在云原生和微服務架構盛行的今天,監控系統已成為保障業務穩定性的核心基礎設施。作為監控領域的標桿工具,Prometheus和Grafana憑借其高效的數據采集、靈活的可視化能力,成為運維和開發團隊的“標配”。
一、Prometheus
Prometheus誕生于2012年,由SoundCloud開發并捐贈給CNCF基金會,現已成為繼Kubernetes之后最受歡迎的云原生項目之一。
1. 核心特性
- 多維數據模型:通過
<metric name>{<label1>=<value1>, ...}的格式記錄數據,支持按標簽動態分類(如區分不同服務的HTTP請求延遲)。 - PromQL查詢語言:提供強大的時間序列數據分析能力,例如計算CPU使用率的滑動平均值:
avg_over_time(node_cpu_seconds_total{mode="idle"}[5m])
- Pull/Push混合模式:默認通過HTTP主動拉取目標數據,同時支持通過Pushgateway接收短期任務推送的指標。
- 分布式高可用:支持聯邦集群架構,實現跨數據中心的數據聚合。
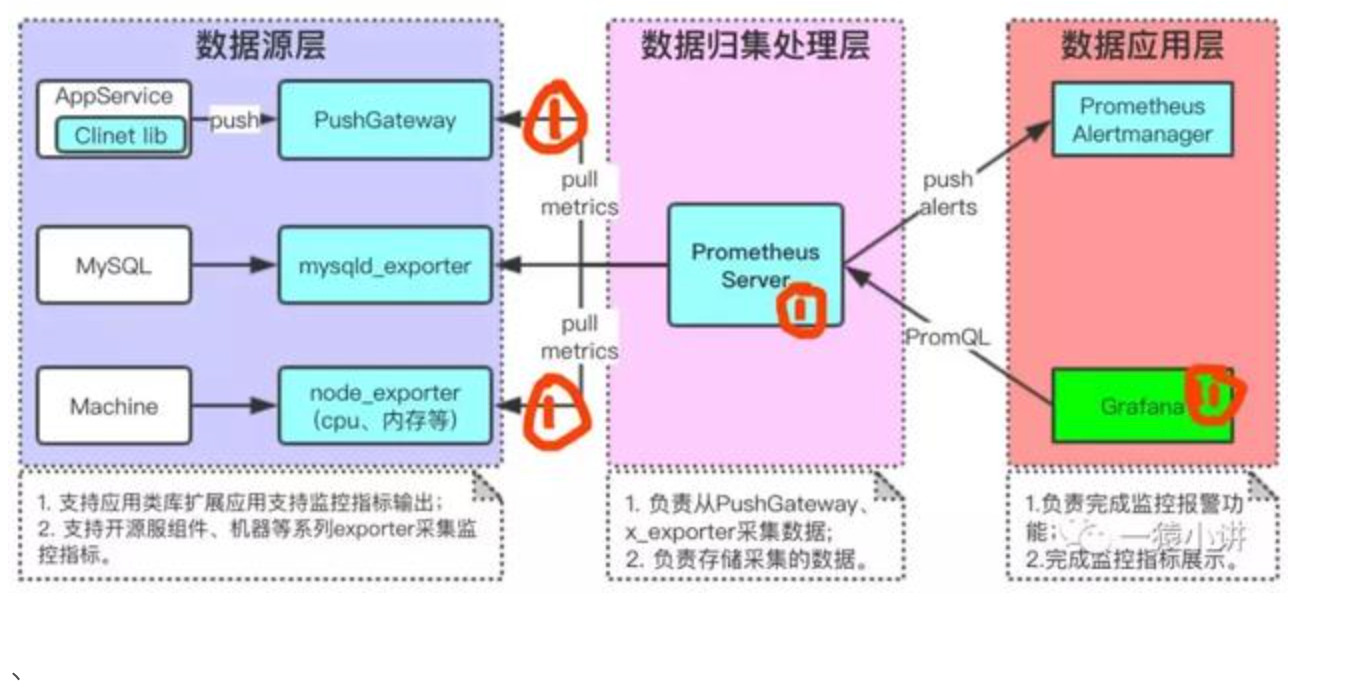
2. 架構組件
體系結構
下圖說明了Prometheus的體系結構及其某些生態系統組件:
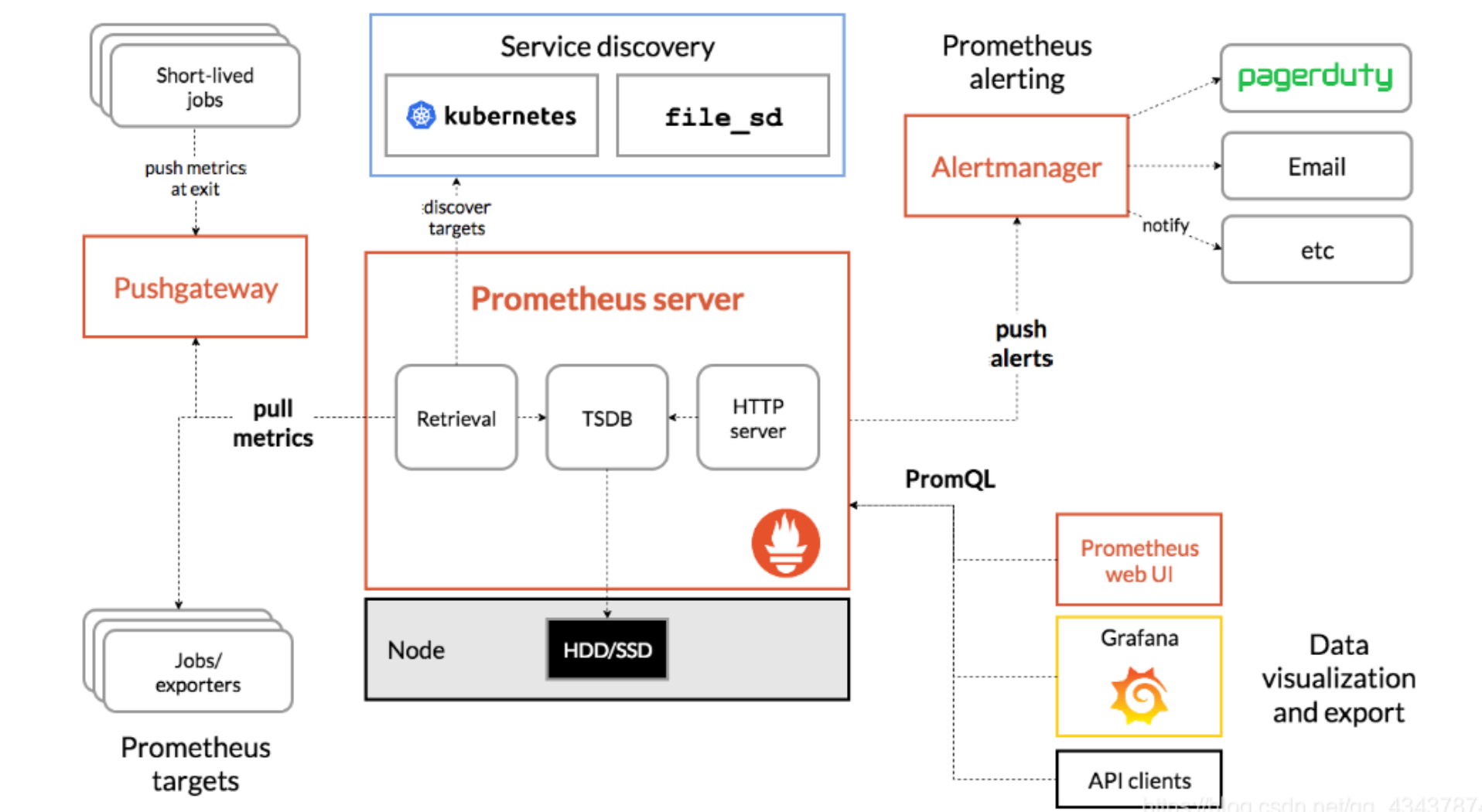
Prometheus體系涉及的組件
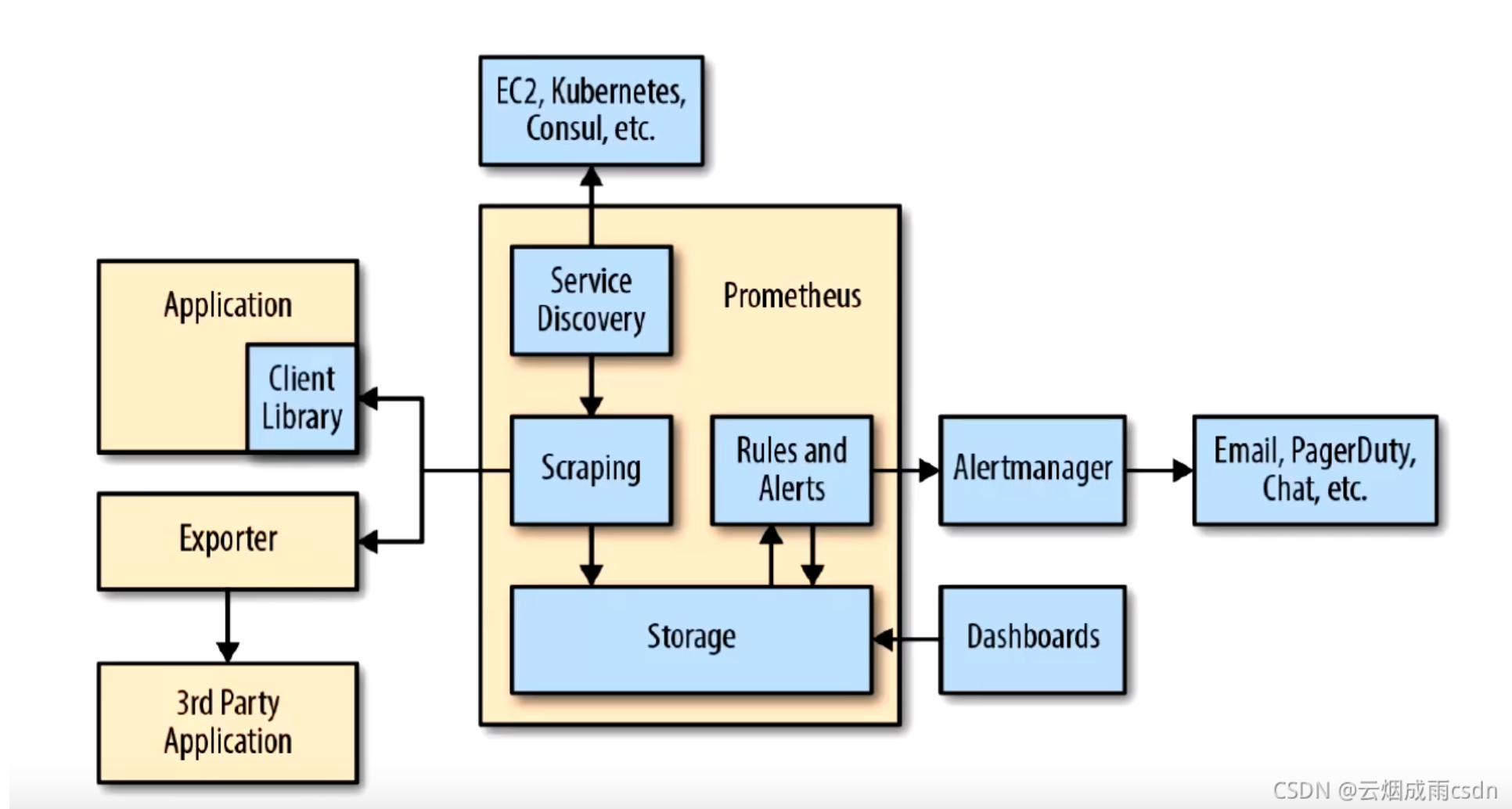
- Prometheus server - 收集和存儲時間序列數據
- Client Library: 客戶端庫,為需要監控的服務生成相應的
- metrics 并暴露給 - Prometheus server。當 Prometheus server 來 pull 時,直接返回實時狀態的 metrics。
- pushgateway - 對于短暫運行的任務,負責接收和緩存時間序列數據,同時也是一個數據源
- exporter - 各種專用exporter,面向硬件、存儲、數據庫、HTTP服務等
- alertmanager - 處理報警
- webUI等,其他各種支持的工具,本身的界面值適合用來語句查詢,數據可視化,需要第三方組件,比如Grafana。
3.如何收集度量值
度量指標由監控系統執行的過程通常可以分為兩種方法:推和拉。
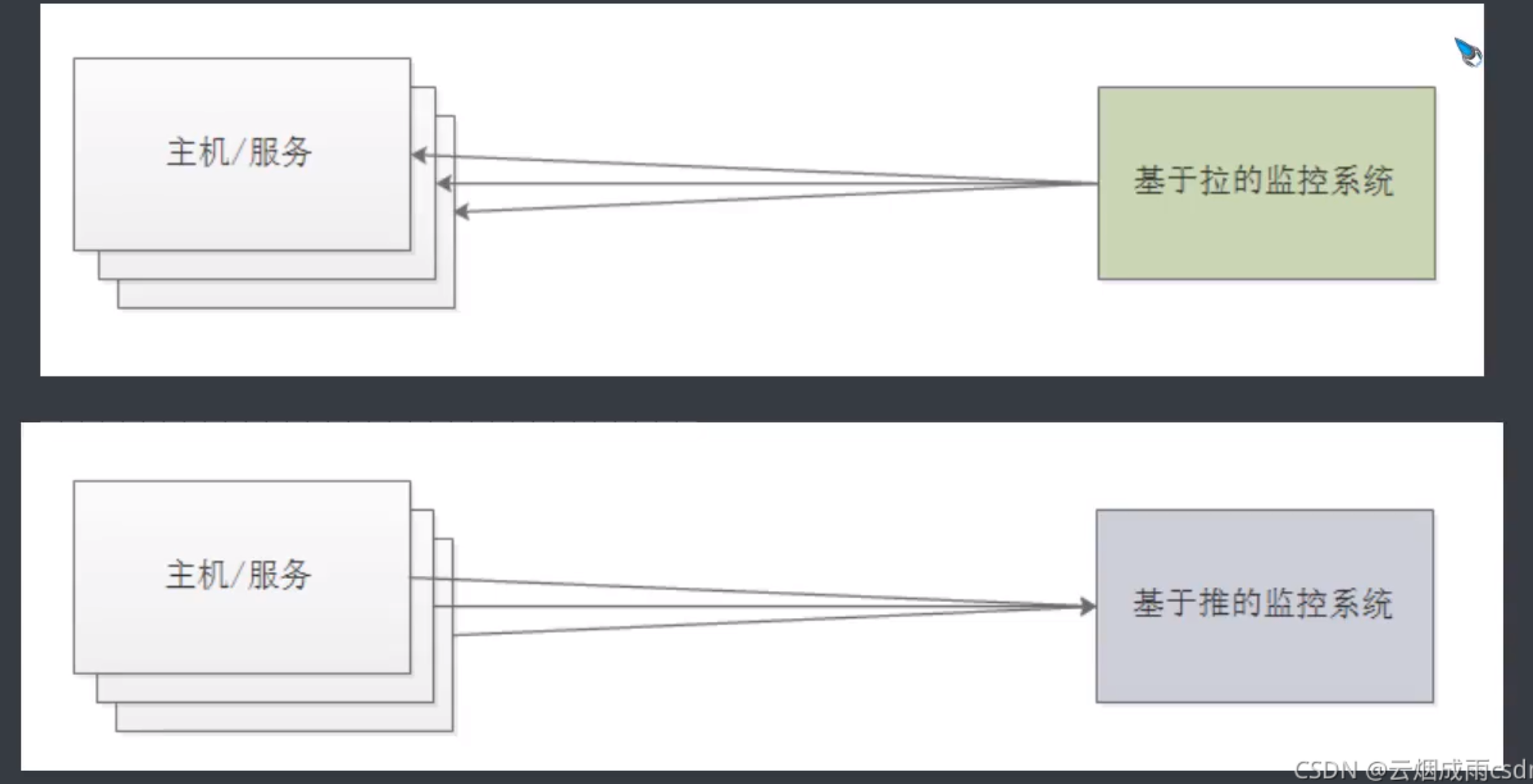
Prometheus基于HTTP call,從配置文件中指定的網絡端點(endpoint)上周期性獲取指標數據。
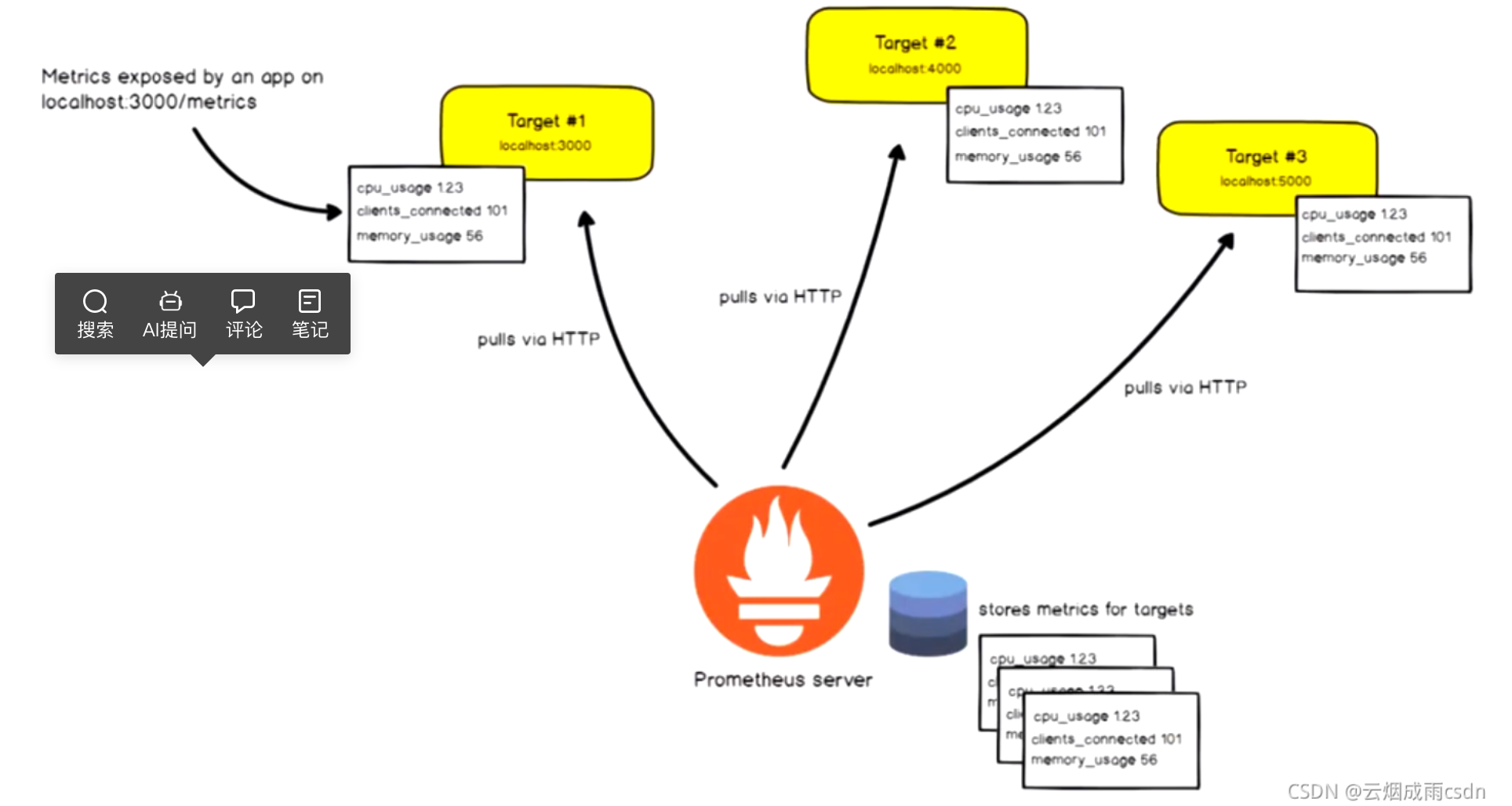
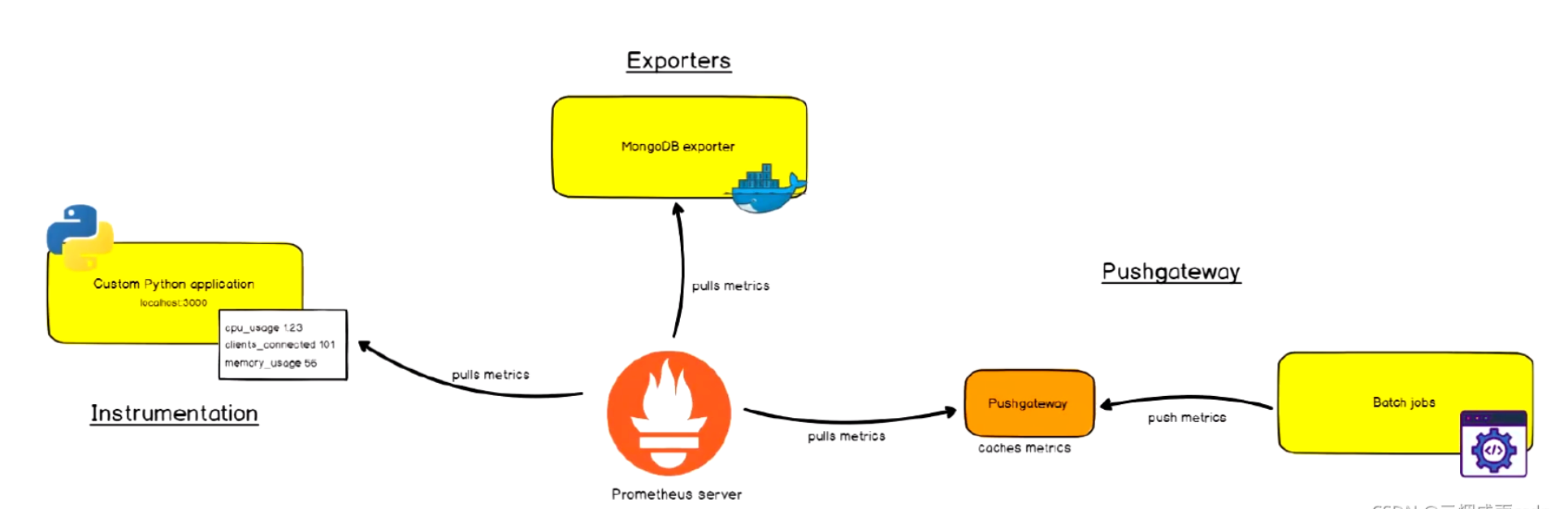
Prometheus支持通過三種類型的途徑從目標上“抓取(Serape)”指標數據:
Exporters:被監控的目標不支持pro的數據格式,通過exporters抽取指標數據,進行格式化處理成pro兼容的數據格式,再響應給pro server。
Instrumentation:應用系統內建了pro兼容的指標數據格式,pro server可以直接采集。
Push gateway:pro采用 pull 模式,可能由于不在一個子網或者防火墻原因,導致 Prometheus 無法直接拉取各個 target 數據。在監控業務數據的時候,需要將不同數據匯總, 由 Prometheus 統一收集。暫存在pushgateway,等待Prometheus server拉取。
二、Grafana
Grafana作為開源可視化領域的“瑞士軍刀”,能夠將Prometheus的原始數據轉化為直觀的運維儀表盤。
1. 核心優勢
- 多數據源支持:無縫集成Prometheus、Loki、InfluxDB、Elasticsearch等30+數據源。
- 動態儀表盤:提供折線圖、熱力圖、統計面板等10+圖表類型,支持通過變量實現交互式過濾(如按環境/服務篩選)。
- 告警可視化:可在圖表中直接標注閾值告警點,并結合Alertmanager實現分級通知。
- 模板生態:官方市場提供1.5萬+預置模板,例如:
- 主機監控模板(ID: 8919)
- MySQL性能分析模板(ID: 11329)
- Kubernetes集群監控模板(ID: 315)
2. 高級功能
- 混合數據源:在同一面板中對比不同系統的數據(如同時展示Prometheus的CPU指標和Elasticsearch的日志量)。
- 權限管控:支持基于角色的訪問控制(RBAC),細化到儀表盤級別的權限管理。
三、協同工作流
- 數據采集
Node Exporter采集主機CPU/內存指標,cAdvisor收集容器資源使用情況,應用通過Client Library暴露自定義指標(如Spring Boot的HTTP請求數)。 - 存儲分析
Prometheus每15秒拉取一次數據,存儲至TSDB,并通過PromQL實現實時分析。例如檢測內存泄漏:
increase(container_memory_usage_bytes{container="app"}[1h]) > 1GB
- 可視化展示
在Grafana中創建儀表盤,組合多個圖表形成監控全景(圖2)。例如:- 實時顯示服務的QPS、錯誤率、響應時間百分位數
- 通過GeoMap插件展示全球用戶的訪問延遲分布
- 智能告警
當Prometheus檢測到指標異常(如錯誤率>5%持續5分鐘),Alertmanager會觸發Grafana通知,并自動生成事件時間線供事后分析。
四、典型應用場景
- 基礎設施監控
通過Node Exporter+主機模板(圖3),實時跟蹤服務器CPU/磁盤/網絡狀態,預測硬件故障。 - 微服務觀測
結合Istio等服務網格,監控服務間調用的黃金指標(吞吐量、錯誤率、飽和度)。 - CI/CD健康度
分析流水線的構建時長、失敗原因,優化Jenkins任務調度策略。 - 業務指標可視化
將訂單成交量、用戶活躍度等業務指標接入,實現技術與業務數據的聯動分析。
五、最佳實踐
- 指標設計規范
- 遵循
<service>_<metric>_<unit>命名規則(如http_requests_total) - 避免高基數標簽(如用戶ID會導致時序爆炸)
- 遵循
- 性能優化
- 設置合理的抓取間隔(生產環境建議30-60秒)
- 使用Recording Rules預計算常用查詢
- 可視化策略
- 關鍵指標采用紅/黃/綠狀態標識
- 在儀表盤頂部放置全局過濾器(如環境/數據中心)


)




 的潛在風險與安全使用指南)





)


Java/python/JavaScript/C/C++/GO最佳實現)

)
