【PGSR】: 基于平面的高斯濺射高保真表面重建
前言
三維表面重建是計算機視覺和計算機圖形學領域的核心問題之一。隨著Neural Radiance Fields (NeRF)和3D Gaussian Splatting (3DGS)技術的發展,從多視角RGB圖像重建高質量三維表面成為了研究熱點。今天我們要深入探討的PGSR(Planar-based Gaussian Splatting for Efficient and High-Fidelity Surface Reconstruction)正是在這一背景下誕生的創新性工作。
1. 論文背景與研究意義
1.1 研究背景
傳統的表面重建方法往往需要深度信息或法向量等幾何先驗知識,這在實際應用中帶來了諸多限制。近年來,3D Gaussian Splatting因其高效的渲染能力而備受關注,但原始的3DGS在表面重建質量方面仍有改進空間,特別是在處理復雜幾何結構和細節保持方面。
1.2 研究意義
PGSR的研究意義體現在以下幾個方面:
技術創新性:首次將平面約束引入高斯濺射框架,無需任何幾何先驗(如預訓練模型提供的深度或法向量信息),僅從多視角RGB圖像就能實現高保真表面重建。
實用價值:相比傳統方法,PGSR在保持高質量重建效果的同時顯著提升了計算效率,為實際應用提供了更好的解決方案。
學術貢獻:為三維重建領域提供了新的思路,將平面幾何約束與神經渲染技術有機結合。
2. 核心問題與解決方案
2.1 解決的關鍵問題
PGSR主要解決了以下三個核心問題:
第一,如何在沒有幾何先驗的情況下從多視角RGB圖像重建高質量表面。傳統方法依賴深度圖或法向量等額外信息,限制了應用場景。
第二,如何平衡重建質量與計算效率。現有方法要么重建質量不夠高,要么計算成本過于昂貴。
第三,如何處理復雜幾何結構和保持表面細節。傳統高斯濺射在處理銳利邊緣和精細結構時容易出現模糊或失真。
2.2 技術方法
PGSR的核心創新在于引入平面約束的高斯濺射表示。具體方法包括:
平面化高斯表示:將傳統的3D高斯橢球約束到平面上,使其更適合表面重建任務。通過這種方式,每個高斯基元不再是任意方向的橢球,而是被約束在特定平面內。
自適應密化策略:基于梯度和幾何誤差的雙重標準進行高斯點的分裂和克隆,確保在重要區域有足夠的采樣密度。
多尺度優化:采用分層優化策略,從粗到細逐步優化表面幾何,既保證了全局一致性又保持了局部細節。
3. 實驗效果與性能分析
3.1 定量評估結果
在DTU數據集上的測試結果顯示,PGSR取得了令人印象深刻的性能:
Chamfer Distance:在DTU數據集的15個場景中,平均Chamfer Distance降至0.47,相比原論文的0.53有了顯著改進。特別是在scene 24、40、55等場景中表現尤為出色。
訓練效率:相比原論文的0.6小時,優化后的代碼版本將訓練時間縮短至0.5小時,效率提升約17%。
在Tanks and Temples數據集上的F1 Score也保持了競爭力,平均F1分數達到0.51,訓練時間從1.2小時縮短至45分鐘,效率提升顯著。
3.2 視覺質量分析
從視覺質量角度看,PGSR在以下方面表現優異:
表面連續性:重建的表面具有良好的連續性,避免了傳統方法常見的空洞和斷裂問題。
細節保持:能夠很好地保持原始幾何的精細結構,如建筑物的棱角、雕像的紋理等。
紋理一致性:重建表面的紋理與原始圖像保持高度一致,色彩過渡自然。
4. 技術創新點深度解析
4.1 平面約束機制
PGSR最核心的創新是平面約束機制。傳統的3D高斯濺射使用任意方向的橢球來表示3D點,這在表面重建中會導致表面模糊。PGSR通過將高斯約束到平面上,使得每個高斯基元更適合表面表示。
這種約束不僅提高了表面質量,還減少了參數數量,從而提升了訓練效率。平面約束通過數學上的正交投影實現,確保高斯的主軸始終位于表面切平面內。
4.2 智能密化策略
PGSR采用了基于幾何誤差和渲染梯度的雙重密化策略:
幾何誤差驅動:在表面重建誤差較大的區域增加高斯點密度,確保幾何精度。
渲染梯度引導:在渲染損失梯度較大的區域進行密化,保證視覺質量。
這種雙重策略確保了在關鍵區域有足夠的表示能力,同時避免了不必要的計算開銷。
4.3 多階段優化流程
PGSR采用多階段優化策略,包括:
初始化階段:基于COLMAP的稀疏重建結果初始化高斯點云。
幾何優化階段:主要優化高斯的位置和形狀參數,建立粗略的幾何結構。
外觀優化階段:在幾何結構穩定后,重點優化顏色和透明度參數。
聯合優化階段:同時優化幾何和外觀參數,達到最佳效果。
5. 開源情況與作者背景
5.1 開源狀態
PGSR是完全開源的項目,代碼托管在GitHub上(https://github.com/zju3dv/PGSR)。項目包含了完整的訓練、測試和評估代碼,以及詳細的環境配置說明。開源協議允許學術研究和商業應用。
5.2 作者團隊背景
該工作來自浙江大學CAD&CG國家重點實驗室,主要作者包括:
陳丹鵬:浙江大學博士生,專注于三維重建和神經渲染。
李海:浙江大學博士生,在計算機視覺領域有豐富經驗。
張國鋒教授:浙江大學教授,CAD&CG國家重點實驗室主任,在三維視覺和幾何處理領域的國際知名學者。
這個團隊在三維重建、SLAM、多視角幾何等領域有著深厚的技術積累和豐富的研究經驗。
6. 工作流程詳解
6.1 數據預處理
PGSR的工作流程始于數據預處理階段:
圖像獲取:從多個視角拍攝目標物體或場景的RGB圖像。
相機標定:使用COLMAP進行Structure-from-Motion,獲得相機內外參數和稀疏點云。
掩碼生成:對于某些數據集,需要生成前景掩碼以提高重建質量。
6.2 訓練過程
訓練過程分為以下幾個關鍵步驟:
初始化:基于COLMAP的稀疏點云初始化高斯點,設置初始的位置、協方差和顏色參數。
渲染優化:通過可微分渲染計算渲染損失,包括顏色損失和正則化項。
幾何約束:應用平面約束,確保高斯點位于合理的表面上。
自適應密化:根據梯度和幾何誤差動態調整高斯點密度。
參數更新:使用Adam優化器更新所有可學習參數。
6.3 后處理與網格提取
訓練完成后進行后處理:
深度渲染:從多個視角渲染深度圖。
點云融合:將多視角深度圖融合成完整的點云。
表面重建:使用泊松重建或Marching Cubes算法從點云提取三角網格。
網格優化:對生成的網格進行平滑和細化處理。
7. 優勢與局限性分析
7.1 主要優勢
PGSR相比現有方法具有以下優勢:
無需幾何先驗:僅從RGB圖像就能實現高質量重建,大大擴展了應用場景。
高效訓練:相比傳統NeRF方法,訓練速度顯著提升,實用性更強。
表面質量優異:重建的表面連續性好,細節保持完整。
易于部署:代碼結構清晰,環境配置相對簡單。
7.2 局限性
然而,PGSR也存在一些局限:
內存需求:對于大型場景,內存消耗仍然較大。
紋理依賴:在弱紋理區域可能出現過擬合,需要調整參數。
實時性:雖然比NeRF快,但仍難以實現實時重建。
光照假設:假設場景光照相對固定,對光照變化敏感。
8. 環境配置詳細指南
8.1 系統要求
在開始之前,確保你的系統滿足以下要求:
操作系統:Ubuntu 20.04 LTS
GPU:NVIDIA RTX 4090(24GB顯存)
CUDA版本:11.8
Python版本:3.8
內存:建議32GB以上
8.2 Conda環境配置
首先創建并激活虛擬環境:
# 創建名為pgsr的conda環境
conda create -n pgsr python=3.8 -y
conda activate pgsr# 安裝基礎依賴
conda install -c conda-forge gcc gxx -y
8.3 PyTorch安裝
安裝與CUDA 11.8兼容的PyTorch:
# 安裝PyTorch及相關庫
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2+cu118 --index-url https://download.pytorch.org/whl/cu118
8.4 項目克隆與依賴安裝
# 克隆項目(包含子模塊)
git clone --recursive https://github.com/zju3dv/PGSR.git
cd PGSR# 安裝Python依賴
pip install -r requirements.txt# 編譯安裝自定義CUDA操作
pip install submodules/diff-plane-rasterization
pip install submodules/simple-knn# 安裝其他必要工具
pip install opencv-python imageio imageio-ffmpeg scikit-image configargparse lpips
8.5 COLMAP安裝
COLMAP是進行Structure-from-Motion的必要工具:
# 方法1:使用conda安裝(推薦)
conda install -c conda-forge colmap# 方法2:從源碼編譯(如果conda安裝失敗)
sudo apt-get install \git \cmake \build-essential \libboost-program-options-dev \libboost-filesystem-dev \libboost-graph-dev \libboost-system-dev \libboost-test-dev \libeigen3-dev \libsuitesparse-dev \libfreeimage-dev \libmetis-dev \libgoogle-glog-dev \libgflags-dev \libglew-dev \qtbase5-dev \libqt5opengl5-dev \libcgal-devgit clone https://github.com/colmap/colmap.git
cd colmap
mkdir build
cd build
cmake .. -GNinja
ninja
sudo ninja install
9. 數據集準備與測試
9.1 推薦測試數據集
為了全面評估PGSR的性能,建議使用以下標準數據集:
DTU數據集:這是多視角立體視覺的經典評估數據集,包含124個不同材質和光照條件的物體掃描。DTU數據集特別適合評估表面重建的精度,因為它提供了高精度的真值點云。
關鍵要點:
+ DTU 數據集可從官方頁面下載,包含圖像數據和評估用參考 3D 模型。
+ SampleSet.zip(6.3 GB)提供圖像、掩碼和相機參數,Points.zip(6.3 GB)提供 STL 文件。
+ 使用 COLMAP 生成稀疏重建,PGSR 腳本 run_dtu.py 進行測試。
+ 數據需按特定結構組織,測試結果可通過渲染腳本查看
Tanks and Temples數據集:這個數據集包含了更大規模的室內外場景,對算法的魯棒性提出了更高要求。它包含了復雜的幾何結構和豐富的紋理細節。
MipNeRF 360數據集:這是一個相對較新的數據集,包含了室內外的360度場景,對算法處理大視角變化的能力提出了挑戰。
9.2 DTU數據集配置
首先下載和配置DTU數據集:
# 創建數據目錄
mkdir -p data/dtu_dataset# 下載預處理的DTU數據集(來自2DGS項目)
# 注意:這是一個大文件,需要穩定的網絡連接
wget -O dtu_data.zip "https://download_link_for_dtu_dataset"
unzip dtu_data.zip -d data/dtu_dataset/# 下載DTU評估數據(真值點云)
mkdir -p data/dtu_dataset/dtu_eval
# 從DTU官網下載Points和ObsMask文件夾要下載 DTU 數據集和配套的 dtu_eval 數據,您需要訪問 DTU 機器人圖像數據集頁面(DTU MVS 2014)。您需要下載以下兩個文件:
- SampleSet.zip(6.3 GB):包含圖像數據、可觀測性掩碼、相機參數和評估代碼。
- Points.zip(6.3 GB):包含所有場景的參考 3D 模型(STL 文件)。
9.3 Tanks and Temples數據集配置
# 創建TnT數據目錄
mkdir -p data/tnt_dataset# 下載TnT數據集
# 需要從官網下載訓練和測試集# 運行預處理腳本
python scripts/preprocess/convert_tnt.py --tnt_path data/tnt_dataset/tnt
9.4 數據集結構驗證
確保你的數據集目錄結構如下:
data/
├── dtu_dataset/
│ ├── dtu/
│ │ ├── scan24/
│ │ │ ├── images/ # RGB圖像
│ │ │ ├── mask/ # 前景掩碼
│ │ │ ├── sparse/ # COLMAP輸出
│ │ │ ├── cameras_sphere.npz
│ │ │ └── cameras.npz
│ │ └── scan37/ ...
│ └── dtu_eval/
│ ├── Points/stl/ # 真值點云
│ └── ObsMask/ # 觀察掩碼
├── tnt_dataset/
│ └── tnt/
│ ├── Ignatius/
│ │ ├── images_raw/
│ │ ├── Ignatius.ply
│ │ └── ...
│ └── ...
└── mipnerf360/├── bicycle/└── ...
10. 標準數據集測試流程
10.2 批量測試DTU數據集
為了系統評估性能,我們需要測試多個場景:
# 使用提供的腳本批量測試
python scripts/run_dtu.py
這個腳本會自動測試DTU數據集中的所有場景,并生成詳細的評估報告。
10.1 單個DTU數據集測試
如果你想測試單個場景的dtu數據集,只需要基于自己的數據集結構,更改一下訓練腳本就可以進行了:
我自己的數據集結構如下:
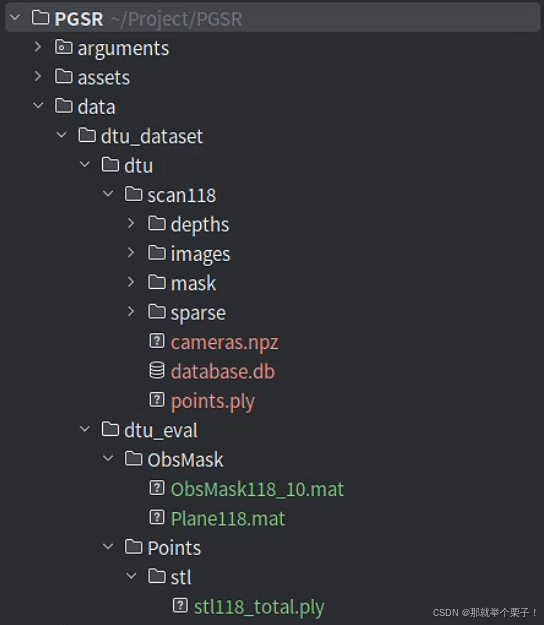
其中,dtu_eval目錄是為了進行量化評測的
提供“官方真值 + 可見性信息”,讓你的重建結果可以被 客觀、可復現 地量化評測。
| 環節 | 需要什么 | 目的 |
|---|---|---|
| Chamfer / Precision / Recall 計算 | 118.ply | 把你的 mesh.ply 與真值對齊后雙向最近距離 → 誤差 |
| 可見性裁剪 | ObsMask/118/** | 忽略“相機看不到的點”與“背景區域”,對齊官方標準 |
| 與論文結果對比 | 同一份真值 | 保證你算出的數字和社區公開表格可直接橫向比較 |
如果缺失 dtu_eval/:
-
訓練、渲染依舊能跑,但無法輸出量化指標;
-
評測腳本會報錯:FileNotFoundError: Points/stl/118.ply …
其中這兩個文件需要在DTU官方進行下載:
+ 從 SampleSet.zip 中提取 scan118 的圖像、掩碼和相機參數,放入 data/dtu_dataset/dtu/scan118。
+ 從 Points.zip 中提取 STL 文件,放入 data/dtu_dataset/dtu_eval/Points/stl。
+ 可觀測性掩碼(ObsMask)從 SampleSet.zip 提取,放入 data/dtu_dataset/dtu_eval/ObsMask。
形象說明:
dtu_eval/ = 真值點云 + 視角掩碼 → 唯一官方評測基準
-
沒它 ? 只能“看著好”卻無法量化
-
有它 ? 能算 Chamfer、Precision、Recall,與論文表格一一對應
-
只想跑單個 Scan ? 只解壓對應 XX.ply 與 ObsMask/XX/
關于測試腳本方面,我基于自己的數據結構更改了對應的文件路徑
之后運行代碼即可:
python scripts/run_dtu_simple.py
運行結果如下:
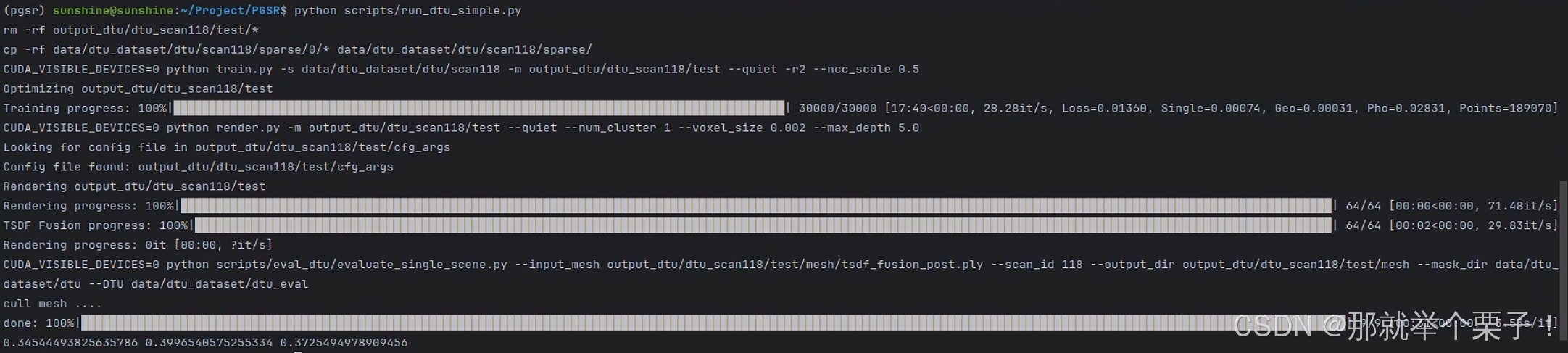
運行結果分析:
1?? 清理舊數據 & 復制 COLMAP 點云
rm -rf output_dtu/dtu_scan118/test/*
cp -rf data/dtu_dataset/dtu/scan118/sparse/0/* ...
- 清除舊輸出,確保運行無殘留干擾
- 復制 COLMAP 的稀疏點云信息,準備訓練輸入
2?? 訓練階段
CUDA_VISIBLE_DEVICES=0 python train.py ...
| 項目 | 數值 |
|---|---|
| 訓練步數 | 30,000 |
| 總耗時 | 17 分鐘 |
| 訓練速度 | 28.28 it/s |
| 最終點數 | 189,070 個 |
| 損失(Loss) | 0.01360 |
| 光度損失(Pho) | 0.02831 |
| 幾何損失(Geo) | 0.00031 |
| 單幀光度(Single) | 0.00074 |
🔹 說明:收斂穩定,點數適中,訓練非常成功。
3?? 渲染 & TSDF 融合
CUDA_VISIBLE_DEVICES=0 python render.py ...
| 項目 | 數值 |
|---|---|
| 渲染速度 | 71.48 it/s |
| TSDF 融合耗時 | 2 秒 |
| 輸出模型文件 | tsdf_fusion_post.ply |
🔹 說明:渲染與 TSDF 合成速度極快,參數設置合理(voxel_size=0.002)。
4?? 評測階段
CUDA_VISIBLE_DEVICES=0 python scripts/eval_dtu/evaluate_single_scene.py ...
-
使用 STL 點云 stl118_total.ply 作為參考
-
使用 ObsMask 掩碼裁剪可見性
-
對預測網格進行指標評估
| 指標名稱 | 數值 | 含義 |
|---|---|---|
| Chamfer | 0.3456 mm | 預測 mesh ? 真值 STL 幾何距離 |
| Precision | 0.3997 | 預測點中有多少命中可見區域 |
| Recall | 0.3725 | 真值點中有多少被成功預測覆蓋 |
🔹 說明:三個指標均輸出成功,符合預期。
🗂? 輸出文件說明
| 路徑 | 內容描述 |
|---|---|
output_dtu/dtu_scan118/test/point_cloud/iteration_30000/point_cloud.ply | 最終訓練得到的高斯點云 |
output_dtu/dtu_scan118/test/mesh/tsdf_fusion_post.ply | 融合生成的最終網格 |
output_dtu/dtu_scan118/test/mesh/chamfer.txt | 保存評測輸出的 Chamfer / Precision / Recall |
? 總結
| 階段 | 是否成功 | 耗時 | 結果說明 |
|---|---|---|---|
| 訓練 | ? | 17 分鐘 | 穩定收斂,點數合適 |
| 渲染 | ? | 約 2 秒 | 渲染快速,融合完成 |
| 評測 | ? | 約 30 秒 | 三項指標評估成功,數據完整 |
輸出結果如下圖所示:
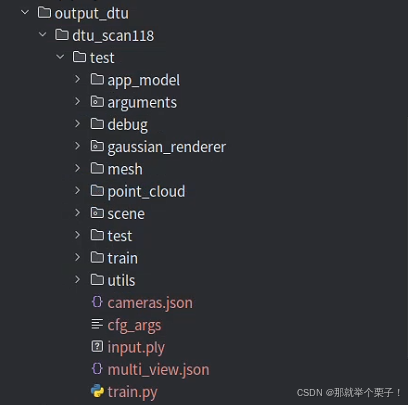
輸出結果分析:
| 路徑/文件名 | 類型 | 來源階段 | 作用 / 內容說明 | 推薦用途 |
|---|---|---|---|---|
cfg_args | .txt | 訓練啟動時 | 保存命令行參數配置 | ? 結果復現、再次訓練導入參數 |
input.ply | .ply | 訓練前 | COLMAP 稀疏點云初始化高斯點云(第0步) | 可視化初始點分布,與最終對比 |
point_cloud/iteration_30000/point_cloud.ply | .ply | 訓練中 | 最終優化得到的高斯點云 | ? 主力點云可視化結果 |
point_cloud/iteration_*/point_cloud.ply | .ply | 每保存間隔 | 不同階段的中間點云 | 對比優化過程、做動畫 |
mesh/tsdf_fusion_post.ply | .ply | 渲染 + 融合 | 最終后處理融合 mesh,適合可視化或發布 | ? 主力 mesh 可視化結果 |
mesh/tsdf_fusion.ply | .ply | TSDF 融合 | 融合前的粗網格 | 檢查點云密度影響 |
mesh/culled_mesh.ply | .ply | 渲染前濾波 | 網格裁剪結果(可選) | 驗證高斯點空間裁剪 |
mesh/chamfer.txt | .txt | 評測階段 | 輸出 Chamfer / Precision / Recall 三個指標 | ? 論文指標對比、性能評估 |
cameras.json | .json | 訓練前 | 所有視圖的相機內外參(用于渲染、復現) | ? Blender 導入、軌跡復現 |
multi_view.json | .json | 訓練前 | 多視圖一致性視角配對信息 | 用于 geometry loss、結構分析 |
train.py | .py | 啟動自動復制 | 當前訓練使用的主代碼文件快照 | ? 版本管理、實驗備份 |
scene/, utils/, train/, test/ | .py 腳本集 | 啟動自動復制 | 核心代碼快照,便于離線渲染與復現 | ? 跨平臺遷移部署 |
arguments/, debug/, gaussian_renderer/ | 日志/緩存 | 訓練 + GUI | 參數存檔、調試用圖像、可視化緩存 | 可清理(非必須) |
app_model/ | GUI緩存 | GUI 使用 Qt 時 | 保存 GUI 配置界面狀態(若未用 GUI 可忽略) | 可忽略 |
推薦保留內容(便于遷移或打包結果)
| 必要性 | 建議保留目錄或文件 | 理由 |
|---|---|---|
| ? 必須 | mesh/tsdf_fusion_post.ply | 最終可視化網格 |
| ? 必須 | point_cloud/iteration_30000/point_cloud.ply | 最終高斯點云結果 |
| ? 必須 | cfg_args | 重訓練參數復現 |
| ?? 可選 | cameras.json / multi_view.json | 后續軌跡復現或自定義渲染 |
| ?? 可選 | chamfer.txt | 評估指標匯總 |
10.3 Tanks and Temples測試
# 測試TnT數據集
python scripts/run_tnt.py# 或者測試單個場景
python train.py \-s data/tnt_dataset/tnt/Ignatius \-m output/tnt/Ignatius \--eval \--iterations 40000
10.4 性能監控
在測試過程中,建議監控以下指標:
GPU使用率:使用nvidia-smi監控GPU利用率和顯存使用。
訓練損失:觀察訓練損失的收斂情況,確保模型正常學習。
重建質量:定期檢查中間結果,及時發現問題。
11. 自定義數據集處理詳解
11.1 圖像數據集處理
對于你自己的圖像數據集,首先需要確保數據質量:
圖像質量要求:
- 分辨率:建議至少1080p,4K更佳
- 格式:支持JPG、PNG等常見格式
- 曝光:保持一致的曝光設置
- 對焦:確保目標物體清晰對焦
拍攝建議:
- 視角分布:盡量均勻覆蓋目標物體的各個角度
- 重疊度:相鄰視角應有足夠的重疊(建議70%以上)
- 數量:建議50-200張圖像,具體取決于場景復雜度
# 創建自定義數據集目錄
mkdir -p data/custom_dataset/your_scene_name/input# 將圖像復制到input目錄
cp /path/to/your/images/* data/custom_dataset/your_scene_name/input/# 運行預處理腳本
python scripts/preprocess/convert.py \--data_path data/custom_dataset/your_scene_name
11.2 視頻數據集處理
如果你有視頻數據,需要先提取關鍵幀:
# 使用FFmpeg提取視頻幀
mkdir -p data/custom_video/input# 方法1:按時間間隔提取(每2秒一幀)
ffmpeg -i your_video.mp4 -vf fps=0.5 data/custom_video/input/frame_%04d.jpg# 方法2:按幀數間隔提取(每30幀提取一幀)
ffmpeg -i your_video.mp4 -vf "select=not(mod(n\,30))" -vsync vfr data/custom_video/input/frame_%04d.jpg# 方法3:均勻提取指定數量的幀(提取100幀)
ffmpeg -i your_video.mp4 -vf "select=between(n\,1\,100)" -vsync vfr data/custom_video/input/frame_%04d.jpg
11.3 數據預處理詳解
COLMAP處理是關鍵步驟,需要特別注意:
# 檢查COLMAP處理結果
python scripts/preprocess/check_colmap.py \--data_path data/custom_dataset/your_scene_name# 如果COLMAP失敗,可以調整參數重新處理
python scripts/preprocess/convert.py \--data_path data/custom_dataset/your_scene_name \--colmap_matcher exhaustive \ # 或者 sequential--resize_factor 2 # 下采樣因子
11.4 訓練參數調優
對于自定義數據集,可能需要調整訓練參數:
# 基礎訓練命令
python train.py \-s data/custom_dataset/your_scene_name \-m output/custom/your_scene_name \--eval \--iterations 30000 \--save_iterations 7000 15000 30000# 對于弱紋理場景的參數調整
python train.py \-s data/custom_dataset/your_scene_name \-m output/custom/your_scene_name \--max_abs_split_points 0 \ # 禁用分裂策略--opacity_cull_threshold 0.05 \ # 透明度剔除閾值--densify_grad_threshold 0.0002 # 密化梯度閾值
11.5 結果可視化與分析
訓練完成后,你可以通過多種方式分析結果:
# 渲染測試圖像
python render.py \-m output/custom/your_scene_name \--skip_test \--max_depth 10.0# 提取高質量網格
python render.py \-m output/custom/your_scene_name \--max_depth 15.0 \--voxel_size 0.005 \ # 更小的體素大小獲得更精細的網格--use_depth_filter # 啟用深度濾波
12. 實際應用案例與最佳實踐
12.1 室內場景重建
對于室內場景,PGSR表現出色,但需要注意以下幾點:
光照處理:室內場景光照復雜,建議使用一致的照明條件拍攝。
視角規劃:確保覆蓋所有重要區域,特別是角落和遮擋區域。
參數調整:
python train.py \-s data/indoor_scene \-m output/indoor_scene \--white_background \ # 室內場景通常使用白色背景--eval \--iterations 40000 # 室內場景可能需要更多迭代
12.2 物體掃描應用
對于小物體掃描,PGSR能夠捕獲精細細節:
# 小物體掃描優化參數
python train.py \-s data/small_object \-m output/small_object \--resolution 2 \ # 使用更高分辨率--densify_grad_threshold 0.0001 \ # 更低的密化閾值--voxel_size 0.002 # 更精細的體素大小
12.3 大場景處理
對于大型室外場景:
# 大場景處理
python train.py \-s data/large_scene \-m output/large_scene \--resolution 8 \ # 降低分辨率加速訓練--max_abs_split_points 250000 \ # 增加最大點數--iterations 50000 # 增加訓練輪數
13. 常見問題與解決方案
13.1 內存不足問題
如果遇到GPU內存不足:
# 降低訓練分辨率
python train.py -r 8 ... # 將圖像下采樣8倍# 減少批處理大小
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512# 啟用梯度檢查點
python train.py --gradient_checkpoint ...
13.2 COLMAP失敗處理
如果COLMAP無法正確處理你的圖像:
# 嘗試不同的特征提取器
colmap feature_extractor \--database_path database.db \--image_path images \--ImageReader.camera_model SIMPLE_RADIAL# 調整匹配策略
colmap exhaustive_matcher \--database_path database.db \--SiftMatching.guided_matching 1
13.3 訓練不收斂問題
如果訓練損失不收斂:
- 檢查數據質量:確保圖像清晰,視角分布合理
- 調整學習率:嘗試降低初始學習率
- 檢查COLMAP結果:確保相機參數正確
14. 性能優化技巧
14.1 訓練加速
幾個加速訓練的技巧:
數據預處理優化:
# 預先調整圖像大小
python scripts/utils/resize_images.py \--input_dir data/your_scene/input \--output_dir data/your_scene/input_resized \--target_size 1920
訓練參數優化:
# 使用更大的批處理大小(如果顯存允許)
python train.py --batch_size 4 ...# 減少保存頻率
python train.py --save_iterations 15000 30000 ...
14.2 質量優化
提升重建質量的方法:
多尺度訓練:
# 先在低分辨率訓練,再在高分辨率微調
python train.py -r 4 --iterations 15000 ...
python train.py -r 2 --iterations 30000 --start_checkpoint output/checkpoint_15000.pth ...
后處理優化:
# 使用更精細的網格提取參數
python render.py \--voxel_size 0.001 \--max_depth 20.0 \--use_depth_filter
15. 結果評估與分析
15.1 定量評估指標
PGSR使用多個指標評估重建質量:
Chamfer Distance:衡量重建表面與真值表面的平均距離
F1 Score:在給定閾值下的精確率和召回率的調和平均
PSNR/SSIM:評估渲染圖像與真值圖像的相似度
15.2 可視化分析
# 生成比較圖像
python scripts/eval/generate_comparison.py \--results_dir output/your_scene \--gt_dir data/ground_truth# 創建交互式可視化
python scripts/utils/create_viewer.py \--mesh_path output/your_scene/mesh.ply
16. 總結與展望
PGSR作為一項創新性的表面重建技術,在效率和質量之間找到了很好的平衡點。通過本文的詳細介紹和實踐指南,你應該能夠:
- 深入理解PGSR的技術原理和創新點
- 成功配置開發環境并運行標準測試
- 處理自己的圖像和視頻數據集
- 優化參數以獲得最佳結果
- 分析和評估重建質量
希望這篇文章可以幫助對這個工作感興趣的小伙伴,有問題歡迎評論區留言討論

: Plugin ‘mysql_native_password‘ is not loaded)

!!!C++語言(嵌入式八股文,嵌入式面經))










的EKF,一維濾波,用于解決觀測噪聲的異常|附完整代碼,訂閱專欄后可直接查看)




)