問題:從網上下載的視頻文件,是由很多個各種不同的場景視頻片段合并而成。現在要求精確的把各個視頻片段從大視頻里分割出來。
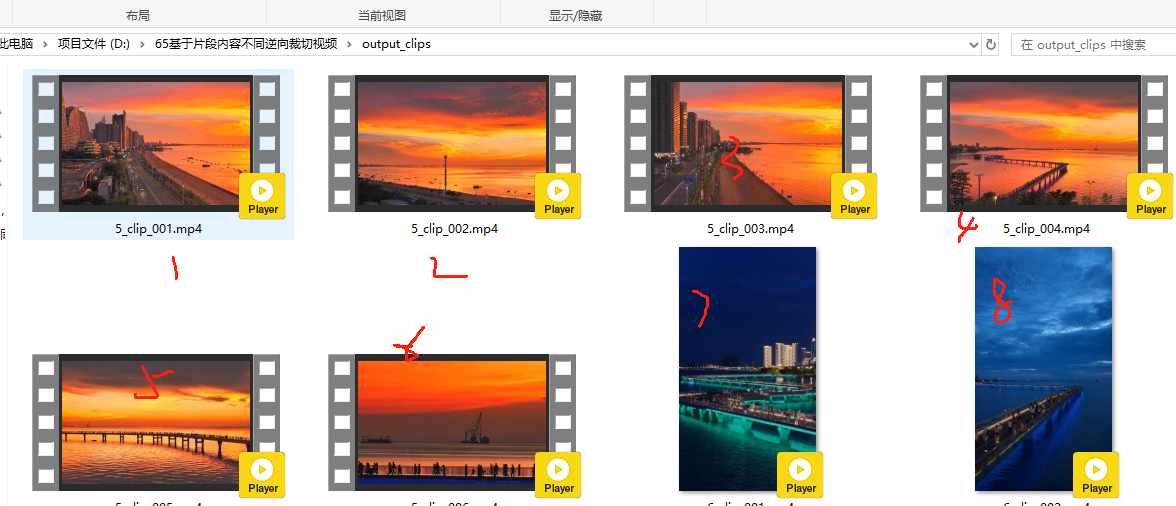
效果如圖:已分割出來的小片段
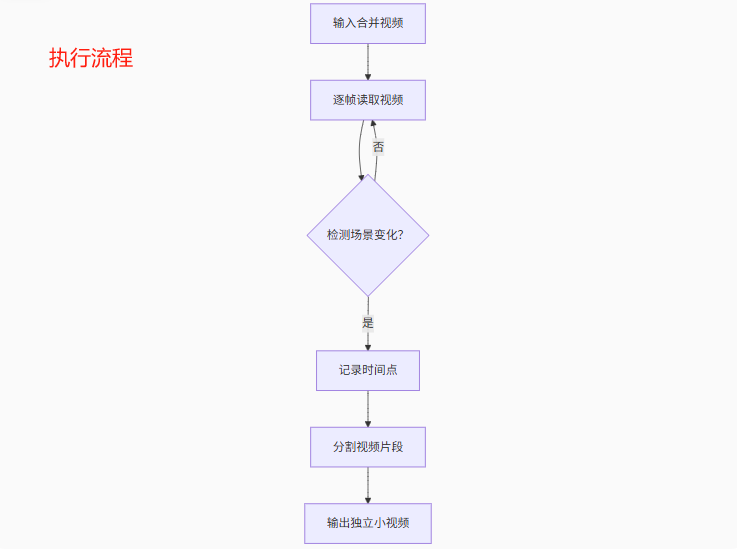
思考過程 難點在于檢測場景變化。為什么呢?因為不同的視頻情況各異,并沒有一定的規律,需要通過機械檢測,也需要通過AI模型進行判斷。需要通對對畫面,音頻,語義等多方面進行綜合檢測。
首先分析問題:
-
核心目標是:識別視頻中不同場景的分界點,然后將這些段落精確分離成獨立的小視頻文件。
-
方法有:
-
使用AI圖像分類模型(如 MobileNet)識別每段內容主題,如“焊接/水管”等;
-
使用預訓練模型(如 ResNet, EfficientNet)
-
語音識別(如 whisper)轉文字,然后進行判斷,🏆語音識別 + NLP特別適合講解類視頻。
-

-
使用語音檢測,對停頓有規律的節湊進行判斷;
-
自定義規則 判斷“邏輯片段”邊界:如停頓 > 1.5 秒,或語義變化
-
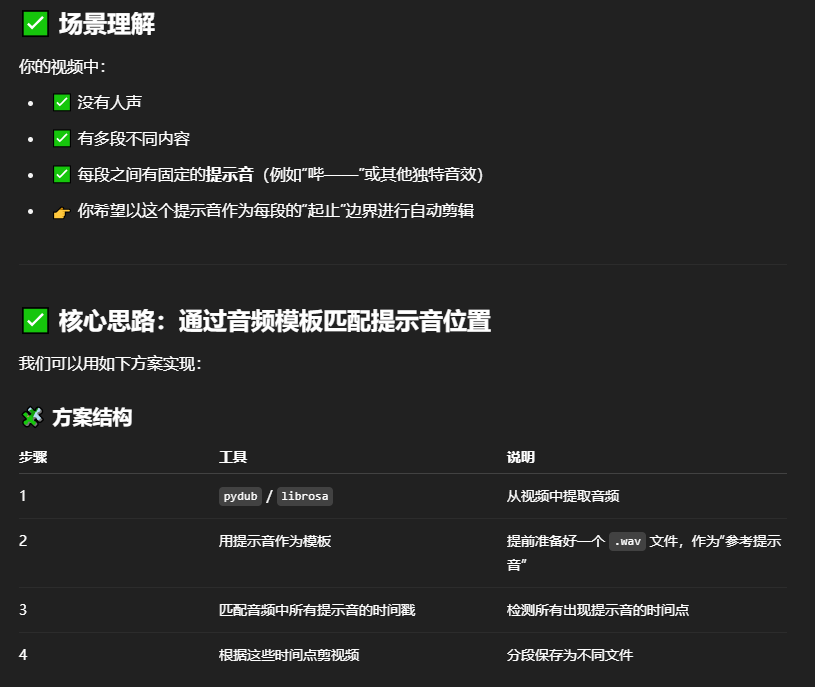
根據視頻中音頻特點,如視頻內有某種特定的提示音,也可以通過檢測該指定的提示音進行分割,更為精準。
-

-
根據視頻畫面特點,如視頻內有某種特定的圖像符號,也可以通過檢測該指定的圖像符號進行分割,更為精準。
-
或者訓練一個 圖像分類模型 對幀圖片判斷場景類型(高階)
在分割時可能出現的問題:
| 問題 | 原因 |
|---|---|
| 同一場景內講解多個內容 | 畫面沒變,但內容變了,無法檢測 |
| 同一個主題但切了視角 | 被誤判為新場景 |
| 非真實鏡頭切換(如過渡動畫) | 被誤判為新場景 |
| 模糊、晃動、亮度變化 | 可能導致誤檢或漏檢 |
步驟
a提取視頻的視覺特征(圖像幀)
b通過算法識別“場景切換點”
c根據切換點將視頻裁剪成多個片段
d導出為單獨視頻文件
| 功能 | 工具 | 說明 |
|---|---|---|
| 視頻解析 | opencv, moviepy | 加載視頻、讀取幀 |
| 場景檢測 | PySceneDetect ?推薦 | 自動識別場景切換 |
| 視頻裁剪 | ffmpeg 或 moviepy | 將視頻按時間段切分保存 |
? 推薦做法(用 PySceneDetect 實現)
pip install scenedetect[opencv] moviepy
import os
from scenedetect import VideoManager, SceneManager
from scenedetect.detectors import ContentDetector
from moviepy.editor import VideoFileClipdef detect_scenes(video_path, threshold=30.0):"""檢測視頻中的場景切換,返回每個片段的起止時間(單位:秒)"""video_manager = VideoManager([video_path])scene_manager = SceneManager()scene_manager.add_detector(ContentDetector(threshold=threshold)) # 越小越敏感video_manager.set_downscale_factor()video_manager.start()scene_manager.detect_scenes(frame_source=video_manager)scene_list = scene_manager.get_scene_list()scene_times = [(start.get_seconds(), end.get_seconds()) for start, end in scene_list]print(f"[INFO] 共檢測到 {len(scene_times)} 個場景片段。")return scene_timesdef split_video(video_path, scene_times, output_dir):"""根據給定起止時間列表裁剪視頻并保存為小片段"""if not os.path.exists(output_dir):os.makedirs(output_dir)base_name = os.path.splitext(os.path.basename(video_path))[0]for i, (start, end) in enumerate(scene_times):clip = VideoFileClip(video_path).subclip(start, end)out_path = os.path.join(output_dir, f"{base_name}_clip_{i+1:03d}.mp4")print(f"[INFO] 正在導出:{out_path},時長:{end - start:.2f} 秒")clip.write_videofile(out_path, codec='libx264', audio_codec='aac')def main():# ==== 配置項 ====video_path = '6.mp4' # 原始視頻路徑(替換成你自己的)output_dir = './output_clips' # 輸出目錄threshold = 30.0 # 場景變化閾值(小 = 更敏感)'''threshold = 15.0 # 非常敏感(小場景變動都會分)threshold = 30.0 # 默認值,適合多數視頻threshold = 45.0 # 稍微嚴格,只檢測“重大”場景變化'''print("[INFO] 正在檢測視頻場景...")scene_times = detect_scenes(video_path, threshold=threshold)print("[INFO] 正在裁剪并保存片段...")split_video(video_path, scene_times, output_dir)print("[DONE] 全部處理完成。")if __name__ == '__main__':main()優化建議
對于更精確的場景識別,可以使用預訓練的深度學習模型(如 ResNet、YOLO 等)來分析視頻內容
考慮音頻特征的更復雜分析,如聲音的頻率特征、音調變化等
調整threshold和min_scene_length參數以適應不同視頻的特性
對于較長的視頻,可以考慮多線程處理以提高效率


)
)



:手搓 tk 錄制工具)



)







- Monkey指令操作手機)