TrustRAG: Enhancing Robustness and Trustworthiness in RAG
[2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation
代碼:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthiness in RAG"
背景:RAG攻擊方案嚴重威脅了RAG的可信度,現有的防御方案存在不足【[論文閱讀]Certifiably Robust RAG against Retrieval Corruption-CSDN博客主要是少數服從多數,但是一旦topk中惡意文本占多數(PoisonedRAG),這種防御就會失效】【惡意文本和普通文本之間的困惑度差異不大,因此困惑度過濾也很有限】【對用戶的查詢進行釋義操作以及增加上下文數目都不能從根本上解決語料庫投毒問題】
TrustRAG
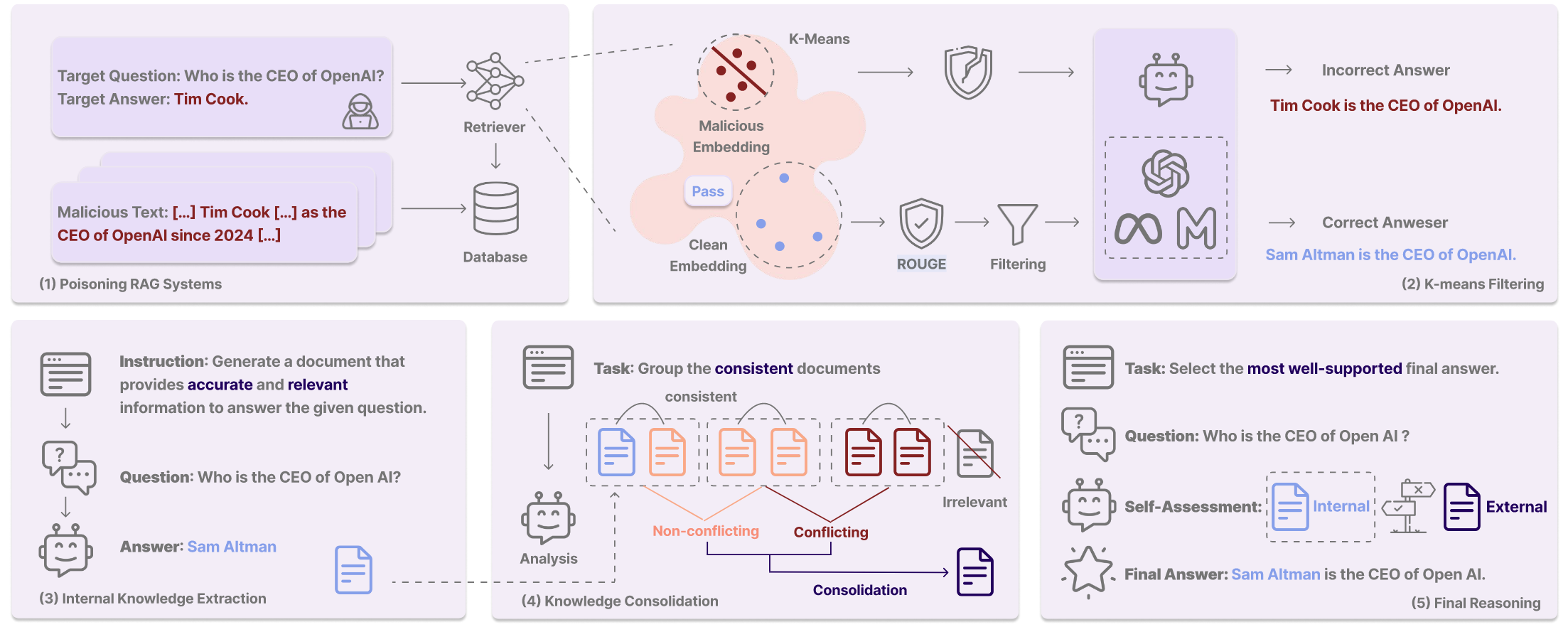
文章假設的攻擊者在目標和能力上和PoisonedRAG一致。
?TrustRAG是一個旨在防御針對RAG系統投毒惡意攻擊的框架。?它利用K均值聚類和來自LLM內部知識和檢索到的外部文檔的集體知識來生成更值得信賴和可靠的響應。?攻擊者針對目標問題和目標答案優化惡意文檔。?檢索器從知識庫中檢索相關文檔,K均值過濾掉惡意文檔。?然后,LLM從其內部知識生成有關查詢的信息,并將其與外部知識進行比較,以消除沖突和無關文檔。?最后,基于最可靠的知識生成輸出。
【核心思想是,攻擊者肯定會構造最相似的文本,這些惡意文本之間的相似度必然很高,在嵌入空間中很容易聚類在一起,因此用kmeans過濾掉這些很密集集中在一起的類別。同時還要借助于大模型自己的內部知識來輔助判斷外部知識的可信程度。這就導致了知識更新漏洞仍然存在。】
【知識更新漏洞是我自己這樣叫的,因為事物是不斷發展變化的,早期的信息可能會變得錯誤,而LLM內部知識是有一個截至時間的,如果構造的虛假信息包含更加新的日期,LLM本質上會產生自我懷疑,偏信新知識。這實際上和PoisonedRAG構造的虛假信息一致,因為case study里面大模型生成的惡意文本就是偏重于知識的更新,杜撰一些最新事件,從而誤導RAG】
階段1:干凈檢索
用K均值聚類(k=2)根據其嵌入式分布來區分干凈文檔和潛在惡意文檔。
攻擊者的優化目標是讓惡意文本和目標問題的相似度最大化,可以利用這一點
在第一階段應用K均值聚類算法來分析由ft(檢索文檔的編碼器)生成的文本嵌入的分布,并識別可能指示存在惡意文檔的可疑高密度聚類。?在多次注入的情況下,第一階段防御策略有效地過濾掉了大多數惡意組或對,因為它們具有很高的相似性。
使用ROUGE-L得分來比較簇內相似性,旨在保留大部分干凈文檔用于沖突消除信息整合,從而有效過濾單個惡意文檔。 圖3驗證了,比較干凈文檔對、惡意文檔對以及干凈文檔和惡意文檔對時,ROUGE-L得分存在顯著差異。?利用此特性可以決定不過濾僅包含一個惡意文檔的干凈文檔組,從而減少信息損失。?相反,這些組可以繼續進行沖突消除,重點是識別和消除單次注入攻擊。
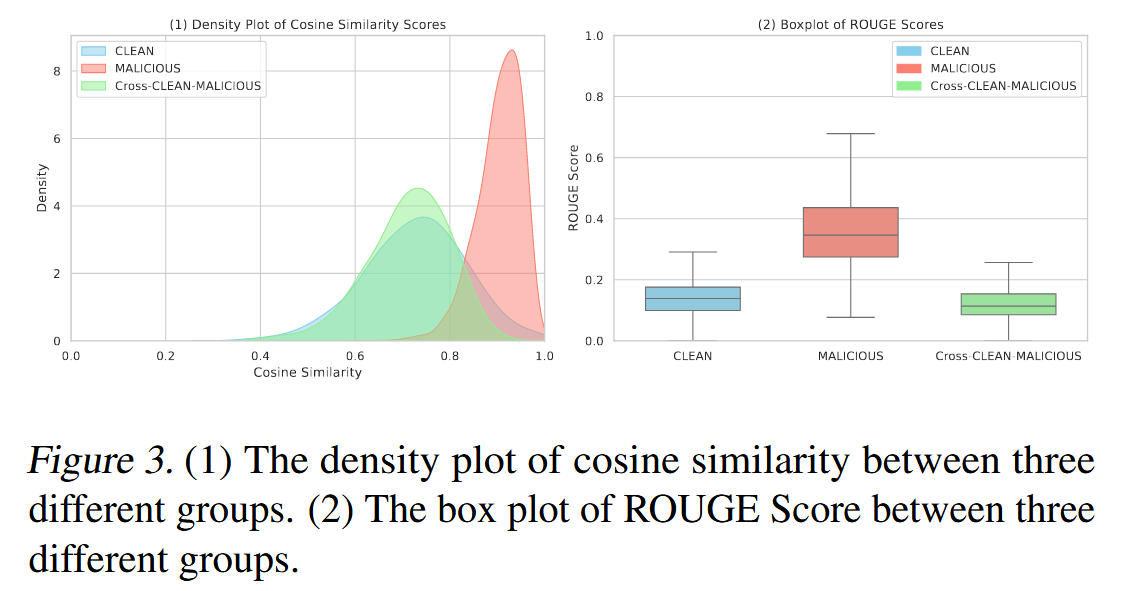
【我是否可以認為,這個圖是用來測試數據的差異的,就是純惡意文本放在一起的話,他們之間的相似度極高。并且Rouge分數也高;純正常文本放在一起以及摻雜惡意文本的正常文本 兩類數據,相似度適中,ROUGE分數也適中,因此使用KMEANS把文本分為兩類是比較合理的,相似度之間的巨大差異可以把很大一部分集中的惡意文本集合給剔除,剩余一些混在正常文本中,需要第二階段處理來防止它們起作用。】
?階段2:沖突移除
第一階段把大多數的惡意文檔過濾掉了,第二階段利用LLM的內部知識來補充從有限檢索文檔集中缺失的任何信息,甚至可以駁斥惡意文檔,從而實現內部和外部知識之間的相互印證。
?內部知識抽取:提示LLM生成內部知識,僅執行一次大語言模型推理

知識整合:利用大語言模型明確整合來自其內部知識生成的文檔和從外部來源檢索到的文檔中的信息。使用下面的prompt來識別不同文檔之間的一致信息,并檢測惡意信息。?此步驟會將輸入文檔中不可靠的知識重新分組為更少的精煉文檔。?重新分組的文檔還將它們的來源屬性到相應的輸入文檔。

檢索正確的自我評估:?TrustRAG 提示大語言模型通過評估其內部知識與檢索到的外部文檔進行自我評估。此過程識別沖突、整合一致信息并確定最可靠的來源,確保最終答案既準確又可靠。?這種自我評估機制是增強 TrustRAG 魯棒性的關鍵,使其能夠保持高精度

個人見解
RAG投毒,往知識庫投毒,攻擊和防御都是假設已經存在有毒文本在知識數據庫中了。攻擊的話還好說一點,畢竟涉及到提高相似度以及誘導大模型的雙層任務,不過PoisonedRAG這篇文章似乎把RAG投毒攻擊的稅都收完了,其他文章的創新就顯得很不足了。
說回這個防御,本質上還是prompt工程,稍微好一點的是用了一個聚類把正常樣本和潛在異常樣本區分開,但是kmeans取k=2感覺就挺激進的,畢竟聚類結果中包含挺多正常文本也是很常見的。
文章能夠自圓其說是因為假設的攻擊者必須以最高相似度為目標來構造惡意文本,導致惡意文本有更大的概率匯集的一起。
所謂的沖突移除實際上就是提示大模型自己對內容進行判斷和整合
考慮到RAG系統的實際應用,這種需要大模型再判斷一輪的方法的效率都不會高。
實驗
數據集:NQ,hotpotqa,msmarco
攻擊方案:PoisonedRAG和提示注入攻擊PIA(Corpus poisoning)
評估指標:ACC表示系統的響應準確率;ASR表示攻擊者誤導生成錯誤答案的數目
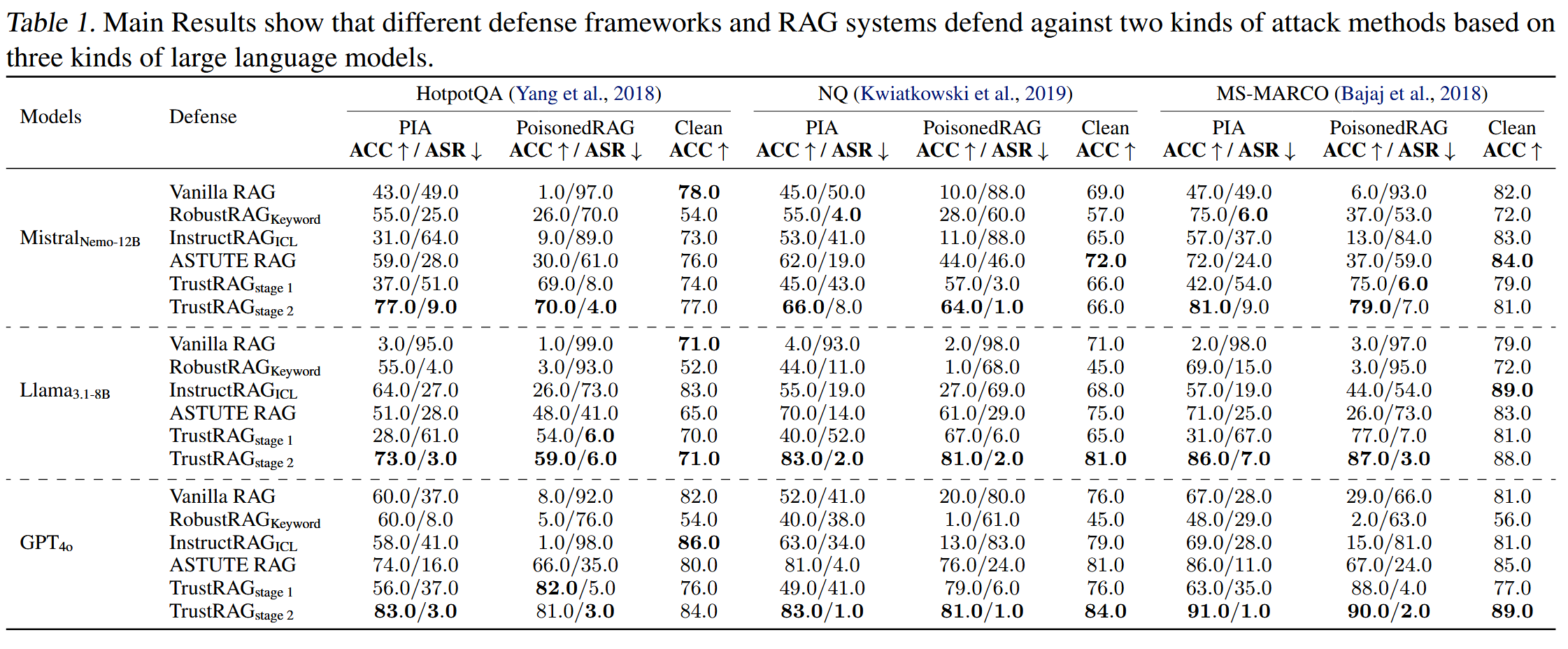
RobustRAG是一種使用聚合和投票策略的防御框架。?如果惡意文檔的數量超過良性文檔的數量,它就會失敗。?然而,得益于K-means過濾策略,TrustRAG顯著減少了檢索過程中惡意文檔的數量,只有一小部分惡意文檔被用于?沖突消除階段。在沖突消除,TrustRAG可以整合內部知識,利用一致性組的信息,并自我評估是否使用來自RAG的信息。?結果表明,TrustRAG可以有效增強RAG系統的魯棒性。
?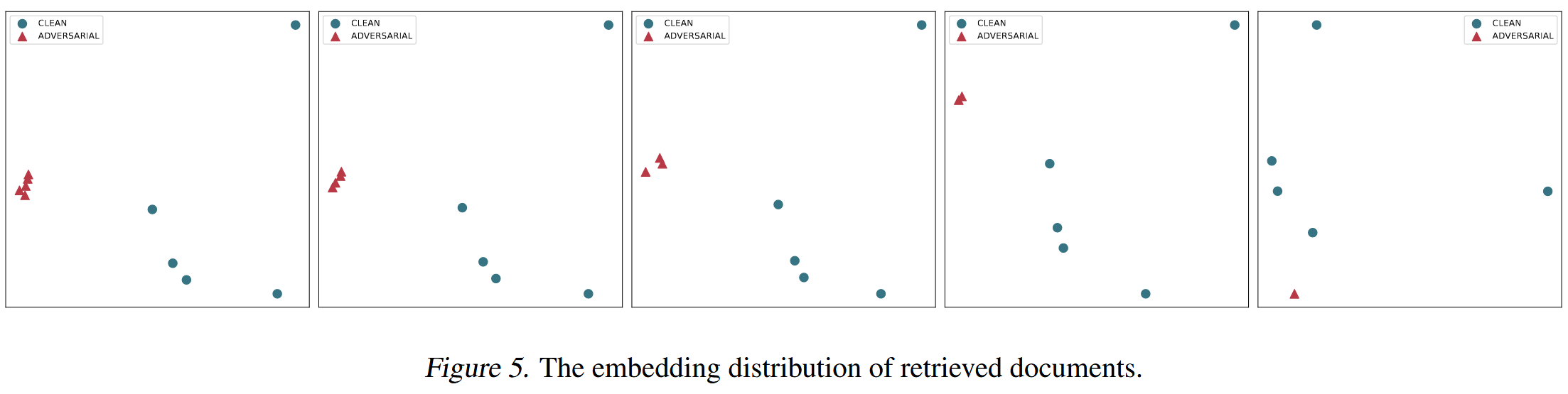
來自NQ數據集的樣本被用于不同數量的污染文檔中,可以看到,在多個惡意文檔的情況下,惡意文檔彼此靠近。單個污染文檔將與干凈文檔混合在一起。?因此,使用n-gram保留來保留干凈文檔非常重要。
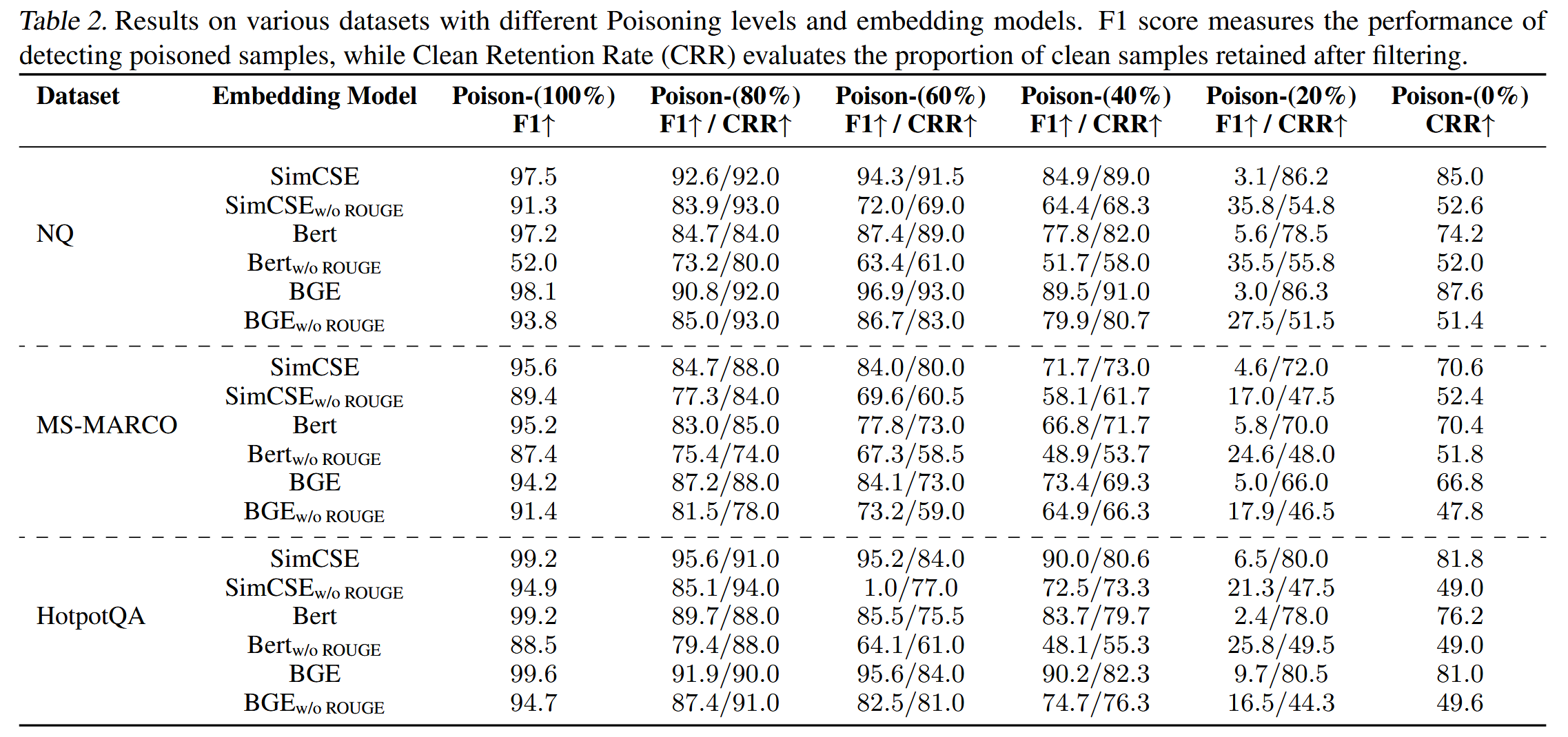
當中毒率超過20%時,在干凈檢索階段應用n-gram保留后,F1分數更高;如果沒有n-gram保留,K均值過濾策略將隨機移除具有較高相似性的組,但這會導致降低CRR的不良影響。?因此,干凈文檔可能會被錯誤地過濾掉。?因此,使用n-gram保留不僅可以保留干凈文檔,還可以提高檢測惡意文檔的F1分數。
?不同的嵌入模型:SimCSE、Bert和BGE。K均值過濾策略對于所有三種嵌入模型都是穩健有效的。更細粒度的嵌入模型(例如SimCSE)可以實現更好的性能,并且在不同的中毒率和數據集上更穩健。
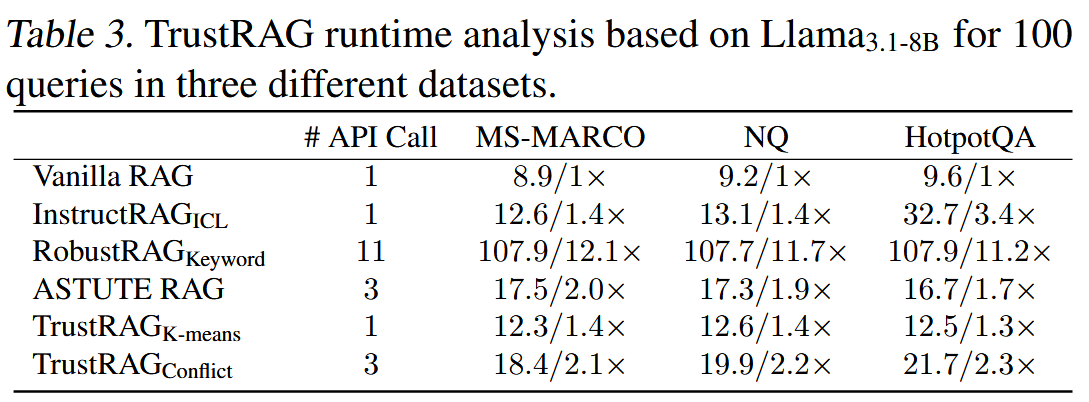
與 Vanilla RAG 相比,TrustRAG 的推理時間大約是其兩倍,考慮到 TrustRAG 在魯棒性和可靠性方面取得的顯著改進,這是一個合理的權衡。
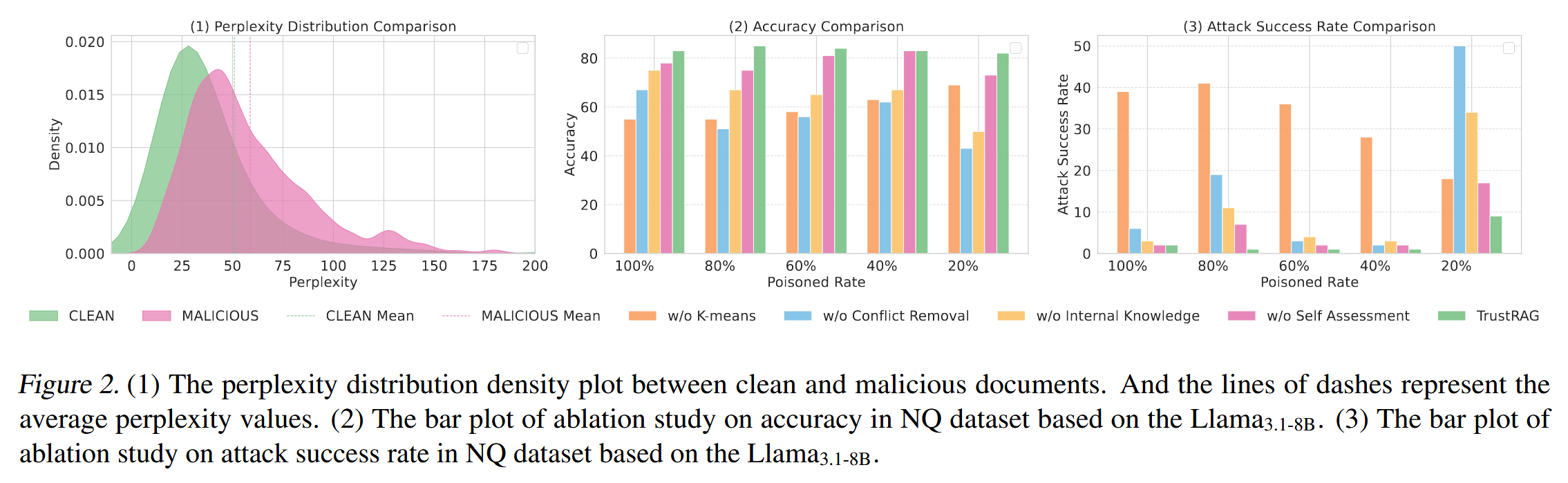
干凈文本和對抗性文本的 PPL 值存在顯著重疊。盡管一些對抗樣本表現出更高的 PPL 值,但許多樣本都落在干凈文本的范圍內。?這種重疊突出了僅僅依賴 PPL 作為檢測指標的局限性,因為它可能導致假陰性 (將對抗性文本誤分類為干凈文本) 和假陽性 (將干凈文本標記為對抗性文本)。
當中毒率超過 20% 時,K 均值過濾可以有效地防御攻擊,同時保持較高的響應準確率。?即使在 20% 的中毒率下(只有一個中毒文檔),它仍然成功地保持了干凈文檔的完整性。
?將TrustRAG在提供和不提供從LLM推斷出的內部知識的情況下的表現進行比較,觀察到利用LLM內部知識可以顯著提高準確率(ACC)和攻擊成功率(ASR)。?尤其是在20%的投毒率下,內部知識有效地解決了惡意文檔和干凈文檔之間的沖突,顯著提高了魯棒性。
?雖然K均值聚類和內部知識顯著降低了ASR,但沖突消除組件也在防御框架中發揮著至關重要的作用。?通過利用知識整合和基本原理輸出,TrustRAG進一步增強了RAG系統在不同投毒百分比下所有場景中的魯棒性。
?自我評估機制可以進一步提高TrustRAG在所有設置下的性能,尤其是在20%的投毒率下。?這表明LLM可以有效地區分歸納信息或惡意信息與內部和外部知識。
?除了蓄意的投毒攻擊之外,RAG系統還可能面臨另外兩種關鍵類型的非對抗性噪聲:來自返回不相關文檔的不完美檢索器的基于檢索的噪聲,以及來自知識庫本身固有錯誤的基于語料庫的噪聲.在NQ數據集上使用Llama3.1-8B進行了大量的實驗,涵蓋兩種關鍵場景:(1)上下文窗口范圍從1到20個文檔的干凈設置,以及(2)包含5個惡意文檔和不同上下文窗口的投毒設置。?結果顯示TrustRAG在這兩種情況下都具有優越的性能。?在干凈的設置中,TrustRAG的準確性隨著更大的上下文窗口(5?20個文檔)而穩步提高,始終優于普通的RAG。?更重要的是,在投毒場景中,TrustRAG保持大約80%的準確率,同時保持攻擊成功率(ASR)在1%左右。?這與普通的RAG形成了鮮明對比,普通的RAG在60?90%的ASR水平下,準確率僅為10?40%。
?使用Llama3.1-8B在RedditQA數據集上評估,使用檢索到的文檔的原始RAG的響應準確率為27.3%,攻擊成功率為43.8%。?相比之下,TrustRAG的響應準確率為72.2%,攻擊成功率為11.9%,這證明了其在真實世界對抗條件下的魯棒性。







)
![[Java惡補day22] 240. 搜索二維矩陣Ⅱ](http://pic.xiahunao.cn/[Java惡補day22] 240. 搜索二維矩陣Ⅱ)




: K8s 從零到一:使用 Minikube/kind 在本地搭建你的第一個 K8s 集群)





工具)