Python爬取小紅書搜索關鍵詞下面的所有筆記的內容、點贊數量、評論數量等數據,繪制詞云圖、詞頻分析、數據分析
使用 Python 編寫一個簡單的爬蟲程序來從小紅書抓取與指定關鍵詞相關的筆記數據,并對這些數據進行基本的數據分析,包括詞云圖和柱狀圖的繪制。
配套視頻請看:配套視頻教程
完整程序源碼地址:完整程序源碼地址
本教程分為兩大部分:爬蟲部分 和 數據分析部分。
- 爬蟲部分:從指定關鍵詞的小紅書中獲取相關筆記的信息(如標題、鏈接、用戶信息、互動數據等),并保存為 CSV 文件。
- 數據分析部分:加載生成的 CSV 文件,進行文本清洗、分詞,然后生成詞云圖和柱狀圖以直觀展示數據特征。
必要的第三方庫
- Python
- Requests:發送 HTTP 請求
- execjs:執行 JavaScript 代碼(用于 js 逆向)
- json & csv:處理 JSON 數據和 CSV 文件寫入
- pandas: 數據處理
- jieba: 中文分詞
- matplotlib, wordcloud: 數據可視化
文件結構

爬蟲邏輯詳解
小紅書對請求有反爬機制,需要通過 Cookie 和 簽名來模擬合法請求。
獲取 Cookie 設置請求頭
- 打開 小紅書官網 并登錄。
- 在瀏覽器開發者工具中找到并復制請求頭中的 cookie 字段。
- 將獲取到的 cookie 替換到代碼中的相應位置。
- 根據需要修改 base_headers 中的 cookie 值。
base_headers = {"accept": "application/json, text/plain, */*","cookie": "your_cookie_here", # 替換為你自己的cookie...
}
使用 JavaScript 生成請求簽名
使用 execjs 調用本地的 xhs.js 文件完成簽名生成
xhs_sign_obj = execjs.compile(open('xhs.js', encoding='utf-8').read())
sign_header = xhs_sign_obj.call('sign', uri, data, base_headers.get('cookie', ''))
根據關鍵詞搜索筆記,遍歷多頁數據
def keyword_search(keyword):search_url = "https://edith.xiaohongshu.com/api/sns/web/v1/search/notes"page_count = 20 # 爬取的頁數, 一頁有 20 條筆記 最多只能爬取220條筆記for page in range(1, page_count + 1):data = {"ext_flags": [],"image_formats": ["jpg", "webp", "avif"],"keyword": keyword,"note_type": 0,"page": page,"page_size": 20,'search_id': xhs_sign_obj.call('searchId'),"sort": "general"}response = post_request(search_url, uri='/api/sns/web/v1/search/notes', data=data)json_data = response.json()try:notes = json_data['data']['items']except:print('================爬取完畢================')breakfor note in notes:note_id = note['id']xsec_token = note['xsec_token']if len(note_id) != 24:continueget_note_info(note_id, xsec_token)
獲取筆記詳情并保存
def get_note_info(note_id, xsec_token):note_url = 'https://edith.xiaohongshu.com/api/sns/web/v1/feed'data = {"source_note_id": note_id,"image_scenes": ["jpg", "webp", "avif"],"extra": {"need_body_topic": "1"},"xsec_token": xsec_token,"xsec_source": "pc_search"}response = post_request(note_url, uri='/api/sns/web/v1/feed', data=data)json_data = response.json()try:note_data = json_data['data']['items'][0]except:print(f'筆記 {note_id} 不允許查看')returnsave_data(note_data, note_id, xsec_token)
爬取關鍵詞相關的小紅書筆記
keyword_search(keyword)
數據分析邏輯詳解
加載數據由爬蟲程序生成的 CSV 文件。
import pandas as pddata = pd.read_csv(r'秋招和春招到底哪個機會多.csv')
對爬取到的數據進行去重、文本清洗和中文分詞。
xhs_content = data['筆記內容']
xhs_content = xhs_content.drop_duplicates()# 數據清洗
xhs_content = xhs_content.apply(clean_text)
# 對小紅書內容進行分詞
segment_list = segment_text(xhs_content)
利用 matplotlib 和 wordcloud 庫生成詞云圖和柱狀圖
# 繪制詞云圖
generate_wordcloud(segment_list)
# 繪制總的詞頻圖
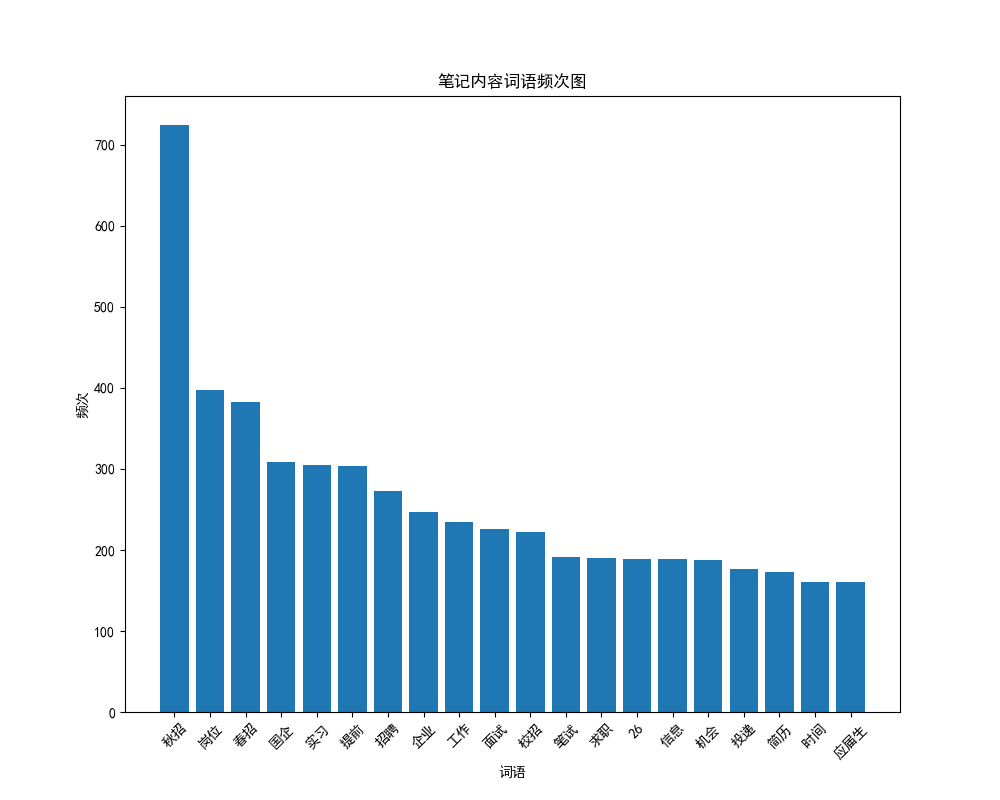
plot_word_frequency(segment_list)
繪圖結果如下:

其他繪圖:
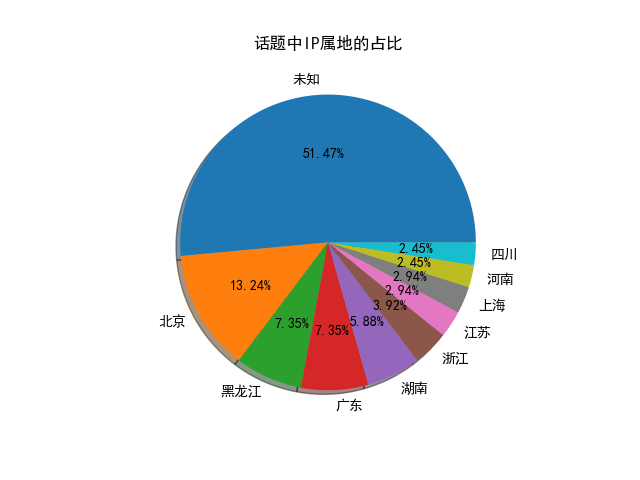
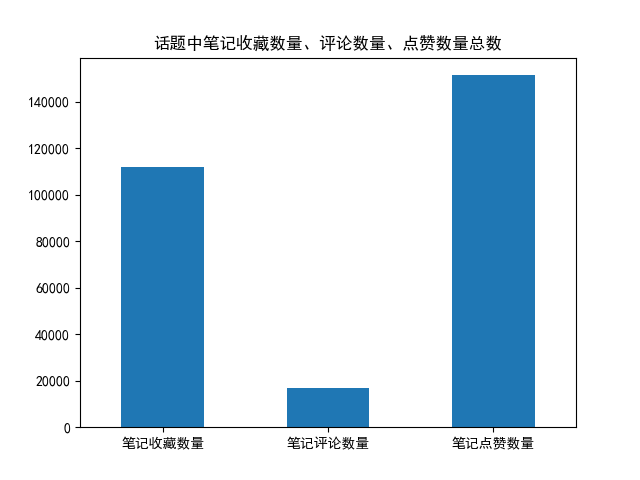






)




」2025年7月4日)







