前言
從15年開始,在深度學習的重要模型中,AutoEncoder(自編碼器)可以說是打開生成模型世界的起點。它不僅是壓縮與重建的工具,更是VAE、GAN、DIffusion等復雜生成模型的思想起源。其實AutoEncoder并不復雜,它是以一種無監督的方式教會模型將復雜的數據轉換成一種更簡單的表現形式。
一、什么是AutoEncoder
AutoEncoder是一種無監督學習模型,其目標是通過編碼器將輸入壓縮成低維的隱藏表示,稱為隱空間,再通過解碼器將其還原回原始輸入。總的來說,就是:編碼器壓縮,解碼器還原。
編碼器主要由兩部分組成:
- Encoder:把輸入?
?映射到潛在表示?
- Decoder:再將?
?還原為近似輸入的?
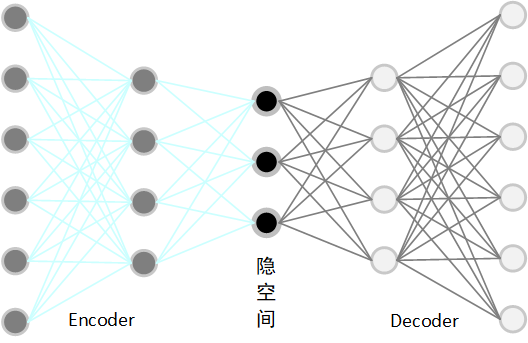
二、AutoEncoder的原理
前面我已經說了,AutoEncoder是一種神經網絡,主要是用來學習數據的表示,嘗試用盡可能少的特征來描述大量數據,實現數據壓縮,例如下圖所示: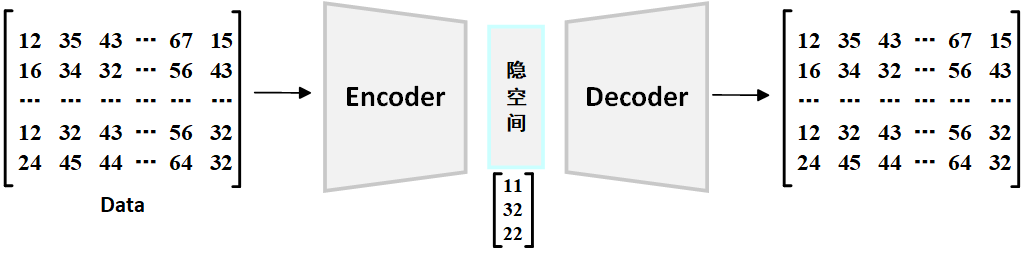
?Encoder將輸入數據壓縮成潛在空間表示,潛在空間是一個低維空間,捕捉了輸入數據的核心特征,Decoder則從潛在空間產生的壓縮表示中重建原始數據。
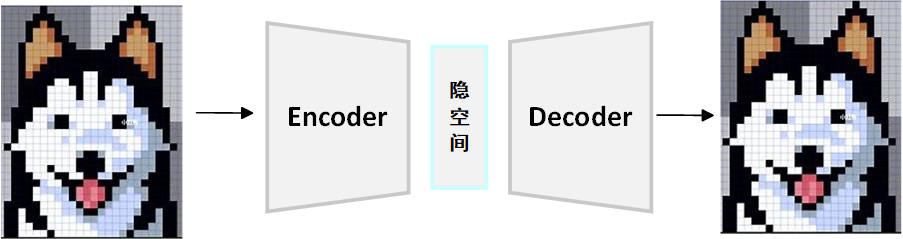
例如編碼圖像,對于上面的小狗頭像,編碼其將圖像降維到幾個關鍵特征,潛在空間保存這些特征,解碼器再從這些低維特征中重建圖像。
三、如何訓練AutoEncoder?
我們已經知道了AutoEncoder工作的原理,那么訓練自編碼器就是最小化原始數據與重建數據之間的差異,目的是提高解碼器根據隱空間表示準確重建原始數據的能力,同時,編碼器也以一種更好的方式壓縮數據,確保原始數據被有效地重建。
通常,我們使用MSE來表示原始數據與重建數據的差異:
四、隱空間維度的影響
我們已經知道了如何訓練AutoEncoder,接下來我們討論一下隱空間維度對模型的影響。
我們已經知道,AutoEncoder的優勢就是它能夠進行數據降維,隱空間的維度是由隱空間層的神經元數量決定的,如果隱空間層神經元數量為2,則隱空間就是二維的。接下來我將使用MINST手寫數字數據集,訓練AutoEncoder,并可視化一下隱空間維度對模型影響。
訓練AutoEncoder:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
from torchvision import transformstransform = transforms.ToTensor()
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)class AutoEncoder(nn.Module):def __init__(self):super(AutoEncoder, self).__init__()self.encoder = nn.Sequential(nn.Linear(784, 128),nn.ReLU(),nn.Linear(128, 64))self.decoder = nn.Sequential(nn.Linear(64, 128),nn.ReLU(),nn.Linear(128, 784),nn.Sigmoid())def forward(self, x):x = x.view(x.size(0), -1)z = self.encoder(x)out = self.decoder(z)return outmodel = AutoEncoder()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.MSELoss()for epoch in range(5):for imgs, _ in train_loader:imgs = imgs.view(imgs.size(0), -1)out = model(imgs)loss = loss_fn(out, imgs)optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {epoch}: Loss={loss.item():.4f}")可視化:
import matplotlib.pyplot as plt
# 設置中文字體為黑體(可選字體)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 正確顯示負號
plt.rcParams['axes.unicode_minus'] = False model.eval()
with torch.no_grad():for imgs, _ in train_loader:imgs = imgsout = model(imgs)break # 只看一批就夠了imgs = imgs.cpu().view(-1, 1, 28, 28)
out = out.cpu().view(-1, 1, 28, 28)# 顯示原圖與重建圖
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):# 原圖ax = plt.subplot(2, n, i + 1)plt.imshow(imgs[i].squeeze(), cmap='gray')plt.title("原始圖")plt.axis("off")# 重建圖ax = plt.subplot(2, n, i + 1 + n)plt.imshow(out[i].squeeze(), cmap='gray')plt.title("重構圖")plt.axis("off")
plt.show()
當隱空間層的維度設置為2時,訓練好的AutoEncoder的效果為:
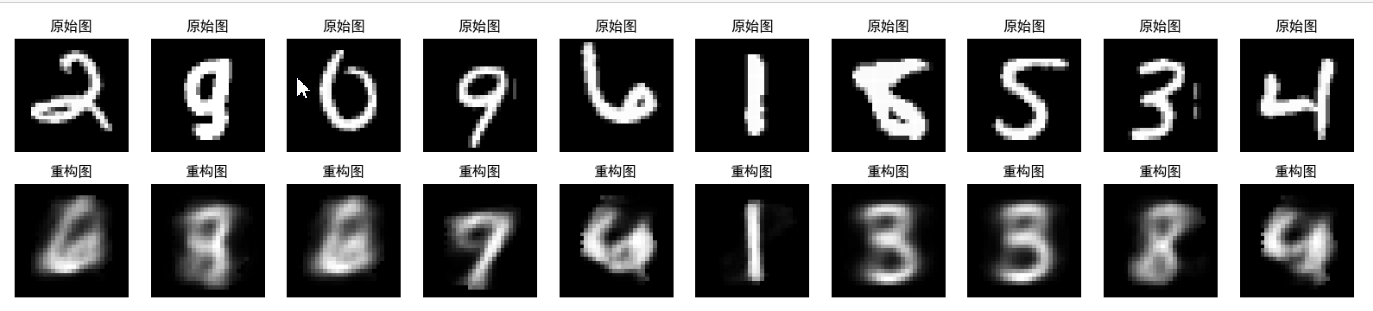
?當隱空間層的維度設置為64時,訓練好的AutoEncoder的效果為:

通過對比發現,隱空間的維度大小直接重構數據的質量,?為什么或這樣呢?
其實這很好解釋,因為AutoEncoder的任務就是壓縮、重建,較差的重建質量說明隱空間的組織性較差,因為好的隱空間表示能夠將每種類型的數字聚類成一簇。但是較低的隱空間維度雖然也能使得一些類型聚類成簇,但是會導致它們相互重疊,很大概率集中在同一區域,而且可能存在系數現象,如下圖所示:
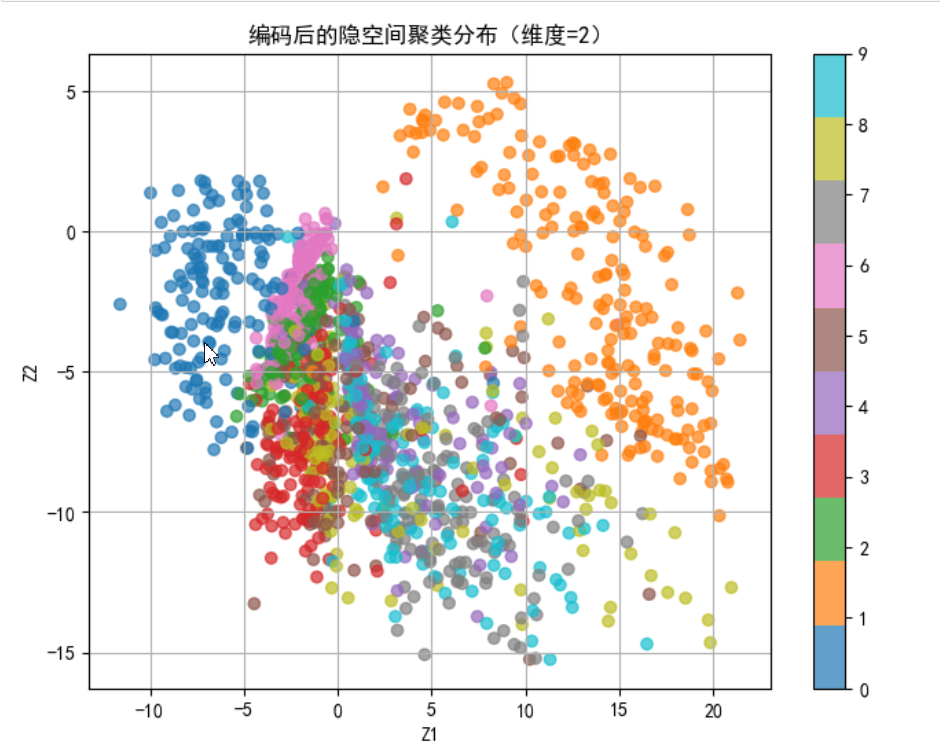
?而更高的維度之間的聚類的分隔度更高,但是仍然會有重疊的部分出現。
五、AutoEncoder的局限
AutoEncoder的最大的局限性就是隱空間,因為AutoEncoder只依賴重建損失來組織隱空間,雖然表現良好,但是通過第四部分我們可以知道,聚類的簇并不是特別完美。為此,大多數基于此類的自編碼器都會對隱空間進行正則化,而其中最有名的就是變分自編碼器(VAE)。當然,之后我會詳細的介紹VAE。
總結
以上就是AutoEncoder的全部內容,相信小伙伴們已經對AutoEncoder有了深刻的理解:AutoEncoder是深度學習中一個經典且充滿啟發的結構,壓縮重構的結構,能夠學到數據的“核心特征”,為后續的復雜的生成模型奠定了基礎。
如果小伙伴們覺得本文對各位有幫助,歡迎:👍點贊 |?? 收藏 | ?🔔 關注。我將持續在專欄《人工智能》中更新人工智能知識,幫助各位小伙伴們打好扎實的理論與操作基礎,歡迎🔔訂閱本專欄,向AI工程師進階!
: Plugin ‘mysql_native_password‘ is not loaded)

!!!C++語言(嵌入式八股文,嵌入式面經))










的EKF,一維濾波,用于解決觀測噪聲的異常|附完整代碼,訂閱專欄后可直接查看)




)
