文章目錄
- Pre
- 1. 概述:性能優化提綱與使用場景
- 2. 準備階段
- 2.1 明確優化范圍與目標
- 2.2 環境與工具準備
- 3. 數據收集與指標確認
- 3.1 關鍵資源維度與指標項
- 3.2 監控體系搭建與初始采集
- 3.3 日志與追蹤配置
- 4. 問題定位思路
- 4.1 從整體到局部的分析流程
- 4.2 常見瓶頸維度檢查方法
- 4.3 猜想驗證與工具使用指南
- 5. 優化策略候選與權衡
- 5.1 業務/架構/硬件等多種途徑的評估
- 5.2 軟件層面優化分類
- 5.3 成本—效果—風險權衡原則
- 6. 詳細優化操作清單
- 6.1 CPU 優化檢查與方案
- 6.2 內存優化檢查與方案
- 6.3 I/O(磁盤/網絡)優化檢查與方案
- 6.4 應用/框架層面優化項
- 6.5 配置層面(JVM、容器、數據庫、緩存)
- 6.6 代碼層面(算法、并發、異步、緩存中間層、鎖與同步、重構)
- 6.7 架構層面(拆分、異步流水線、隊列/緩沖、微服務或模塊化調整)
- 6.8 外部依賴優化(第三方服務、RPC、數據庫、消息隊列等)
- 7. 驗證與回歸測試
- 7.1 壓測或真實流量驗證方案
- 7.2 指標對比與數據分析
- 7.3 回歸監控與風險預案
- 8. 持續改進與PDCA循環
- 8.1 記錄與文檔化優化過程
- 8.2 定期回顧與經驗沉淀
- 8.3 自動化監控與警報策略
- 9. 團隊協作
- 9.1 優化經驗分享與評審
- 9.2 性能優化方法論要點
- 10. 附錄:常用工具與示例命令清單
- 10.1 系統層工具
- 10.2 Java 生態工具
- 10.3 壓測工具
- 10.4 監控與追蹤配置

Pre
性能優化 - 理論篇:常見指標及切入點
性能優化 - 理論篇:性能優化的七類技術手段
性能優化 - 理論篇:CPU、內存、I/O診斷手段
性能優化 - 工具篇:常用的性能測試工具
性能優化 - 工具篇:基準測試 JMH
性能優化 - 案例篇:緩沖區
性能優化 - 案例篇:緩存
性能優化 - 案例篇:數據一致性
性能優化 - 案例篇:池化對象_Commons Pool 2.0通用對象池框架
性能優化 - 案例篇:大對象的優化
性能優化 - 案例篇:使用設計模式優化性能
性能優化 - 案例篇:并行計算
性能優化 - 案例篇:多線程鎖的優化
性能優化 - 案例篇:CAS、樂觀鎖、分布式鎖和無鎖
性能優化 - 案例篇: 詳解 BIO NIO AIO
性能優化 - 案例篇: 19 條常見的 Java 代碼優化法則
性能優化 - 案例篇:JVM垃圾回收器
性能優化 - 案例篇:JIT
性能優化 - 案例篇:11種優化接口性能的通用方案
性能優化 - 高級進階:JVM 常見優化參數
性能優化 - 高級進階: Spring Boot服務性能優化
1. 概述:性能優化提綱與使用場景
- 在面對復雜系統或新場景時,僅憑頭腦回憶往往難以全面覆蓋各項可能性。
- 一份結構化提綱可以在分析過程中逐項檢查,避免遺漏關鍵環節,也能幫助團隊保持一致思路。
- 適用于排查線上性能問題、制定優化計劃、團隊分享的思路
2. 準備階段
2.1 明確優化范圍與目標
- 識別具體性能痛點:是單接口響應慢、系統整體吞吐不足、資源利用不平衡,還是偶發問題?
- 確定優化指標:如響應時延(平均/95%/99%)、吞吐量(QPS)、資源利用率(CPU/內存/網絡/磁盤)、錯誤率、成本限制等。
- 設定可衡量的目標:例如將95%延遲從500ms降到200ms;或在相同硬件下提升吞吐20%;或降低資源成本。
- 評估業務優先級:優化收益是否足以投入;是否存在業務或硬件方案可替代。
2.2 環境與工具準備
- 確保測試環境或預生產環境與生產相似度足夠高,避免環境差異導致失真結果。
- 搭建/確認監控與日志體系,包括系統指標、JVM/應用指標、分布式追蹤、日志聚合。
- 準備性能剖析工具:如
async-profiler、arthas、jvisualvm/jmc、perf等;確保有權限與安全合規。 - 確保壓測工具安裝并熟悉基本用法;明確壓測腳本場景與數據準備方式。
- 團隊角色分工:誰負責監控配置、誰執行壓測、誰分析代碼、誰跟進驗證。
3. 數據收集與指標確認
3.1 關鍵資源維度與指標項
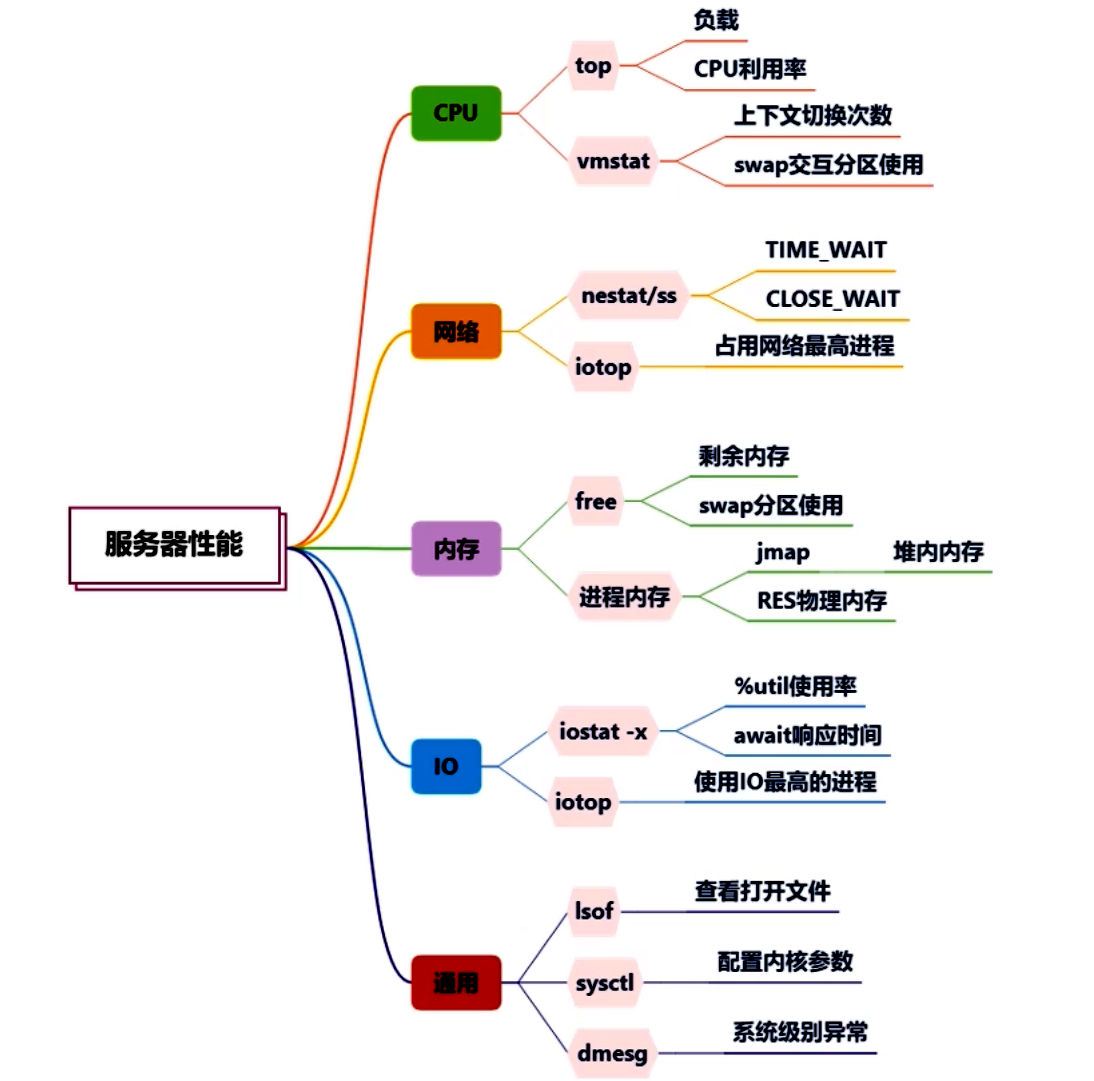
- CPU:
top命令 利用率、負載(load average)、上下文切換速率、線程饑餓或阻塞情況。 - 內存:
free命令 總內存與可用內存、JVM堆使用(Eden/Survivor/Old)、堆外內存、GC停頓時長與頻率、Swap使用情況。 - 磁盤I/O:IOPS、吞吐量、等待時間(await)、隊列長度、磁盤利用率;日志寫入量。 通過
iostat命令,可以查看磁盤 I/O 的使用情況,如果利用率過高,就需要從使用源頭找原因;類似 iftop,iotop 可以查看占用 I/O 最多的進程,很容易可以找到優化目標。 - 網絡I/O:吞吐量、延遲、連接數(TIME_WAIT/CLOSE_WAIT)、丟包或重傳情況。
iotop可以看到占用網絡流量最高的進程;通過netstat命令或者ss命令,能夠看到當前機器上的網絡連接匯總。在一些較底層的優化中,會涉及針對mtu的網絡優化。 - 通用:
lsof命令可以查看當前進程所關聯的所有資源;sysctl命令可以查看當前系統內核的配置參數;dmesg命令可以顯示系統級別的一些信息,比如被操作系統的 oom-killer 殺掉的進程就可以在這里找到。 - 應用層指標:請求速率、響應時延分布、錯誤率、業務關鍵指標(如緩存命中率、數據庫連接池使用率、隊列長度等)。
- 分布式追蹤指標:調用鏈各段耗時、遠程調用成功率、重試次數。
3.2 監控體系搭建與初始采集
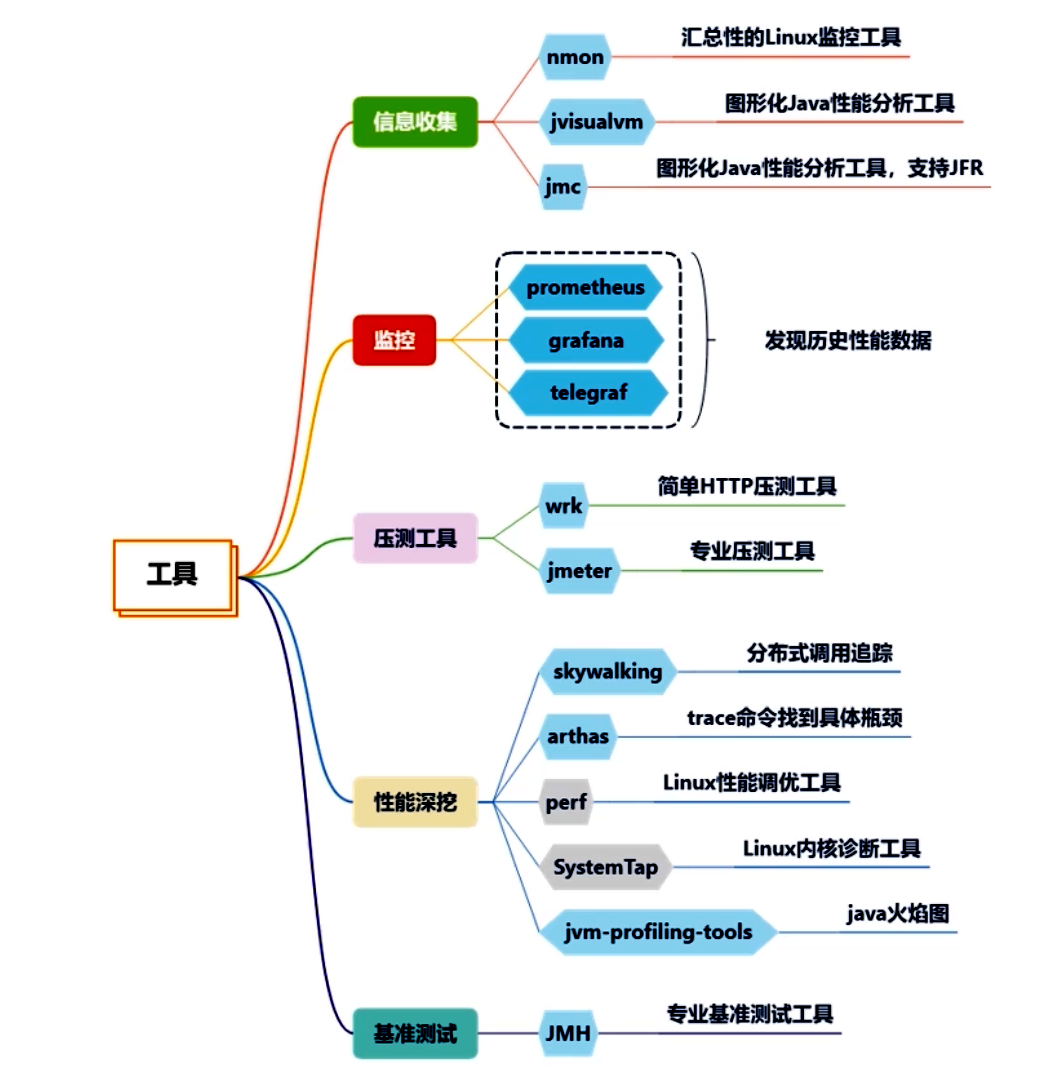
1.信息收集
nmon 是一個可以輸出系統整體性能數據的命令行工具,應用較為廣泛。
jvisualvm 和 jmc,都是用來獲取 Java 應用性能數據的工具。由于它們是 UI 工具,應用需要開啟 JMX 端口才能夠被遠程連接。
2.監控
- 利用 Prometheus + Grafana 或類似方案,配置抓取 SpringBoot/Microservices 的 actuator 或自定義指標;抓取系統層指標(node_exporter、telegraf 等)。
- 開啟 GC 日志(Java 8/Java 9+區別),并配合可視化工具分析;配置 HeapDumpOnOutOfMemoryError。
- 配置分布式追蹤 Agent(如 SkyWalking、Zipkin、Jaeger),獲取調用鏈數據。
- 初始運行一段時間,收集基線數據,記錄典型負載下的各項指標,形成對現狀的整體認知。
3.壓測工具
wrk 是一個命令行工具,可以對 HTTP 接口進行壓測;jmeter 是較為專業的壓測工具,可以生成壓測報告。壓測工具配合監控工具,可以正確評估系統當前的性能。
3.3 日志與追蹤配置
- 確保應用日志級別適當:生產環境避免過多 DEBUG 級別日志導致磁盤I/O壓力;發生問題時可臨時提升Level收集更多線索。
- 配置異常記錄與報警:如慢日志、錯誤日志集中告警。
- 在代碼熱點處添加必要的指標記錄(Histogram/Timer等),便于后續精細化分析。
- 對關鍵資源(緩存、連接池、線程池等)開啟 JMX 指標暴露并納入監控。
4. 問題定位思路
4.1 從整體到局部的分析流程
- 確認問題發生場景:是持續負載下的穩定偏差,還是偶發峰值下的異常?是某個時間段或特定操作觸發?
- 查看監控指標變化:對比基線,檢查資源利用率與業務指標的異常跳變。
- 大致方向判斷:CPU、內存、I/O、網絡或應用自身瓶頸;通過工具初步篩選。
- 細化分析:針對大方向使用剖析工具或更深層監控(如線程 dump、堆 dump、async-profiler/arthas 等),定位具體代碼或配置問題。
- 驗證猜想:提出可能原因并設計試驗(修改小配置、模擬負載場景、單元測試等),確認是否如預期改善或不產生不良影響。
- 記錄與迭代:對每次分析過程與結果進行記錄,若未解決則返到下一個猜想;若解決,進入優化實施階段。
4.2 常見瓶頸維度檢查方法
- CPU 瓶頸:持續高利用率或線程排隊饑餓;使用 top/htop、perf、async-profiler 查看熱點;注意并行流池饑餓、線程池配置不當。
- 內存瓶頸:頻繁GC或長停頓;OOM;堆外內存過高;Swap使用;使用 jmap、jcmd、GC日志分析對象分配與存活;注意本地緩存過大導致內存占用。
- 磁盤I/O瓶頸:高 I/O 等待;日志寫入過多;數據庫或存儲組件自身I/O壓力;使用 iostat、iotop 監控;調整日志級別或落盤策略;優化存儲配置或硬件。
- 網絡瓶頸:高延遲或丟包;頻繁小請求;跨機調用未壓縮;連接泄漏;使用 netstat/ss、tcpdump 分析;合并請求、啟用壓縮、優化連接復用。
- 應用邏輯瓶頸:慢查詢、深度循環、鎖競爭、同步等待、分布式事務阻塞;使用 async-profiler、arthas trace、數據庫慢日志分析、事務監控。
- 資源利用不均:某節點過載、緩存熱點、線程池飽和或空閑;觀察集群中各實例指標,進行負載均衡或擴縮容評估;調整緩存分布策略。
4.3 猜想驗證與工具使用指南
- 對每個可能原因,設計小規模試驗:修改配置、局部模擬負載、單元/集成測試驗證性能改善與風險。
- 使用 async-profiler 生成 flame 圖定位熱點;使用 arthas trace 方法調用;使用 jfr(Java Flight Recorder)收集運行期采樣。
- 利用監控面板在更改前后對比指標;使用 A/B 測試或灰度發布降低風險。
- 對分布式系統,可對單節點先優化再驗證集群效果,注意副作用如緩存一致性、限流等。
5. 優化策略候選與權衡
5.1 業務/架構/硬件等多種途徑的評估
- 業務層面調整:是否可以通過改變用戶輸入范圍、分頁設計或業務流程優化減少壓力?示例:限定查詢時間范圍、異步批量后臺處理。
- 架構層面調整:增加中間層(緩存、隊列、批處理)、拆分服務或功能、異步流水線、微服務拆分或合并、分布式計算方案。
- 硬件層面:短期可通過增配 CPU/內存/網絡帶寬/存儲提升性能;需結合成本與長期演進考慮。
- 軟件層面:JVM/Garbage Collector、框架配置(連接池、線程池)、代碼優化(算法、并發模型)、資源復用(對象池、連接池)、第三方庫替換或升級。
- 對比不同方案的工時與收益:記錄預估成本、實施難度、風險及收益,優先考慮低成本高收益方案。
5.2 軟件層面優化分類
- 配置優化:JVM 參數、容器參數(Tomcat/Undertow/Nginx)、數據庫連接池、緩存策略等。
- 代碼優化:熱點方法重構、算法改進、減少同步鎖競爭、并行/異步改造、緩存中間層設計、減少對象分配、優化序列化。
- 資源利用優化:合理利用 CPU 并行度、內存緩存、I/O 異步、線程池參數調整、連接復用。
- 架構調整:增設緩存層、消息隊列、批處理流水線、拆分或合并模塊、選型更輕量組件。
- 外部優化:使用 CDN、壓縮協議、近端緩存、網絡優化(MTU、QoS)、硬件升級或專用硬件加速。
5.3 成本—效果—風險權衡原則
- 對每項優化方案,評估實施成本(開發、測試、部署)、可能帶來的風險(兼容性、穩定性、維護復雜度)、預期收益(性能提升、用戶體驗改善、資源節省)。
- 優先實施小范圍、可回滾、易驗證的改動;對高風險大改動,先在測試環境或灰度環境充分驗證。
- 記錄決策過程與理由,便于未來復盤和團隊共享。
6. 詳細優化操作清單
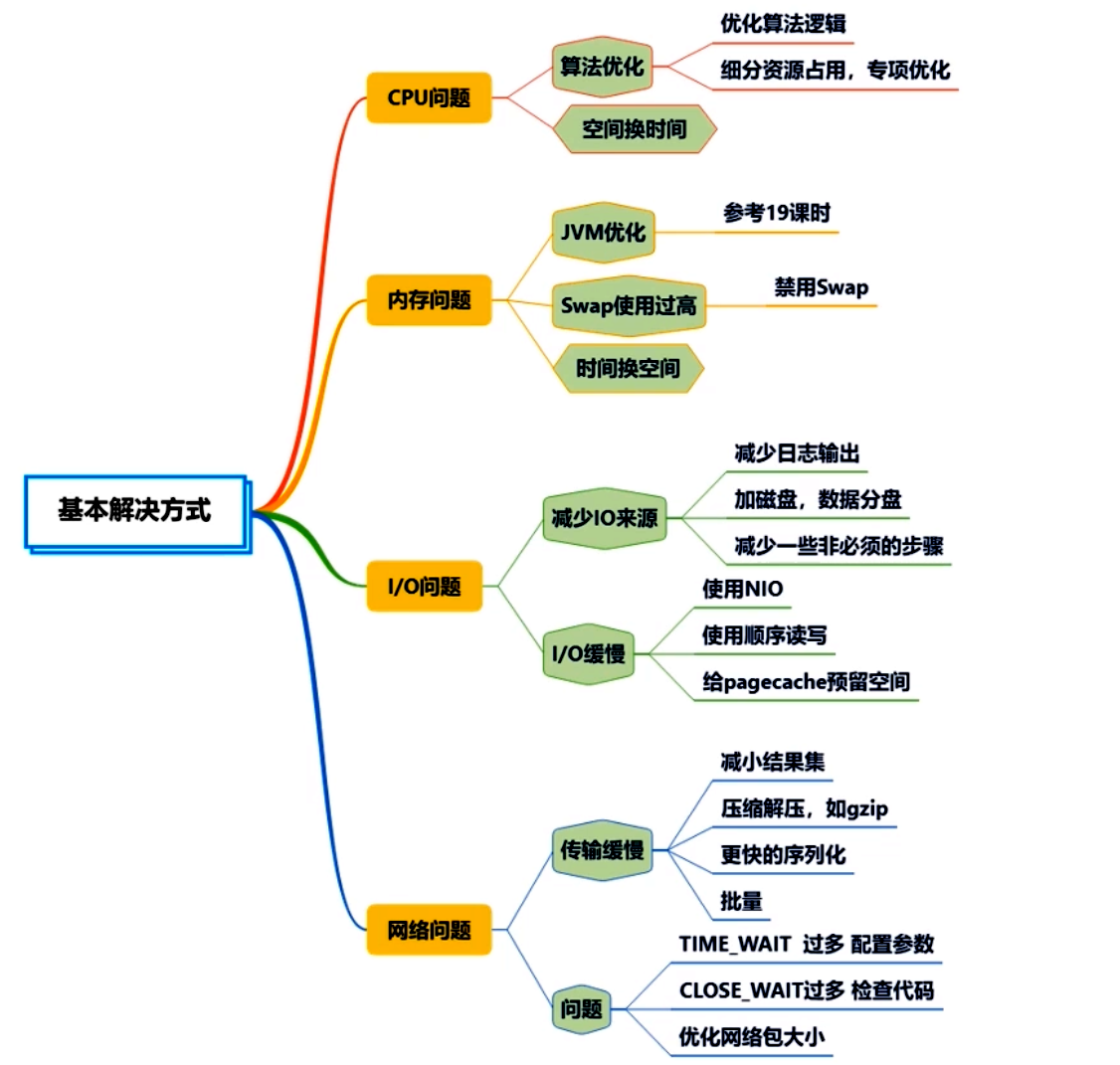
6.1 CPU 優化檢查與方案
-
檢查:持續高 CPU 利用、線程饑餓、鎖競爭、頻繁上下文切換。
-
方案:
- 剖析熱點:async-profiler、perf 分析方法調用熱點,針對性優化算法或減少不必要循環。
- 并發配置:檢查線程池并行度是否合理(如 ForkJoinPool 并行流默認線程數、自定義線程池)。
- I/O 等待避免阻塞:將阻塞I/O操作異步化或使用 NIO,避免占用 CPU 之外浪費線程。
- JIT與編譯:觀察是否存在方法過大導致編譯延遲,必要時調整 CodeCache 大小。
- 減少對象分配:緩存可重用對象,減少GC壓力從而降低GC CPU消耗。
- 方法內聯與編譯級別:通過 JVM 參數或代碼重構幫助JIT優化。
6.2 內存優化檢查與方案
-
檢查:頻繁GC或長停頓、Heap使用異常、堆外內存泄漏、Swap使用、OOM。
-
方案:
- 調整堆大小:基于監控與GC日志調整Xms/Xmx;避免過大或過小;考慮AlwaysPreTouch提升運行穩定性。
- 選擇合適GC器:根據場景(低延遲/大堆/高吞吐)選擇G1、ZGC等;調整GC參數(Pause目標、Region大小、并發標記閾值)。
- 優化本地緩存:Caffeine容量設置基于實際命中率;避免過度緩存導致內存緊張。
- 避免內存泄漏:定期使用工具(jmap+MAT、jmc)分析長生命周期對象;關注靜態集合、ThreadLocal、緩存引用等。
- 控制堆外內存:設置MaxDirectMemorySize;監控網絡緩沖、JNI調用等,避免隱性內存過高。
- 優化序列化:減少中間臨時對象,選擇高效序列化庫;分頁或流式處理大對象。
- 異常捕獲優化:避免過度捕獲導致堆棧信息生成過多占用內存或磁盤I/O。
6.3 I/O(磁盤/網絡)優化檢查與方案
-
磁盤I/O:
- 檢查日志寫入量與級別;調整日志策略或異步寫入。
- 存儲組件優化:數據庫/搜索引擎參數(緩沖區、批量寫、刷新頻率)、使用SSD或更優存儲。
- 本地文件操作:避免頻繁小文件讀寫;使用緩存或批量處理;異步I/O。
-
網絡I/O:
- 檢查請求大小與頻率、連接數、丟包或高延遲。
- 啟用壓縮(HTTP gzip/Brotli)、優化序列化;減少字段;分頁或批量請求。
- 連接復用:HTTP Keep-Alive、數據庫連接池、重用網絡連接;對RPC/Feign客戶端啟用壓縮與連接池優化。
- 網絡配置優化:MTU/TCP參數調整(如 TIME_WAIT 回收)、負載均衡設置、CDN加速。
- 減少跳轉與外部依賴等待:合理緩存遠程數據、本地降級、異步調用與超時設置。
6.4 應用/框架層面優化項
- Web容器:自定義Tomcat/Undertow線程池、協議(NIO2)、連接超時等;根據壓測結果調整MaxThreads/MaxConnections。
- SpringBoot配置:開啟HTTP compression、異步執行、WebFlux場景下資源利用;合理配置線程池Bean。
- 數據庫訪問:優化ORM查詢、批量操作、連接池配置(HikariCP);開啟數據庫端性能監控,避免慢查詢。
- 緩存中間層:本地與分布式緩存設計、CacheManager配置、緩存一致性策略。
- 消息隊列:異步處理、預fetch與消費者并發數調整、冪等與冪等補償邏輯。
- 序列化/反序列化:選擇高效庫、減少字段、使用流式處理。
- 第三方依賴:評估第三方庫性能、升級或替換低效組件;關注網絡調用超時與重試策略。
6.5 配置層面(JVM、容器、數據庫、緩存)
- JVM:堆內存、GC器及參數、Metaspace、CodeCache、DirectMemory、HeapDumpOnOOM、GC日志。
- 容器:Tomcat/Undertow/Nginx/LB 參數、Keep-Alive、超時、并發連接數、負載均衡算法。
- 數據庫:連接池大小、事務隔離級別、索引策略、緩存(如Query cache)、批量與預編譯、SQL優化。
- 緩存:容量、過期策略、分片策略、Eviction機制、持久化配置(如Redis持久化會帶來的I/O)。
- 網絡及系統參數:TCP/IP參數、文件描述符限制、線程數限制、中間件網絡配置。
6.6 代碼層面(算法、并發、異步、緩存中間層、鎖與同步、重構)
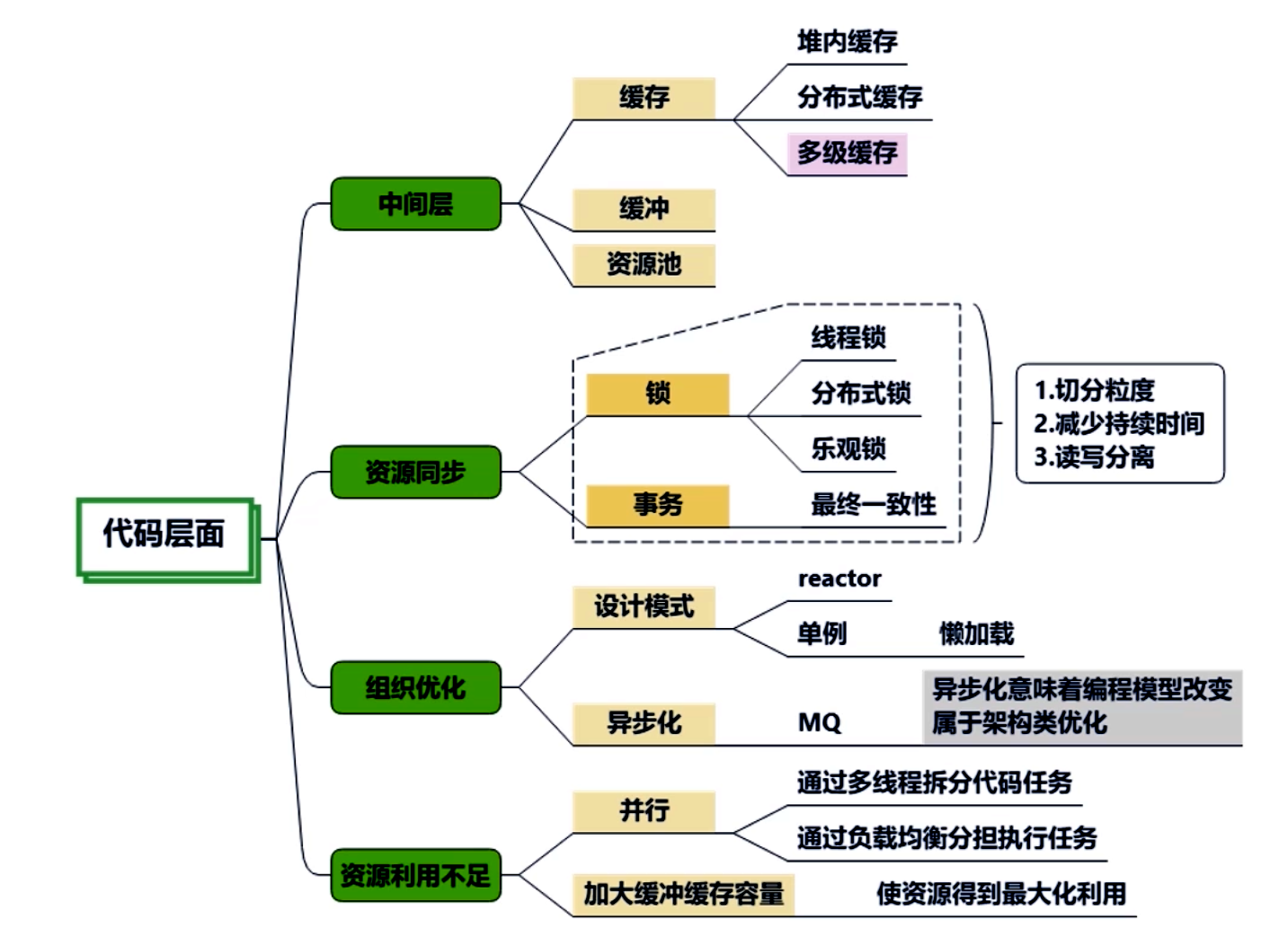
- 算法優化:關注算法復雜度;在大數據量場景選擇合適數據結構與算法;使用懶計算與惰性加載。
- 并發優化:避免不必要鎖;減小鎖粒度;使用無鎖或讀寫分離策略;合理配置線程池;避免共享資源競爭。
- 異步化:對于可異步的場景(I/O調用、后臺處理),使用CompletableFuture、消息隊列等;注意異常處理與上下文傳遞。
- 緩存中間層設計:在關鍵路徑添加緩存或批處理緩沖;避免重復調用下游;監控命中率并調整策略。
- 鎖與同步:避免長時間持有鎖;區分讀寫;使用樂觀鎖場景;對于分布式鎖,評估開銷與超時策略。
- 重構與組織:清晰模塊邊界,便于隔離性能熱點;采用設計模式提高可維護性;避免深層次依賴導致優化困難。
- 資源釋放:確保及時關閉連接、流、線程池任務等,避免資源泄漏導致長期累積問題。
- 代碼度量:在關鍵邏輯處埋點計時、統計調用次數;便于后續分析。
6.7 架構層面(拆分、異步流水線、隊列/緩沖、微服務或模塊化調整)
- 服務拆分與合并:根據性能瓶頸,將高耗資源模塊單獨部署;避免跨服務調用頻繁帶來的網絡延遲。
- 異步流水線與消息隊列:將長耗時任務異步化或拆分成多階段,用隊列解耦;注意冪等、失敗重試、消息積壓監控。
- 批量與緩沖:對突發高并發使用緩沖層平滑流量;批量處理提升吞吐;需關注延遲要求。
- 緩存服務/共享存儲:設計多級緩存架構;對于熱點數據,考慮本地緩存+分布式緩存組合;注意一致性與失效策略。
- 服務發現與負載均衡:合理配置負載均衡算法;避免單點過載;考慮健康檢查與動態調度。
- 容器化與彈性伸縮:在云/容器環境中利用自動伸縮;結合監控指標觸發擴容;注意冷啟動成本與容量預留。
6.8 外部依賴優化(第三方服務、RPC、數據庫、消息隊列等)
- 遠程調用:啟用壓縮、超時與重試策略、限流與熔斷;合并請求或緩存結果減少調用頻率。
- 數據庫:讀寫分離、只讀副本、分庫分表;索引與查詢優化;緩存熱點表/行;慢查詢監控與報警。
- 消息系統:合適的并發消費數、批量消費、Backpressure 處理、延遲隊列使用場景評估。
- 外部依賴監控:對第三方API響應時延和錯誤率監控,及時降級或切換備用方案。
7. 驗證與回歸測試
7.1 壓測或真實流量驗證方案
- 壓測前準備:確保環境、監控、采樣機制已就緒;準備代表性測試數據;設計腳本覆蓋典型和極端場景。
- 執行壓測:逐步增加負載,觀察系統各項指標;記錄關鍵拐點(如吞吐瓶頸出現時的資源利用情況)。
- 真實流量灰度:若可行,在灰度環境或少量流量下驗證改動;實時監控健康與性能指標。
- 對比分析:收集優化前后數據對比報告,包括響應時延、吞吐、資源使用、錯誤率等;繪制圖表幫助決策。
7.2 指標對比與數據分析
- 聚合指標:平均/分位響應時延、GC停頓統計、線程池隊列長度趨勢、連接池等待時間、CPU/內存/IO利用率曲線。
- 靶向分析:針對調整部分(如某接口方法、某配置項)單獨對比具體指標變化。
- 異常與副作用檢查:觀察是否引入新問題,如資源占用突增、錯誤率上升、延遲抖動增大。
- 記錄結論與建議:明確哪些改動可穩定采納,哪些需調整或回退;形成優化報告文檔。
7.3 回歸監控與風險預案
- 在生產環境部署后,開啟強化監控與報警;設定短期內更嚴格閾值,及時發現可能的問題。
- 準備快速回滾方案:若發現生產異常,可迅速恢復至優化前版本或配置。
- 定期回顧優化效果:觀察長期趨勢,評估優化是否持續有效,或是否出現新的瓶頸。
8. 持續改進與PDCA循環
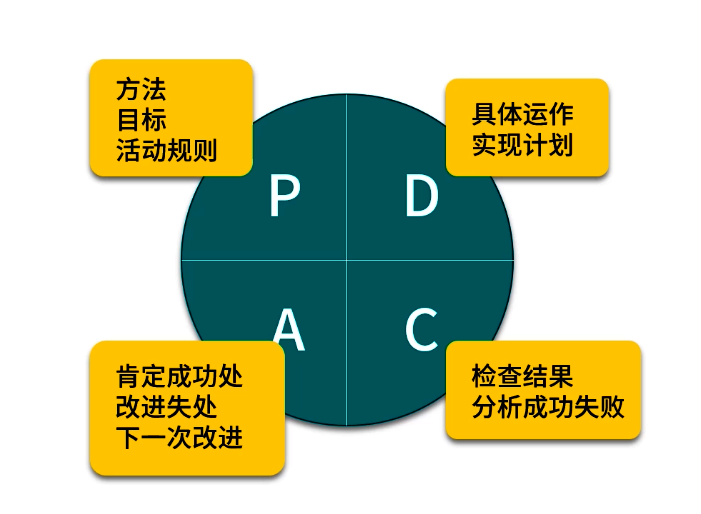
8.1 記錄與文檔化優化過程
- 為每次優化記錄:背景、現狀指標、猜想、驗證過程、實施方案、結果數據、風險與教訓。
- 形成團隊內部最佳實踐文檔,供新成員學習和復用。
- 思維導圖或流程圖形式歸納常見問題與對應解決思路,便于快速查閱。
8.2 定期回顧與經驗沉淀
- 定期組織性能評審會議,分享案例與教訓;討論新場景下可能的優化策略。
- 定期檢查系統健康與性能趨勢,提前發現潛在瓶頸。
- 在技術選型或版本升級時,將性能考慮納入決策過程。
8.3 自動化監控與警報策略
- 設定關鍵指標報警規則,避免問題演變為嚴重故障;包括延遲、錯誤率、資源利用異常等。
- 自動化測試:在CI/CD中引入簡易性能基準測試,檢測主要接口或關鍵模塊的性能回歸。
- 自動化報告:定期生成性能報告,便于管理層和團隊了解系統狀況。
9. 團隊協作
9.1 優化經驗分享與評審
- 定期內部分享會:講解某次優化案例的思路與實操過程;強調權衡與風險管理。
- 組織代碼走查,關注潛在性能隱患;在設計階段就考慮性能擴展性。
- 鼓勵團隊成員在遇到問題時先參考提綱,引導思考流程,而非直奔解決方案。
9.2 性能優化方法論要點
- 從問題發現到驗證方案、執行優化、回歸測試、監控反饋的完整流程。
- 使用工具與方法的能力:監控指標、剖析工具、壓測工具、分布式追蹤等。
- 清晰闡述不同優化方案的成本、風險與收益權衡。
10. 附錄:常用工具與示例命令清單
10.1 系統層工具
- top/htop:CPU、內存、進程狀態
- vmstat:系統運行統計(CPU、IO、內存)
- iostat:磁盤IO情況
- netstat/ss:網絡連接狀態
- lsof:進程打開文件/網絡資源
- perf:Linux性能剖析
- dmesg、sysctl:系統消息與內核參數
- iotop:磁盤I/O實時監控
- nmon:綜合系統性能監控導出
10.2 Java 生態工具
- jvisualvm/jconsole/jmc:JVM監控與分析
- jcmd/jmap/jstack/jstat:命令行JVM診斷
- async-profiler、async-profiler flame圖生成
- arthas:運行時在線診斷與trace
- Java Flight Recorder (JFR):采樣與事件分析
- GC 日志分析工具:GCViewer、GCEasy等
- Prometheus + Micrometer + Grafana:指標采集與可視化
- SkyWalking/Zipkin/Jaeger:分布式追蹤
- Spring Boot Actuator:應用內部指標與健康檢查
- HikariCP metrics、Caffeine stats:連接池與緩存監控
10.3 壓測工具
- wrk:輕量HTTP壓測
- JMeter:復雜場景壓測與報告生成
- Locust:Python腳本化壓測
- gatling:Scala DSL壓測
- siege、ab等簡單工具
10.4 監控與追蹤配置
- Spring Boot actuator prometheus endpoint 配置
- Nginx 配置(gzip、緩存頭、keep-alive、upstream)
- async-profiler 啟動與 attach
- SkyWalking agent 配置
- JVM 啟動參數(G1GC、Metaspace、DirectMemory、HeapDumpOnOOM、GC日志)






![100.Complex[]同時儲存實數和虛數兩組double的數組 C#例子](http://pic.xiahunao.cn/100.Complex[]同時儲存實數和虛數兩組double的數組 C#例子)



)


學習筆記)




)

)