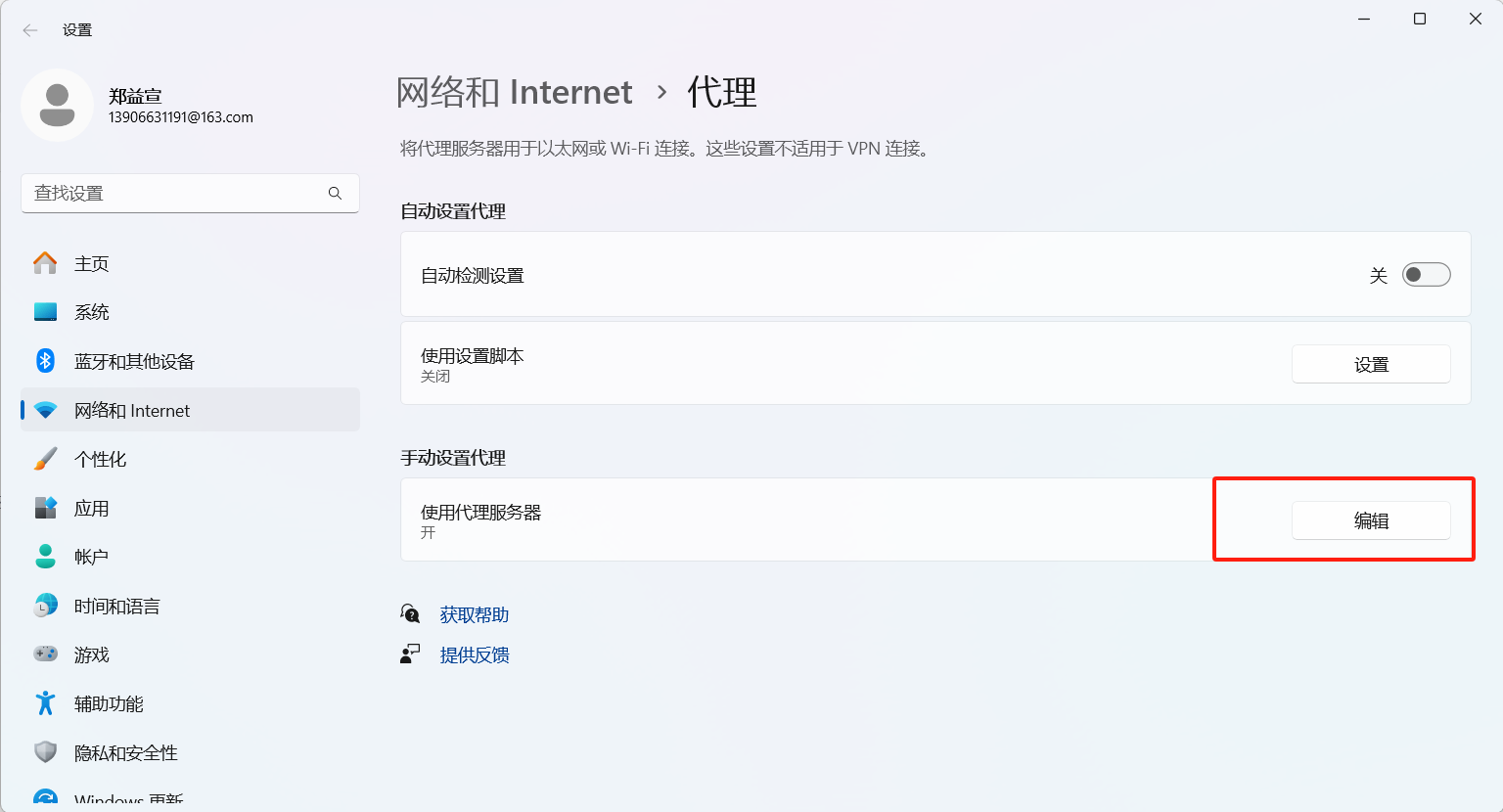
然后使用墻的小伙伴們注意了
我這里改了代理,如果你們使用墻有可能后面會出錯,因為你們墻也是一個代理,他監聽的端口和我們這里用mitmproxy的端口不一樣,所以用完后一定要修改代理配置回來,如下圖是博主一打開時候的樣子,到時候弄完得改回去!:
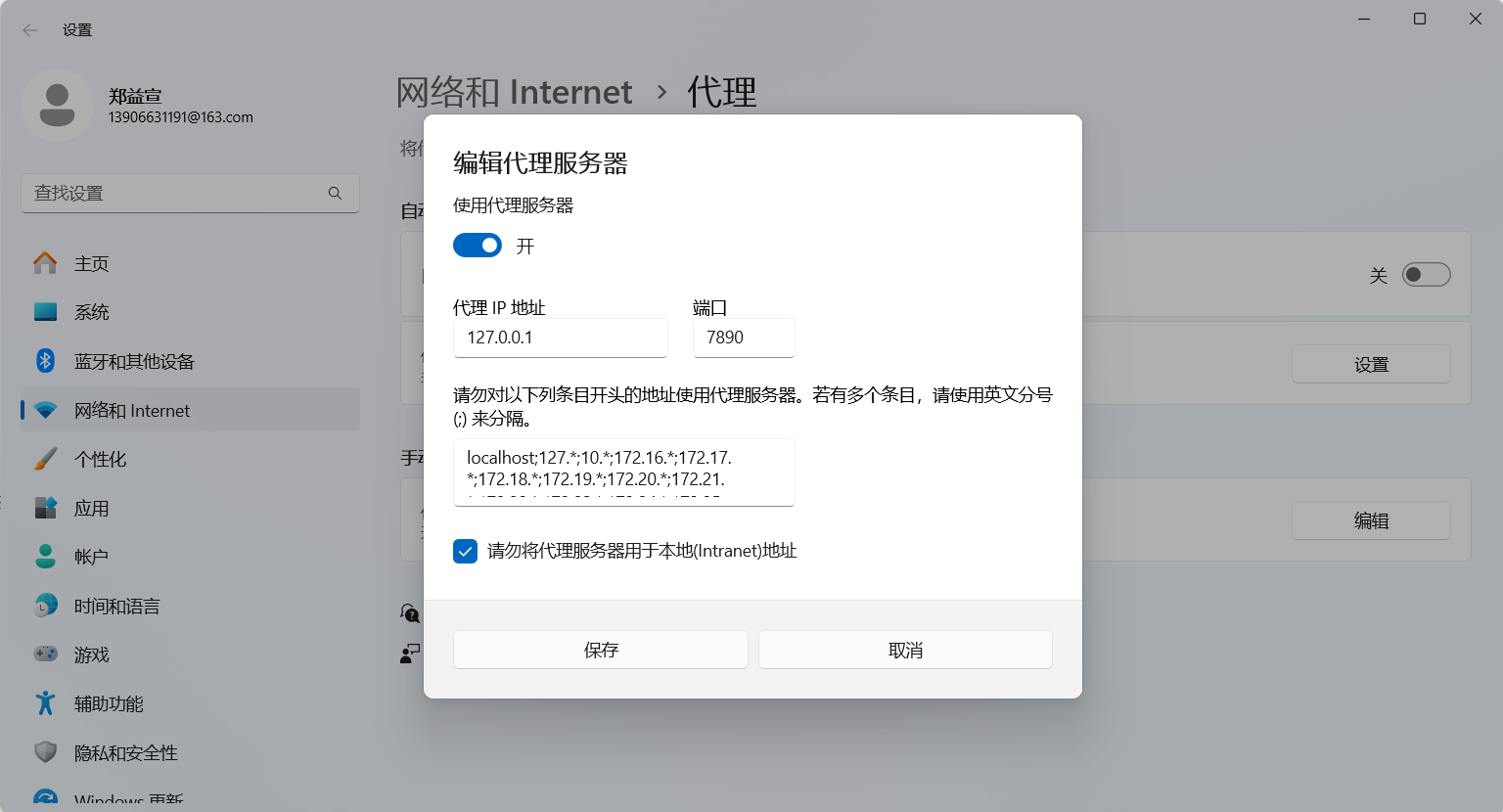
接下來是需要操作的,打開使用代理服務器,需要改端口為8080并保存(此操作前需要讀一下后面的注意點,即“沒用墻的小伙伴們注意了,這個非常重要,是全場最重要的一點”,因為這個操作處理不好可能讓瀏覽器訪問不了網頁的):
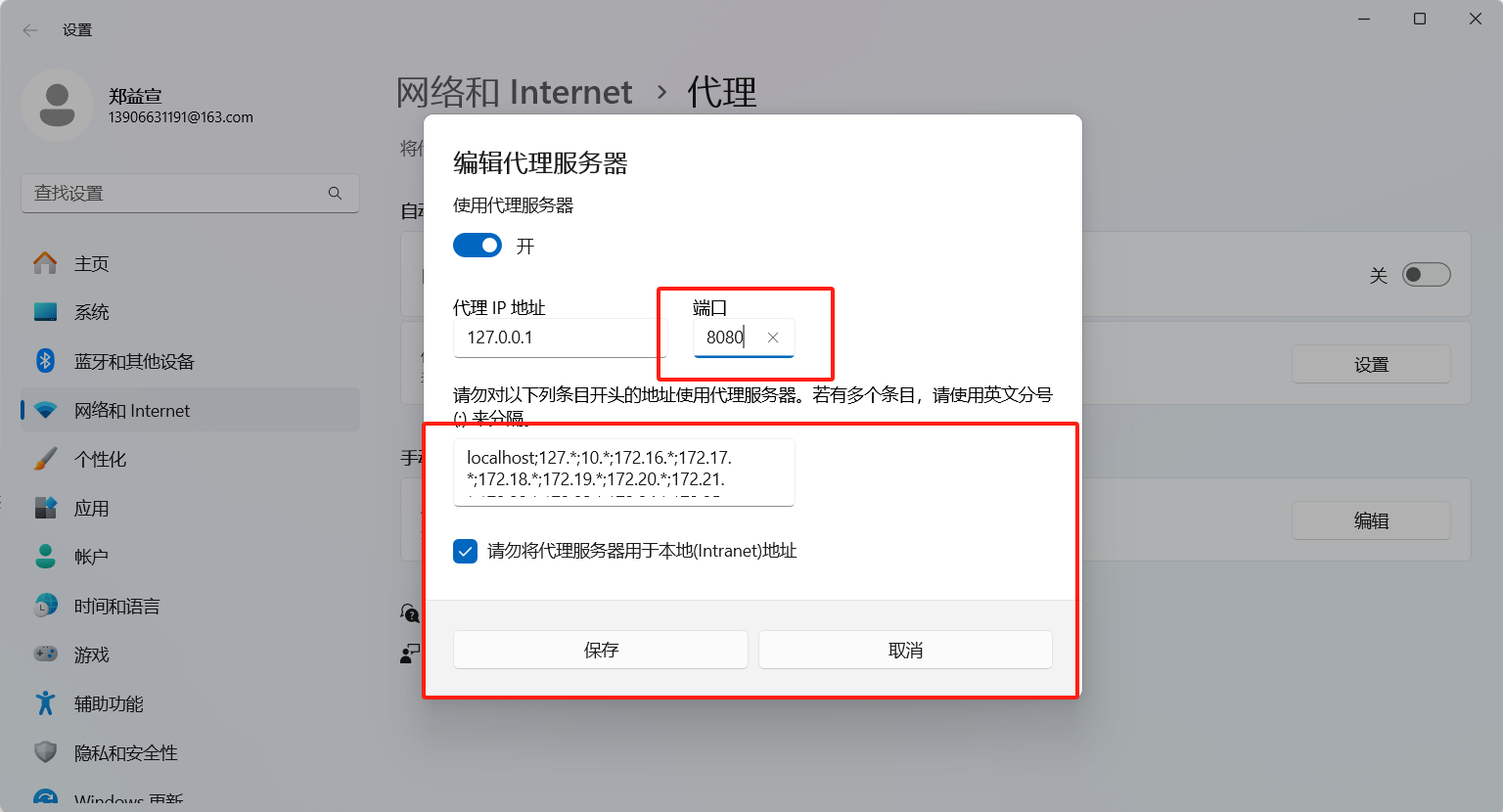
然后沒用墻的小伙伴們注意了,這個非常重要,是全場最重要的一點!!請認真觀看
因為你們一上來是沒有開代理服務器的,點擊了開代理服務器就意味著你們后面瀏覽器的請求要通過8080發送,8080是我們自己的服務器,如果你后面關掉了我們自己的8080服務器(即mitmproxy -s dup_forward.py)那個,那么你打開瀏覽器新頁面將會看到如下場景“你尚未鏈接,代理服務器可能有問題”。

看起來像是你沒網了一樣,所以,如果你打開了代理服務器,再沒有關閉這個代理服務器之前,你的瀏覽器是沒法訪問其他網站的,除非你按照我前面的操作部署了8080服務器(即mitmproxy -s dup_forward.py)
如果你臨時想退出!或者臨時想訪問其他網頁!!或者干脆就不想干了,你需要做的僅僅只是打開剛剛開代理的頁面,然后把使用代理服務器關掉,一切就正常了。
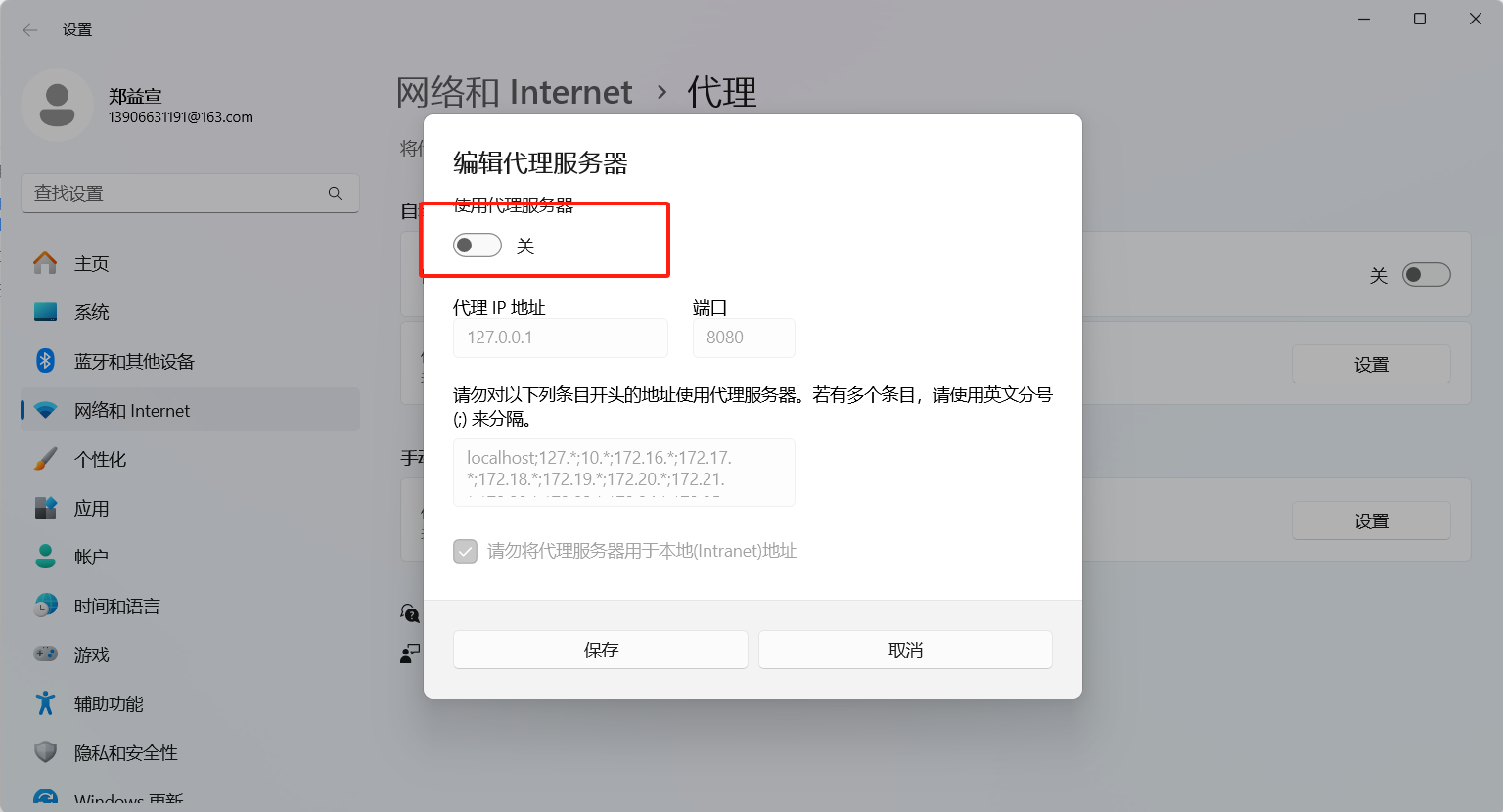
我需要再次強調的是:
我們用mitmproxy開的服務器是自己的服務器去監聽8080端口。打開代理的8080端口,瀏覽器走會先走我們自己的mitmproxy服務器。如果我們服務器開啟著,那一切都正常,因為我們服務器會轉發請求,因此可以爬。
如果你不小心關掉了我們自己的服務器,那么請把“使用代理服務器”關掉,因為會“顯示您尚未連接的”,但如果你真的有需求還需要繼續往下爬,那你可以終端輸入“mitmproxy -s dup_forward.py”,瀏覽器走自己服務器轉發,后面爬操作暢通無阻。
這時候全部已經部署完成,然后可以開始爬了。
然后隨便打開一個視頻,然后往下滑動評論區,評論區加載多少,后臺就能爬多少。
 爬多少取決于你往下加載的評論區多少,見同目錄下的douyin_comments.json
爬多少取決于你往下加載的評論區多少,見同目錄下的douyin_comments.json
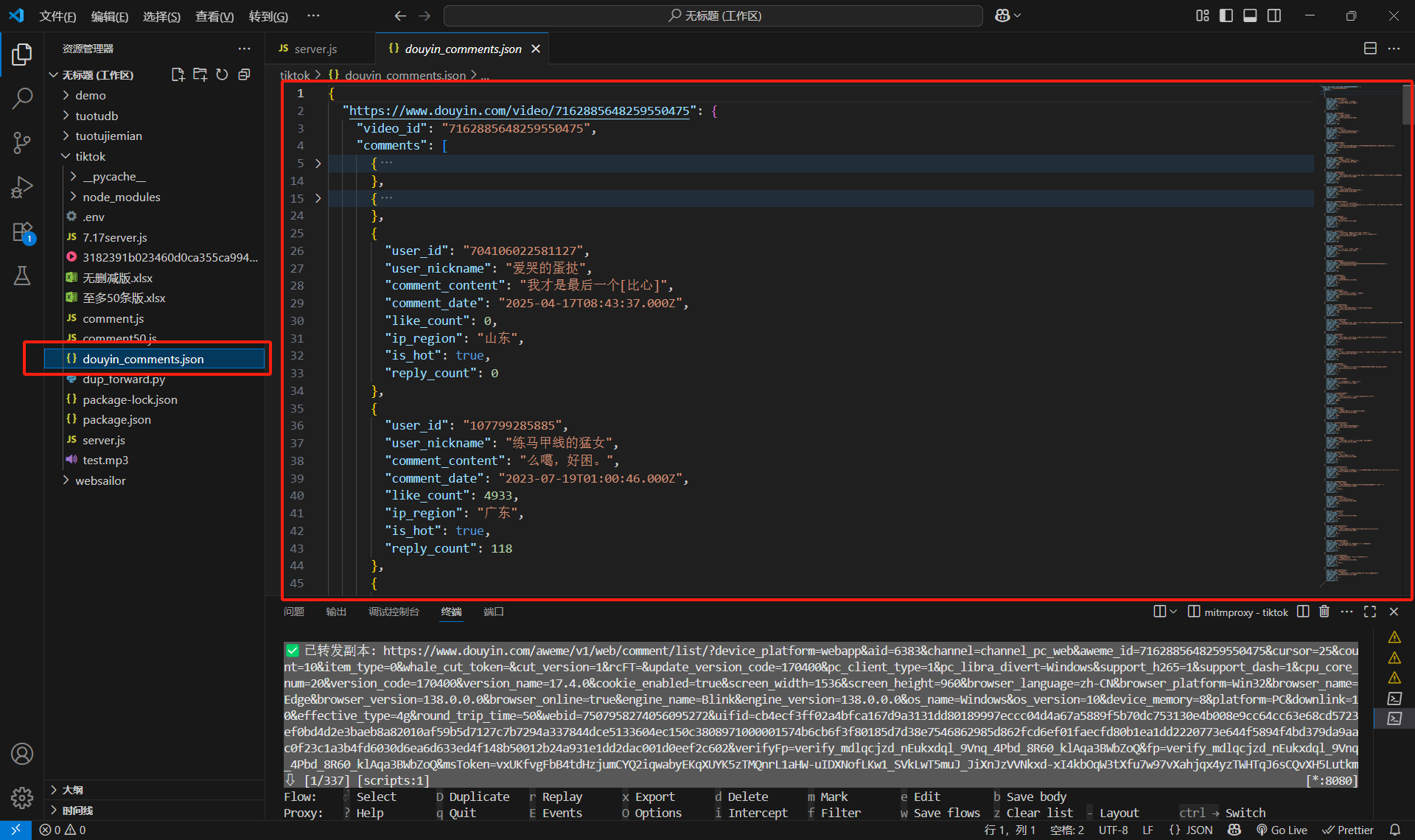 如果需要換下一個視頻就直接打開一個新的鏈接就行,腳本會按網頁自動分類的
如果需要換下一個視頻就直接打開一個新的鏈接就行,腳本會按網頁自動分類的
 然后這個時候數據還是json文件嘛,json文件不是那種xlsx看的不太爽(此時已經可以ai分析了)
然后這個時候數據還是json文件嘛,json文件不是那種xlsx看的不太爽(此時已經可以ai分析了)
如果需要轉成xlsx那么前面有一個comment.js(所有都轉xlsx)以及comment50.js(前50條轉xlsx)
就派上用場了:新開一個終端,然后輸入node comment.js或者node comment50.js

然后douyin_comments.xlsx就是了。
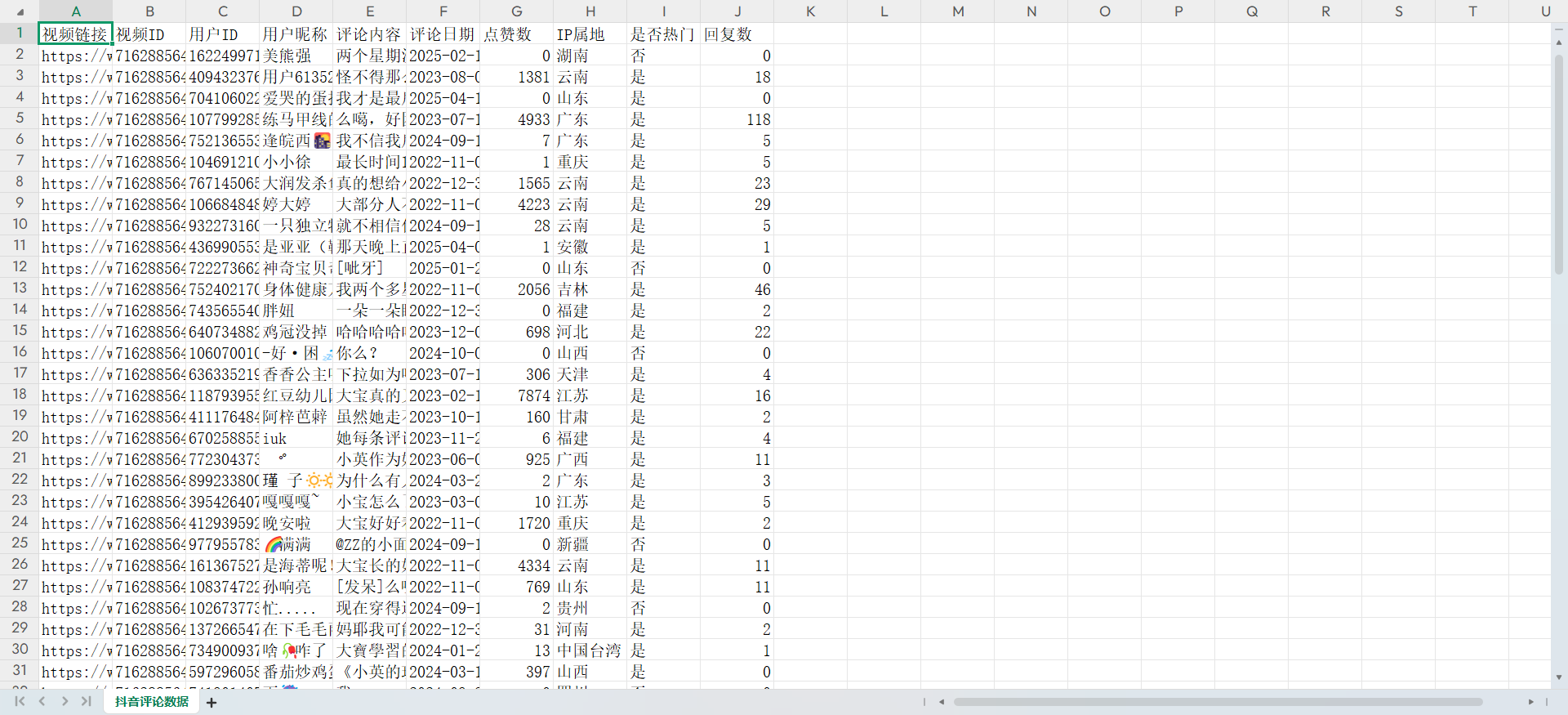
第二天爬的看:
然后由于大家肯定不是一次性一天全部爬完,終端一旦關閉,所有的緩存都刪除,但是douyin_comments.json和douyin_comments.xlsx不會刪除!!雖然不會刪除,但是如果你第二天發現我還得爬,請你記住給原來的名字改掉,不然腳本又自動替換掉原來的douyin_comments.json和douyin_comments.xlsx了!
douyin_comments.json這個文件如果你第二天一運行node server.js直接就全部清空了。
想重新開啟服務器來的看:
如果你發現vscode調試的時候亂七八糟的,想重新服務器關掉重新開。
那么你可以切換到那個server.js的那個終端,然后按一下ctrl+c,就可以退出了,然后可以重新執行node server.js (此操作會清空douyin_comment.json啊別亂重啟,如果真需要重啟又要保留原來的json,請你把原來douyin_comment.json和douyin_comment.xlsx改個名唄)
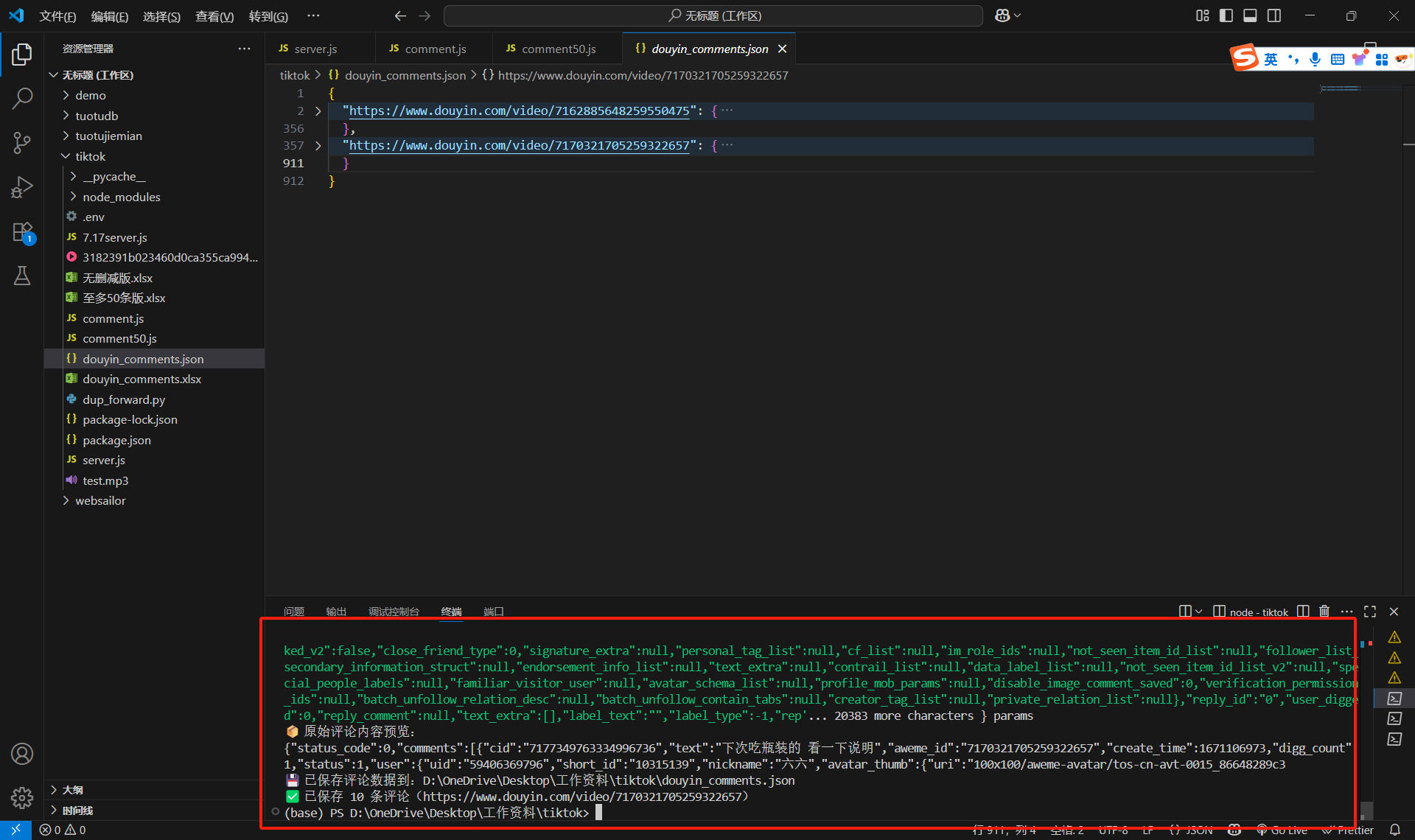
另一個服務器也是一樣:先切換到dup_forward.py的那個終端,然后ctrl+c,然后最下面輸入yes
重啟的時候再執行mitmproxy -s dup_forward.py就行了
然后就可以重新爬取了,記住重啟要改名啊!!!不然原來白白爬了。
?






防暴力破解BAT腳本)











)
