在R語言中,有多種數據類型,用以存儲和處理數據。每種數據類型都有其特定的用途和操作函數,使得R語言在處理各種數據分析任務時非常靈活和強大:
向量(Vector): 向量是R語言中最基本的數據類型,它是由相同類型的元素構成的一維數組。例如,一個由數值組成的向量或一個由字符串組成的向量。
矩陣(Matrix): 矩陣是一個二維數組,其中的數據元素按照行和列的形式排列。矩陣中的所有元素必須是同一類型。
數組(Array): 數組是向量的一種擴展,可以有多維。例如,你可以有一個三維數組,其中包含多個二維矩陣。
數據框(Data Frame): 數據框是R語言中用于存儲表格數據的最重要的數據類型。它類似于數據庫中的表或Excel中的電子表格。數據框可以包含不同類型的列(數值、字符、邏輯等)。
列表(List): 列表是一種復合數據類型,可以包含任意類型的元素(數值、字符、向量、矩陣、甚至其他列表等),并且各元素的長度也可以不同。
因子(Factor): 因子是用于分類數據的數據類型。它們用于表示有限的分類值集,例如性別(男、女)、評級(優、良、差)等。
邏輯值(Logical): 邏輯值是R語言中的布爾類型,代表真(TRUE)或假(FALSE)。
2.1 理解數據集
行(row):表示觀測值 列(col):表示變量
2.2 數據結構
包括標量、向量、矩陣、數組、數據框、列表。
2.2.1 向量(vector)
-
2.2.1.1 定義
是用于存儲數值型、字符型或邏輯型數據的一維數組。例如:
a <- c(1,2,3,4,5,6,-2,4)
b <- c("one","two","three","four")
c <- c(TRUE,TRUE,TRUE,FALSE,FALSE)a為數值型向量,b字符型(必須加”“),c邏輯型向量。
單個向量中的數據類型必須相同
標量(scalar)是只含一個元素的向量。eg g<-1
-
2.2.1.2 訪問向量中的元素
注:R中位置索引從1開始,而不是0
1)訪問單個元素
a <- c("k","q","e","f","a","w","p","m")
a[3]## [1] "e"2)訪問多個元素
a <- c("k","q","e","f","a","w","p","m")
a[c(1,2,4,6)]## [1] "k" "q" "f" "w"3)連續訪問多個元素
a <- c("k","q","e","f","a","w","p","m")
a[c(2:6)]## [1] "q" "e" "f" "a" "w"2.2.2 矩陣(matrix)
-
2.2.2.1 定義
是一個二維數組,只是每個元素都擁有相同的模式(數值型、字符型或邏輯型)。
可以通過函數matrix()創建矩陣,格式如下:
mymatrix <- matrix(vector,nrow = number_of_rows,ncol = number_of_columns,byrow = logical_value,dimnames = list(char_vector_rownames,char_vector_colnames))vector:矩陣的元素
nrow:行的維數
ncol:列的維數
dimnames:可選的、以字符型向量表示的行名和列名,如果沒有設定可以不寫
byrow = TRUE:矩陣按行填充,byrow = FALSE:矩陣按列填充。**如果不做設定,默認情況下按列填充。
因此,創建矩陣時至少包括vector,nrow,ncol
-
2.2.2.2 創建矩陣
y <- matrix(1:20,nrow = 5,ncol = 4)
y## ? ? ?[,1] [,2] [,3] [,4]
## [1,] ? ?1 ? ?6 ? 11 ? 16
## [2,] ? ?2 ? ?7 ? 12 ? 17
## [3,] ? ?3 ? ?8 ? 13 ? 18
## [4,] ? ?4 ? ?9 ? 14 ? 19
## [5,] ? ?5 ? 10 ? 15 ? 20cells <- c(1,26,24,68)
rnames <- c("R1","R2")
cnames <- c("C1","C2")
mymatrix1 <- matrix(cells,nrow = 2,ncol = 2,byrow = FALSE,dimnames = list(rnames,cnames))
mymatrix1## ? ?C1 C2
## R1 ?1 24
## R2 26 68可以看到優先按列填充,且行名為rnames,列名為cnames。
下面改變一些參數:
cells <- c(1,26,24,68)
rnames <- c("R1","R2")
cnames <- c("C1","C2")
mymatrix2 <- matrix(cells,nrow = 2,ncol = 2,byrow = TRUE,dimnames = list(cnames,rnames))
mymatrix2## ? ?R1 R2
## C1 ?1 26
## C2 24 68可以看的變成了優先按行填充,行名變為cnames,列名變為rnames。
2.2.3 訪問矩陣中的元素
使用下標和方括號來選擇矩陣中的行、列或元素。
x[i,]:矩陣x中的第i行
x[,j]:矩陣x中的第j列
x[i,j]:矩陣x中第i行第j列個元素
x[i,c(h,j)]:矩陣x中第i行,第h和j列
x[c(h:i),j]:矩陣x中第h-i行,第j列
舉例
x <- matrix(21:40,nrow = 4,ncol = 5 )
x## ? ? ?[,1] [,2] [,3] [,4] [,5]
## [1,] ? 21 ? 25 ? 29 ? 33 ? 37
## [2,] ? 22 ? 26 ? 30 ? 34 ? 38
## [3,] ? 23 ? 27 ? 31 ? 35 ? 39
## [4,] ? 24 ? 28 ? 32 ? 36 ? 40x[1,]## [1] 21 25 29 33 37x[,5]## [1] 37 38 39 40x[c(1,2,3),5]## [1] 37 38 39x[c(2:4),c(2:4)]## ? ? ?[,1] [,2] [,3]
## [1,] ? 26 ? 30 ? 34
## [2,] ? 27 ? 31 ? 35
## [3,] ? 28 ? 32 ? 36矩陣也只能包含一種數據類型,當維度超過2時,可以使用數組
2.2.3 數組(array)
-
2.2.3.1 定義
數組(array)與矩陣類似,但是維度可以大于2,即可以是三維的。
通過函數array()創建:
myarray <- array(vector,dimensions,dimnames)vector:數組中的數據
dimensions:數值型向量,給出了各個維度下標的最大值,按行,列,面進行排序
dimnames:可選的、各維度名稱標簽的列表
-
2.2.3.2 創建數組
dim1 <- c("A1","A2")
dim2 <- c("B1","B2","B3")
dim3 <- c("C1","C2","C3","C4")
z <- array(1:24,c(2,3,4),dimnames = list(dim1,dim2,dim3))
z## , , C1
##
## ? ?B1 B2 B3
## A1 ?1 ?3 ?5
## A2 ?2 ?4 ?6
##
## , , C2
##
## ? ?B1 B2 B3
## A1 ?7 ?9 11
## A2 ?8 10 12
##
## , , C3
##
## ? ?B1 B2 B3
## A1 13 15 17
## A2 14 16 18
##
## , , C4
##
## ? ?B1 B2 B3
## A1 19 21 23
## A2 20 22 24可以看到這里c(2,3,4)表示的3個維度分別為2,3,4個,即2行3列4面。
-
2.2.3.3 訪問數組中的元素
和矩陣類似,使用下標和方括號來選擇。
z[1,3,4]## [1] 23這表示選擇是維度1中的1(第一行),維度2中的3(第三列),維度3中的4(第4個矩陣)?可以某種程度上將數組看出幾個矩陣的組合。
2.2.4 數據框(data)
-
2.2.4.1 定義
數據框的不同列可以包含不同模式(數值型、字符型、邏輯型)數據,更類似于常見的數據集。
通過函數data.frame()創建:
mydata <- data.frame(col1,col2,col3,...)col1,col2,col3,…:列向量,可以為任何類型的數據,每一列的名稱由函數names指定。?但通常不同列(變量)的向量中的數據(觀測值)個數相同,且每一列數據的模式必須相同
-
2.2.4.2 創建數據框
patientID <- c(1,2,3,4)
age <- c(25,34,28,52)
diabetes <- c("Type1","Type2","Type1","Type1")
status <- c("Poor","Improved","Excellent","Poor")
patientdata <- data.frame(patientID,age,diabetes,status)
patientdata## ? patientID age diabetes ? ?status
## 1 ? ? ? ? 1 ?25 ? ?Type1 ? ? ?Poor
## 2 ? ? ? ? 2 ?34 ? ?Type2 ?Improved
## 3 ? ? ? ? 3 ?28 ? ?Type1 Excellent
## 4 ? ? ? ? 4 ?52 ? ?Type1 ? ? ?Poor-
2.2.4.3 選取數據框中的元素
1)用方括號和下標來選取,[n]和[n1:n2]格式下標的數字表示第n1到n2變量(列)
patientdata[1:2]## ? patientID age
## 1 ? ? ? ? 1 ?25
## 2 ? ? ? ? 2 ?34
## 3 ? ? ? ? 3 ?28
## 4 ? ? ? ? 4 ?52patientdata[4]## ? ? ?status
## 1 ? ? ?Poor
## 2 ?Improved
## 3 Excellent
## 4 ? ? ?Poor而[n1,n2]則選取的依然是第n1行,n2列對應的元素
patientdata[3,4]## [1] "Excellent"2)直接利用函數制定特定變量名來獲取
patientdata[c("age","status")]## ? age ? ?status
## 1 ?25 ? ? ?Poor
## 2 ?34 ?Improved
## 3 ?28 Excellent
## 4 ?52 ? ? ?Poor注意變量名是字符型數據,所以要加”“
3)利用$符號+變量名(不用雙引號)
patientdata$status## [1] "Poor" ? ? ?"Improved" ?"Excellent" "Poor"with()函數
在每個變量名前都輸入一次patientdata$比較繁瑣,可以借助with()函數簡化代碼
以內置數據框mtcars為例:
mtcars## ? ? ? ? ? ? ? ? ? ? ?mpg cyl ?disp ?hp drat ? ?wt ?qsec vs am gear carb
## Mazda RX4 ? ? ? ? ? 21.0 ? 6 160.0 110 3.90 2.620 16.46 ?0 ?1 ? ?4 ? ?4
## Mazda RX4 Wag ? ? ? 21.0 ? 6 160.0 110 3.90 2.875 17.02 ?0 ?1 ? ?4 ? ?4
## Datsun 710 ? ? ? ? ?22.8 ? 4 108.0 ?93 3.85 2.320 18.61 ?1 ?1 ? ?4 ? ?1
## Hornet 4 Drive ? ? ?21.4 ? 6 258.0 110 3.08 3.215 19.44 ?1 ?0 ? ?3 ? ?1
## Hornet Sportabout ? 18.7 ? 8 360.0 175 3.15 3.440 17.02 ?0 ?0 ? ?3 ? ?2
## Valiant ? ? ? ? ? ? 18.1 ? 6 225.0 105 2.76 3.460 20.22 ?1 ?0 ? ?3 ? ?1
## Duster 360 ? ? ? ? ?14.3 ? 8 360.0 245 3.21 3.570 15.84 ?0 ?0 ? ?3 ? ?4
## Merc 240D ? ? ? ? ? 24.4 ? 4 146.7 ?62 3.69 3.190 20.00 ?1 ?0 ? ?4 ? ?2
## Merc 230 ? ? ? ? ? ?22.8 ? 4 140.8 ?95 3.92 3.150 22.90 ?1 ?0 ? ?4 ? ?2
## Merc 280 ? ? ? ? ? ?19.2 ? 6 167.6 123 3.92 3.440 18.30 ?1 ?0 ? ?4 ? ?4
## Merc 280C ? ? ? ? ? 17.8 ? 6 167.6 123 3.92 3.440 18.90 ?1 ?0 ? ?4 ? ?4
## Merc 450SE ? ? ? ? ?16.4 ? 8 275.8 180 3.07 4.070 17.40 ?0 ?0 ? ?3 ? ?3
## Merc 450SL ? ? ? ? ?17.3 ? 8 275.8 180 3.07 3.730 17.60 ?0 ?0 ? ?3 ? ?3
## Merc 450SLC ? ? ? ? 15.2 ? 8 275.8 180 3.07 3.780 18.00 ?0 ?0 ? ?3 ? ?3
## Cadillac Fleetwood ?10.4 ? 8 472.0 205 2.93 5.250 17.98 ?0 ?0 ? ?3 ? ?4
## Lincoln Continental 10.4 ? 8 460.0 215 3.00 5.424 17.82 ?0 ?0 ? ?3 ? ?4
## Chrysler Imperial ? 14.7 ? 8 440.0 230 3.23 5.345 17.42 ?0 ?0 ? ?3 ? ?4
## Fiat 128 ? ? ? ? ? ?32.4 ? 4 ?78.7 ?66 4.08 2.200 19.47 ?1 ?1 ? ?4 ? ?1
## Honda Civic ? ? ? ? 30.4 ? 4 ?75.7 ?52 4.93 1.615 18.52 ?1 ?1 ? ?4 ? ?2
## Toyota Corolla ? ? ?33.9 ? 4 ?71.1 ?65 4.22 1.835 19.90 ?1 ?1 ? ?4 ? ?1
## Toyota Corona ? ? ? 21.5 ? 4 120.1 ?97 3.70 2.465 20.01 ?1 ?0 ? ?3 ? ?1
## Dodge Challenger ? ?15.5 ? 8 318.0 150 2.76 3.520 16.87 ?0 ?0 ? ?3 ? ?2
## AMC Javelin ? ? ? ? 15.2 ? 8 304.0 150 3.15 3.435 17.30 ?0 ?0 ? ?3 ? ?2
## Camaro Z28 ? ? ? ? ?13.3 ? 8 350.0 245 3.73 3.840 15.41 ?0 ?0 ? ?3 ? ?4
## Pontiac Firebird ? ?19.2 ? 8 400.0 175 3.08 3.845 17.05 ?0 ?0 ? ?3 ? ?2
## Fiat X1-9 ? ? ? ? ? 27.3 ? 4 ?79.0 ?66 4.08 1.935 18.90 ?1 ?1 ? ?4 ? ?1
## Porsche 914-2 ? ? ? 26.0 ? 4 120.3 ?91 4.43 2.140 16.70 ?0 ?1 ? ?5 ? ?2
## Lotus Europa ? ? ? ?30.4 ? 4 ?95.1 113 3.77 1.513 16.90 ?1 ?1 ? ?5 ? ?2
## Ford Pantera L ? ? ?15.8 ? 8 351.0 264 4.22 3.170 14.50 ?0 ?1 ? ?5 ? ?4
## Ferrari Dino ? ? ? ?19.7 ? 6 145.0 175 3.62 2.770 15.50 ?0 ?1 ? ?5 ? ?6
## Maserati Bora ? ? ? 15.0 ? 8 301.0 335 3.54 3.570 14.60 ?0 ?1 ? ?5 ? ?8
## Volvo 142E ? ? ? ? ?21.4 ? 4 121.0 109 4.11 2.780 18.60 ?1 ?1 ? ?4 ? ?2summary(mtcars$mpg)## ? ?Min. 1st Qu. ?Median ? ?Mean 3rd Qu. ? ?Max.
## ? 10.40 ? 15.43 ? 19.20 ? 20.09 ? 22.80 ? 33.90plot(mtcars$mpg,mtcars$disp)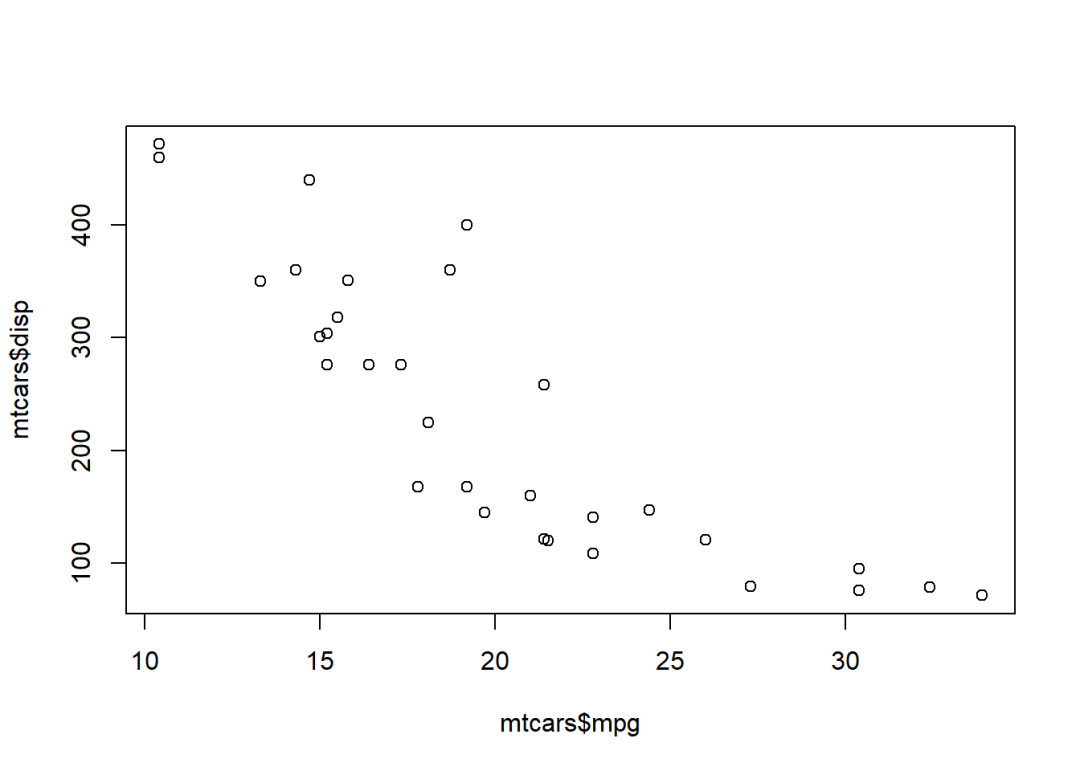
plot(mtcars$mpg,mtcars$wt)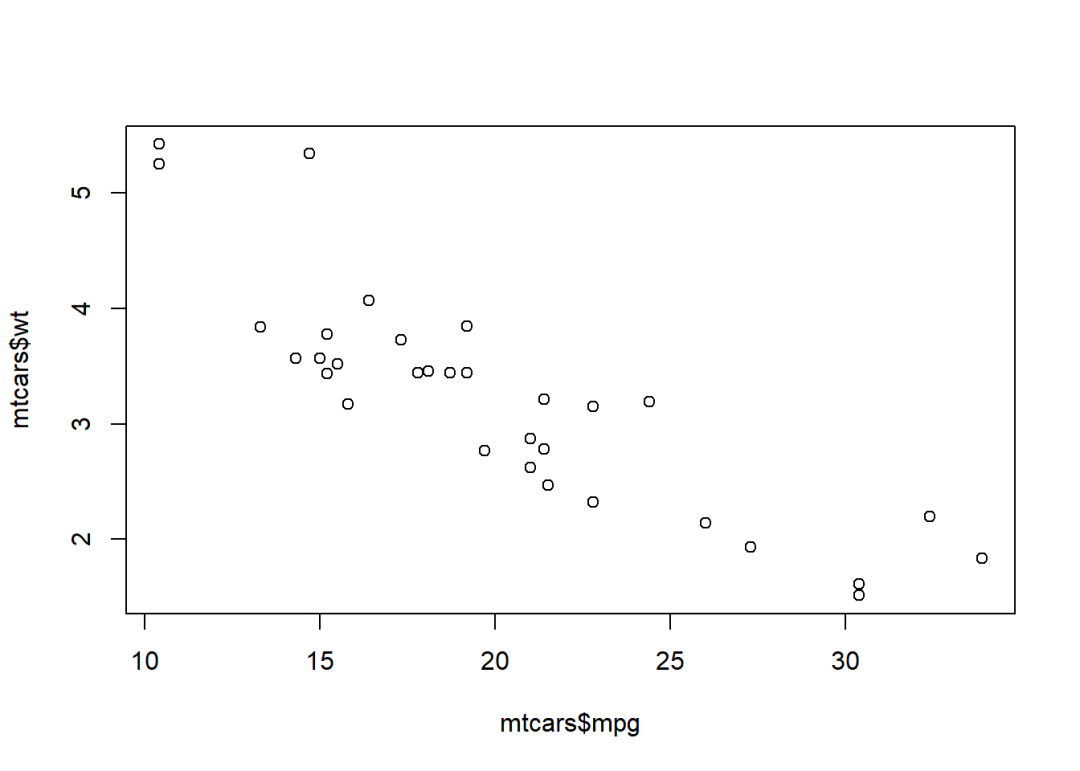
summary()獲取描述性統計量,可以提供最小值、最大值、四分位數和數值型變量的均值,以及因子向量和邏輯型向量的頻數統計等。結果輸出中的1Q和Q3分別為殘差第一四分位數(1Q)和第三分位數(Q3)。
利用with()函數可以簡化為:
with(mtcars,{summary(mpg)plot(mpg,disp)plot(mpg,wt)})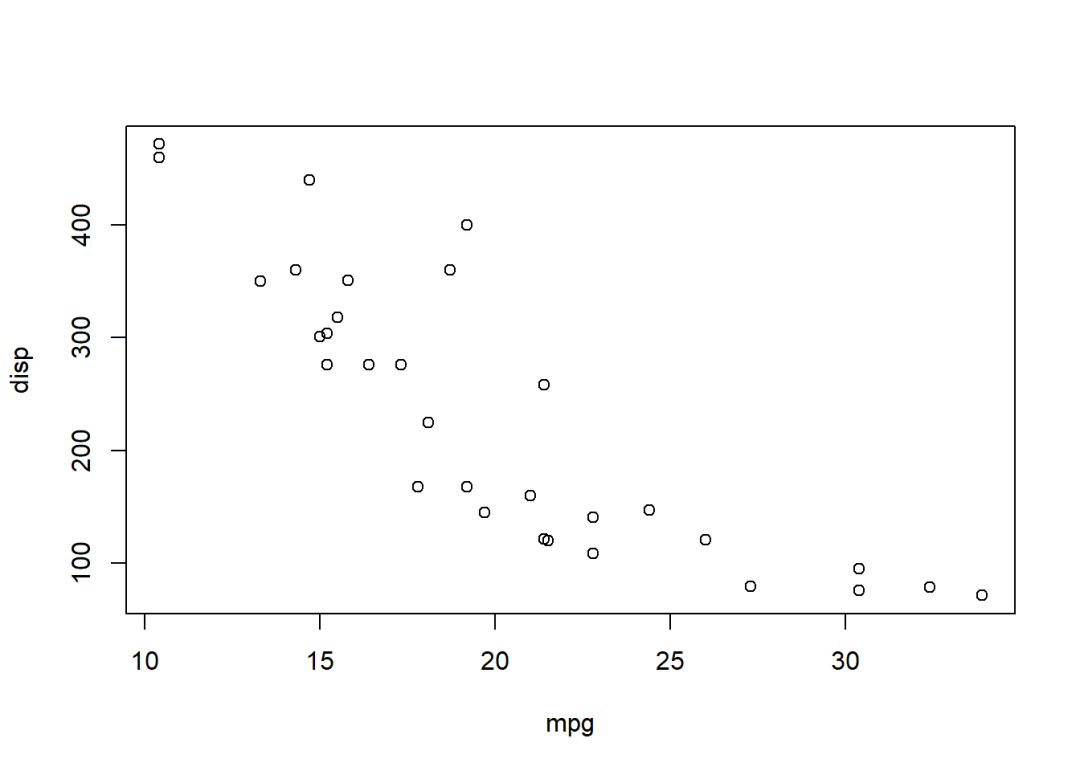
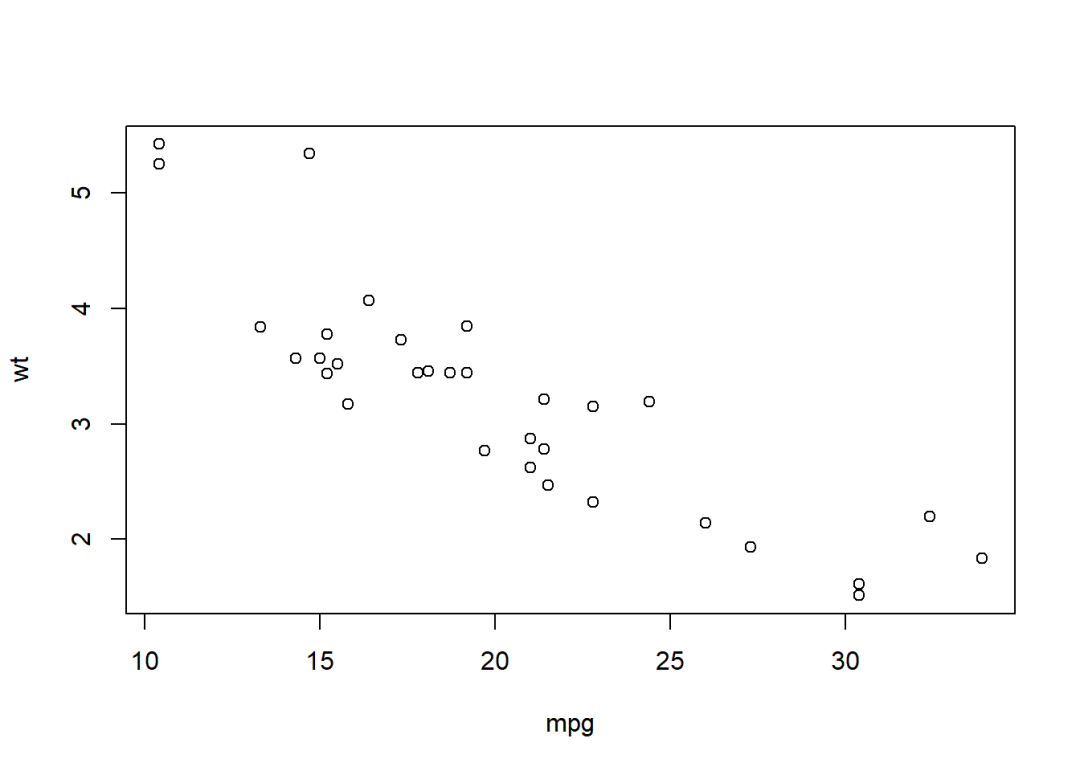
{}中的命令都是針對mtcars執行,如果僅有一條命令,那么{}可省略。
函數with()的局限性在于賦值僅在此函數的括號里生效,例如:
with(mtcars,{stats <- summary(mpg)
stats})## ? ?Min. 1st Qu. ?Median ? ?Mean 3rd Qu. ? ?Max.
## ? 10.40 ? 15.43 ? 19.20 ? 20.09 ? 22.80 ? 33.90stats## Error in eval(expr, envir, enclos): 找不到對象'stats'如果需要創建with()以外存在的對象,可使用特殊賦值符號?<<-替代原來的<- ,即可將對象保存到with()之外的全局環境中,例如:
with(mtcars,{stats <<- summary(mpg)
stats})## ? ?Min. 1st Qu. ?Median ? ?Mean 3rd Qu. ? ?Max.
## ? 10.40 ? 15.43 ? 19.20 ? 20.09 ? 22.80 ? 33.90stats## ? ?Min. 1st Qu. ?Median ? ?Mean 3rd Qu. ? ?Max.
## ? 10.40 ? 15.43 ? 19.20 ? 20.09 ? 22.80 ? 33.902.2.5 因子(factor)
-
2.2.5.1 定義
談因子前首先要對變量進行分類,可以分為:
| 變量分類 | 定義 | 包括 | 具體舉例 |
|---|---|---|---|
| 名義變量(分類變量) nominal variable | 沒有順序之分的分類變量 | 性別,省份,職業、分型等 | Diabetes(Type1、Type2) |
| 順序變量 ordinal variable | 一種順序關系而非數量關系 | 班級,名次,病情等 | Status(poor、improved、excellent) |
| 連續變量 continuous variable | 可呈現為某個范圍內的任意值,并同時表示了順序和數量 | 連續的數值,可以進行求和,平均值等運算 | age(15、21、33) |
其中名義變量和順序變量稱為因子
-
2.2.5.1.1 名義變量作為因子時
函數factor()以一個整數向量的形式存儲類別值,整數的取值范圍是1…k。同時,一個由字符串(原始值)組成的內部向量將映射到這些整數上。
舉例:
diabetes <- c("Type1","Type2","Type1","Type1")
diabetes1 <- factor(diabetes)
str(diabetes)## ?chr [1:4] "Type1" "Type2" "Type1" "Type1"str(diabetes1)## ?Factor w/ 2 levels "Type1","Type2": 1 2 1 1可以看到用factor()將向量存儲為(1,2,1,1),并在內部將其關聯為1=Type1,2=Type2.
-
2.2.5.1.2 順序變量作為因子時
表示順序變量時,要指定ordered=TRUE
status<- c("poor","improved","excellent","poor")
status1 <- factor(status,ordered = TRUE)
str(status)## ?chr [1:4] "poor" "improved" "excellent" "poor"str(status1)## ?Ord.factor w/ 3 levels "excellent"<"improved"<..: 3 2 1 3對于字符型向量,因子的水平(level)默認依字母順序創建,但很少情況是理想的,可以用levels選項覆蓋默認排序,重新排序:
status<- c("poor","improved","excellent","poor")
status2 <- factor(status,ordered = TRUE,levels = c("poor","improved","excellent"))
str(status)## ?chr [1:4] "poor" "improved" "excellent" "poor"str(status2)## ?Ord.factor w/ 3 levels "poor"<"improved"<..: 1 2 3 1這樣排序從原來的3213變成了1231。
數值型變量可以用參數levels和labels來編碼因子?例如,男性被編碼為1,女性被編碼為2:
sex <- c(1,2,2,1)
sex<- factor(sex,levels = c(1,2),labels = c("Male","Female"))
sex## [1] Male ? Female Female Male ?
## Levels: Male Female歸根結底,因子和非因子到底什么區別?我們用一張圖就可以直觀感受?plot函數的數據集是向量的作圖輸出散點圖:
mtcars$cyl## ?[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4plot(mtcars$cyl)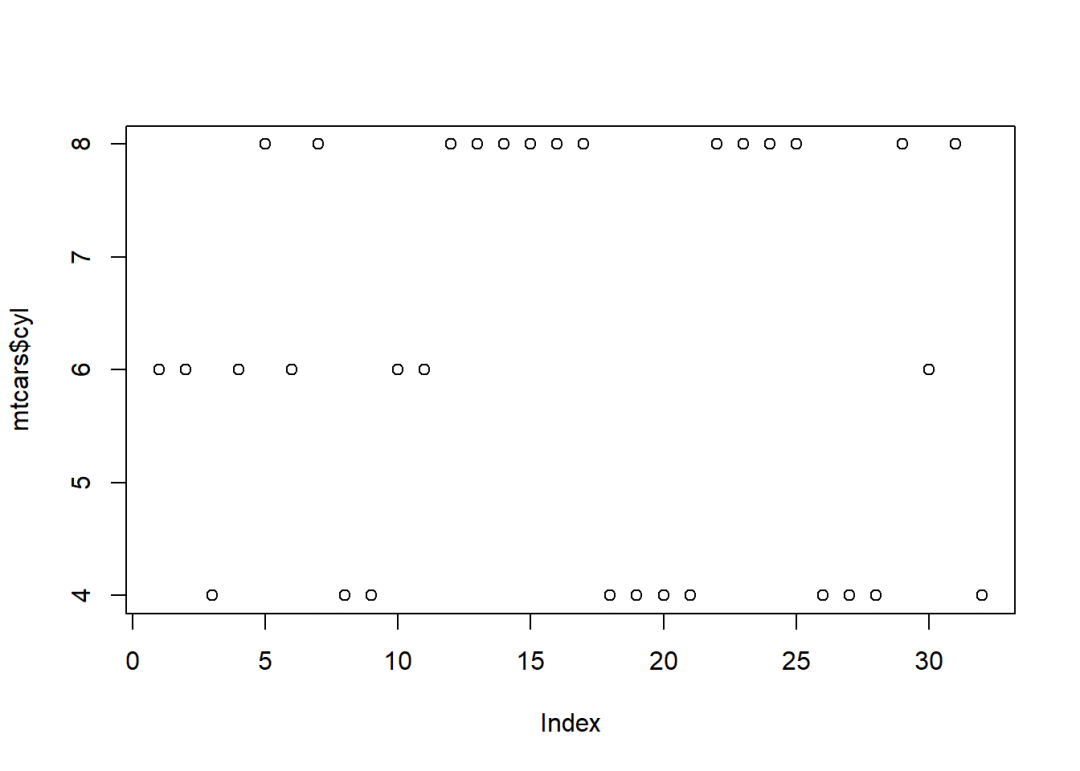
plot函數的數據集是因子的作圖輸出條形圖:
mtcars$cyl## ?[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4mtcars1 <- factor(mtcars$cyl)
plot(mtcars1)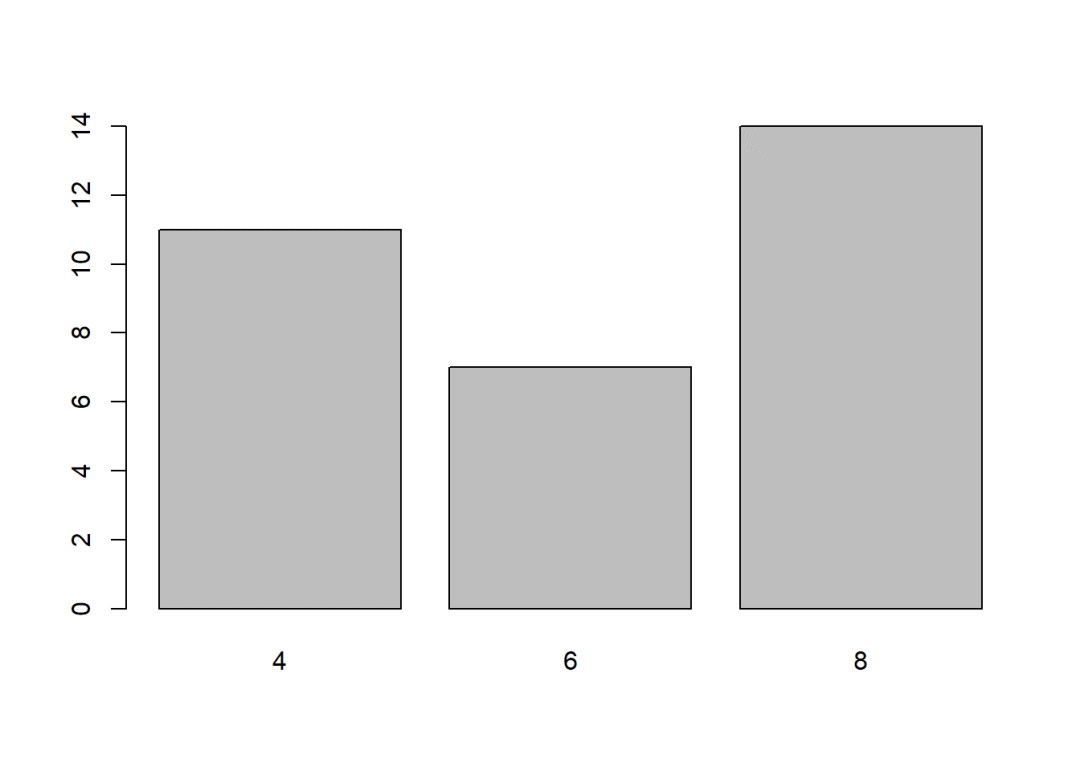
2.2.6 列表(list)
-
2.2.6.1 定義
一些對象(或成分)的有序集合。一個列表中可能包含若干對象(可能無關的)如向量,矩陣,數據框甚至其他列表。
用函數list()創建,也可以對列表中的對象命名:
mylist <- list(object1,object2,...)
mylist <- list(name1=object1,name2=object2,...)-
2.2.6.2 創建一個列表
g <- "My Frist list"
h <- c(25,23,11,13)
j <- matrix(1:10,nrow = 5)
k <- c("one","two","three")
mylist <- list(title=g,ages=h,j,k)
mylist## $title
## [1] "My Frist list"
##
## $ages
## [1] 25 23 11 13
##
## [[3]]
## ? ? ?[,1] [,2]
## [1,] ? ?1 ? ?6
## [2,] ? ?2 ? ?7
## [3,] ? ?3 ? ?8
## [4,] ? ?4 ? ?9
## [5,] ? ?5 ? 10
##
## [[4]]
## [1] "one" ? "two" ? "three"這個列表中包含了字符型、數值型向量,矩陣。
-
2.2.6.3 選取列表中的元素
一般用[[]],雙重方括號加數字或名稱來訪問
mylist[[2]]## [1] 25 23 11 13mylist[["title"]]## [1] "My Frist list"mylist["title"]## $title
## [1] "My Frist list"2.2.7 tibble數據框
-
2.2.7.1 定義
與標準數據框相比,tibble數據框的打印格式更加緊湊。且變量標簽描述了每一列的數據類型。
安裝tibble包:
install.packages("tibble")用函數tibble()或as_tibble()創建
舉例來看:
mtcars## ? ? ? ? ? ? ? ? ? ? ?mpg cyl ?disp ?hp drat ? ?wt ?qsec vs am gear carb
## Mazda RX4 ? ? ? ? ? 21.0 ? 6 160.0 110 3.90 2.620 16.46 ?0 ?1 ? ?4 ? ?4
## Mazda RX4 Wag ? ? ? 21.0 ? 6 160.0 110 3.90 2.875 17.02 ?0 ?1 ? ?4 ? ?4
## Datsun 710 ? ? ? ? ?22.8 ? 4 108.0 ?93 3.85 2.320 18.61 ?1 ?1 ? ?4 ? ?1
## Hornet 4 Drive ? ? ?21.4 ? 6 258.0 110 3.08 3.215 19.44 ?1 ?0 ? ?3 ? ?1
## Hornet Sportabout ? 18.7 ? 8 360.0 175 3.15 3.440 17.02 ?0 ?0 ? ?3 ? ?2
## Valiant ? ? ? ? ? ? 18.1 ? 6 225.0 105 2.76 3.460 20.22 ?1 ?0 ? ?3 ? ?1
## Duster 360 ? ? ? ? ?14.3 ? 8 360.0 245 3.21 3.570 15.84 ?0 ?0 ? ?3 ? ?4
## Merc 240D ? ? ? ? ? 24.4 ? 4 146.7 ?62 3.69 3.190 20.00 ?1 ?0 ? ?4 ? ?2
## Merc 230 ? ? ? ? ? ?22.8 ? 4 140.8 ?95 3.92 3.150 22.90 ?1 ?0 ? ?4 ? ?2
## Merc 280 ? ? ? ? ? ?19.2 ? 6 167.6 123 3.92 3.440 18.30 ?1 ?0 ? ?4 ? ?4
## Merc 280C ? ? ? ? ? 17.8 ? 6 167.6 123 3.92 3.440 18.90 ?1 ?0 ? ?4 ? ?4
## Merc 450SE ? ? ? ? ?16.4 ? 8 275.8 180 3.07 4.070 17.40 ?0 ?0 ? ?3 ? ?3
## Merc 450SL ? ? ? ? ?17.3 ? 8 275.8 180 3.07 3.730 17.60 ?0 ?0 ? ?3 ? ?3
## Merc 450SLC ? ? ? ? 15.2 ? 8 275.8 180 3.07 3.780 18.00 ?0 ?0 ? ?3 ? ?3
## Cadillac Fleetwood ?10.4 ? 8 472.0 205 2.93 5.250 17.98 ?0 ?0 ? ?3 ? ?4
## Lincoln Continental 10.4 ? 8 460.0 215 3.00 5.424 17.82 ?0 ?0 ? ?3 ? ?4
## Chrysler Imperial ? 14.7 ? 8 440.0 230 3.23 5.345 17.42 ?0 ?0 ? ?3 ? ?4
## Fiat 128 ? ? ? ? ? ?32.4 ? 4 ?78.7 ?66 4.08 2.200 19.47 ?1 ?1 ? ?4 ? ?1
## Honda Civic ? ? ? ? 30.4 ? 4 ?75.7 ?52 4.93 1.615 18.52 ?1 ?1 ? ?4 ? ?2
## Toyota Corolla ? ? ?33.9 ? 4 ?71.1 ?65 4.22 1.835 19.90 ?1 ?1 ? ?4 ? ?1
## Toyota Corona ? ? ? 21.5 ? 4 120.1 ?97 3.70 2.465 20.01 ?1 ?0 ? ?3 ? ?1
## Dodge Challenger ? ?15.5 ? 8 318.0 150 2.76 3.520 16.87 ?0 ?0 ? ?3 ? ?2
## AMC Javelin ? ? ? ? 15.2 ? 8 304.0 150 3.15 3.435 17.30 ?0 ?0 ? ?3 ? ?2
## Camaro Z28 ? ? ? ? ?13.3 ? 8 350.0 245 3.73 3.840 15.41 ?0 ?0 ? ?3 ? ?4
## Pontiac Firebird ? ?19.2 ? 8 400.0 175 3.08 3.845 17.05 ?0 ?0 ? ?3 ? ?2
## Fiat X1-9 ? ? ? ? ? 27.3 ? 4 ?79.0 ?66 4.08 1.935 18.90 ?1 ?1 ? ?4 ? ?1
## Porsche 914-2 ? ? ? 26.0 ? 4 120.3 ?91 4.43 2.140 16.70 ?0 ?1 ? ?5 ? ?2
## Lotus Europa ? ? ? ?30.4 ? 4 ?95.1 113 3.77 1.513 16.90 ?1 ?1 ? ?5 ? ?2
## Ford Pantera L ? ? ?15.8 ? 8 351.0 264 4.22 3.170 14.50 ?0 ?1 ? ?5 ? ?4
## Ferrari Dino ? ? ? ?19.7 ? 6 145.0 175 3.62 2.770 15.50 ?0 ?1 ? ?5 ? ?6
## Maserati Bora ? ? ? 15.0 ? 8 301.0 335 3.54 3.570 14.60 ?0 ?1 ? ?5 ? ?8
## Volvo 142E ? ? ? ? ?21.4 ? 4 121.0 109 4.11 2.780 18.60 ?1 ?1 ? ?4 ? ?2library(tibble)
mtcars2 <- tibble(mtcars)
mtcars2## # A tibble: 32 × 11
## ? ? ?mpg ? cyl ?disp ? ?hp ?drat ? ?wt ?qsec ? ?vs ? ?am ?gear ?carb
## ? ?<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## ?1 ?21 ? ? ? 6 ?160 ? ?110 ?3.9 ? 2.62 ?16.5 ? ? 0 ? ? 1 ? ? 4 ? ? 4
## ?2 ?21 ? ? ? 6 ?160 ? ?110 ?3.9 ? 2.88 ?17.0 ? ? 0 ? ? 1 ? ? 4 ? ? 4
## ?3 ?22.8 ? ? 4 ?108 ? ? 93 ?3.85 ?2.32 ?18.6 ? ? 1 ? ? 1 ? ? 4 ? ? 1
## ?4 ?21.4 ? ? 6 ?258 ? ?110 ?3.08 ?3.22 ?19.4 ? ? 1 ? ? 0 ? ? 3 ? ? 1
## ?5 ?18.7 ? ? 8 ?360 ? ?175 ?3.15 ?3.44 ?17.0 ? ? 0 ? ? 0 ? ? 3 ? ? 2
## ?6 ?18.1 ? ? 6 ?225 ? ?105 ?2.76 ?3.46 ?20.2 ? ? 1 ? ? 0 ? ? 3 ? ? 1
## ?7 ?14.3 ? ? 8 ?360 ? ?245 ?3.21 ?3.57 ?15.8 ? ? 0 ? ? 0 ? ? 3 ? ? 4
## ?8 ?24.4 ? ? 4 ?147. ? ?62 ?3.69 ?3.19 ?20 ? ? ? 1 ? ? 0 ? ? 4 ? ? 2
## ?9 ?22.8 ? ? 4 ?141. ? ?95 ?3.92 ?3.15 ?22.9 ? ? 1 ? ? 0 ? ? 4 ? ? 2
## 10 ?19.2 ? ? 6 ?168. ? 123 ?3.92 ?3.44 ?18.3 ? ? 1 ? ? 0 ? ? 4 ? ? 4
## # ? 22 more rows這里變量名下的<>中的內容代表變量類型:
| 縮寫 | 變量類型 |
|---|---|
| int | 整數型變量 |
| dbl | 雙精度浮點數型變量,或稱實數 |
| chr | 字符向量,或稱字符串 |
| dttm | 日期時間(日期+ 時間)型變量 |
| date | 日期型變量 |
| lgl | 邏輯型變量,是一個僅包括TRUE 和FALSE 的向量 |
| fctr | 因子,R 用其來表示具有固定數目的值的分類變量 |
可以看到tibble數據框有幾個特點:
1)不支持行名,可以用rownames_to_column()將數據框的行名轉變為變量。
library(tibble)
mtcars2 <- tibble(mtcars)
mtcars2## # A tibble: 32 × 11
## ? ? ?mpg ? cyl ?disp ? ?hp ?drat ? ?wt ?qsec ? ?vs ? ?am ?gear ?carb
## ? ?<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## ?1 ?21 ? ? ? 6 ?160 ? ?110 ?3.9 ? 2.62 ?16.5 ? ? 0 ? ? 1 ? ? 4 ? ? 4
## ?2 ?21 ? ? ? 6 ?160 ? ?110 ?3.9 ? 2.88 ?17.0 ? ? 0 ? ? 1 ? ? 4 ? ? 4
## ?3 ?22.8 ? ? 4 ?108 ? ? 93 ?3.85 ?2.32 ?18.6 ? ? 1 ? ? 1 ? ? 4 ? ? 1
## ?4 ?21.4 ? ? 6 ?258 ? ?110 ?3.08 ?3.22 ?19.4 ? ? 1 ? ? 0 ? ? 3 ? ? 1
## ?5 ?18.7 ? ? 8 ?360 ? ?175 ?3.15 ?3.44 ?17.0 ? ? 0 ? ? 0 ? ? 3 ? ? 2
## ?6 ?18.1 ? ? 6 ?225 ? ?105 ?2.76 ?3.46 ?20.2 ? ? 1 ? ? 0 ? ? 3 ? ? 1
## ?7 ?14.3 ? ? 8 ?360 ? ?245 ?3.21 ?3.57 ?15.8 ? ? 0 ? ? 0 ? ? 3 ? ? 4
## ?8 ?24.4 ? ? 4 ?147. ? ?62 ?3.69 ?3.19 ?20 ? ? ? 1 ? ? 0 ? ? 4 ? ? 2
## ?9 ?22.8 ? ? 4 ?141. ? ?95 ?3.92 ?3.15 ?22.9 ? ? 1 ? ? 0 ? ? 4 ? ? 2
## 10 ?19.2 ? ? 6 ?168. ? 123 ?3.92 ?3.44 ?18.3 ? ? 1 ? ? 0 ? ? 4 ? ? 4
## # ? 22 more rowsrownames_to_column(mtcars2)## # A tibble: 32 × 12
## ? ?rowname ? mpg ? cyl ?disp ? ?hp ?drat ? ?wt ?qsec ? ?vs ? ?am ?gear ?carb
## ? ?<chr> ? <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## ?1 1 ? ? ? ?21 ? ? ? 6 ?160 ? ?110 ?3.9 ? 2.62 ?16.5 ? ? 0 ? ? 1 ? ? 4 ? ? 4
## ?2 2 ? ? ? ?21 ? ? ? 6 ?160 ? ?110 ?3.9 ? 2.88 ?17.0 ? ? 0 ? ? 1 ? ? 4 ? ? 4
## ?3 3 ? ? ? ?22.8 ? ? 4 ?108 ? ? 93 ?3.85 ?2.32 ?18.6 ? ? 1 ? ? 1 ? ? 4 ? ? 1
## ?4 4 ? ? ? ?21.4 ? ? 6 ?258 ? ?110 ?3.08 ?3.22 ?19.4 ? ? 1 ? ? 0 ? ? 3 ? ? 1
## ?5 5 ? ? ? ?18.7 ? ? 8 ?360 ? ?175 ?3.15 ?3.44 ?17.0 ? ? 0 ? ? 0 ? ? 3 ? ? 2
## ?6 6 ? ? ? ?18.1 ? ? 6 ?225 ? ?105 ?2.76 ?3.46 ?20.2 ? ? 1 ? ? 0 ? ? 3 ? ? 1
## ?7 7 ? ? ? ?14.3 ? ? 8 ?360 ? ?245 ?3.21 ?3.57 ?15.8 ? ? 0 ? ? 0 ? ? 3 ? ? 4
## ?8 8 ? ? ? ?24.4 ? ? 4 ?147. ? ?62 ?3.69 ?3.19 ?20 ? ? ? 1 ? ? 0 ? ? 4 ? ? 2
## ?9 9 ? ? ? ?22.8 ? ? 4 ?141. ? ?95 ?3.92 ?3.15 ?22.9 ? ? 1 ? ? 0 ? ? 4 ? ? 2
## 10 10 ? ? ? 19.2 ? ? 6 ?168. ? 123 ?3.92 ?3.44 ?18.3 ? ? 1 ? ? 0 ? ? 4 ? ? 4
## # ? 22 more rows2)不會更改變量的名稱。例如導入的數據集中有一變量名為last dance,在R中變量名中不得有空格,因此普通數據集函數會將其改為last.dance,而tibble數據框會保留這樣的命名,并用反引號(last dance)使變量名在語法上正確。
3)tibble數據框取子集總是返回一個tibble數據框。
例如,普通的數據框取子集時一般返回向量,除非加上drop=FALSE,才會以列表的形式返回:
mtcars[,"mpg"]## ?[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
## [16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
## [31] 15.0 21.4mtcars[,"mpg",drop=FALSE]## ? ? ? ? ? ? ? ? ? ? ?mpg
## Mazda RX4 ? ? ? ? ? 21.0
## Mazda RX4 Wag ? ? ? 21.0
## Datsun 710 ? ? ? ? ?22.8
## Hornet 4 Drive ? ? ?21.4
## Hornet Sportabout ? 18.7
## Valiant ? ? ? ? ? ? 18.1
## Duster 360 ? ? ? ? ?14.3
## Merc 240D ? ? ? ? ? 24.4
## Merc 230 ? ? ? ? ? ?22.8
## Merc 280 ? ? ? ? ? ?19.2
## Merc 280C ? ? ? ? ? 17.8
## Merc 450SE ? ? ? ? ?16.4
## Merc 450SL ? ? ? ? ?17.3
## Merc 450SLC ? ? ? ? 15.2
## Cadillac Fleetwood ?10.4
## Lincoln Continental 10.4
## Chrysler Imperial ? 14.7
## Fiat 128 ? ? ? ? ? ?32.4
## Honda Civic ? ? ? ? 30.4
## Toyota Corolla ? ? ?33.9
## Toyota Corona ? ? ? 21.5
## Dodge Challenger ? ?15.5
## AMC Javelin ? ? ? ? 15.2
## Camaro Z28 ? ? ? ? ?13.3
## Pontiac Firebird ? ?19.2
## Fiat X1-9 ? ? ? ? ? 27.3
## Porsche 914-2 ? ? ? 26.0
## Lotus Europa ? ? ? ?30.4
## Ford Pantera L ? ? ?15.8
## Ferrari Dino ? ? ? ?19.7
## Maserati Bora ? ? ? 15.0
## Volvo 142E ? ? ? ? ?21.4但在tibble數據框中則可以直接呈現單列的tibble數據框:
mtcars2[,"mpg"]## # A tibble: 32 × 1
## ? ? ?mpg
## ? ?<dbl>
## ?1 ?21 ?
## ?2 ?21 ?
## ?3 ?22.8
## ?4 ?21.4
## ?5 ?18.7
## ?6 ?18.1
## ?7 ?14.3
## ?8 ?24.4
## ?9 ?22.8
## 10 ?19.2
## # ? 22 more rows4)不改變輸入的類型(例如,不能將字符串轉換為因子)。在R4.0.0以前的版本中,函數read.table(),as.data.frame()會默認將字符型數據轉換為因子。AsFactors = FALSE可以取消該默認設置。
2.3 數據輸入
這里介紹2種常用的,分別是從帶分隔符的文本文件導入和從excel導入。
文本文件包括:純文本文件,Markdown文件,HTML文件,XML文件,JSON文件,CSV文件,日志文件,配置文件,腳本文件。
2.3.1 從帶分隔符的文本文件導入數據
2.3.1.1 定義
用函數read.table()來導入,此函數讀入一個表格格式的文件并將其保存為一個數據框。語法:
mydataframe <- read.table(file,options)其中,file是一個帶分隔符的ASCII文本文件,options是控制如何處理數據的選項。常見選項有:

以studentgrades.csv的文本文件舉例:
grades <- read.table("studentgrades.csv",header = TRUE,row.names = "studentID",sep = ",")## Warning in read.table("studentgrades.csv", header = TRUE, row.names =
## "studentID", : incomplete final line found by readTableHeader on
## 'studentgrades.csv'grades## ? ?First ? ? ? ? ? Last Math Science Social
## 11 ? Bob ? ? ? ? ?Smith ? 90 ? ? ?80 ? ? 67
## 12 ?Jane ? ? ? ? ?Weary ? 75 ? ? ?NA ? ? 80
## 10 ? Dan "Thornton,III" ? 65 ? ? ?75 ? ? 70
## 40 ?Mary ? ? ?"O'Leary" ? 90 ? ? ?95 ? ? 92studentID現在是行名,不再有標簽,也失去了前置0。
str(grades)## 'data.frame': ? ?4 obs. of ?5 variables:
## ?$ First ?: chr ?"Bob" "Jane" "Dan" "Mary"
## ?$ Last ? : chr ?"Smith" "Weary" "\"Thornton,III\"" "\"O'Leary\""
## ?$ Math ? : int ?90 75 65 90
## ?$ Science: int ?80 NA 75 95
## ?$ Social : int ?67 80 70 92注:對于“Thornton,III”要用雙引號包圍住,否則R會將其讀為2個值而出錯。
我們重新導入上面的數據,并同時為每個變量指定一個類:
grades <- read.table("studentgrades.csv",header = TRUE,row.names = "studentID",sep = ",",colClasses = c("character","character","character","numeric","numeric","numeric"))## Warning in read.table("studentgrades.csv", header = TRUE, row.names =
## "studentID", : incomplete final line found by readTableHeader on
## 'studentgrades.csv'grades## ? ? First ? ? ? ? ? Last Math Science Social
## 011 ? Bob ? ? ? ? ?Smith ? 90 ? ? ?80 ? ? 67
## 012 ?Jane ? ? ? ? ?Weary ? 75 ? ? ?NA ? ? 80
## 010 ? Dan "Thornton,III" ? 65 ? ? ?75 ? ? 70
## 040 ?Mary ? ? ?"O'Leary" ? 90 ? ? ?95 ? ? 92str(grades)## 'data.frame': ? ?4 obs. of ?5 variables:
## ?$ First ?: chr ?"Bob" "Jane" "Dan" "Mary"
## ?$ Last ? : chr ?"Smith" "Weary" "\"Thornton,III\"" "\"O'Leary\""
## ?$ Math ? : num ?90 75 65 90
## ?$ Science: num ?80 NA 75 95
## ?$ Social : num ?67 80 70 92可以看到行名保留了前綴0
其他讀取方法:
1)read.csv():默認header=T,sep=“,”
2)read.delim():默認默認header=T,sep=“
3)readr包:其中主要函數是read.delim(),輔助函數為read.csv()和read.tsv(),其優點是速度快,且可以推測每一列的數據類型。
2.3.2 導入Excel數據
2.3.2.1 方法
1)將excel數據導出為一個csv文件后,使用前面方法進行導入
2)用readxl包直接導入excel工作表:readxl可以用來讀取.xls和.xlsx版本的excel文件
語法:
read_table(file,n)file是excel工作簿的所在路徑,n則為導入的工作表序號,工作表的第一行為變量名。
例如:
install.packages("readxl")library(readxl)## Warning: 程輯包'readxl'是用R版本4.3.2 來建造的a <- "./test.xlsx"
mytest <- read_excel(a,2)
mytest## # A tibble: 8 × 2
## ? `動物\r\n編號` `體重(g)`
## ? <chr> ? ? ? ? ? ? ? ?<dbl>
## 1 A71 ? ? ? ? ? ? ? ? ? 18.7
## 2 A74 ? ? ? ? ? ? ? ? ? 18.8
## 3 A79 ? ? ? ? ? ? ? ? ? 18 ?
## 4 A80 ? ? ? ? ? ? ? ? ? 18.5
## 5 A81 ? ? ? ? ? ? ? ? ? 18.7
## 6 A82 ? ? ? ? ? ? ? ? ? 18.3
## 7 A83 ? ? ? ? ? ? ? ? ? 20 ?
## 8 A84 ? ? ? ? ? ? ? ? ? 17.5read_excel()可以指定某個單元區域(range=“mysheet!B2:G14”),例如:
a <- "./test.xlsx"
mytest1 <- read_excel(a,2,range ="A3:B8" )
mytest1## # A tibble: 5 × 2
## ? A74 ? `18.8`
## ? <chr> ?<dbl>
## 1 A79 ? ? 18 ?
## 2 A80 ? ? 18.5
## 3 A81 ? ? 18.7
## 4 A82 ? ? 18.3
## 5 A83 ? ? 20另外,xlsx,XLConnect,openxlsx包也可以處理excel文件。
往期回顧
R語言基礎學習手冊
下載、安裝
![nssctf第二題[SWPUCTF 2021 新生賽]簡簡單單的邏輯](http://pic.xiahunao.cn/nssctf第二題[SWPUCTF 2021 新生賽]簡簡單單的邏輯)
)

Java/python/JavaScript/C++/C語言/GO六種最佳實現)








 的陷阱)


![BUUCTF[ACTF2020 新生賽]Include 1題解](http://pic.xiahunao.cn/BUUCTF[ACTF2020 新生賽]Include 1題解)

. 引用作為函數參數的使用)

