
論文地址:https://arxiv.org/abs/2504.02407v3
摘要
我們提出了F5R-TTS,這是一種新穎的文本到語音(TTS)系統,它將群體相對策略優化(GRPO)集成到基于流匹配的架構中。?通過將流匹配TTS的確定性輸出重新表述為概率高斯分布,我們的方法能夠無縫集成強化學習算法。?在預訓練期間,我們訓練了一個基于概率重新表述的流匹配模型,該模型源自F5-TTS和一個開源數據集。?在隨后的強化學習(RL)階段,我們采用一個由GRPO驅動的增強階段,該階段利用雙重獎勵指標:通過自動語音識別計算的詞錯誤率(WER)和通過驗證模型評估的說話人相似度(SIM)。?零樣本語音克隆的實驗結果表明,與傳統的基于流匹配的TTS系統相比,F5R-TTS在語音可懂度(WER相對降低29.5%)和說話人相似度(SIM得分相對提高4.6%)方面都取得了顯著的改進。?音頻樣本可在https://frontierlabs.github.io/F5R訪問。
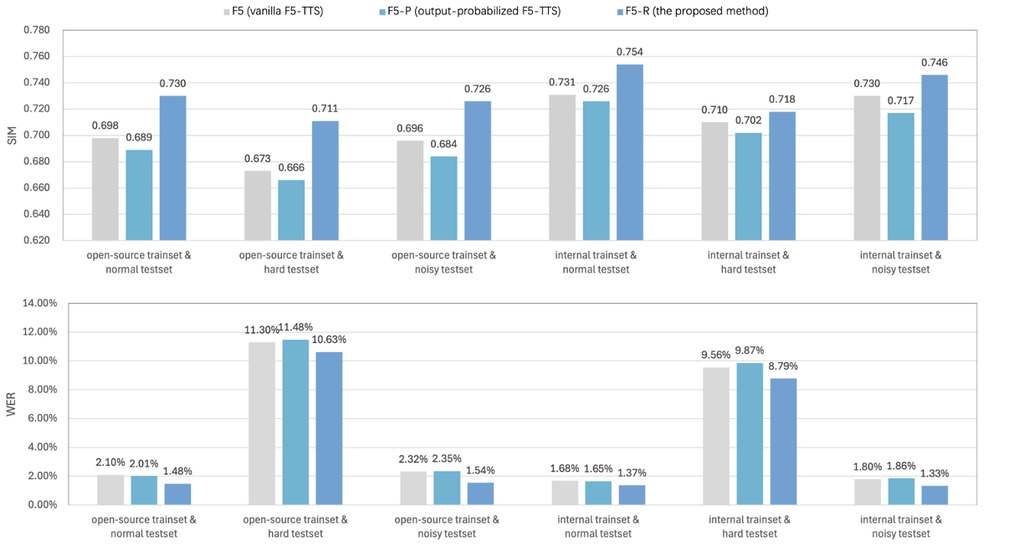
評估是從兩個關鍵角度進行的:說話人相似度(由SIM衡量)和語義準確性(由WER衡量)。?
更高的SIM值和更低的WER值表示性能更優。
1、引言
近年來,文本到語音(TTS)系統的顯著進步使得能夠生成高保真、自然的聲音和零樣本語音克隆能力。這些發展涵蓋了自回歸(AR)[1, 2, 3, 4]和非自回歸(NAR)[5, 6, 7]模型架構。?AR模型通常使用語音編解碼器將音頻編碼成離散符元,然后采用基于語言模型(LM)的自回歸模型來預測這些符元。?然而,這種方法存在推理延遲和暴露偏差的問題。?相反,基于去噪擴散或流匹配的NAR模型利用并行計算來加快推理速度,展現出強大的應用潛力。
此外,正如DeepSeek系列[8, 9, 10, 11]所示,強化學習(RL)已引發了大語言模型(LLM)研究的趨勢。?直接偏好優化(DPO)[12]和組相對策略優化(GRPO)[8]等RL方法已被證明能夠有效地使LLM輸出與人類偏好保持一致,通過反饋優化來增強生成文本的安全性和實用性。?在圖像生成領域,去噪擴散策略優化(DDPO)[13]等RL方法也已成功應用。?這種范式現已擴展到AR TTS系統:Seed-TTS[14]使用說話人相似度(SIM)和詞錯誤率(WER)作為獎勵,并結合近端策略優化(PPO)[15]、REINFORCE[16]和DPO實現了RL集成。?在一些其他的AR架構工作中,也探討了DPO及其變體[17, 18, 19, 20]。?然而,由于與LLM的根本結構差異,將RL集成到NAR架構中仍然具有挑戰性。?當前的研究沒有顯示出在基于NAR的TTS系統中成功集成RL的案例,這表明這一挑戰仍在等待可行的研究解決方案。
在本文中,我們介紹了F5R-TTS,這是一種新穎的TTS系統,它通過兩項關鍵創新將GRPO應用于流匹配模型。?首先,我們將基于流匹配模型的確定性輸出重新表述為概率序列,其中F5-TTS[7]被用作我們修改的骨干。?這種重新表述使得在后續階段能夠無縫集成RL算法。?其次,設計了一個由GRPO驅動的增強階段,使用WER和SIM作為獎勵指標,兩者都與人類感知高度相關。?實驗結果證明了該系統的有效性,與傳統的NAR TTS基線相比,在語音清晰度(WER相對降低了29.5%)和說話人一致性(SIM得分相對提高了4.6%)方面都取得了顯著改進。
本工作的關鍵貢獻如下。
- 我們提出了一種方法,將基于流匹配的TTS模型的輸出轉換為概率表示,這使得各種強化學習算法能夠方便地應用于流匹配模型。
- 我們成功地將GRPO方法應用于NAR-TTS模型,使用WER和SIM作為獎勵信號。
- 我們已在零樣本語音克隆應用場景中實現了 F5R-TTS 模型,并證明了其有效性。
本文的其余部分組織如下:第 2 節描述了所提出的方法。?然后,第 3 節介紹了實驗設置和評估結果。?最后,第 4 節總結了本文。
2、提出的方法
所提出的方法將訓練過程分為兩個階段。?我們首先使用流匹配損失對模型進行預訓練,隨后使用 GRPO 改進模型。?在本節中,我們將詳細解釋如何利用 GRPO 策略來改進基于流匹配的模型。
2.1、預備知識
我們的模型主要遵循 F5-TTS?[7],這是一種具有零樣本能力的新型基于流匹配的 TTS 模型。?該模型在文本引導的語音填充任務上進行訓練。?根據流匹配的概念,目標是預測??以??
作為輸入,其中?
?數據分布?q?(x)?和?
?。標準目標函數定義為
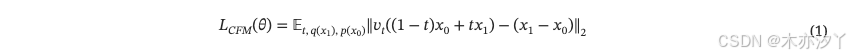
其中?θ?參數化神經網絡?。
并且我們旨在使用GRPO進一步增強模型的性能,GRPO是PPO的簡化變體,它消除了價值模型,并通過基于規則或基于模型的方法計算獎勵。?懲罰項KL散度??之間?
?和?
?的估計如公式所示。?
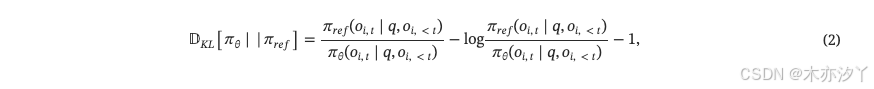
對于每個問題?q?,它根據輸出的相對獎勵計算優勢?o?在每個組內,然后通過最大化以下目標來優化策略模型??。
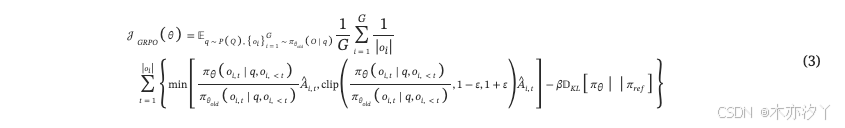
其中?ε?和?β?是超參數,優勢?。
2.2、輸出概率化和預訓練
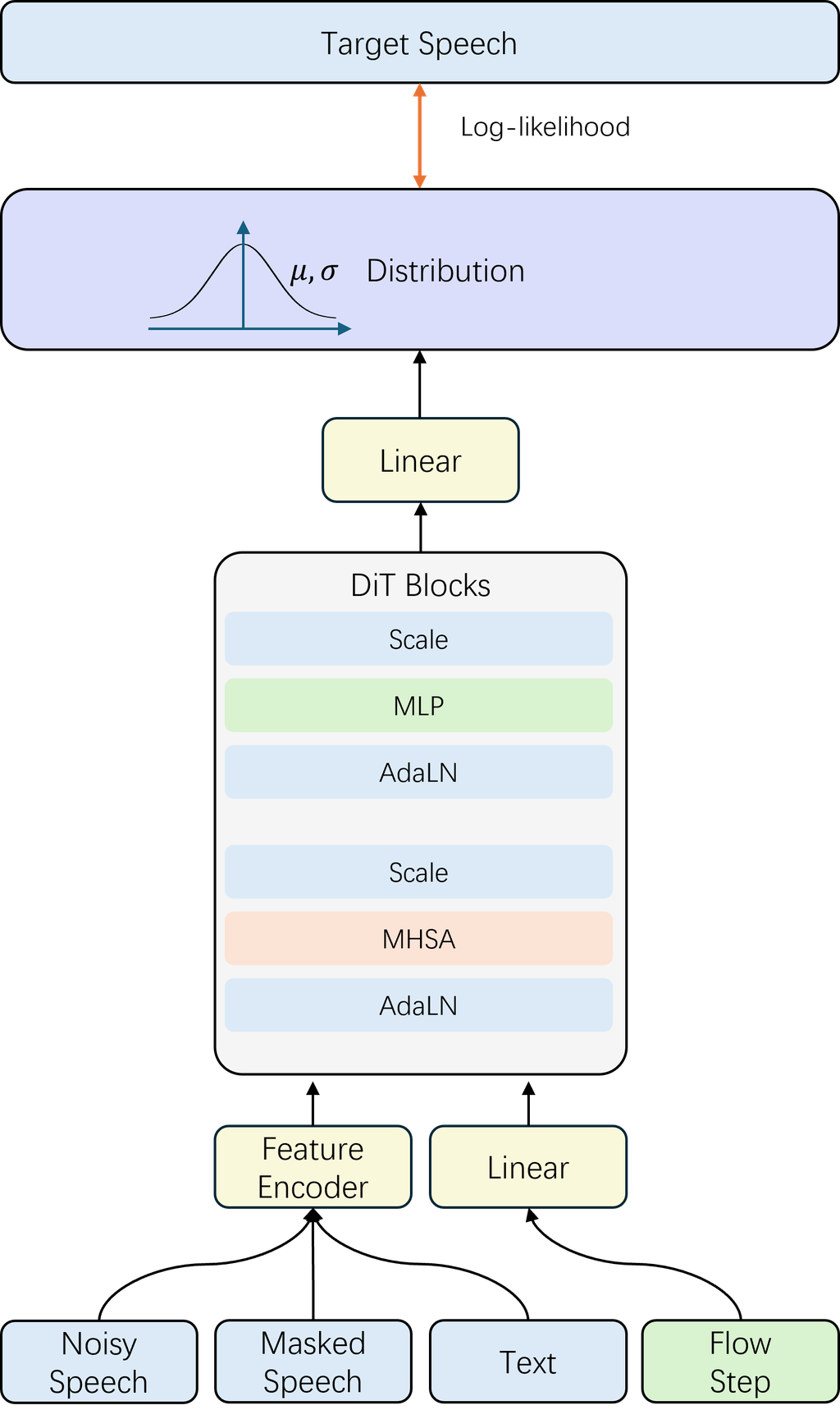
我們模型中最重要的區別在于修改了最終的線性層,以便準確預測每個流步驟的概率分布。
我們將模型的輸出重新表述為概率術語,以增強與GRPO的兼容性,從而能夠預測……的分布概率?。?圖2顯示了模型的整體結構。?在第一階段,我們保留了流匹配目標函數。?流匹配目標是將標準正態分布中的概率路徑與近似于數據分布的分布匹配。
所提出的模型也在填充任務上進行了訓練。?在訓練過程中,模型接收流步驟?t、噪聲聲學特征?、掩蔽聲學特征?
以及完整語音的文本轉錄?
作為輸入。?我們使用提取的梅爾譜圖特征作為訓練的聲學特征,并將文本特征填充到與聲學特征相同的長度。
所提出的模型并不直接預測……的精確值??。我們讓模型預測均值?μ?(x)?以及方差?σ?(x)?最后一層高斯分布和參數?θ?被優化以最大化以下對數似然?
。
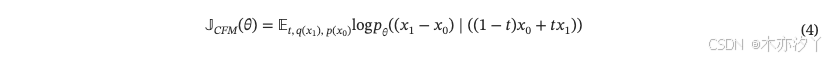
簡化公式后?4,我們可以得到以下改進的目標函數
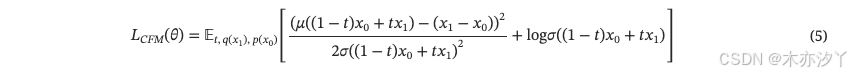
在預訓練階段,我們使用公式?5來優化模型。
2.3、使用GRPO增強模型
在預訓練階段之后,我們繼續使用GRPO來提高模型的性能。?GRPO階段的流程如圖3所示:
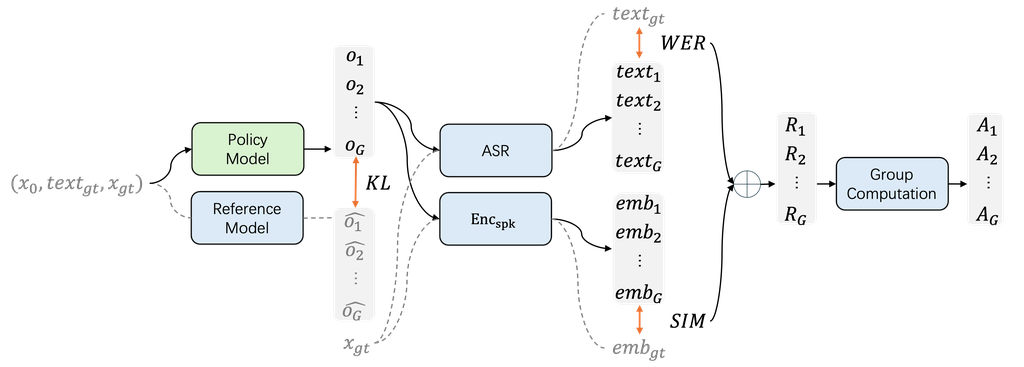
KL散度被納入作為懲罰項,以增強GRPO階段的訓練穩定性。
在第二階段,我們進一步訓練預訓練模型作為策略模型??同時初始化參考模型?
?使用預訓練參數。?在整個 GRPO 階段,參考模型保持凍結狀態。?在 GRPO 訓練期間,我們的 TTS 模型的前向操作與預訓練階段不同。?存在一個類似于推理的采樣操作。?策略模型?
?接收?
?作為輸入,然后計算每個流程步驟的輸出概率。?策略模型的采樣結果?o?用于計算獎勵以及與參考模型結果相比的 KL 損失
?.
就獎勵指標而言,我們選擇 WER 和 SIM 作為改進語義一致性和說話人相似性的主要標準,因為它們代表了語音克隆任務中最關鍵的兩個方面。?我們使用一個 ASR 模型來轉錄合成的語音,獲得轉錄文本??,然后將轉錄文本與真實語音的?
真實文本進行比較以計算 WER。?此外,我們利用說話人編碼器?
?來提取合成的說話人嵌入?
?和真實說話人嵌入?
?分別來自生成的語音?o?和真實語音樣本?
。?通過計算這些嵌入之間的余弦相似度來評估說話人相似度。
因此,GRPO獎勵被分為語義相關獎勵和說話人相關獎勵,定義如下。
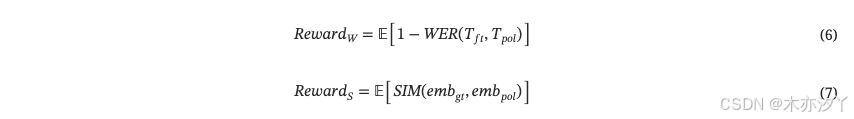
總獎勵定義為:
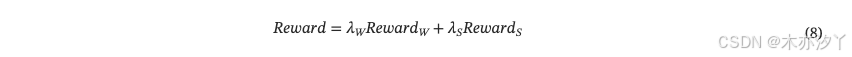
其中??和
??是各自獎勵的權重項。
計算獎勵后,我們可以通過組相對優勢估計[8]得到優勢。
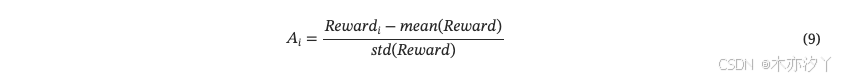
為了保持模型輸出的穩定性,GRPO還需要使用參考模型??來提供約束。?最后,我們定義公式。?10作為第二階段的目標函數。
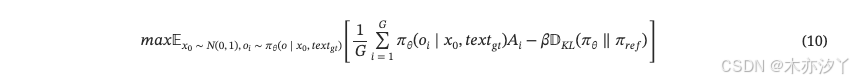
3、實驗
在本節中,我們的實驗重點在于驗證所提出方法在增強零樣本語音克隆任務性能方面的有效性。
3.1、數據集和實驗設置
在預訓練階段,我們使用了WenetSpeech4TTS Basic?[21],這是一個包含7226小時多說話人語料的普通話開源數據集,作為訓練集。?在GRPO階段,我們從同一數據集中隨機選擇了100小時的語音數據進行訓練。?在評估中,遵循Seed-TTS的測試設置,我們使用Seed-TTS-eval測試集(cn集)1中的參考語音合成了2020個通用樣本和400個困難樣本。?通用樣本使用純文本,而困難樣本使用難以處理的文本,例如繞口令或包含高頻重復詞語和短語的文本。?為了測試噪聲魯棒性,我們使用同一測試集中的70個含噪語音生成了140個樣本。
我們的模型架構主要遵循F5-TTS論文中描述的配置,僅對最后一層輸出層進行了修改。?在預訓練階段,模型在8個A100 40GB GPU上進行了100萬次更新訓練,批量大小為160,000幀。?在GRPO訓練階段,模型在8個A100 40GB GPU上進行了1100次更新訓練,批量大小為6400幀。?對于GRPO訓練,我們使用SenseVoice?[22]作為自動語音識別(ASR)系統來計算?R?e?w?a?r?dW?,并使用WeSpeaker?[23]作為說話人編碼器進行?R?e?w?a?r?dS?計算。
我們選擇原始F5-TTS作為我們實驗的基線。?為了證明GRPO在改進TTS模型方面的有效性,我們比較了原始F5-TTS、輸出概率化F5-TTS和所提出的方法的性能。?我們分別將它們命名為F5、F5-P和F5-R。?F5嚴格保留了原始架構和參數設置。?F5-P也是GRPO階段的預訓練模型。?我們在相同的預訓練數據集上訓練所有模型。
3.2、評估
3.2.1、可視化分析
我們嘗試可視化不同模型在零樣本語音克隆任務中的性能差異。

圖表中的每個小數字代表一個話語樣本。?不同的數字或顏色對應不同的目標說話人。?
帶星號的數字表示目標說話人的參考話語(數字代表的目標說話人)。?不帶星號的數字指的是合成的語音。?并用紅箭頭標出了一些錯誤案例。
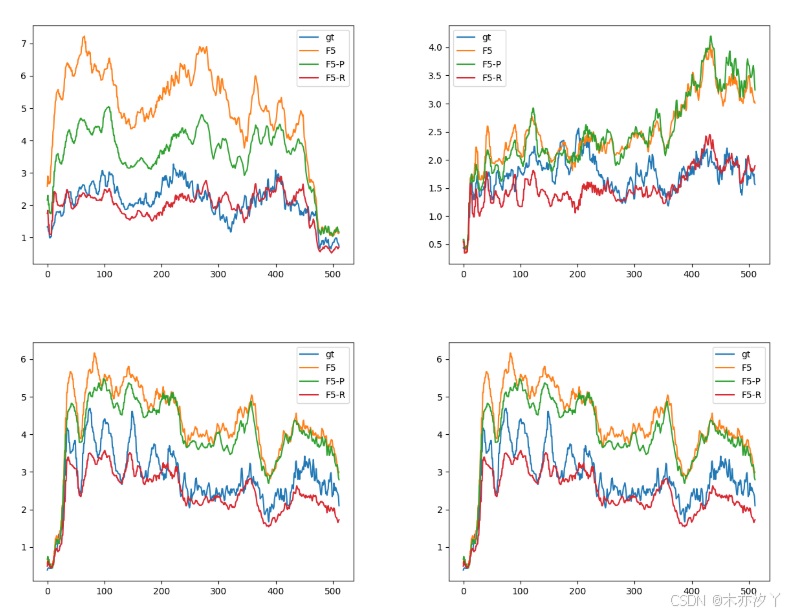
在每個子圖中,橫軸表示梅爾頻譜系數數量,縱軸表示方差。?每個子圖中都有4條GV曲線,對應不同的來源。?
曲線的對應關系如圖例所示,其中gt表示ground truth(真實值)。
?我們首先使用t-SNE[24]將說話人相似度可視化到二維空間。?T-SNE可以以無監督的方式對數據(例如說話人嵌入)進行聚類。?對于此分析,我們從Seed-TTS-eval test-cn集中隨機選擇了10個未見過的說話人作為目標說話人,然后模型分別為每個說話人合成了10個話語。?我們使用WeSpeaker獲取話語的說話人嵌入,然后通過t-SNE進行可視化。?我們可以直觀地看到合成結果與真實樣本之間的相似性。?我們還可以觀察到目標說話人之間的分布差異。?如圖4所示,F5-R的結果根據目標說話人進行了很好的聚類。?同時,F5和F5-P的子圖顯示,對應于某些目標說話人的合成結果并未完全聚在一起。?這意味著F5-R的合成結果具有更好的說話人相似性。
其次,我們使用了全局方差(GV)[25]。?GV是一種可視化話語頻譜方差分布的方法。?我們分別為Seed-TTS-eval test-cn集中的4個未見過的說話人(2個女性和2個男性)生成了20個話語。?然后,我們計算了參考話語和合成話語的GV。?合成曲線和參考曲線越接近,表明性能越好。?如圖5所示,F5-R的紅色曲線比其他曲線與參考話語的藍色曲線更好地吻合,這也表明F5-R的合成結果與參考話語更相似。
3.2.2、指標分析
為評估模型性能,我們基于seed-tts-eval test-cn采用了WER和SIM作為客觀指標。?對于指標計算,我們利用了seed-tts-eval提供的官方評估工具包。?對于WER,我們使用了Paraformer-zh[26]進行轉錄。?對于SIM,我們利用了基于WavLM-large的說話人識別模型[27]提取說話人嵌入。?這些指標分別量化了語義準確性(較低的WER更佳)和說話人相似度(較高的SIM更佳)。?表1展示了這三個模型的比較評估結果。
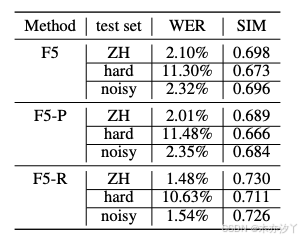
就SIM而言,可以觀察到F5和F5-P在兩個不同的測試集上表現出相當的性能,F5略優于后者。?我們提出的模型在這兩個集合上都取得了優越的性能,確立了其頂級性能的地位。?值得注意的是,在通用測試集上,我們的模型以至少0.03 SIM點的優勢優于其他模型。?與F5相比,F5-R在通用測試集和困難測試集上分別取得了4.6%和5.6%的相對增長。?這表明GRPO對提高說話人相似度有積極貢獻。
就詞錯誤率 (WER) 而言,F5 和 F5-P 在兩個不同的測試集上保持高度一致。?然而,我們的模型在這兩個數據集上都取得了顯著更好的結果。?在通用測試集上,與基線相比,它實現了 29.5% 的 WER 相對降低,在困難測試集上進一步降低了 5.9%。?這些結果最終證實了 GRPO 在提高語義準確性方面的有效性。
對于噪聲魯棒性測試,我們使用噪聲話語作為參考音頻。?噪聲對所有模型的 SIM 影響微乎其微,同時導致 F5 和 F5-P 的 WER 增加。?同時,F5-R 顯示出顯著改進的噪聲魯棒性。?我們發現 F5-R 在噪聲條件下也保持了優越的節奏性能。?噪聲魯棒性測試的音頻樣本可在?https://frontierlabs.github.io/F5R?獲取。

為了證明所提出方法的泛化能力,我們在其他數據集上進行了并行實驗。?對于預訓練階段,我們使用了一個包含 10,000 小時語料庫的內部普通話數據集,主要來自廣播和有聲讀物。?我們對數據集進行了預備的基于質量的過濾。?此外,隨機選擇了一個 100 小時的子集用于 GRPO 訓練。?使用內部數據集的客觀指標比較如表?2?所示。?與F5相比,F5-R在通用測試集上的字錯誤率(WER)相對降低了18.4%,語音相似度(SIM)相對提高了3.1%。?在困難測試集上,F5-R的WER相對降低了8.1%,SIM相對提高了1.1%。?在噪聲測試集上,F5-R的WER相對降低了26.1%,SIM相對提高了2.2%。?總體結果與在WenetSpeech4TTS Basic上獲得的結果一致,表明GRPO持續提高了不同數據集上的模型性能。
總體而言,F5和F5-P的性能大體相當。?正如預期,以WER和SIM作為獎勵的GRPO使模型在語義準確性和說話人相似度方面均取得了提升。?在說話人相關獎勵組件的指導下,該模型通過上下文學習展示了增強的克隆目標說話人特征的能力。?在困難測試集上,所提出的模型在WER性能方面表現出更明顯的相對優勢。?我們假設這種改進源于WER相關的獎勵組件,該組件有效地增強了模型的語義保持能力。?然而,所有三個模型在困難測試集上都表現出性能下降,這表明文本復雜性的增加通常會降低模型的穩定性。?這一觀察結果可以作為未來優化工作的重點。
4、結論
在本文中,我們提出了F5R-TTS,它將GRPO方法引入基于流匹配的NAR TTS系統。?通過將基于流匹配模型的輸出轉換為概率表示,GRPO可以集成到訓練流程中。?實驗結果表明,與基線系統相比,所提出的方法實現了更高的SIM和更低的WER,這表明具有適當獎勵函數的GRPO對語義準確性和說話人相似性都有積極的貢獻。
我們下一步將投資于以下方向的研究。
- 強化學習方法研究: 我們計劃探索將額外的強化學習方法(例如,PPO,DDPO)集成到NAR TTS系統中。
- 獎勵函數優化: 為了進一步增強模型在挑戰性場景中的穩定性,我們將繼續研究優化的獎勵函數設計。
- 數據探索: 為了更好地理解模型在大數據集上的性能,我們將利用更多訓練數據進行進一步的實驗。
參考文獻?
參見原文
)


)












)


