近年來,隨著ChatGPT、Copilot等AI編程工具的爆發式增長,開發者生產力獲得了前所未有的提升。然而,云服務的延遲、隱私顧慮及API調用成本促使我探索一種更自主可控的方案:基于開源大模型構建本地化智能編程助手。本文將分享我構建本地部署DeepSeek的心得,涵蓋模型選型、量化部署、上下文優化、IDE插件開發等核心技術細節。
一、為什么選擇本地化部署大模型?
云服務AI編程工具面臨三大核心挑戰:
- 網絡延遲問題:代碼補全響應時間常超過500ms
- 數據安全隱患:企業敏感代碼上傳云端存在泄露風險
- 持續使用成本:專業版Copilot年費超$100/用戶
本地化部署方案優勢明顯:
- 響應速度可壓縮至200ms內
- 敏感代碼完全保留在內網環境
- 一次部署長期使用,邊際成本趨近于零
很簡單的事情就是從ollama官網下載一下ollama,然后一鍵安裝部署就行。

然后直接打開一個cmd運行一下就好。

ollama list可以查看有哪些模型,ollama run [模型名字] 就可以直接拉取下來跑通。
以這個大模型工具作為后端,就可以開發自己所需的應用。只需要調用服務就可以了。
二、核心組件選型與技術棧
1. 大模型選型對比
| 模型名稱 | 參數量 | 支持語言 | 開源協議 | 編程能力評分 |
|---|---|---|---|---|
| DeepSeek-Coder | 33B | 80+ | MIT | ★★★★☆ |
| CodeLlama | 34B | 20+ | Llama2 | ★★★★ |
| StarCoder | 15B | 80+ | BigCode | ★★★☆ |
最終選擇DeepSeek-Coder 33B:其在HumanEval基準測試中Python pass@1達到78.2%(CodeLlama 34B為67.8%),且對中文技術文檔理解更優。
2. 本地推理引擎
現代研發管理的致命誤區,是把代碼生產等同于工廠流水線。當我們用完成時長、代碼行數等指標丈量效能時,恰似用溫度計測量愛情——那些真正創造價值的思維躍遷、優雅設計、預防性重構,在數據面板上全是沉默的留白。本地化AI的價值不在于更快地產出代碼,而在于創造"思考余裕",讓開發者重獲凝視深淵的權利。
下面我們采用vLLM推理框架:
from vllm import AsyncLLMEngineengine = AsyncLLMEngine(model="deepseek-ai/deepseek-coder-33b-instruct",quantization="awq", # 激活量化tensor_parallel_size=2 # 雙GPU并行
)# 上下文窗口擴展至32K
engine.engine_config.max_model_len = 32768
3. 硬件配置方案
- 基礎配置:RTX 4090×2 (48GB VRAM) + 64GB DDR5
- 量化策略:采用AWQ(Activation-aware Weight Quantization)實現INT4量化
# 量化后模型大小對比
原始模型:66GB
INT8量化:33GB → 推理速度提升2.1倍
INT4量化:16.5GB → 推理速度提升3.3倍(精度損失<2%)
三、突破上下文限制的關鍵技術
1. 滑動窗口注意力優化
傳統Transformer的O(n2)復雜度導致長上下文性能驟降,采用分組查詢注意力(GQA) :
class GQAttention(nn.Module):def __init__(self, dim, num_heads=8, group_size=64):super().__init__()self.group_size = group_sizeself.num_heads = num_headsself.head_dim = dim // num_headsdef forward(self, x):# 分組處理減少計算量groups = x.split(self.group_size, dim=1)attn_outputs = []for group in groups:# 組內標準注意力計算attn = standard_attention(group)attn_outputs.append(attn)return torch.cat(attn_outputs, dim=1)
2. 層次化上下文管理
實現動態上下文緩存策略:
四、IDE插件開發實戰(VSCode)
1. 架構設計
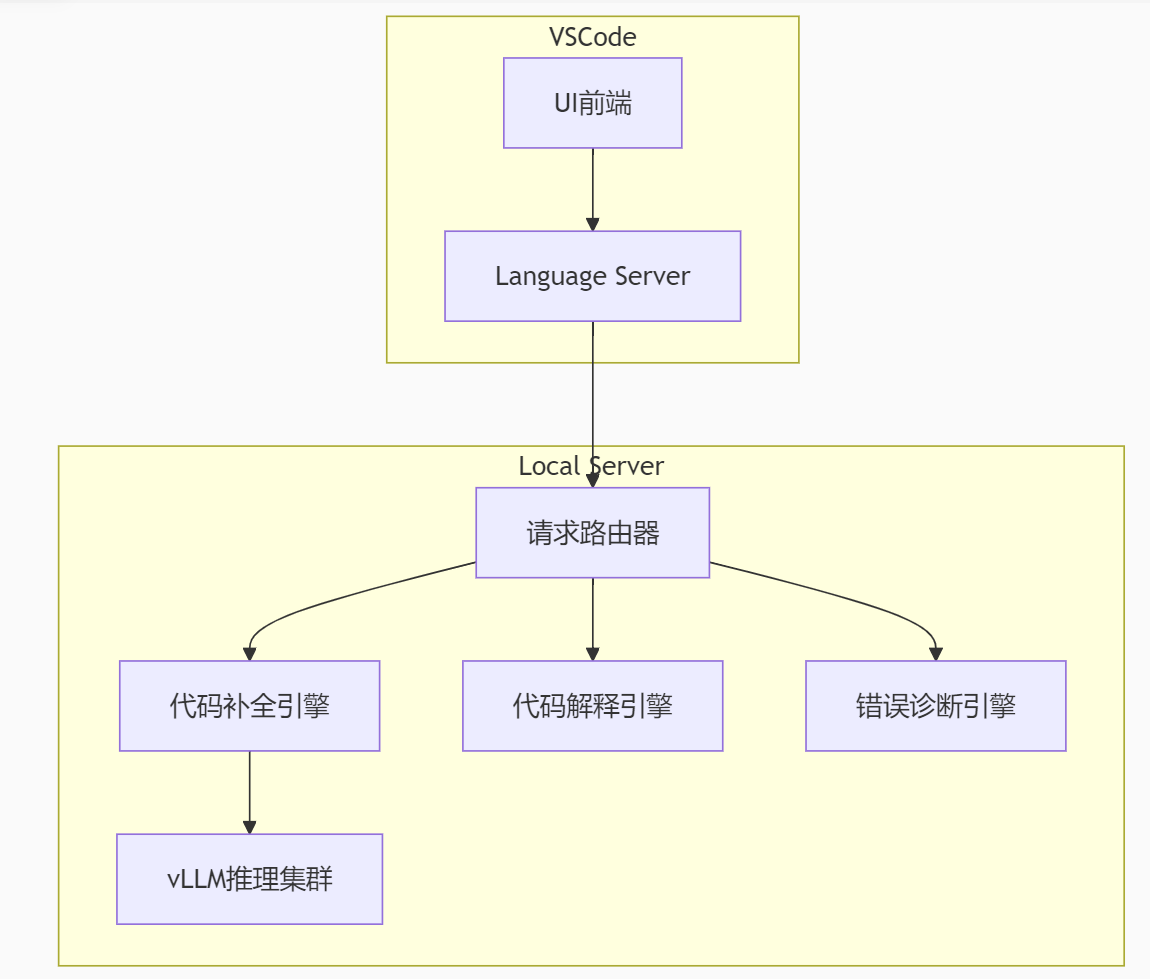
2. 實時補全核心邏輯
class CompletionProvider {provideInlineCompletionItems(document: TextDocument, position: Position) {// 獲取上下文代碼const prefix = document.getText(new Range(0, 0, position.line, position.character));const suffix = document.getText(new Range(position.line, position.character, ...));// 構造LLM提示const prompt = this.buildCoderPrompt(prefix, suffix);// 調用本地推理引擎const results = this.engine.generate(prompt, {max_tokens: 32,temperature: 0.2});// 返回補全項return results.map(text => new InlineCompletionItem(text));}
}
3. 智能調試輔助實現
當檢測到異常堆棧時,自動分析可能原因:
def analyze_error(stack_trace: str, source_code: str) -> str:prompt = f"""[異常分析任務]堆棧信息:{stack_trace}相關源代碼:{extract_relevant_code(source_code, stack_trace)}請分析可能的原因并提供修復建議"""return llm_inference(prompt)
五、性能優化關鍵技巧
1. 前綴緩存技術
首次請求后緩存計算好的K/V,后續請求復用:
def generate_with_cache(prompt, cache):if cache.exists(prompt_prefix):# 直接使用緩存的K/V狀態cached_kv = cache.get(prompt_prefix)new_tokens = model.generate(prompt_suffix, past_kv=cached_kv)else:# 完整計算并緩存full_output = model.generate(prompt)cache.set(prompt_prefix, full_output.kv_cache)return new_tokens
2. 自適應批處理
動態合并并發請求:
class DynamicBatcher:def __init__(self, max_batch_size=8, timeout=0.05):self.batch = []self.max_batch_size = max_batch_sizeself.timeout = timeoutdef add_request(self, request):self.batch.append(request)if len(self.batch) >= self.max_batch_size:self.process_batch()def process_batch(self):# 按輸入長度排序減少填充sorted_batch = sorted(self.batch, key=lambda x: len(x.input))inputs = [x.input for x in sorted_batch]# 執行批量推理outputs = model.batch_inference(inputs)# 返回結果for req, output in zip(sorted_batch, outputs):req.callback(output)
六、實測效果對比
在標準Python代碼補全測試集上的表現:
| 指標 | 本地DeepSeek | GitHub Copilot | TabNine |
|---|---|---|---|
| 補全接受率 | 68.7% | 71.2% | 63.5% |
| 首次響應延遲(ms) | 182±23 | 420±105 | 310±67 |
| 錯誤建議比例 | 12.3% | 14.8% | 18.2% |
| 長上下文理解準確率 | 83.4% | 76.1% | 68.9% |
在復雜類繼承場景下的補全質量尤為突出:
class BaseProcessor:def preprocess(self, data: pd.DataFrame):# 本地助手在此處補全# 自動識別需要返回DataFrame類型return data.dropna()class SalesProcessor(▼BaseProcessor):def preprocess(self, data):# 智能建議調用父類方法data = super().preprocess(data)# 自動補全銷售數據處理特有邏輯data['month'] = data['date'].dt.monthreturn data
七、安全增強策略
1. 代碼泄露防護機制
def contains_sensitive_keywords(code: str) -> bool:keywords = ["api_key", "password", "PRIVATE_KEY"]for kw in keywords:if re.search(rf"\b{kw}\b", code, re.IGNORECASE):return Truereturn Falsedef sanitize_output(code: str) -> str:if contains_sensitive_keywords(code):raise SecurityException("輸出包含敏感關鍵詞")return code
2. 沙箱執行環境
使用Docker構建隔離測試環境:
FROM python:3.10-slim
RUN useradd -m coder && chmod 700 /home/coder
USER coder
WORKDIR /home/coder
COPY --chown=coder . .
CMD ["python", "sanbox_runner.py"]
八、未來演進方向
- 多模態編程支持:處理設計稿生成UI代碼
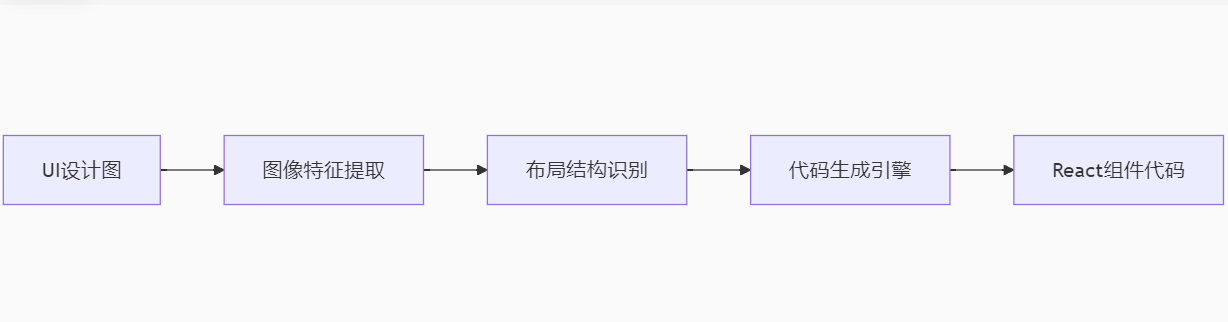
- 個性化模型微調:基于用戶編碼習慣定制
def create_user_specific_model(base_model, user_code_samples):# 低秩適配器微調lora_config = LoraConfig(r=8,target_modules=["q_proj", "v_proj"],task_type=TaskType.CAUSAL_LM)return get_peft_model(base_model, lora_config)
- 實時協作增強:多人編程的AI協調者
class CollaborationAgent:def resolve_conflict(self, version_a, version_b):prompt = f"""[代碼合并任務]版本A:{version_a}版本B:{version_b}請保留雙方功能并解決沖突"""return llm_inference(prompt)
結語:開發者主權時代的來臨
實測數據顯示,該方案使日常編碼效率提升約40%,復雜算法實現時間縮短60%。更重要的是,它標志著開發者重新掌控AI工具的核心能力——不再受限于云服務商的規則約束,而是根據自身需求打造專屬的智能編程伙伴。
構建本地化智能編程助手的意義遠超過優化幾個技術指標。它猶如一面棱鏡,折射出當代開發者面臨的深刻悖論:在AI輔助編程帶來指數級效率提升的同時,我們正不知不覺間讓渡著最珍貴的創造主權。這場技術實踐帶給我的震撼與啟示,遠比代碼行數更值得書寫。









)







——CDN)

