帶你從不一樣的視角綜合認識交叉熵損失,閱讀這篇文章,幫你建立其分類問題,對比學習,行人重識別,人臉識別等問題的聯系,閱讀這篇文章相信對你閱讀各種底層深度學習論文有幫助。
引言
1. 重新理解全連接層:不只是線性變換
1.1 全連接層的雙重身份
1.2 幾何直覺:相似度計算
1.2.1 輸入特征矩陣 A(上左圖)
1.2.2. 類別原型矩陣 B(上右圖)
1.2.3. 相似度矩陣 X = A·B(下圖)
1.2.4 幾何解釋
幾何解釋兩向量夾角θ的余弦值即為相似度:?編輯
1.3 分類的本質目標
2. 從損失函數設計需求到交叉熵
2.1 損失函數的設計原則
2.2 候選函數分析
?2.3 Softmax交叉熵損失函數
2.4 對交叉熵損失的深度解釋?
2.4.1 梯度下降法
2.4.2 幾何解釋:
2.4.3 概率空間幾何解釋
2.4.4 海森矩陣與凸性分析
2.4.5 信息幾何視角
2.4.6 梯度行為的深入分析
2.5 簡單例子
3. 交叉熵的數值穩定性
3.1 數值不穩定的根本原因
3.1.1 理論分析
3.1.2 Softmax函數的數值問題
3.2 數值不穩定常見的PyTorch報錯原因
3.2.1 數值溢出錯誤
3.2.2 梯度爆炸/消失
3.2.3 類別標簽未定義錯誤
3.2.4 維度不匹配錯誤
3.3 數值不穩定的解決方案
3.3.1 使用數值穩定的實現
3.3.2 避免不穩定的做法
3.3.4 梯度裁剪
4. 對比學習中的交叉熵公式變體
4.1 重新審視分類:從原型對比到樣本對比
4.1.1 分類任務的對比本質
4.1.2 從固定原型到動態樣本
4.1.3 交叉熵的自然延伸
4.2 InfoNCE
4.2.1 從分類交叉熵到InfoNCE
4.2.2 溫度參數τ的交叉熵理解
4.2.3 為什么使用 InfoNCE 進行大規模數據訓練?
1.?類別爆炸問題
2.?負樣本代替類別原型
3.?負樣本過多但可采樣處理
4.?端到端優化相似性度量
5.?適用于自監督與弱監督學習
4.3 監督對比學習:多正樣本的交叉熵擴展
4.3.1 從單一正確答案到多個正確答案
4.3.2 多標簽交叉熵的自然擴展
4.4 Circle Loss:重新參數化的交叉熵
4.4.1 從歐氏距離到余弦相似度
4.4.2 隱藏的二分類交叉熵結構
4.4.3 動態權重的交叉熵解釋
4.5 Triplet Loss
4.6 ?小結
引言
當我們面對一個分類問題時,本質上是在高維特征空間中尋找合適的決策邊界。神經網絡通過多層特征提取,最終需要在最后一層做出分類決策。這個決策過程的核心就是全連接層+Softmax+交叉熵損失的組合。它不僅僅是數學公式,更是一個幾何上的相似度匹配過程。
交叉熵損失函數(Cross-Entropy Loss)是深度學習中最重要的損失函數之一,幾乎所有的分類任務都會用到它。本文深入探討其背后的幾何直覺、工程實現和現代應用。我想從實際寫代碼的角度來寫一篇關于交叉熵的深入理解,可能與大多數介紹交叉熵的文字不同,但對于實際的代碼編寫尤其是理解各種復雜的交叉熵變體有一定幫助。
1. 重新理解全連接層:不只是線性變換
在深入交叉熵之前,我們可以重新認識下分類網絡的最后一層——全連接層。
1.1 全連接層的雙重身份
假設我們有一個分類網絡,輸入batch_size為b的圖片,網絡輸出特征矩陣A ∈ R^(b×f),其中f是特征維度。全連接層的參數矩陣B ∈ R^(f×n),n是類別數。
# 偽代碼示例
features = backbone(images) # A: [batch_size, feature_dim]
logits = fc_layer(features) # X = A @ B: [batch_size, num_classes]另一個視角的理解:矩陣B不僅僅是一個線性變換的參數,它也可以看坐上是一個分類器,存儲著各個類別的典型特征向量。全連接層的權重矩陣B實際上存儲了每個類別的"原型特征"。當我們計算時,實際上是在計算第i個樣本與第j個類別原型的內積相似度。
- A[i]:第i個樣本的特征向量
- B[:, j]:第j個類別的典型特征向量
- X[i, j] = A[i] · B[:, j]:第i個樣本與第j個類別的相似度
1.2 幾何直覺:相似度計算
如果我們對特征A和分類器B都進行L2歸一化:
A_norm = F.normalize(A, dim=1) # 樣本特征歸一化
B_norm = F.normalize(B, dim=0) # 類別特征歸一化
X = A_norm @ B_norm # 余弦相似度矩陣此時,X[i, j]就是第i個樣本與第j個類別的余弦相似度,取值范圍為[-1, 1]。
輸入特征矩陣 A (b×f) 類別原型矩陣 B (f×n)[A?? A?? ... A?f] [B?? B?? ... B?n][A?? A?? ... A?f] [B?? B?? ... B?n][ ... ... ... ...] × [ ... ... ... ...][Ab? Ab? ... Abf] [Bf? Bf? ... Bfn]│ │└─────────┬───────────┘↓相似度矩陣 X = A·B (b×n)[X?? X?? ... X?n][X?? X?? ... X?n][ ... ... ... ...][Xb? Xb? ... Xbn]其中 X[i,j] = A[i]·B[:,j] = ‖A[i]‖‖B[:,j]‖cosθ直觀圖解:
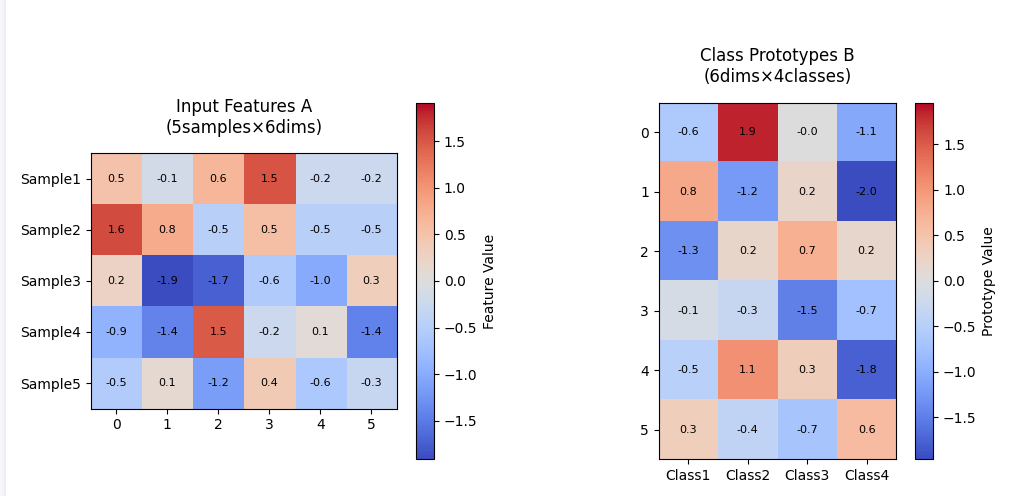
1.2.1 輸入特征矩陣 A(上左圖)
-
數據結構
-
行(S1-S5):5個樣本的特征向量
-
列(F1-F6):6維特征空間
-
示例值范圍:-1.5 ~ +1.5(隨機生成)
-
-
關鍵說明
-
顏色映射:
🔵 藍色 → 負值特征(如F2列S3樣本的-1.0)
🔴 紅色 → 正值特征(如F5列S1樣本的+1.3)
? 白色 → 接近零的值(如F3列S2樣本的0.1) -
物理意義:展示原始數據經過神經網絡提取后的特征分布
-
1.2.2. 類別原型矩陣 B(上右圖)
-
核心概念
-
列向量(C1-C4):每個類別對應的"典型特征模板"
-
行方向:與輸入特征維度完全對齊(F1-F6)
-
-
學習機制
-
訓練過程中,B矩陣通過梯度下降自動更新
-
例如C3列的F4特征值為+1.2 → 表示該類在F4維度有強正相關性
-
可視化價值:直接觀察模型學到的類別判別特征
-
1.2.3. 相似度矩陣 X = A·B(下圖)
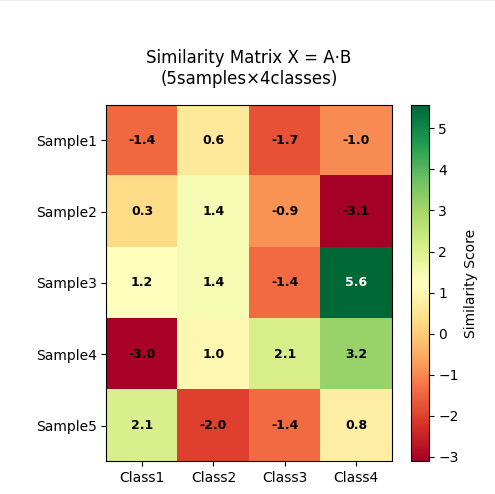
-
計算原理
?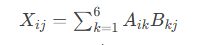
-
每個元素表示樣本與類別的匹配得分
-
-
決策解讀
-
顏色編碼:
🟢 深綠 → 高相似度(如S4行C3列的2.8分)
🟡 黃色 → 中等相似度(如S2行C1列的0.5分)
🔴 紅色 → 低相似度(如S5行C4列的-1.2分) -
分類規則:每行取最大值所在列(如S1應歸為C2類)
-
1.2.4 幾何解釋
想象在一個3D特征空間中:
- 每個樣本是空間中的一個點
- 每個類別原型是從原點出發的一個向量
- 內積
衡量樣本向量與類別向量的"對齊程度"
類別A原型 ↗| θ| ←── 夾角越小,相似度越高|
樣本點 ----+在機器學習中,當對特征向量A和B進行L2歸一化處理后,它們的相似度度量即等價于余弦相似度:sim(A,B)=cosθ,其中θ表示兩個向量之間的夾角。深度神經網絡的核心目標在于學習能夠有效表征樣本本質特征的特征向量空間,而分類層中的權重向量則可視為各類別的原型表征(prototype representation)。通過設計適當的損失函數,模型能夠優化網絡參數,使得在特征空間中:1)樣本特征向量與其對應類別原型的相似度最大化;2)與其它類別原型的相似度最小化。這種優化過程實質上是在構建一個具有良好判別性的特征空間幾何結構,其中類內樣本緊湊聚集在其類別原型周圍,而不同類別的原型則保持足夠的分離度。
這種可視化結果見下圖
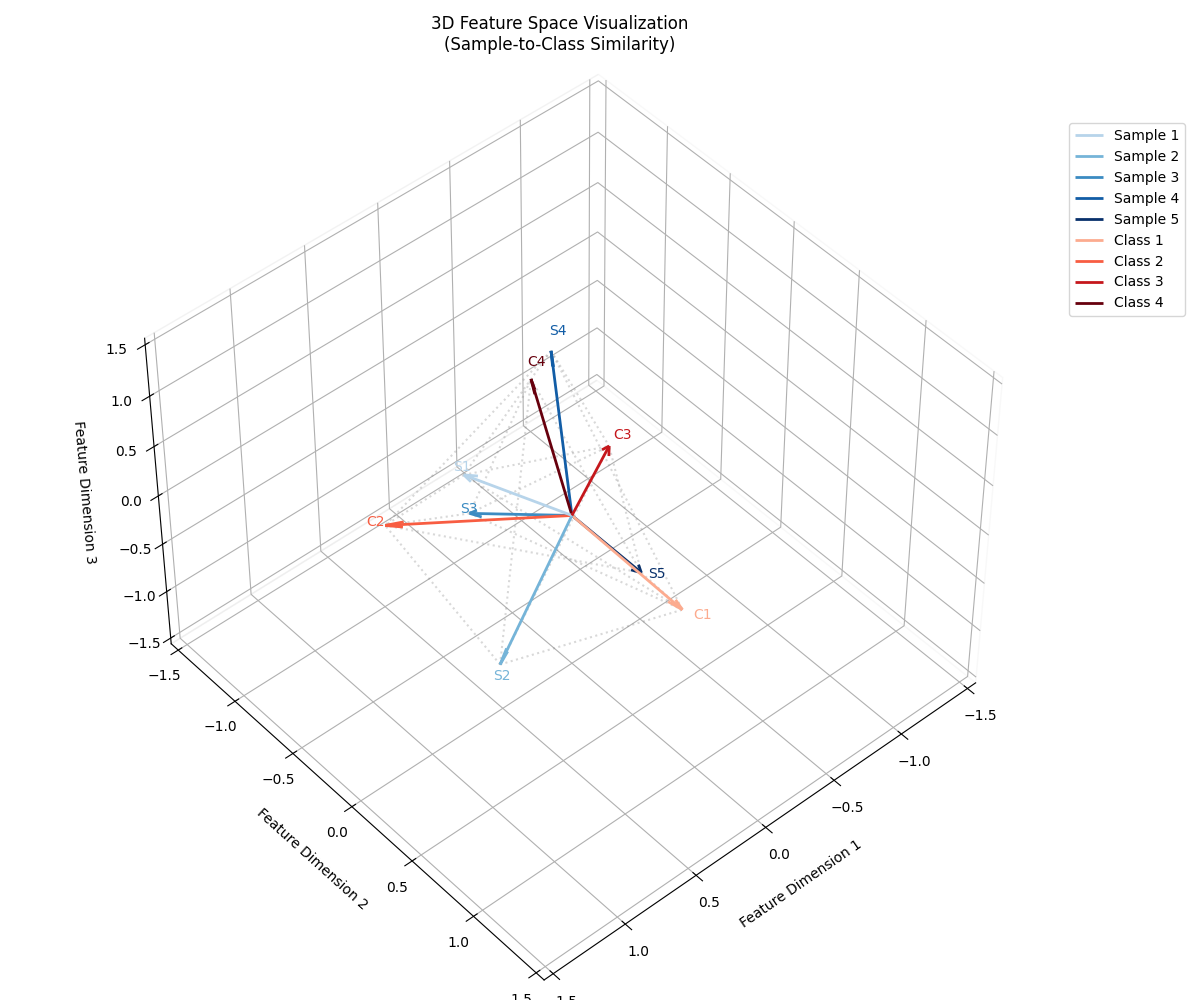
-
可視化要素
-
箭頭起點:坐標原點 (0,0,0)
-
箭頭方向:樣本在3D特征空間的投影(取前3維)
-
-
歸一化處理
S2向量=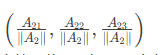
所有向量長度統一為1,便于觀察角度關系
幾何解釋
兩向量夾角θ的余弦值即為相似度: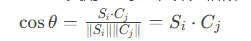
-
-
強匹配:虛線短且夾角小 → 高置信度分類
-
弱匹配:虛線長且夾角大 → 可能分類錯誤
-
對抗情況:夾角>90° → 負相關(需梯度修正)
-
-
訓練目標
通過損失函數迫使:-
同類樣本-原型夾角 → 0°
-
異類樣本-原型夾角 → 180°
-
1.3 分類的本質目標
對于分類任務,我們希望:
- ?正樣本相似度最大?:對于第?
i?個樣本(真實類別為?y_i),X[i,yi?]?應該是?X[i,:]?中的最大值。 - ?負樣本相似度非最大?:不強制要求其他類別的相似度很小,只要它們不超過正樣本的相似度即可。
?數學表達?:
![]()
這一目標將指導我們設計損失函數(如交叉熵損失),通過優化各中間矩陣來實現分類。?
2. 從損失函數設計需求到交叉熵
2.1 損失函數的設計原則
一個好的分類損失函數應該滿足:
- 區分正確與錯誤:分類正確時損失小,錯誤時損失大
- 反映錯誤程度:預測置信度越低,損失越大
- 提供合適梯度:在不同錯誤程度下提供不同強度的梯度信號
2.2 候選函數分析
假設某個樣本屬于類別0,模型預測它屬于類別0的概率為p,我們需要一個關于p的損失函數。
候選函數比較:
| 函數 | 表達式 | p=0.1時損失 | p=0.01時損失 | 梯度表達式 | 梯度特性 |
|---|---|---|---|---|---|
| 1-p | 1?p | 0.9 | 0.99 | ?1 | 恒定梯度 |
| exp(-p) | e?p | 0.905 | 0.990 | ?e?p | 衰減梯度 |
| -log(p) | ?lnp | 2.30 | 4.61 | ?1/p | 自適應梯度 |
-log(p)的優勢:
- 當p → 0時,損失 → ∞,提供強烈的糾正信號
- 當p → 1時,損失 → 0,符合預期
- 梯度為-1/p,預測越錯梯度越大
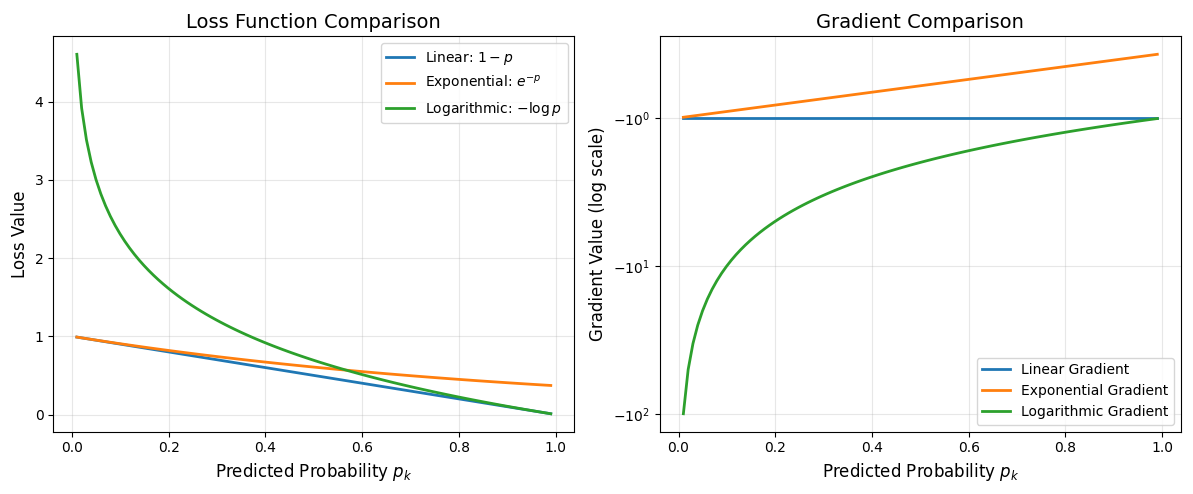
?2.3 Softmax交叉熵損失函數
在全連接層的輸出中,我們得到了一個相似度矩陣?X其中?表示第?i個樣本與第?j個類別的相似度,然而,相似度的值范圍可能很大(尤其是未歸一化時),直接用于損失計算會導致數值不穩定。因此,我們需要將相似度轉換為概率分布。
Softmax函數的作用正是將相似度映射為概率分布:

Softmax通過指數函數放大相似度差異,再歸一化,使得最大相似度對應的概率接近1,其余接近0。這種特性非常適合分類任務。
?交叉熵用于衡量模型預測概率分布?P?與真實標簽分布?Y?的差異,原始的交叉熵損失定義如下
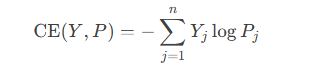
對于Softmax交叉熵損失:
其中: -是logits(未歸一化的模型輸出) -
是真實類別(one-hot編碼) -
是softmax概率
梯度推導:
第一項梯度:
第二項梯度:
合并梯度:
矩陣形式:
?
其中,? -
是one-hot標簽向量
?梯度解釋:
|(真實類別) |
| 預測概率
越接近1,梯度越小 | |
(其他類別) |
越大,梯度越大 |
在反向傳播中:
? ? ? ? ? ? ? ? ?
2.4 對交叉熵損失的深度解釋?
2.4.1 梯度下降法
? ? 從最速下降法的角度看,真實類別方向,?因為
,所以
,梯度始終為負值,負梯度方向:
,意味著需要增大
,:
,
為學習率。?? - 當預測概率
較小時(如0.2),梯度
→ 大幅增加
,當
時,梯度
→ 停止更新。
? ? 對?(
)的梯度,
,
,則起到減小錯誤類別的logit值的作用。
是logits向量
中對應真實類別的分量:
-:模型最后一層的原始輸出(未歸一化)
-
-
? 為什么需要增大
| 數學機制 | 實際影響 | 理論保證 |
|----------------------------|--------------|-------------------|
|? ? ? ? | 增大分子 | 單調遞增函數 |
|| 提高
? ? | 概率歸一化 |
|| 降低損失 | 極大似然估計 |
舉個例子:
假設:
- 當前logits:(3分類)
- 真實類別
- 計算得softmax:
梯度計算:
更新過程():
X_new = [2.0 - 0.1*(-0.35),
1.0 - 0.1*0.24,
0.5 - 0.1*0.11]
= [2.035, 0.976, 0.489]可見:
- (第一個元素)確實增大,(因為它的真實類別是第0類)
- 其他減小
由此softmax起到了預期的作用。
2.4.2 幾何解釋:
回顧交叉熵的原始定義為:
梯度為:?
-
正樣本梯度:Pk?1(負值,推動增加?Xy?)
-
負樣本梯度:Pk?(正值,推動減少?Xk?)
廣義的交叉熵的矩陣計算示意圖如下,第一列表示真實的標簽值Y,它是一個分布,即當前樣本屬于各個類別的概率(與硬分類不同,它在許多場景中是有用的),第二列P是當前樣本經過神經網絡和全連接層后預測的類別的概率(softmax結果),第3列為Y*log(Pju)的計算值。
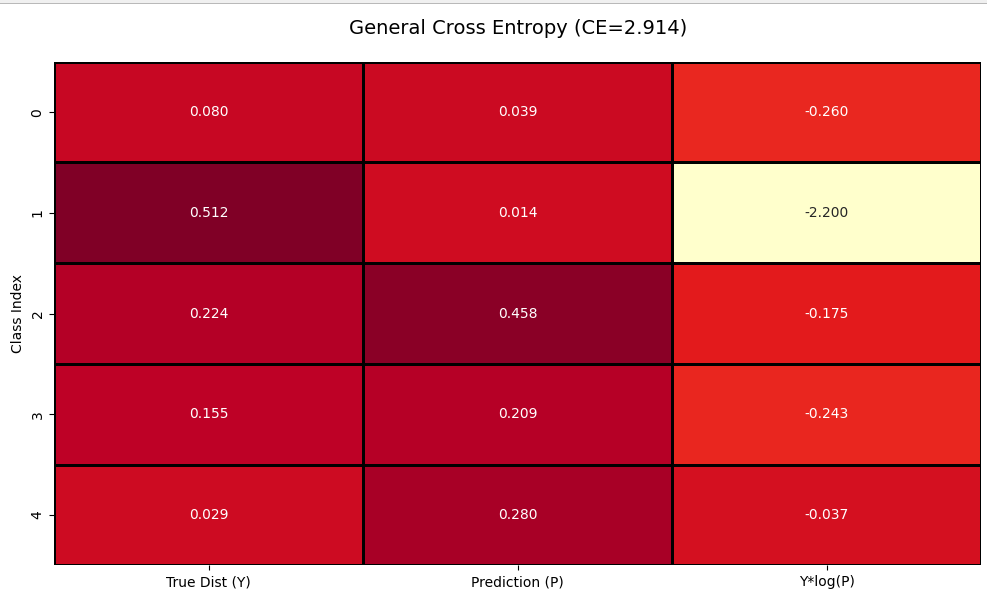
? 在上面的定義中,真實標簽分布?Y 不是非0即1的,這樣對于每個預測標簽都需要算損失。
它的一個經典應用就是平滑標簽的交叉熵損失,在非監督學習領域,由于標簽存在噪聲,往往使用平滑的標簽,效果圖如下:
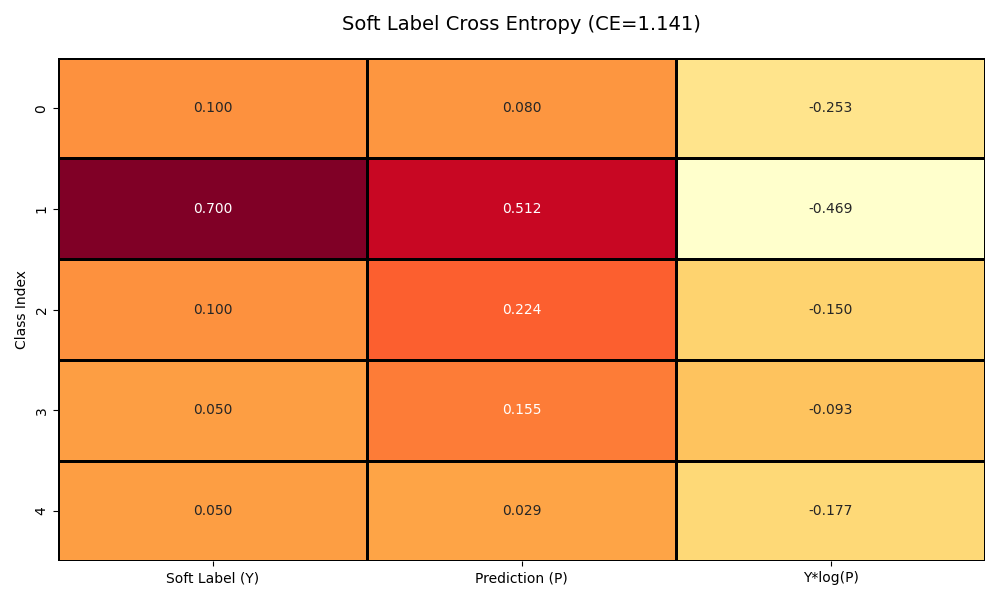
? 而在一般情況下,我們往往使用的是硬標簽損失,而對于硬標簽(one-hot編碼),真實分布?Y?僅在真實類別位置為1,其余為0。由于?Y是one-hot向量,實際計算簡化為:

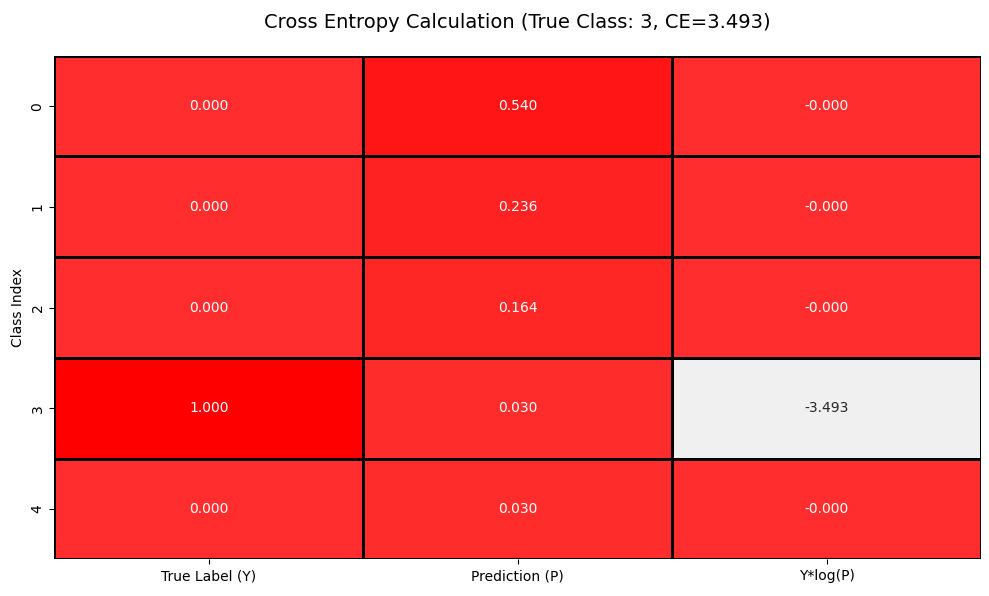
可以觀察到它的計算發生了簡化。
我們總結下交叉熵計算流程:
-
輸出數據經過神經網絡得到每個樣本的特征向量Feature
-
特征向量與全連接層進行矩陣乘法得到相似度矩陣?X(樣本與類別的相似度)。
-
Softmax將?X?轉換為概率分布?P。
-
交叉熵衡量?P?與真實分布?Y?的差異。
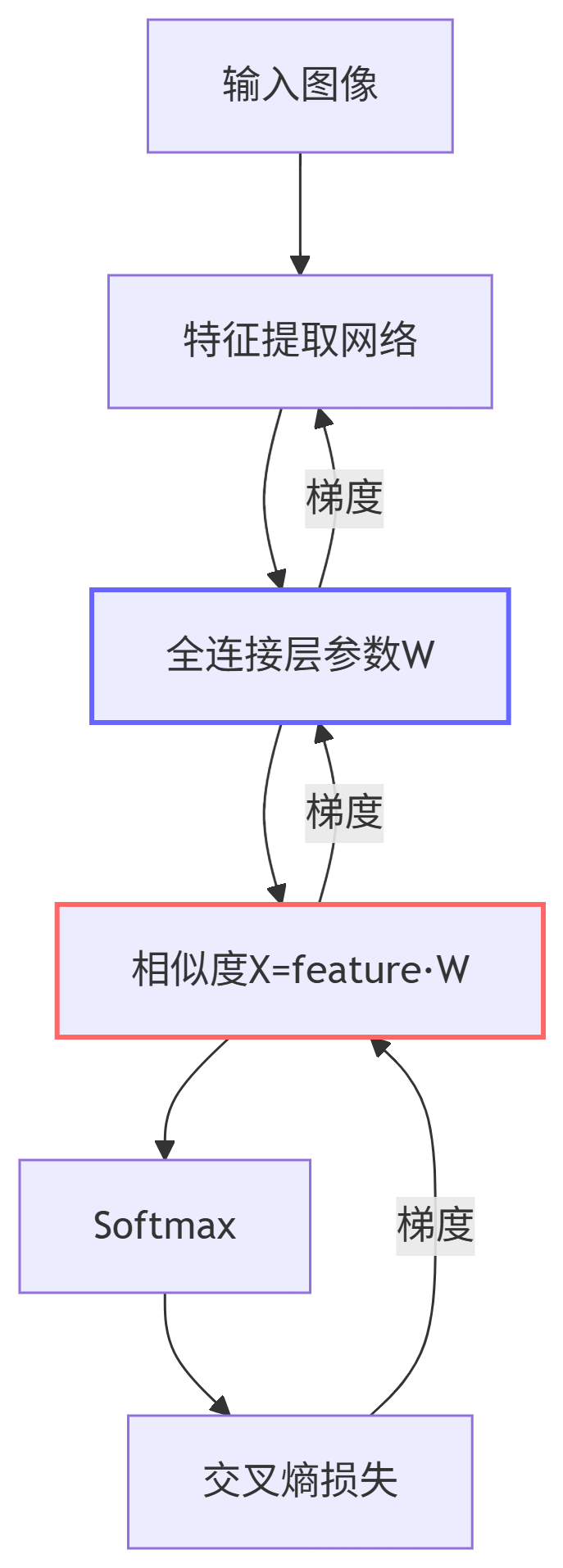
2.4.3 概率空間幾何解釋
在概率單純形中:
- 梯度指向真實類別頂點方向
- 更新使預測分布向真實分布
移動
- 當時達到全局最優(梯度為0)
2.4.4 海森矩陣與凸性分析
二階導數:
海森矩陣的性質:
1. 半正定性:
2. 說明損失函數是凸的
3. 保證梯度下降能收斂到全局最優
2.4.5 信息幾何視角
從KL散度角度看:
梯度更新最小化真實分布與預測分布
之間的KL散度。
2.4.6 梯度行為的深入分析
2.4.6.1 學習動態
| 情況 | 梯度行為 | 學習效果 |
|-----------------------------|----------------------|-------------------------|
|? ? ? ? ? ? ? ? ? ? ? | 大梯度 (
) | 快速增強正確類別 |
| ? ? ? ? ? ? ? ? ? ? ?| 小梯度 (
)? ? | 微調? ? ? ? ? ? ? ? ? ? ? |
| (錯誤類別) | 正梯度? ? ? ? ? ? ?| 強烈抑制? ? ? ? ? ? ? ? |
2.4.3.2?梯度飽和問題
當時:
- 梯度
- 可能導致學習停滯
- 解釋為什么需要適當的權重初始化
2.4.3.3 與Margin的聯系
梯度更新隱式地最大化:
即推動正確類別的logit比其他類別大至少一個margin。
2.4.3.4. 實際訓練中的意義
1. **類間競爭**:softmax的梯度自動保持
2. **自適應學習**:梯度與預測誤差成比例
3. **概率校準**:推動預測概率反映真實置信度
2.5 簡單例子
全連接層輸出的相似度矩陣?X∈Rb×n 需要通過Softmax轉換為概率分布。我們通過具體例子說明:
?例子1:假設batch中有1個樣本,輸出3個類別的相似度:
?
Softmax計算過程:
對于真實類別為"貓"(類別0)的情況:
交叉熵計算:
對比錯誤預測時的表現:
?則預測結果與真實結果相差越大CE的損失值越高。
3. 交叉熵的數值穩定性
交叉熵損失函數在深度學習中廣泛應用,但在實際計算過程中容易出現數值不穩定問題。本章將詳細分析這些問題的成因、表現形式以及解決方案。
3.1 數值不穩定的根本原因
3.1.1 理論分析
交叉熵損失函數的數學表達式為
L = -∑(i=1 to N) y_i * log(p_i)其中:
y_i是真實標簽的one-hot編碼p_i是模型預測的概率分布
數值不穩定主要源于以下幾個方面:
- 對數函數的特性:當
p_i接近0時,log(p_i)趨向于負無窮 - 指數函數的溢出:在softmax計算中,
exp(x)當x很大時會溢出 - 浮點數精度限制:計算機表示浮點數的精度有限
3.1.2 Softmax函數的數值問題
Softmax函數定義為
softmax(x_i) = exp(x_i) / ∑(j=1 to K) exp(x_j)當輸入值很大時,指數函數會導致數值溢出;當輸入值很小或負數絕對值很大時,會導致下溢。
3.2 數值不穩定常見的PyTorch報錯原因
3.2.1 數值溢出錯誤
import torch
import torch.nn as nn# 模擬極端情況下的logits
logits = torch.tensor([[100.0, 200.0, 150.0]], requires_grad=True)
targets = torch.tensor([1])criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)典型報錯信息:
RuntimeError: result type Float can't be cast to the desired output type Long
# 或者
RuntimeError: CUDA error: an illegal memory access was encountered
# 或者出現 NaN 值
tensor(nan, grad_fn=<NllLossBackward>)3.2.2 梯度爆炸/消失
# 梯度爆炸示例
logits = torch.tensor([[1e10, 1e5, 1e8]], requires_grad=True)
targets = torch.tensor([0])criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)
loss.backward()print(f"梯度值: {logits.grad}")
# 輸出可能是: tensor([[nan, nan, nan]])3.2.3 類別標簽未定義錯誤
# 錯誤的標簽索引
logits = torch.randn(2, 3) # 3個類別
targets = torch.tensor([1, 5]) # 標簽5超出了類別范圍[0,2]criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)3.2.4 維度不匹配錯誤
# 維度不匹配
logits = torch.randn(4, 10) # batch_size=4, num_classes=10
targets = torch.randn(4, 10) # 錯誤:應該是類別索引,不是概率分布criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)3.3 數值不穩定的解決方案
數值不穩定往往表現為梯度異常或損失值異常
3.3.1 使用數值穩定的實現
PyTorch的nn.CrossEntropyLoss內部已經實現了數值穩定的版本,它直接從logits計算,避免了顯式的softmax計算:
import torch
import torch.nn as nn
import torch.nn.functional as F# 推薦的穩定做法
def stable_cross_entropy_example():"""演示數值穩定的交叉熵計算"""logits = torch.tensor([[100.0, 200.0, 150.0],[50.0, 75.0, 25.0]])targets = torch.tensor([1, 0])# 方法1: 使用nn.CrossEntropyLoss (推薦)criterion = nn.CrossEntropyLoss()loss1 = criterion(logits, targets)# 方法2: 使用F.cross_entropy (等價)loss2 = F.cross_entropy(logits, targets)# 方法3: 手動實現穩定版本log_softmax = F.log_softmax(logits, dim=1)loss3 = F.nll_loss(log_softmax, targets)print(f"nn.CrossEntropyLoss: {loss1.item():.6f}")print(f"F.cross_entropy: {loss2.item():.6f}")print(f"手動穩定實現: {loss3.item():.6f}")stable_cross_entropy_example()3.3.2 避免不穩定的做法
# ? 不穩定的做法
def unstable_implementation(logits, targets):"""不推薦的不穩定實現"""softmax_probs = F.softmax(logits, dim=1)log_probs = torch.log(softmax_probs) # 這里可能出現log(0)return F.nll_loss(log_probs, targets)# ? 穩定的做法
def stable_implementation(logits, targets):"""推薦的穩定實現"""return F.cross_entropy(logits, targets)3.3.4 梯度裁剪
def training_with_gradient_clipping():"""帶梯度裁剪的訓練示例"""# 模擬模型和數據model = nn.Linear(10, 3)optimizer = torch.optim.Adam(model.parameters(), lr=0.01)criterion = nn.CrossEntropyLoss()# 模擬一個batch的數據inputs = torch.randn(32, 10)targets = torch.randint(0, 3, (32,))# 前向傳播outputs = model(inputs)loss = criterion(outputs, targets)# 反向傳播optimizer.zero_grad()loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)# 參數更新optimizer.step()print(f"損失值: {loss.item():.6f}")# 檢查梯度for name, param in model.named_parameters():if param.grad is not None:grad_norm = torch.norm(param.grad).item()print(f"{name} 梯度范數: {grad_norm:.6f}")training_with_gradient_clipping()4. 對比學習中的交叉熵公式變體
注意,本節不在于揭示各不同損失函數的統一性,而是幫助讀者用聯系的觀點看待這些不同問題,這對于編程和寫論文是由幫助的。
4.1 重新審視分類:從原型對比到樣本對比
4.1.1 分類任務的對比本質
在深入對比學習之前,讓我們重新審視傳統分類任務。回顧第1章中全連接層的幾何直覺,我們發現分類本質上也可以看出一種特殊對比過程:
傳統分類:樣本 vs 類別原型
X = A · B^T
其中:A是輸入樣本特征,B是類別原型特征當我們計算 softmax 交叉熵時:
P(class_i|x) = exp(x · w_i) / Σ_j exp(x · w_j)這個過程實際上是:
- 計算樣本x與每個類別原型
的相似度
- 通過softmax將相似度轉換為概率分布
- 最大化樣本與正確類別原型的相似度
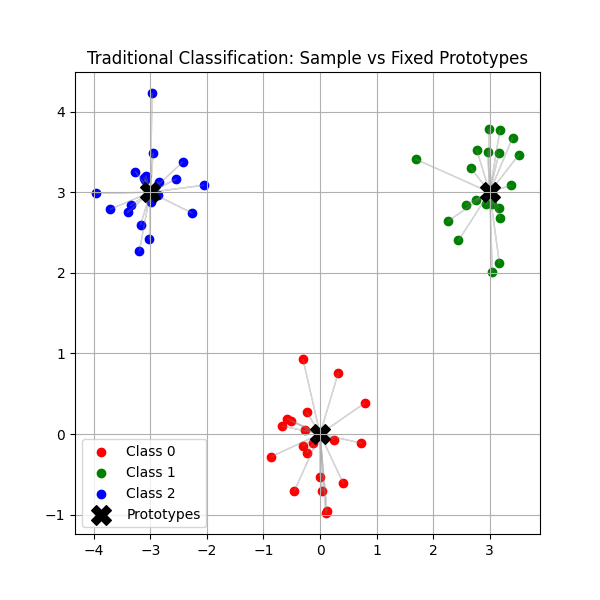
我們發現,傳統分類過程也可以看出是樣本與固定原型的對比,這個類別原型實際是隱藏在全連接層中,它在訓練的過程中也會發生移動。每個類別樣本的值不會與其它樣本之間對比,而是與類別原型進行對比。
4.1.2 從固定原型到動態樣本
對比學習將這個思想進一步擴展:
傳統分類:樣本 vs 固定類別原型
對比學習:樣本 vs 動態樣本集合在對比學習中:
- 正樣本:與查詢樣本語義相似的樣本
- 負樣本:與查詢樣本語義不同的樣本
- 目標:拉近正樣本,推遠負樣本
本質上,我們是在學習一個動態的"原型空間",其中每個樣本都可能成為某種語義的原型。
4.1.3 交叉熵的自然延伸
既然傳統分類已經使用交叉熵來處理"樣本vs原型"的對比,那么"樣本vs樣本"的對比自然也可以采用交叉熵的形式進行理解。
4.2 InfoNCE
4.2.1 從分類交叉熵到InfoNCE
在傳統分類中:
在InfoNCE中,我們有查詢樣本q和候選樣本集合{k_0, k_1, ..., k_N},其中k_0是正樣本:
對比分析:
- 分類交叉熵:x與權重向量
- InfoNCE:q與動態樣本向量
的內積
- 共同點:都是通過內積計算相似度,通過softmax歸一化,通過負對數似然優化
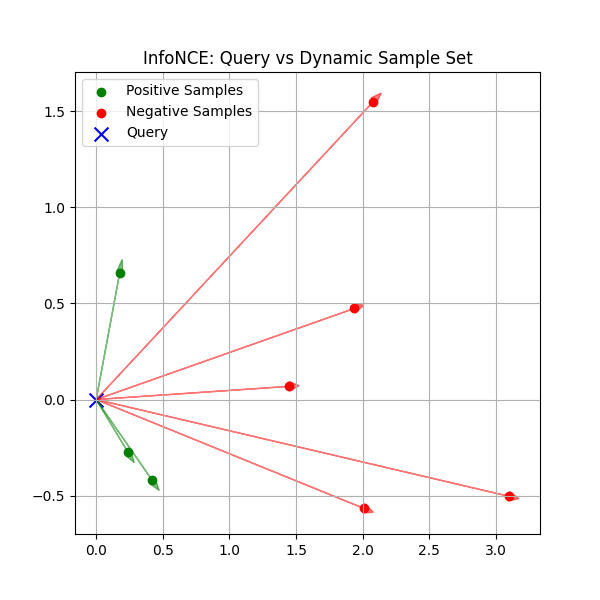
如上圖所示,在InfoNce中,是不存在類別原型的,而是樣本之間直接的對比,這里面既包括正樣本的對比也包括負樣本的對比。
4.2.2 溫度參數τ的交叉熵理解
溫度參數τ在分類任務中也經常使用,稱為temperature scaling:
分類中的溫度縮放:P(y|x) = softmax(logits/τ)
InfoNCE中的溫度:P(pos|q) = softmax(similarities/τ)τ的作用機制:
τ < 1(低溫度):
- softmax分布變得尖銳
- 模型更加"自信",傾向于給最相似的候選更高概率
- 梯度主要來自最相似的負樣本
- 類似于hard attention機制
τ > 1(高溫度):
- softmax分布變得平滑
- 模型更加"謙遜",概率分布更均勻
- 所有負樣本都對梯度有貢獻
- 類似于soft attention機制
τ = 1(標準溫度):
- 保持原始的softmax特性
- 在尖銳性和平滑性之間平衡
4.2.3 為什么使用 InfoNCE 進行大規模數據訓練?
在實際的大規模視覺或語言任務中,類別數量可能非常龐大(例如數萬甚至上百萬類),傳統的分類交叉熵方法面臨嚴重的效率與性能瓶頸。InfoNCE(Noise Contrastive Estimation 的一種信息論擴展)在此類場景下具有顯著優勢,主要原因如下:
1.?類別爆炸問題
- 在傳統分類任務中,softmax 輸出層的大小與類別數成正比。
- 當類別數達到十萬、百萬級別時,全類別 softmax 計算變得不可行:
- 參數量巨大,模型內存和計算開銷劇增;
- 梯度更新效率低下,訓練速度慢;
- 長尾分布問題加劇,大量類別樣本稀少,難以有效學習。
而 InfoNCE 并不依賴于顯式類別標簽,而是通過對比學習構建監督信號,避免了對類別數量的直接依賴。
2.?負樣本代替類別原型
- InfoNCE 不需要為每個類別維護一個“類別原型”向量;
- 取而代之的是,在每次訓練迭代中,將其他樣本作為負樣本,動態地進行對比;
- 正樣本通常來自數據增強或語義匹配策略(如同一圖像的不同視角、同一句子的不同表達等);
- 這種方式更靈活,尤其適用于無明確類別劃分的任務(如自監督學習)。
3.?負樣本過多但可采樣處理
- 雖然 InfoNCE 使用大量負樣本,但可以通過以下技術緩解其影響:
- 負樣本采樣(Negative Sampling):從所有樣本中隨機選取一部分作為負樣本;
- 動量編碼器(Momentum Encoder):用于生成高質量負樣本嵌入(如 MoCo 中的方法);
- 隊列機制(Queue):緩存歷史負樣本,提升負樣本多樣性(如 MoCo v2);
- 去噪技巧(De-noising):過濾掉潛在的偽負樣本,提高訓練穩定性。
這些技術使得 InfoNCE 在面對超大規模數據時仍能保持高效穩定的學習過程。
4.?端到端優化相似性度量
- InfoNCE 直接優化查詢樣本與正樣本之間的相似性,同時拉開與負樣本的距離;
- 更適合學習可用于檢索、匹配等下游任務的表示;
- 對比損失(Contrastive Loss)、三元組損失(Triplet Loss)等早期方法往往需要特定的數據構造(如成對/成組數據),而 InfoNCE 利用批量內的樣本即可構建對比目標,更加簡潔高效。
5.?適用于自監督與弱監督學習
- 在缺乏類別標簽的情況下,InfoNCE 提供了一種有效的學習表示的方式;
- 例如:在視覺自監督學習中,通過對同一圖像進行不同變換得到兩個視圖,互為正樣本,其余為負樣本;
- InfoNCE 構建的對比目標可以引導模型學習到語義一致的表示,即使沒有人工標注的類別標簽。
4.3 監督對比學習:多正樣本的交叉熵擴展
4.3.1 從單一正確答案到多個正確答案
傳統分類假設每個樣本只屬于一個類別,但現實中一個樣本可能與多個樣本相似。監督對比學習處理這種情況:
# 傳統分類:一個樣本對應一個類別
labels = [0, 1, 2, 0, 1] # 每個樣本一個標簽# 監督對比:一個錨點對應多個正樣本
positive_pairs = {0: [0, 3], # 樣本0與樣本0,3相似1: [1, 4], # 樣本1與樣本1,4相似2: [2], # 樣本2只與自己相似
}4.3.2 多標簽交叉熵的自然擴展
監督對比學習的損失函數:
L_sup = -1/|P(i)| Σ_{p∈P(i)} log(exp(z_i·z_p/τ) / Σ_{a∈A(i)} exp(z_i·z_a/τ))這可以理解為多個二分類交叉熵的平均:
def supervised_contrastive_loss(features, labels, temperature=0.1):batch_size = features.shape[0]similarities = torch.mm(features, features.t()) / temperature# 構建正樣本masklabels = labels.view(-1, 1)mask = torch.eq(labels, labels.t()).float() # 相同標簽為1mask = mask - torch.eye(batch_size) # 移除對角線# 對每個正樣本計算交叉熵,然后平均loss = 0for i in range(batch_size):if mask[i].sum() > 0: # 如果有正樣本pos_similarities = similarities[i] * mask[i]# 這里每個正樣本都相當于一個獨立的交叉熵計算loss += -torch.log(torch.sum(torch.exp(pos_similarities)) / torch.sum(torch.exp(similarities[i])))return loss / batch_size- 每個正樣本對應一個"虛擬類別"
- 對每個虛擬類別計算交叉熵
- 最終損失是所有虛擬類別交叉熵的平均
4.4 Circle Loss:重新參數化的交叉熵
4.4.1 從歐氏距離到余弦相似度
Circle Loss最初設計用于度量學習,處理樣本間的距離關系。但我們可以通過交叉熵的視角來理解它。
Circle Loss的原始形式:
4.4.2 隱藏的二分類交叉熵結構
通過重新組織,我們可以將Circle Loss寫成二分類交叉熵的形式:
若
則:
這正是二分類交叉熵的標準形式!
def circle_loss_as_crossentropy(pos_scores, neg_scores, gamma=1.0):# 計算正類和負類的綜合logitpos_logit = torch.logsumexp(-gamma * pos_scores, dim=0)neg_logit = torch.logsumexp(gamma * neg_scores, dim=0)# 二分類交叉熵:log(1 + exp(neg_logit - pos_logit))return F.softplus(neg_logit - pos_logit)理解要點:
- Circle Loss將多個正負樣本分別聚合成兩個綜合得分
- 然后在這兩個得分之間進行二分類
- 本質上是"正樣本集合 vs 負樣本集合"的交叉熵對比
4.4.3 動態權重的交叉熵解釋
Circle Loss的動態權重:
從交叉熵角度理解:
- 困難正樣本(相似度低)獲得更大權重,相當于增加其在損失中的重要性
- 困難負樣本(相似度高)獲得更大權重,相當于增加其在損失中的重要性
- 這類似于Focal Loss中根據預測置信度調整權重的思想
4.5 Triplet Loss
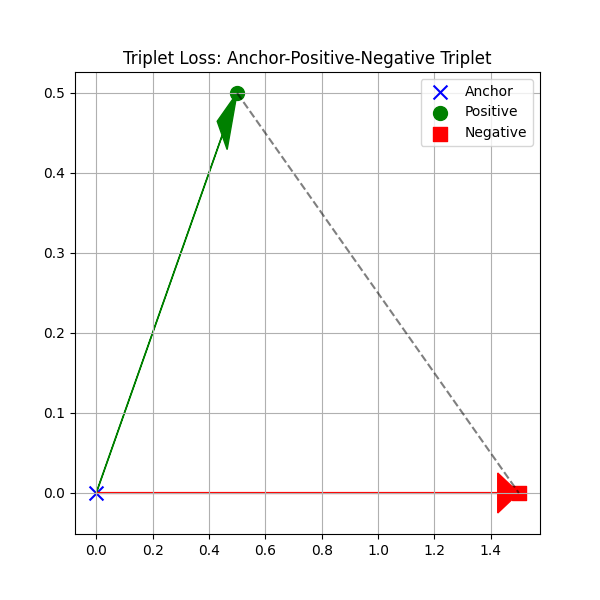
傳統的Triplet Loss使用硬邊界:
這個損失函數是不可導的(在邊界處),實際應用中常使用軟化版本:
另??(similarity for positive pair),
(similarity for negative pair)
則
這也是二元交叉熵的形式: - ?用作正類 logit -
用作負類 logit - 公式與標準 BCE 匹配:
當擴展到多個負樣本時:
從交叉熵角度,這等價于:
def multi_triplet_as_crossentropy(anchor, positive, negatives):pos_sim = torch.dot(anchor, positive)neg_sims = torch.mm(anchor.unsqueeze(0), negatives.t()).squeeze()# 對每個負樣本進行二分類losses = []for neg_sim in neg_sims:# 二分類:正樣本 vs 當前負樣本logit = pos_sim - neg_simloss = F.binary_cross_entropy_with_logits(logit.unsqueeze(0), torch.ones(1) # 正樣本應該獲勝)losses.append(loss)return torch.stack(losses).mean()4.6 ?小結
通過本章的分析,我們深入理解了對比學習中各種損失函數:
- 分類是特殊的對比:樣本與固定類別原型的對比
- 對比學習是泛化的分類:樣本與動態樣本集合的對比
- 交叉熵是通用的框架:無論是原型對比還是樣本對比,都可以用交叉熵來建模
統一的理解框架
傳統分類:max P(correct_class | sample)
對比學習:max P(positive_sample | query)共同本質:通過交叉熵優化概率分布的匹配結語
。編寫中可能不嚴謹和錯漏的地方,歡迎討論指正。
)






(附詳細解題思路))









)

