說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔),如需數據+代碼+文檔可以直接到文章最后關注獲取。

1.項目背景
隨著人工智能和深度學習技術的快速發展,卷積神經網絡(CNN)在圖像分類、目標檢測等領域取得了顯著成果。然而,在回歸任務中,如時間序列預測、圖像像素值估計等場景下,CNN 的性能往往受限于超參數的選擇,例如學習率、卷積核大小、層數等。不合理的超參數設置可能導致模型過擬合或欠擬合,從而影響預測精度。傳統的手動調參方法耗時且依賴經驗,難以應對復雜問題。因此,如何高效地優化 CNN 的超參數成為了一個亟待解決的問題。
為了解決上述問題,智能優化算法逐漸被引入到深度學習領域。粒子群優化算法(PSO)因其簡單高效、全局搜索能力強而備受關注。然而,標準 PSO 在處理高維、非線性問題時可能存在收斂速度慢、易陷入局部最優等問題。為此,并行粒子群優化算法(P-PSO)應運而生,通過多子種群協同搜索和信息共享機制,顯著提升了優化效率和魯棒性。將 P-PSO 應用于 CNN 超參數優化,可以有效提高模型的泛化能力和預測精度,同時降低人工干預成本。
本項目旨在結合 P-PSO 和 CNN 構建一個高效的回歸模型,利用 P-PSO 自動優化 CNN 的關鍵超參數,從而提升模型在復雜數據集上的表現。這一研究不僅為深度學習模型的自動化優化提供了新思路,還具有廣泛的實際應用價值。例如,在金融領域,可用于股票價格預測;在醫療領域,可用于醫學影像分析和疾病風險評估;在工業領域,可用于設備狀態監測和故障預測。通過本項目的實施,我們期望為相關領域的智能化發展提供有力的技術支持。
本項目通過Python實現P-PSO優化算法優化卷積神經網絡CNN回歸模型項目實戰。???????????????
2.數據獲取
本次建模數據來源于網絡(本項目撰寫人整理而成),數據項統計如下:
| 編號 | 變量名稱 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因變量 |
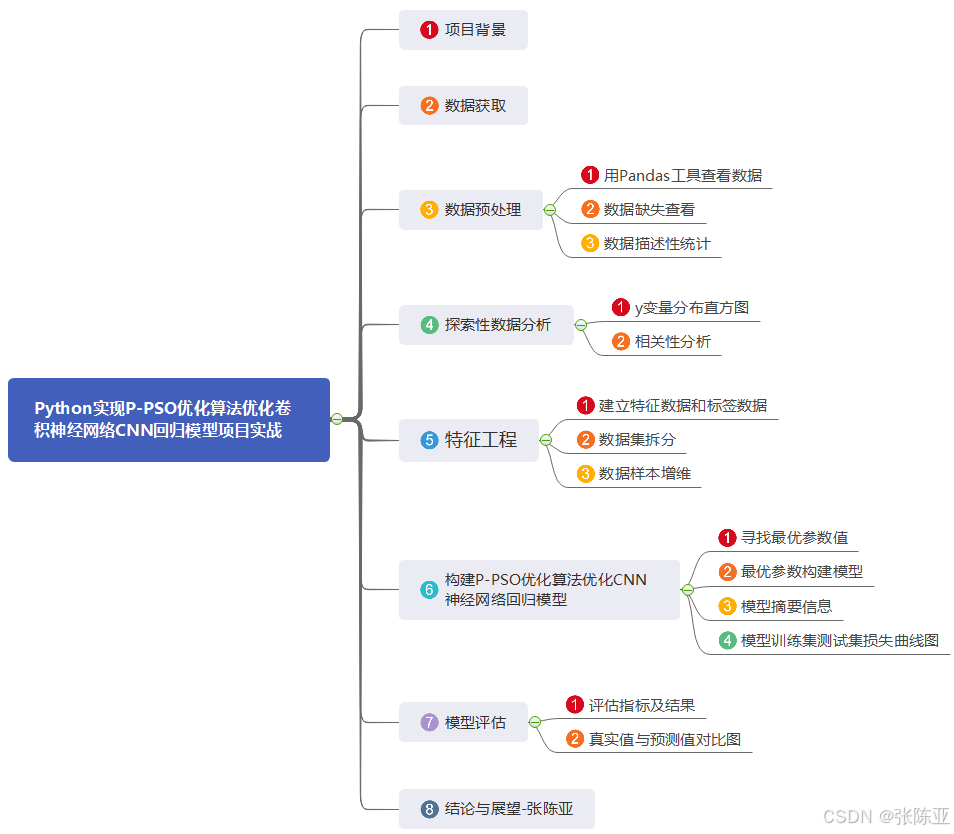
數據詳情如下(部分展示):
3.數據預處理
3.1?用Pandas工具查看數據
使用Pandas工具的head()方法查看前五行數據:

關鍵代碼:

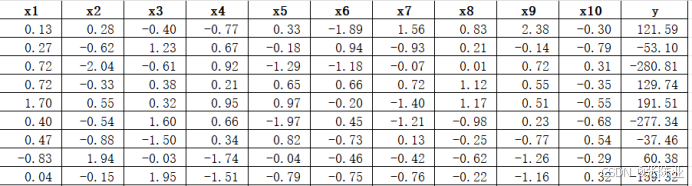
3.2數據缺失查看
使用Pandas工具的info()方法查看數據信息:
從上圖可以看到,總共有11個變量,數據中無缺失值,共2000條數據。
關鍵代碼:?

3.3數據描述性統計
通過Pandas工具的describe()方法來查看數據的平均值、標準差、最小值、分位數、最大值。
關鍵代碼如下: ?

4.探索性數據分析
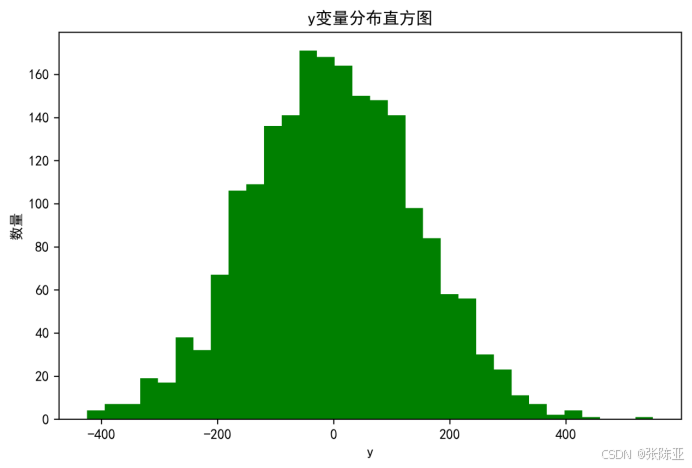
4.1 y變量分布直方圖
用Matplotlib工具的hist()方法繪制直方圖:
4.2 相關性分析
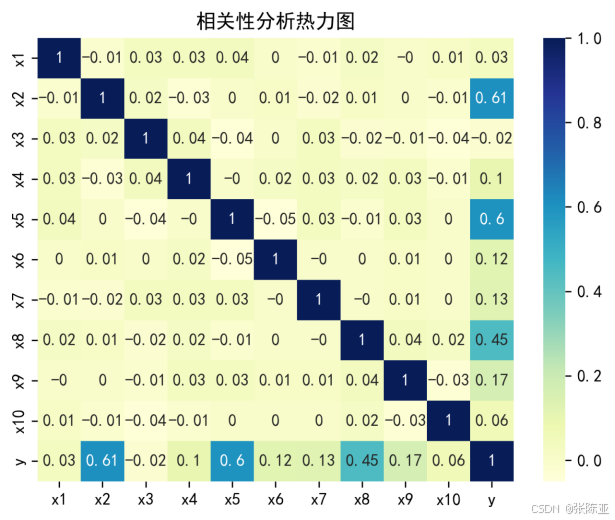
從上圖中可以看到,數值越大相關性越強,正值是正相關、負值是負相關。??
5.特征工程
5.1 建立特征數據和標簽數據
關鍵代碼如下:

5.2?數據集拆分
通過train_test_split()方法按照80%訓練集、20%測試集進行劃分,關鍵代碼如下:?

5.3?數據樣本增維
為滿足建模的需要,對特征樣本進行增加一個維度,增維的關鍵代碼如下:

6.構建P-PSO優化算法優化CNN神經網絡回歸模型???
主要使用通過P-PSO優化算法優化CNN神經網絡回歸模型,用于目標回歸。??????????
6.1?尋找最優參數值??
最優參數值:?
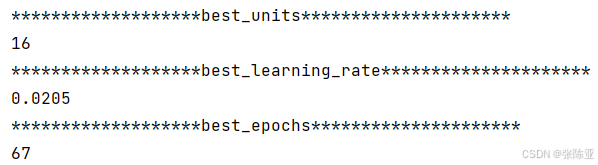
6.2?最優參數構建模型?
| 編號 | 模型名稱 | 參數 |
| 1 | CNN神經網絡回歸模型???? | units=best_units |
| 2 | optimizer = tf.keras.optimizers.Adam(best_learning_rate) | |
| 3 | epochs=best_epochs |
6.3?模型摘要信息

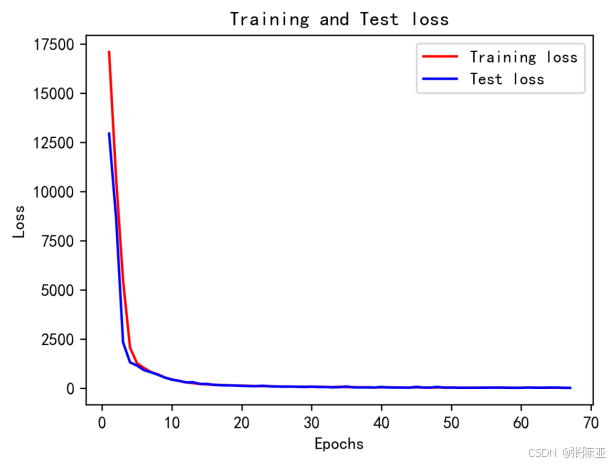
6.4?模型訓練集測試集損失曲線圖
7.模型評估
7.1評估指標及結果??
評估指標主要包括R方、均方誤差、解釋性方差、絕對誤差等等。?
| 模型名稱 | 指標名稱 | 指標值 |
| 測試集 | ||
| CNN神經網絡回歸模型???? | R方 | 0.9994 |
| 均方誤差 | 10.7141 | |
| 解釋方差分 | 0.9994 | |
| 絕對誤差 | 2.4069? | |
從上表可以看出,R方分值為0.9994,說明模型效果較好。????
關鍵代碼如下: ????

7.2 真實值與預測值對比圖
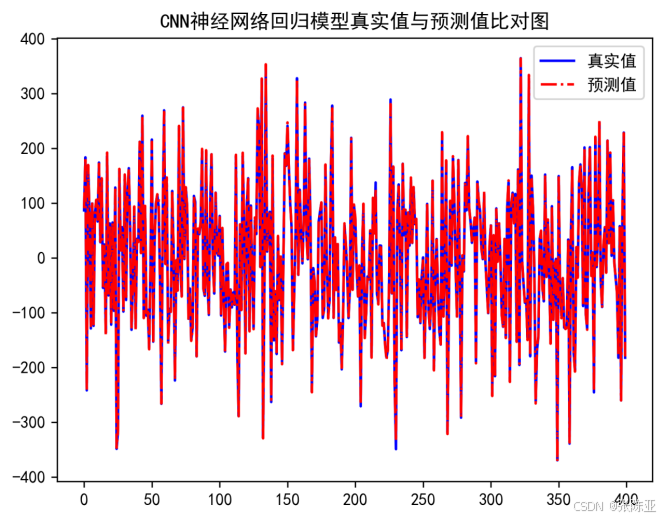
從上圖可以看出真實值和預測值波動基本一致,模型效果良好。???????
8.結論與展望
綜上所述,本文采用了Python實現P-PSO優化算法優化CNN神經網絡回歸算法來構建回歸模型,最終證明了我們提出的模型效果良好。此模型可用于日常產品的預測。??



![LeetCode[513]找樹左下角的值](http://pic.xiahunao.cn/LeetCode[513]找樹左下角的值)















