??PaliGemma 2是輕量級開放式視覺語言模型 (VLM),靈感源自 PaLI-3,基于 SigLIP 視覺模型和 Gemma 語言模型等開放式組件。PaliGemma 同時接受圖片和文本作為輸入,并且可以回答有關圖片的詳細問題和背景信息。
PaliGemma 2 提供 30 億、100 億和 280 億個參數的大小,分別基于 Gemma 2 20 億、90 億和 270 億個參數的模型。三種參數規模(3B/10B/28B)、三種分辨率(224×224/448×448/896×896)。
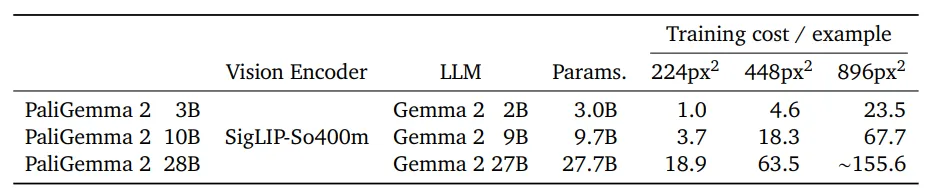
模型架構
??PaliGemma 2 由 Transformer 解碼器和 Vision Transformer 圖片編碼器組成。文本解碼器從 2B、9B 和 27B 參數大小的 Gemma 2 初始化。圖片編碼器從 SigLIP-So400m/14 初始化。與原始 PaliGemma 模型類似,PaLiGemma 2 是按照 PaLI-3 方案訓練的。
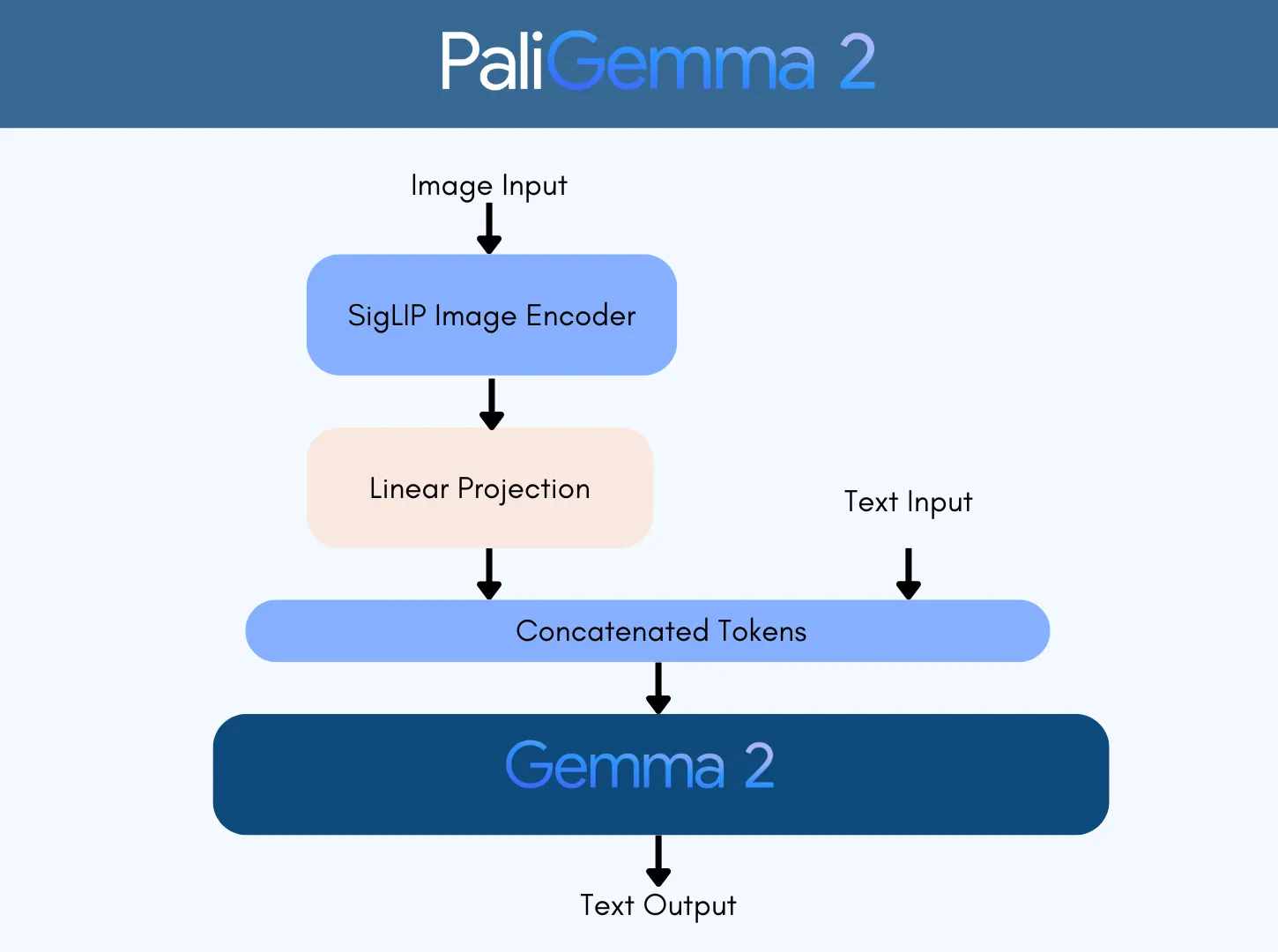
輸入和輸出
??● 輸入:圖片和文本字符串,例如用于為圖片添加說明的提示或問題。
● 輸出:針對輸入生成的文本,例如圖片的標題、問題的答案、對象邊界框坐標列表或分割代碼詞。
視覺編碼器
??SigLIP:其shape optimized ViT-So400m圖像編碼器,該模型通過sigmoid損失在大規模上進行了對比預訓練,且其在小尺寸上也表現出色。
輸入投影
??線性投影:將SigLIP的輸出到與gemma的詞匯token相同的維度,以便它們可以被連接。
LLM主干。
LLM主干
??Gemma2 10B:該模型可以匹配或超越使用相對更大些的語言模型的VLMs的性能,包括之前的PaLIs。
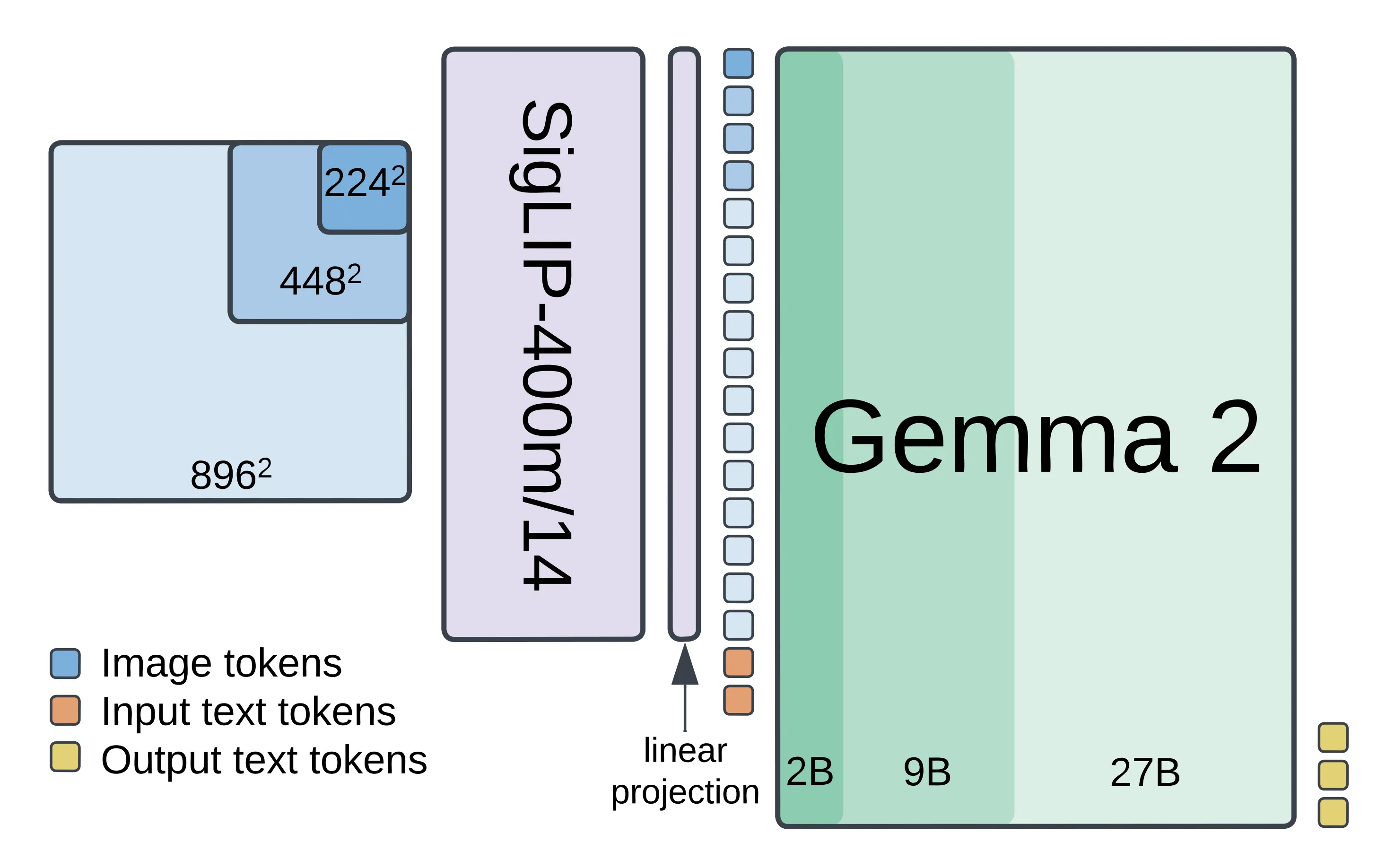
Finetune
不在這里








的工具選擇方式)
![[硬件電路-57]:根據電子元器件的受控程度,可以把電子元器件分為:不受控、半受控、完全受控三種大類](http://pic.xiahunao.cn/[硬件電路-57]:根據電子元器件的受控程度,可以把電子元器件分為:不受控、半受控、完全受控三種大類)






![[前端技術基礎]CSS選擇器沖突解決方法-由DeepSeek產生](http://pic.xiahunao.cn/[前端技術基礎]CSS選擇器沖突解決方法-由DeepSeek產生)

0.5.7.3版本)
)