第六章:信息檢索器
在上一章中,我們成功完成了知識庫攝入流程。這是巨大的進步~
我們精心準備了文檔"塊"(類似獨立的索引卡),并將其存儲在兩套智能歸檔系統中:向量數據庫(用于基于含義的搜索)和BM25索引(用于基于關鍵詞的搜索)。我們的"數字圖書館"現已完美組織就緒,隨時可被檢索。
但當用戶提出問題時會如何運作?例如,若用戶詢問:"公司Z在2023年關于營收和利潤的關鍵財務結果是什么?"我們的系統可能有數千甚至數百萬張索引卡。
它如何快速定位恰好包含答案的少數幾張,而不被無關信息干擾?
這正是信息檢索器的職責所在
信息檢索器解決什么問題?
想象我們身處龐大的數字圖書館,需要快速查找特定信息。我們不想逐本閱讀每本書籍,而是需要"超級管理員"或"搜索引擎"能立即指向最相關的頁面或段落。
挑戰在于:
- 理解問題:即使表述寬泛
- 掃描整個知識庫:遍歷所有存儲塊
- 尋找最佳匹配:識別最可能包含答案的塊
- 快速響應:在秒級而非分鐘級提供結果
信息檢索器組件即扮演這種"超級管理員"或"搜索引擎"角色。
當問題輸入時,它會查詢我們已建立的知識庫(向量和BM25),尋找可能包含答案的最相關文檔塊。該組件專為從海量數據中快速高效提取潛在答案而設計。
其核心角色可分解如下:
| 角色 | 類比 | 功能說明 |
|---|---|---|
| 超級管理員 | 快速定位正確書籍/頁面 | 接收問題并搜索"基于含義"(向量)和"基于關鍵詞"(BM25)的索引,尋找相關文檔塊 |
| 相關性評估器 | 判斷哪些信息最有幫助 | 使用高級算法(如向量搜索的余弦相似度、關鍵詞搜索的BM25評分)確定每個找到的塊與原始問題的相關度 |
| 數據提取器 | 提取潛在答案 | 檢索最相關塊的實際文本,附帶頁碼等輔助細節,供后續處理使用 |
如何使用信息檢索器
流水線協調器控制整體流程,但在回答問題時主要依賴信息檢索器。開發者不會直接從命令行調用InformationRetriever,它由更大的"問答流程"內部調用
不過我們可以觀察其不同部分的編程用法。本項目提供三種主要檢索器:
BM25Retriever:基于關鍵詞搜索VectorRetriever:基于語義(含義)搜索HybridRetriever:混合檢索,通常包含進階重排序步驟
以下示例展示如何查找特定公司報告的財務信息。假設需要查找"公司A在2023年的營收增長數據":
首先確保數據庫和原始文檔路徑已配置(main.py中由流水線協調器管理路徑):
from pathlib import Path
from src.retrieval import BM25Retriever, VectorRetriever, HybridRetriever# 知識庫存儲路徑(第五章創建)
vector_db_path = Path("data/vector_db")
bm25_db_path = Path("data/bm25_db")
documents_path = Path("data/debug/chunked_reports") # 預處理后的塊# 目標公司
target_company = "ACME Corp"
# 用戶問題
user_query = "ACME Corp在2023年的營收和利潤是多少?"
說明:配置知識庫(vector_db和bm25_db)及處理文檔(chunked_reports)路徑,定義目標公司和查詢內容。
1. 使用BM25Retriever(關鍵詞搜索)
該檢索器擅長查找精確詞匯或短語:
# 創建BM25檢索器實例
bm25_retriever = BM25Retriever(bm25_db_dir=bm25_db_path, documents_dir=documents_path
)print(f"\n--- {target_company}的BM25檢索結果 ---")
# 獲取前3個相關塊
bm25_results = bm25_retriever.retrieve_by_company_name(company_name=target_company, query=user_query, top_n=3
)for i, res in enumerate(bm25_results):print(f"結果{i+1}(第{res['page']}頁): 相關性={res['distance']:.2f}")print(f"文本: {res['text'][:100]}...") # 顯示前100字符
預期輸出(簡化):
--- ACME Corp的BM25檢索結果 ---
結果1(第5頁): 相關性=0.75
文本: ...2023年營收增長15%達5億美元,凈利潤5000萬美元...
結果2(第7頁): 相關性=0.68
文本: ...財務表現亮點:2023年營收趨勢與盈利能力...
結果3(第12頁): 相關性=0.55
文本: ...2023財年及未來展望相關信息...
解析:創建BM25Retriever實例,指向BM25索引和文檔塊。
調用retrieve_by_company_name方法,傳入公司名、查詢內容和返回數量。該方法高效掃描BM25索引,返回關鍵詞匹配度最高的塊。
2. 使用VectorRetriever(語義搜索)
該檢索器通過嵌入向量查找語義相似的塊,即使不含相同詞匯:
# 創建向量檢索器實例
vector_retriever = VectorRetriever(vector_db_dir=vector_db_path, documents_dir=documents_path
)print(f"\n--- {target_company}的向量檢索結果 ---")
# 獲取前3個語義相關塊
vector_results = vector_retriever.retrieve_by_company_name(company_name=target_company, query=user_query, top_n=3
)for i, res in enumerate(vector_results):print(f"結果{i+1}(第{res['page']}頁): 向量距離={res['distance']:.2f}")print(f"文本: {res['text'][:100]}...")
預期輸出(簡化):
--- ACME Corp的向量檢索結果 ---
結果1(第5頁): 向量距離=0.92
文本: ...去年達成重要財務里程碑,關鍵指標...
結果2(第7頁): 向量距離=0.88
文本: ...截至2023年12月31日的財年收益摘要...
結果3(第10頁): 向量距離=0.80
文本: ...年報亮點:經濟表現與戰略舉措...
解析:創建VectorRetriever實例后,調用方法時會將用戶查詢轉換為嵌入向量(使用LLM),在目標公司的FAISS向量庫中查找數值"最接近"的塊。
3. 使用HybridRetriever(混合重排序)
HybridRetriever結合兩者優勢,通常使用向量搜索初步檢索,再通過LLM重排序提升精度:
# 創建混合檢索器實例
hybrid_retriever = HybridRetriever(vector_db_dir=vector_db_path, documents_dir=documents_path
)print(f"\n--- {target_company}的混合檢索結果 ---")
# 獲取重排序后的前3結果
hybrid_results = hybrid_retriever.retrieve_by_company_name(company_name=target_company, query=user_query, top_n=3,llm_reranking_sample_size=10 # 獲取10個初選結果再重排序
)for i, res in enumerate(hybrid_results):print(f"結果{i+1}(第{res['page']}頁): 重排序得分={res['score']:.2f}")print(f"文本: {res['text'][:100]}...")
預期輸出(簡化):
--- ACME Corp的混合檢索結果 ---
結果1(第5頁): 重排序得分=0.98
文本: ...2023年營收增長15%達5億美元,凈利潤5000萬美元...
結果2(第7頁): 重排序得分=0.95
文本: ...截至2023年12月31日的財年收益摘要...
結果3(第1頁): 重排序得分=0.90
文本: ...2023財年表現概覽與未來展望...
解析:HybridRetriever先用向量檢索獲取較多候選塊(llm_reranking_sample_size控制數量),再通過LLMReranker(將在第七章詳述)使用LLM評估相關性得分
最終返回精排結果。這種方法通常準確率最高。
底層原理:信息檢索器工作機制
信息檢索器通過協調src/retrieval.py中的組件實現其功能,本質上是專業化的搜索代理。
信息檢索流程:
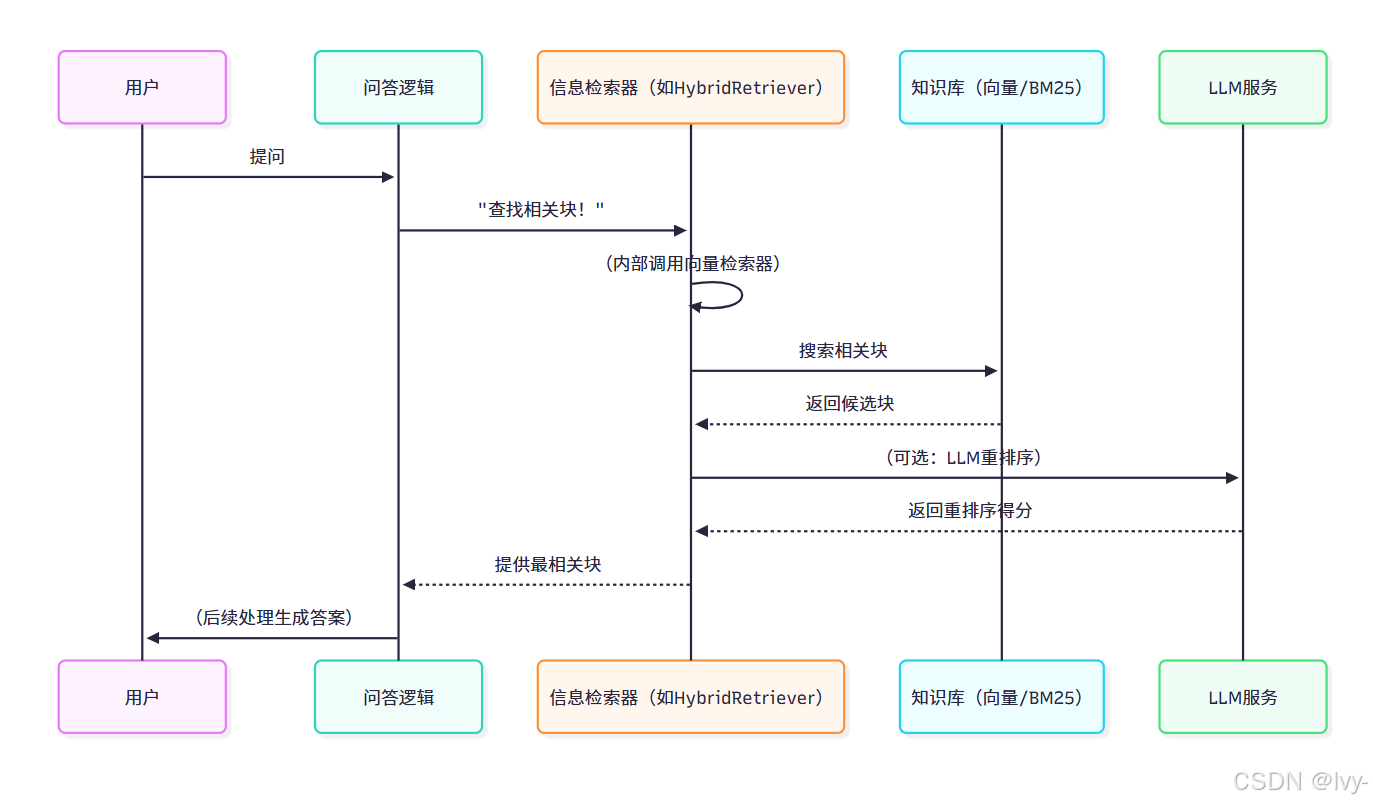
1. BM25Retriever 實現解析
該類處理基于關鍵詞的檢索:
# 來源:src/retrieval.py(簡化版)
import pickle
from pathlib import Path
from rank_bm25 import BM25Okapi class BM25Retriever:def __init__(self, bm25_db_dir: Path, documents_dir: Path):self.bm25_db_dir = bm25_db_dir # BM25索引存儲路徑self.documents_dir = documents_dir # 文檔塊路徑def retrieve_by_company_name(self, company_name: str, query: str, top_n: int = 3) -> list:# 查找目標公司文檔document_path = next((p for p in self.documents_dir.glob("*.json") if company_name in str(p)), None)if not document_path: return []# 加載BM25索引bm25_path = self.bm25_db_dir / f"{document_path.stem}.pkl"with open(bm25_path, 'rb') as f:bm25_index = pickle.load(f)# 加載文檔塊with open(document_path, 'r', encoding='utf-8') as f:document = json.load(f)chunks = document["content"]["chunks"]# 分詞查詢并計算相關性tokenized_query = query.split()scores = bm25_index.get_scores(tokenized_query)# 取top_n結果top_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:top_n]return [{"distance": round(scores[i],4),"page": chunks[i]["page"],"text": chunks[i]["text"]} for i in top_indices]
實現了一個基于BM25算法的文檔檢索工具,專門用于根據公司名稱和查詢詞檢索相關文檔片段。
核心類說明
BM25Retriever類包含兩個關鍵參數:
bm25_db_dir:存儲預先構建好的BM25檢索索引的目錄documents_dir:存放原始文檔數據的目錄
檢索流程
檢索方法retrieve_by_company_name執行以下操作:
- 通過公司名稱定位對應文檔文件(查找.json文件)
- 加載該文檔對應的BM25預訓練索引(.pkl文件)
讀取原始文檔的分塊內容(chunks字段)- 對查詢語句進行
簡單分詞處理 - 計算查詢詞與所有文檔塊的相關性得分
- 返回得分最高的
top_n個結果,包含:- 相關性分數(保留4位小數)
- 所在頁碼
- 文本內容
特點:
- 采用BM25算法進行相關性排序(經典信息檢索算法)
- 使用
pickle格式存儲預計算索引 - 結果按相關性降序排列
- 默認返回最相關的3個結果片段
應用場景:
適用于企業文檔管理系統,比如根據公司名稱快速查找年報/財報中與特定查詢詞相關的內容片段。
流程:定位目標公司文檔→加載對應BM25索引→分詞查詢→計算相關性得分→返回前N結果。
🎢Pickle格式
是Python特有的數據序列化方式,能將任何對象(如列表、字典、類實例等)轉換為二進制數據保存或傳輸,使用時再還原回原對象。類似“打包”和“拆包”的過程。
同二進制的protobuf傳送:ProtoBuf專欄
2. VectorRetriever 實現解析
該類處理基于語義的檢索:
# 來源:src/retrieval.py(簡化版)
import faiss
from openai import OpenAI
import numpy as npclass VectorRetriever:def __init__(self, vector_db_dir: Path, documents_dir: Path):self.vector_db_dir = vector_db_dirself.documents_dir = documents_dirself.llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY")) # 嵌入模型連接def retrieve_by_company_name(self, company_name: str, query: str, top_n: int = 3) -> list:# 加載目標公司向量庫target_report = next((r for r in self._load_dbs() if company_name in r["name"]), None)if not target_report: return []# 生成查詢嵌入query_embedding = self.llm.embeddings.create(input=query, model="text-embedding-3-large").data[0].embeddingquery_embedding = np.array(query_embedding, dtype=np.float32).reshape(1, -1)# FAISS向量搜索distances, indices = target_report["vector_db"].search(query_embedding, top_n)return [{"distance": round(distances[0][i],4),"page": target_report["document"]["content"]["chunks"][indices[0][i]]["page"],"text": target_report["document"]["content"]["chunks"][indices[0][i]]["text"]} for i in range(top_n)]
實現了一個基于向量檢索的文檔查詢系統,專門針對公司報告進行語義搜索。
核心邏輯分解
初始化階段
VectorRetriever類初始化時設置兩個路徑:向量數據庫目錄和文檔目錄
同時創建OpenAI嵌入模型連接用于文本向量化。
檢索流程
- 通過公司名稱定位目標報告庫,在預加載的數據庫列表中匹配包含指定公司名的報告
- 將用戶查詢文本通過OpenAI的
text-embedding-3-large模型轉換為1536維向量 - 使用FAISS庫在目標公司的向量數據庫中進行最近
鄰搜索,找出與查詢最相似的top_n個文本片段
1536維向量
是由1536個數字組成的有序列表,用于在高維空間中精確表示數據(如文本、圖像等),每個數字對應一個特征維度。
返回結果
結構化返回包含三個字段的列表:
- 匹配度分數(
歐式距離) - 原文所在頁碼
- 匹配的文本內容
歐式距離就是日常生活中兩點之間的直線距離,比如地圖上兩個地點的最短路徑長度。
技術特點
- 采用稠密向量檢索(Dense Retrieval)替代傳統關鍵詞匹配
- 向量維度適配text-embedding-3-large模型的1536維輸出
- 距離計算使用FAISS優化的L2距離(歐式距離)
應用場景
當用戶需要查詢某公司報告中與特定問題相關的內容時(如"蘋果公司的碳排放政策"),系統會返回報告中最相關的文本段落及其位置信息。
流程:加載向量庫→轉換查詢為嵌入向量→執行FAISS相似性搜索→返回最鄰近結果。
3. HybridRetriever 實現解析
該類結合向量檢索與LLM重排序:
# 來源:src/retrieval.py(簡化版)
from src.reranking import LLMReranker class HybridRetriever:def __init__(self, vector_db_dir: Path, documents_dir: Path):self.vector_retriever = VectorRetriever(vector_db_dir, documents_dir)self.reranker = LLMReranker() # 第七章詳解def retrieve_by_company_name(self, company_name: str, query: str, top_n: int = 6) -> list:# 初步獲取更多候選結果vector_results = self.vector_retriever.retrieve_by_company_name(company_name, query, top_n=28)# LLM精細重排序reranked_results = self.reranker.rerank_documents(query, vector_results)return reranked_results[:top_n]
實現了一個混合檢索系統,結合向量檢索和LLM(大語言模型)重排序技術,用于根據公司名稱和查詢文本獲取最相關的文檔。
核心組件
HybridRetriever類包含兩個主要組件:
vector_retriever:基于向量的文檔檢索器,負責初步篩選相關文檔reranker:LLM重排序器,對初步結果進行精細化排序
工作流程
初始化時指定向量數據庫目錄和文檔目錄,創建向量檢索器和LLM重排序器實例
retrieve_by_company_name方法執行以下操作:
- 使用向量檢索器獲取28個初步候選結果(參數
top_n=28) - 調用LLM重排序器對這些結果進行精細化重新排序
- 返回最終前6個(默認值)最相關的結果
參數說明
company_name:目標公司名稱query:用戶查詢文本top_n:最終返回的結果數量(默認6個)
技術特點
該方法采用了兩階段檢索策略:
- 寬泛召回:先獲取較多候選結果(28個)
- 精準排序:用LLM對結果進行質量重排
這種設計平衡了召回率和精確度。
流程:向量檢索擴大候選池→LLM評估每個塊與問題的深層關聯→返回精排結果。
結論
信息檢索器是RAG系統的核心搜索引擎,通過結合關鍵詞匹配(BM25)和語義理解(向量)兩種檢索方式,高效定位知識庫中的相關文檔塊。
特別是采用HybridRetriever進行智能重排序后,系統能確保提取最精準的信息來解答用戶問題。該組件在用戶問題與文檔潛在答案之間架起了關鍵橋梁。
在掌握如何查找相關信息后,下一步是確保獲取最優信息并按相關性精確排序。
有時初步檢索會返回多個候選結果,我們需要更智能的方式來排序。
下一章:LLM重排序





 ? | AutoTextEffect(自動打字機))
![[RAG] LLM 交互層 | 適配器模式 | 文檔解析器(`docling`庫, CNN, OCR, OpenCV)](http://pic.xiahunao.cn/[RAG] LLM 交互層 | 適配器模式 | 文檔解析器(`docling`庫, CNN, OCR, OpenCV))




:多叉樹)
中的節能控制(一))





![[Mysql] Connector / C++ 使用](http://pic.xiahunao.cn/[Mysql] Connector / C++ 使用)
