這篇文章已經放到騰訊智能工作臺的知識庫啦,鏈接在這里:ima.copilot-Go 入門到入土。要是你有啥不懂的地方,就去知識庫找 AI 聊一聊吧。
1、變量的聲明與使用
我們來探討編程語言中最核心的概念之一:變量。
1、靜態語言中的變量特性
Go 是一種靜態類型語言,其變量處理方式與 Python 等動態語言有顯著差異。對于沒有靜態語言背景的開發者來說,需要特別注意以下幾點:
-
必須先聲明后使用:任何變量都必須先經過聲明,才能在代碼中使用。
-
類型固定:在聲明變量時,其類型就已經確定。
-
類型不可變:一旦類型確定,就不能再賦予其他類型的值。例如,一個整型(
int)變量不能被賦值為字符串(string)。
這種強類型約束使得編譯器能在編譯階段就發現許多潛在的錯誤,有助于編寫更健壯、更規范的大型項目。
2、變量的聲明方式
Go 語言提供了多種聲明變量的方式。
2.1 標準聲明 (var)
這是最基礎的聲明方式。使用 var 關鍵字,后跟變量名和類型。

注意:Go 的類型聲明位于變量名之后,這與其他靜態語言(如 C++ 或 Java)不同。建議直接適應這種語法,無需糾結其設計原因。
2.2 聲明并初始化
可以在聲明變量的同時為其賦予初始值。

當提供初始值時,Go 可以自動推斷類型,因此可以省略類型聲明:
2.3 短變量聲明 (:=)
這是 Go 中最常用、最簡潔的聲明方式,它會合并聲明和初始化兩個步驟。

這種方式只能用于局部變量(在函數內部聲明的變量),不能用于全局變量。在日常開發中,你會頻繁地使用這種方法。
3、全局變量與局部變量
3.1 全局變量
在函數體外聲明的變量,其作用域覆蓋整個包。

3.2 局部變量
在函數體內聲明的變量,其作用域僅限于該函數內部。

注意:短變量聲明
:=不能用于聲明全局變量。
4、多變量生成
Go 支持在一行內聲明多個變量。

5、變量使用的注意事項
-
變量名沖突:在同一作用域(代碼塊)內,不能重復聲明同名變量。但局部變量可以與全局變量同名,此時局部變量會“覆蓋”全局變量。
-
零值 (Zero Value):在 Go 中,變量在聲明后若未被顯式初始化,會被自動賦予其類型的零值。這避免了在其他語言中可能出現的“隨機值”問題。
-
int:0 -
string:""(空字符串) -
bool:false -
指針、接口、切片、映射、通道:
nil

- 聲明后必須使用:Go 語言強制要求,局部變量在聲明后必須被使用,否則會在編譯時報錯。此舉旨在鼓勵編寫整潔、無冗余的代碼。全局變量則無此限制。

2、常量的定義和使用
在 Go 語言中,常量(Constant)是指在程序編譯時就已確定,并且在運行時不能被修改的固定值。當程序中有些值從始至終都不應改變時,將其定義為常量是最佳實踐。這可以有效防止在代碼的某個地方無意中修改了重要的值。
1、常量的基本定義
常量的定義與變量類似,但使用 const 關鍵字。

核心特性:
- 不可變性:常量一旦聲明,其值就不能再被修改。任何嘗試對常量重新賦值的行為都會導致編譯錯誤。

2、常量的類型
常量也具有類型。Go 語言支持在定義常量時顯式指定類型,也支持通過值進行隱式類型推斷。
2.1 顯式定義
明確指定常量的類型。

2.2 隱式定義
不指定類型,由編譯器根據所賦的值自動推斷。

在這種情況下,編譯器會自動推斷 E 的類型。
3、命名規范
為了在代碼中清晰地區分常量和變量,Go 語言的開發社區遵循以下命名規范:
-
常量名全部大寫。
-
如果常量名由多個單詞組成,使用下劃線
_分隔。

雖然這并非強制性語法,但遵循此規范可以極大地提高代碼的可讀性。
4、分組定義常量
為了代碼的整潔和可讀性,當需要定義多個相關的常量時,可以使用括號 () 將它們分組。

分組定義時,存在一個重要的特性:在一組常量中,如果某個常量沒有被顯式賦值,它會自動沿用上一個常量的值和類型。
看下面的例子:

當我們打印這些常量時,會得到 16, 16, "abc", "abc", "abc"。
對這個特性的理解,是掌握 Go 中另一個重要關鍵字 iota 的基礎,我們將在后續文章中詳細講解。
5、常量定義的核心規則總結
-
支持的類型:常量只能是布爾類型、數值類型(整數、浮點數、復數)和字符串類型。其他更復雜的類型(如
struct或array)不支持定義為常量。 -
無需強制使用:與變量不同,如果定義了一個常量但從未使用它,編譯器不會報錯。
-
類型一致性:如果顯式指定了常量的類型,那么賦予它的值必須與該類型兼容。
3、Go 語言中的 iota 詳解
iota 是 Go 語言中一個非常有用的關鍵字,專用于常量的定義。它可以被看作一個可由編譯器在編譯期間修改的特殊常量。iota 的主要作用是簡化具有遞增規律的常量的定義,尤其在定義枚舉值、錯誤碼等場景中,能顯著提高代碼的可讀性和可維護性。
1、iota 的基本用法
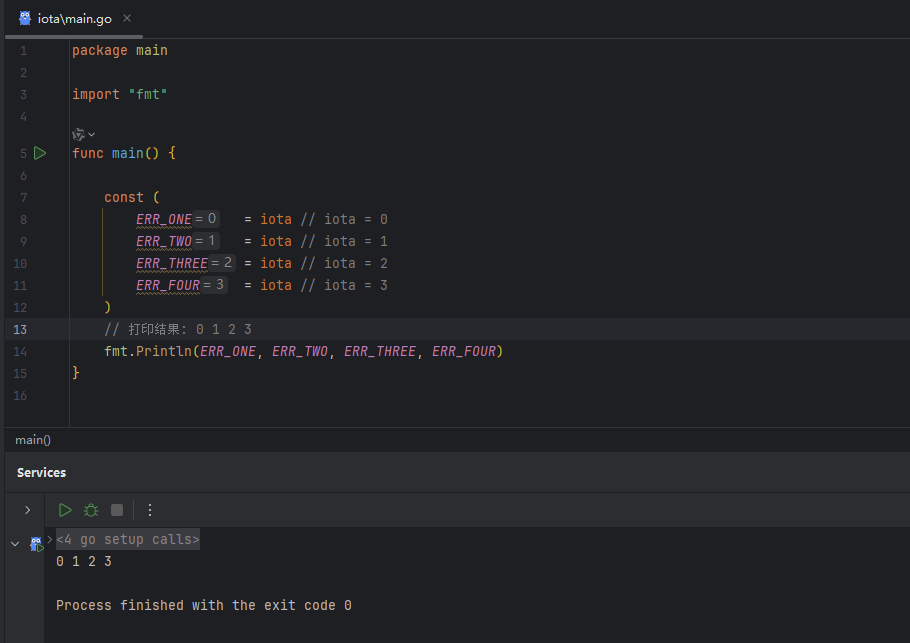
iota 的值由編譯器控制,它從 0 開始,在同一個 const 定義組中,每增加一個常量聲明,其值就會自動加 1。
2、iota 的隱式特性與簡化寫法
Go 語言的 const 聲明有一個特性:如果某一行沒有指定值,它會自動沿用上一行的表達式。這個特性與 iota 結合使用,可以寫出非常簡潔的代碼。
你只需要在第一個常量上使用 iota,后續的常量會自動應用遞增的

這種寫法是 iota 最常用、最推薦的實踐。如果后續需要在中間插入新的常量,無需手動修改后續所有常量的值,iota 會自動處理。
3、使用表達式自定義 iota 序列
iota 的強大之處在于它可以參與運算。你可以用它來構建更復雜的常量序列。
例如,讓序列從 1 開始:

4、中斷和恢復 iota
如果在 const 組中,你手動為某個常量賦值,那么 iota 的遞增在這一行會被中斷。但是,iota 的內部計數器仍然會根據行數繼續增加。
當你再次使用 iota 時,它會返回當前行對應的計數值,而不是被中斷行的值。

關鍵點:iota 的值取決于它所在的行號(從 0 開始),而不是上一行的常量值。
5、iota 的核心規則總結
const塊重置:iota的計數器在每一個新的const關鍵字出現時都會被重置為 0。

-
行數遞增:在
const塊中,每新增一行常量聲明(即使該行是空標識符),iota的計數器就會自動加 1。 -
表達式沿用:如果常量定義被省略,它會自動沿用上一行的賦值表達式。
-
中斷不影響計數:即使某一行不使用
iota,其內部計數器依然會增加。當后續行恢復使用iota時,將獲取該行對應的計數值。
iota 是 Go 語言中一個精妙的設計,掌握它能讓你的代碼更加簡潔和優雅。
4、匿名變量
在 Go 語言中,有一個非常嚴格的規則:所有聲明的變量都必須被使用,否則編譯器會報錯。然而,在某些場景下,我們可能需要接收一個值,但又確實不需要使用它。為了解決這個問題,Go 提供了匿名變量(Anonymous Variable)。
匿名變量使用一個下劃線 _ 來表示,它是一個特殊的變量名,可以看作一個“占位符”。任何賦予匿名變量的值都會被直接丟棄,因此它不需要被使用,也不會引發編譯錯誤。
1、匿名變量的核心用途
匿名變量最常見的用途是處理函數的多個返回值。
在 Go 中,一個函數可以返回多個值。當調用這樣的函數時,你必須用相應數量的變量來接收所有返回值。但有時,你可能只關心其中的一部分返回值。
場景示例:
假設我們有一個函數 getData(),它返回一個整數和一個布爾值。

現在,我們只想判斷操作是否成功(即只關心返回的布爾值),而對那個整數不感興趣。
錯誤的做法:

正確的做法:使用匿名變量
我們可以使用匿名變量 _ 來接收那個我們不關心的整數值。

通過這種方式,我們既滿足了函數多返回值的接收要求,又避免了因變量未使用而導致的編譯錯誤。
總結
-
定義:匿名變量是一個下劃線
_。 -
作用:作為值的占位符,接收并丟棄你不需要的值,以滿足語法要求。
-
優勢:使代碼更簡潔,可以優雅地忽略不必要的函數返回值或其他值。
在后續學習 Go 的接口(Interface)等更高級的概念時,你還會遇到匿名變量的其他應用場景。掌握它是編寫地道 Go 代碼的重要一步。
5、變量作用域
在像 Go 這樣的靜態類型語言中,作用域(Scope) 是一個至關重要的概念。它定義了程序中一個變量可以被訪問的區域。與許多動態語言相比,Go 對作用域的規定非常嚴格,這有助于在編譯階段就發現潛在的錯誤,從而提高代碼的健壯性。
1、全局作用域 (Global Scope)
在所有函數體外部聲明的變量,擁有全局作用域。這意味著它們可以在當前包(package)的任何地方被訪問和修改。

2、局部作用域 (Local Scope)

3、塊級作用域 (Block Scope)
Go 語言的作用域規則是基于 代碼塊的,代碼塊由花括號 {} 界定。在 if、for、switch 或普通 {} 內部聲明的變量,其作用域僅限于該代碼塊。
這是靜態語言中一個非常重要的特性:一旦程序執行離開一個代碼塊,該塊內聲明的所有變量都將被銷毀,無法在外部訪問。
示例 1:普通代碼塊

示例 2:if 條件塊

一個常見的誤區是,認為如果在 if 和 else 的所有分支中都定義了同名變量,那么在外部就可以訪問它。這是錯誤的,因為每個變量的作用域都被限制在各自的代碼塊內。
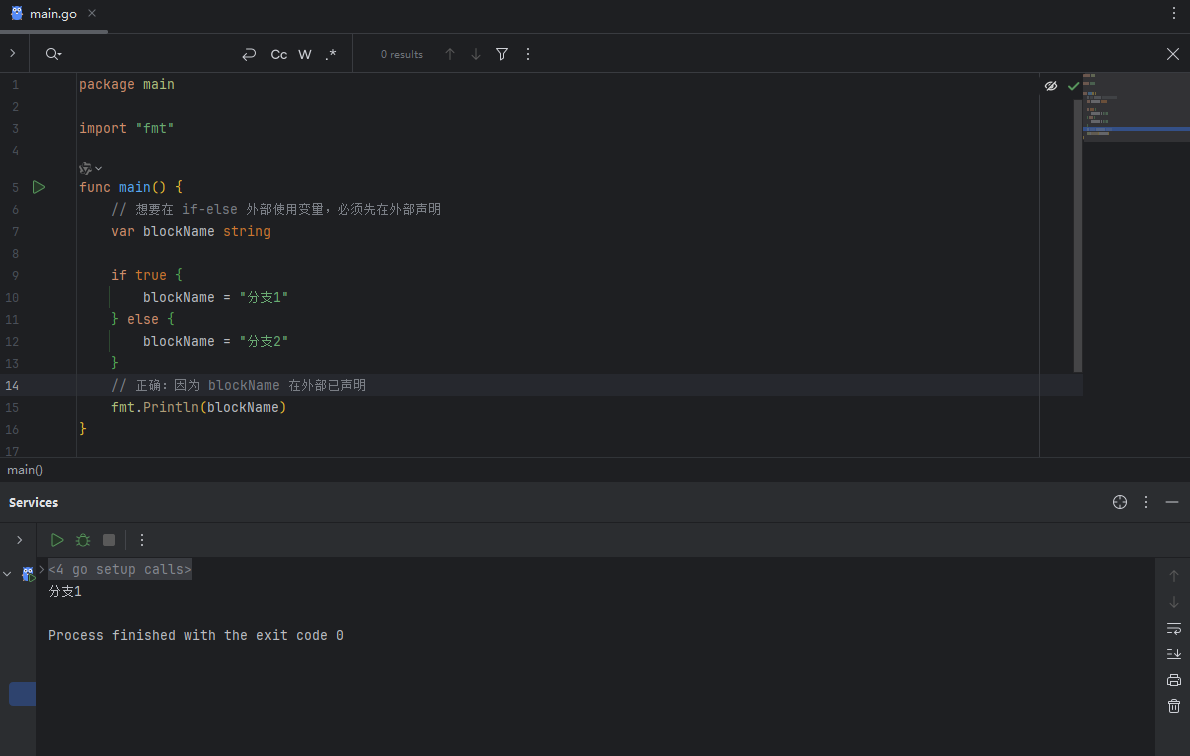
4、總結
-
全局變量:在整個包內可見。
-
局部變量:僅在聲明它的函數或代碼塊
{}內部可見。 -
嚴格性:Go 語言嚴格遵循基于代碼塊的作用域規則。離開一個代碼塊,內部變量即失效。
-
好處:這種嚴格性可以有效防止變量被意外訪問或修改,減少了程序出錯的可能性,是靜態語言可靠性的重要保障。IDE 和編譯器也能基于此規則提供準確的錯誤提示。









是一個用于“壓縮”大語言模型的工具包)

:自然語言處理的核心基石)







