第七章:文檔流
歡迎回來
在前面的章節中,我們學習了如何使用解析器結合填充字符串獲取表示JSON根節點的文檔,并通過按需API(On-Demand API)遍歷值、對象和數組,同時使用simdjson_result進行錯誤處理。
到目前為止,我們專注于逐個解析單個JSON文檔。
但如果需要處理包含多個連續JSON文檔的大型文件或網絡流呢?
常見格式如NDJSON(換行符分隔的JSON)或JSON Lines,其中每行都是完整且有效的JSON文檔。
例如:
{"user":"Alice", "id":1}
{"user":"Bob", "id":2}
{"user":"Charlie", "id":3}
...(可能有數百萬行)
將整個文件加載到內存逐個解析會非常低效且消耗大量內存。這正是文檔流抽象要解決的問題。
什么是文檔流?
simdjson::ondemand::document_stream(DOM API對應simdjson::dom::document_stream,但我們聚焦按需API的iterate_many)旨在高效處理包含多個JSON文檔的大型輸入。
-
不同于逐個提供文檔字符串,
iterate_many(DOM API用parse_many)一次性接收整個緩沖區或文件內容。 -
iterate_many不會立即解析所有內容,而是建立內部機制,在迭代流時逐個查找并解析文檔。
想象成傳送帶:將整個大型容器裝載到傳送帶(iterate_many),然后逐個處理到達面前的物品(循環遍歷document_stream)。無需同時存儲所有物品,只需處理當前項。
這種方法有兩大優勢:
- 內存高效:無需同時加載整個GB級流到內存(盡管需要初始大緩沖區)。解析器為每個文檔
復用內部緩沖區。 - 高性能:Simdjson可用高速方法處理流塊。按需API甚至能用
后臺線程在您處理當前文檔時查找下一個文檔!
獲取文檔流
通過simdjson::ondemand::parser實例的iterate_many()方法獲取document_stream。
鏈接:https://github.com/simdjson/simdjson/blob/master/doc/iterate_many.md
iterate_many()參數通常包括:
- 填充JSON數據緩沖區指針(
const uint8_t*或padded_string) - 數據長度(
size_t) - 可選的
batch_size(后續討論) - 可選的允許逗號分隔文檔標志(NDJSON/JSONL不常用)
與其他simdjson操作類似,iterate_many()返回simdjson_result<simdjson::ondemand::document_stream>。使用流前必須檢查結果是否有錯誤。
以下為示例NDJSON數據處理:
#include <simdjson.h>
#include <iostream>int main() {// 假設從大文件讀取的NDJSON數據simdjson::padded_string ndjson_data = R"({"user":"Alice", "id":1}{"user":"Bob", "id":2}{"user":"Charlie", "id":3})"_padded; // _padded確保填充simdjson::ondemand::parser parser;// 獲取文檔流simdjson::simdjson_result<simdjson::ondemand::document_stream> stream_result =parser.iterate_many(ndjson_data);// 檢查流設置是否成功if (stream_result.error()) {std::cerr << "文檔流設置錯誤: " << stream_result.error() << std::endl;return EXIT_FAILURE;}// 從結果中獲取document_stream對象simdjson::ondemand::document_stream doc_stream = std::move(stream_result.value());std::cout << "成功建立文檔流。" << std::endl;// 現在可以迭代流...(見下節)return EXIT_SUCCESS;
}
注意iterate_many接收包含所有JSON文檔的整個填充緩沖區。
迭代文檔流
simdjson::ondemand::document_stream設計用于基于范圍的for循環。循環中每個項是simdjson_result<simdjson::ondemand::document_reference>。
為什么用
document_reference而非document?
因為流為高效性復用解析器內部單個document對象。document_reference是輕量句柄,指向此內部可復用文檔對象。每次循環移動時,內部文檔對象更新為流中下一個JSON文檔。
#include <simdjson.h>
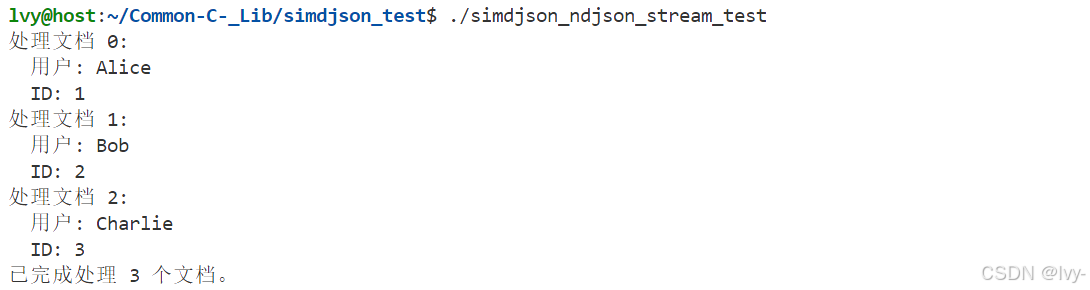
#include <iostream>int main() {simdjson::padded_string ndjson_data = R"({"user":"Alice", "id":1}{"user":"Bob", "id":2}{"user":"Charlie", "id":3})"_padded;simdjson::ondemand::parser parser;auto stream_result = parser.iterate_many(ndjson_data);if (stream_result.error()) {std::cerr << "文檔流設置錯誤: " << stream_result.error() << std::endl;return EXIT_FAILURE;}simdjson::ondemand::document_stream doc_stream = std::move(stream_result.value());// 遍歷流中每個文檔int doc_count = 0;for (auto doc_result : doc_stream) {// 每個'doc_result'是simdjson_result<simdjson::ondemand::document_reference>// 訪問文檔前檢查錯誤if (doc_result.error()) {std::cerr << "解析文檔" << doc_count << "錯誤: " << doc_result.error() << std::endl;// 可選擇繼續或停止continue; // 跳過損壞文檔}// 獲取文檔引用simdjson::ondemand::document_reference doc = doc_result.value();std::cout << "處理文檔 " << doc_count << ":" << std::endl;// 可像常規文檔一樣使用'doc'對象訪問字段auto user_result = doc["user"].get_string();if (!user_result.error()) {std::cout << " 用戶: " << user_result.value() << std::endl;} else {std::cerr << " 獲取用戶字段錯誤: " << user_result.error() << std::endl;}auto id_result = doc["id"].get_int64();if (!id_result.error()) {std::cout << " ID: " << id_result.value() << std::endl;} else {std::cerr << " 獲取ID字段錯誤: " << id_result.error() << std::endl;}doc_count++;}std::cout << "已完成處理 " << doc_count << " 個文檔。" << std::endl;// 'parser'和'ndjson_data'在循環期間需保持有效return EXIT_SUCCESS;
}
輸出:
此模式是使用
document_stream的核心。遍歷流時獲取當前JSON文檔句柄(document_reference),然后用標準按需API方法(get_object()、[]、get_string()等)處理。
錯誤處理至關重要。錯誤可能發生在流設置(stream_result.error())或循環內解析單個文檔時(doc_result.error()),均需檢查。
批處理大小與內存
調用iterate_many(buffer, len, batch_size)時,batch_size參數很重要。它定義simdjson初始結構分析(階段1)時處理的輸入緩沖區塊大小。
batch_size需大于流中最大單個JSON文檔。若文檔大于批處理大小,simdjson無法在單批次正確解析。- 更大
batch_size可能通過減少批次切換開銷提升性能,但需解析器分配足夠內存。 - 合理默認值通常為1MB,但可根據文檔大小調整。解析器容量需通過
parser.allocate()設置足夠大或自動擴展。
Simdjson讀取batch_size字節(或剩余字節),在階段1查找塊內所有文檔邊界,迭代時從該塊提供文檔。消耗完塊內文檔后加載下一批次。
線程加速
iterate_many的強大功能之一(當simdjson啟用線程時)是使用后臺線程重疊工作。
主線程處理當前批次文檔時(循環調用document_reference方法),工作線程可同時在后臺對下一批次數據執行階段1分析。
這種重疊意味著后續批次階段1的時間被"隱藏"在當前批次處理時間內。若單文檔處理時間足夠長,下批次階段1可能已完成,使階段1成本趨近于零!
(類似于 生產消費者模型的思想)
無需修改循環代碼即可啟用此功能。若simdjson編譯時啟用線程(SIMDJSON_THREADS_ENABLED),iterate_many會自動在適當時使用后臺線程。
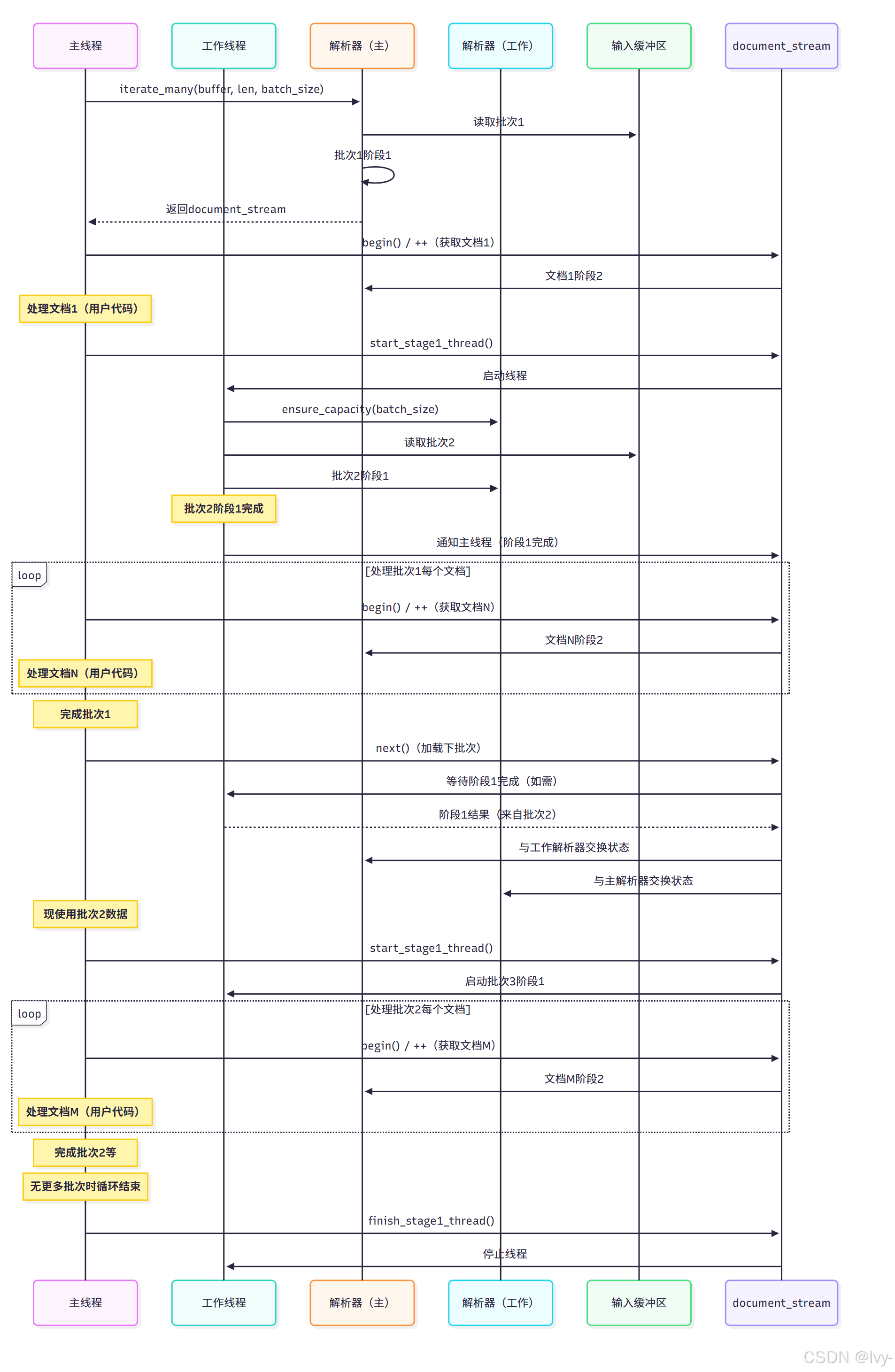
底層機制(簡化版)
document_stream對象管理輸入緩沖區、batch_size及跨文檔和批次的迭代狀態。包含:
- 原始輸入緩沖區指針及長度
- 主
simdjson::ondemand::parser指針 - 當前處理批次信息(起始位置
batch_start) - 跟蹤批次內當前文檔的內部狀態
- 啟用線程時管理
stage1_worker線程對象和輔助parser實例(stage1_thread_parser)
調用iterate_many(buffer, len, batch_size)時:
- 構建
document_stream對象,存儲緩沖區/長度/批次大小和解析器指針 - 啟動循環(
stream.begin())觸發初始處理:- 主解析器內部緩沖區可能調整以適應
batch_size - 用主解析器對輸入緩沖區第一個
batch_size字節執行階段1 - 設置初始
document句柄指向第一個文檔 - 啟用線程且有更多數據時,啟動工作線程對下一批次執行階段1
- 主解析器內部緩沖區可能調整以適應
- 循環內(
for (auto doc_result : doc_stream))document_reference包裝主解析器內部文檔狀態。對doc的操作(get_object()、[]等)執行當前文檔階段2解析 - 循環
++運算符移動至下一文檔時:- 主解析器內部迭代器跳過當前文檔
- 若迭代器到達當前批次末尾,檢查工作線程是否完成下一批次階段1
- 若下一批次階段1就緒,快速交換主解析器和工作解析器內部狀態。工作解析器成為新主解析器
- 禁用線程或工作線程未就緒時,主線程自行執行下一批次階段1
- 加載新批次后更新內部文檔句柄指向首文檔
- 無更多批次時結束流迭代
關鍵在于document_stream管理緩沖區塊和后臺階段1處理,通過迭代器接口逐個產出文檔。
高級:位置與截斷
如需更多控制或調試,document_stream::iterator(范圍for循環隱式使用)提供額外方法:
iterator::current_index() const:返回當前文檔在原始緩沖區的字節偏移,用于記錄錯誤或跟蹤大文件進度iterator::source() const:返回指向當前文檔原始字節的std::string_view(可能含周圍空白)iterator::error() const:返回當前文檔error_code
流迭代完成后,document_stream對象提供:
document_stream::truncated_bytes() const:返回緩沖區末尾無法解析為完整JSON文檔的字節數,用于檢測不完整輸入或尾部垃圾
逗號分隔文檔
默認iterate_many期望JSON空白分隔文檔。
若文檔用逗號分隔(如1, "hello", true, {}),可在iterate_many傳入allow_comma_separated參數為true。但此模式需整個輸入作為單批次處理(忽略batch_size)且禁用線程,不適合大規模流式處理。
總結
處理多JSON文檔大型文件(如NDJSON/JSON Lines)需內存高效方案。simdjson::ondemand::document_stream專為此設計:
- 通過
parser.iterate_many(padded_data, ...)獲取文檔流 - 用范圍for循環迭代流:
for (auto doc_result : stream) - 循環項是表示流中文檔的
simdjson_result<document_reference>,訪問前需檢查錯誤 batch_size參數控制階段1處理塊大小,應不小于最大文檔- 啟用線程時,
iterate_many可重疊下批次階段1與當前批次處理,極大提升吞吐 - 循環中
document_reference是輕量句柄,指向解析器復用內存
(通過指針移動,減少拷貝開銷和零碎內存)
使用document_stream可高效解析多文檔輸入,使simdjson成為處理流式JSON數據的利器。
掌握解析、數據處理、導航、錯誤處理和流處理后,我們已建立堅實基礎。下一章將揭秘simdjson通過實現/CPU派發機制實現高性能的奧秘。
下一章:實現/CPU派發
補充:
輕量句柄
輕量句柄是內存中對象的簡易引用,不直接存儲數據,僅指向已存在的資源(如解析后的文檔)。
循環中的document_reference作為輕量句柄,避免了重復解析,直接復用內存中的結果,節省計算開銷。
類似書簽標記書頁位置,書簽(輕量句柄)本身不是書頁內容,但能快速定位到已存在的頁面(內存數據)。
核心特點
- 低開銷:不復制數據,僅保存指向內存的指針或標識符。
- 高效復用:通過
引用共享已解析內容,避免重復處理。 - 無所有權:輕量句柄不管理資源生命周期,
需確保目標資源有效。
(通過指針移動,減少拷貝開銷和零碎內存)

- 數據渲染與顯示之首頁)










的心電圖分類的統一時頻方法)






庫和XPath 語法的使用)