數據集成參考架構解析
引言
在當今數字化時代,數據已成為企業最寶貴的資產之一。隨著企業規模的不斷擴大和業務的日益復雜,數據來源也變得多樣化,包括客戶關系管理(CRM)、企業資源規劃(ERP)、人力資源管理(HR)和市場營銷等領域的運營系統。這些系統雖然在其特定功能領域表現出色,但將它們作為企業所有數據的中央存儲庫來滿足運營、高級分析和人工智能/機器學習(AI/ML)需求則具有挑戰性。因此,數據集成架構的設計與實施顯得尤為重要。
架構核心概念
Gartner 將數據集成定義為一種學科,涵蓋了架構模式、方法論和工具,使企業能夠跨多種數據源和數據類型實現數據的穩定訪問和交付,以滿足業務應用程序和最終用戶的數據消費需求。數據集成架構通過開發和監控數據管道,以系統化和一致的方式移動數據,從而提高數據的可用性和可理解性。
架構用例
數據集成在多個領域有著廣泛的應用場景。例如,SaaS 數據集成能夠將來自各種 SaaS 系統的數據整合在一起,創建更全面的分析;一致的報告和分析則確保所有系統使用相同的數據;主數據引用/同步將主數據分發或同步到中央位置,作為所有用戶的參考;在數據集成管道中標準化/收集元數據可以收集操作和業務元數據;商業智能則通過整合來自各種業務功能的數據,提供全面的洞察和報告。
架構圖解析
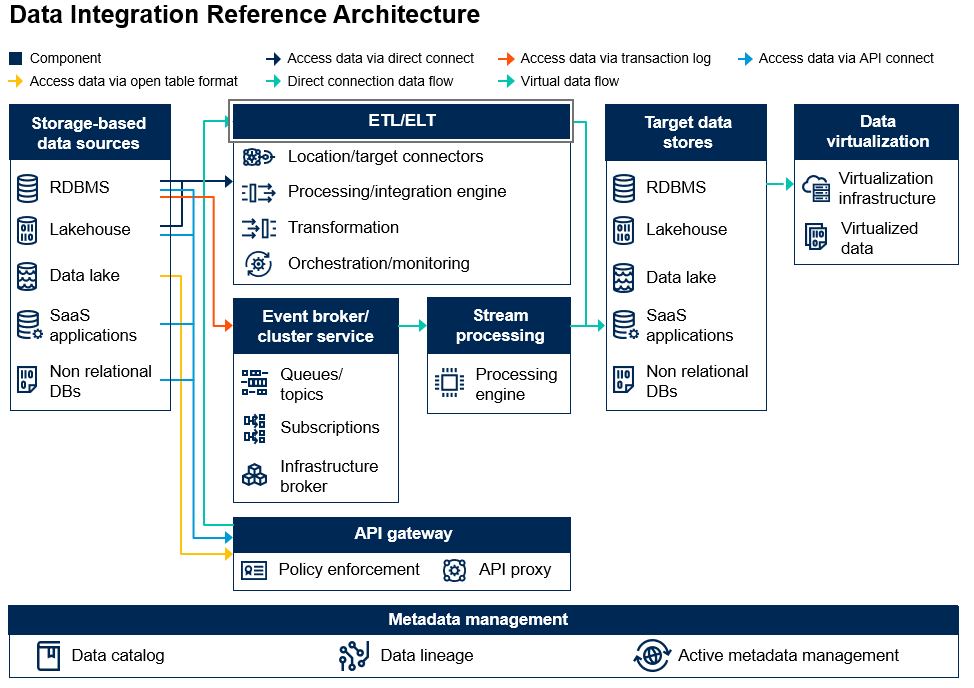
數據集成在核心功能層面涉及從源讀取數據,無論直接還是間接,然后執行轉換,再將其交付至目標系統。根據數據源、數據格式和業務用例,可以利用不同的方法和技術來集成和處理數據。如今的集成挑戰主要源于多樣化數據格式、動態商業模式和不斷增長的數據量。集成架構需要讀取和解析不同來源的數據,高效地組合和集成,然后將數據傳遞給下游進行消費或進一步處理。
架構能力與組件
數據集成架構包含八個組件:基于存儲的數據源、ETL(提取、轉換、加載)、ELT(提取、加載、轉換)、事件代理/集群服務、流處理、API 網關、目標數據存儲、數據可視化和元數據管理。
基于存儲的數據源
基于存儲的數據源是數據的生成器或需要集成的數據的位置。這些通常是某種類型的數據庫,如關系型或非關系型數據庫。它們以表格格式或不同結構組織數據。
存儲類型
-
關系數據庫/數據倉庫:如 Amazon Redshift、Google Cloud AlloyDB、Oracle、SQL Server 等。
-
非關系數據庫:如 Amazon DynamoDB、Apache Cassandra、MongoDB、Redis 等。
-
數據湖:如 Amazon S3、Azure Data Lake Storage、Google Cloud Storage、Snowflake Cloud Data Platform 等。
-
湖倉架構:如 Amazon Web Services(AWS)(多種服務組合)、Databricks、Microsoft Fabric Lakehouse 等。



)
![[Java惡補day22] 240. 搜索二維矩陣Ⅱ](http://pic.xiahunao.cn/[Java惡補day22] 240. 搜索二維矩陣Ⅱ)




: K8s 從零到一:使用 Minikube/kind 在本地搭建你的第一個 K8s 集群)





工具)



