第04篇:數據可視化——一圖勝千言
寫在前面:大家好,我是藍皮怪!前面幾篇我們聊了統計學的基本概念、數據類型和描述性統計,這一篇我們要聊聊數據分析中最直觀、最有趣的部分——數據可視化。你有沒有發現,很多時候一張圖勝過千言萬語?無論是新聞報道、商業分析,還是朋友圈曬步數,數據可視化都無處不在。今天我們就來聊聊,如何用圖表讓數據"說話"。
🎯 這篇文章你能學到什么
- 數據可視化的基本概念、發展與作用
- 常見統計圖表的類型、適用場景、優缺點和解讀方法
- 生活化案例與常見陷阱
- Python可視化代碼示例
- 如何用圖表講好數據的故事
1. 從生活說起:為什么要學數據可視化?
你有沒有遇到過這些場景:
📈 看新聞時:一張房價走勢圖讓你一秒看懂十年變化。
🍰 點外賣時:餅圖顯示不同菜品的銷量占比,幫你選出"爆款"。
🏃 刷朋友圈時:步數排行榜一目了然,誰最愛運動一看便知。
其實,數據可視化早已滲透到我們生活的方方面面。它能讓復雜的數據變得直觀、易懂,也能幫助我們發現數據背后的規律和故事。
2. 數據可視化的核心概念與發展
2.1 什么是數據可視化?
數據可視化,就是用圖形、圖表等視覺手段,把抽象的數據變成直觀的信息。它的本質是"讓數據說話",幫助我們更快、更準確地理解數據。
2.2 為什么要做可視化?
- 直觀表達:一張圖能讓人秒懂數據全貌。
- 發現規律:圖表能揭示數據中的趨勢、分布和異常。
- 輔助決策:可視化結果常常是決策的依據。
- 溝通交流:圖表是團隊、公眾溝通的"通用語言"。
2.3 可視化的歷史與發展
- 18世紀:最早的統計圖表(如威廉·普萊費爾的條形圖、折線圖、餅圖)
- 19世紀:南丁格爾玫瑰圖、約翰·斯諾霍亂地圖等推動了數據可視化在醫學、社會科學的應用
- 20世紀:計算機普及,圖表類型和交互方式極大豐富
- 21世紀:大數據、AI、交互式可視化(如Tableau、PowerBI、ECharts、D3.js)成為主流
3. 常見統計圖表類型與適用場景
| 圖表類型 | 適用數據 | 主要作用 | 優點 | 局限 | 生活例子 |
|---|---|---|---|---|---|
| 條形圖 | 分類/分組 | 比較各類別數量 | 直觀、易讀 | 類別過多時擁擠 | 各城市人口、不同菜品銷量 |
| 餅圖 | 分類/比例 | 顯示各部分占比 | 形象、突出比例 | 類別多時難分辨 | 市場份額、預算分配 |
| 直方圖 | 連續/分組 | 展示分布形態 | 反映分布、異常 | 只適合數值型 | 成績分布、身高分布 |
| 箱線圖 | 數值型 | 展示分布特征和異常值 | 顯示中位數、離群值 | 不顯示分布細節 | 班級成績、工資分布 |
| 折線圖 | 時間序列 | 展示趨勢變化 | 反映趨勢 | 不適合離散類別 | 股價走勢、氣溫變化 |
| 散點圖 | 數值型 | 展示變量關系 | 發現相關性 | 變量多時難讀 | 身高與體重、收入與消費 |
| 熱力圖 | 分組/矩陣 | 展示分布密度 | 直觀、對比強 | 需二維分組 | 城市與性別分布 |
| 密度圖 | 數值型 | 展示分布平滑曲線 | 細膩、平滑 | 受帶寬影響 | 收入分布、消費分布 |
| 分組對比 | 分類+數值 | 多組對比 | 直觀對比 | 組數多時擁擠 | 各城市步數對比 |
| 相關性熱力圖 | 多變量 | 展示變量間相關性 | 一目了然 | 只反映線性相關 | 多指標分析 |
4. 實際案例與可視化代碼
這里我們用一組模擬數據,展示不同類型的可視化效果。
4.1 生成示例數據
import numpy as np
import pandas as pd
np.random.seed(42)
n = 300
data = {'性別': np.random.choice(['男', '女'], n, p=[0.52, 0.48]),'城市': np.random.choice(['北京', '上海', '廣州', '深圳', '杭州'], n),'年齡': np.random.normal(32, 8, n).round(1),'身高': np.random.normal(168, 8, n).round(1),'月收入': np.random.lognormal(9.2, 0.5, n).round(0),'步數': np.random.poisson(8000, n),'消費': np.random.gamma(2, 2000, n).round(0)
}
df = pd.DataFrame(data)
df['年齡'] = np.clip(df['年齡'], 18, 65)
df['身高'] = np.clip(df['身高'], 150, 190)
4.2 條形圖:不同城市樣本數量
import matplotlib.pyplot as plt
city_counts = df['城市'].value_counts()
plt.figure(figsize=(7,5))
city_counts.plot(kind='bar', color='skyblue')
plt.title('不同城市樣本數量')
plt.xlabel('城市')
plt.ylabel('人數')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()
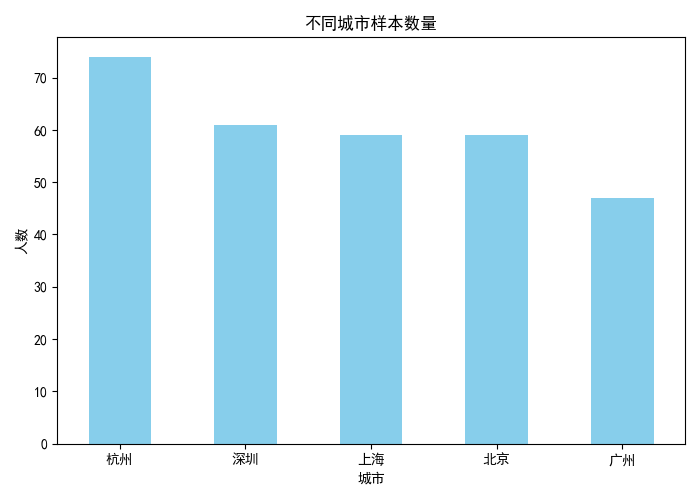
- 條形圖適合比較各類別數量,直觀反映不同城市的樣本分布。
4.3 餅圖:性別比例
plt.figure(figsize=(4,4))
df['性別'].value_counts().plot(kind='pie', autopct='%1.1f%%', colors=['lightblue','lightpink'])
plt.title('性別比例')
plt.ylabel('')
plt.tight_layout()
plt.show()
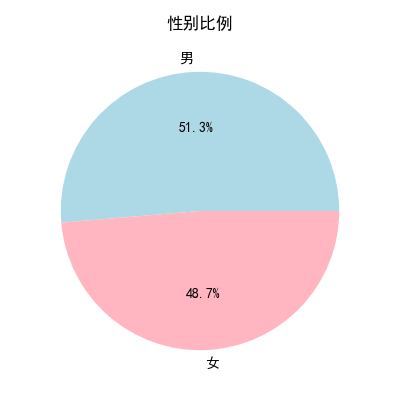
- 餅圖突出比例關系,適合展示性別、市場份額等占比。
4.4 直方圖:年齡分布
plt.figure(figsize=(7,5))
plt.hist(df['年齡'], bins=15, color='lightgreen', edgecolor='black')
plt.title('年齡分布直方圖')
plt.xlabel('年齡')
plt.ylabel('人數')
plt.tight_layout()
plt.show()
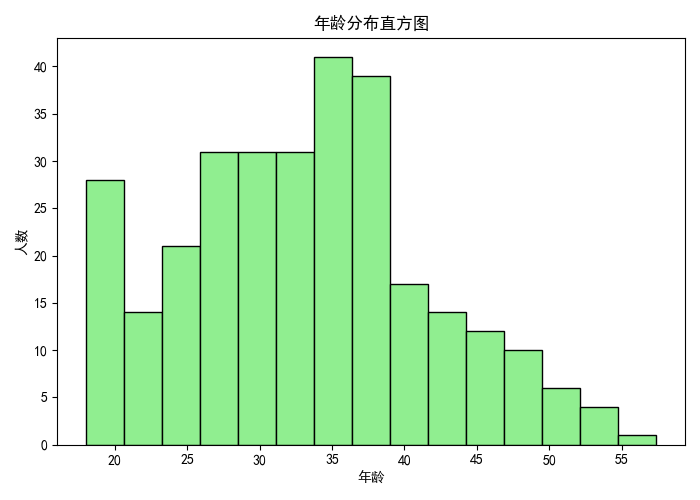
- 直方圖反映年齡的分布形態,是否偏態、集中或分散。
4.5 箱線圖:身高分布
import seaborn as sns
plt.figure(figsize=(6,5))
sns.boxplot(y=df['身高'], color='gold')
plt.title('身高分布箱線圖')
plt.ylabel('身高 (cm)')
plt.tight_layout()
plt.show()
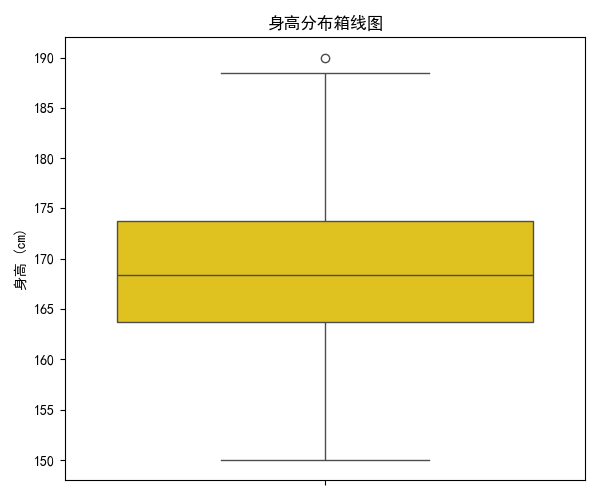
- 箱線圖揭示身高的中位數、四分位數和異常值。
4.6 折線圖:某城市月收入趨勢
months = np.arange(1,13)
city_income = np.random.normal(12000, 2000, 12)
plt.figure(figsize=(7,5))
plt.plot(months, city_income, marker='o', color='orange')
plt.title('某城市月收入趨勢')
plt.xlabel('月份')
plt.ylabel('月收入 (元)')
plt.xticks(months)
plt.tight_layout()
plt.show()
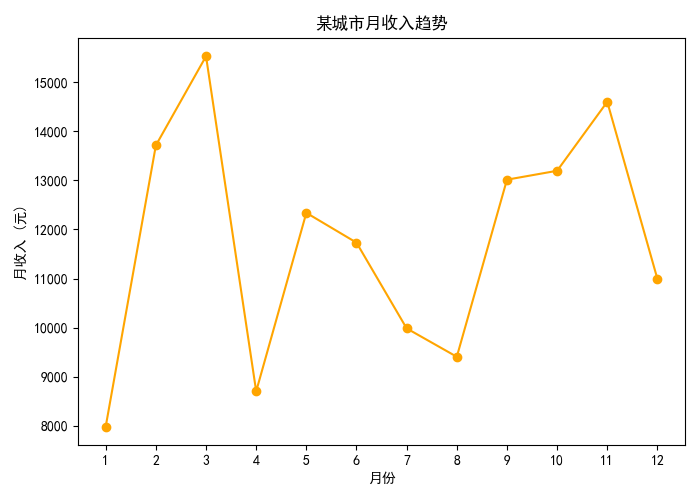
- 折線圖適合展示時間序列數據的趨勢變化。
4.7 散點圖:身高與月收入的關系
plt.figure(figsize=(7,5))
plt.scatter(df['身高'], df['月收入'], alpha=0.6, color='purple')
plt.title('身高與月收入的關系')
plt.xlabel('身高 (cm)')
plt.ylabel('月收入 (元)')
plt.tight_layout()
plt.show()
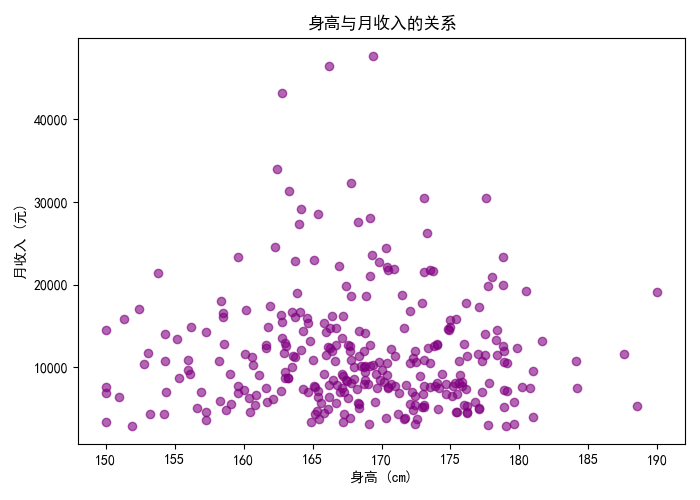
- 散點圖揭示變量間的相關性和分布特征。
4.8 熱力圖:不同城市與性別的樣本分布
pivot = pd.crosstab(df['城市'], df['性別'])
plt.figure(figsize=(6,5))
sns.heatmap(pivot, annot=True, cmap='YlGnBu', fmt='d')
plt.title('不同城市與性別的樣本分布熱力圖')
plt.tight_layout()
plt.show()
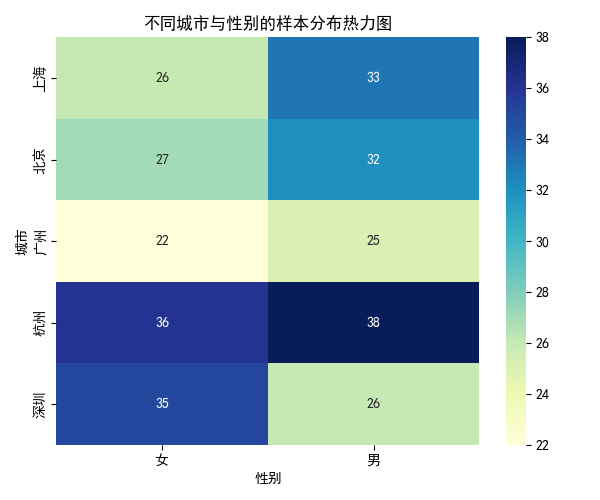
- 熱力圖適合展示二維分組數據的分布密度。
4.9 密度圖:消費分布
plt.figure(figsize=(7,5))
sns.kdeplot(df['消費'], fill=True, color='teal')
plt.title('消費分布密度圖')
plt.xlabel('消費 (元)')
plt.tight_layout()
plt.show()
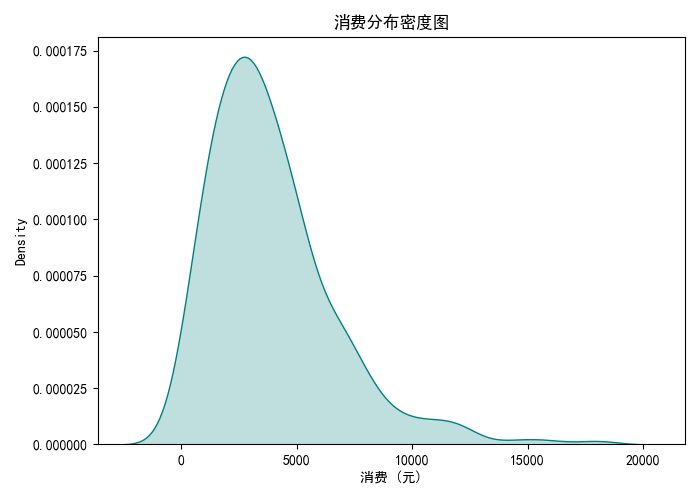
- 密度圖平滑展示消費數據的分布形態。
4.10 分組對比箱線圖:不同城市步數分布
plt.figure(figsize=(8,6))
sns.boxplot(x='城市', y='步數', data=df)
plt.title('不同城市步數分布箱線圖')
plt.xlabel('城市')
plt.ylabel('步數')
plt.tight_layout()
plt.show()
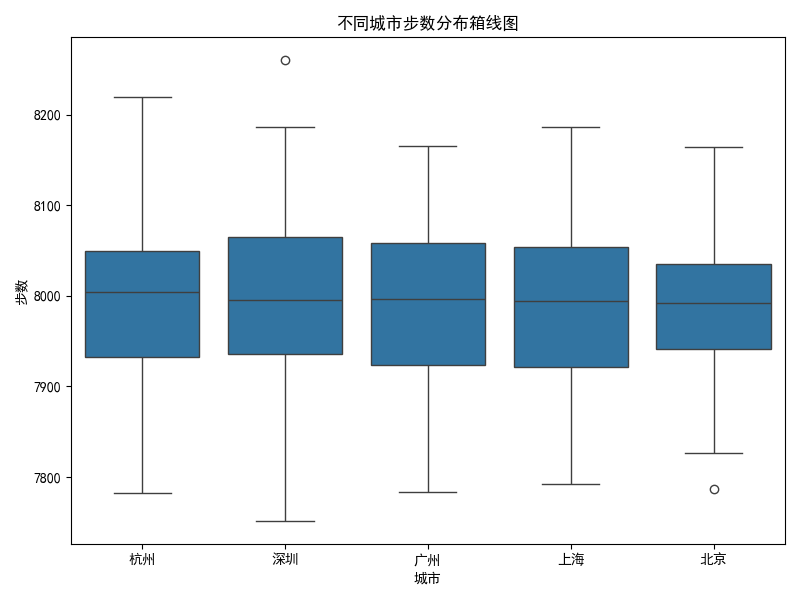
- 分組箱線圖適合多組數值型數據的對比。
4.11 相關性熱力圖:數值變量相關性
corr = df[['年齡','身高','月收入','步數','消費']].corr()
plt.figure(figsize=(7,6))
sns.heatmap(corr, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('數值變量相關性熱力圖')
plt.tight_layout()
plt.show()
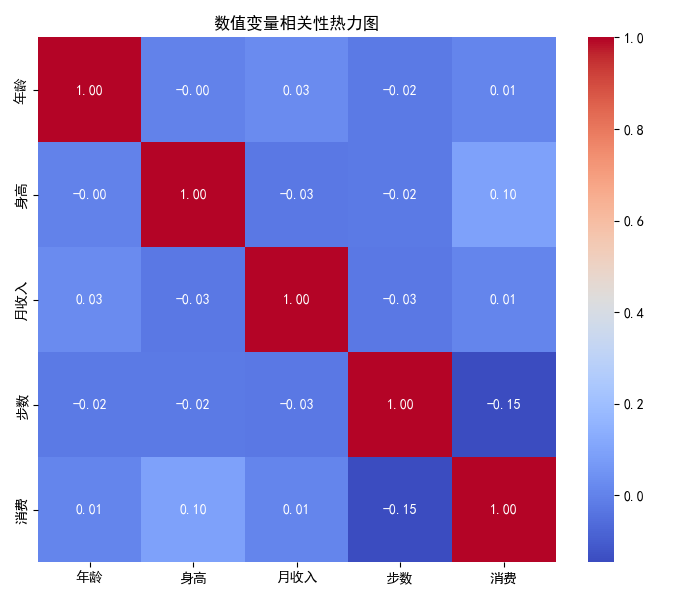
- 相關性熱力圖一目了然地展示多變量間的線性相關關系。
5. 別被這些誤區騙了
? 誤區1:圖越花哨越好
真相:可視化的核心是清晰表達,過度裝飾反而干擾理解。
? 誤區2:圖表越多越好
真相:圖表不是越多越好,關鍵是選對、用好。過多的圖表反而會分散重點,甚至造成信息干擾。
? 誤區3:只看圖不看數據
真相:圖表是輔助理解,關鍵還是要結合數據本身。
? 誤區4:圖表類型隨意選
真相:不同數據類型、分析目的需選用合適的圖表。
6. 實際應用建議
- 選對圖表類型,別"亂燉"。
- 圖表要有標題、坐標軸、單位,必要時加注釋。
- 顏色搭配要協調,避免過度花哨。
- 關注數據分布和異常值,別只看均值。
- 代碼可復用,建議封裝常用繪圖函數。
- 結合交互式可視化工具(如Tableau、PowerBI、ECharts、Plotly等)提升分析效率。
7. 練習一下
基礎題
- 哪些場景適合用條形圖?哪些適合用折線圖?
- 餅圖和條形圖的區別是什么?
- 箱線圖能揭示哪些信息?
- 熱力圖和相關性熱力圖的區別?
思考題
- 你在生活中見過哪些有趣或誤導的數據可視化?
- 如果要展示某公司三年內各部門員工人數變化,應該用什么圖?為什么?
- 如何判斷散點圖中的變量是否存在線性相關?
動手題
- 用Python畫出你自己的步數、體重或消費數據的趨勢圖。
- 用模擬數據畫出身高與體重的散點圖,并嘗試解釋相關性。
- 試著用箱線圖和密度圖對比同一組數據的分布特征。
8. 重點回顧
- 數據可視化讓數據"說話",是數據分析的重要環節。
- 常見圖表有條形圖、餅圖、直方圖、箱線圖、折線圖、散點圖、熱力圖、密度圖、分組對比圖、相關性熱力圖等。
- 選對圖表類型,表達更清晰。
- 圖表要關注分布、趨勢、異常值。
9. 下期預告
下一篇我們將進入概率的世界,聊聊"概率基礎:不確定性的數學"。你將學到:
- 概率的基本概念和計算方法
- 生活中的概率現象
- 概率與統計的關系
- 常見概率誤區
概率是理解統計推斷的基石,敬請期待!
📚 參考資料
- 吳喜之著《統計學:從數據到結論》,中國統計出版社
- 盛驟等著《概率論與數理統計》,高等教育出版社
- 作者個人學習和實踐經驗總結
寫在最后:如果你覺得這篇文章對你有幫助,歡迎點贊、收藏和分享!有任何問題或建議,歡迎在評論區留言交流,我會認真回復每一條評論。讓我們一起用統計學的眼光看世界,一起進步!📊













線性方程組的多種解法)
)




