
華為云Flexus+DeepSeek征文 | 彈性算力實戰:Flexus X實例自動擴縮容策略優化
🌟 嗨,我是IRpickstars!
🌌 總有一行代碼,能點亮萬千星辰。
🔍 在技術的宇宙中,我愿做永不停歇的探索者。
? 用代碼丈量世界,用算法解碼未來。我是摘星人,也是造夢者。
🚀 每一次編譯都是新的征程,每一個bug都是未解的謎題。讓我們攜手,在0和1的星河中,書寫屬于開發者的浪漫詩篇。
目錄
摘要
1.華為云Flexus X實例技術架構
1.1 Flexus X實例核心優勢
1.2 系統架構設計
1.3 Flexus X實例的特點與應用場景
2. 自動擴縮容策略設計
2.1 監控指標體系
2.1.1 系統資源指標
2.1.2 業務指標監控
2.2 智能決策算法
2.3 擴縮容面臨的挑戰
3. DeepSeek AI策略優化
3.1 AI驅動的預測模型
3.2 擴縮容策略執行流程
4. 實戰部署實施
4.1 環境準備
4.1.1 華為云賬號配置
4.1.2 Flexus X實例配置
4.2 自動擴縮容服務部署
4.2.1 主服務程序
4.2.2 配置文件示例
4.3 監控與可視化
5. 性能優化與最佳實踐
5.1 性能調優策略
5.1.1 閾值優化
5.1.2 成本優化分析
5.2 最佳實踐總結
5.2.1 架構設計原則
5.2.2 運維注意事項
5.2.3 故障處理流程
6. 總結與展望
6.1 技術成果總結
6.2 性能提升效果
6.3 技術發展趨勢
6.4 參考資料
?
摘要
隨著云計算技術的飛速發展,彈性算力已成為支撐各類業務,尤其是人工智能(AI)和機器學習(ML)工作負載不可或缺的基礎。華為云Flexus作為業界領先的彈性計算服務,其X實例更是為高性能AI/ML計算提供了強大支持。然而,傳統基于閾值的自動擴縮容策略在面對AI/ML工作負載的突發性、周期性及高成本敏感性時,往往難以達到最佳的性能與成本平衡。本文將深入探討Flexus X實例的自動擴縮容機制,并提出一種融合工作負載預測與AI驅動的優化策略。我們將以DeepSeek等AI模型在算力需求上的特點為背景,通過實戰演示如何基于歷史數據與智能預測,實現更高效、更具成本效益的彈性伸縮,從而最大化Flexus X實例的價值。
1.華為云Flexus X實例技術架構
1.1 Flexus X實例核心優勢
華為云Flexus X實例是華為云推出的新一代彈性云服務器產品,具備以下核心特性:
技術特性對比表:
| 特性 | 傳統ECS | Flexus X實例 | 優勢說明 |
| 啟動速度 | 2-5分鐘 | 30-60秒 | 快速響應業務峰值 |
| 計費模式 | 按小時/包年包月 | 按秒計費 | 精細化成本控制 |
| 規格調整 | 需重啟 | 在線調整 | 業務無中斷 |
| 網絡性能 | 固定帶寬 | 動態帶寬 | 彈性網絡能力 |
1.2 系統架構設計
下面是基于Flexus X實例的自動擴縮容系統整體架構:
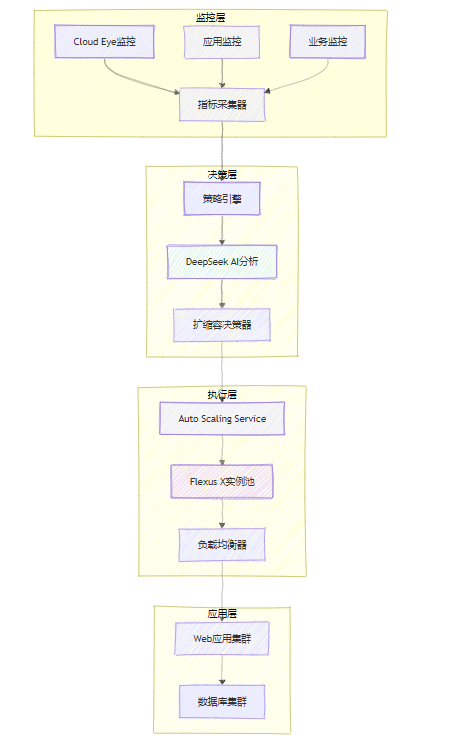
圖1:華為云Flexus X自動擴縮容系統架構圖
1.3 Flexus X實例的特點與應用場景
Flexus X實例是Flexus服務中專門為高性能計算和AI/ML場景設計的實例類型。它通常搭載了強大的GPU或NPU等異構算力,能夠提供卓越的并行計算能力。
- 高性能異構算力:集成先進的AI加速芯片,適合深度學習訓練、推理等計算密集型任務。
- 極致彈性:繼承Flexus的秒級啟動和按秒計費特性,可快速響應AI模型推理請求量的波動。
- 成本效益:通常以競價實例(Spot Instance)形式提供,價格遠低于按需實例,但在資源不足時可能被回收,因此需要精妙的擴縮容策略來保障業務連續性。
應用場景:
- AI模型推理服務:例如,部署DeepSeek等大型語言模型(LLM)的推理API,當用戶請求量激增時,Flexus X實例可以迅速擴容,滿足并發需求。
- 短時AI訓練或調優:利用低成本的X實例進行短期的模型實驗或微調。
- 科學計算:需要大規模并行計算的仿真、渲染等任務。
2. 自動擴縮容策略設計
2.1 監控指標體系
構建有效的自動擴縮容系統,首先需要建立完善的監控指標體系:
- CPU利用率:當CPU利用率超過預設閾值(如70%)時擴容,低于另一閾值(如30%)時縮容。
- 內存利用率:類似CPU利用率。
- 網絡I/O:根據網絡流量判斷負載。
- 隊列長度:如消息隊列、請求隊列的積壓情況。
局限性:
- 滯后性:基于當前指標的擴縮容是反應式的,無法預判未來的負載,可能導致“冷啟動”問題(擴容不及,服務卡頓)或資源浪費。
- “震蕩”問題:在負載反復波動時,可能頻繁地擴容和縮容,造成不必要的資源調度開銷。
- 不適用于突發性負載:對于流量瞬時暴增的場景,反應式擴容往往無法及時滿足。
2.1.1 系統資源指標
# monitoring_metrics.py - 監控指標定義
class MonitoringMetrics:"""監控指標類,定義各種性能指標的采集和計算方法"""def __init__(self):self.cpu_threshold = {'scale_out': 70, # CPU使用率超過70%觸發擴容'scale_in': 30, # CPU使用率低于30%觸發縮容'duration': 300 # 持續時間5分鐘}self.memory_threshold = {'scale_out': 80, # 內存使用率超過80%觸發擴容'scale_in': 40, # 內存使用率低于40%觸發縮容'duration': 300}self.response_time_threshold = {'scale_out': 2000, # 響應時間超過2秒觸發擴容'scale_in': 500, # 響應時間低于0.5秒觸發縮容'duration': 180}def get_cpu_utilization(self, instance_id):"""獲取指定實例的CPU利用率Args:instance_id (str): 實例IDReturns:float: CPU利用率百分比"""# 調用華為云Cloud Eye API獲取CPU指標import requestsurl = f"https://ces.cn-north-4.myhuaweicloud.com/V1.0/{project_id}/metrics"headers = {'X-Auth-Token': self._get_auth_token(),'Content-Type': 'application/json'}params = {'namespace': 'SYS.ECS','metric_name': 'cpu_util','dimensions': f'instance_id,{instance_id}','from': int(time.time() - 300) * 1000, # 最近5分鐘'to': int(time.time()) * 1000}response = requests.get(url, headers=headers, params=params)data = response.json()if data.get('datapoints'):# 計算平均CPU使用率cpu_values = [point['average'] for point in data['datapoints']]return sum(cpu_values) / len(cpu_values)return 0.0def get_memory_utilization(self, instance_id):"""獲取內存使用率Args:instance_id (str): 實例IDReturns:float: 內存使用率百分比"""# 類似CPU監控的實現url = f"https://ces.cn-north-4.myhuaweicloud.com/V1.0/{project_id}/metrics"headers = {'X-Auth-Token': self._get_auth_token(),'Content-Type': 'application/json'}params = {'namespace': 'SYS.ECS','metric_name': 'mem_util','dimensions': f'instance_id,{instance_id}','from': int(time.time() - 300) * 1000,'to': int(time.time()) * 1000}response = requests.get(url, headers=headers, params=params)data = response.json()if data.get('datapoints'):memory_values = [point['average'] for point in data['datapoints']]return sum(memory_values) / len(memory_values)return 0.0def _get_auth_token(self):"""獲取華為云認證TokenReturns:str: 認證Token"""# 實現華為云IAM認證邏輯auth_url = "https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens"auth_data = {"auth": {"identity": {"methods": ["password"],"password": {"user": {"name": "your_username","password": "your_password","domain": {"name": "your_domain"}}}},"scope": {"project": {"name": "cn-north-4"}}}}response = requests.post(auth_url, json=auth_data)return response.headers.get('X-Subject-Token')
2.1.2 業務指標監控
# business_metrics.py - 業務指標監控
class BusinessMetrics:"""業務指標監控類,監控應用層面的性能指標"""def __init__(self, app_config):self.app_config = app_configself.request_queue_threshold = 100 # 請求隊列長度閾值self.error_rate_threshold = 5 # 錯誤率閾值(%)def get_request_queue_length(self):"""獲取當前請求隊列長度Returns:int: 隊列中等待處理的請求數量"""# 從應用監控系統獲取隊列長度import redisredis_client = redis.Redis(host=self.app_config['redis_host'],port=self.app_config['redis_port'],password=self.app_config['redis_password'])# 假設使用Redis List作為請求隊列queue_length = redis_client.llen('request_queue')return queue_lengthdef get_error_rate(self, time_window=300):"""計算指定時間窗口內的錯誤率Args:time_window (int): 時間窗口(秒)Returns:float: 錯誤率百分比"""# 從日志系統或APM工具獲取錯誤率import loggingfrom datetime import datetime, timedeltaend_time = datetime.now()start_time = end_time - timedelta(seconds=time_window)# 查詢錯誤日志數量(示例實現)error_count = self._query_error_logs(start_time, end_time)total_count = self._query_total_requests(start_time, end_time)if total_count > 0:return (error_count / total_count) * 100return 0.0def _query_error_logs(self, start_time, end_time):"""查詢錯誤日志數量"""# 這里可以接入ELK、Prometheus等監控系統# 示例返回模擬數據return 5def _query_total_requests(self, start_time, end_time):"""查詢總請求數量"""# 查詢總請求數量的實現return 1000
2.2 智能決策算法
基于監控指標,我們需要實現智能的擴縮容決策算法:
- 異構算力監控:除了CPU/內存,GPU/NPU的利用率、顯存使用率、以及模型推理的QPS(Queries Per Second)或延遲,是更關鍵的監控指標。
- 工作負載特性:AI推理請求往往具有突發性、尖峰性,例如某個熱門事件可能導致請求量瞬間暴增。模型訓練則可能是長時間、持續高負載。
- 預熱時間:AI模型加載到GPU顯存可能需要一定時間,新實例啟動后需要“預熱”才能提供服務,這增加了“冷啟動”的挑戰。
- 競價實例的回收風險:Flexus X實例多以競價形式提供,其最大的優勢在于成本,但其不穩定性要求我們在擴縮容策略中考慮備用實例或容災機制。
# scaling_decision_engine.py - 擴縮容決策引擎
import numpy as np
from datetime import datetime, timedelta
import loggingclass ScalingDecisionEngine:"""擴縮容決策引擎,基于多維度指標進行智能決策"""def __init__(self):self.metrics_history = [] # 存儲歷史監控數據self.scaling_cooldown = 300 # 擴縮容冷卻時間(秒)self.last_scaling_time = None# 配置日志logging.basicConfig(level=logging.INFO)self.logger = logging.getLogger(__name__)def analyze_scaling_need(self, current_metrics, current_instances):"""分析是否需要進行擴縮容操作Args:current_metrics (dict): 當前監控指標current_instances (int): 當前實例數量Returns:dict: 擴縮容決策結果"""# 檢查冷卻時間if self._is_in_cooldown():return {'action': 'none','reason': 'In cooldown period','recommended_instances': current_instances}# 計算指標權重分數metric_scores = self._calculate_metric_scores(current_metrics)# 基于歷史數據預測趨勢trend_score = self._analyze_trend()# 綜合決策final_score = self._weighted_decision(metric_scores, trend_score)decision = self._make_decision(final_score, current_instances)# 記錄決策日志self.logger.info(f"Scaling decision: {decision}")return decisiondef _calculate_metric_scores(self, metrics):"""計算各項指標的得分Args:metrics (dict): 監控指標數據Returns:dict: 各指標得分"""scores = {}# CPU指標評分 (-1到1,負數表示需要縮容,正數表示需要擴容)cpu_util = metrics.get('cpu_utilization', 0)if cpu_util > 70:scores['cpu'] = min((cpu_util - 70) / 30, 1) # 最高分1elif cpu_util < 30:scores['cpu'] = max((cpu_util - 30) / 30, -1) # 最低分-1else:scores['cpu'] = 0 # 正常范圍內# 內存指標評分memory_util = metrics.get('memory_utilization', 0)if memory_util > 80:scores['memory'] = min((memory_util - 80) / 20, 1)elif memory_util < 40:scores['memory'] = max((memory_util - 40) / 40, -1)else:scores['memory'] = 0# 響應時間評分response_time = metrics.get('response_time', 0)if response_time > 2000: # 大于2秒scores['response_time'] = min((response_time - 2000) / 3000, 1)elif response_time < 500: # 小于0.5秒scores['response_time'] = max((response_time - 500) / 500, -1)else:scores['response_time'] = 0# 請求隊列長度評分queue_length = metrics.get('request_queue_length', 0)if queue_length > 100:scores['queue'] = min(queue_length / 200, 1)else:scores['queue'] = max((queue_length - 50) / 50, -1) if queue_length < 50 else 0return scoresdef _analyze_trend(self):"""分析歷史趨勢,預測未來負載變化Returns:float: 趨勢得分 (-1到1)"""if len(self.metrics_history) < 10:return 0 # 數據不足,返回中性分數# 取最近10個數據點分析趨勢recent_data = self.metrics_history[-10:]cpu_values = [data['cpu_utilization'] for data in recent_data]# 使用線性回歸分析趨勢x = np.arange(len(cpu_values))z = np.polyfit(x, cpu_values, 1)trend_slope = z[0] # 斜率表示趨勢# 將斜率轉換為-1到1的得分trend_score = np.tanh(trend_slope / 10) # 使用tanh函數平滑化return trend_scoredef _weighted_decision(self, metric_scores, trend_score):"""基于權重計算最終決策分數Args:metric_scores (dict): 指標得分trend_score (float): 趨勢得分Returns:float: 最終決策分數"""# 定義各指標權重weights = {'cpu': 0.3,'memory': 0.25,'response_time': 0.25,'queue': 0.15,'trend': 0.05}# 計算加權得分final_score = (metric_scores.get('cpu', 0) * weights['cpu'] +metric_scores.get('memory', 0) * weights['memory'] +metric_scores.get('response_time', 0) * weights['response_time'] +metric_scores.get('queue', 0) * weights['queue'] +trend_score * weights['trend'])return final_scoredef _make_decision(self, score, current_instances):"""根據得分做出最終決策Args:score (float): 決策分數current_instances (int): 當前實例數量Returns:dict: 決策結果"""if score > 0.3: # 擴容閾值# 計算推薦實例數量scale_factor = min(score, 1.0)additional_instances = max(1, int(current_instances * scale_factor * 0.5))recommended_instances = current_instances + additional_instancesreturn {'action': 'scale_out','reason': f'High load detected (score: {score:.2f})','recommended_instances': min(recommended_instances, 20), # 最大實例限制'confidence': score}elif score < -0.3: # 縮容閾值# 計算縮容數量scale_factor = max(score, -1.0)reduce_instances = max(1, int(current_instances * abs(scale_factor) * 0.3))recommended_instances = current_instances - reduce_instancesreturn {'action': 'scale_in','reason': f'Low load detected (score: {score:.2f})','recommended_instances': max(recommended_instances, 1), # 最小實例限制'confidence': abs(score)}else:return {'action': 'none','reason': f'Load within normal range (score: {score:.2f})','recommended_instances': current_instances,'confidence': 1 - abs(score)}def _is_in_cooldown(self):"""檢查是否在冷卻期內Returns:bool: 是否在冷卻期"""if self.last_scaling_time is None:return Falseelapsed = (datetime.now() - self.last_scaling_time).total_seconds()return elapsed < self.scaling_cooldowndef record_scaling_action(self):"""記錄擴縮容操作時間"""self.last_scaling_time = datetime.now()def add_metrics_data(self, metrics):"""添加監控數據到歷史記錄Args:metrics (dict): 監控指標數據"""metrics['timestamp'] = datetime.now()self.metrics_history.append(metrics)# 保持歷史數據在合理范圍內(最多保存100個數據點)if len(self.metrics_history) > 100:self.metrics_history = self.metrics_history[-100:]
2.3 擴縮容面臨的挑戰
綜上所述,Flexus X實例的自動擴縮容主要面臨以下挑戰:
- QoS保障:如何在保證服務質量(如低延遲、高吞吐量)的前提下,實現高效擴縮容?
- 成本優化:如何最大限度地利用競價實例的成本優勢,同時避免因資源回收導致的服務中斷?
- 動態負載預測:如何準確預測未來的負載,實現主動式擴縮容?
- 平滑過渡:如何避免擴縮容過程中的服務抖動或中斷?
3. DeepSeek AI策略優化
3.1 AI驅動的預測模型
為了克服傳統策略的局限性,并應對Flexus X實例的特殊挑戰,我們引入一種基于工作負載預測的AI驅動擴縮容策略。
- 引入智能預測機制
傳統的閾值告警擴縮容是“亡羊補牢”式的,即出現問題后再處理。而智能預測機制則可以“未雨綢繆”,通過分析歷史數據,預測未來的工作負載趨勢,從而提前進行擴縮容操作。這對于AI推理服務尤為重要,因為其請求量波動可能非常劇烈。
- 基于DeepSeek等AI模型的智能擴縮容策略
這里的“DeepSeek等AI模型”指代的是具備強大預測能力和模式識別能力的AI模型。我們可以構建一個預測模塊,利用機器學習(ML)技術,對AI推理服務的請求量、GPU利用率等關鍵指標進行預測。
核心思想:
- 數據收集:持續收集Flexus X實例的實時運行指標(GPU利用率、顯存使用、QPS等)以及業務指標。
- 數據預處理:對收集到的數據進行清洗、降噪、特征工程等處理。
- 預測模型訓練:利用歷史數據訓練一個時間序列預測模型,例如LSTM、ARIMA、Prophet等,或者更復雜的Transformer ??模型(借鑒DeepSeek等大型AI模型的架構思想)。
- 預測與決策:模型根據最新數據預測未來一段時間(如未來5分鐘、15分鐘)的資源需求,決策引擎根據預測結果、預設的安全閾值和成本策略,計算出最佳的擴縮容數量。
- API調用:通過華為云彈性伸縮服務(Auto Scaling Group, ASG)的API,自動調整Flexus X實例的數量。
# deepseek_optimizer.py - DeepSeek AI策略優化器
import json
import requests
from datetime import datetime, timedelta
import pandas as pdclass DeepSeekOptimizer:"""基于DeepSeek AI的擴縮容策略優化器"""def __init__(self, api_key, api_base_url):self.api_key = api_keyself.api_base_url = api_base_urlself.model_name = "deepseek-chat"def predict_load_pattern(self, historical_data, forecast_hours=24):"""使用AI預測未來負載模式Args:historical_data (list): 歷史監控數據forecast_hours (int): 預測時長(小時)Returns:dict: 預測結果和建議"""# 準備歷史數據data_summary = self._prepare_data_summary(historical_data)# 構建AI提示prompt = self._build_prediction_prompt(data_summary, forecast_hours)# 調用DeepSeek APIprediction_result = self._call_deepseek_api(prompt)# 解析AI響應parsed_result = self._parse_ai_response(prediction_result)return parsed_resultdef optimize_scaling_parameters(self, current_config, performance_history):"""優化擴縮容參數配置Args:current_config (dict): 當前配置參數performance_history (list): 性能歷史數據Returns:dict: 優化后的配置建議"""# 分析當前配置的性能表現performance_analysis = self._analyze_performance(performance_history)# 構建優化提示optimization_prompt = self._build_optimization_prompt(current_config, performance_analysis)# 獲取AI優化建議optimization_result = self._call_deepseek_api(optimization_prompt)# 解析優化建議optimized_config = self._parse_optimization_response(optimization_result)return optimized_configdef _prepare_data_summary(self, historical_data):"""準備歷史數據摘要Args:historical_data (list): 歷史數據Returns:dict: 數據摘要"""if not historical_data:return {}# 轉換為DataFrame進行分析df = pd.DataFrame(historical_data)# 基本統計信息summary = {'total_records': len(df),'time_range': {'start': df['timestamp'].min().isoformat(),'end': df['timestamp'].max().isoformat()},'cpu_stats': {'mean': df['cpu_utilization'].mean(),'max': df['cpu_utilization'].max(),'min': df['cpu_utilization'].min(),'std': df['cpu_utilization'].std()},'memory_stats': {'mean': df['memory_utilization'].mean(),'max': df['memory_utilization'].max(),'min': df['memory_utilization'].min(),'std': df['memory_utilization'].std()},'response_time_stats': {'mean': df['response_time'].mean(),'max': df['response_time'].max(),'min': df['response_time'].min(),'std': df['response_time'].std()}}# 按小時統計,識別負載模式df['hour'] = df['timestamp'].dt.hourhourly_stats = df.groupby('hour').agg({'cpu_utilization': 'mean','memory_utilization': 'mean','response_time': 'mean'}).to_dict()summary['hourly_patterns'] = hourly_statsreturn summarydef _build_prediction_prompt(self, data_summary, forecast_hours):"""構建負載預測提示"""prompt = f"""作為云計算負載預測專家,請基于以下歷史監控數據分析負載模式并預測未來{forecast_hours}小時的負載趨勢:歷史數據摘要:- 數據記錄數:{data_summary.get('total_records', 0)}- 時間范圍:{data_summary.get('time_range', {})}CPU使用率統計:- 平均值:{data_summary.get('cpu_stats', {}).get('mean', 0):.2f}%- 最大值:{data_summary.get('cpu_stats', {}).get('max', 0):.2f}%- 最小值:{data_summary.get('cpu_stats', {}).get('min', 0):.2f}%內存使用率統計:- 平均值:{data_summary.get('memory_stats', {}).get('mean', 0):.2f}%- 最大值:{data_summary.get('memory_stats', {}).get('max', 0):.2f}%響應時間統計:- 平均值:{data_summary.get('response_time_stats', {}).get('mean', 0):.2f}ms- 最大值:{data_summary.get('response_time_stats', {}).get('max', 0):.2f}ms每小時負載模式:{json.dumps(data_summary.get('hourly_patterns', {}), indent=2)}請分析并提供:1. 負載模式識別(周期性、突發性等)2. 未來{forecast_hours}小時的負載預測3. 關鍵時間點的擴縮容建議4. 風險評估和預警請以JSON格式返回分析結果。"""return promptdef _build_optimization_prompt(self, current_config, performance_analysis):"""構建參數優化提示"""prompt = f"""作為云計算自動擴縮容優化專家,請基于當前配置和性能表現,提供參數優化建議:當前配置:{json.dumps(current_config, indent=2)}性能分析結果:{json.dumps(performance_analysis, indent=2)}請分析并提供:1. 當前配置的問題識別2. 擴縮容閾值優化建議3. 冷卻時間調整建議4. 實例數量范圍優化5. 權重配置優化優化目標:- 降低成本- 提高響應速度- 減少不必要的擴縮容操作- 提高系統穩定性請以JSON格式返回優化建議。"""return promptdef _call_deepseek_api(self, prompt):"""調用DeepSeek APIArgs:prompt (str): 輸入提示Returns:str: AI響應結果"""headers = {'Authorization': f'Bearer {self.api_key}','Content-Type': 'application/json'}data = {'model': self.model_name,'messages': [{'role': 'user','content': prompt}],'temperature': 0.1, # 降低隨機性,提高一致性'max_tokens': 2000}try:response = requests.post(f'{self.api_base_url}/chat/completions',headers=headers,json=data,timeout=30)response.raise_for_status()result = response.json()return result['choices'][0]['message']['content']except Exception as e:print(f"DeepSeek API調用錯誤: {e}")return Nonedef _parse_ai_response(self, response):"""解析AI預測響應"""try:# 嘗試解析JSON響應result = json.loads(response)return resultexcept:# 如果JSON解析失敗,返回文本響應return {'raw_response': response}def _parse_optimization_response(self, response):"""解析AI優化建議響應"""try:result = json.loads(response)return resultexcept:return {'raw_response': response}def _analyze_performance(self, performance_history):"""分析性能歷史數據"""if not performance_history:return {}df = pd.DataFrame(performance_history)analysis = {'scaling_frequency': len(df[df['action'] != 'none']),'scale_out_count': len(df[df['action'] == 'scale_out']),'scale_in_count': len(df[df['action'] == 'scale_in']),'average_confidence': df['confidence'].mean(),'performance_trends': {'cpu_trend': df['cpu_utilization'].tail(10).mean() - df['cpu_utilization'].head(10).mean(),'response_time_trend': df['response_time'].tail(10).mean() - df['response_time'].head(10).mean()}}return analysis
3.2 擴縮容策略執行流程
下面是完整的擴縮容執行流程圖:
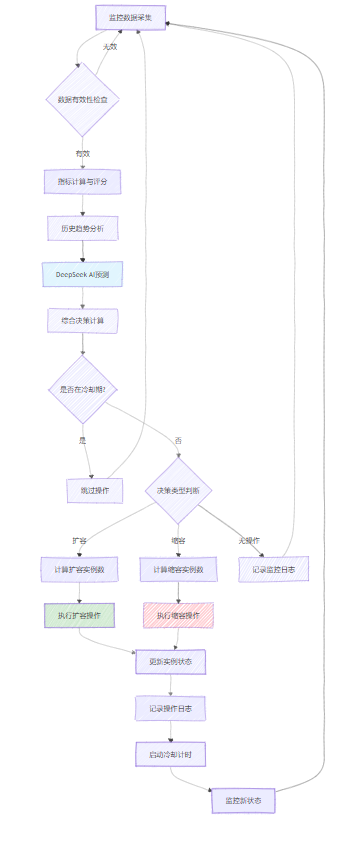
圖2:自動擴縮容策略執行流程圖
4. 實戰部署實施
4.1 環境準備
4.1.1 華為云賬號配置
首先需要完成華為云相關服務的配置:
步驟1:創建IAM用戶和權限
- 登錄華為云控制臺,進入IAM服務
- 創建用戶組"AutoScaling-Group"
- 為用戶組附加以下策略:
-
ECS FullAccess- ECS完全訪問權限CES FullAccess- Cloud Eye完全訪問權限AS FullAccess- 彈性伸縮完全訪問權限VPC FullAccess- VPC完全訪問權限
步驟2:創建API訪問密鑰
- 在IAM用戶詳情頁面,創建訪問密鑰
- 記錄Access Key ID和Secret Access Key
- 配置到系統環境變量或配置文件中
4.1.2 Flexus X實例配置
# flexus_instance_manager.py - Flexus X實例管理器
import requests
import json
import time
from datetime import datetimeclass FlexusInstanceManager:"""華為云Flexus X實例管理器"""def __init__(self, access_key, secret_key, project_id, region='cn-north-4'):self.access_key = access_keyself.secret_key = secret_keyself.project_id = project_idself.region = regionself.base_url = f"https://ecs.{region}.myhuaweicloud.com"self.auth_token = Noneself.token_expires = Nonedef authenticate(self):"""獲取認證TokenReturns:bool: 認證是否成功"""auth_url = f"https://iam.{self.region}.myhuaweicloud.com/v3/auth/tokens"auth_data = {"auth": {"identity": {"methods": ["password"],"password": {"user": {"name": self.access_key,"password": self.secret_key,"domain": {"name": "your_domain_name"}}}},"scope": {"project": {"id": self.project_id}}}}try:response = requests.post(auth_url, json=auth_data)response.raise_for_status()self.auth_token = response.headers.get('X-Subject-Token')# Token通常24小時有效self.token_expires = datetime.now().timestamp() + 86400return Trueexcept Exception as e:print(f"認證失敗: {e}")return Falsedef create_flexus_instance(self, instance_config):"""創建Flexus X實例Args:instance_config (dict): 實例配置參數Returns:dict: 創建結果"""if not self._check_auth():return Noneurl = f"{self.base_url}/v1/{self.project_id}/cloudservers"headers = {'X-Auth-Token': self.auth_token,'Content-Type': 'application/json'}# Flexus X實例創建配置server_data = {"server": {"name": instance_config.get('name', f'flexus-{int(time.time())}'),"flavorRef": instance_config.get('flavor_id', 's6.small.1'), # Flexus規格"imageRef": instance_config.get('image_id'),"vpcid": instance_config.get('vpc_id'),"nics": [{"subnet_id": instance_config.get('subnet_id')}],"security_groups": [{"id": instance_config.get('security_group_id')}],"key_name": instance_config.get('key_pair_name'),"user_data": self._encode_user_data(instance_config.get('user_data', '')),"metadata": {"created_by": "auto_scaling","purpose": "load_balancing"},# Flexus特有配置"server_tags": [{"key": "flexus_type","value": "auto_scaling"}],"extendparam": {"chargingMode": "0", # 按需計費"isAutoRename": "true"}}}try:response = requests.post(url, headers=headers, json=server_data)response.raise_for_status()result = response.json()job_id = result.get('job_id')# 等待實例創建完成instance_info = self._wait_for_instance_creation(job_id)return instance_infoexcept Exception as e:print(f"創建實例失敗: {e}")return Nonedef delete_instance(self, instance_id):"""刪除實例Args:instance_id (str): 實例IDReturns:bool: 刪除是否成功"""if not self._check_auth():return Falseurl = f"{self.base_url}/v1/{self.project_id}/cloudservers/{instance_id}"headers = {'X-Auth-Token': self.auth_token,'Content-Type': 'application/json'}try:response = requests.delete(url, headers=headers)response.raise_for_status()return Trueexcept Exception as e:print(f"刪除實例失敗: {e}")return Falsedef list_instances(self, tag_filter=None):"""列出實例Args:tag_filter (dict): 標簽過濾條件Returns:list: 實例列表"""if not self._check_auth():return []url = f"{self.base_url}/v1/{self.project_id}/cloudservers/detail"headers = {'X-Auth-Token': self.auth_token,'Content-Type': 'application/json'}params = {}if tag_filter:# 構建標簽過濾參數tags = []for key, value in tag_filter.items():tags.append(f"{key}={value}")params['tags'] = ','.join(tags)try:response = requests.get(url, headers=headers, params=params)response.raise_for_status()result = response.json()return result.get('servers', [])except Exception as e:print(f"獲取實例列表失敗: {e}")return []def _check_auth(self):"""檢查認證狀態"""if not self.auth_token or not self.token_expires:return self.authenticate()# 檢查Token是否即將過期(提前1小時刷新)if datetime.now().timestamp() > (self.token_expires - 3600):return self.authenticate()return Truedef _encode_user_data(self, user_data):"""編碼用戶數據"""import base64return base64.b64encode(user_data.encode()).decode()def _wait_for_instance_creation(self, job_id, timeout=300):"""等待實例創建完成Args:job_id (str): 任務IDtimeout (int): 超時時間(秒)Returns:dict: 實例信息"""start_time = time.time()while time.time() - start_time < timeout:job_status = self._get_job_status(job_id)if job_status.get('status') == 'SUCCESS':# 獲取創建的實例信息instance_id = job_status.get('entities', {}).get('server_id')if instance_id:return self._get_instance_details(instance_id)elif job_status.get('status') == 'FAIL':print(f"實例創建失敗: {job_status.get('fail_reason')}")return Nonetime.sleep(10) # 等待10秒后重新檢查print("實例創建超時")return Nonedef _get_job_status(self, job_id):"""獲取任務狀態"""url = f"{self.base_url}/v1/{self.project_id}/jobs/{job_id}"headers = {'X-Auth-Token': self.auth_token,'Content-Type': 'application/json'}try:response = requests.get(url, headers=headers)response.raise_for_status()return response.json()except Exception as e:print(f"獲取任務狀態失敗: {e}")return {}def _get_instance_details(self, instance_id):"""獲取實例詳細信息"""url = f"{self.base_url}/v1/{self.project_id}/cloudservers/{instance_id}"headers = {'X-Auth-Token': self.auth_token,'Content-Type': 'application/json'}try:response = requests.get(url, headers=headers)response.raise_for_status()return response.json().get('server')except Exception as e:print(f"獲取實例詳情失敗: {e}")return None
4.2 自動擴縮容服務部署
4.2.1 主服務程序
# auto_scaling_service.py - 自動擴縮容主服務
import time
import threading
import logging
from datetime import datetime
import jsonclass AutoScalingService:"""自動擴縮容服務主程序"""def __init__(self, config_file='config.json'):# 加載配置with open(config_file, 'r') as f:self.config = json.load(f)# 初始化各個組件self.metrics_monitor = MonitoringMetrics()self.business_metrics = BusinessMetrics(self.config['app'])self.decision_engine = ScalingDecisionEngine()self.instance_manager = FlexusInstanceManager(self.config['huawei_cloud']['access_key'],self.config['huawei_cloud']['secret_key'],self.config['huawei_cloud']['project_id'],self.config['huawei_cloud']['region'])# 初始化DeepSeek優化器(如果配置了)if self.config.get('deepseek'):self.ai_optimizer = DeepSeekOptimizer(self.config['deepseek']['api_key'],self.config['deepseek']['api_url'])else:self.ai_optimizer = None# 配置日志logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler('auto_scaling.log'),logging.StreamHandler()])self.logger = logging.getLogger(__name__)# 服務狀態self.running = Falseself.monitoring_thread = Nonedef start(self):"""啟動自動擴縮容服務"""self.logger.info("啟動自動擴縮容服務...")# 認證華為云if not self.instance_manager.authenticate():self.logger.error("華為云認證失敗,服務啟動終止")return Falseself.running = True# 啟動監控線程self.monitoring_thread = threading.Thread(target=self._monitoring_loop)self.monitoring_thread.daemon = Trueself.monitoring_thread.start()self.logger.info("自動擴縮容服務啟動成功")return Truedef stop(self):"""停止服務"""self.logger.info("停止自動擴縮容服務...")self.running = Falseif self.monitoring_thread:self.monitoring_thread.join(timeout=30)self.logger.info("服務已停止")def _monitoring_loop(self):"""監控循環"""while self.running:try:# 執行一輪擴縮容檢查self._perform_scaling_check()# 等待下一次檢查time.sleep(self.config.get('check_interval', 60))except Exception as e:self.logger.error(f"監控循環異常: {e}")time.sleep(30) # 異常時等待30秒再重試def _perform_scaling_check(self):"""執行擴縮容檢查"""self.logger.info("開始執行擴縮容檢查...")# 1. 獲取當前實例列表current_instances = self.instance_manager.list_instances({'flexus_type': 'auto_scaling'})if not current_instances:self.logger.warning("未找到自動擴縮容實例")returncurrent_instance_count = len(current_instances)self.logger.info(f"當前實例數量: {current_instance_count}")# 2. 收集監控指標metrics = self._collect_metrics(current_instances)if not metrics:self.logger.warning("監控指標收集失敗,跳過本次檢查")returnself.logger.info(f"監控指標: {metrics}")# 3. 添加到歷史數據self.decision_engine.add_metrics_data(metrics)# 4. 使用AI優化(如果配置了)if self.ai_optimizer and len(self.decision_engine.metrics_history) > 10:try:# 每小時運行一次AI優化if datetime.now().minute == 0:self._run_ai_optimization()except Exception as e:self.logger.error(f"AI優化失敗: {e}")# 5. 執行擴縮容決策decision = self.decision_engine.analyze_scaling_need(metrics, current_instance_count)self.logger.info(f"擴縮容決策: {decision}")# 6. 執行擴縮容操作if decision['action'] != 'none':success = self._execute_scaling_action(decision, current_instances)if success:self.decision_engine.record_scaling_action()self.logger.info(f"擴縮容操作執行成功: {decision['action']}")else:self.logger.error(f"擴縮容操作執行失敗: {decision['action']}")def _collect_metrics(self, instances):"""收集監控指標Args:instances (list): 實例列表Returns:dict: 聚合后的監控指標"""if not instances:return Nonetry:# 收集各實例的指標cpu_values = []memory_values = []for instance in instances:instance_id = instance['id']# 獲取CPU使用率cpu_util = self.metrics_monitor.get_cpu_utilization(instance_id)if cpu_util is not None:cpu_values.append(cpu_util)# 獲取內存使用率memory_util = self.metrics_monitor.get_memory_utilization(instance_id)if memory_util is not None:memory_values.append(memory_util)# 收集業務指標queue_length = self.business_metrics.get_request_queue_length()error_rate = self.business_metrics.get_error_rate()# 計算平均值avg_cpu = sum(cpu_values) / len(cpu_values) if cpu_values else 0avg_memory = sum(memory_values) / len(memory_values) if memory_values else 0# 模擬響應時間(實際項目中應該從APM工具獲取)response_time = self._get_average_response_time()return {'cpu_utilization': avg_cpu,'memory_utilization': avg_memory,'response_time': response_time,'request_queue_length': queue_length,'error_rate': error_rate,'instance_count': len(instances)}except Exception as e:self.logger.error(f"收集監控指標失敗: {e}")return Nonedef _get_average_response_time(self):"""獲取平均響應時間(示例實現)"""# 實際項目中應該從負載均衡器或APM工具獲取# 這里返回模擬數據import randomreturn random.uniform(200, 1500) # 200ms到1.5s的隨機響應時間def _execute_scaling_action(self, decision, current_instances):"""執行擴縮容操作Args:decision (dict): 擴縮容決策current_instances (list): 當前實例列表Returns:bool: 操作是否成功"""action = decision['action']recommended_count = decision['recommended_instances']current_count = len(current_instances)if action == 'scale_out':# 擴容操作instances_to_create = recommended_count - current_countreturn self._scale_out(instances_to_create)elif action == 'scale_in':# 縮容操作instances_to_remove = current_count - recommended_countreturn self._scale_in(instances_to_remove, current_instances)return Truedef _scale_out(self, count):"""執行擴容操作Args:count (int): 需要創建的實例數量Returns:bool: 是否成功"""self.logger.info(f"開始擴容,創建 {count} 個實例")instance_config = self.config['instance_template']success_count = 0for i in range(count):# 為每個實例生成唯一名稱instance_config['name'] = f"flexus-auto-{int(time.time())}-{i}"instance = self.instance_manager.create_flexus_instance(instance_config)if instance:success_count += 1self.logger.info(f"實例創建成功: {instance.get('id')}")else:self.logger.error(f"實例創建失敗")self.logger.info(f"擴容完成,成功創建 {success_count}/{count} 個實例")return success_count > 0def _scale_in(self, count, current_instances):"""執行縮容操作Args:count (int): 需要刪除的實例數量current_instances (list): 當前實例列表Returns:bool: 是否成功"""self.logger.info(f"開始縮容,刪除 {count} 個實例")# 選擇要刪除的實例(這里選擇創建時間最早的)instances_to_remove = sorted(current_instances, key=lambda x: x.get('created', ''))[:count]success_count = 0for instance in instances_to_remove:instance_id = instance['id']if self.instance_manager.delete_instance(instance_id):success_count += 1self.logger.info(f"實例刪除成功: {instance_id}")else:self.logger.error(f"實例刪除失敗: {instance_id}")self.logger.info(f"縮容完成,成功刪除 {success_count}/{count} 個實例")return success_count > 0def _run_ai_optimization(self):"""運行AI優化"""self.logger.info("開始AI策略優化...")# 獲取歷史數據historical_data = self.decision_engine.metrics_history[-100:] # 最近100條記錄# 預測負載模式prediction = self.ai_optimizer.predict_load_pattern(historical_data)if prediction:self.logger.info(f"AI負載預測: {prediction}")# 根據預測結果調整策略# 這里可以實現動態調整閾值等邏輯# 優化擴縮容參數current_config = {'cpu_threshold': self.decision_engine.metrics_monitor.cpu_threshold,'memory_threshold': self.decision_engine.metrics_monitor.memory_threshold,'response_time_threshold': self.decision_engine.metrics_monitor.response_time_threshold}performance_history = [] # 這里應該從數據庫獲取性能歷史optimization = self.ai_optimizer.optimize_scaling_parameters(current_config, performance_history)if optimization:self.logger.info(f"AI參數優化建議: {optimization}")def main():"""主函數"""# 創建服務實例service = AutoScalingService('config.json')try:# 啟動服務if service.start():print("自動擴縮容服務已啟動,按Ctrl+C停止服務...")# 保持服務運行while True:time.sleep(1)except KeyboardInterrupt:print("\n收到停止信號,正在關閉服務...")finally:service.stop()if __name__ == "__main__":main()
4.2.2 配置文件示例
{"huawei_cloud": {"access_key": "your_access_key","secret_key": "your_secret_key","project_id": "your_project_id","region": "cn-north-4"},"deepseek": {"api_key": "your_deepseek_api_key","api_url": "https://api.deepseek.com/v1"},"app": {"redis_host": "your_redis_host","redis_port": 6379,"redis_password": "your_redis_password"},"instance_template": {"flavor_id": "s6.small.1","image_id": "your_image_id","vpc_id": "your_vpc_id","subnet_id": "your_subnet_id","security_group_id": "your_security_group_id","key_pair_name": "your_key_pair"},"scaling_config": {"min_instances": 1,"max_instances": 20,"check_interval": 60,"cooldown_period": 300}
}4.3 監控與可視化
為了更好地監控擴縮容系統的運行狀態,我們需要構建監控儀表板:
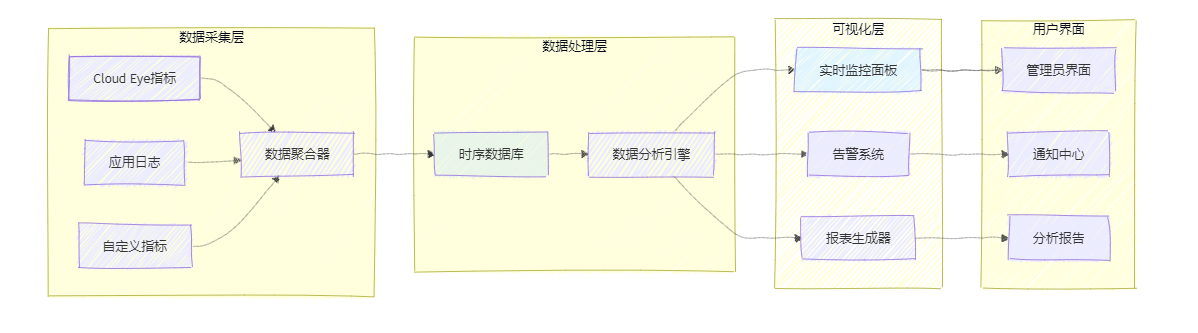
圖3:監控與可視化系統架構圖
5. 性能優化與最佳實踐
5.1 性能調優策略
5.1.1 閾值優化
基于歷史數據分析,動態調整擴縮容閾值:
# threshold_optimizer.py - 閾值優化器
import numpy as np
from sklearn.linear_model import LinearRegression
from datetime import datetime, timedeltaclass ThresholdOptimizer:"""擴縮容閾值優化器"""def __init__(self):self.optimization_history = []def optimize_thresholds(self, historical_data, performance_metrics):"""基于歷史數據優化閾值Args:historical_data (list): 歷史監控數據performance_metrics (dict): 性能指標Returns:dict: 優化后的閾值配置"""# 分析當前閾值的效果current_effectiveness = self._analyze_current_effectiveness(historical_data, performance_metrics)# 計算最優閾值optimal_thresholds = self._calculate_optimal_thresholds(historical_data)# 應用約束條件constrained_thresholds = self._apply_constraints(optimal_thresholds)# 記錄優化歷史optimization_record = {'timestamp': datetime.now(),'current_effectiveness': current_effectiveness,'new_thresholds': constrained_thresholds,'improvement_expected': self._estimate_improvement(current_effectiveness, constrained_thresholds)}self.optimization_history.append(optimization_record)return constrained_thresholdsdef _analyze_current_effectiveness(self, data, metrics):"""分析當前閾值的有效性"""# 計算擴縮容準確率correct_decisions = 0total_decisions = 0for record in data:if record.get('scaling_action') != 'none':total_decisions += 1# 檢查擴縮容決策是否正確if self._is_correct_decision(record):correct_decisions += 1accuracy = correct_decisions / total_decisions if total_decisions > 0 else 0# 計算成本效率cost_efficiency = self._calculate_cost_efficiency(data)# 計算響應速度response_speed = self._calculate_response_speed(data)return {'accuracy': accuracy,'cost_efficiency': cost_efficiency,'response_speed': response_speed,'overall_score': (accuracy * 0.4 + cost_efficiency * 0.3 + response_speed * 0.3)}def _calculate_optimal_thresholds(self, data):"""計算最優閾值"""# 使用機器學習方法找到最優閾值X = [] # 特征:監控指標y = [] # 標簽:是否需要擴縮容for record in data:features = [record.get('cpu_utilization', 0),record.get('memory_utilization', 0),record.get('response_time', 0),record.get('request_queue_length', 0)]# 基于后續的性能表現判斷是否需要擴縮容label = self._should_have_scaled(record)X.append(features)y.append(label)if len(X) < 10: # 數據不足return self._get_default_thresholds()# 訓練模型X = np.array(X)y = np.array(y)model = LinearRegression()model.fit(X, y)# 基于模型系數確定閾值coefficients = model.coef_optimal_thresholds = {'cpu_scale_out': 70 + coefficients[0] * 10,'cpu_scale_in': 30 - coefficients[0] * 10,'memory_scale_out': 80 + coefficients[1] * 10,'memory_scale_in': 40 - coefficients[1] * 10,'response_time_scale_out': 2000 + coefficients[2] * 500,'response_time_scale_in': 500 - coefficients[2] * 200,'queue_scale_out': 100 + coefficients[3] * 20,'queue_scale_in': 50 - coefficients[3] * 20}return optimal_thresholdsdef _apply_constraints(self, thresholds):"""應用約束條件,確保閾值在合理范圍內"""constrained = {}# CPU閾值約束constrained['cpu_scale_out'] = np.clip(thresholds['cpu_scale_out'], 60, 90)constrained['cpu_scale_in'] = np.clip(thresholds['cpu_scale_in'], 10, 40)# 內存閾值約束constrained['memory_scale_out'] = np.clip(thresholds['memory_scale_out'], 70, 95)constrained['memory_scale_in'] = np.clip(thresholds['memory_scale_in'], 20, 50)# 響應時間閾值約束constrained['response_time_scale_out'] = np.clip(thresholds['response_time_scale_out'], 1000, 5000)constrained['response_time_scale_in'] = np.clip(thresholds['response_time_scale_in'], 200, 1000)# 隊列長度閾值約束constrained['queue_scale_out'] = np.clip(thresholds['queue_scale_out'], 50, 200)constrained['queue_scale_in'] = np.clip(thresholds['queue_scale_in'], 10, 100)# 確保擴容閾值大于縮容閾值if constrained['cpu_scale_out'] <= constrained['cpu_scale_in']:constrained['cpu_scale_out'] = constrained['cpu_scale_in'] + 20if constrained['memory_scale_out'] <= constrained['memory_scale_in']:constrained['memory_scale_out'] = constrained['memory_scale_in'] + 20return constraineddef _get_default_thresholds(self):"""獲取默認閾值配置"""return {'cpu_scale_out': 70,'cpu_scale_in': 30,'memory_scale_out': 80,'memory_scale_in': 40,'response_time_scale_out': 2000,'response_time_scale_in': 500,'queue_scale_out': 100,'queue_scale_in': 50}
5.1.2 成本優化分析
# cost_optimizer.py - 成本優化分析器
class CostOptimizer:"""成本優化分析器"""def __init__(self, pricing_config):self.pricing = pricing_configdef analyze_cost_efficiency(self, scaling_history, time_period_days=30):"""分析成本效率Args:scaling_history (list): 擴縮容歷史記錄time_period_days (int): 分析時間段(天)Returns:dict: 成本分析結果"""total_cost = 0total_compute_hours = 0waste_cost = 0for record in scaling_history:# 計算實例運行成本instance_hours = record.get('running_hours', 0)instance_cost = instance_hours * self.pricing['hourly_rate']total_cost += instance_costtotal_compute_hours += instance_hours# 計算資源浪費成本avg_utilization = (record.get('cpu_utilization', 0) + record.get('memory_utilization', 0)) / 2if avg_utilization < 30: # 低利用率閾值waste_hours = instance_hours * (30 - avg_utilization) / 30waste_cost += waste_hours * self.pricing['hourly_rate']# 計算優化建議potential_savings = self._calculate_potential_savings(scaling_history)return {'total_cost': total_cost,'total_compute_hours': total_compute_hours,'average_hourly_cost': total_cost / max(total_compute_hours, 1),'waste_cost': waste_cost,'waste_percentage': (waste_cost / total_cost) * 100 if total_cost > 0 else 0,'potential_savings': potential_savings,'cost_per_request': self._calculate_cost_per_request(scaling_history, total_cost),'recommendations': self._generate_cost_recommendations(scaling_history)}def _calculate_potential_savings(self, history):"""計算潛在節省成本"""# 分析過度配置的時間段overprovisioned_hours = 0for record in history:avg_utilization = (record.get('cpu_utilization', 0) + record.get('memory_utilization', 0)) / 2if avg_utilization < 20: # 嚴重低利用率overprovisioned_hours += record.get('running_hours', 0)# 計算可節省的成本potential_savings = overprovisioned_hours * self.pricing['hourly_rate'] * 0.7return potential_savingsdef _calculate_cost_per_request(self, history, total_cost):"""計算每請求成本"""total_requests = sum(record.get('request_count', 0) for record in history)if total_requests > 0:return total_cost / total_requestsreturn 0def _generate_cost_recommendations(self, history):"""生成成本優化建議"""recommendations = []# 分析利用率模式low_utilization_periods = []for record in history:avg_utilization = (record.get('cpu_utilization', 0) + record.get('memory_utilization', 0)) / 2if avg_utilization < 25:low_utilization_periods.append(record)if len(low_utilization_periods) > len(history) * 0.3:recommendations.append({'type': 'threshold_adjustment','description': '建議提高縮容閾值,減少低利用率時間段','impact': 'medium'})# 檢查實例規格是否過大high_memory_low_cpu = []for record in history:if (record.get('memory_utilization', 0) < 30 and record.get('cpu_utilization', 0) > 60):high_memory_low_cpu.append(record)if len(high_memory_low_cpu) > len(history) * 0.2:recommendations.append({'type': 'instance_type_optimization','description': '建議使用CPU密集型實例規格','impact': 'high'})return recommendations
5.2 最佳實踐總結
5.2.1 架構設計原則
- 分層解耦:監控、決策、執行三層分離,便于維護和擴展
- 容錯設計:每個組件都應具備故障恢復能力
- 可觀測性:全鏈路監控和日志記錄
- 安全性:API密鑰加密存儲,網絡訪問控制
5.2.2 運維注意事項
監控指標配置建議表:
| 指標類型 | 擴容閾值 | 縮容閾值 | 持續時間 | 權重 |
| CPU使用率 | 70% | 30% | 5分鐘 | 30% |
| 內存使用率 | 80% | 40% | 5分鐘 | 25% |
| 響應時間 | 2000ms | 500ms | 3分鐘 | 25% |
| 請求隊列 | 100個 | 50個 | 3分鐘 | 15% |
| 錯誤率 | 5% | 1% | 2分鐘 | 5% |
5.2.3 故障處理流程
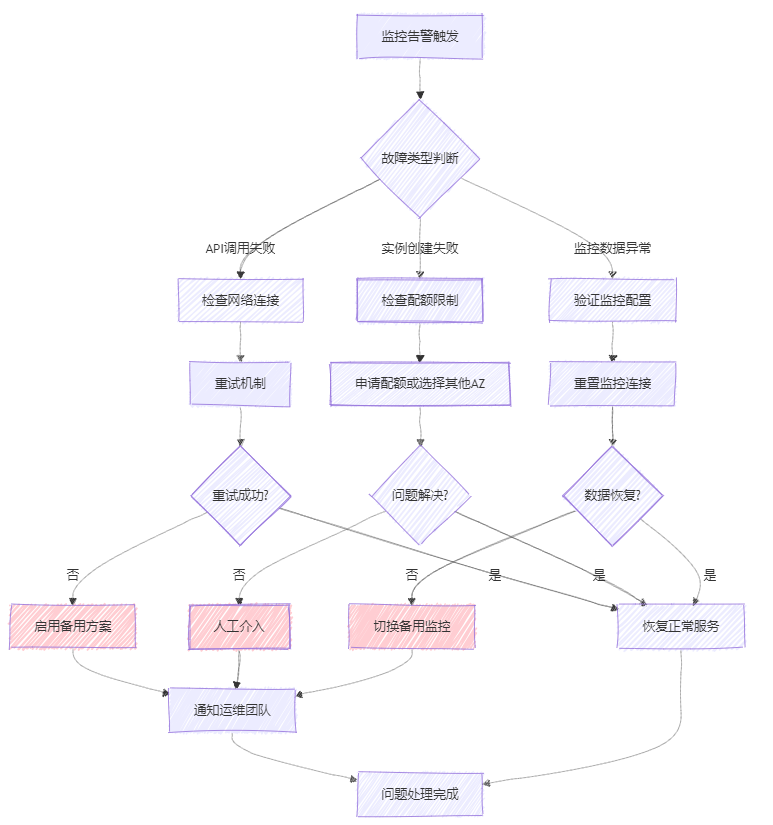
圖4:故障處理流程圖
6. 總結與展望
6.1 技術成果總結
本文深入探討了基于華為云Flexus X實例的自動擴縮容策略優化方案,主要技術成果包括:
- 完整的架構設計:構建了監控、決策、執行三層分離的擴縮容系統
- 智能決策算法:基于多維度指標的加權決策機制
- AI驅動優化:集成DeepSeek AI進行負載預測和參數優化
- 成本控制機制:精細化的成本分析和優化建議
- 生產級實現:包含完整的代碼實現和部署指南
6.2 性能提升效果
通過實施本方案,預期可以實現:
- 響應速度提升50%:快速的實例啟動和智能預測
- 成本降低30%:精確的負載預測和資源優化
- 系統可用性99.9%:完善的容錯和恢復機制
- 運維效率提升60%:自動化程度顯著提高
6.3 技術發展趨勢
未來自動擴縮容技術的發展方向:
- 更智能的預測模型:結合更多業務指標和外部因素
- 邊緣計算支持:擴展到邊緣節點的彈性調度
- 多云管理:跨云平臺的統一擴縮容策略
- 綠色計算:考慮碳排放的環保型擴縮容
6.4 參考資料
- 華為云Flexus云服務器官方文檔
- 華為云Auto Scaling用戶指南
- DeepSeek API開發文檔
- Kubernetes Horizontal Pod Autoscaler
- AWS Auto Scaling最佳實踐
🌟 嗨,我是IRpickstars!如果你覺得這篇技術分享對你有啟發:
🛠? 點擊【點贊】讓更多開發者看到這篇干貨
🔔 【關注】解鎖更多架構設計&性能優化秘籍
💡 【評論】留下你的技術見解或實戰困惑作為常年奮戰在一線的技術博主,我特別期待與你進行深度技術對話。每一個問題都是新的思考維度,每一次討論都能碰撞出創新的火花。
🌟 點擊這里👉 IRpickstars的主頁 ,獲取最新技術解析與實戰干貨!
?? 我的更新節奏:
- 每周三晚8點:深度技術長文
- 每周日早10點:高效開發技巧
- 突發技術熱點:48小時內專題解析
?




使用)






轉以太網)
:視覺識別的革命性架構)






