目錄
- 1.摘要
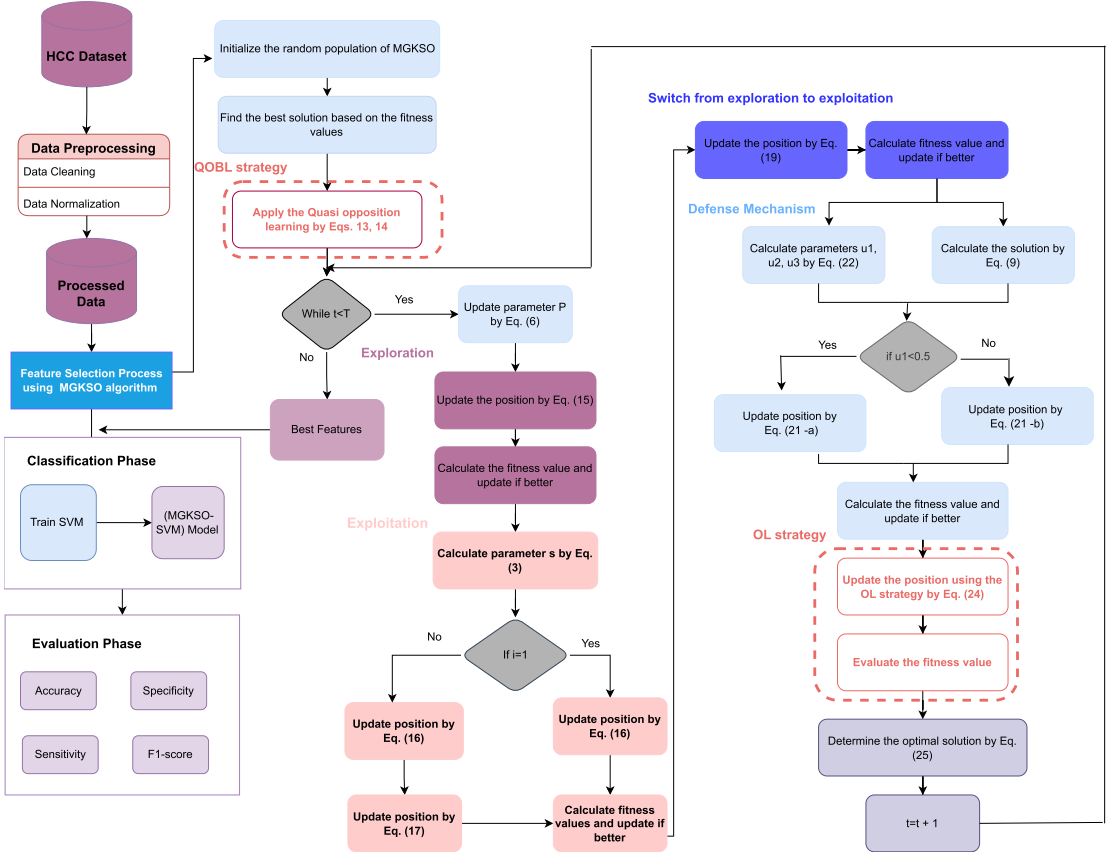
- 2.成吉思汗鯊魚優化算法GKSO原理
- 3.MGKSO
- 4.結果展示
- 5.參考文獻
- 6.代碼獲取
- 7.算法輔導·應用定制·讀者交流

1.摘要
本文針對肝癌(HCC)早期診斷難題,提出了一種基于改進成吉思汗鯊魚優化算法(MGKSO)的計算機輔助診斷系統。由于HCC在早期癥狀不明顯且涉及高維復雜數據,傳統機器學習方法易受噪聲和冗余特征干擾。為提升診斷準確性與效率,MGKSO融合了準對立學習(QOBL)與正交學習(OL)策略,有效增強了特征選擇過程中的全局搜索與局部優化能力。
2.成吉思汗鯊魚優化算法GKSO原理
【智能算法】成吉思汗鯊魚優化算法(GKSO)原理及實現
3.MGKSO
MGKSO中引入了準對立學習(QOBL)機制,用來提升初始化階段種群的多樣性和全局搜索能力。在初始解生成過程中,每個候選解在給定的搜索邊界內隨機產生。在MGKSO中,QOBL通過計算解空間邊界的平均值,生成位于搜索區域對側的準對立解,提升搜索范圍與解的多樣性。為避免早期陷入局部最優,本研究將QOBL策略延后至初始化階段末尾引入,從而更有效地推動算法向全局最優收斂。
x j O B L = L B j + U B j ? x j x_j^{\mathrm{OBL}}=LB_j+UB_j-x_j xjOBL?=LBj?+UBj??xj?
x j Q O B L = { L B j + U B j 2 + rand() ? ( x j O B L ? L B j + U B j 2 ) , if? x j < L B j + U B j 2 x j O B L + rand() ? ( L B j + U B j 2 ? x j O B L ) , otherwise x^{QOBL}_j = \begin{cases} \frac{LB_j + UB_j}{2} + \text{rand()} \cdot \left( x^{OBL}_j - \frac{LB_j + UB_j}{2} \right), & \text{if } x_j < \frac{LB_j + UB_j}{2} \\ x^{OBL}_j + \text{rand()} \cdot \left( \frac{LB_j + UB_j}{2} - x^{OBL}_j \right), & \text{otherwise} \end{cases} xjQOBL?=? ? ??2LBj?+UBj??+rand()?(xjOBL??2LBj?+UBj??),xjOBL?+rand()?(2LBj?+UBj???xjOBL?),?if?xj?<2LBj?+UBj??otherwise?
在此之后,MGKSO開始使用布朗運動來模擬隨機運動:
X i j ( t + 1 ) = X b e s t + exp ? ( ( t i t ) 4 ) × ( R B ? 0.5 ) × ( X b e s t ? Q O X i ) , 1 3 T < t < 2 3 T X_i^j(t+1) = X_{best} + \exp\left( \left( \frac{t}{it} \right)^4 \right) \times (RB - 0.5) \times (X_{best} - QOX_i), \quad \frac{1}{3}T < t < \frac{2}{3}T Xij?(t+1)=Xbest?+exp((itt?)4)×(RB?0.5)×(Xbest??QOXi?),31?T<t<32?T
狩獵階段:每個解 X i X_i Xi?會通過朝向當前已知的最優解移動來進行更新:
X i n e w = X b e s t + exp ? ( i t e r M a x i t e r ) 4 ? ( R i ? 0.5 ) ? ( X b e s t ? X i ) X_i^{new}=X_{best}+\exp\left(\frac{iter}{Max_iter}\right)^4\cdot(R_i-0.5)\cdot(X_{best}-X_i) Xinew?=Xbest?+exp(Maxi?teriter?)4?(Ri??0.5)?(Xbest??Xi?)
最優解吸引:通過向最優解移動:
X i n e w = X i + s i ? ( r a n d ? X b e s t ? r a n d ? X i ) X_i^{new}=X_i+s_i\cdot \begin{pmatrix} rand\cdot X_{best}-rand\cdot X_i \end{pmatrix} Xinew?=Xi?+si??(rand?Xbest??rand?Xi??)
其中, s i s_i si?是基于解的適應度的比例因子:
s i = 1.5 ? ( F i t n e s s ( X i ) ) r a n d s_{i}=1.5\cdot\left(\mathrm{Fitness}(X_{i})\right)^{rand} si?=1.5?(Fitness(Xi?))rand
覓食階段:覓食階段引入拋物線運動:
X i n e w = X b e s t + r a n d ? ( X b e s t ? X i ) + T F ? 2 ? ( X b e s t ? X i ) X_i^{new}=X_{best}+rand\cdot(X_{best}-X_i)+TF\cdotp^2\cdot(X_{best}-X_i) Xinew?=Xbest?+rand?(Xbest??Xi?)+TF?2?(Xbest??Xi?)
自我保護機制:該機制通過引入復雜的擾動來保證多樣性:
X i new = { X i ( t ) + f 1 ? ( u 1 ? X best ( t ) ? u 2 ? X p ( t ) ) + f 2 ? ρ ? ( u 3 ? X 2 ( t ) ? X 1 ( t ) ) + u 2 ? ( X r 1 ( t ) ? X r 2 ( t ) ) / 2 , if? u 1 < 0.5 , X best ( t ) + f 1 ? ( u 1 ? X best ( t ) ? u 2 ? X p ( t ) ) + f 2 ? ρ ? u 3 ( X 2 ( t ) ? X 1 ( t ) ) + u 2 ? ( X r 1 ( t ) ? X r 2 ( t ) ) / 2 , otherwise . X_i^{\text{new}} = \begin{cases} X_i(t) + f_1 \cdot \left( u_1 \cdot X_{\text{best}}(t) - u_2 \cdot X_p(t) \right) \\ \quad + f_2 \cdot \rho \cdot \left( u_3 \cdot X_2(t) - X_1(t) \right) \\ \quad + u_2 \cdot \left( X_{r1}(t) - X_{r2}(t) \right)/2, & \text{if } u_1 < 0.5, \\ X_{\text{best}}(t) + f_1 \cdot \left( u_1 \cdot X_{\text{best}}(t) - u_2 \cdot X_p(t) \right) \\ \quad + f_2 \cdot \rho \cdot u_3 \left( X_2(t) - X_1(t) \right) \\ \quad + u_2 \cdot \left( X_{r1}(t) - X_{r2}(t) \right)/2, & \text{otherwise}. \end{cases} Xinew?=? ? ??Xi?(t)+f1??(u1??Xbest?(t)?u2??Xp?(t))+f2??ρ?(u3??X2?(t)?X1?(t))+u2??(Xr1?(t)?Xr2?(t))/2,Xbest?(t)+f1??(u1??Xbest?(t)?u2??Xp?(t))+f2??ρ?u3?(X2?(t)?X1?(t))+u2??(Xr1?(t)?Xr2?(t))/2,?if?u1?<0.5,otherwise.?
正交學習(OL)是一種廣泛應用的技術,用來在通過在搜索過程中的探索和開發階段之間實現平衡,從而增強對最優解的搜索能力。OL策略采用了正交實驗設計(OED)方法,以構造出能有效代表群體的解,從而引導群體朝著全局最優解前進(Gao, Liu, & Huang, 2013)。通過在少量實驗中確定因子水平的最佳組合,OED能夠提供新的解,引導搜索過程更加高效地進行。OL策略分為兩個主要階段:
正交表(Orthogonal Array, OA):第一階段涉及生成一個預定義的表格,稱為正交表(OA),該表格由一系列特定的數字組成,通常表示為 L M ( L Q ) L_{M}(L^{Q}) LM?(LQ)。

因子分析(FA):第二階段使用成分分析,通過利用正交表(OA)中所有 M M M種可能組合的實驗結果來實現,用于確定這種影響:
W q , l = ∑ m = 1 M f ( C m ) ? E m , q , l W_{q,l}=\sum_{m=1}^Mf(C_m)\cdot E_{m,q,l} Wq,l?=m=1∑M?f(Cm?)?Em,q,l?
f ( C m ) f(C_m) f(Cm?)表示正交表 (OA) 中第 m m m個組合的適應度。變量 E m , q , l E_{m,q,l} Em,q,l?在第 m m m個組合中,若第 q q q個因子使用的是第 l l l個水平,則設置為 1; 否則為 0。可以迅速確定每個水平對各因子的影響:
X n m = X n b e s t m ⊕ X n m X_n^m=X_{n_{best}}^m\oplus X_n^m Xnm?=Xnbest?m?⊕Xnm?
⊕ \oplus ⊕表示正交學習過程。

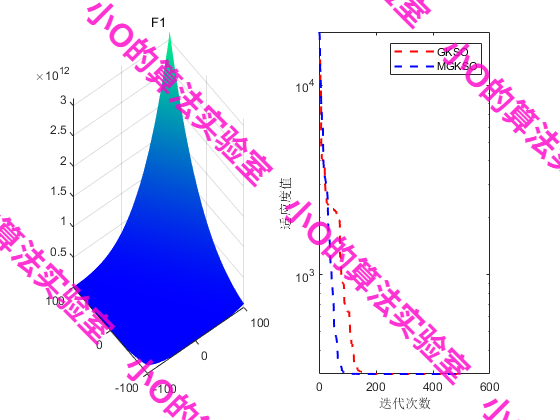
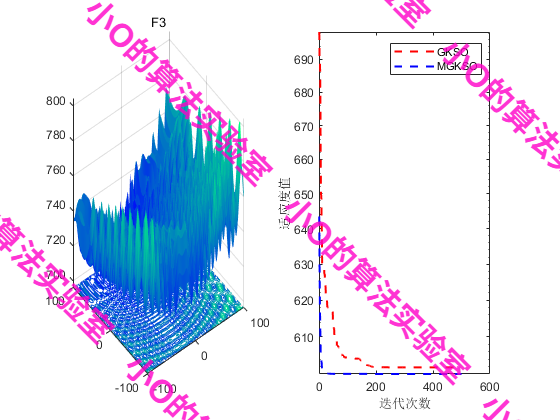
4.結果展示
5.參考文獻
[1] Emam M M, Mostafa R R, Houssein E H. Computer-aided diagnosis system for predicting liver cancer disease using modified Genghis Khan Shark Optimizer algorithm[J]. Expert Systems with Applications, 2025, 285: 128017.

)





![LeetCode[513]找樹左下角的值](http://pic.xiahunao.cn/LeetCode[513]找樹左下角的值)











