一、緩存與數據庫的使用場景及性能差異
1. 緩存的適用場景
- 高頻讀、低頻寫場景:如商品詳情頁、用戶信息等讀多寫少的數據,減少數據庫壓力。
- 實時性要求不高的數據:如首頁推薦列表、統計數據(非實時更新),允許短時間內數據不一致。
- 高并發場景下的性能優化:通過緩存抗住流量峰值,避免數據庫直接被擊穿(如秒殺活動中的庫存查詢)。
2. 數據庫的適用場景
- 數據持久化與強一致性場景:如用戶交易記錄、訂單狀態變更,需保證數據不丟失且事務完整。
- 復雜查詢與業務邏輯:涉及多表關聯、聚合統計(如SQL的JOIN、GROUP BY),數據庫更擅長處理此類結構化查詢。
- 數據一致性要求高的場景:如金融交易、庫存扣減,需通過數據庫事務(ACID)保證操作原子性。
3. 數據庫讀寫慢于緩存的根本原因
- 存儲介質差異:
-
- 緩存(如Redis)基于內存(RAM),讀寫速度可達納秒級(10??秒)。
- 數據庫(如MySQL)依賴磁盤(SSD/HDD),隨機讀寫延遲在毫秒級(10?3秒),比內存慢約百萬倍。
- 數據結構與查詢開銷:
-
- 緩存使用哈希表、跳表等內存友好的數據結構,查詢復雜度低(如O(1))。
- 數據庫需維護索引(如B+樹)、事務日志(redo/undo log),且涉及磁盤I/O尋址,開銷更高。
二、MySQL核心問題
1. 事務隔離級別
MySQL支持4種隔離級別(由低到高):
| 隔離級別 | 臟讀 | 不可重復讀 | 幻讀 |
| 讀未提交 | 允許 | 允許 | 允許 |
| 讀已提交 | 禁止 | 允許 | 允許 |
| 可重復讀 | 禁止 | 禁止 | 部分禁止 |
| 串行化 | 禁止 | 禁止 | 禁止 |
不可重復讀的場景:
在一個事務內,兩次讀取同一數據時結果不一致。例如:
- 事務A查詢用戶余額為100元(未提交)。
- 事務B修改余額為80元并提交。
- 事務A再次查詢時,余額變為80元,導致前后結果不一致。
原因:讀已提交和可重復讀隔離級別下,普通查詢(非快照讀)會讀取最新提交的數據,而可重復讀通過MVCC(多版本并發控制)避免此問題。
2. 底層存儲數據結構:B+樹
- 為什么不用平衡二叉樹?
平衡二叉樹的樹高為O(logN),當數據量大時,磁盤I/O次數多(每次I/O對應樹的一層)。而B+樹通過以下特性優化:
-
- 多叉樹結構:每個節點可存儲多個鍵值對,樹高更低(如三層B+樹可存儲百萬級數據)。
- 數據全在葉子節點:非葉子節點僅存索引,葉子節點存數據且有序連接,便于范圍查詢(如
WHERE age > 18)。
3. 三層B+樹最大數據量計算
InnoDB的葉子節點存儲的單位是頁
mysql頁默認存儲的單位是 16384 個字節 16kb 也就是一個節點的大小 節點大小為16KB
非葉子節點存儲的是索引鍵值和頁指針
索引鍵值 BigInt 8字節
頁指針 6字節
那么根節點有
16384 字節 / 14 字節 = 1170 個頁指針
第二層有1170個子節點 每個子節點又指向1180個子節點
第三層都是葉子節點
每個葉子節點存16kb
那么總大小就是 1170 * 1170 * 16 =21902400 條
2200萬kb的數據
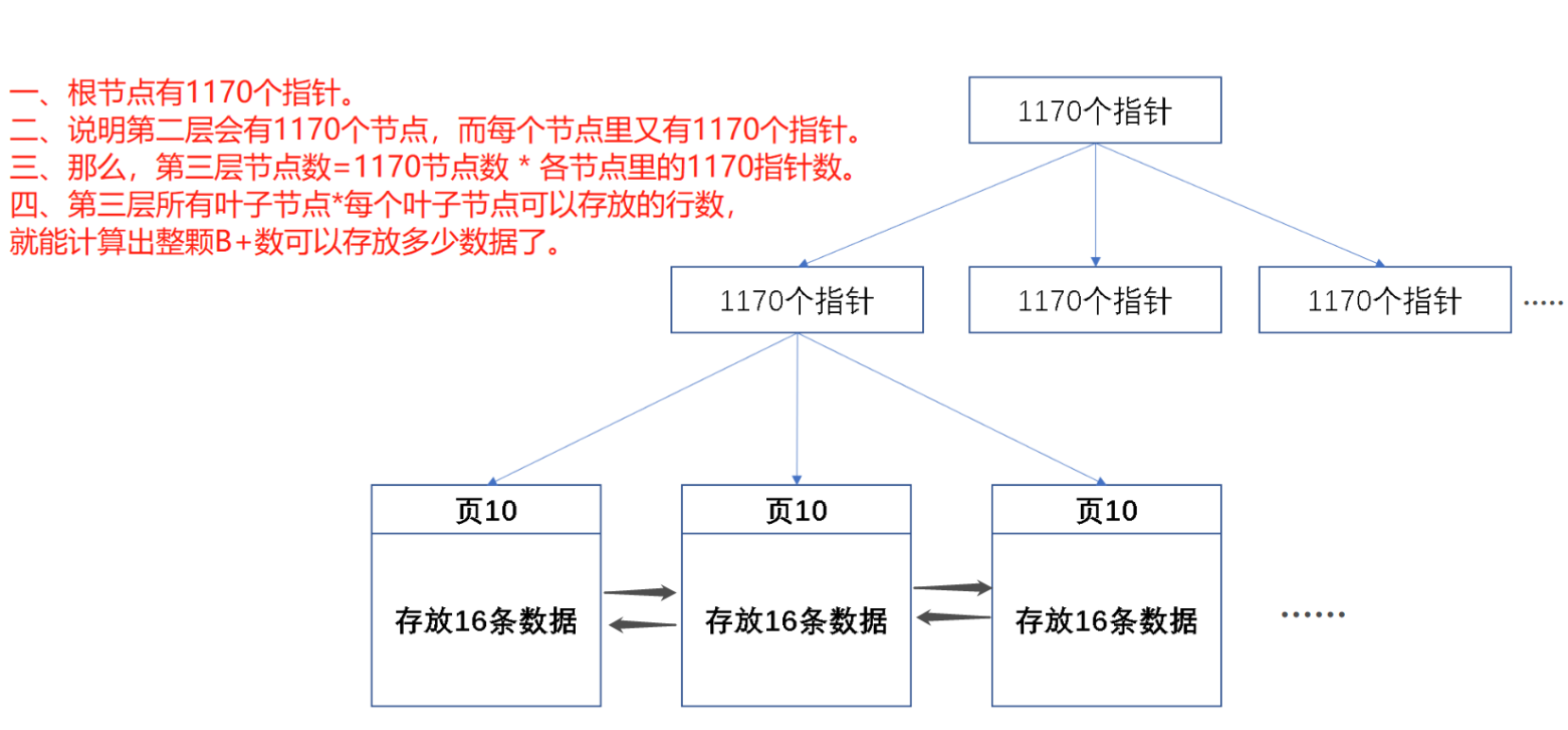
假設:
- 節點大小為16KB(MySQL默認頁大小),鍵值(索引)為8字節(如BIGINT),指針為6字節(指向子節點或數據)。
- 非葉子節點:每個節點存儲
16KB/(8+6B)≈1170個鍵值對。 - 葉子節點:每個節點存儲數據(假設一行數據1KB),則每個葉子節點存16條數據。
- 三層B+樹結構:
-
- 第一層(根節點):1個節點,1170個子節點。
- 第二層(中間層):1170個節點,每個節點1170個子節點,共
1170×1170個葉子節點。 - 第三層(葉子層):
1170×1170×16≈ 22 million(約2200萬) 條數據。
三、HTTPS與HTTP的區別
| 特性 | HTTP | HTTPS |
| 端口 | 80 | 443 |
| 安全性 | 明文傳輸,無加密 | 基于TLS/SSL加密,防篡改、竊聽 |
| 證書 | 無需證書 | 需要CA機構頒發的SSL證書 |
| 性能 | 低延遲,適合簡單場景 | 需握手協商加密參數,延遲略高 |
| 信任機制 | 無 | 通過數字證書驗證服務器身份 |
四、Redis持久化
1. 持久化方式
- RDB(快照):定期將內存數據全量寫入磁盤,生成二進制文件(
.rdb)。 - AOF(日志):記錄每條寫命令,重啟時重放命令恢復數據。
2. AOF快照形式
AOF文件以文本形式存儲命令(如SET key value),可通過BGREWRITEAOF壓縮日志(合并同類命令,如先INCR后DECR可合并為SET)。
3. RDB快照原理(BGSAVE)
- fork子進程:主進程執行
BGSAVE時,通過操作系統fork創建子進程,子進程共享主進程內存數據。 - 寫入快照:子進程將內存數據按RDB格式寫入磁盤,主進程繼續處理請求,避免阻塞。
- 替換舊文件:寫入完成后,用新快照文件替換舊文件,重啟時通過加載
.rdb恢復數據。
五、虛擬內存與頁表
1. 虛擬內存
- 概念:操作系統為每個進程分配的獨立地址空間(如32位系統為4GB),通過內存與磁盤的換入換出(Swap),允許程序使用超過物理內存的空間。
- 作用:
-
- 隔離進程地址空間,避免內存沖突。
- 支持大程序運行,通過分頁機制(Page)將不常用數據暫存磁盤。
2. 頁表
- 概念:虛擬地址到物理地址的映射表,存儲每個頁(Page,如4KB)對應的物理內存地址或磁盤位置。
- 結構:
-
- 一級頁表:適用于小內存系統,虛擬地址直接對應頁表項。
- 多級頁表:如二級頁表,將虛擬地址分為目錄和頁號,減少頁表內存占用(如x86的CR3寄存器指向頁目錄)。
- 查詢過程:CPU通過MMU(內存管理單元)查詢頁表,若頁不在內存中(缺頁中斷),則從磁盤加載到內存。
六、Redis內存占用比預期大的原因
- 數據結構額外開銷:
-
- 例如,存儲字符串
"a"時,Redis使用sdshdr結構體(包含長度、容量、標志位等),實際占用內存大于1字節。 - 哈希表、列表等復雜結構需存儲指針、長度等元數據。
- 例如,存儲字符串
- 內存對齊與分配策略:
-
- Redis按2的冪次分配內存(如存儲10字節數據,分配16字節空間),避免頻繁申請小塊內存導致的碎片。
- 操作系統分配內存時的對齊要求(如8字節對齊)也會增加占用。
- 持久化與復制機制:
-
- RDB/AOF文件生成時的臨時內存開銷,主從復制時的緩沖區等。
七、分庫分表的適用場景
- 單表數據量過大:如單表超過500萬條,查詢性能顯著下降(索引效率降低,磁盤I/O增加)。
- 高并發導致性能瓶頸:單機數據庫連接數、CPU/內存資源不足,無法支撐請求量。
- 數據熱點問題:某部分數據被頻繁訪問(如社交APP的用戶消息表),需分散到不同庫表。
- 業務垂直拆分:按功能模塊分庫(如用戶庫、訂單庫),降低耦合度,便于擴展。
- 跨地域/多租戶需求:數據需按區域或租戶隔離存儲(如多商戶SaaS系統)。
注意:分庫分表會引入分布式事務、跨庫查詢等復雜性,需權衡使用(如優先優化索引、讀寫分離,再考慮分庫分表)。

(附詳細解題思路))
)


![[BIOS]VSCode zx-6000 編譯問題](http://pic.xiahunao.cn/[BIOS]VSCode zx-6000 編譯問題)


音頻延遲的一些感想跟分析,讓你對A2DP體驗更佳深入)


)



)

混合策略實現 doc-doc 對稱檢索)

