一,卷積后的特征圖大小計算
眾所周知,提到深度學習,必不可少的會提及卷積,那么如何計算卷積之后的圖片大小呢?
下圖呈現:
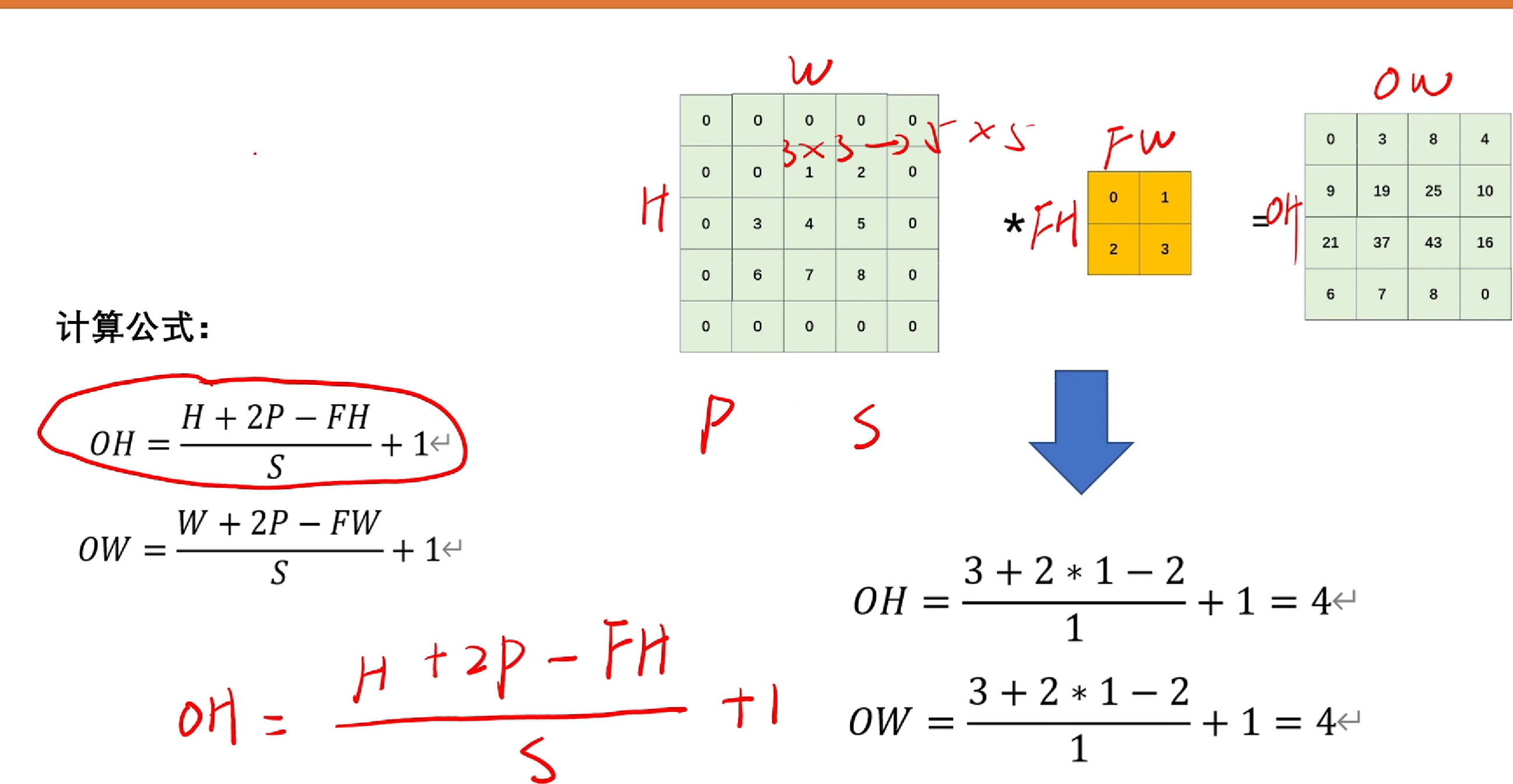
如圖, 我們令FH,FW為原圖像的長度FH*FW。P為padding的長度(假如padding=1,則3*3變成5*5),H,W為圖像padding后的長度。OH,OW為卷積后的圖像長度。
ps:計算結果為小數的話向下取整。
練習題:
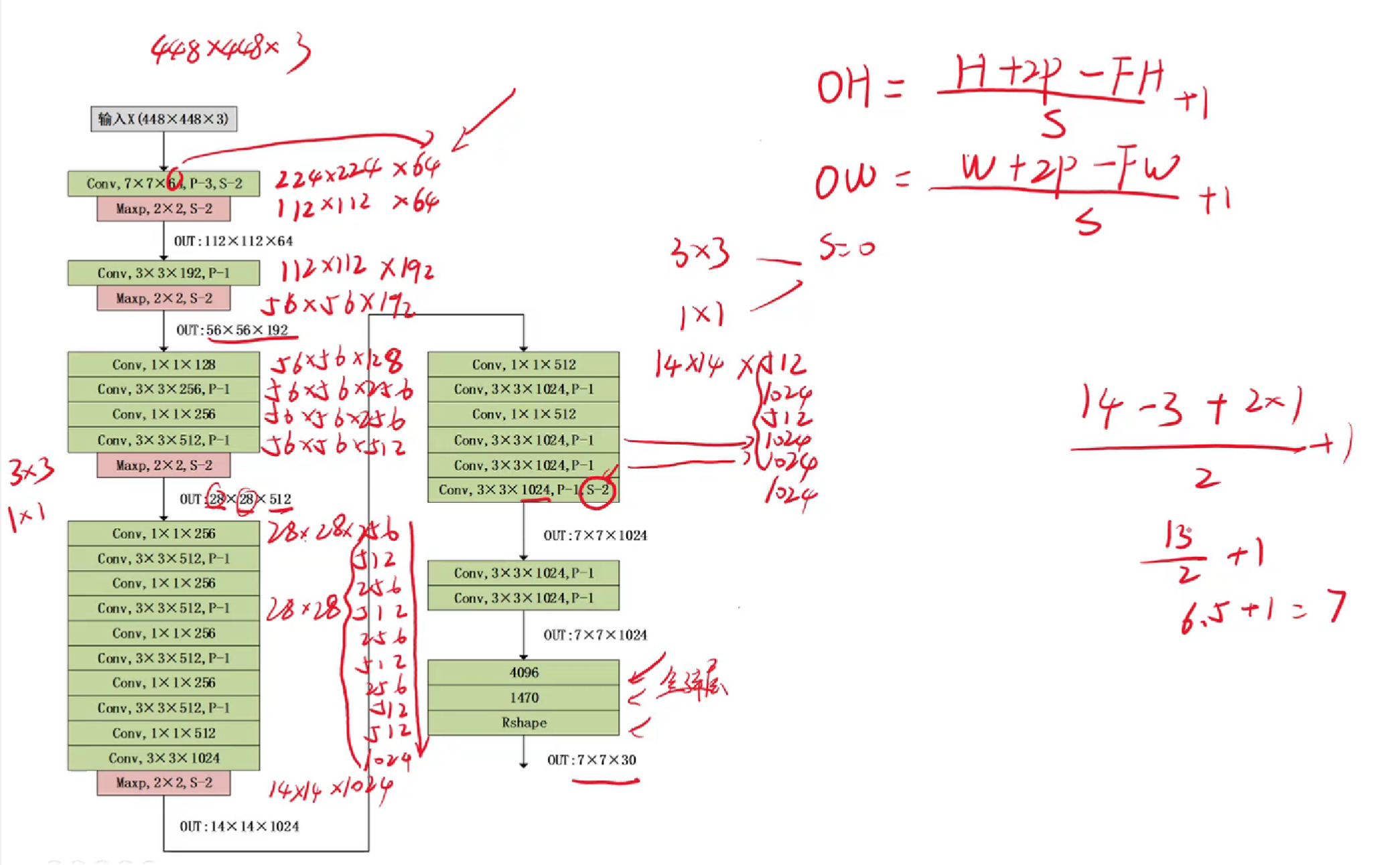
答案:
 ?
?
小tip:(1)單階段檢測:分類和檢測同時做----速度快
? ? ? ? (2)雙階段檢測:先分類,再摳圖給檢測器做檢測---精度高
池化,下采樣,上采樣概念區分:
- 池化:一種特殊的采樣操作,通常用于減少特征圖的空間尺寸,常見的有最大池化和平均池化。
- 下采樣:將數據的空間尺寸減少的操作,池化是一種常見的下采樣方法。
- 上采樣:將數據的空間尺寸增加的操作,常見于生成更高分辨率的圖像或特征圖。
卷積,池化會使得模型對圖像的感受野不斷增大。
二,深刻理解yolov1模型
不管現在發展到了yolov幾,要想深刻理解yolo模型的本質設計,就要回到yolov1~yolov3.
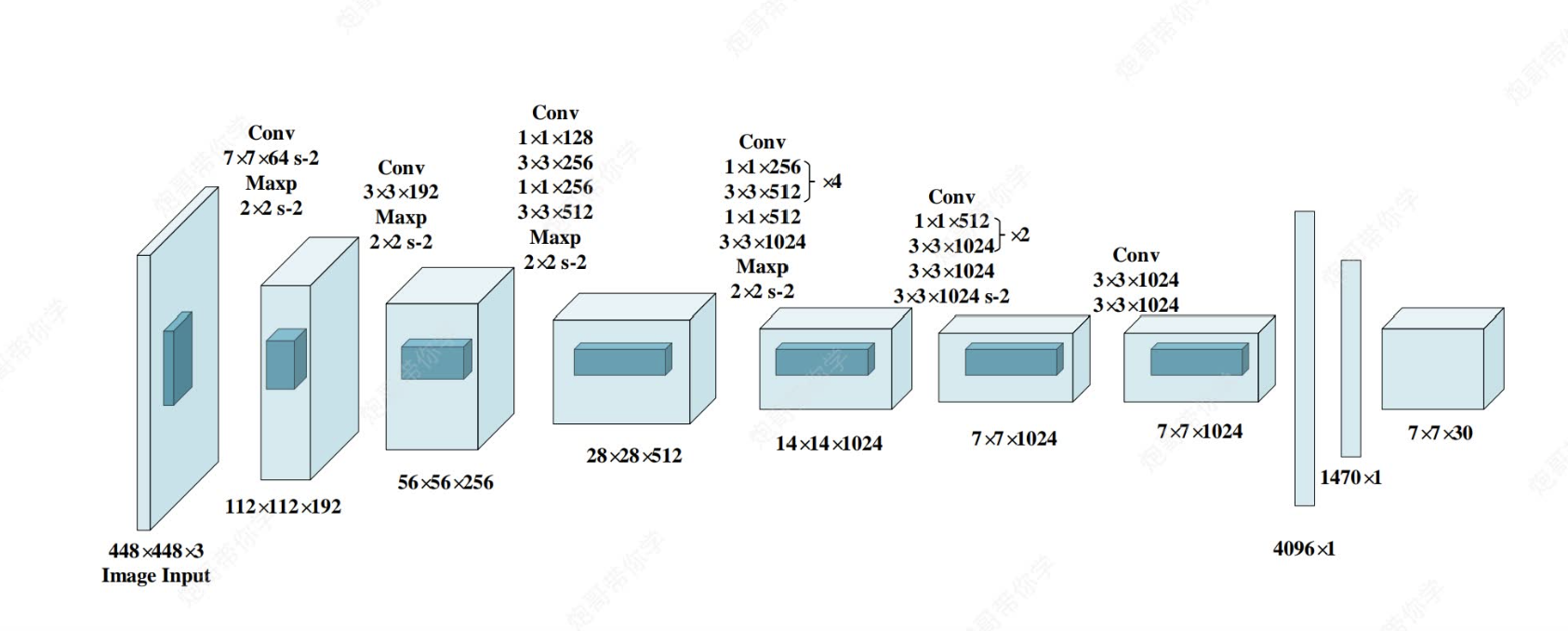
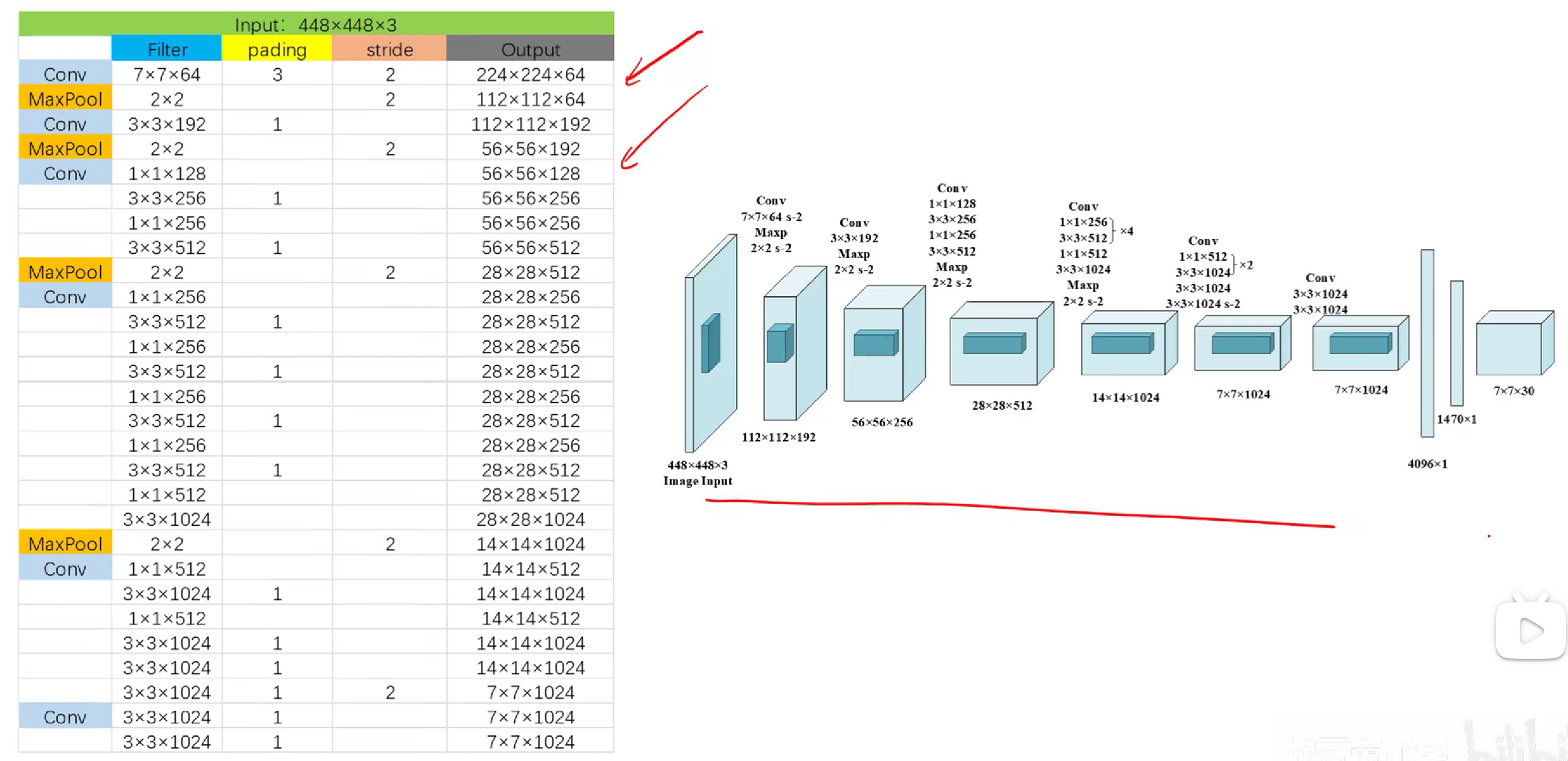
上圖為yolov1的網絡模型圖,?其中都是采用和CNN一樣的思路(卷積+激活函數+池化+最后全連接層),但是和CNN不一樣的是,CNN全連接層最后通過softmax函數可以直接輸出我們分類各類別的概率來完成任務,但是yolo中最后全連接層輸出的只是7×7×30的向量,他是怎么實現對原圖的目標識別與類別檢測的呢?(`ヘ′)=3
解答:
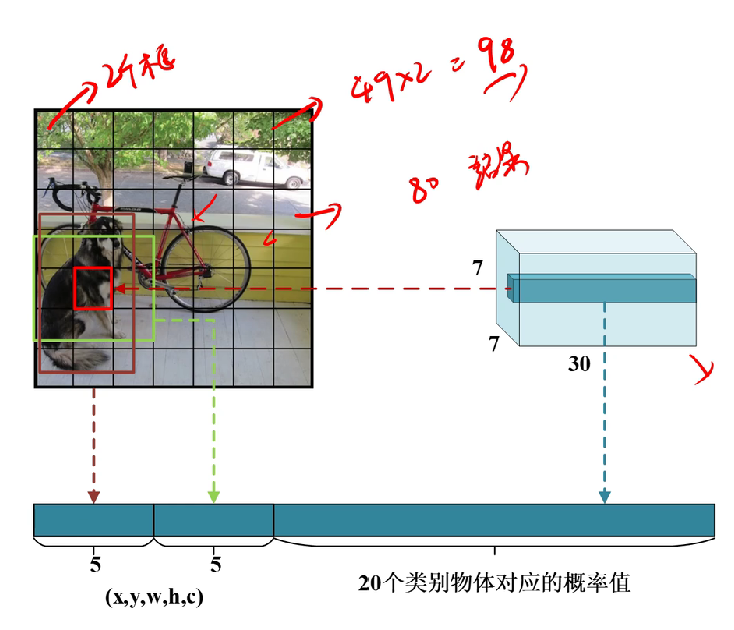
首先,我們需要理解7*7*30這個向量,他的意思是有7*7個格子,每個格子有30個向量(如下圖)(包含30個信息,為什么是30個呢?稍后會說)
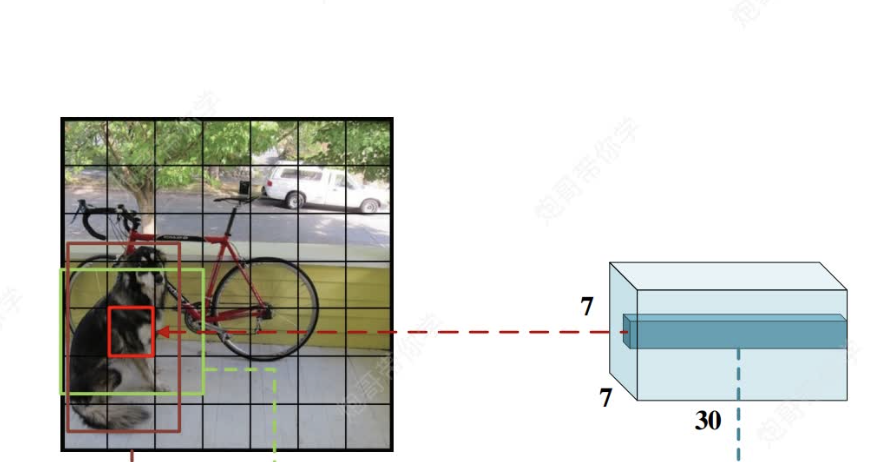
然后這個7*7的向量會被映射到原圖448*448?,將原圖劃分為49個格子(注意,不是真的劃分,是一種映射),每個格子對應原圖的一塊區域。
對每個區域信息的理解
然后,這時你可能會想每個格子會有原圖該區域的檢測信息,理解正確,但是要注意,每個格子并不只有該區域的信息,而是都具有全圖像全局信息,為什么呢?(這里是理解難點)
由CNN的知識可知,通過層層卷積和池化操作,輸出的每個向量信息都具有擁有全局感受野(Global Receptive Field)。
特征表示的層次性和抽象性:
- 深度卷積網絡通過多層卷積和池化操作,逐步提取圖像的層次化特征。低層特征(靠近輸入層)通常對應邊緣、紋理等簡單模式,感受野較小。高層特征(靠近輸出層)則對應更復雜、更抽象的概念,如物體部件、物體類別等,感受野更大。
- 當信息傳遞到網絡的最后幾層,形成用于預測的77特征圖時,每個特征圖上的值(對應一個網格單元)已經包含了非常高級和抽象的信息。這些信息不僅僅是簡單的像素疊加,而是通過復雜的非線性變換學習到的、對目標檢測任務有用的表示。
- 即使感受野覆蓋了整個圖像,這些高級特征對于“當前網格單元中心是否有特定類別的物體”這個問題來說,仍然是非常相關的。例如,圖像其他部分的物體、背景、甚至物體的上下文信息,都可以幫助模型判斷當前網格單元內的區域是否更可能包含某個特定類別的物體(比如,如果網格單元區域看起來像車輪,而圖像其他部分有車身,那么它屬于車的概率就更高)。
局部信息的權重和定位:
- 雖然全局信息被整合,但模型在學習過程中會自動學習到哪些信息對于當前網格單元的預測更重要。對于“當前網格單元中心是否有物體”的判斷(置信度分數 Pr(Object) * IoU),模型會賦予網格單元直接覆蓋區域的特征更高的權重。
- 對于邊界框坐標(bx, by, bw, bh)的預測,模型學習到的回歸函數也會主要關注網格單元覆蓋區域的特征來精確定位。全局感受野提供上下文和背景信息,幫助更精確地定位(例如,避免將目標框錯誤地延伸到背景區域),但最終的坐標預測仍然是以網格單元為中心,并受其局部特征主導的。
注意力機制(隱式):
- 可以將深度學習模型看作一種隱式的注意力機制。在訓練過程中,模型通過反向傳播學習,會“關注”那些對預測目標(即當前網格單元是否包含物體及其類別和位置)最有用的特征。即使感受野很大,模型也會學習到,對于當前網格單元的預測任務,只有來自其中心區域及其附近的信息才是最關鍵的。
網格劃分的設計:
- YOLOv1的設計本身就是將圖像劃分為網格,并讓每個網格單元負責其中心區域。網絡在訓練時會學習到這種責任分配。因此,即使特征具有全局感受野,網絡的最終輸出(通過全連接層和Sigmoid函數)被訓練成主要反映對應網格單元責任區域內的內容。
簡單類比:
想象一下,你要判斷一張照片的左上角(一個網格單元負責的區域)是否有一只貓。你不僅僅看左上角,你還會看看整個照片的上下文(比如背景是在室內還是室外,是否有其他動物,整體色調等)。這些全局信息(整個照片)幫助你做出更準確的判斷(左上角是否有貓,以及是什么類型的貓),但你的最終判斷仍然主要基于左上角區域本身的內容。深度學習模型在做類似的事情,它利用全局上下文信息來增強對局部區域的判斷能力。
因此,全局感受野并非壞事,它提供了寶貴的上下文信息,有助于提高檢測和分類的準確性,同時模型通過學習能夠有效地將注意力集中在需要負責的局部區域上。
也就是說,雖然每個格子對應原圖的一塊區域而已,但是他們都擁有全局感受野(目的:更好進行上下文聯系識別),然后通過權重定位更加關注原圖該區域的信息識別(注意力機制有點像)。
回到上文,我們將?這個7*7的向量會被映射到原圖448*448?,將原圖劃分為49個格子(注意,不是真的劃分,是一種映射),每個格子對應原圖的一塊區域后,每個格子都包含30個信息,分別是兩個檢測框(當初設計是為了提高準確率)的(中心坐標x,y,寬高w,h,及其對應的檢測置信度c)*2共10個,然后還有要識別的20個類別的概率(兩個檢測框共用概率值)共30個。
之后,每個格子都會生成2個檢測框,只是如果置信度低于我們認為設定的閾值,會被直接不畫出檢測框。然后剩下的框會進行非極大值抑制,最終產生概率最高的框。
?對獲取的(x,y,w,h)的理解,以及怎么運用的
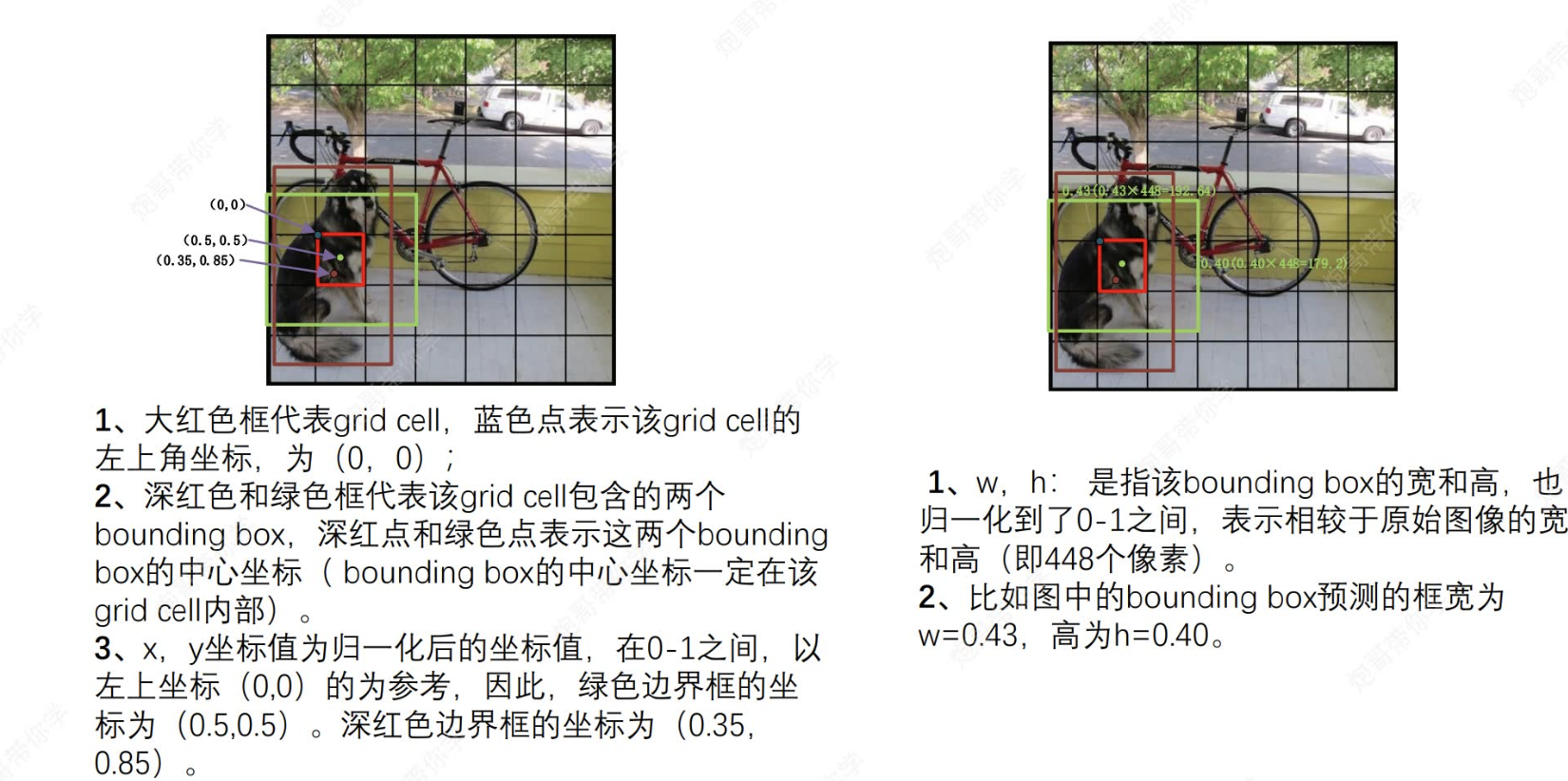
上文我們說到,沒過小格子都會得到x,y和w,h信息。接下來將解讀這些信息:
(1) 每個小格子都以自身左上角頂點為(0,0)原點,每個小個子所獲取的兩個預測框的中心一定在格子里面,并且坐標值都是經過歸一化標注于在各自原點的坐標系之中,然后映射到原圖坐標:
eg:綠色邊框的中心坐標為(0.5,0.5),格子有49個,原圖為448*448像素,則每個格子為64個像素,則該綠色中心在原圖的映射y坐標為0.5*64+64*4.
(2)而對于w,h,其值也是進行了歸一化,映射為原始圖像的寬高(這里也是每個格子都擁有全局信息的證明,能獲取全局信息)。
eg: w=0.43,h=0.40那么原始圖像的寬高就是448*0.43;448*0.40。
好啦好啦,不學了,還有沒講完的,精彩請看下一集~~
















技術構建的數據可視化大屏展示頁面)


