一、目錄
kmp動態規劃簡易處理next數組+字符函數與字符串函數
- 一、目錄
- 二、引言
- C語?標準庫中提供了?系列庫函數
- 三、字符分類函數(字符相關的函數)
- 推薦一個網站
- 四、字符轉換函數(字符相關的函數)
- 五、strlen(字符串相關的函數)
- strlen函數的模擬實現
- 方式一:計數器記錄字符個數
- 方式二:**指針 - 指針 = 指針之間的元素個數**
- 方式三:遞歸(一種不創建臨時變量就能計算字符串長度的方法)
- 六、strcpy的使用和模擬
- strcpy的模擬實現:
- 七、strcat的使用和模擬
- 易混:0,'0',空格,'\0',NULL----他們不一樣哦~
- 模擬實現strcat
- 博主剛剛寫代碼的時候,犯了一個小錯誤,發出來給小伙伴們看看,希望有我踩過的坑,你們不要踩~
- 字符串自己給自己追加,能實現嗎?
- 八、strcmp函數的使用和模擬
- 這里補充一個知識點:ASCII編碼和Unicode編碼
- 打開文件內容出現亂碼的本質
- 返回值:
- strcmp函數的模擬實現:
- 九、strncpy,strncat,strcmp函數
- 1、strcpy和strncpy
- 2、strcat和strncat(拷貝好相應的字符數量后會在末尾自動加上\0)
- 3、strcmp和strncmp
- 十、strtok函數
- strtok函數的使用方法:
- 十一、strstr函數
- 使用方法
- strstr模擬實現:字符串中找字符串,這里是暴力匹配的過程
- 情景1:一次匹配成功
- 情景2:多次匹配
- 情景3:str1先遇到\0,不可能匹配成功
- 暴力尋找子串程序實現:實際上我們變量選擇最多的,情景盡量都能考慮到。
- kmp算法:
- kmp算法的工作原理
- 接下來看看next數組的生成:
- 字符串的一些算法實現(王道考研):
- StrLength
- ClearString
- SubString
- StringCmp:
- Index:
- 十二、strerror函數的使用
- 這樣講未免有些抽象,我一句一句給大家講講
- 注解:如何看當前目錄是否有此文件
- 到這里也算是懂得strerror工作原理了
- 十三、perror函數
- 使用
二、引言
C語?標準庫中提供了?系列庫函數
在編程的過程中,我們經常要處理字符和字符串,為了?便操作字符和字符串,C語?標準庫中提供了?系列庫函數,接下來我們就學習?下這些函數。
三、字符分類函數(字符相關的函數)
首先介紹一下c語言中有一系列專門做字符分類的函數,也就是這些函數屬于什么類別的,這里所有的函數使用前都要包含ctype.h

推薦一個網站
函數的使用文檔請看c/c++官網
網站打開是這樣的,在search欄里面搜索相應的庫函數,即可跳轉到相應的函數介紹頁面

這里我示范islower函數:

int islower(int c):
- 函數的形參是整形,其實傳入字符,字符的ASCII碼值都是可以的,因為字符的本質就是ASCII碼值。
- 函數功能:檢查字符c是否是一個小寫字母
- 返回值:如果是小寫字母就返回一個非零整數,如果不是則返回0。
#include<stdio.h>
#include<ctype.h>
int main()
{int ret = islower('a');printf("%d\n", ret);ret = islower('0');printf("%d\n", ret);ret = islower('A');printf("%d\n", ret);return 0;
}
運行結果是:

再來看一個idigit函數

int isdigit(int c)
- 形參是ASCII碼或者字符,也就是整形家族,與上面的lower函數一樣
- 函數功能:檢查一個字符時不是十進制字符,順便一提,在計算機里,以0b或者0B作為前綴的是二進制數,以0或者0O為前綴作為八進制數,以0x為前綴作為十六進制數。
- 返回值:如果是,返回非0值,如果不是返回0值
isxdigit函數則是檢查一個字符是否是十六進制字符的,其余的解釋均與isdigit函數一致

#include<stdio.h>
#include<ctype.h>
int main()
{int ret = isdigit('9');printf("%d\n", ret);ret = isdigit('0');printf("%d\n", ret);ret = isdigit('A');printf("%d\n", ret);ret = isxdigit('A');printf("%d\n", ret);return 0;
}
運行結果是:

當然在我們實際使用的時候,其實是拿他的返回值做判斷的
練習:
- 寫?個代碼,將字符串中的?寫字?轉?寫,其他字符不變。
提示:小寫字母ASCII碼值 - 32 == 大寫字母ASCII值。
#include<stdio.h>
#include<ctype.h>
int main()
{char arr[] = "I am a student.";// 0123456789... 注意:空格的可不是\0,他是有自己的ASCII值的,\0是字符串的結束符int i = 0;while (arr[i] != '\0'){if (islower(arr[i])){arr[i] -= 32;}i++;}printf("%s\n",arr);return 0;
}
輸出結果為:

四、字符轉換函數(字符相關的函數)
c語言中兩個庫函數:
int tolower ( int c ); //將參數傳進去的?寫字?轉?寫
int toupper ( int c ); //將參數傳進去的?寫字?轉?寫


測試一下:
#include<stdio.h>
#include<ctype.h>
int main()
{char ch = toupper('a');char ch1 = tolower('A');int ch2 = toupper('a');int ch3 = tolower('A');printf("%c\n", ch);printf("%c\n", ch1);printf("%d\n", ch2);printf("%d\n", ch3);return 0;
}運行結果是:打印字符或者字符的ASCII碼值都是可以的,本質上就是ASCII碼

當然通過字符轉換函數也可以改變我們剛剛練習的代碼:可以看出庫函數是c語言封裝一系列功能,幫助我們簡化代碼的操作。
#include<stdio.h>
#include<ctype.h>
int main()
{char arr[] = "I am a student.";int i = 0;while (arr[i] != '\0'){if (islower(arr[i]))//if(arr>'a' && arr<'z'),這樣寫也是可以的{arr[i] = toupper(arr[i]);//arr[i] -= 32;,另一種寫法}i++;}printf("%s",arr);return 0;
}
運行結果仍是:

五、strlen(字符串相關的函數)
這個函數也算是老朋友了,之前將指針6的時候有詳細講過。統計的是字符串’\0’之前的字符個數。
size_t strlen ( const char * str );
參數傳遞是指針,也就是字符串首字符地址,指針一直往后走,直到找到‘\0’,統計其之前遍歷了多少字符,將字符的個數以無符號整形返回。
使用的時候注意幾點:
- 1、字符串以 ‘\0’ 作為結束標志,strlen函數返回的是在字符串中 ‘\0’ 前?出現的字符個數(不包含 ‘\0’ )。
- 2、參數指向的字符串必須要以 ‘\0’ 結束。
- 3、注意函數的返回值為 size_t,是?符號的( 易錯 )
- 4、strlen的使?需要包含頭?件
- 5、學會strlen函數的模擬實現
#include<stdio.h>
#include<string.h>
int main()
{char arr[] = "abcdef";printf("%zd\n", strlen(arr));//數組名 == 數組首元素地址char arr1[] = { 'a','b','c','d','e','f' };printf("%zd\n", strlen(arr1));//隨機值return 0;
}

隨機值原因:因為strlen從頭開始找,一直沿著內存空間向后走,直到找到’0’才停止,返回之前走的步數(遍歷的字符數量),而我們數組中并沒有給放置’\0’,所以他一直向后找,直到找到內存中原始就存放的\0,才停下來,而在原始內存中找\0是隨機的,因為你并不知道內存初始值都放著什么,這是編譯器自己決定的,對用戶是透明的。 返回值是size_t,size_t是無符號整型(長整型,長長整型)的統一名稱,可以是unsigned int,unsigned long,也可以是 unsigned long long。(包含0,正整數)
返回值是size_t,size_t是無符號整型(長整型,長長整型)的統一名稱,可以是unsigned int,unsigned long,也可以是 unsigned long long。(包含0,正整數)
sizeof的返回值也是size_t,sizeof是一個操作符,計算的是操作數在內存中占用空間的大小,單位是字節,不關注操作數的內容,僅關注其表達式最左側操作數在內存中的大小
這里有一個易錯點:
#include<stdio.h>
#include<string.h>
int main()
{//判斷字符串的大小if (strlen("abc") - strlen("abcdef")>0){printf(">");}else{printf("<=");}return 0;
}運行結果:

原因竟是無符號整形引起的:
無符號整型 - 無符號整型 = 無符號整型
3 - 6 = -3
如果將-3當做無符號整型的話,那么就是-3在內存中的補碼被當做是無符號整型了,也就是最后這一行代表的無符號整數,是一個超級大的正數。所以輸出一個大于號。

修改方法有兩種:輸出結果都是<=
//強轉int
#include<stdio.h>
#include<string.h>
int main()
{//判斷字符串的大小if ((int)strlen("abc") - (int)strlen("abcdef") > 0){printf(">");}else{printf("<=");}return 0;
}
//直接使用比較運算符
#include<stdio.h>
#include<string.h>
int main()
{//判斷字符串的大小if (strlen("abc")>(int)strlen("abcdef")){printf(">");}else{printf("<=");}return 0;
}
strlen函數的模擬實現
方式一:計數器記錄字符個數
#include<stdio.h>
#include<string.h>
#include<assert.h>
size_t my_strlen(const char* ch)//不想修改ch數組內部的值,只是對其盡進行訪問,const修飾誰,誰的值就不能被修改,* ch也就是ch數組中存放的字符串內容,char * const ch代表的就是不可修改ch指針。
{size_t count = 0;assert(ch != NULL);//涉及到指針的解引用操作,所以對指針判空(空指針不可解引用)while (*ch != '\0'){count++;//先判斷字符是否為空,再計數加1ch++;//判斷完之后到下一個字符}return count;
}
int main()
{char ch[] = "abcdef";size_t ret = my_strlen(ch);printf("%zd\n", ret);return 0;
}

方式二:指針 - 指針 = 指針之間的元素個數

#include<stdio.h>
#include<string.h>
#include<assert.h>
size_t my_strlen(const char* ch)//不想修改ch數組內部的值,只是對其進行訪問
{const char* start = ch;//類型一致的賦值,記錄字符串的初始位置assert(ch != NULL);//涉及到指針的解引用操作,所以對指針判空(空指針不可解引用)while (*ch != '\0'){ch++;//一直走,直到遇到\0}return ch - start;
}
int main()
{char ch[] = "abcdef";size_t ret = my_strlen(ch);printf("%zd\n", ret);return 0;
}
方式三:遞歸(一種不創建臨時變量就能計算字符串長度的方法)
my_strlen(“abcdef\0”)
1+my_strlen(“bcdef\0”)
1+1+my_strlen(“cdef\0”)
1+1+1+my_strlen(“def\0”)
1+1+1+1+my_strlen(“ef\0”)
1+1+1+1+1+my_strlen(“f\0”)
1+1+1+1+1+1+my_strlen(“\0”)
1+1+1+1+1+1+0;
遞歸思想:遞推:將一個大問題層層拆分為一個個與原問題求解方法類似的子問題,剝下來一層+子問題,再剝下來一層+子問題…直到不能再剝,開始回歸。
- 首先相信my_strlen函數能夠記錄字符串的長度
- 每次把最左邊的字符拿出來,就是1長度,再加上剩余字符串長度就是總字符串長度
- 最終到\0的時候返回0值,也就是它是不占長度的
size_t my_strlen(const char* ch)
{if (*ch != '\0'){return 1 + my_strlen(ch + 1);//每一次都返回最左邊的長度1,加上后面的長度,也就是去掉最左邊字符,指針加1的長度}else{return 0;//識別到\0返回0,不包含這個長度}
}
int main()
{char ch[] = "abcdef";size_t ret = my_strlen(ch);printf("%zd\n", ret);return 0;
}
六、strcpy的使用和模擬
char* strcpy(char * destination, const char * source );
將原指針指向的字符串,拷貝到目的指針指向的空間中,包含‘\0’,返回目標空間的起始地址,為了能夠實現鏈式訪問。
注意幾點使用:
- 源字符串必須以 ‘\0’ 結束。
- 會將源字符串中的 ‘\0’ 拷?到?標空間。
- ?標空間必須?夠?,以確保能存放源字符串。
- ?標空間必須可修改。
- 學會模擬實現。
#include<stdio.h>
#include<string.h>
#include<ctype.h>
int main()
{char arr[] = "abcdef";char arr1[20] = { 0 };strcpy(arr1, arr);printf("%s\n", arr1);return 0;
}

1、那現在我們來看看內存中的樣子,按下F11,點擊調試,再按照圖片中的順序,隨便點擊一個監視窗口,在監視窗口中輸入arr,arr1,繼續按下F11,開始時程序從int main開始進入,接著每按一次F11就走一句代碼。

走到這句代碼,由于之前的代碼中arr1中的內容全是\0,所以看不出arr中的\0有沒有被拷貝進去,所以我把arr1中的內容改成了"xxxxxxxxxxx"。

走完這句代碼,可以發現\0被拷貝進去了

2、當原字符串中并不是以\0為結尾的時候,就會導致程序不知道拷貝內容的時候,到底在哪里結束。strcpy停不下來。

3、如果目標空間不夠大,是放不下原字符串的。

4、目標空間必須是可修改的,如果是常量字符串是不可被修改的,是被放置在只讀數據區。

strcpy的模擬實現:
#include<stdio.h>
#include<string.h>
char* my_strcpy(char* dest,const char* src)//不期望源指針所指向的字符串內容被修改,而目的空間必須被修改
{char* parr = dest;//記錄初始目標空間位置,以便后續返回空間地址assert(dest && src);//指針判空:空指針不能解引用,有一個為空就是0,為假報錯終止。while (*src != '\0'){*dest = *src;src++;dest++;}*dest = *src;return parr;
}
int main()
{char arr1[] = "abcdef";char arr2[20] = { 0 };char* ret = my_strcpy(arr2, arr1);printf("%s\n", arr2);printf("%s\n",ret);printf("%s\n",my_strcpy(arr2, arr1));return 0;
}

過程:
1、源指針和目標指針都指向自己的空間的起始位置
2、將源指針src解引用得到它所指的內存單元中的值,把它放進目標指針dest解引用后的空間,如圖每一個向下的箭頭。
src和dest都向后走,直到src解引用后遇到\0,也就是src的字符串末尾,停下循環。
3、\0的處理在循環外面,最后src指向的是\0,所以直接解引用將\0放在dest解引用的空間,如圖最后一個圈+下箭頭。
運行結果:

簡易寫法:直接將循環判斷條件更改,*dest++ = *src++
#include<stdio.h>
#include<string.h>
char* my_strcpy(char* dest, const char* src)//不期望源指針所指向的字符串內容被修改,而目的空間必須被修改
{char* parr = dest;assert(dest && src);//assert(dest != NULL); assert(src != NULL);while (*dest++ = *src++);return parr;
}
int main()
{char arr1[] = "abcdef";char arr2[20] = { 0 };char* ret = my_strcpy(arr2, arr1);printf("%s\n", arr2);printf("%s\n", ret);printf("%s\n", my_strcpy(arr2, arr1));return 0;
}++運算符后置,代表先把值拷貝(解引用操作),再判斷(while),再加加(++)。
這樣做就可以將\0和其他值一樣被拷貝進去,不需要單獨處理,每次拷貝一個值,拷貝完判斷是否為\0,不是就將src和dest都加加,往后移。而當src解引用到\0時,賦值給dest空間(將\0及其以前的字符串都拷貝進去了)后,整個表達式就是0(賦值表達式的結果是最左操作數的值),在判斷為假,就跳出循環了。
- 注意:因為是循環就得有循環語句,所以while后我加上了一個分號,代表是跳過循環語句或者循環語句為空執行的意思。

七、strcat的使用和模擬
string+concatenate 字符拼接,或者叫成字符串的追加。

1、參數:目標指針,原指針。
2、作用:將原地址指向的字符串內容,連接到目標指針指向的字符串的末尾,是將目標字符串中\0覆蓋的拷貝。
3、返回值:返回目標空間的起始地址。
使用注意點:
- 源字符串必須以 ‘\0’ 結束。–保證拷貝的時候知道拷貝到哪結束。
- ?標字符串中也得有 \0 ,否則沒辦法知道追加從哪?開始。
- ?標空間必須有?夠的?,能容納下源字符串的內容。
- ?標空間必須可修改。–不可以是常量字符串,因為其是只讀數據區內容,是不可修改的。
- 字符串??給??追加,如何?--提前預告,會導致死循環打印這個內容,但是不同編譯器處理不同。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[20] = "hello ";char arr2[] ="world.";char* ret = strcat(arr1, arr2);printf("%s\n", arr1);printf("%s\n", ret);return 0;
}

易混:0,‘0’,空格,‘\0’,NULL----他們不一樣哦~
1、0代表數字0,非字符沒有ASCII碼值,字符才有ASCII碼值。
2、‘0’代表的是字符0,ASCII碼值是48。
3、空格不是’\0’,空格的ASCII值是32。
4、\0 :null 字符,代表沒有內容, \0 就是 \ddd 這類轉義字符的?種,?于字符串的結束標志,其ASCII碼值是0.
注解:下?2種轉義字符可以理解為:字符的8進制或者16進制表?形式
- \ddd :d d d表?1~3個?進制的數字。 如: \130 表?字符X
- \xdd :d d表?2個?六進制數字。 如: \x30 表?字符0
5、NULL:代表就是空,是0,為了區分指針的0值和變量的0值
int* p = NULL;
int a = 0;
一看到NULL就知道是指針空值了。
字符中有0,打印不會停下來,代表’0’并不是字符串結束符。

發現拷貝提前了,說明’\0’是字符串結束符。

模擬實現strcat
#include<stdio.h>
#include<string.h>
char* my_strcat(char* dest, const char* src)
{char* ret = dest;assert(dest && src);while (*dest )//找到\0,開始位置dest++;//一直往下走while (*dest++ = *src++)//一個一個字符拷貝,直到拷貝到src的末尾\0,結束;return ret;//返回目標空間的起始位置
}
int main()
{char arr1[20] = "hello ";char arr2[] = "world.";char* ret = my_strcat(arr1, arr2);printf("%s\n", arr1);printf("%s\n", ret);return 0;
}過程是這樣的:


1、目標指針和源指針都指向自己空間開始位置
2、dest指針向后遍歷直到找到\0(開始拼接的地方),將\0位置解引用出空間,填入src解引用出的字符,如圖中的向上箭頭,解引用后兩指針向后移動,重復這個過程。
3、直到src解引用出\0(結束),拼接結束。
博主剛剛寫代碼的時候,犯了一個小錯誤,發出來給小伙伴們看看,希望有我踩過的坑,你們不要踩~
#include<stdio.h>
#include<string.h>
char* my_strcat(char* dest, const char* src)
{char* ret = dest;assert(dest && src);while (*dest++)//找到\0,開始位置;while (*dest++ = *src++)//一個一個字符拷貝,直到拷貝到src的末尾\0,結束;return ret;//返回目標空間的起始位置
}
int main()
{char arr1[20] = "hello ";char arr2[] = "world.";char* ret = my_strcat(arr1, arr2);printf("%s\n", arr1);printf("%s\n", ret);return 0;
}

1、我圖省事,直接把第一個循環條件寫成了dest++
2、我原本的意思是讓指針解引用,判斷是否為結束,不是就往后走,直到找到\0停下來
3、調試的時候發現:arr1中的內容,在字符串中多了一個\0,正常應該是hello world\0.現在是hello \0 world,所以打印的時候回提前停止,遇到\0便停了下來,結果就是hello 了。注:窗口還是監視窗口
4、然后追其原因,我發現當dest解引用找到\0之后,dest直接++了,也就是它直接保留了\0,并沒有像原來一樣把\0給覆蓋掉,而是直接就從\0后面開始賦值了
5、那么正常的是,如果解引用之后遇到\0,就應該退出循環,不應該將dest++,也就是不能再讓他后移了,這樣后來拷貝的時候才能把這個\0給覆蓋掉,正常改法就是我寫的第一個代碼,x循環內部寫dest++。


字符串自己給自己追加,能實現嗎?
#include<stdio.h>
#include<string.h>
char* my_strcat(char* dest, const char* src)
{char* ret = dest;assert(dest && src);while (*dest)//找到\0,開始位置dest++;while (*dest++ = *src++)//一個一個字符拷貝,直到拷貝到src的末尾\0,結束;return ret;//返回目標空間的起始位置
}
int main()
{char arr1[20] = "abc";char* ret = my_strcat(arr1, arr1);printf("%s\n", arr1);printf("%s\n", ret);return 0;
}拿我們自己寫的strcpy函數測試,發現服務器崩掉了。

我們來找找原因:

1、首先dest找到\0所在位置,也就是開始位置。
2、將src中的內容開始拷貝到接下來的空間中,拷貝完一個,兩指針就向后走一步,發先,永遠向后走都都走不到有\0的位置讓拷貝結束,這種情況就相當于原字符串沒有\0,會讓拷貝停不下來。
那么我們使用strcpy函數呢?

發現是可行的,其實說明的是編譯器內部實現的strcpy算法和我們自己所使用的并不是一樣的,它內部是有防止出現拷貝停不下來行為的方法的,說明編譯器還是比我們代碼能力強的多呀哈哈哈。
but!!!
1、strcpy函數并不保證字符串的自拼接,有可能你換一個編譯器結果就不一樣了,因為在不同編譯器中,他們庫函數實現是有可能不一樣的,其他編譯器不一定有這種機制。
八、strcmp函數的使用和模擬

參數:指向字符串1和字符串2的起始位置的指針。其實傳遞字符串,傳遞的就是字符串的首地址。
功能:對比字符串1和字符串2的對應位置字符的ASCII碼值的大小,注意比較的不是字符串的長度。
注:當字符串長度不一樣的時候,前面的字符串都一樣,那就比較\0與下一個字符的大小,比完之后就能判斷大小了,不用在比下去了
這里補充一個知識點:ASCII編碼和Unicode編碼
- 每一個英文字符在存儲在計算機中的時候,都會翻譯成對應的二進制數,一個英文字符翻譯為二進制數包括其高四位,低四位(比特位),這八個比特位構成了一個字節,所以一個英文字母按照ASCII字符集編碼規則轉為對應的二進制數存儲在計算機中,每個字符大小是一個字節。比如空格這個字符,是0010 0000存儲在計算機中,轉換為十進制數就是32。其余的英文字符同樣的道理,這些英文字符集就叫做ASCII字符集,考研中知道這種英文字符集就夠了。
- 但是只有8個比特位,顯然是不夠存儲英文字符以外的其他字符的,因為8的bit位僅有2的8次冪個態,也就是256個態,也就是256個不同組合二進制ASCII編碼,也就是256個字符。
- 那么出現了另外一種字符集,叫做Unicode字符集,包括韓文,日文,中文,俄羅斯文等等,這些字符的數量遠超256個,它給這些字符編碼的規則就很多,比如常見的UTF-8,UTF-16等等,編碼規則不一樣,同一個字符所表示的二進制序列就不同,長度也可能不同,當然你自己也可以給它編碼,這就是你獨特的編碼方案,而當你編寫文件和打開文件使用同一個編碼方案的時,打開就會顯示出相應的內容。
打開文件內容出現亂碼的本質
- 請看下面這種情況,相信很多小伙伴都遇到過吧亂碼問題,本質上就是編碼和解碼的方案不同,你編寫的時候是采用一套編碼方案的,將你寫的字符翻譯成對應的二進制數存儲在計算機里面,在你使用一個軟件打開的時候,這個軟件默認你使用的是另一套編碼規則,將存儲在計算機中的這些二進制采用另一套編碼規則翻譯的時候就會翻譯出與原來不同的內容。
- 當然這個有以下場景,你可以利用上,比如你賣給其他公司一套算法,但是你不想讓這個公司知道這個函數內部是如何實現的,你只想告訴他使用的方法,那么你就可以將你編寫內部實現的說明采用你選擇的一套編碼方案,但是你并不告訴公司,這樣只有你自己能查看內部實現,即使公司獲得了這樣的內部實現文件,也查看不了。

返回值:
- 如果字符串1>字符串2,返回一個大于0的值。
- 如果字符串1=字符串2,返回0。
- 如果字符串1<字符串2,返回一個小于0的值。
注:vs中是默認大于0的值是1,小于0的值就是-1。在其他編譯器中可能就是其他形式,但是都會滿足 >0, <0這個條件。
#include<stdio.h>
#include<string.h>
int main()
{char* str1 = "abcdef";//用字符指針存放字符串的首地址char* str2 = "abq";int ret = strcmp(str1, str2);printf("%d\n", ret);return 0;
}

#include<stdio.h>
#include<string.h>
int main()
{char* str1 = "abcdef";//用字符指針存放字符串的首地址char* str2 = "abcdef";int ret = strcmp(str1, str2);printf("%d\n", ret);return 0;
}

字符數組的寫法也是可以的,因為字符數組的字符串的首字符的首地址就是數組名
#include<stdio.h>
#include<string.h>
int main()
{char* str1 = "abf";//char str1[] = "abf";char* str2 = "abcdef";//char str2[] = "abcdef";int ret = strcmp(str1, str2);printf("%d\n", ret);return 0;
}


strcmp函數的模擬實現:
1、這種寫法完全是基于vs這個編譯器實現的。沒體現>0,<0這種的返回值。
#include<stdio.h>
#include<string.h>
int my_strcmp(const char* str1,const char* str2)
{ assert(str1 && str2);while (*str1 == *str2)//如果字符串前面都相等,往后走{if (*str1 == '\0')//全都相等直到走到\0,說明兩個字符串相同。return 0;str1++;//后走str2++;}if (*str1 > *str2)//不相等字符開始比較return 1;else//不相等,不大于就剩小于了return -1;return 0;
}
int main()
{char* str1 = "abc";//用字符指針存放字符串的首地址char* str2 = "abcdef";int ret = my_strcmp(str1, str2);printf("%d\n", ret);return 0;
}
2、體現總體規則的代碼:
#include<stdio.h>
#include<string.h>
int my_strcmp(const char* str1,const char* str2)
{assert(str1 && str2);while (*str1 == *str2){if (*str1 == '\0')return 0;str1++;str2++;}return(*str1 - *str2);//字符相減就是ASCII碼值相減。正好比較的就是ASCII碼值的大小
}
int main()
{char* str1 = "abcdef";//用字符指針存放字符串的首地址char* str2 = "abq";int ret = my_strcmp(str1, str2);printf("%d\n", ret);return 0;
}

九、strncpy,strncat,strcmp函數
- 上面三個是不受長度限制的字符串函數,就是找\0,確定開始和終止。
- 下面三個是受長度限制的字符串函數,n是number的意思,他會規定拷貝幾個字符,連接幾個字符,比較幾個字符。更為靈活,按照需求可以做很多事情。
- 當然兩組函數其實vs編譯器認為是使用不安全的,如果將我們代碼的第一行紫色的東西注釋掉,使用這些函數就會報錯,所以其實除了scanf被vs認為不安全,這些會報錯,因為比如說你拷貝一個字符串到一個空間中,但是這個空間給的很小,不夠放,而這個函數本身是不具備檢查空間大小夠不夠的功能的,所以使用起來會有風險。


1、strcpy和strncpy
兩者之間差一個參數:num,代表拷貝的字符數量。
- 拷?num個字符從源字符串到?標空間。
- 如果源字符串的?度?于num,則拷?完源字符串之后,在?標的后邊追加0,直到num個。

不足六個字符,后面直接補上\0。

這樣的調試,并不能發現到底拷貝完之后到底會不會給你放\0結束符,由于char arr1[20]是一個局部變量,局部變量未初始化的值為0,所以arr1中其他的值就是0。
其實因為這樣打印出來也是xxxxxxxx。

所以我們可以這樣去調試:發現并沒有在結尾給我們放上結束符\0。sum是多少就拷貝多少個字符。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[20] = "abcdefyyyy";//用字符指針存放字符串的首地址char arr2[20] = "xxxxxxxxx";char* ret = strncpy(arr1, arr2,8);printf("%s\n", ret);return 0;
}

2、strcat和strncat(拷貝好相應的字符數量后會在末尾自動加上\0)
兩者之間差一個參數:num,代表追加的字符數量。
- 將source指向字符串的前num個字符追加到destination指向的字符串末尾,再追加?個 \0 字符
- 如果source 指向的字符串的?度?于num的時候,只會將字符串中到\0 的內容追加到destination指向的字符串末尾

還是一樣的問題,這樣調試是看不出來拼接好的時候有沒有給你放置\0。

所以我們這樣調試:可以看出它將3個x拼接到arr1的尾部了,并且還加上了一個\0結束符。

所以基于這個特性,我們就可以方便的實現字符串的自拷貝了,他會把拷貝好的內容加上\0。

3、strcmp和strncmp
兩者之間差一個參數:num,代表比較字符的數量。
- ?較str1和str2的前num個字符,如果相等就繼續往后?較,最多?較num個字?,如果提前發現不?樣,就提前結束,?的字符所在的字符串?于另外?個。
- 如果num個字符都相等,就是相等返回0



十、strtok函數
學過計算機網絡的同學應該知道,IP地址是采用點分十進制的形式,每一個點都分隔一個十進制數,如果是三段式就是網絡號,子網號,主機號。代表你的電腦(主機)在一個網絡中的唯一編號。
郵箱:郵箱名@域名.后綴。

- sep參數指向?個字符串,定義了?作分隔符的字符集合
比如. ,@和. ,寫作char* = “@.”;
- 第?個參數指定?個字符串,它包含了0個或者多個由sep字符串中?個或者多個分隔符分割的標記。
意思是每一個分隔符將字符串分為各個小段,每一個小段都叫做一個標記。比如192是一個標記,168也是一個標記,zpengwei也是一個標記等。
- strtok函數找到str中的下?個標記,并將其? \0 結尾,返回?個指向這個標記的指針。
strtok函數找到標記后,會將其末尾的分隔符更改為\0
strtok函數會改變被操作的字符串,所以被strtok函數切分的字符串?般都是臨時拷?的內容并且可修改。

- strtok函數的第?個參數不為 NULL ,函數將找到str中第?個標記,strtok函數將保存它在字符串中的位置。
第一次調用的時候,,第一個參數應為你傳入的字符串,找到第一個分隔符,改為\0后,跳過\0,記住當前位置。

- strtok函數的第?個參數為 NULL ,函數將在同?個字符串中被保存的位置開始,查找下?個標記。
除第一次調用以外,以后的調用,每一次都傳進去空指針就可以了,因為當前函數已經記住了當前指向字符串的位置了,只需要繼續向后走,再次找分隔符,改為\0后,跳過\0,記住當前位置,一直重復操作,直到找到\0的時候停止即可。

- 如果字符串中不存在更多的標記,則返回 NULL 指針。

strtok函數的使用方法:
- 返回值:char* 類型會返回每一次分割到的這個標記的起始位置。
#include<stdio.h>
#include<string.h>
int main()
{char str[40] = "zpengwei@yeah.net";char buf[256] = { 0 };//zpengwei@yeah.netstrcpy(buf, str);char* sep = "@.";char* ret = strtok(buf, sep);//zpengwei\0yeah.netprintf("%s\n", ret);//zpengweiret = strtok(NULL, sep);//yeah\0netprintf("%s\n", ret);//yeahret = strtok(NULL, sep);//net\0printf("%s\n", ret);//netret = strtok(NULL, sep);//NULLprintf("%s\n", ret);//(NULL)return 0;
}

然而在實際使用的時候,我們往往不知道或者很不愿意數有多少個分割符,在確定執行幾次函數。
所以巧妙地使用for循環可以實現在不知道有多少個分隔符的情況下還能把內容分隔開。
#include<stdio.h>
#include<string.h>
int main()
{char str[40] = "zpengwei@yeah.net";char buf[256] = { 0 };//zpengwei@yeah.netstrcpy(buf, str); //我覺得有好幾種寫法,都測試過了呢,沒問題,如果有其他簡潔寫法也可以留言哦~char* sep = "@."; //*ret !='\0'或ret != NULL或retfor (char* ret = strtok(buf, sep); *ret; ret = strtok(NULL, sep))//第一次調用后返回第一個標記指針,打印,后續每一次都只是記錄當前位置傳入NULL,打印下一個標記,直到最終ret指針指向空的空間。{printf("%s\n", ret);//每一次根據返回的每一個標記的起始地址開始打印,打印到其放置的\0之前的內容。}return 0;
}
執行順序就是:1234,然后一直循環執行234操作。

十一、strstr函數


使用方法
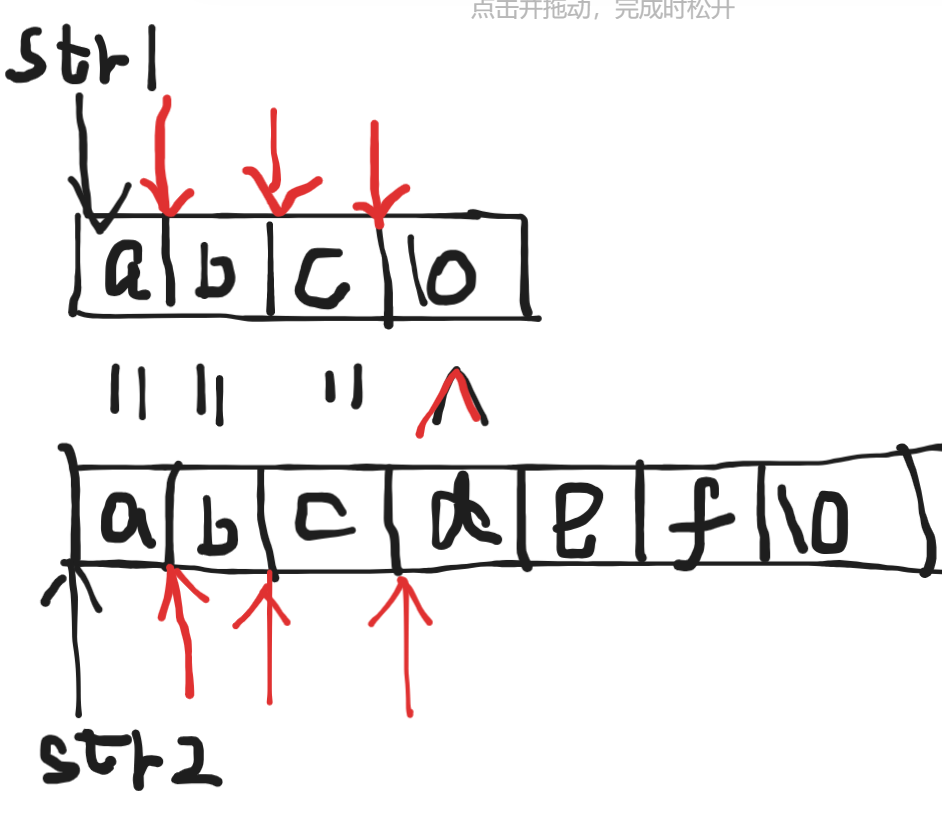
1、找到了:返回c的地址,所以打印的時候會把后續的字符串都打印出來。
#include<stdio.h>
#include<assert.h>
#include<string.h>
int main()
{char arr[] = "abcdef";char* p = "cde";char* ret = strstr(arr, p);printf("%s\n", ret);return 0;
}

2、沒找到:返回空指針

3、如果想在字符串中找空串,返回此字符串的首地址,也就是會把這個字符串再次打印出來
#include<stdio.h>
#include<assert.h>
#include<string.h>
int main()
{char arr[] = "abcedf";char* p = "";char* ret = strstr(arr, p);printf("%s\n", ret);return 0;
}

strstr模擬實現:字符串中找字符串,這里是暴力匹配的過程
我們考慮以下三種情景(可以多考慮,算法是多樣性的):
情景1:一次匹配成功
1、首先需要三個指針,str1和str2是函數參數傳過來的形參,而cur指針是current就是當前指針的意思,需要它記錄當前有可能匹配成功的臨時初始位置。
2、cur和str2開始匹配,如果匹配不成功,cur就往后走,直到和需要查找的字符串起始字符相同的時候,str1走到當前cur位置,str1開始和str2匹配,假設一次匹配成功,他們一起往后走,發現都相同,直到str2找到\0,結束符的時候,匹配結束,返回cur指針。
情景2:多次匹配

首先應該對cur解引用,看看str1中有沒有字符串。
1、此種情形需要新建3個指針,s1,s2,cur,圖里的p和arr是主程序中創建這兩個空間的時候指向他們的指針,str1和str2是模擬函數my_strstr中形參,接收這p和arr指針的形參。
2、cur向后走,找到第一個與s2首字符一樣的位置,說明當前位置是有可能匹配成功的,所以此時s1走到此處,等待與s2的匹配
3、s2和s1指針都向后走,發現有不匹配的,s2依據原來記錄的str2的字符初始位置返回,說明此處并不能匹配,而后面的也有可能匹配呀,所以cur指針需要向后走,再次找,直到找到與s2首字符相同的地方,這個地方有可能匹配成功,s1再來到cur的位置等待匹配,重復這樣的不走,直到完全匹配
4、匹配結果1、剛好str2走到\0了,說明匹配成功,返回cur指針
2、str1先走到\0,不用管,因為最終程序會停下來,因為在str1找到\0的時候和str2不匹配,str2返回初始位置,cur往后走,重復步驟,直到cur走到\0,停下來。也就是對cur解引用后,是\0。終止循環,返回null代表沒找到。
情景3:str1先遇到\0,不可能匹配成功

1、首先cur往后走,走到有可能匹配成功的位置,str1過來到這,與str2開始匹配,發現str1先遇到\0,直接返回null,后續不可能匹配上
暴力尋找子串程序實現:實際上我們變量選擇最多的,情景盡量都能考慮到。
大家可以自己調整主函數里面兩個字符串的值去調試,兩個代碼都能做到相應的效果。
//我自己寫了一遍,但是時間復雜度高一點,后來我又敲了一遍鵬哥代碼,比我快,我沒想到str能直接被賦予cur
//下一個是鵬哥的代碼
#include<stdio.h>
#include<assert.h>
#include<string.h>
const char* my_strstr(const char* str1, const char* str2)
{//創建指針變量,str1,str2是不可以動的,它記錄著初始位置。//s1,s2是可以動的,cur是可以動的。const char* s1 = NULL;const char* s2 = NULL;const char* cur = str1;while (*cur)//判斷當前str1中有字符{//將s1和s2指向當前字符串s1 = str1;s2 = str2;while (*cur != *s2){cur++;if (*cur == '\0')//如果一直找不到,直到s1都遍歷完str1了,直接返回NULL{return NULL;}}while (*cur == *s2)//找到可能匹配的位置{s1 = cur;//賦予s1當前位置,等待與s2匹配while (*s2 && *s1 && *s1 == *s2)//開始匹配,字符相同就向后走,直到s2先遇到\0說明匹配成功//如果沒匹配成功,cur往后走,再次找到可能匹配的位置//如果s1先遇上\0,不用管,因為說明與s2不匹配,cur還會往后走,再次匹配還是s1到\0,cur再往后走循環這個操作,直到cur內容是\0,最外層while判斷為假退出{s1++;s2++;}if (*s2 == '\0')//匹配成功{return cur;}cur++;}return NULL;}return NULL;}
int main()
{char arr[] = "abcdefg";char* p = "k";const char* ret = my_strstr(arr, p);printf("%s\n", ret);return 0;
}
//鵬哥代碼:
#include<stdio.h>
#include<assert.h>
#include<string.h>
const char* my_strstr(const char* str1, const char* str2)
{assert(str1 && str2);//創建指針變量,str1,str2是不可以動的,它記錄著初始位置。//s1,s2是可以動的,cur是可以動的。const char* s1 = NULL;const char* s2 = NULL;const char* cur = str1;if (*str2 == '\0'){return str1;}while (*cur)//判斷當前str1中有字符{//將s1和s2指向當前字符串s1 = cur;//由于s1是跟著cur走的,所以直接賦上cur值就好了s2 = str2;//沒匹配成功,s2回歸原位while (*s2 && *s1 && *s1 == *s2)//找到合適位置,開始匹配,字符相同就向后走,直到s2先遇到\0說明匹配成功//如果沒匹配成功,cur往后走,再次找到可能匹配的位置//如果s1先遇上\0,不用管,因為說明與s2不匹配,cur還會往后走,再次匹配還是s1到\0,cur再往后走循環這個操作,直到cur內容是\0,最外層while判斷為假退出{s1++;s2++;}if (*s2 == '\0')//匹配成功{return cur;}cur++;//沒找到cur就一直往后走,如果沒匹配上,cur到了\0,退出外層循環,返回NULL}return NULL;
}
int main()
{char arr[] = "abcdefg";char* p = "k";const char* ret = my_strstr(arr, p);printf("%s\n", ret);return 0;
}
kmp算法:
實際上有一種高效的字符串中查找字符串的方法:叫做kmp算法,鵬哥沒有細講,這里我看了b站視頻,嘗試給各位講講。
在我們剛剛的暴力匹配的過程是一個字符一個字符的匹配,一旦有沒匹配成功,就跳回主串中的下一個字符重新匹配。



- 但是它的時間復雜度高,是O(n*m),n代表主串的長度,m代表子串的長度,效率低下
- 假如運氣不好,恰好碰到主串和子串都是若干個A最后緊跟著一個B的情況。此時算法會傻傻的將前面多的A都比對完,發現最后一個B字符不匹配,于是跳回下一個字符重新對比。做了不少的無用功。







介紹一下有三位大佬knuth,morris,pratt(保護他們的知識產權~)

他們提出,既然字符串在比對失敗的時候已經知道之前都讀過哪些字符了,有沒有可能避免跳回下一個字符再重新匹配的步驟呢


于是他們發表了線性時間復雜度的KMP算法,再一次字符串的遍歷過程中就可以匹配出子串。
kmp算法的工作原理
基本思路:當我們發現某一個字符不匹配的時候,由于已經知道之前遍歷過的字符,利用這些信息來避免暴力算法中的回退(backup)步驟。
- 我們不希望遞減上面的指針,對應我之前講過的匹配失敗后,str1 = cur的操作

- 希望它永遠向前移動:做到方可實現線性時間復雜度。

在這里,由于我們已經知道前面都讀到過哪些字符了, 可以將子串移動到如圖位置接著進行匹配,避免重復比對,接下來只需要繼續測試子串后面的字符就好了。 - 那么我們怎么知道子串應該跳過幾個字符再次與主串進行比對呢?


這里就就要用到kmp中定義的next數組了:
先不管next數組怎么生成的,先看一下其功能和用途,kmp算法在匹配失敗的時候,會去看最后一個匹配的字符,它對應的next數值--------子串中可以跳過匹配的字符個數

于是移動了子串,直接跳過了前兩個字符,也就是前面的兩個字符不需要看了,直接從下一個字符接著匹配。 - 顯然這樣做事沒有問題的,因為跳過的兩個字符AB確實能與主串中的AB匹配上

所以繼續測試后面的字符就好了。

由于不再需要回退主串中的指針。只需要一次主串的遍歷就可以完成匹配,效率果真比之前的暴力算法高很多。



接下來看看next數組的生成:
可以使用暴力求解,for循環,但是有一種快速的辦法,聽評論區說好像是動態規劃,本人沒學過動態規劃,但是up主講的配合評論區我懂了,也有自信給各位講懂。
這里給一個前后綴的概念:

也就是比如說我有個一個串是ABABAAB
前綴就是:A,AB,ABA,ABAB,ABABA,ABABAA
后綴就是:BABAAB,ABAAB,BAAB,AAB,AB,B
最長相等前后綴就是:AB(也就是上面兩排長度最長的,相等的字母)
當然我們找next數組找的也是這個
1、假設現在我們已經找到當前最長公共前后綴了。

分兩種情況討論:
如果下一個字符依然相同,直接構成一個更長的前后綴,長度等于之前長度加1

但是如果下一個字符不同的話,既然ABA無法與下一個字符構成更長的前后綴,就看看其中存不存在更短的比如A,有可能與下一個字符構共同前后綴,就需要找左右兩邊ABA子串這個原本的最長前后綴的左邊ABA最長前后綴部分,在與當前后面的B這位去判斷能否繼續構成最長前后綴。看不懂沒關系有解釋,接著往后看明白了再來品味這句話


- 解釋:根據之前的經驗,next數組是需要找左右兩邊最長前后綴,那么就需要找左邊的前綴=右邊的后綴,那么可以看到目前子串前后的這ABA兩部分是相同的,并且右邊的后綴=左邊的后綴(相同的肯定后綴一樣啊),那么直接找左邊的ABA的前綴和后綴的最長相等前后綴就好了,即找左邊前綴=左邊后綴,直接尋找左邊ABA的最長前后綴,那么左邊ABA的最長前后綴,之前就已經找到過了,就是在求解ABA的最長前后綴的時候,在A那填上1的過程,所以是1

那么找到左右子串ABA的最長前后綴了,是1個,那就是第一個A和倒數第二個A,就可以回到最開始的步驟,檢查下一個字符是否相同,相同就構成更長的前后綴,長度加1即可,相當于現在是A一樣,往后走B也一樣,那么最長前后綴就是AB,長度為2即可。


相信到這里大家也明白了,如果還有問題歡迎評論區留言,up主會給大家解答,那么最后看看整個過程吧:









字符串的一些算法實現(王道考研):
1、首先創建結構體串,我們基于這樣的邏輯結構設計串:第一個位置舍棄,由于字符串中的字符位置和線性表中的位序是一樣的,都是從1開始的,所以將數組第一個下標為0的位置舍棄。最后一個內存位置存放字符的個數,而一個這樣的內存單元空間大小為1B,只能8bit,也就是最大能表示的數是1111 1111也就是256。而第一個空間舍棄,所以最多能存儲的字符個數MAXLEN = 255;結構體中包含這樣一個靜態數組,還有串長度。

接下來模擬實現StrLength,ClearString,SubString,StringCmp,Index的實現,對應的測試方法代碼中有寫。
StrLength
這個就是數組的遍歷,i從0到length-1,其實和1到length一樣,也就是從第一個位置到最后一個位置。
int StrLength(SString S)
{int count = 0;for (int i = 0; i < S.length; i++){count++;}return count;
}
ClearString
清空串,也就是將length置為0,但其實他在內存中還是存在的,這是我們下一次操作這塊空間的時候直接可以默認里面沒有值,再去覆蓋相應的值。
bool ClearString(SString &S)
{S.length = 0;return true;
}
SubString
- 參數列表,Sub存放子串的地方,用引用就代表它需要改Sub在主函數中申請的空間內的值,S主串,pos代表從此位置開始切割主串,len代表子串長度
- 首先判斷子串是否越界,從i位置起len個字符,如果從5開始的3個字符這個自串就越界了,長度是7,pos+len-1自己帶入相應的數字試試就知道了。
- 循環開始,將主串的內容都放到開辟好的子串存放數組,結構體訪問用點
- 最后將子串長度給子串數組。

StringCmp:
- 參數列表:比較的兩個串
- 遍歷這兩個串,如果遇到不相同的,直接返回此處字符相減的值,是滿足比較函數對返回值的要求的
- 如果遍歷下來發現都相同,那就返回字符串長度相減的值。

Index:
- 需要使用我們之前搭建好的函數,在S串中找T串,首先應該知道這兩個字符串的長度
- 從S中切割T長度的子串,放進Sub臨時存放子串地方,再去比較T與Sub是否相同,使用比較函數
- 如果相同,那么比較函數返回值是0,直接返回當前位置i就可以了,如果不是0意味著S中當前切割的子串并不與T相同,那就找下一個子串與T相比,如果遍歷完子串了,還不相同,返回0。

# define MAXLEN 255
typedef struct {char ch[MAXLEN];//靜態數組;int length;//串多的長度
}SString;
//SubString(&Sub,S,pos,len)用Sub返回串S的第pos個中字符起長度為len的子串。
int StrLength(SString S)
{int count = 0;for (int i = 0; i < S.length; i++){count++;}return count;
}
bool ClearString(SString &S)
{S.length = 0;//實際上內存中還是具有這些值,但是可以覆蓋掉,所以就相當于清空了return true;
}
bool SubString(SString& Sub, SString S, int pos, int len)
{//判斷pos是否越界if (pos + len - 1 > S.length)return false;//不越界for (int i = pos;i < pos+len; i++){Sub.ch[i - pos + 1] = S.ch[i];}Sub.length = len;return true;
}
//比較操作
int StringCmp(SString S, SString T)
{//循環比較每一個字符,是否相同for (int i = 0; i < S.length && i < T.length; i++){//如果有不相同的,直接讓當前位置字符相減,返回對應值即可。if (S.ch[i] != T.ch[i])return S.ch[i] - T.ch[i];}//如果比較完完全相同,則直接返回長度之差,滿足字符串比較返回值的要求return S.length - T.length;
}
//查找子串在主串中的位置
int Index(SString S, SString T)
{//聲明一系列變量,i代表位置,主串和子串的長度,暫存子串的空間int i = 0; int n = StrLength(S); int m = StrLength(T);SString Sub;while(i <= n-m)//1 ~n-m+1也是一樣的,王道書是1到n-m+1{SubString(Sub, S, i, m);if (StringCmp(Sub, T) != 0){i++;}return i;}
}
int main()
{ //測試全部成功SString S = {"abcdef",6};//測試長度函數int count = StrLength(S);cout << count << endl;SString Sub = {};SString T = { "abc",3 };//測試比較函數int ret = StringCmp(S, T);cout << ret << endl;//測試子串分割函數bool a = SubString(Sub, S, 3, 2);cout << a << endl;//測試索引函數int b = Index(S, T);cout << b << endl;//測試清空函數ClearString(S);cout << S.length << endl;return 0;
}十二、strerror函數的使用
strerror 函數可以把參數部分錯誤碼對應的錯誤信息的字符串地址返回來。
char* strerror ( int errnum );
解釋:
- 在不同的系統和C語?標準庫的實現中都規定了?些錯誤碼,?般是放在 errno.h 這個頭?件中說明的,C語?程序啟動的時候就會使??個全局的變量errno來記錄程序的當前錯誤碼,只不過程序啟動的時候errno是0,表示沒有錯誤。
- 當我們在使?標準庫中的函數的時候發?了某種錯誤,就會將對應的錯誤碼,存放在errno中
- 而一個錯誤碼的數字是整數很難理解是什么意思,所以每?個錯誤碼都是有對應的錯誤信息的。strerror函數就可以將錯誤碼對應的錯誤信息字符串的地址返回,通過%s,即可打印錯誤信息,將錯誤信息可視化。
這樣講未免有些抽象,我一句一句給大家講講
1、不同的系統和C語?標準庫的實現中都規定了?些錯誤碼,?般是放在 errno.h 這個頭?件中說明的。
我們打開vs,之后打開everything工具,搜索此文件,找到vs路徑下的,一般跟著鵬哥下載的vs路徑都是這個,將此文件拖動到vs中。

2、會出現如下界面:里面存放著很多的錯誤碼,每一個出錯誤碼都對應著一個錯誤信息,比如2對應著no such file or directory。


int main()
{int i = 0;for (i = 0; i < 10; i++){printf("%d:%s\n", i,strerror(i));}return 0;
}

3、在c語言程序啟動的時候,會創建并使用一個全局的變量errno來記錄程序的當前錯誤碼,此時是0,也就是沒有錯誤的意思。

4、當我們在使?標準庫中的函數的時候發?了某種錯誤,就會將對應的錯誤碼,存放在errno中
- 比如我以讀的形式使用標準庫函數fopen打開文件,而這個文件在我當前vs的目錄下并沒有被我創建,就會產生錯誤,此時errno全局變量的值就會被修改為2,(這里的2指錯誤碼,因為錯誤碼2的錯誤信息就是文件操作錯誤no such file or drictory)
- 那如果只有2這個信息,我并不知道錯哪了,還需要將這個錯誤碼解釋一下,就使用strerror函數,傳入errno參數,錯誤碼值是2,strerror函數會將2翻譯成一個錯誤信息(字符串),并且返回這個字符串的首地址,以char* 的形式返回
- 接下來使用printf(“%s\n”,strerror(errno));,找到字符串地址,使用%s打印,便可將錯誤信息可視化出來了。
- 代碼中以讀形式打開文件"abc.txt"
int main()
{FILE* pf = fopen("abc.txt", "r");//文件打開函數,以讀形式打開,如果此文件不存在,打開失敗返回空指針if (pf == NULL){printf("打開文件失敗了,原因是: %s", strerror(errno));return 1;//退出程序}else{printf("打開成功");//.....一系列操作fclose(pf);//關閉文件pf = NULL;//指針置空}return 0;
}

注解:如何看當前目錄是否有此文件
- 光標放在當前項目下,有當前目錄

- 當前目錄沒有創建“abc.txt”

到這里也算是懂得strerror工作原理了
再回去看看之前總結的話語,會明白很多。
十三、perror函數

perror函數:顧名思義:printf+error:將錯誤信息直接打印出來。直接在參數部分放入錯誤說明字符串,然后它會幫忙打印冒號,空格,接著打印錯誤信息。
使用
int main()
{FILE* pf = fopen("abc.txt", "r");if (pf == NULL){printf("打開文件失敗了,原因是: %s\n", strerror(errno));perror("打開文件失敗了,原因是");return 1;}else{printf("打開成功");//.....一系列操作fclose(pf);pf = NULL;}return 0;
}

- 所以未來如果是想獲得錯誤信息字符串,就可使用strerror函數和errno。
- 如果是想打印錯誤信息,直接使用perror函數更為方便,當然,使用strerror和printf也是可以的。
:擁抱官方標準 - Spring AI框架入門與實踐)

)


語法知識點及案例(14))







)



(Model-View-Delegate))

