目錄
一、案例總結
1、基礎知識
(1)第1章 通向智能安全的旅程
(2)第2章 打造機器學習工具箱
(3)第3章 機器學習概述
(4)第4章 Web安全基礎
2、安全案例
(1)第5章 K近鄰算法(KNN)
(2)第6章 決策樹與隨機森林
(3)第7章 樸素貝葉斯算法
(4)第8章 邏輯回歸
(5)第9章 支持向量機(SVM)
(6)第10章 K-Means與DBSCAN
(7)第11章 Apriori與FP-growth算法
(8)第12章 隱馬爾可夫模型
(9)第13章 圖算法與知識圖譜
(10)第14章 神經網絡
(11)第15章 多層感知機與DNN算法
(12)第16章 循環神經網絡算法
(13)第17章 卷積神經網絡算法
二、源碼部分
本文是《Web安全之機器學習入門》的讀書筆記總結,這本書涵蓋Webshell檢測、用戶異常操作檢測、DGA域名檢測、垃圾郵件/垃圾短信等場景,結合實戰案例講解如何用機器學習和深度學習模型(CNN、RNN等)解決網絡安全難題。
- 第1-4?章為基礎內容,主要講解機器學習和web安全基礎知識、以開發環境的搭建等內容。
- 第5-15章深入講解機器學習和深度學習在網絡安全的應用,書中案例豐富且具實踐價值。
總體來講,本書提供了大量機器學習算法在網絡安全中的實踐案例,適合AI安全入門者。只這本書是理論講解的比較淺,代碼同樣講解不夠深入,好在提供了源碼可以讓讀者復現,但是這本書是基于python2開發,在現在python3為主流開發環境的今天需要修改才可能跑通程序,會稍微麻煩些,我在調試代碼上就花費了大量時間。
一、案例總結
1、基礎知識
(1)第1章 通向智能安全的旅程
本章闡述了人工智能(AI)、機器學習(ML)與深度學習(DL)的關聯,講解人工智能的發展歷程及其在網絡安全領域的應用場景,同時本章節以2015年Kaggle發起的惡意代碼分類比賽為例,分析了冠軍隊伍選取的三個特征,分別是惡意代碼圖像、OpCode N-gram以及Headers的個數等,其檢測效果超過傳統的惡意軟件檢測方式。
(2)第2章 打造機器學習工具箱
這一張主要講解如何搭建python環境,如何搭建Scikit-Learn和TensorFlow、Anaconda配置方法等。當然此時不能完全按照書中的python庫版本安裝,因為書中使用的python2環境,比如書中的numpy版本是>1.6。如果真的想調通書中配套代碼,還是建議大家不要特意為此安裝python2,建議將代碼改為python3環境 。這本書出版于2017年主要的開發環境用的還是Scikit-Learn和TensorFlow,當前比較主流的環境是pytorch和Keras。
(3)第3章 機器學習概述
本章節淺淺的講解機器學習的原理,包括監督學習(如分類、回歸)與無監督學習(如聚類)的核心概念,并引入評估指標(準確率、召回率),還提到了自然語言特征提取的相關理論。因此,閱讀本書建議具備人工智能(含機器學習、深度學習、自然語言處理)基礎,否則可能會感到些許吃力。
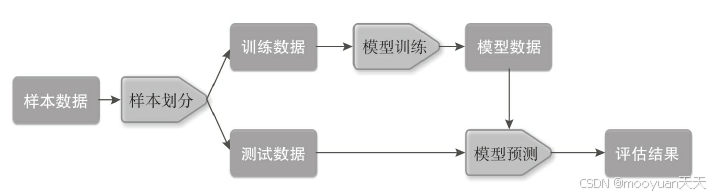
此外,本章還介紹了本文使用的數據集,包括涵蓋 KDD99 入侵檢測數據集、SEA 用戶行為異常數據集、ADFA-LA入侵檢測數據集等。這部分內容是前四章中較為出色的部分,當然,若能闡述得更詳盡些,效果會更好。
- KDD Cup 1999:這是網絡安全領域的經典數據集,源于第三屆國際知識發現和數據挖掘工具競賽,與 KDD - 99 第五屆知識發現和數據挖掘國際會議同期。其構建目的是打造能區分正常與入侵連接的網絡入侵檢測器,數據庫中的標準數據模擬了軍事網絡環境里的多樣入侵,像 back dos、ipsweep probe 等多種攻擊類型均包含其中。
- HTTP DATASET CSIC 2010:由 CSIC(西班牙國家研究委員會)的 “信息安全研究所” 開發,涵蓋自動生成的數千個 web 請求,可用于測試 web 攻擊防護系統。其流量針對電子商務 web 應用程序生成,用戶能在該程序中購物、注冊。此數據集中包含西班牙語字符,共有 36000 個正常請求與 25000 多個異常請求,涉及 SQL 注入、XSS 等多種攻擊類型 。
- SEA 用戶行為異常數據集:該數據集聚焦于用戶行為的異常檢測,涵蓋豐富多樣的用戶行為數據,包括用戶操作序列、訪問時間、訪問頻率等多維度信息。這些數據源于對大量用戶日常行為的長期監測與收集,能有效反映正常行為模式及各類異常行為的特征。通過對這些數據的分析與挖掘,可助力構建精準的用戶行為異常檢測模型,廣泛應用于網絡安全領域的用戶賬號異常檢測、內部威脅發現等場景,為及時識別潛在安全風險提供有力支持 。
- ADFA - LD 數據集:由澳大利亞國防學院發布,是一套主機級入侵檢測數據集合,包含 Linux 系統相關數據 。其主機配置具有代表性,如采用 Ubuntu Linux version 11.04 系統,開啟 Apache2.2.17、php5.3.5 、ftp、ssh、mysql14.14 等服務且使用默認端口,并部署存在已知遠程 php 代碼注入漏洞的 Tikiwiki8.1 。該數據集涵蓋 6 種攻擊類型,如 ftp 和 ssh 服務的暴力猜解密碼攻擊等。數據集中的每個數據文件都獨立記錄一段時間內的系統調用順序,且各類系統調用已完成特征化,并針對攻擊類型進行標注,常用于入侵檢測類產品的測試與研究 。
- Alexa 域名數據集:由 Corley 等人引入,由排名前 100 萬的網站的 URL 組成。這些域名依據 Alexa 流量排名進行排序,排名綜合考量了網站用戶的瀏覽行為、獨立訪客數量以及頁面瀏覽量。其中,獨立訪客指特定日期訪問網站的唯一用戶數量,頁面瀏覽量是用戶對網站 URL 的總請求數,同一網站同一天的多次請求計為一次頁面瀏覽量。在該數據集中,獨立訪客和頁面瀏覽量綜合最高的網站排名最靠前,常被用于網絡分析、搜索引擎優化以及研究網站流量分布等相關領域 。
- Scikit - Learn 數據集:Scikit - learn 庫提供了豐富的數據集,可分為幾類。一是 Toy datasets(玩具數據集),如鳶尾花、糖尿病、手寫數字、葡萄酒、威斯康星乳腺癌等數據集,這些是小型標準數據集,無需從外部網站下載文件,可通過 datasets.load_xx () 便捷加載,常用于快速展示 Scikit - learn 中各類算法的運行效果,但規模較小,對現實世界機器學習任務的代表性有限 。二是 Real world datasets(真實世界數據集),像新聞組(20 Newsgroups)數據集,需通過 sklearn.datasets.fetch_<name>函數從網絡下載,適用于更復雜的機器學習任務 。此外,還有 Generated datasets(生成數據集),可通過 make_classification、make_regression 等函數按用戶指定參數生成用于分類、回歸等任務的數據集 。這些數據集為機器學習算法的開發、測試與比較提供了多樣化的數據來源 。
- Mnist 數據集:是一個經典的用于圖像識別的數據集,由手寫數字的圖像組成。數據集中包含 10 個類別,分別對應數字 0 - 9。圖像經過預處理,被轉換為標準化的位圖形式。其構建過程中,從預印表格中提取手寫數字的歸一化位圖,參與人員共 43 人,其中 30 人貢獻數據用于訓練集,13 人貢獻數據用于測試集 。圖像被劃分為 32x32 的位圖,進一步分割為不重疊的 4x4 塊,并統計每個塊中的像素點亮數,生成 8x8 的輸入矩陣,矩陣元素取值范圍為 0 - 16,這一處理既降低了維度,又使數據對小的圖像變形具有不變性,在數字識別的模型訓練與評估等方面應用廣泛 。
- Movie Review Data 數據集(1000 正面,1000 負面):該數據集專門用于文本情感分析任務,包含 1000 條正面電影評論和 1000 條負面電影評論。評論內容涵蓋電影的劇情、表演、畫面、音效等多個方面的評價。這些評論來源于真實的用戶反饋,能直觀反映大眾對電影的情感傾向。通過對該數據集的學習與分析,可訓練出能夠準確判斷電影評論情感極性(正面或負面)的模型,在電影口碑分析、推薦系統以及電影產業的市場調研等方面發揮重要作用 。
- SpamBase 數據集:該數據集主要用于垃圾郵件檢測研究。每一條數據記錄都包含了郵件的多個特征信息,如郵件中出現的特定字符頻率、詞語頻率、郵件格式相關特征等共計 57 個特征,最后一列為標簽,用于標識該郵件是否為垃圾郵件(1 表示是垃圾郵件,0 表示正常郵件) 。通過對這些特征的分析和模型訓練,可以構建有效的垃圾郵件分類模型,幫助過濾掉大量無用的垃圾郵件,提高郵件系統的使用效率和用戶體驗 。
- Enron 數據集:這是一個與安然公司相關的數據集,包含了大量與安然公司運營、財務、通信等方面相關的數據。其中可能包括公司內部郵件往來記錄、財務報表數據、業務合同信息等 。在網絡安全領域,可利用該數據集研究企業內部網絡安全風險,例如通過分析郵件數據檢測釣魚郵件攻擊、識別內部人員的異常行為等;在金融領域,可用于財務欺詐檢測等研究,為多領域的分析與決策提供豐富的數據支持 。
(4)第4章 Web安全基礎
本章簡要介紹了 Web 安全的部分攻擊場景,包括 XSS 攻擊、SQL 注入、WebShell、僵尸網絡等常見攻擊的原理,對部分場景下攻擊載荷的構造方式也做了簡單說明。這部分內容的講解同樣較為淺顯,例如 4.3 節的 WebShell 部分僅給出了載荷,卻未解釋其具體含義,若不是該領域從業者,理解起來會有較大難度。這部分內容需要一定網絡安全基礎,否則僅看本書第 4 章可能會感到困惑。由于本書本身圍繞 Web 安全展開,相信多數讀者具備相關基礎,有基礎的話讀起來會十分易懂。
2、安全案例
(1)第5章 K近鄰算法(KNN)
本章講解K近鄰(KNN)算法的原理與其在網絡安全中的應用,包括檢測UNIX異常操作、檢測Rookit、檢測Webshell等案例,具體如下所示。
《Web安全之機器學習入門》筆記:第五章 5.2 決策樹K近鄰
《Web安全之機器學習入門》筆記:第五章 5.3 K近鄰檢測異常操作(一)
《Web安全之機器學習入門》筆記:第五章 5.4 K近鄰檢測異常操作(二)
《Web安全之機器學習入門》筆記:第五章 5.5 K近鄰檢測Rootkit
《Web安全之機器學習入門》筆記:第五章 5.6 K近鄰檢測WebShell
(2)第6章 決策樹與隨機森林
本文講解機器學習算法中的決策樹與隨機森林的原理以及其在網絡安全中的應用案例,包括POP3/FTP暴力破解檢測、FTP暴力破解攻擊檢測等案例。
《Web安全之機器學習入門》筆記:第六章 6.2 決策樹hello world
《Web安全之機器學習入門》筆記:第六章 6.3決策樹檢測POP3暴力破解
《Web安全之機器學習入門》筆記:第六章 6.4決策樹檢測ftp暴力破解
《Web安全之機器學習入門》筆記:第六章 6.5隨機森林檢測POP3暴力破解
《Web安全之機器學習入門》筆記:第六章 6.6隨機森林檢測FTP暴力破解
(3)第7章 樸素貝葉斯算法
本文講解樸素貝葉斯NB算法的原理以及在網絡安全中的應用案例,包括檢測異常操作、檢測WebShell、檢測DDoS攻擊檢測等案例,具體如下所示。
《Web安全之機器學習入門》筆記:第七章 7.2樸素貝葉斯hello world
《Web安全之機器學習入門》筆記:第七章 7.3樸素貝葉斯檢測異常操作
《Web安全之機器學習入門》筆記:第七章 7.4樸素貝葉斯檢測WebShell(一)
《Web安全之機器學習入門》筆記:第七章 7.5樸素貝葉斯檢測WebShell(二)
《Web安全之機器學習入門》筆記:第七章 7.6樸素貝葉斯檢測DGA域名
《Web安全之機器學習入門》筆記:第七章 7.7 樸素貝葉斯檢測對Apache的DDoS攻擊
《Web安全之機器學習入門》筆記:第七章 7.8 樸素貝葉斯識別mnist驗證碼
(4)第8章 邏輯回歸
本文講解邏輯回歸算法的原理以及在網絡安全中的應用案例,包括檢測Java溢出攻擊以及識別MNIST驗證碼等案例,具體如下所示。
《Web安全之機器學習入門》筆記:第八章 8.2 邏輯回歸hello world
《Web安全之機器學習入門》筆記:第八章 8.3 邏輯回歸算法檢測Java溢出攻擊
《Web安全之機器學習入門》筆記:第八章 8.4 邏輯回歸算法識別mnist驗證碼
(5)第9章 支持向量機(SVM)
本章講解SVM算法的原理和其在網絡安全中的應用場景,案例包括XSS攻擊識別(URL特征提取)和DGA域名分類(Jaccard系數特征)。
《Web安全之機器學習入門》筆記:第九章 9.2 支持向量機SVM hello world
《Web安全之機器學習入門》筆記:第九章 9.3 支持向量機算法SVM 檢測XSS攻擊
《Web安全之機器學習入門》筆記:第九章 9.4 支持向量機算法SVM 檢測DGA域名
(6)第10章 K-Means與DBSCAN
本章節講解無監督算法K-Means與DBSCAN,并講解KMeans算法在DGA域名聚類的應用,具體如下所示。
《Web安全之機器學習入門》筆記:第十章 10.2 K-Means hello world
《Web安全之機器學習入門》筆記:第十章 10.3 K-Means算法檢測DGA域名
《Web安全之機器學習入門》筆記:第十章 10.5 DBSCAN hello world
(7)第11章 Apriori與FP-growth算法
本章系統講解兩種關聯規則算法在Web攻擊檢測中的應用(挖掘XSS攻擊樣本潛在關系,挖掘疑似僵尸主機),具體如下所示。
《Web安全之機器學習入門》筆記:第十一章 11.2 Apriori算法
《Web安全之機器學習入門》筆記:第十一章 11.3 Apriori算法挖掘XSS相關參數
《Web安全之機器學習入門》筆記:第十一章 11.5 Fp-growth算法
《Web安全之機器學習入門》筆記:第十一章 11.6 Fp-growth算法挖掘僵尸主機
(8)第12章 隱馬爾可夫模型
本章節講解通過馬爾可夫挖掘時序數據的關系,介紹馬爾科夫的概念以及如何識別XSS攻擊和DGA域名,具體如下所示。
《Web安全之機器學習入門》筆記:第十二章 12.2 隱式馬爾可夫
《Web安全之機器學習入門》筆記:第十二章 12.3 隱式馬爾可夫算法識別XSS攻擊(一)
《Web安全之機器學習入門》筆記:第十二章 12.4 隱式馬爾可夫算法識別XSS攻擊(二)
《Web安全之機器學習入門》筆記:第十二章 12.5 隱式馬爾可夫算法識別DGA域名
(9)第13章 圖算法與知識圖譜
本章講解圖算法與知識圖譜,并通過多個案例講解其在網絡安全中的應用,具體如下所示。
《Web安全之機器學習入門》筆記:第十三章 13.2 有向圖 hello world
《Web安全之機器學習入門》筆記:第十三章 13.3 有向圖識別WebShell
《Web安全之機器學習入門》筆記:第十三章 13.4 有向圖識別僵尸網絡
《Web安全之機器學習入門》筆記:第十三章 13.5 知識圖譜 hello world
《Web安全之機器學習入門》筆記:第十三章 13.6 知識圖譜在風控領域的應用
《Web安全之機器學習入門》筆記:第十三章 13.7 知識圖譜在威脅情報領域的應用
(10)第14章 神經網絡
本章節講解神經網絡的理論與案例,通過識別MNIST驗證碼和檢測JAVA兩個案例講解神經網絡的實踐案例,具體如下所示。
《Web安全之機器學習入門》筆記:第十四章 14.3 神經網絡識別驗證碼
《Web安全之機器學習入門》筆記:第十四章 14.4 神經網絡算法檢測JAVA溢出攻擊
(11)第15章 多層感知機與DNN算法
深入講解隱藏層大于1的神經網絡模型,通過多層感知機和DNN來識別MNIST數字以及檢測垃圾郵件,具體如下所示。
《Web安全之機器學習入門》筆記:第十五章 15.4 TensorFlow識別驗證碼(一)
《Web安全之機器學習入門》筆記:第十五章 15.5 TensorFlow多層感知機識別驗證碼(二)
《Web安全之機器學習入門》筆記:第十五章 15.6 TensorFlow DNN識別驗證碼(三)
《Web安全之機器學習入門》筆記:第十五章 15.7與15.8 TensorFlow識別垃圾郵件
(12)第16章 循環神經網絡算法
本章節講解循環神經網絡在網絡安全領域的應用,處理有時序特點的數據集,包括識別驗證碼(基于MNIST數據集)、識別惡意負面評論(Movie Review Data 數據集)、學習城市的名稱從而自動生成城市的名稱、識別Webshell、通過學習常用密碼自動生成常用密碼、識別異常操作(SEA數據集)。
《Web安全之機器學習入門》筆記:第十六章 16.2 DNN和RNN識別驗證碼
《Web安全之機器學習入門》筆記:第十六章 16.3 惡意評論識別(一)
《Web安全之機器學習入門》筆記:第十六章 16.3 惡意評論識別(二)
《Web安全之機器學習入門》筆記:第十六章 16.4 生成城市名稱
《Web安全之機器學習入門》筆記:第十六章 16.5 識別WebShell
《Web安全之機器學習入門》筆記:第十六章 16.6 生成常用密碼
《Web安全之機器學習入門》筆記:第十六章 16.7 識別異常操作
(13)第17章 卷積神經網絡算法
本章講解卷積神經網絡CNN的基本概念,本章的卷積神經網絡算法與第14章神經網絡的區別在于兩者的模型不同,具體如下所示。
| 對比維度 | MLP(多層感知機) | CNN(卷積神經網絡) |
|---|---|---|
| 網絡結構 | 全連接層堆疊,無空間結構保留 | 卷積層+池化層交替,保留輸入的空間/時序結構 |
| 參數共享 | 無參數共享,參數量大(輸入維度×神經元數) | 卷積核權重共享,參數量小(與輸入尺寸無關) |
| 特征提取 | 顯式學習全局特征,需人工特征工程 | 自動提取局部特征(如邊緣、紋理),具有平移不變性 |
| 輸入要求 | 需展平(Flatten)為一維向量,丟失空間信息 | 直接處理多維數據(如圖像H×W×C、時序序列) |
| 應用場景 | 結構化數據(表格數據、數值特征) | 非結構化數據(圖像、視頻、音頻、文本時序) |
| 計算效率 | 高計算成本(參數量大) | 參數高效,適合大規模數據 |
| 空間處理 | 無法自動捕捉局部模式 | 通過卷積核捕捉局部空間/時序模式 |
本章節涉及到3個案例,通過案例講解如何用CNN識別驗證碼、惡意評論和垃圾郵件。?
《Web安全之機器學習入門》筆記:第十七章 17.2 卷積神經網絡CNN識別驗證碼
《Web安全之機器學習入門》筆記:第十七章 17.3 卷積神經網絡CNN識別惡意評論
《Web安全之機器學習入門》筆記:第十七章 17.4 卷積神經網絡CNN識別垃圾郵件
二、源碼部分
這本書的源碼是本書原始代碼基于Python 2.7環境開發,而當前主流技術棧已全面轉向Python 3.x版本。這個代碼基本上想調試成功每個章節的每個源碼都需要修改(python2改為python3),要有這個心理準備,并不是代碼一跑就直接通了,除了python2和python3的核心語法變化導致需要修改代碼外;很多庫文件由于基于老的版本,還會有依賴庫兼容性問題,比如部分示例使用的第三方庫已停止維護。整體來講需要改很多代碼,比較麻煩。
?對于python2的code,由于當前主流技術棧已全面轉向Python 3.x版本,想調試成功code要將《Web安全之機器學習入門》書中Python 2環境代碼轉換為Python 3代碼,可以使用Python自帶的2to3工具,具體方法如下所示。
(1)對于單個Python文件
2to3 -w 原文件.py(2)對于整個目錄
2to3 -w 目錄路徑/

安裝 Docker 容器完整教程)



完全指南)
)


![[simdjson] document_stream | iterate_many() | batch_size | 線程加速 | 輕量handle](http://pic.xiahunao.cn/[simdjson] document_stream | iterate_many() | batch_size | 線程加速 | 輕量handle)

- 數據渲染與顯示之首頁)






