目錄
1 Introduction
1.1 Product revision status
1.2 Intended audience
1.3 Scope
1.4 Conventions
1.5 Useful resources
2 Overview
2.1 Pipeline overview
3 Instruction characteristics
3.1 Instruction tables
3.2 Legend for reading the utilized pipelines? ? //閱讀所使用的流水線的圖例
3.3 Branch instructions
3.4 Arithmetic and logical instructions
3.5 Divide and multiply instructions
3.6 Pointer Authentication Instructions? ? //指針認證指令
3.7 Miscellaneous data-processing instructions? ? //雜項數據處理指令
3.8 Load instructions
3.9 Store instructions
3.10 Tag Load Instructions
3.11 Tag Store instructions
3.12 FP data processing instructions
3.13 FP miscellaneous instructions
3.14 FP load instructions
3.15 FP store instructions
3.16 ASIMD integer instructions
3.17 ASIMD floating-point instructions
3.18 ASIMD BFloat16 (BF16) instructions
3.19 ASIMD miscellaneous instructions
3.20 ASIMD load instructions
3.21 ASIMD store instructions
3.22 Cryptography extensions? ? //密碼學擴展
3.23 CRC
3.24 SVE Predicate instructions
3.25 SVE integer instructions
3.26 SVE floating-point instructions
3.27 SVE BFloat16 (BF16) instructions
3.28 SVE Load instructions
3.29 SVE Store instructions
3.30 SVE Miscellaneous instructions
3.31 SVE Cryptographic instructions
4 Special considerations
4.1 Dispatch constraints? ? //調度約束
4.2?Optimizing general-purpose register spills and fills? ? //優化通用寄存器的溢出和填充
4.3 Optimizing memory routines
4.4 Load/Store alignment
4.5 Store to Load Forwarding
4.6 AES encryption/decryption
4.7 Region based fast forwarding
4.8 Branch instruction alignment
4.9 FPCR self-synchronization
4.10 Special register access
4.11 Instruction fusion
4.12 Zero Latency Instructions
4.13 Cache maintenance operation? ? //緩存維護操作
4.14 Memory Tagging - Tagging Performance? ? //內存標簽
4.15 Memory Tagging - Synchronous Mode
4.16 Complex ASIMD and SVE instructions
4.17 MOVPRFX fusion
1 Introduction
1.1 Product revision status
"rxpy"標識符表示了此書中描述的產品的修訂狀態,例如r1p2,其中:
rx
標識產品的主要修訂版本,例如r1。
py
標識產品的次要修訂或修改狀態,例如p2。
1.2 Intended audience
本文檔適用于系統設計師、系統集成商和編程人員,他們正在設計或編程使用Arm核心的片上系統(SoC)。
1.3 Scope
本文檔描述了影響軟件性能的Cortex-A715核心微體系結構的各個方面。微體系結構的詳細信息僅限于對軟件優化有用的內容。
此文檔僅涵蓋Cortex-A715核心的軟件可見行為,并不涉及背后行為的硬件原理。
這份文檔旨在幫助系統設計師、系統集成商和程序員理解和優化Cortex-A715核心的軟件,以確保在不需要深入了解底層硬件實現的情況下達到最佳性能和效率。
1.4 Conventions
以下的小節描述了在Arm文檔中使用的約定。
1.4.1 Glossary
Arm詞匯表是Arm文檔中使用的術語列表,其中包含這些術語的定義。Arm詞匯表不包含行業標準術語,除非Arm對該術語的含義與普遍接受的含義有所不同。
要了解更多信息,請參閱Arm詞匯表:Documentation – Arm Developer。
1.4.2 Terms and abbreviations
本文檔使用以下術語和縮寫語:
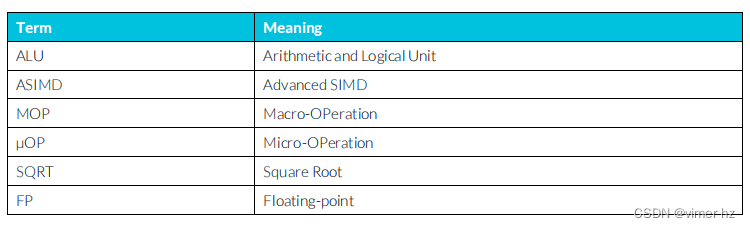
1.5 Useful resources
本文檔包含特定于該產品的信息。有關其他相關信息,請參閱以下文檔:

2 Overview
?Cortex-A715核心是一款平衡性能、低功耗和資源受限的產品,實現了Armv9.0-A架構。Armv9.0-A架構是在Arm?v8-A架構基礎上擴展的,延伸到了Arm?v8.5-A。它適用于大屏計算應用和智能手機應用。
Cortex-A715核心的主要特點包括:
? 實現了Armv9.0-A A64指令集。
? 所有異常級別(EL0到EL3)都支持AArch64執行狀態。
? 內存管理單元(MMU)。
? 40位物理地址(PA)和48位虛擬地址(VA)。
? 通用中斷控制器(GIC)CPU接口,可連接到外部中斷分發器。
? 支持從外部系統計數器輸入的64位計數的通用定時器接口。
? 實現了可靠性、可用性和可維護性(RAS)擴展。
? 實現了具有128位矢量長度的可伸縮矢量擴展(SVE)和可伸縮矢量擴展2(SVE2)。
? 集成執行單元,具有先進的單指令多數據(SIMD)和浮點支持。
? 支持可選擇的加密擴展,需要單獨許可。
? 活動監視單元(AMU)。
? 單獨的L1數據和指令緩存。
? 私有的統一的L2數據和指令緩存。
? 可選擇的錯誤保護,可以在L1指令和數據緩存、L2緩存和L2轉換后備緩沖器(TLB)上進行奇偶校驗或錯誤糾正碼(ECC),實現單錯誤糾正和雙錯誤檢測(SECDED)。
? 支持內存系統資源分區和監控(MPAM)。
? Armv9.0-A調試邏輯。
? 性能監測單元(PMU)。
? 嵌入式跟蹤宏單元(ETM),支持嵌入式跟蹤擴展(ETE)。
? 跟蹤緩沖器擴展(TRBE)。
? 可選擇的統計分析擴展(SPE)實現。
? 可選擇的嵌入式邏輯分析儀(ELA),ELA-600。
本文檔描述了Cortex-A715核心微體系結構中影響軟件性能的元素,以便可以相應地優化軟件和編譯器。
2.1 Pipeline overview
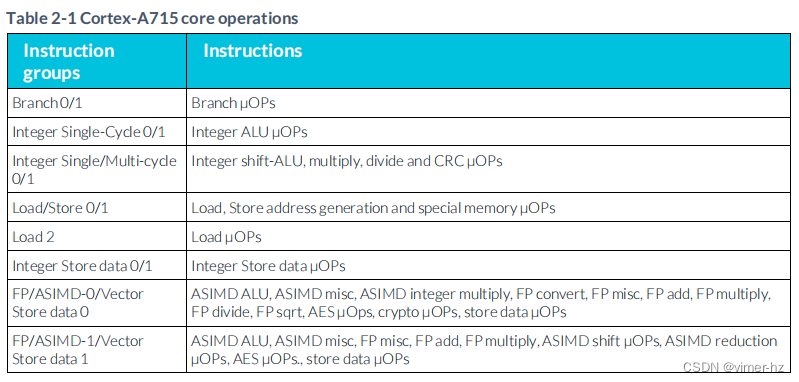
下圖描述了高級別的Cortex-A715指令處理流水線。
指令首先被獲取,然后解碼為內部的宏操作(MOPs)。
然后,MOPs通過寄存器重命名和調度階段進行處理。
在解碼階段之后,一個MOP可以被拆分為兩個微操作(μOPs)。
一旦調度完成,μOPs等待其操作數,并按順序發出到13個發射流水線中的其中一個。
每個發射流水線每個周期可以接受一個μOP。

//順序(in order)取指,亂序(out of order)執行
執行管道支持不同類型的操作,如下表所示。
3 Instruction characteristics
3.1 Instruction tables
本章描述了大多數Armv9-A指令的高級性能特征。一系列表格總結了有效的執行延遲和吞吐量(每個周期的指令帶寬),所使用的流水線以及與每組指令相關的特殊行為。所使用的流水線對應于第2章中描述的執行管道。
在下面的表格中,執行延遲(Exec Latency)被定義為依賴于所描述組中的指令的操作所觀察到的最小延遲。
在下面的表格中,執行吞吐量(Execution Throughput)被定義為可以在Cortex-A715核心微架構的整體上實現的指定指令組的最大吞吐量(每個周期的指令數)。
3.2 Legend for reading the utilized pipelines? ? //閱讀所使用的流水線的圖例
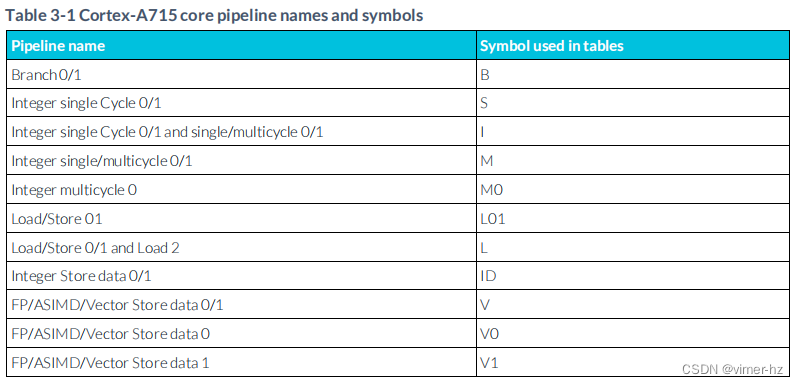
//Pipeline name
3.3 Branch instructions
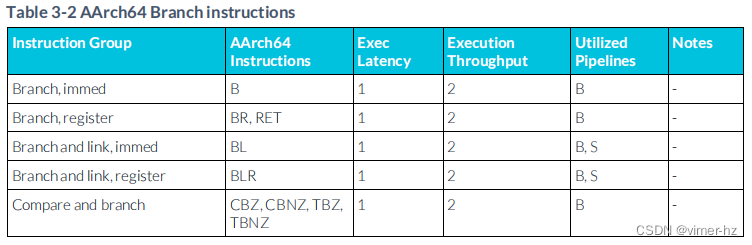
//Exec Latency
//Execution Throughput
//Utilized Pipelines
3.4 Arithmetic and logical instructions
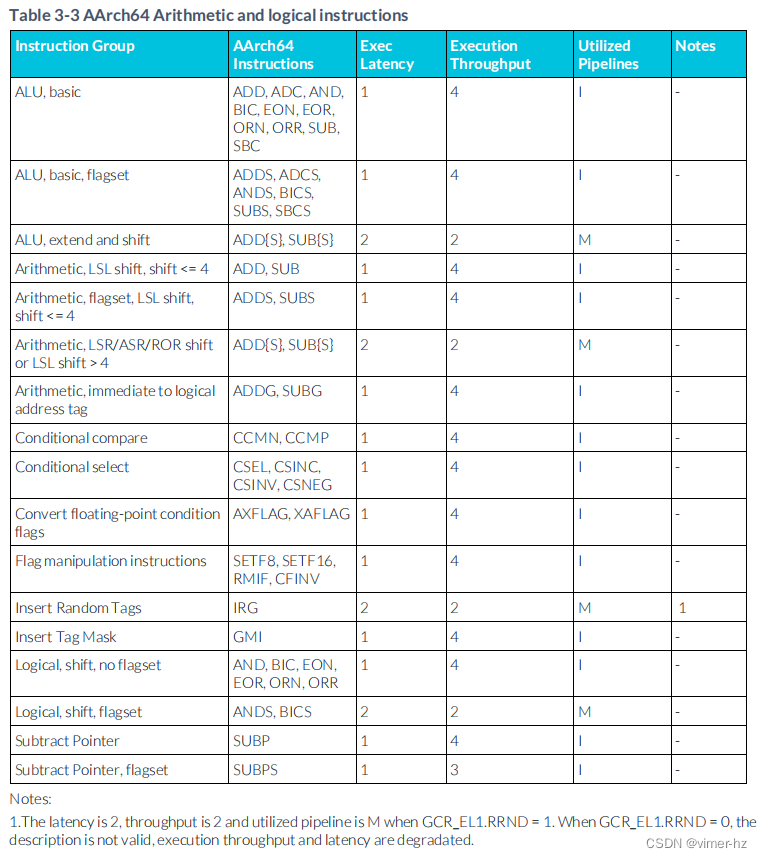
"Degradated" 的正確拼寫應為 "degraded",表示降級或惡化的意思。
GCR_EL1.RRND 是 ARM 架構中的一個寄存器位,用于控制隨機數生成器。RRND 代表 Random Number Register Disable,即禁用隨機數寄存器的意思。
注:
1. 當 GCR_EL1.RRND = 1 時,延遲為2,吞吐量為2,并且所使用的流水線是 M。當 GCR_EL1.RRND = 0 時,描述無效,執行吞吐量和延遲會降低。
3.5 Divide and multiply instructions
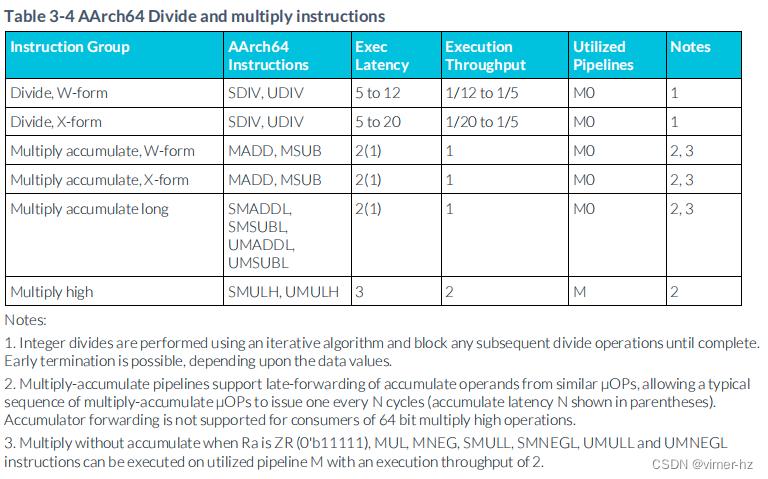
注:
1. 整數除法使用迭代算法進行,并在完成之前阻塞任何后續的除法操作。根據數據值,可能會進行早期終止。
2. 乘累加流水線支持從類似的μOP中延遲轉發累加操作數,允許典型的乘累加μOP序列每N個周期發布一個(累加延遲N以括號表示)。累加器轉發不支持對64位乘積高位操作的使用者。
3. 當 Ra 為 ZR(0'b11111)時,MUL、MNEG、SMULL、SMNEGL、UMULL 和 UMNEGL 指令的乘法而不是累加可以在所使用的流水線 M 上執行,執行吞吐量為2。
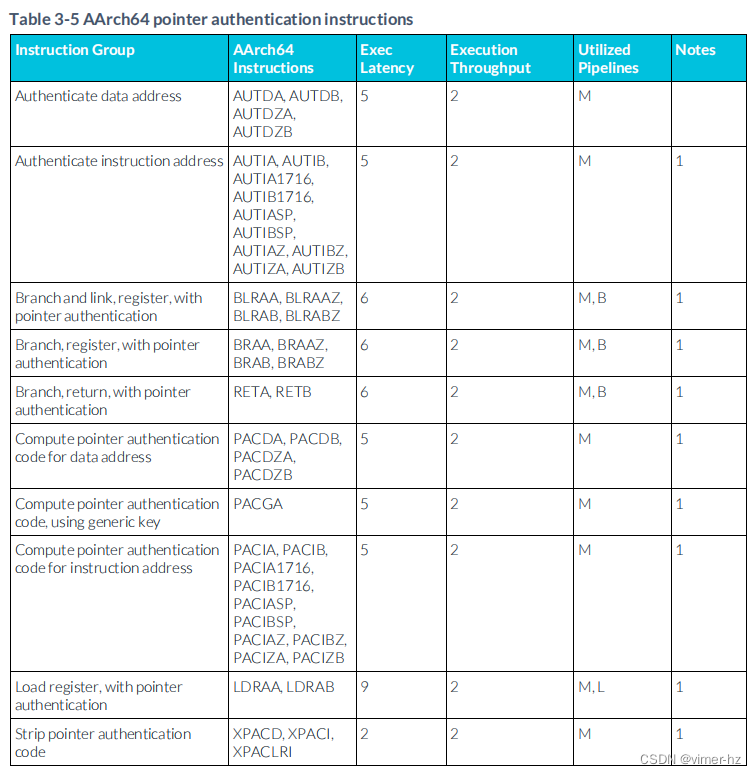
3.6 Pointer Authentication Instructions? ? //指針認證指令
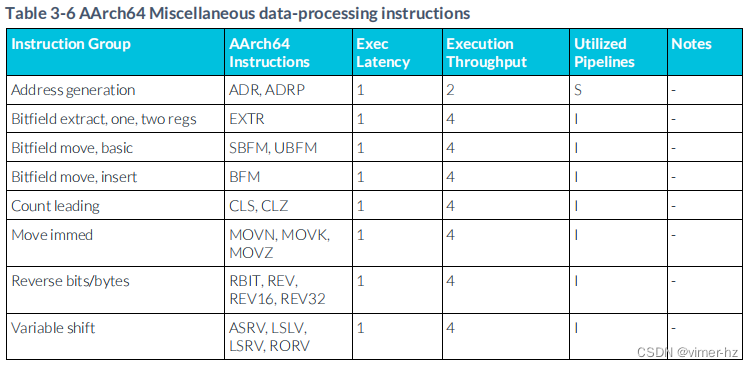
3.7 Miscellaneous data-processing instructions? ? //雜項數據處理指令
3.8 Load instructions
所示延遲假設存儲器訪問在一級數據緩存中命中,并表示加載指令寫入的所有寄存器的最大延遲。
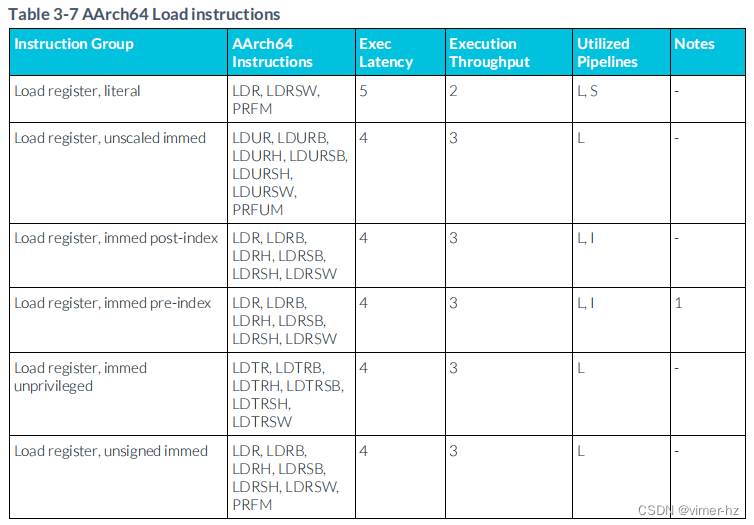
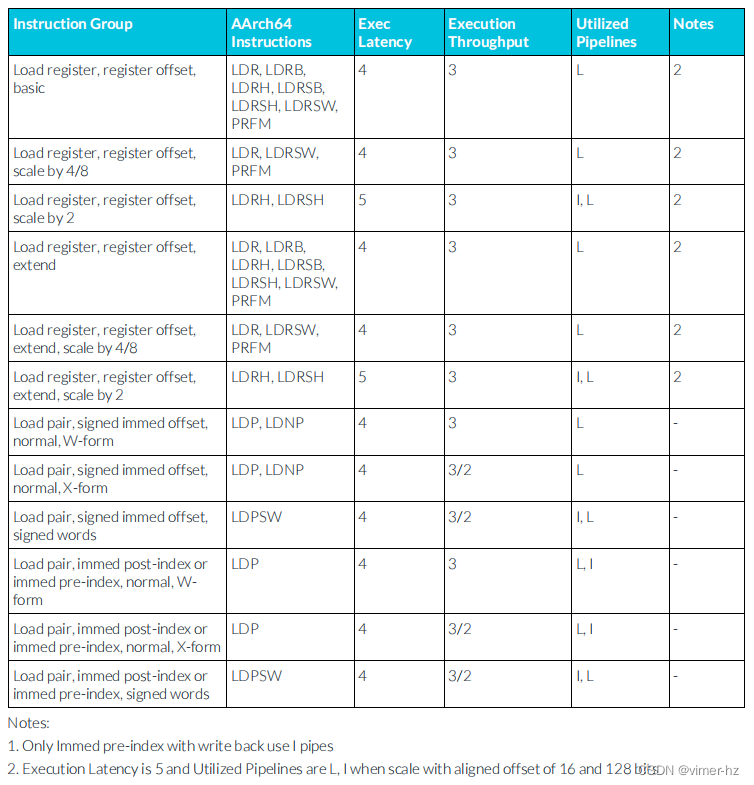
注:
1. 僅使用立即數作為預索引并帶有寫回的指令會使用 I 管道。
2. 執行延遲為5個周期,當使用16字節對齊的偏移和128位時,利用的流水線為 L、I。
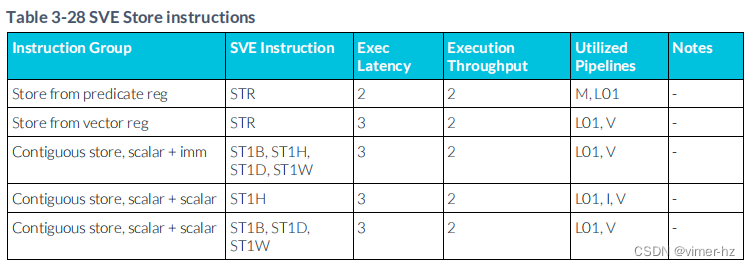
3.9 Store instructions
下表描述了標準存儲指令的性能特征。存儲微操作(μOPs)被分為地址和數據微操作。一旦執行,存儲器會在后臺進行緩沖和提交。
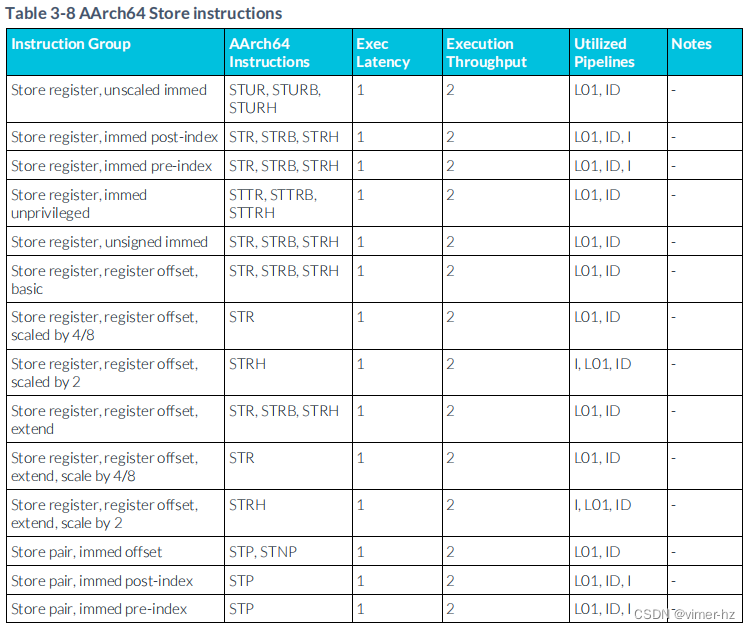
3.10 Tag Load Instructions

3.11 Tag Store instructions
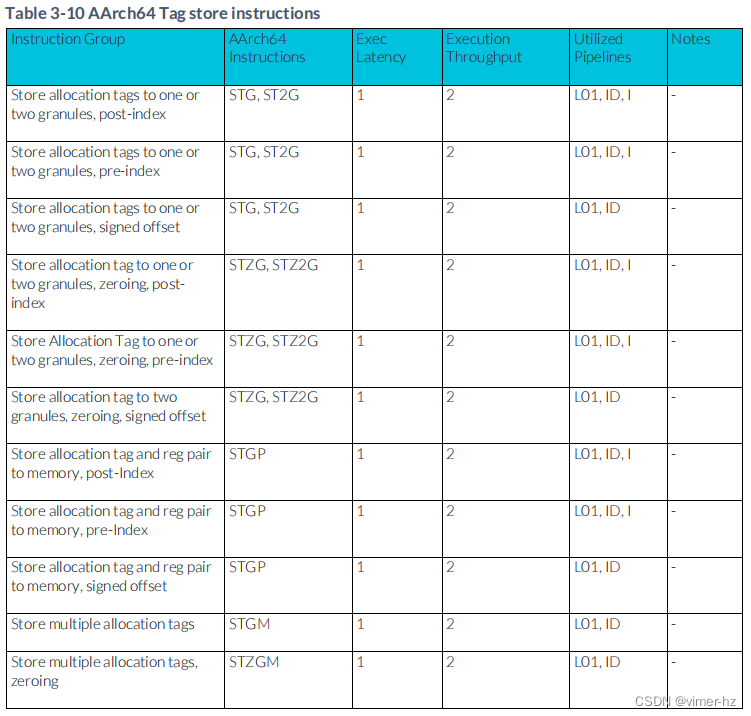
3.12 FP data processing instructions
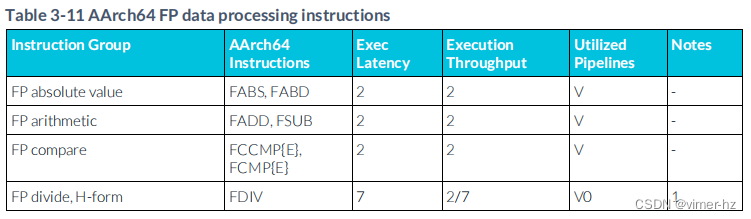
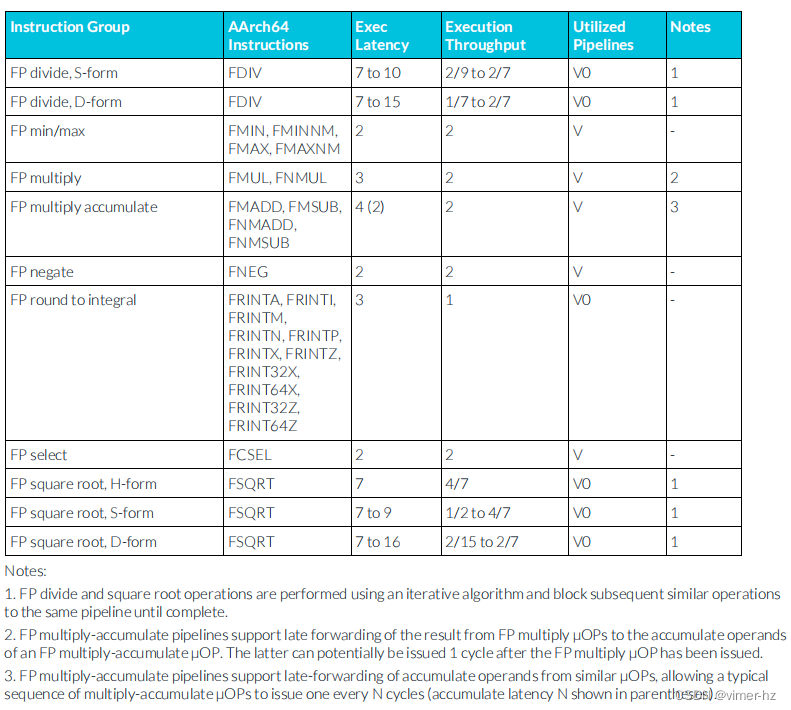
注:
1. 浮點除法和平方根操作使用迭代算法執行,并且會阻塞后續的相似操作直到完成。
2. 浮點乘累加流水線支持將浮點乘法微操作的結果延遲轉發到浮點乘累加微操作的累加操作數。后者在浮點乘法微操作發出后的1個周期內可能被發出。
3. 浮點乘累加流水線支持從相似微操作中延遲轉發累加操作數,允許一系列典型的乘累加微操作每N個周期發出一個(累加延遲為N,括號內顯示)。
3.13 FP miscellaneous instructions
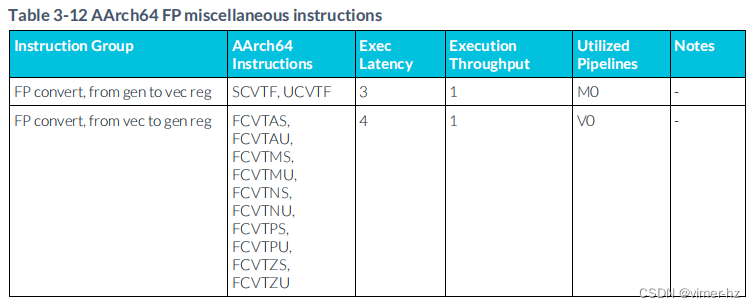
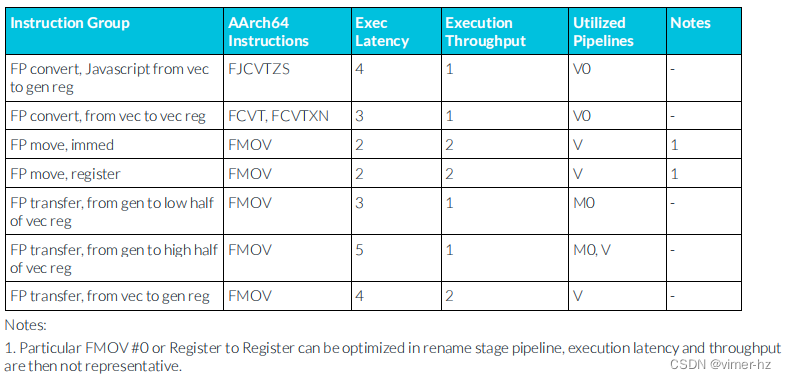
注:
1. 特定的FMOV #0或寄存器到寄存器操作可以在重命名階段的流水線中進行優化,因此執行延遲和吞吐量可能不具有代表性。
3.14 FP load instructions
所示的延遲假設內存訪問在一級數據緩存中命中,并且表示加載該指令寫入的所有向量寄存器的最大延遲。與標準加載相比,需要額外的一個周期來將結果轉發給浮點/ASIMD流水線。

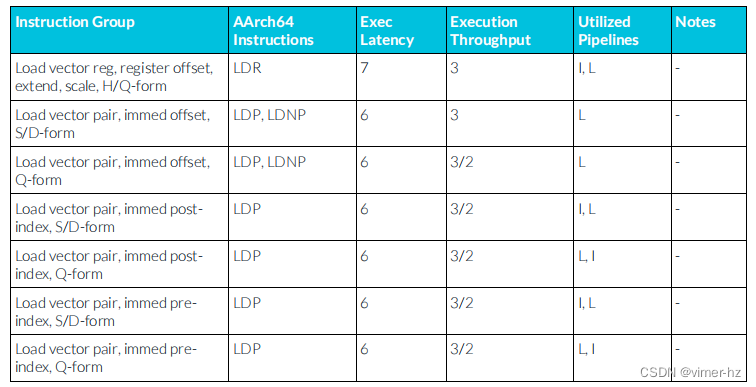
3.15 FP store instructions
存儲MOP(Memory Operation)被分成存儲地址和存儲數據的μOP(Micro Operation)。一旦執行,存儲將被緩沖并在后臺提交。
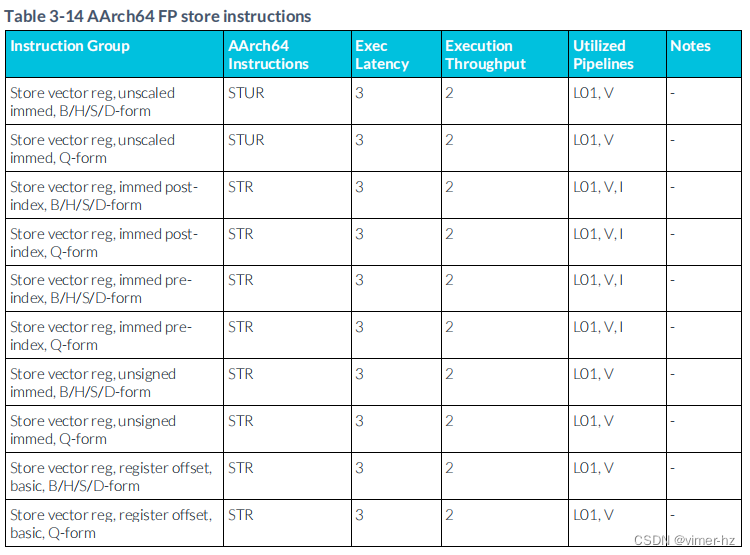
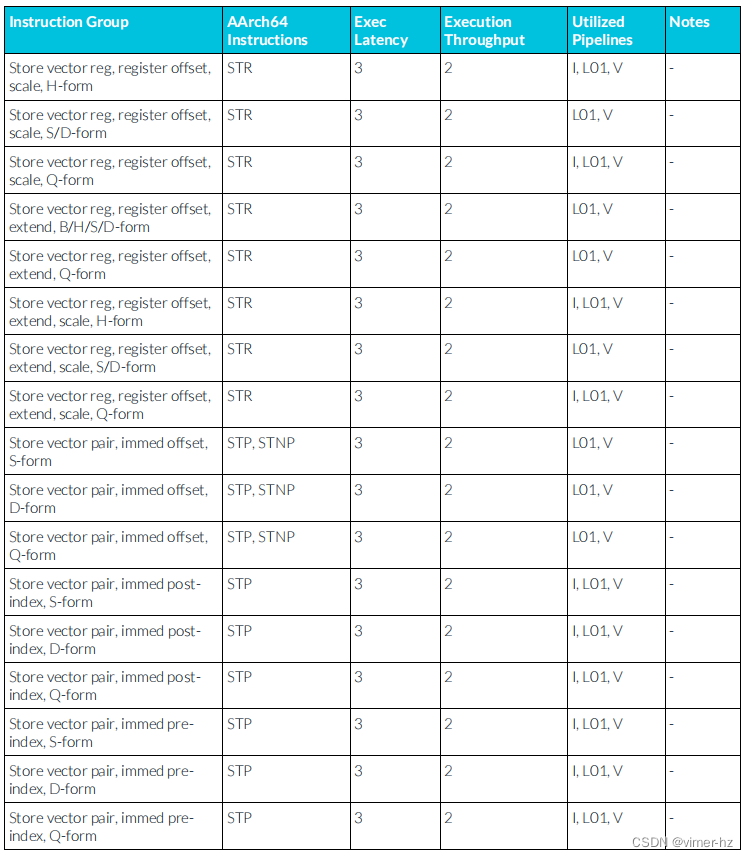
3.16 ASIMD integer instructions

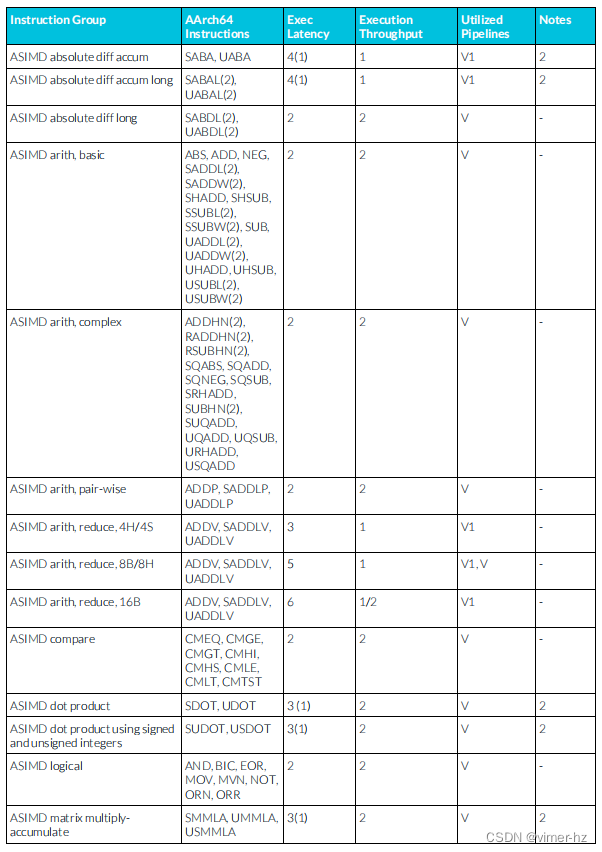
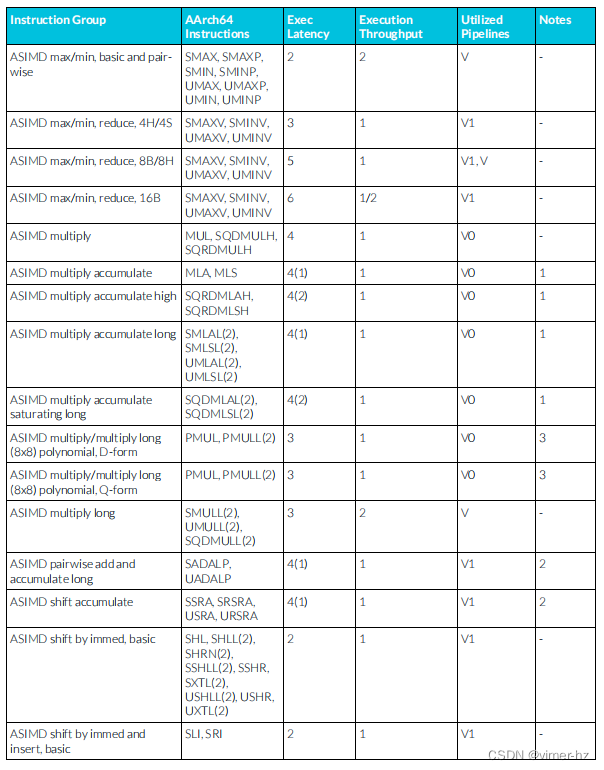
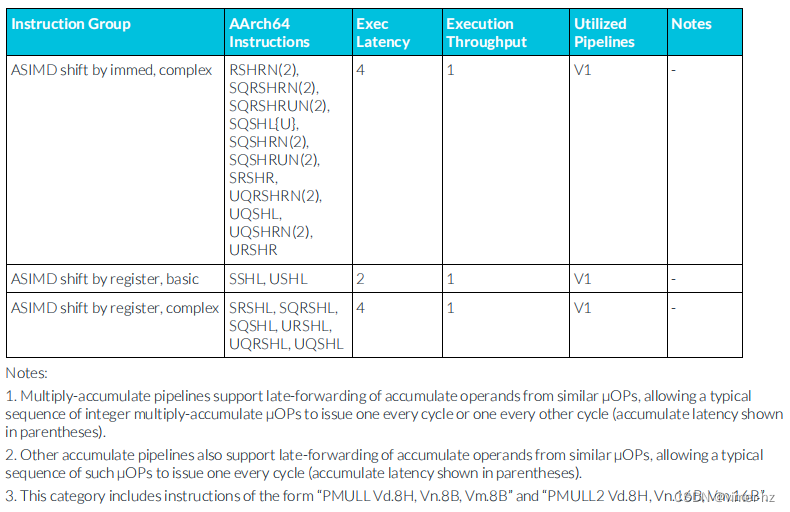
注:
1. 乘累加流水線支持從類似μOP中延遲轉發累加操作數,允許典型的整數乘累加μOP序列每個周期發出一個或每兩個周期發出一個(累加延遲以括號表示)。
2. 其他累加流水線也支持從類似μOP中延遲轉發累加操作數,允許典型的這類μOP序列每個周期發出一個(累加延遲以括號表示)。
3. 此類指令包括形如“PMULL Vd.8H,Vn.8B,Vm.8B”和“PMULL2 Vd.8H,Vn.16B,Vm.16B”的指令。
3.17 ASIMD floating-point instructions
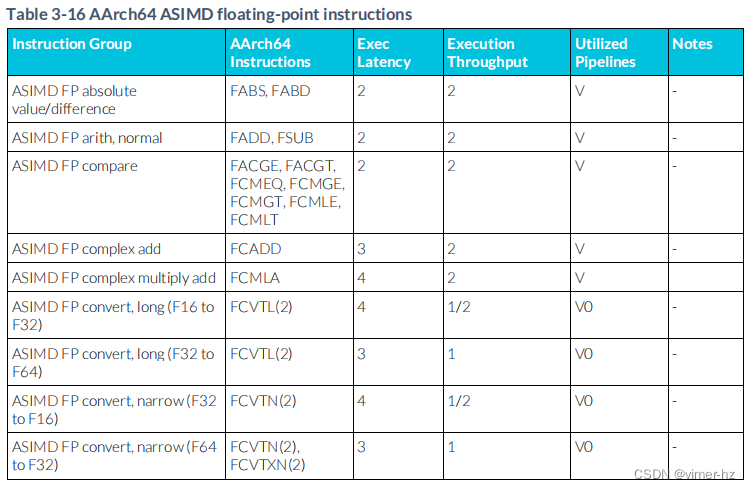
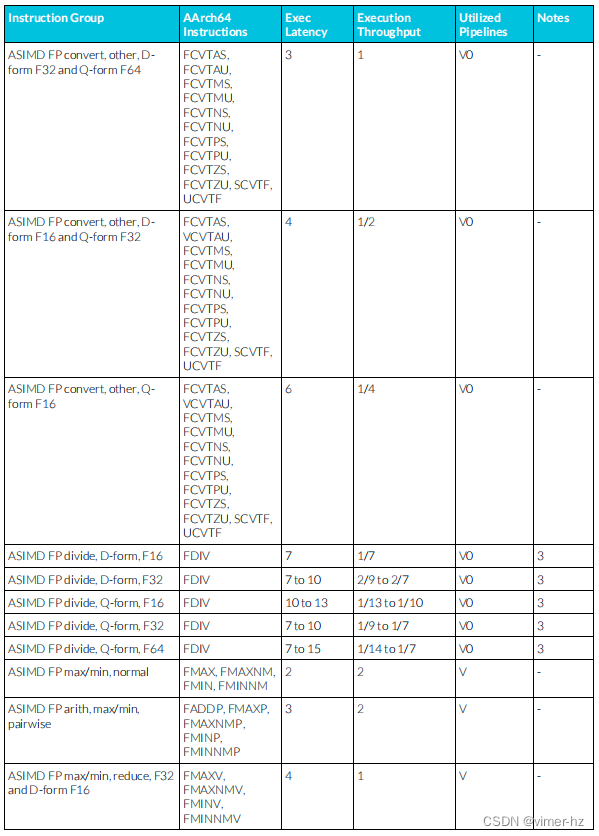
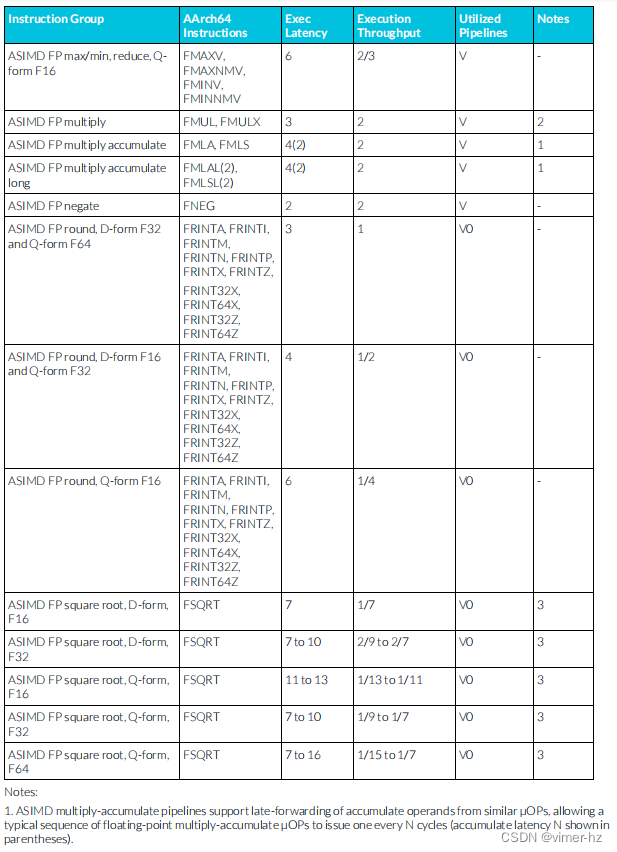
注:
1. ASIMD乘累加流水線支持從類似μOP中延遲轉發累加操作數,允許典型的浮點數乘累加μOP序列每N個周期發出一個(累加延遲N以括號表示)。
2. ASIMD乘累加流水線支持從ASIMD FP乘法μOP的結果延遲轉發到ASIMD FP乘累加μOP的累加操作數。后者可以在發出ASIMD FP乘法μOP后的1個周期內發出。
3. ASIMD除法和平方根操作使用迭代算法執行,并將后續類似操作阻塞在同一流水線上,直到完成。
3.18 ASIMD BFloat16 (BF16) instructions
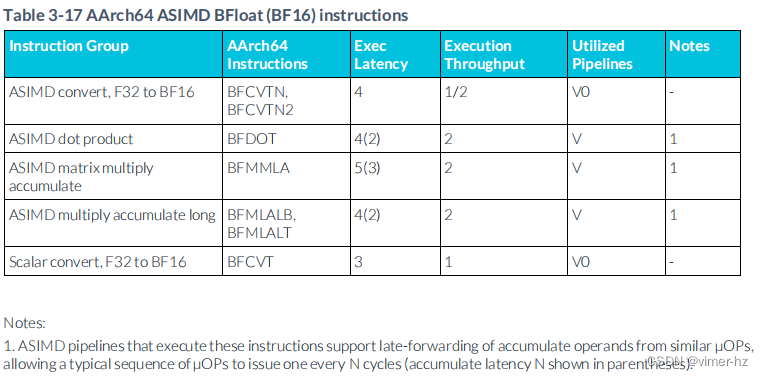
3.19 ASIMD miscellaneous instructions
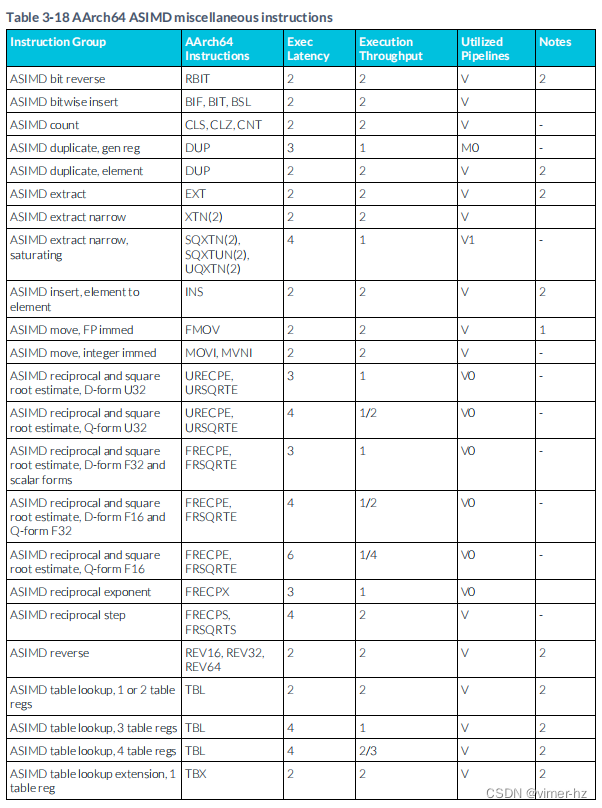
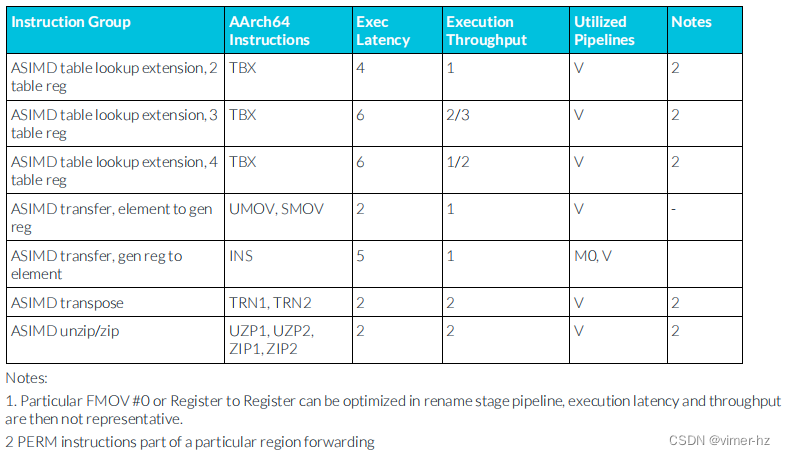
注:
1. 在重命名階段的流水線中,特定的FMOV #0指令或寄存器之間的傳輸可以進行優化,此時執行延遲和吞吐量可能不具有代表性。
2. PERM指令屬于特定區域的轉發。
3.20 ASIMD load instructions
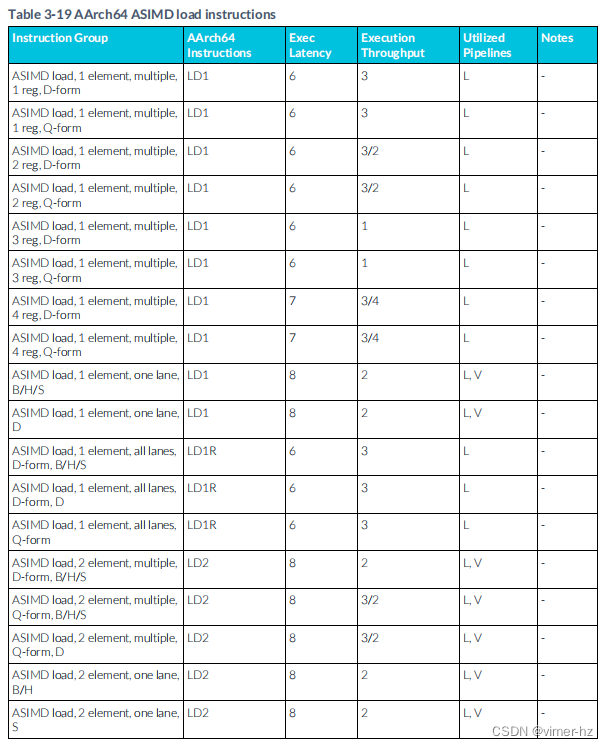
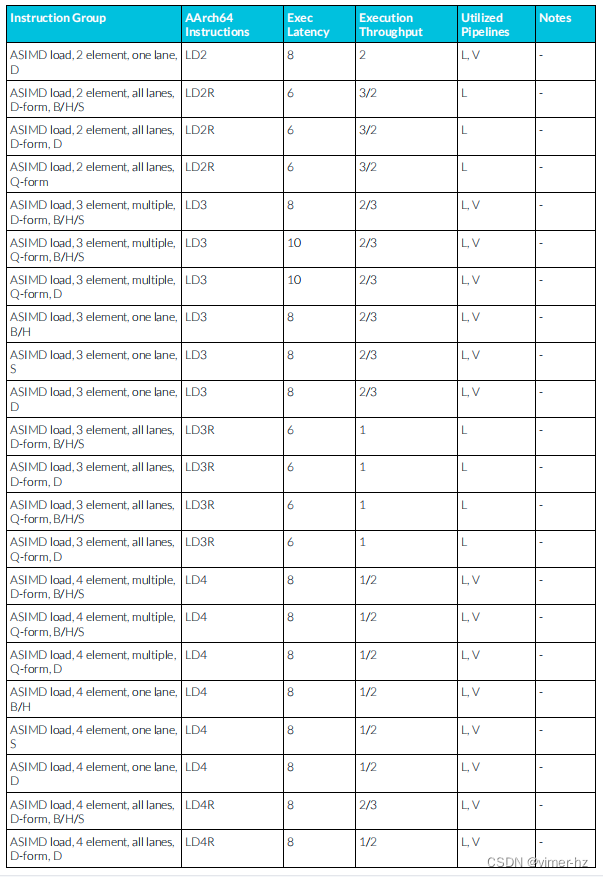
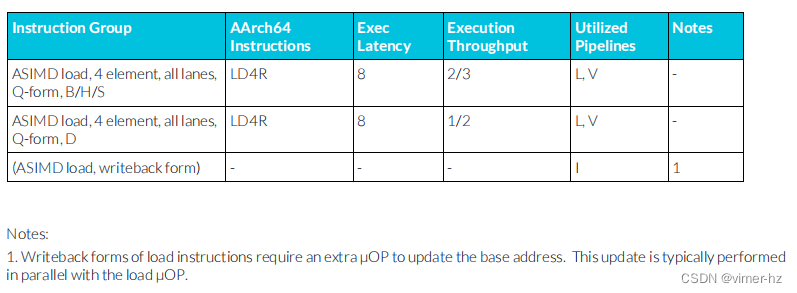
注:
1. 寫回形式的加載指令需要額外的μOP來更新基地址。這個更新通常與加載μOP并行執行。
3.21 ASIMD store instructions
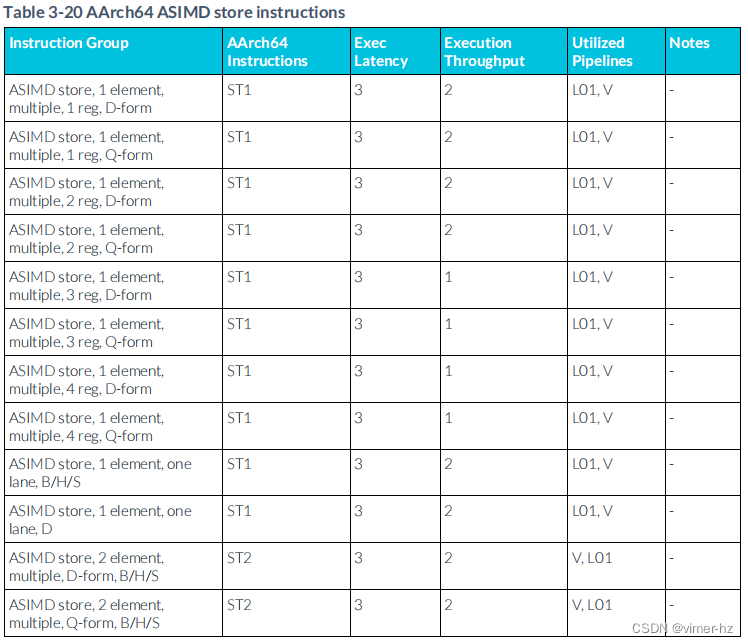
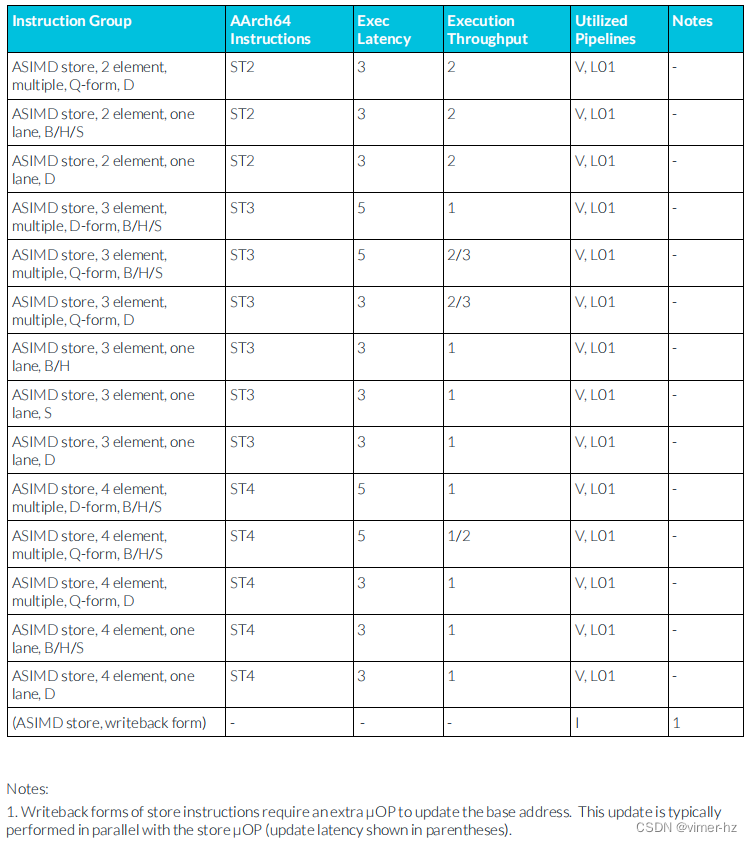
注:
1. 寫回形式的存儲指令需要額外的μOP來更新基地址。這個更新通常與存儲μOP并行執行(更新延遲時間在括號中顯示)。
3.22 Cryptography extensions? ? //密碼學擴展

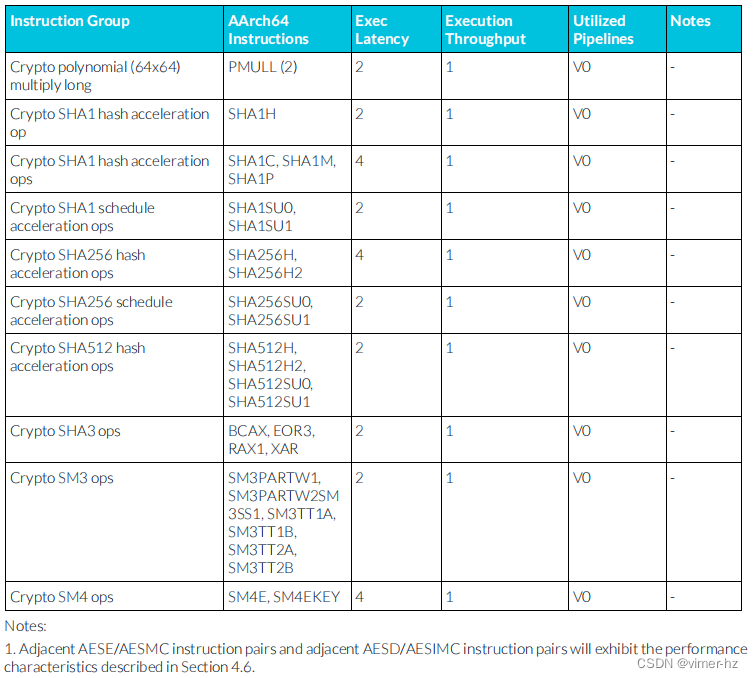
注:
1. 連續的AESE/AESMC指令對和連續的AESD/AESIMC指令對將會呈現出第4.6節中描述的性能特征。
3.23 CRC

注:
1. CRC執行支持將結果從生產者μOP延遲轉發給消費者μOP。這將導致消費者端看到的延遲減少1個周期。
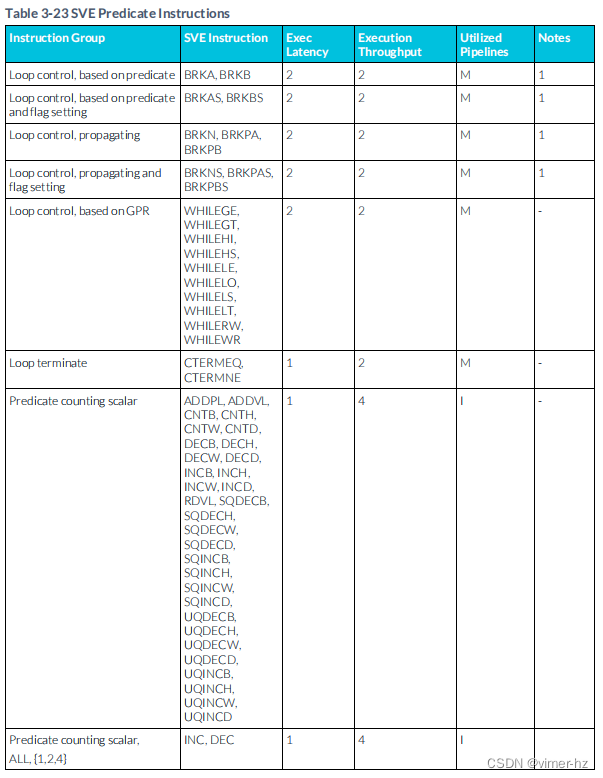
3.24 SVE Predicate instructions
SVE(Scalable Vector Extension)謂詞指令是指針對SVE架構中的謂詞寄存器進行操作的指令。謂詞寄存器是一種特殊的寄存器,用于表示向量元素的有效性或執行控制條件。SVE謂詞指令允許開發人員根據需要設置、清除和測試謂詞寄存器。
Scalable: 可擴展的
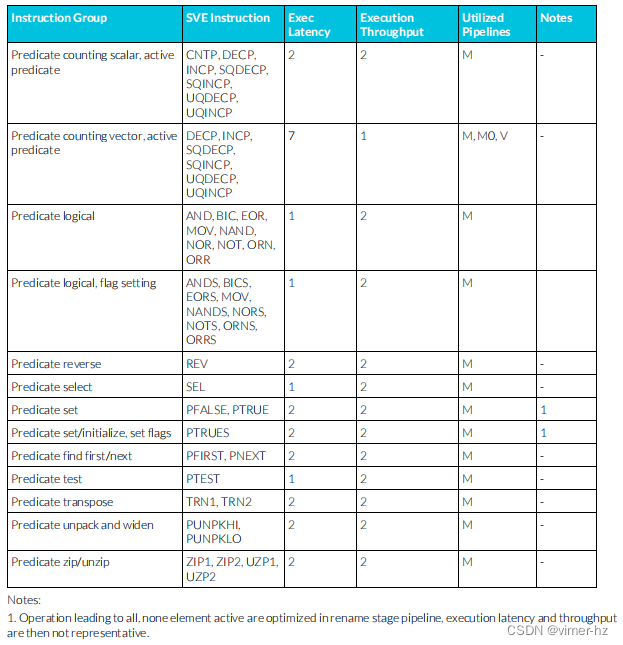
注:
1. 導致所有元素活動或無元素活動的操作在重命名階段的流水線中進行優化,因此執行延遲和吞吐量不具有代表性。
3.25 SVE integer instructions
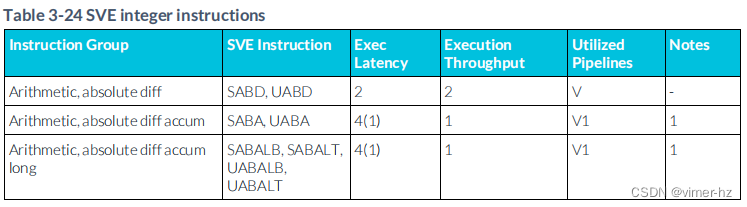
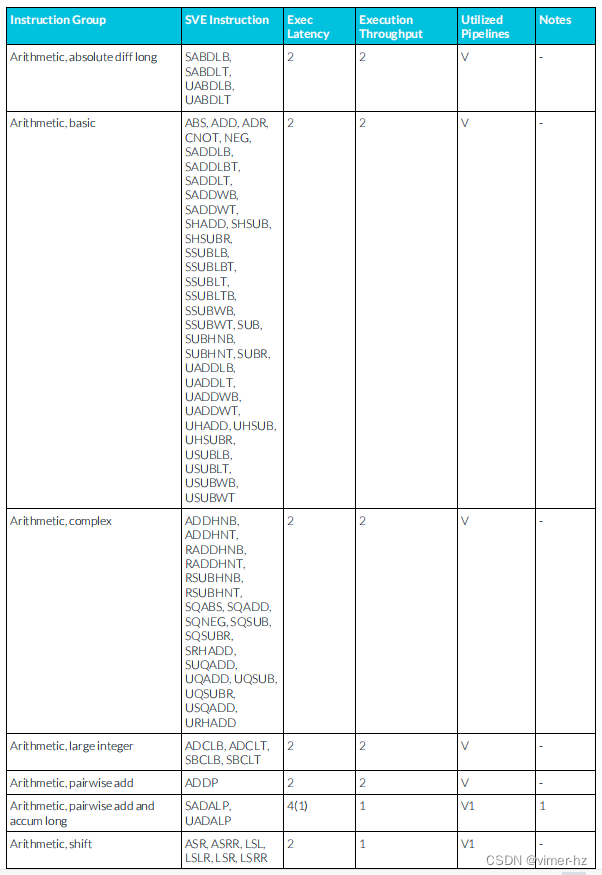
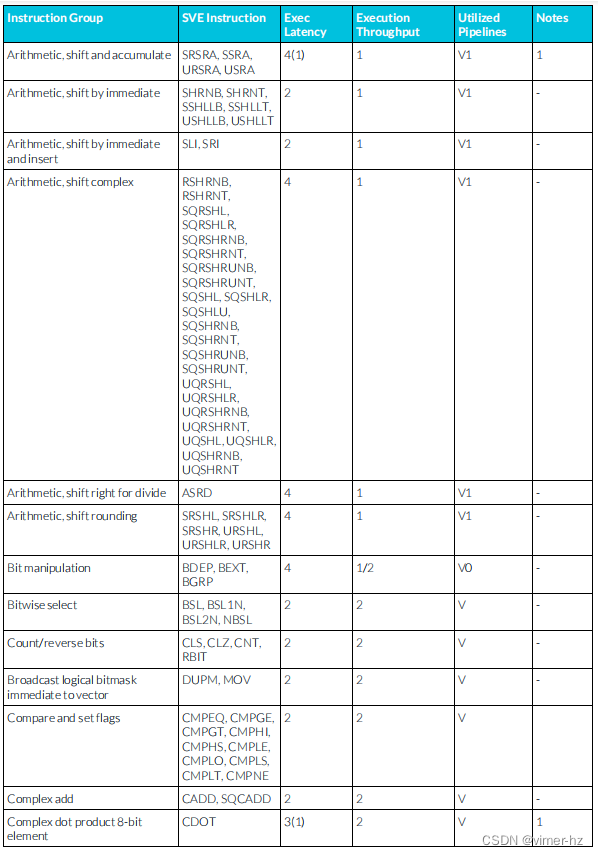
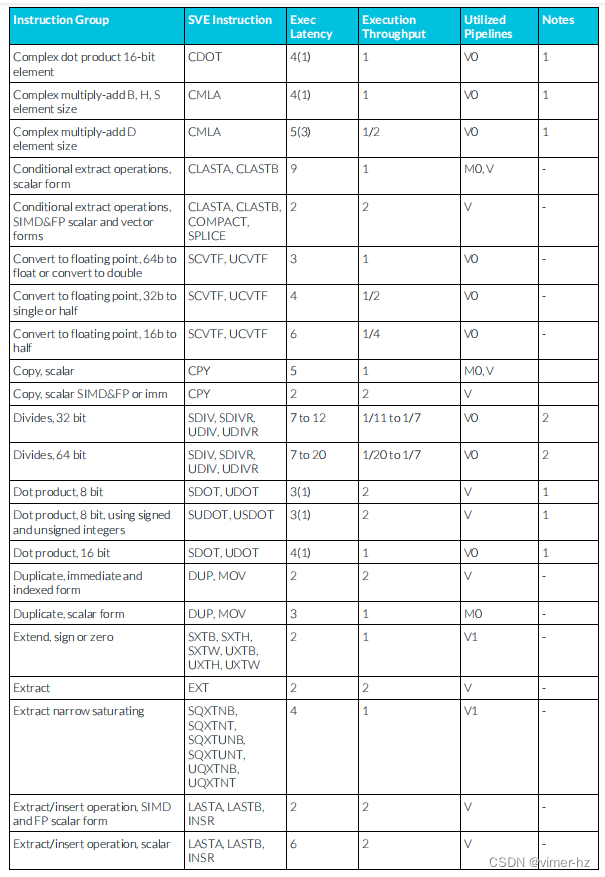
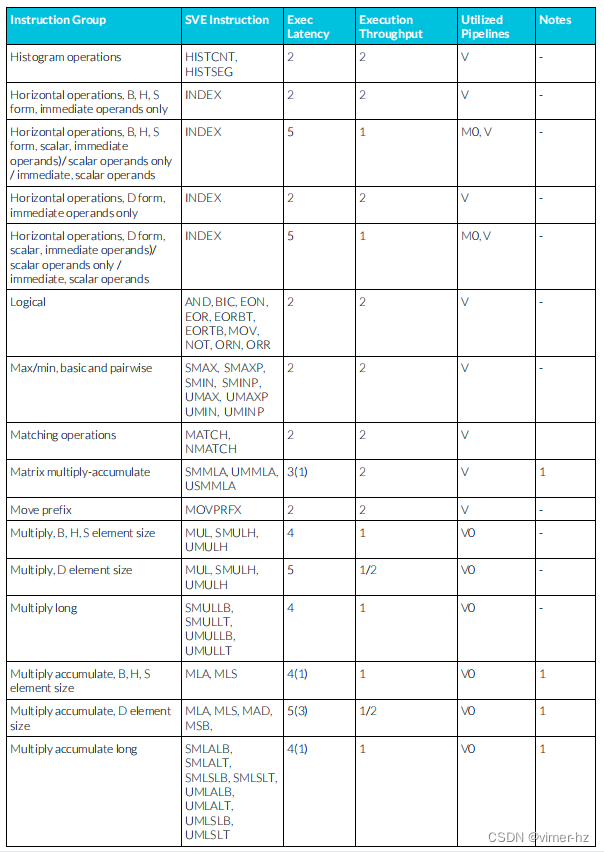
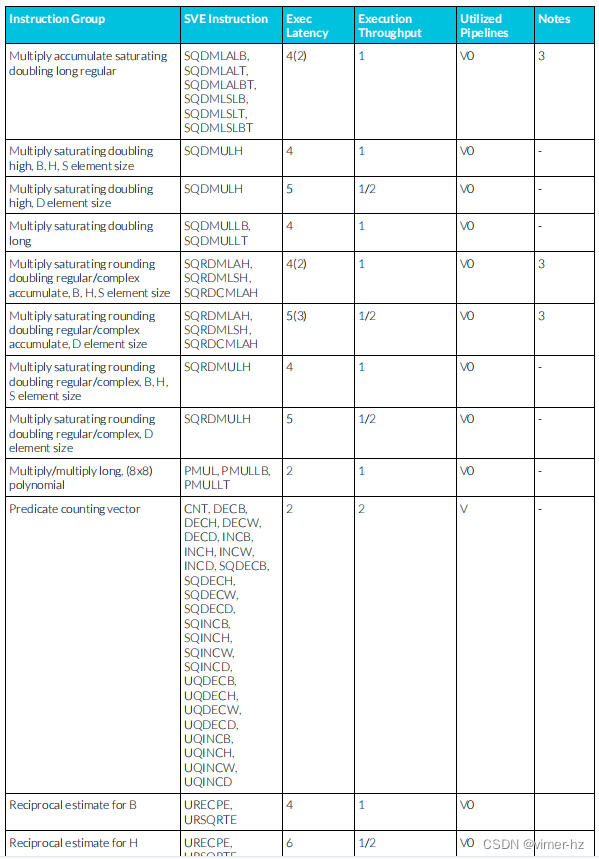
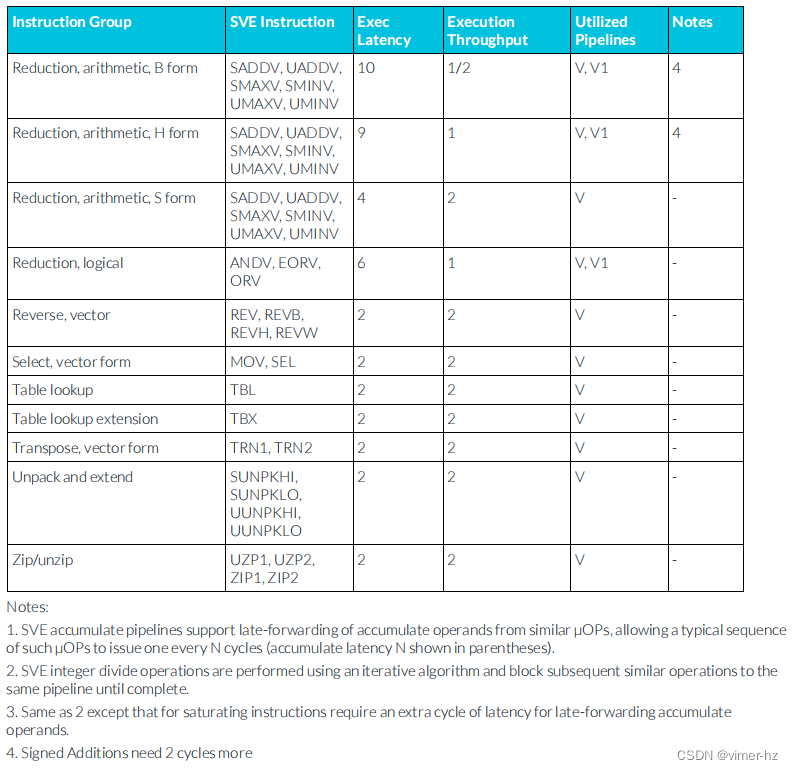
注:
1. SVE累加流水線支持從相似μOP中延遲轉發累加操作數,允許一個典型的這樣的μOP序列每N個周期發出一個(累加延遲N顯示在括號中)。
2. SVE整數除法操作使用迭代算法執行,并阻止后續相似操作進入同一條流水線,直到完成為止。
3. 與2相同,但飽和指令需要額外的一個周期延遲來進行延遲轉發累加操作數。
4. 有符號加法需要多2個周期。
3.26 SVE floating-point instructions
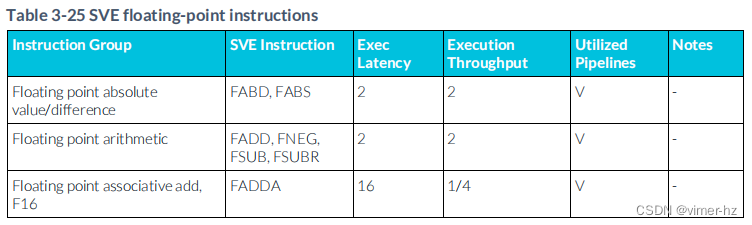
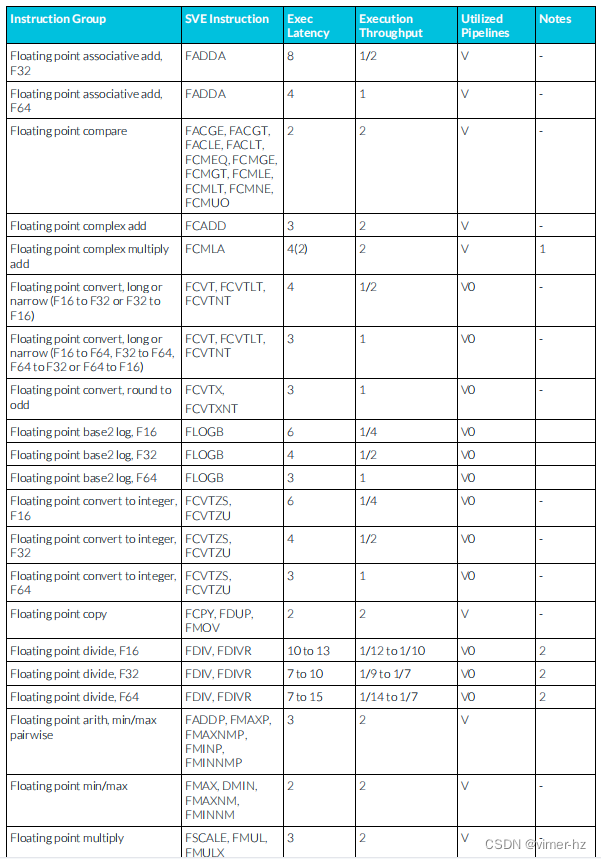
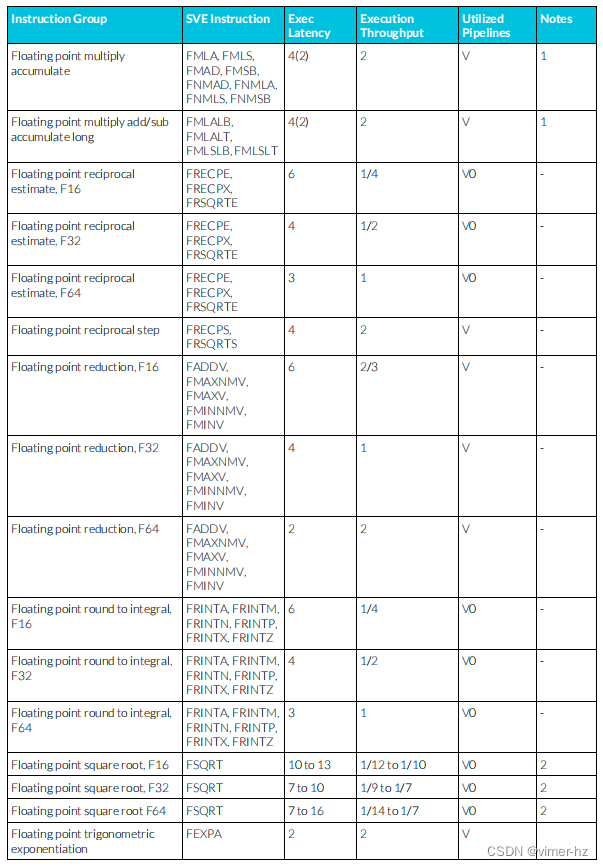
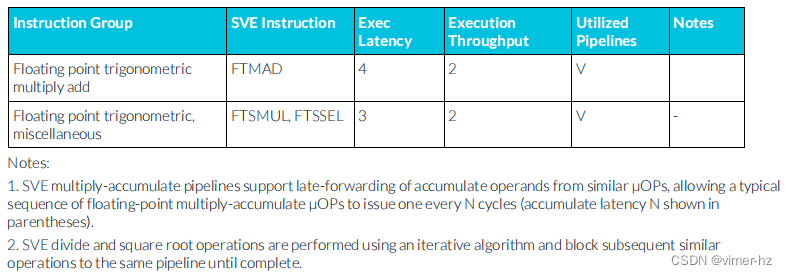
注:
1. SVE乘加流水線支持從相似μOP中延遲轉發累加操作數,允許一個典型的浮點乘加μOP序列每N個周期發出一個(累加延遲N顯示在括號中)。
2. SVE除法和平方根操作使用迭代算法執行,并阻止后續相似操作進入同一條流水線,直到完成為止。
3.27 SVE BFloat16 (BF16) instructions
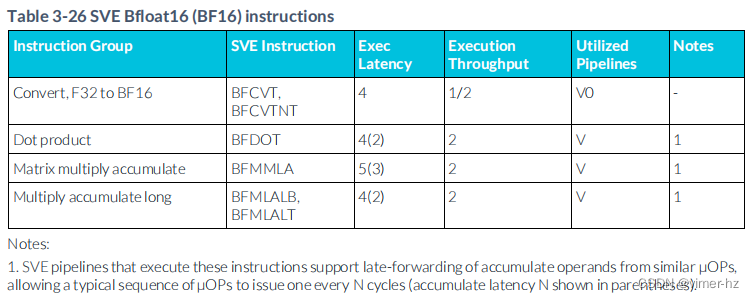
注:
1. 執行這些指令的SVE流水線支持從相似μOP中延遲轉發累加操作數,允許一個典型的μOP序列每N個周期發出一個(累加延遲N顯示在括號中)。
3.28 SVE Load instructions
所顯示的延遲假設內存訪問命中一級數據緩存,并表示加載指令寫入的所有向量寄存器的最大延遲。
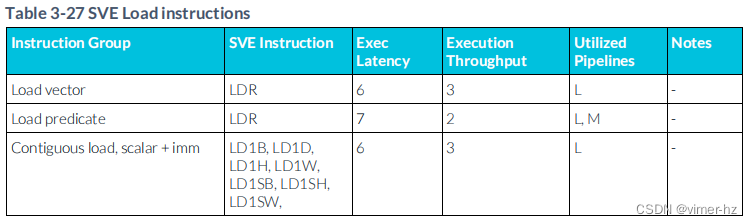
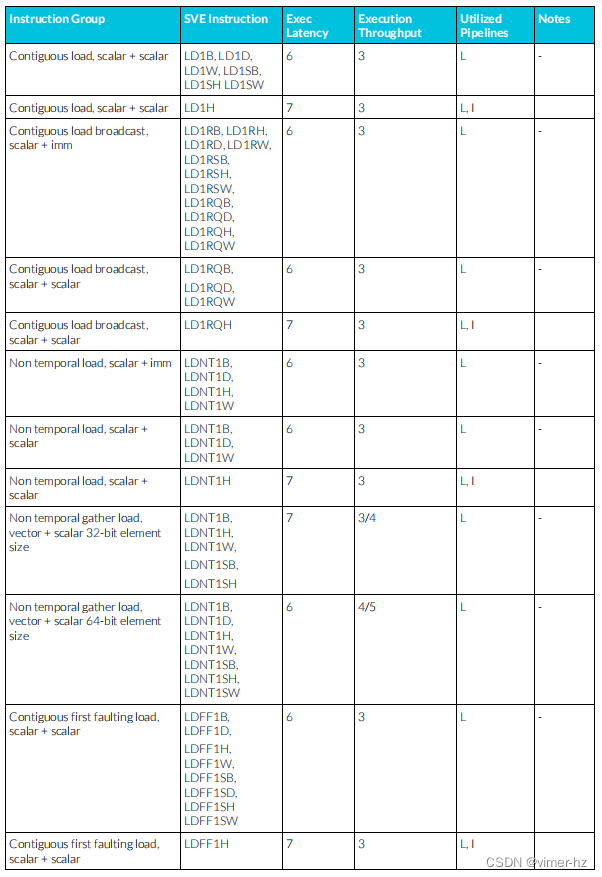
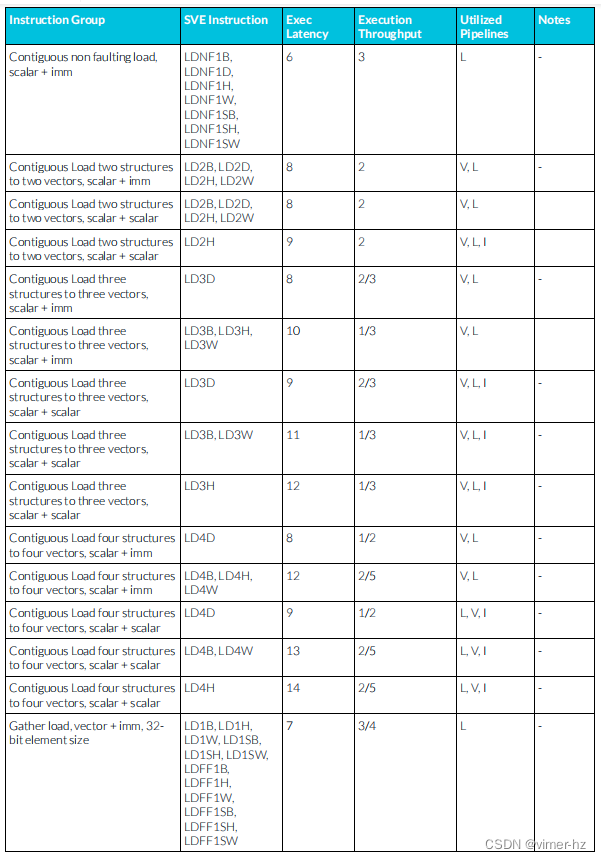
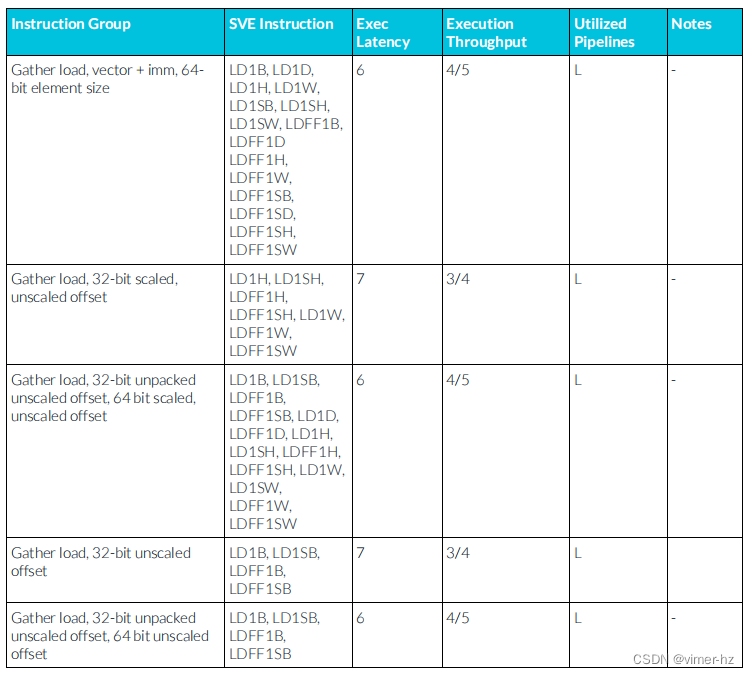
3.29 SVE Store instructions
scalar:標量
vector:向量
CPU SVE(Scalable Vector Extensions)指令集針對的是向量操作。它引入了可擴展的向量長度概念,允許在單個指令中同時處理多個數據元素,從而加速向量計算。SVE指令集的設計目的是優化向量處理能力,提高并行計算性能和能效。因此,SVE指令集主要用于支持向量操作,而不是標量操作。
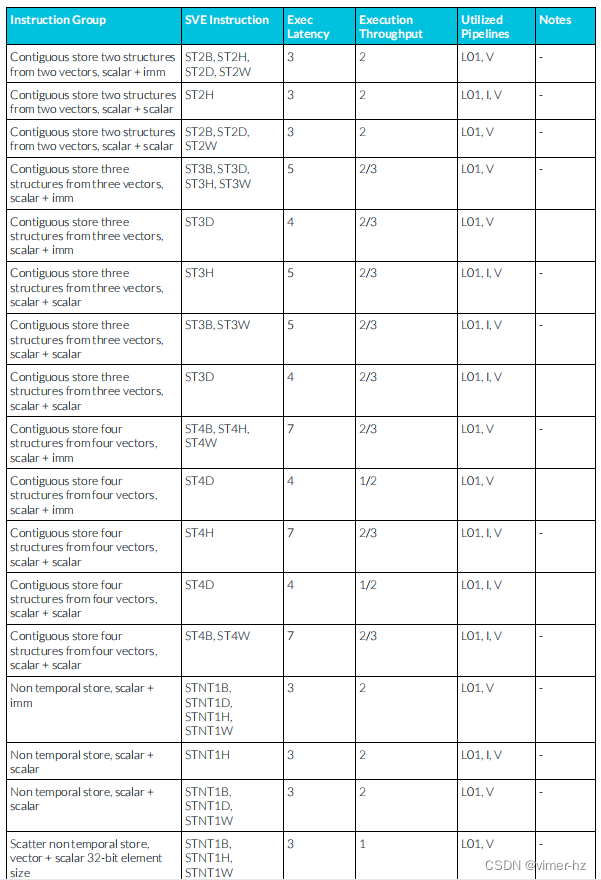
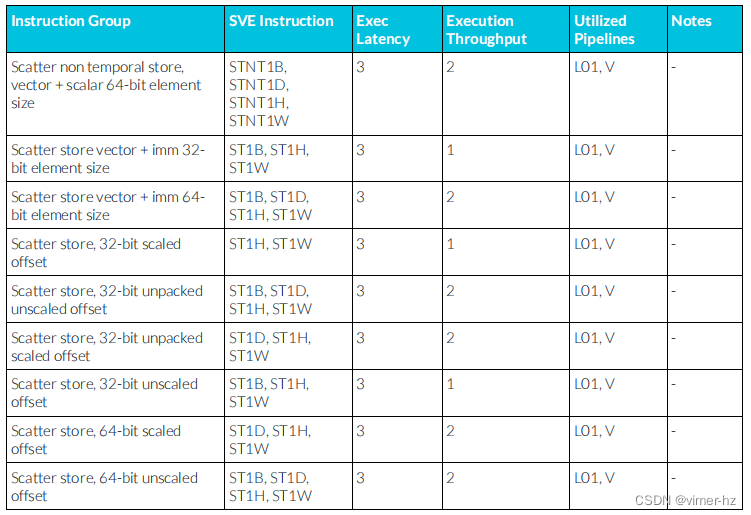
3.30 SVE Miscellaneous instructions
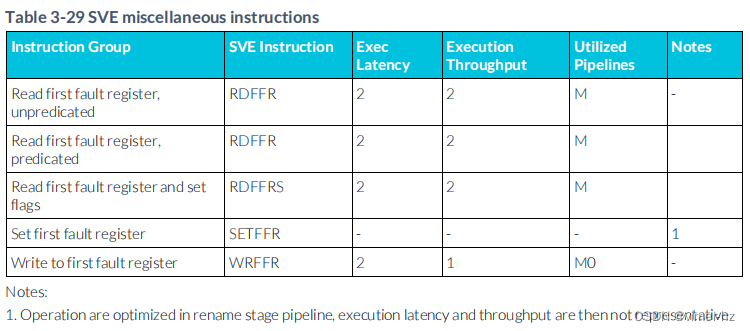
注釋:
1. 操作在重命名階段的流水線中進行了優化,因此執行延遲和吞吐量并不代表性。
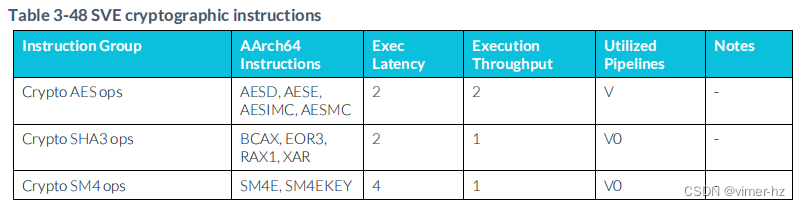
3.31 SVE Cryptographic instructions
4 Special considerations
4.1 Dispatch constraints? ? //調度約束
從微架構的按順序部分到亂序部分的μOP的調度包括幾個限制條件。在代碼生成過程中,考慮這些限制條件對于最大化Cortex-A715核心的有效調度帶寬和后續執行帶寬非常重要。
調度階段每個周期最多能處理5個MOP,并且每個周期最多能調度10個μOP,其中對于每種類型μOP的同時調度數量存在以下限制:
- 最多同時調度4個利用S或B流水線的μOP
- 最多同時調度4個利用M流水線的μOP
- 最多同時調度2個利用M0流水線的μOP
- 最多同時調度2個利用V0流水線的μOP
- 最多同時調度2個利用V1流水線的μOP
- 最多同時調度5個利用L流水線的μOP
如果在給定周期內有更多可供調度的μOP數量超過上述限制條件所支持的數量,則μOP將按照從最老到最新的順序盡可能按照上述限制條件進行調度。
4.2?Optimizing general-purpose register spills and fills? ? //優化通用寄存器的溢出和填充
在通用寄存器(GPR)和ASIMD寄存器(VPR)之間進行寄存器傳輸的延遲比訪問緩存層次結構的讀寫操作要低。因此,建議盡可能將GPR寄存器的填充/溢出操作轉移到VPR寄存器中,而不是內存中。
通過將GPR寄存器的數據直接傳輸到VPR寄存器,可以避免訪問緩存層次結構所引起的延遲和額外的存儲器訪問開銷。這樣做可以提高程序的執行效率和性能,并減少對內存的依賴。
當編譯器進行寄存器溢出和填充優化時,應優先考慮將GPR寄存器的數據移動到VPR寄存器中,而不是直接溢出到內存。這需要基于變量的生命周期和使用模式,以及可用寄存器的情況,做出合理的決策。
然而,需要注意的是,由于VPR寄存器數量有限,如果所有的GPR寄存器都需要被填充到VPR寄存器中,可能會導致寄存器分配瓶頸。在實際優化中,需要綜合考慮寄存器的可用性和數據傳輸的開銷,以在GPR寄存器和VPR寄存器之間實現最佳的數據遷移策略。
總而言之,通過將GPR寄存器的填充/溢出操作轉移到VPR寄存器中,可以利用低延遲的寄存器傳輸,提高程序性能。但在進行優化時,需要考慮寄存器的分配情況和數據遷移開銷,以獲得最佳的性能提升。
4.3 Optimizing memory routines
要實現內存復制(或類似循環)的最大吞吐量,應按照以下方法進行操作:
1. 循環展開:展開循環以每個迭代包含多個加載和存儲操作,從而減少循環的開銷。
2. 在可能的情況下,將存儲操作按32字節邊界對齊。這種對齊可以提高內存傳輸的效率,特別是在處理大塊數據時。
3. 使用非寫回形式的LDP和STP指令,并像下面的示例一樣交錯使用它們:
Loop_start:
SUBS x2,x2,#96
LDP q3,q4,[x1,#0]
STP q3,q4,[x0,#0]
LDP q3,q4,[x1,#32]
STP q3,q4,[x0,#32]
LDP q3,q4,[x1,#64]
STP q3,q4,[x0,#64]
ADD x1,x1,#96
ADD x0,x0,#96
BGT Loop_start
如果要復制的內存位置是非可緩存的,應使用非臨時版本的LDPQ(LDNPQ)。存儲仍然應使用STPQ。
//非寫回形式LDP/STP指令,從內存加載數據后不會修改寄存器的值,還是沒理解???
同樣,建議對比較可緩存內存的memcmp(內存比較)循環使用LDPQ以實現最大吞吐量。非可緩存內存應使用LDNPQ。
要在memset上實現最大吞吐量,建議按照以下步驟進行操作。
展開循環以每次迭代包含多個存儲操作,從而減少循環的開銷。
Loop_start:
STP q1,q3,[x0,#0]
STP q1,q3,[x0,#0x20]
STP q1,q3,[x0,#0x40]
STP q1,q3,[x0,#0x60]
ADD x0,x0,#0x80
SUBS x2,x2,#0x80
B.GT Loop_start
為了實現memset(將內存設置為零)的最佳性能,建議使用DC ZVA(按地址清零數據緩存)指令而不是STP(存儲一對)指令。一個最優的例程可能如下所示:
Loop_start:
SUBS x2,x2,#0x80
DC ZVA,x0
ADD x0,x0,#0x40
DC ZVA,x0
ADD x0,x0,#0x40
B.GT Loop_start
4.4 Load/Store alignment
Armv8-A 架構允許進行許多類型的加載和存儲訪問,它們可以是任意對齊的。Cortex-A715 核心可以處理大多數非對齊訪問而不會帶來性能損失。然而,以下情況可能會降低帶寬或增加額外的延遲:
? 跨越緩存行(64字節)邊界的加載操作。
? 不是4字節對齊的四字加載操作。
? 跨越32字節邊界的存儲操作。
在這些情況下,由于訪問跨越了特定的邊界,可能會導致帶寬降低或延遲增加。因此,在編寫軟件時應盡量避免這些情況,以保持高性能的訪問模式。
4.5 Store to Load Forwarding
Hunter-core允許從存儲指令將數據轉發到加載指令中,但有以下限制:
? 加載的起始地址應與較舊的存儲的起始地址或中間地址對齊。
? 大于8字節的加載可以從最多2個存儲中獲取數據。如果有兩個存儲,則每個存儲只能轉發到加載的第一半或第二半。
? 小于或等于4字節的加載只能從1個存儲中獲取數據。
這些限制規定了Hunter-core體系結構中數據轉發的最佳實踐。它們確保轉發僅限于特定的對齊和大小條件。通過遵守這些限制,軟件開發人員可以最大程度地發揮Hunter-core體系結構中的數據轉發功能的優勢。
4.6 AES encryption/decryption
Cortex-A715核心每個周期可以發出兩個AESE/AESMC/AESD/AESIMC指令(完全流水線化),執行延遲為兩個周期。這意味著為了最大性能,加密或解密至少應該交錯進行四個數據塊的操作。
通過將加密或解密操作交錯進行,可以充分利用Cortex-A715核心的流水線特性。這樣可以保證在每個周期中同時處理多個數據塊,從而提高加密或解密的整體吞吐量和效率。
AESE data0, key_reg
AESMC data0, data0
AESE data1, key_reg
AESMC data1, data1
AESE data2, key_reg
AESMC data2, data2
AESE data3, key_reg
AESMC data3, data3
AESE data0, key_reg
AESMC data0, data0
...
在程序代碼中,當依賴的AESE/AESMC和AESD/AESIMC指令成對出現,并且兩個指令都使用相同的目標寄存器時,它們具有更高的性能。
4.7 Region based fast forwarding
在V流水線中,轉發邏輯經過優化,以提供常常需要相互轉發的指令的最佳延遲。這些優化根據下表進行定義。

請注意以下關于表格中優化的轉發區域的特殊說明:
1. ASIMD/SVE提取窄、飽和指令不包含在這個區域內。
2. ASIM/SVE整數乘累加(INT multiply accumulate)只能快速轉發到累加源。
以下指令不屬于任何區域:
- FP/ASIMD/SVE轉換和舍入指令不會寫入通用寄存器。
- ASIMD/SVE整數歸約(integer reduction)指令。
除了上表中提到的區域之外,INT1和FP1區域中的所有指令都可以快速轉發到FP/ASIMD/SVE存儲以及FP/ASIMD向整數寄存器傳輸,ASIMD寫入通用寄存器的轉換指令和第3.19部分中的PERM指令(參見注釋2)。
關于表格4-1中優化的INT轉發區域的更多特殊說明:
- 在INT1區域中,復雜移位(immediate/register)和位移累加指令不能作為生產者(參見3.16和3.25節)。
- 在INT1區域中,提取窄、飽和指令不能作為生產者(參見3.19和3.25節)。
- 在INT1區域中,絕對值差累加和成對相加累加指令不能作為生產者(參見3.16和3.25節)。
關于表格4-2中優化的FP轉發區域的更多特殊說明:
- ASIMD/SVE浮點乘法和乘累加操作中的元素源(非向量操作數)不能作為消費者。
- 對于浮點生產者-消費者對,指令的精度應該匹配(單精度、雙精度或半精度)在FP1區域中。
- 在FP1區域中,成對浮點指令不能作為生產者或消費者。
不建議交錯使用屬于不同區域的指令。此外,某些指令在特定區域只能作為生產者或消費者,而不能同時兼具兩者身份(請參閱表4-1中針對優化的INT轉發區域和表4-2中針對優化的FP轉發區域的注釋)。例如,下面的代碼交錯了來自INT1和INT2區域的生產者和消費者。這將導致MUL指令面臨額外的1個周期的延遲。
INS v27[1], v20[1]- INT1區域的生產者,但不是INT2區域的消費者
MUL v26, v27, v6 – INT2區域
在表4-1中描述的優化的INT轉發區域和表4-2中的優化的FP轉發區域形成了兩個集群:FP集群和INT集群。集群間通信需要1個額外周期的懲罰。例如,下面的代碼:
FADD v20.2s, v28.2s, v20.2s – FP1區域
ADD v27, v20, v20- INT1區域的生產者,但不是FP1區域的消費者
4.8 Branch instruction alignment
分支指令和分支目標指令的對齊和密度會影響性能。為了獲得最佳性能,應將已經發生的分支放置在對齊的32字節指令內存區域的末尾,并且最好將分支目標指向對齊的32字節指令的開頭。
Cortex-A715核心的預測機制被優化為處理不包含分支的對齊32字節指令區域。為了獲得最佳性能和功耗效率,請避免將分支散布在對齊的指令區域中。
最好是有一個對齊的32字節指令區域包含兩個分支,而不是兩個32字節區域分別包含一個分支。
為避免分支預測限制,請避免將分支放置在4MB對齊的代碼指令區域的最后一條指令位置。
4.9 FPCR self-synchronization
程序員和編譯器編寫者應注意,對FPCR寄存器的寫入是自同步的,即可以依賴其對后續指令的影響,而無需進行干預的上下文同步操作。
4.10 Special register access
Cortex-A715核心對通用寄存器進行了寄存器重命名,以實現亂序和預測執行的指令。但大多數特殊寄存器不會被重命名。讀取或寫入非重命名寄存器的指令將受到以下一個或多個額外的執行約束:
非預測執行 - 指令只能以非預測方式執行。 順序執行 - 指令必須按照與其他相似指令或在某些情況下所有指令相關的順序執行。 刷新副作用 - 指令在執行后觸發刷新副作用,用于同步。
下表總結了各種特殊寄存器讀訪問及其相關的執行約束或副作用。

注意:
1. NZCV和SP寄存器是完全重命名的。
2. FPSR/FPSCR讀取必須等待所有可能更新狀態標志的先前指令執行和完成。
下表總結了各種特殊寄存器寫訪問及其相關的執行約束或副作用。

?
注意:
1. NZCV和SP寄存器是完全重命名的。
2. 如果預測到FPCR寫入將更改控制字段的值,則會引入一個屏障,阻止后續指令的執行。如果預測到FPCR寫入不會更改控制字段的值,則會在沒有屏障的情況下執行,但如果值發生變化則觸發刷新。
3. 如果尚未完成另一個FPSR寫入,則FPSR寫入必須在調度處停頓。
4.11 Instruction fusion
Cortex-A715核心可以通過一種稱為融合的操作來加速特定的指令對。可以進行融合的特定指令對如下所示:
AESE + AESMC(參見AES加密/解密的第4.6節)
AESD + AESIMC(參見AES加密/解密的第4.6節)
CMP/CMN(立即數)+ B.cond
CMP/CMN(寄存器Rn != ZR)+ B.cond
TST(立即數)+ B.cond
TST(寄存器)+ B.cond
BICS ZR(寄存器)+ B.cond
CMP(立即數)+ CSEL
CMP(寄存器)+ CSEL
CMP(立即數)+ CSET
CMP(寄存器)+ CSET
BTI + Integer DP/BR/BLR/RET/B uncond/CBZ/TBZ
SHL + SRI(標量或向量)
FCMP + AXFLAG
MOVPRFX + 支持的SVE指令
這些指令對必須在程序代碼中相鄰。對于CMP、CMN和TST,融合適用于移位和/或擴展的寄存器形式。對于CMP、CMN、TST和BICS,對于支持融合的指令對的兩個指令,存在有關立即數的限制。其他特定限制適用于指令融合。
4.12 Zero Latency Instructions
一些寄存器到寄存器的移動操作、立即數移動操作和謂詞操作可以在零延遲下執行。這些指令不使用調度和執行資源。具體指令如下:
MOV Xd, #{12{1'b0},imm[3:0]}
MOV Xd, XZR
MOV Wd, #{12{1'b0},imm[3:0]}
MOV Wd, WZR
MOV Hd, WZR
MOV Hd, XZR
MOV Sd, WZR
MOV Dd, XZR
MOVI Dd, #0
MOVI Vd.2D, #0
MOV Wd, Wn
MOV Xd, Xn
FMOV Sd, Sn
FMOV Dd, Dn
MOV Vd, Vn(向量)
MOV Zd.D, Zn.D
PTRUE
PFALSE
SETFFR
然而,MOV Wd, Wn、MOV Xd, Xn、FMOV Sd, Sn、FMOV Dd, Dn、MOV Vd, Vn(向量)、MOV Zd.D, Zn.D等指令在某些條件下可能無法以零延遲執行。
4.13 Cache maintenance operation? ? //緩存維護操作
在使用L1緩存的set方式無效化操作時,推薦以內部循環遍歷set,在外部循環遍歷way來編寫軟件。
4.14 Memory Tagging - Tagging Performance? ? //內存標簽
為了實現僅標簽的最大吞吐量,建議按照以下步驟進行操作:
1. 展開循環以在每次迭代中包含多個存儲操作,從而最小化循環的開銷。
2. 使用如下示例所示的STGM(或DCGVA)指令。
Loop_start:
SUBS x2,x2,#0x80
STGM x1,[x0]
ADD x0,x0,#0x40
STGM x1,[x0]
ADD x0,x0,#0x40
B.GT Loop_start
為了實現標簽操作和數據清零的最大吞吐量,建議按照以下步驟進行操作:
1. 展開循環以在每次迭代中包含多個存儲操作,從而最小化循環的開銷。
2. 使用如下示例所示的STZGM(或DCZGVA)指令。這些指令用于同時執行標簽操作和數據清零操作,可以提高效率。
Loop_start:
SUBS x2,x2,#0x80
STZGM x1,[x0]
ADD x0,x0,#0x40
STZGM x1,[x0]
ADD x0,x0,#0x40
B.GT Loop_start
為了實現標簽加載的最大吞吐量,建議按照以下步驟進行操作:
1. 展開循環以在每次迭代中包含多個加載操作,從而最小化循環的開銷。
2. 使用LDGM指令,如下面的示例所示。LDGM指令用于執行標簽加載操作,可以提高效率。
Loop_start:
SUBS x2,x2,#0x80
LDGM x1,[x0]
ADD x0,x0,#0x40
LDGM x1,[x0]
ADD x0,x0,#0x40
B.GT Loop_start
此外,如果不關心數據內容,建議使用STZGM(或DCZGVA)來設置標簽。
4.15 Memory Tagging - Synchronous Mode
在同步標簽檢查模式下,每個存儲操作在執行之前必須完成標簽檢查。因此,在同步標簽檢查模式下,存儲操作的性能會降低。
為了獲得更好的性能,建議使用異步模式。
4.16 Complex ASIMD and SVE instructions
以下是一些ASIMD和SVE指令的帶寬受到解碼限制,當需要高性能代碼時,建議避免使用它們:
ASIMD:
- LD4R,后索引尋址,元素大小為64位。
- LD4,單個4元素結構,后索引尋址模式,元素大小為64位。
- LD4,多個4元素結構,四重形式,元素大小小于64位。
- LD4,多個4元素結構,四重形式,元素大小小于64位,后索引尋址模式。
- ST4,多個4元素結構,四重形式,元素大小小于64位。
- ST4,多個4元素結構,四重形式,元素大小為64位,后索引尋址模式。
SVE:
- LD1H gather(標量 + 矢量尋址),其中矢量索引寄存器與目標寄存器相同,元素大小為32位。尋址模式為32位縮放或非縮放偏移。
- LD3[B/H] contiguous(標量 + 標量尋址)。
- LD4[B/H/W] contiguous(標量 + 立即數尋址)。
- LD4[B/H/W] contiguous(標量 + 標量尋址)。
- LDFF1H gather(標量 + 矢量尋址),其中矢量索引寄存器與目標寄存器相同,元素大小為32位。尋址模式為32位縮放或非縮放偏移。
- ST3[B/H/W/D] contiguous(標量 + 標量尋址)。
- ST4[B/H/D/W] contiguous(標量 + 標量尋址)。
以上指令在執行時受到解碼限制,可能導致帶寬受限,從而影響性能。因此,在對性能要求較高的代碼中,建議避免使用這些指令,選擇其他更適合的指令或優化方法來提高性能。
4.17 MOVPRFX fusion
MOVPRFX是一種指令融合技術,用于將一些特定的MOV和PRFX(Prefix Extend)指令在執行過程中進行融合,以提高執行效率和性能。
在特定條件下,一種名為MOVPRFX融合的機制可以用于加速執行由SVE MOVPRFX指令緊隨其后的SVE整數、浮點或BF16指令組成的指令對。下面的表格中列出了適用于此融合的SVE指令列表和條件。
請注意,在這里我無法直接顯示表格內容,但您可以參考相關文檔、處理器手冊或軟件優化指南以獲取關于MOVPRFX融合的具體說明。這些文獻將詳細介紹適用于融合的指令以及融合機制的條件。建議查閱與您目標處理器架構相應的文檔或咨詢處理器制造商提供的編程資源,以了解適用于融合的具體指令和成功融合執行的特定條件。

?
?
?
)

)




完全解析)






)




