模擬實現之前需要了解的
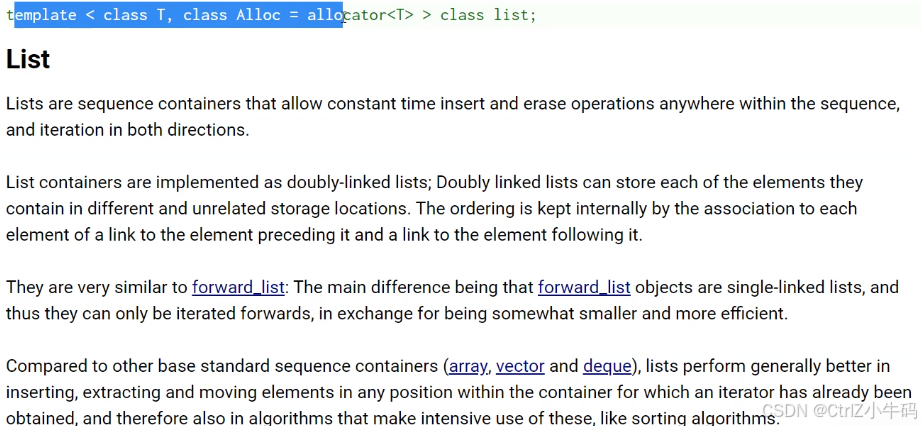
概念
帶頭雙向鏈表(double-linked),允許在任何位置進行插入

區別
相比vector和string,多了這個
已經沒有下標+[ ]了,因為迭代器其實才是主流
(要包頭文件<list>)
方法
構造
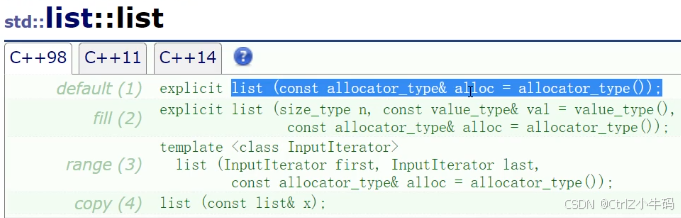
和vector的構造差不多,無參、n個、迭代器、拷貝構造
迭代器失效
因為底層結構不一樣
在list中的迭代器不會因為insert的挪動和擴容而失效,erase刪除到自己就會失效
clear會把所有節點清楚,但是不清楚哨兵位
特殊的方法Operations

逆置reverse
排序sort
(默認升序,如果要改就要傳仿函數)

![]()
list的排序意義不大,因為這個排序的效率太低
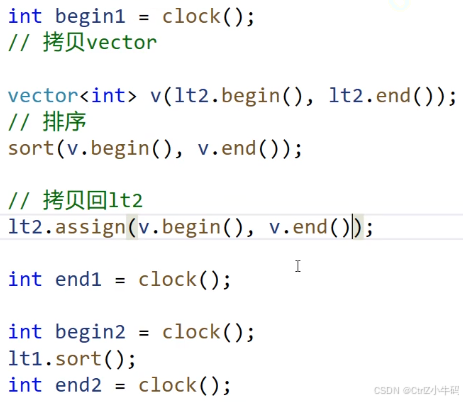
![]()
甚至vector還進行了兩次拷貝構造,都比list高了差不多四倍的效率
list底層用的是歸并排序,訪問效率太低導致的,并不是算法本身效率低
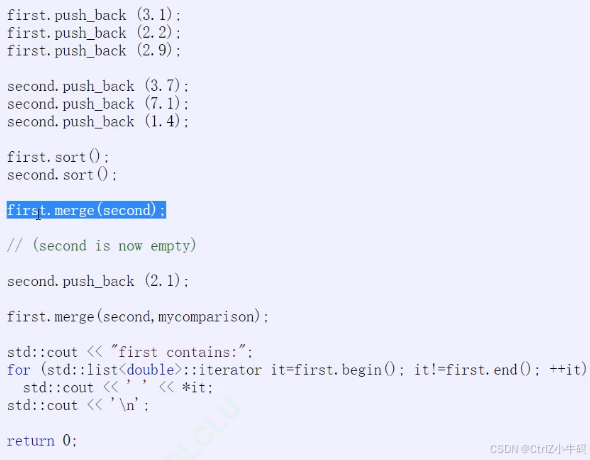
合并merge
本質上就是取小的尾插
去重unique
但是要求先排序
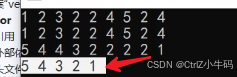
remove
給一個值,然后進行刪除(和erase不同,相當于是find加erase,find到了就刪,沒find到就不刪)
remove_if
條件刪除,和仿函數有關
splice
名字沒取好,應該叫轉移
作用:把某些值轉移到某個位置去
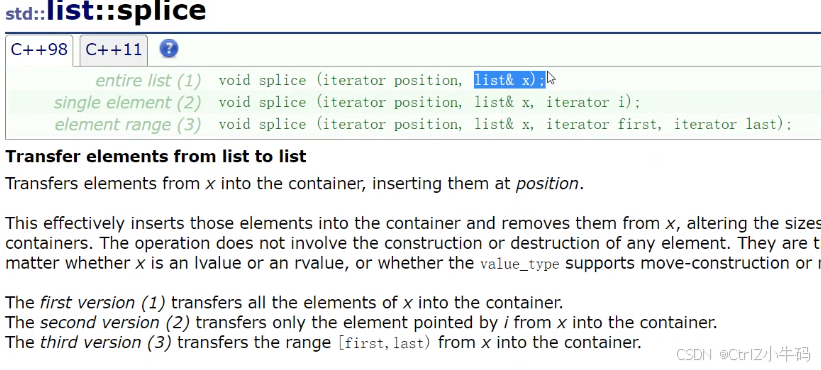
pos就是位置之前,一個鏈表、某個鏈表的一個位置、某個鏈表的一部分
也可以自己轉移自己
用法2

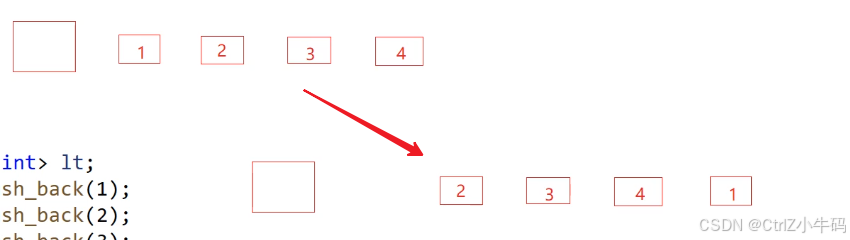
不刪除節點,只會改變指向,把1轉移到哨兵位之前,也就是4后面
用法1
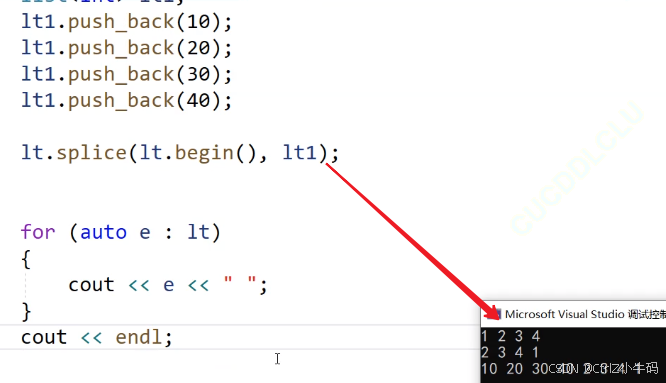
把前面的那個鏈表整個轉移到另個一鏈表的某個位置
另一個鏈表因為被轉移了,所以list1就沒節點了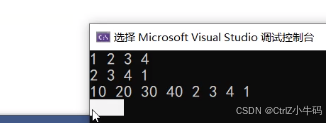
轉移的前提是類型必須匹配
鏈表的內部實現
1.先看源碼
 節點
節點
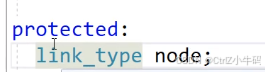 鏈表的成員變量
鏈表的成員變量
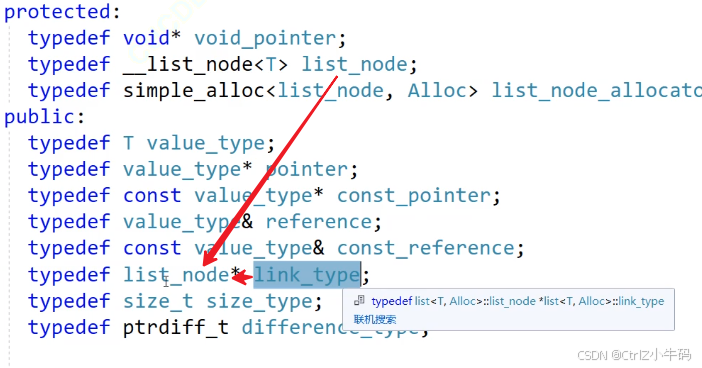
link_type其實就是list_node*;成員就是一個節點指針
2.看構造函數

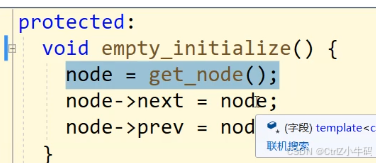
總結:調用了一個空初始化,然后這個空初始化建了一個哨兵位頭結點(get_node()),然后next和prev都指向自己
以下內容看看就好
空間配置器調用一個allocate的接口來獲取空間(單純的獲取節點)
創建一個節點,順帶初始化

3.看push_back
![]()
在哨兵位(end)的頭結點那里插入,在哨兵位的prev插入,就是尾插
insert和我們自己搞的差不多,就不用多看了

主要是迭代器比較麻煩
正式開始模擬實現
非常需要畫圖
先搭個架子出來
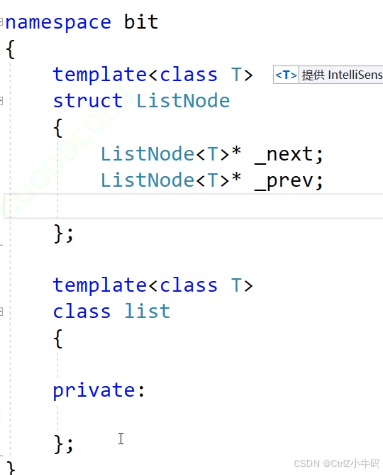
list需要節點,所以需要再建一個節點類出來,節點用的是struct(庫里面也用的是struct,只要是是需要大量公開的內容都可以用struct)
?鏈表的成員: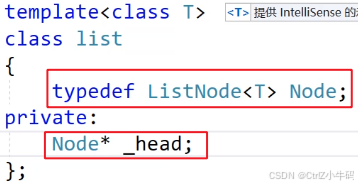
節點
成員變量
- 下個節點位置的指針
- 上個節點位置的指針
- 存值的地方
成員方法
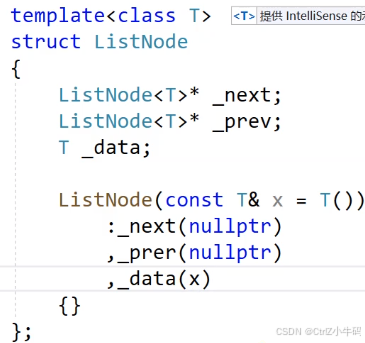
- 構造函數(在鏈表的構造函數地方,邏輯是先搞一個哨兵位頭結點,然后指針全都指向自己,而在搞一個哨兵位頭結點的時候會用到new?Node,此時new?Node就會去調用節點類的構造函數,所以我們需要提前把構造函數準備好)
鏈表
成員變量
- 一個哨兵位的頭結點
構造函數
就先搞一個哨兵位頭結點

pushback
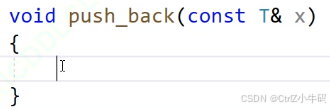
暫且不考慮insert復用,因為要用到迭代器
尾插邏輯:
新建一個節點,然后讓節點之間連接上:尾插就是在head的prev
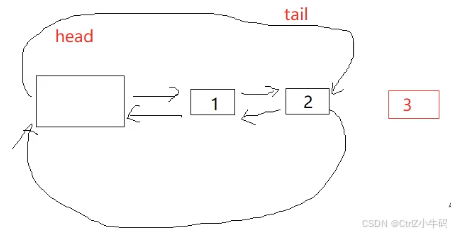
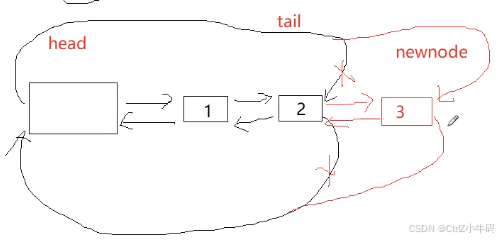
步驟
- 先新建一個節點
- 記錄沒插之前的tail
- 然后修改tail和newnode和head之間的指向

因為有哨兵位,所以就算沒有節點,當他們進行尾插的時候也不用考慮自己是第一個節點要怎么操作,這個是這個設計的優勢(主要工作就是找到tail和head,因為有哨兵位,所以哪怕沒有節點,tail也是head->prev=自己;剩下的就是改變指向了)
現在先實現一下遍歷數據(前提就是有迭代器)
我們的目的是實現以下的遍歷功能
- list<int>::iterator?it = lt.begin();
- lt.end()
- *it
- ++it
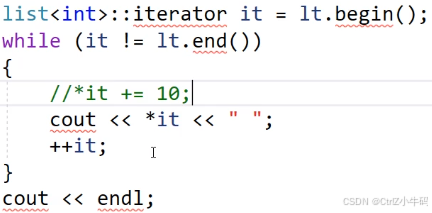
這四個功能對于list迭代器來說:
list的迭代器不能用原生指針
因為節點空間不連續(沒辦法直接typedef?T*?iterator,因為list的T是節點,只用節點指針沒辦法搞定
- list<int>::iterator it = lt.begin();(這個倒是可以用這個訪問方式)
- lt.end()(這個也可以解決)
- *it(對節點指針解引用得到的是節點,而不是節點的值,不滿足)
- ++it(++it實際達到的效果是it指針在地址上往前移動一個節點size單位的空間,并不會到下一個節點處,不滿足)
原因:List是一個節點一個節點開辟空間的,所以空間一定是不連續的
)
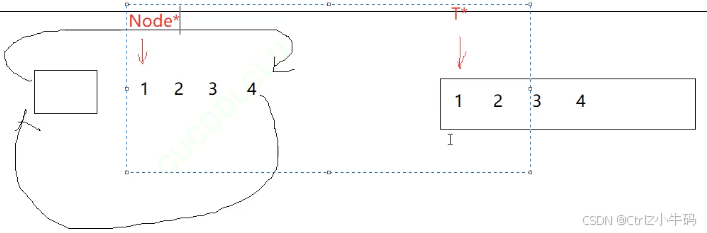
vector可以的原因
- 每個節點之間都是連續的,而且T就是數據的類型,每次++的時候都是往前走T類型size的空間,剛好就可以走到下一個節點處
- 解引用之后就可以得到T的值,即自己想要的數據
需要解決的問題:
- *it(對節點指針解引用得到的是節點,而不是節點的值,不滿足)
- ++it(++it實際達到的效果是it指針在地址上往前移動一個節點size單位的空間,并不會到下一個節點處,不滿足)
類比:
Node*原生指針不能滿足我們的需求
我們的那個日期類,如果想要做到++或者日期減日期,這種操作原本都是不能直接用的,但是我們內部可以自己去控制(憑借運算符重載)
因此,如果我們沒辦法用原生指針去實現*it和++it,那我們就自己去封裝一個迭代器的類(即內置類型不能解決我們的問題,那我們就實現成自定義類型),然后就寫(typedef?迭代器的類?iterator;),這樣就可以照常使用了
這個迭代器的類名字不重要,畢竟之后都是要用來typedef的
庫里面也是這樣實現的
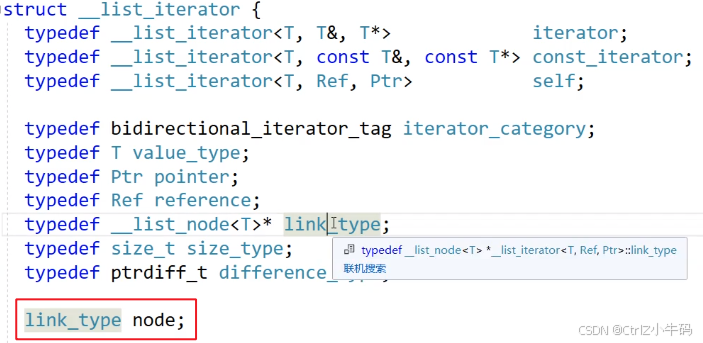
可以看到,庫里面的那個迭代器類的成員變量用的也是原生節點指針(link_type就是list_node*),在list里的迭代器也是原生節點指針,只不過因為原生節點指針的功能不符合我們的預期,所以我們就改造一下,用一個類去封裝,然后去把這個原生節點指針的運算符給重載成我們需要的功能,就可以去掌控迭代器的功能了
也就是可以做到以下功能
- *it(返回節點的值,調用operator*)
- ++it(跳轉到下一個節點,調用operator++)
- (還有一個沒有說的,因為迭代器類的成員變量就是一個節點指針,所以當sizeof這個迭代器的時候,得到的迭代器大小就是4,而這個4恰好就是自己那個節點指針的大小)
(類型決定了我們的行為是什么,如果是單單的原生指針,那++就是到下一個節點大小的位置處;如果說我們封裝了這個原生指針,修改了這個類型的具體行為,那++我們就可以修改為到下一個節點)
實現迭代器類
迭代器的行為是統一的,目的是不關注底層實現,而是要關注用指針類型的來訪問和修改元素
我們的迭代器類是實現成struct的,因為我們要讓外面的人能直接用
成員變量:節點指針
成員方法:構造函數、operator++()、后置++:operator++(int)、
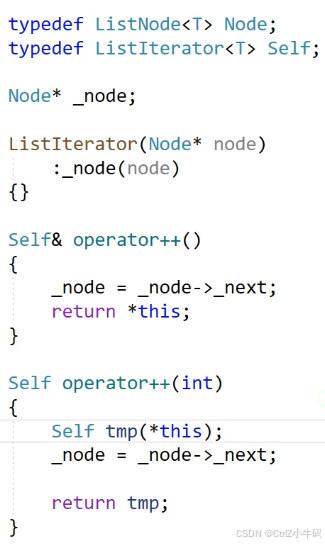
構造函數

使用場景:List<int>::iterator it = lt.begin();
這個it就是在用?lt.begin()的返回值Node*?來進行初始化
前置++和后置++(--也類似)



前置++返回的是++后的自己,后置++返回的是++前的自己
這個地方另外再typedef ListIterator<T> Self是因為后置++要返回的是原本的自己,也就是ListIterator<T> it或者說是*this
(這個地方會有點繞,因為this就是自己的指針,而
中的自己則是ListIterator<T>?it,所以需要解引用之后再返回)
?為了寫的方便,所以我們把ListIterator<T>給typedef成了Self
所以: 就是ListIterator<T> tmp(*this)
就是ListIterator<T> tmp(*this)
我們通過重載++修改了++的規則,讓++可以正確地指向下一個節點
拷貝構造
在這個地方我們可以不用寫拷貝構造,可以直接讓編譯器給我們自己生成那個淺拷貝的拷貝構造,因為我們的成員變量是一個節點的指針,淺拷貝這個節點的指針目的就是讓那個拷貝構造出來的迭代器也指向那個節點,要的就是淺拷貝(并非成員變量中有指針就要深拷貝,要看具體情況)
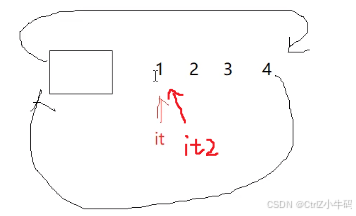
用it拷貝構造出it2,it2也同樣指向節點值為1的那個節點
析構函數
不需要寫析構,析構的目的是為了釋放資源,而迭代器指向的那塊空間并不是屬于迭代器的,而是屬于list的,迭代器的作用僅僅是訪問或者修改值,不需要析構
解引用

解引用要實現讀和寫的功能
運算符
operator!=和==
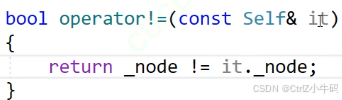
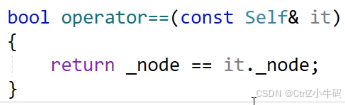
問:需不需要重載比較大小
要看有沒有意義
答:不需要,因為沒有意義,如果說是比較節點所在的位置的大小的話還好,但是這個是比較迭代器的大小,每個節點在new的時候地址都是無規則的,根本就不能保證后面的節點一定就比前面的節點的地址要大
正式開始鏈表類
目前已經搞好了迭代器類
現在我們要做的就是把這個迭代器和我的list連接起來
總結一下前面的部分:
?我們做的鏈表類是一個帶頭雙向鏈表
我們的節點是一個個數據單元,我們的鏈表就是要把他們鏈接起來
鏈表的迭代器因為原生節點指針無法滿足我們的功能,所以我們用一個類去封裝了一下節點指針,再用運算符重載來掌控他的行為
還是要重申一下結構:這個鏈表類需要和迭代器類和節點類結合起來使用,他們之前的關系是并列的,其中,節點類和迭代器類使用的是struct,設置成struct就是為了讓list可以訪問,是專門為list類服務

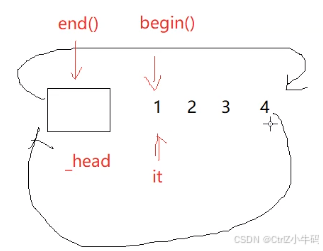
如果說我們要訪問我們的鏈表,那我們就要從第一個節點(_head->next)開始
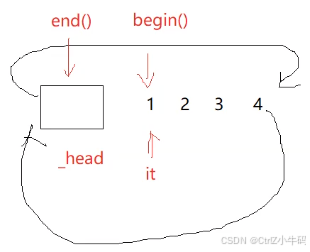
begin()和end()
因為只有list類才知道鏈表的開頭是在哪里,所以我們的begin要寫在鏈表類里
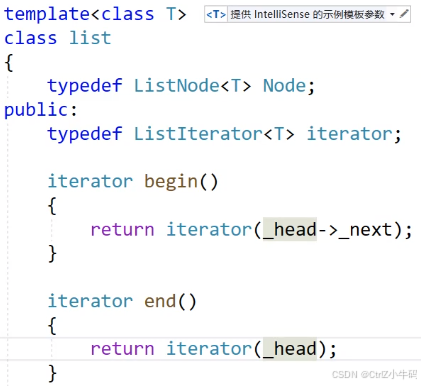
上面的寫法和下面的寫法一樣,沒什么區別,只不過上面用了匿名對象
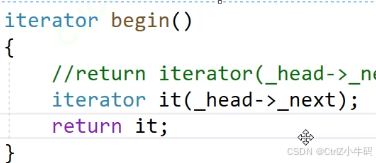
甚至可以這樣寫: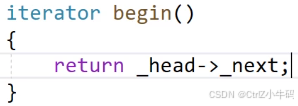 走隱式類型轉換,
走隱式類型轉換,
有了這個我們就可以實現前面沒有實現的遍歷了
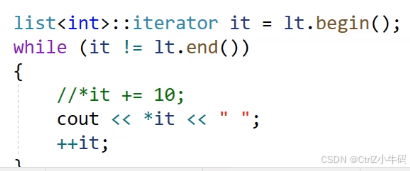
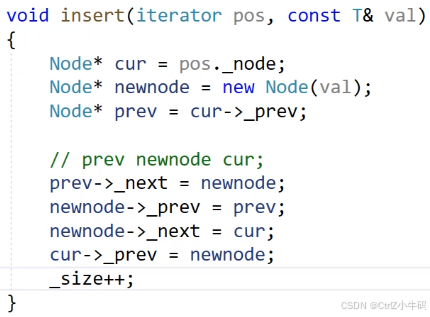
insert
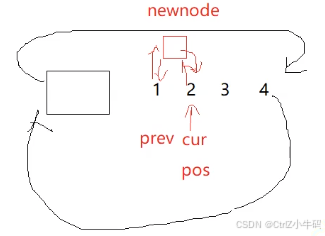

問:為什么還要用cur記錄pos,而不是直接用pos,不都是指向同一塊空間嗎?迭代器不就是指針嗎?為什么還要取_node出來
答:迭代器是一個封裝了節點指針的類,類里面放了節點指針,也就是_node,現在把他拿出來才可以進行找prev和next的操作,因為只有ListNode才有prev和next,迭代器只是ListNode*的一個盒子
erase
別忘了改變指向后還要delete

delete的是cur,而不是pos,我們不是delete外面的那個盒子,而是那個節點
pos已經被erase了
這個地方要小心迭代器失效的問題
所以我們要返回next(利用next構造一個next迭代器回去)
push_front和push_back
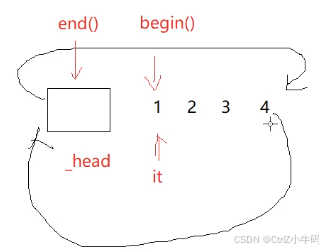


pop_back和pop_front

這個地方用--不要用-1,因為我們只提供了operator--沒有提供operator-

然后我們就可以用范圍for了
 (因為底層被替換成迭代器了)
(因為底層被替換成迭代器了)
size
兩種方案
- 每一次調用size()的時候都遍歷一遍(庫里是這樣實現的)
- 加一個成員變量size_t size;每次創建節點的時候都size++,減少的時候就--(這個地方不是用靜態成員變量,因為每個鏈表的長度都不一樣,靜態成員變量倒是可以記錄一共創建了多少個鏈表,但絕對不是這里)(我們實現這個)
- 成員變量加上_size
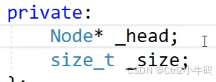
- size方法直接返回成員變量_size

- 初始化的時候賦值0?

- 每次插入的時候都++
- 每次刪除的時候都--

empty

因為我們實現了_size,所以我們就直接看_size就好
也可以用_head來用
resize
這個我們就不寫了,因為鏈表沒有容量的概念,所以基本上就是n比size大,就往后尾插一堆,n比size小,就尾刪一堆
假如說我們的鏈表要存儲自定義類型


匿名對象
有名對象
多參數構造的隱式類型轉換
C++11特有的:{}多參數的構造函數也支持隱式類型轉換了,用花括號(這個地方不是initailizer_list類型)
但是這樣子沒辦法遍歷
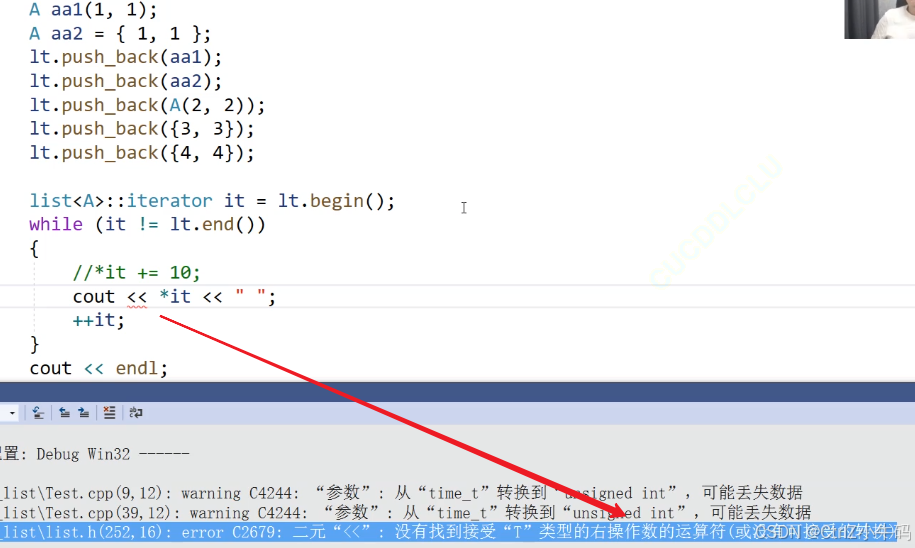
這里是說<<不支持A類型使用
因為我們的A類型里面沒有寫

但如果對方不想寫operator<<怎么解決
如果對方是公有的,我們就自己拿
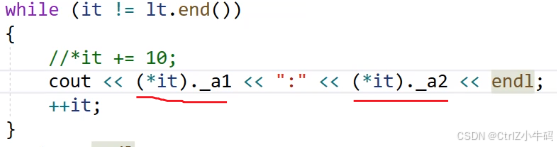
但是這個地方怎么看怎么別扭,因為我們的迭代器的目標是模擬當前類型的指針,既然是指針,肯定就應該能像下面這樣直接用箭頭訪問

所以我們還可以重載一個operator->
operator->
返回的是那個T類型的值的指針
這個地方會很詭異
如果用替換的方法的話,替換出來應該是A*a1,問題是A*是怎么直接啥都不用就可以訪問a1的呢?
答:這個地方隱藏了一個箭頭,編譯器為了可讀性省略了一個箭頭

也可以不省略寫,都一樣

我們要把it當成A*來設計,迭代器就是模擬的T*
外面的箱子iterator里面放了一個小箱子A,從小箱子里面取一個物品_a1
我們用迭代器的時候就是希望直接通過->取_a1,所以operator->和operator*都是要跨兩層的
const迭代器
如果直接在原本的begin或者end那個前面加上const,是沒辦法解決問題的
如果只是讀的話那還好,因為非const的成員用const迭代器是權限的縮小,所以也可以用
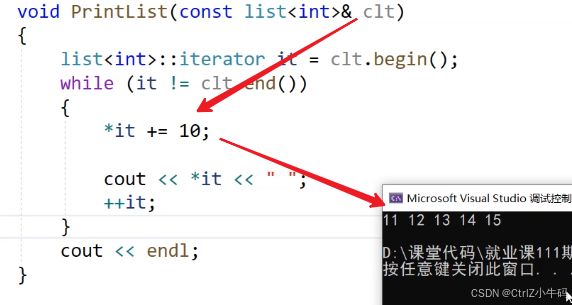
我是一個const的鏈表,但是你通過非const的迭代器修改了我的值
罪魁禍首就是那個加了const的begin和end,原本迭代器是沒辦法去接收const成員的迭代器的,因為const成員不給你begin你就沒轍
但是加了const之后,const成員也可以給你begin了,而你卻只是一個普通迭代器而不是const迭代器,所以普通迭代器肯定可以修改
 (const鏈表調用之后返回了普通迭代器)
(const鏈表調用之后返回了普通迭代器)
因此我們需要增加一個可以返回const迭代器的重載版本,然后普通的鏈表就會調用普通迭代器,const的鏈表就會調用const迭代器
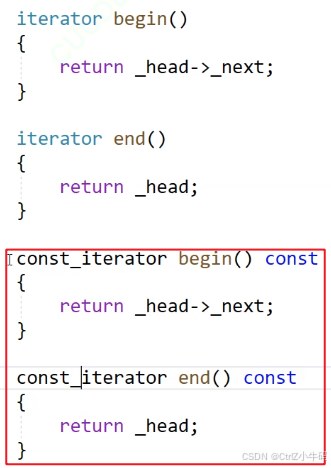
問:為什么不能寫成這樣?
答:上面寫的const?iterator是指本身這個iterator不能被修改
而const_iterator是指迭代器指向的內容不能被修改;
況且,iterator是一個類,如果說用const了這個類,就代表這他連++都調用不了了,因為類的那些成員不能被修改
所以我們得自己實現一個const_iterator類,讓迭代器本身可以修改,但是指向的內容不能修改
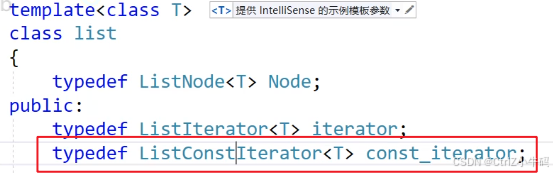
我們需要解決的問題
- *it += 10不能操作
- clt.begin()返回的是const_iterator
這個地方可以干脆直接把原本的iterator給拷貝一下,稍微修改一些功能,讓前面的兩點功能能夠實現
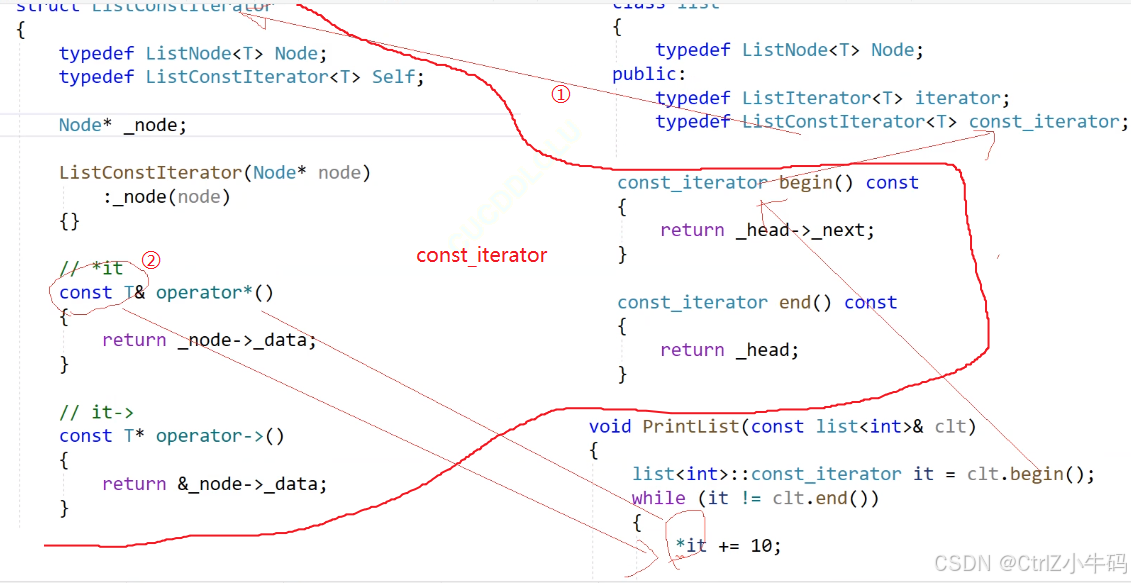
const_iterator就是一個普通 iterator的一個cv版本,只是修改一下名字,以及處理一下寫方面的東西
就是因為cv版本,所以兩個感覺有些冗余了,所以接下來的目的就是解決這個冗余
解決冗余(加模板)
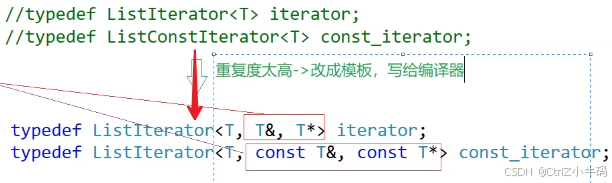
就這兩個返回值不同
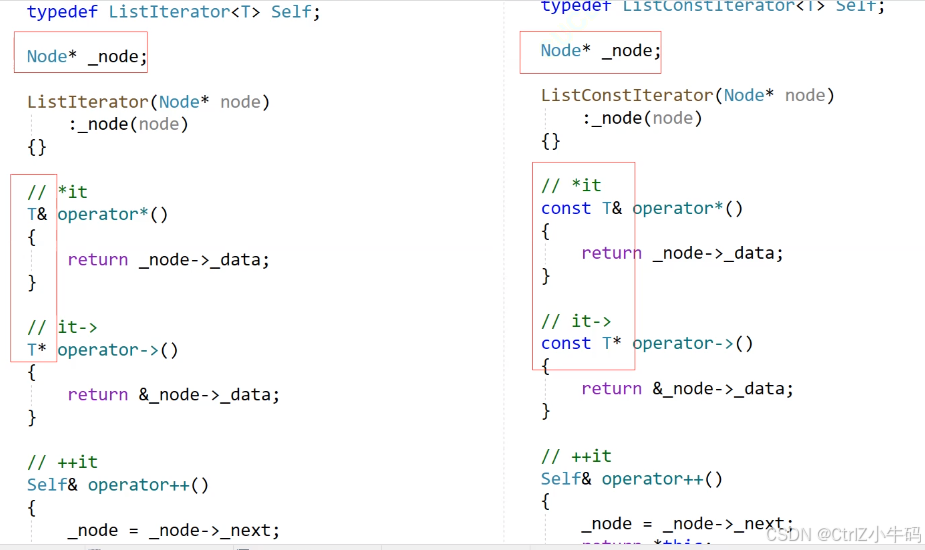
想辦法合并,用模板,用一個模板參數來控制

模板參數傳引用、傳指針
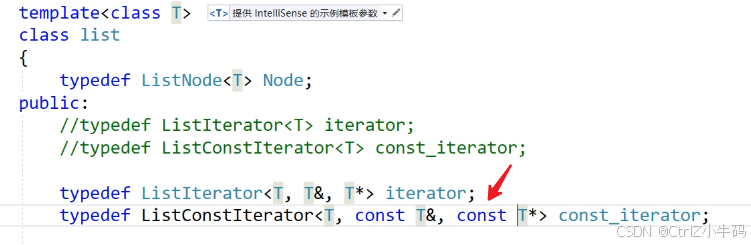
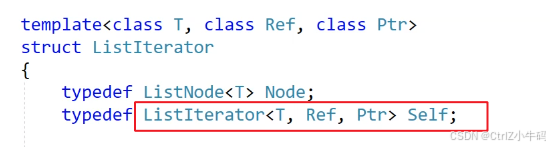

在這個地方,只要傳一個T過去就可以了,另外兩個會根據T而改變
本質上我們寫了一個類模板
編譯器實例化生成了兩個類
- 如果說我們搞的是const的鏈表,那我們在使用迭代器的時候就要用const_iterator,然后const_iterator會根據你的T類型,編譯器生成各種const T&?和const T*的迭代器,然后當我們進行*it+=10的時候,會因為*it?返回的是const的T&而報錯
- 如果說我們搞的是普通鏈表,那我們在使用迭代器的時候就要用iterator,然后iterator會根據你的T類型,編譯器生成各種T&?和T*的迭代器,然后當我們進行*it+=10的時候,就可以修改了
小小收個尾
還沒有銷毀鏈表
~list和clear

原本因為erase搞了之后,會迭代器失效,但是因為我們的erase返回了下一個迭代器,所以就可以這樣
其實這個應該叫clear

但是這個it是到end就停下來,也就是說頭結點沒有被釋放
所以說~list應該這樣寫

拷貝構造
默認的拷貝構造是一個淺拷貝,其中一個析構,另一個就全是野指針了
所以我們要自己實現
我們可以增加一個empty_init(其實就是把無參構造的內容給單獨拿出來了)


這樣會比較方便拷貝構造(因為在pushback的前提是有個哨兵位頭結點)
拷貝邏輯:遍歷另一個鏈表,然后全部插入
T有可能是string,所以auto要加上引用

鏈表的賦值
順便也把swap給搞了
swap邏輯:交換成員
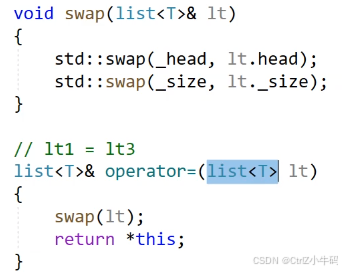
技巧:

因為需要析構,就是申請了資源的,有資源的肯定就是指針指向那個資源,然后就需要深拷貝的了




)




![[CH582M入門第十一步]DS18B20驅動](http://pic.xiahunao.cn/[CH582M入門第十一步]DS18B20驅動)









