一、前言
在日常業務需求中,往往會遇到解析pdf文件中的段落或者表格數據的需求。
常見的做法是使用 pdfbox 來做,但是它只能提取文本數據,沒有我們在文件頁面上面的那種結構化組織,文本通常是散亂的包含各種換行回車空格等格式,因而它適合做一些段落文本提取。
而 tabula 在 pdfbox 的基礎上做了表格的特殊處理,能夠直接讀取到單元格中的內容,但是它處理的前提是表格必須常規完整邊框的表格,只有部分邊框或者無邊框的這種結構化數據還是束手無策。
針對上述情況,筆者實現了有邊框和無邊框表格的數據讀取并結構化,也支持段落文本提取。
二、功能實現
2.1 引入依賴
<!-- PDF解析,內含pdfbox -->
<dependency><groupId>technology.tabula</groupId><artifactId>tabula</artifactId><version>1.0.5</version>
</dependency>
2.2 完整邊框表格
- 支持多表格
- 支持分頁
- 支持跳過標題行
- 支持跳過標題前無關行
- 支持生成字段
- 返回完整集合數據
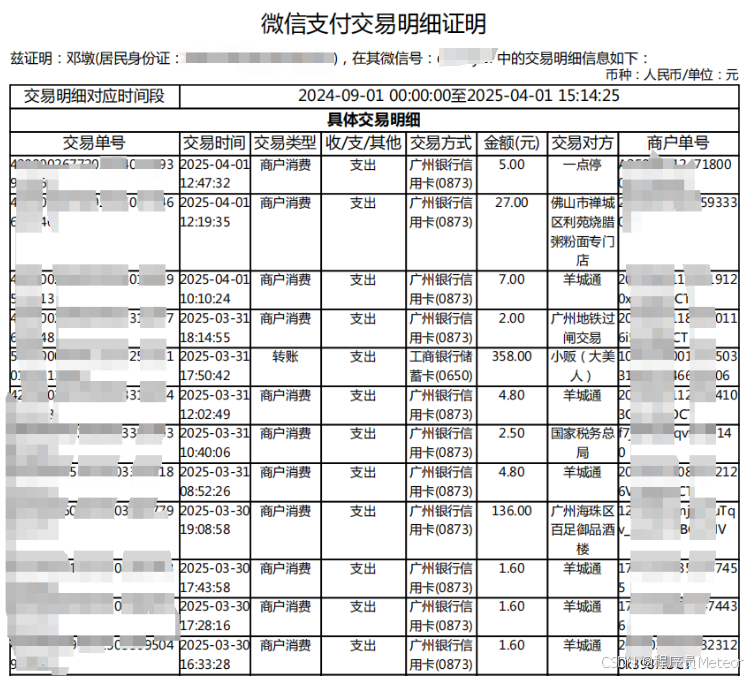
2.2.1 代碼實現
package com.qiangesoft.pdf.util;import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import technology.tabula.*;
import technology.tabula.extractors.SpreadsheetExtractionAlgorithm;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/*** pdf工具類* ps:適合解析純文本、解析表格數據** @author qiangesoft* @date 2025-05-28*/
@Slf4j
public class PdfUtil {public static void main(String[] args) throws FileNotFoundException {String txt = readTxtFromPdf("C:\\Users\\admin\\Desktop\\微信流水.pdf", null);System.out.println(txt);List<List<Map<String, String>>> dataGroupList = readTableDataFromPdf("C:\\Users\\admin\\Desktop\\微信流水.pdf", null, true);for (List<Map<String, String>> list : dataGroupList) {for (Map<String, String> map : list) {System.out.println(JSON.toJSONString(map));}}}/*** 解析pdf的文本數據** @param filePath 文件路徑* @param password 文件密碼* @return*/public static String readTxtFromPdf(String filePath, String password) throws FileNotFoundException {return readTxtFromPdf(new FileInputStream(filePath), password);}/*** 解析pdf的文本數據** @param inputStream 文件流* @param password 文件密碼* @return*/public static String readTxtFromPdf(InputStream inputStream, String password) {String textContent = "";try (PDDocument document = PDDocument.load(inputStream, password)) {PDFTextStripper stripper = new PDFTextStripper();textContent = stripper.getText(document);} catch (IOException e) {e.printStackTrace();}return textContent;}/*** 解析pdf的表格數據** @param filePath 文件路徑* @param password 文件密碼* @param skipFirstRow 是否跳過表頭行 【連續分頁表格可能每頁有表頭】* @return*/public static List<List<Map<String, String>>> readTableDataFromPdf(String filePath, String password, boolean skipFirstRow) throws FileNotFoundException {return readTableDataFromPdf(new FileInputStream(filePath), password, skipFirstRow);}/*** 解析pdf的表格數據** @param inputStream 文件流* @param password 文件密碼* @param skipFirstRow 是否跳過表頭行* @return*/public static List<List<Map<String, String>>> readTableDataFromPdf(InputStream inputStream, String password, boolean skipFirstRow) {// 按照同一個表格分組List<List<Map<String, String>>> dataGroupList = new ArrayList<>();// 表格提取算法SpreadsheetExtractionAlgorithm algorithm = new SpreadsheetExtractionAlgorithm();try (PDDocument document = PDDocument.load(inputStream, password)) {ObjectExtractor extractor = new ObjectExtractor(document);PageIterator pi = extractor.extract();// 遍歷頁double x = 0;int tableIndex = 0;int tableHeadRowNum = 0;List<Table> tables = new ArrayList<>();List<String> fieldList = new ArrayList<>();while (pi.hasNext()) {Page page = pi.next();List<Table> tableList = algorithm.extract(page);// 遍歷表格for (Table table : tableList) {if (tableIndex == 0) {tableHeadRowNum = getTableHeadRowNum(table, fieldList);tables.add(table);tableIndex++;} else {// 第一個 or x軸且列數相同為同一個表格if (new BigDecimal(table.getX()).subtract(new BigDecimal(x)).abs().compareTo(new BigDecimal("0.001")) <= 0&& fieldList.size() == table.getRows().get(0).size()) {tables.add(table);} else {List<Map<String, String>> dataList = convertTableToMap(tables, fieldList, tableHeadRowNum, skipFirstRow);dataGroupList.add(dataList);tables = new ArrayList<>();tables.add(table);tableIndex = 0;}}x = table.getX();}}// 最后一個特殊處理if (!tables.isEmpty()) {List<Map<String, String>> dataList = convertTableToMap(tables, fieldList, tableHeadRowNum, skipFirstRow);dataGroupList.add(dataList);}} catch (Exception e) {e.printStackTrace();}return dataGroupList;}/*** 獲取字段并返回表格頭的行** @param table 表格* @param fieldList 字段列表* @return*/private static int getTableHeadRowNum(Table table, List<String> fieldList) {// 獲取表格頭int headRowNum = 0;List<List<RectangularTextContainer>> rowList = table.getRows();for (int i = 0; i < rowList.size(); i++) {fieldList.clear();List<RectangularTextContainer> cellList = rowList.get(i);int k = 0;for (int j = 0; j < cellList.size(); j++) {RectangularTextContainer cell = cellList.get(j);if (cell instanceof Cell) {k++;fieldList.add("k" + k);}}if (fieldList.size() == cellList.size()) {headRowNum = i;break;}}return headRowNum;}/*** 將表格數據轉為映射數據** @param tableList 表格列表* @param fieldList 字段列表* @param tableHeadRowNum 表格頭行* @param skipFirstRow 是否跳過表頭行* @return*/private static List<Map<String, String>> convertTableToMap(List<Table> tableList, List<String> fieldList, int tableHeadRowNum, boolean skipFirstRow) {List<Map<String, String>> dataList = new ArrayList<>();for (int i = 0; i < tableList.size(); i++) {// 表格所有行Table table = tableList.get(i);List<List<RectangularTextContainer>> rowList = table.getRows();// 遍歷行for (int j = (i == 0 ? tableHeadRowNum + 1 : skipFirstRow ? 1 : 0); j < rowList.size(); j++) {List<RectangularTextContainer> cellList = rowList.get(j);Map<String, String> data = new HashMap<>();// 遍歷列for (int m = 0; m < cellList.size(); m++) {RectangularTextContainer cell = cellList.get(m);// 去除換行符后設置值String text = cell.getText().replace("\r", "");data.put(fieldList.get(m), text);}dataList.add(data);}}return dataList;}/*** 讀取指定文字中間的文本** @param txt 文本* @param startStr 開始字符串* @param endStr 結束字符串* @return*/public static String readTxtFormTxt(String txt, String startStr, String endStr) {int index1 = txt.indexOf(startStr);if (index1 == -1) {return null;}int index2 = txt.length();if (endStr != null) {index2 = txt.indexOf(endStr);if (index2 == -1) {index2 = txt.length();}}return txt.substring(index1 + startStr.length(), index2);}}2.2.2 解析結果
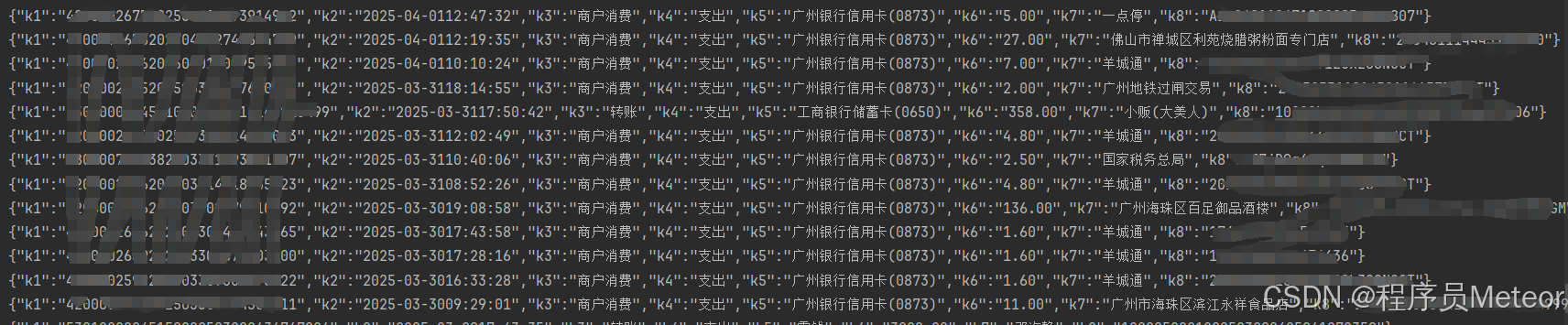
2.3 無邊框表格
- 支持單表格
- 支持分頁
- 支持跳過標題行
- 支持生成字段
- 返回完整集合數據
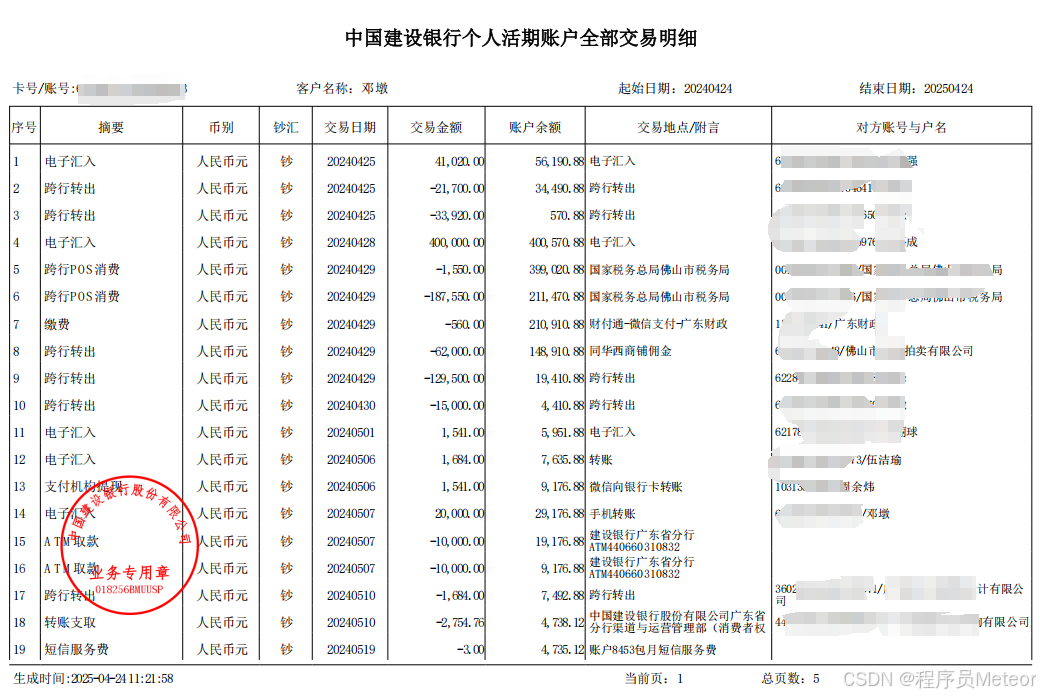
2.3.1 代碼實現
package com.qiangesoft.pdf.util;import com.alibaba.fastjson.JSONObject;
import org.springframework.util.CollectionUtils;import java.io.IOException;
import java.util.*;/*** pdf規則數據分析工具類* ps:分析處理PdfUtil解決不了的表格,沒有格子** @author qiangesoft* @date 2025-05-28*/
public class PdfRuleDataUtil {public static void main(String[] args) throws IOException {String fileTxt = PdfUtil.readTxtFromPdf("C:\\Users\\admin\\Desktop\\流水文件\\中國建設銀行.pdf", null);System.out.println(readTxt(fileTxt, "卡號/賬號:", "客戶名稱:").trim());System.out.println(readTxt(fileTxt, "客戶名稱:", "起始日期:").trim());System.out.println(readTxt(fileTxt, "起始日期:", "結束日期:").trim());System.out.println(readTxt(fileTxt, "結束日期:", "序號").trim());List<Map<String, String>> dataList = readTableData(fileTxt, "序號 摘要 幣別 鈔匯 交易日期 交易金額 賬戶余額 交易地點/附言 對方賬號與戶名", "生成時間:");for (Map<String, String> map : dataList) {System.out.println(JSONObject.toJSONString(map));}}/*** 解析文本** @param fileTxt* @param startStr* @param endStr* @return*/public static String readTxt(String fileTxt, String startStr, String endStr) {return PdfUtil.readTxtFormTxt(fileTxt, startStr, endStr);}/*** 解析表格數據** @param fileTxt 文本數據* @param startStr 開始字符串 【一般為標題行,字段根據標題行定,***很重要***】* @param endStr 結束字符串 【結束標志,如果表格連續中間沒有重復的標題行則直接使用表格末尾的結束標志即可,如果表格不連續每頁都有標題行則使用每頁的結束標志】* @return*/public static List<Map<String, String>> readTableData(String fileTxt, String startStr, String endStr) {int length = startStr.trim().split(" ").length;List<String> fieldList = new ArrayList<>();for (int i = 1; i <= length; i++) {fieldList.add("k" + i);}List<Map<String, String>> lists = new ArrayList<>();while (true) {String dataStr = readTxt(fileTxt, startStr, endStr);if (dataStr == null) {break;}List<Map<String, String>> pageLists = readDataFromTxt(dataStr, startStr, fieldList);fileTxt = fileTxt.substring(fileTxt.indexOf(endStr) + endStr.length());if (CollectionUtils.isEmpty(pageLists)) {break;} else {lists.addAll(pageLists);}}return lists;}/*** 解析pdf的文本數據* ps:通過換行符進行分割行,然后根據空格分割列【如果列中數據存在空格則無法解決】** @param dataStr 待解析的文本* @param tableHeadTxt 標題行文本* @param fieldList 字段列表* @return*/private static List<Map<String, String>> readDataFromTxt(String dataStr, String tableHeadTxt, List<String> fieldList) {List<Map<String, String>> dataList = new ArrayList<>();int cellNum = fieldList.size();// "\r\n" or "\n"String[] split = dataStr.split(System.lineSeparator());StringBuilder chargeStr = new StringBuilder();for (int a = 0; a < split.length; a++) {String itemStr = split[a];// 標題行跳過if (itemStr.contains(tableHeadTxt)) {continue;}String[] split1;if (!chargeStr.toString().isEmpty()) {// 上一行未處理【加上本行一起處理】chargeStr.append(itemStr);split1 = chargeStr.toString().split(" ");} else {split1 = itemStr.split(" ");}if (split1.length < cellNum) { // 不足列數// 拼接本行if (chargeStr.toString().isEmpty()) {chargeStr.append(itemStr);}// 最后一行特殊處理if (a == split.length - 1) {Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split1.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split1[i]);}}dataList.add(dataMap);}} else if (split1.length > cellNum) { // 超過列數if (!chargeStr.toString().isEmpty()) {// 處理上一行String[] split2 = chargeStr.toString().replace(itemStr, "").split(" ");Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split2.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split2[i]);}}dataList.add(dataMap);}// 處理本行chargeStr = new StringBuilder();String[] split3 = itemStr.split(" ");if (split3.length < cellNum) { // 本行不足列數// 拼接本行if (chargeStr.toString().isEmpty()) {chargeStr.append(itemStr);}// 最后一行特殊處理if (a == split.length - 1) {Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split3.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split3[i]);}}dataList.add(dataMap);}} else { // 本行大于等于列數Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split3.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split3[i]);}}dataList.add(dataMap);}} else { // 等于列數Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {dataMap.put(fieldList.get(i), split1[i]);}dataList.add(dataMap);chargeStr = new StringBuilder();}}return dataList;}}2.3.2 解析結果

2.4 解析段落

2.4.1 代碼實現
/*** 讀取指定文字中間的文本** @param txt 文本* @param startStr 開始字符串* @param endStr 結束字符串* @return*/public static String readTxtFormTxt(String txt, String startStr, String endStr) {int index1 = txt.indexOf(startStr);if (index1 == -1) {return null;}int index2 = txt.length();if (endStr != null) {index2 = txt.indexOf(endStr);if (index2 == -1) {index2 = txt.length();}}return txt.substring(index1 + startStr.length(), index2);}
2.4.2 解析結果

三、源碼倉庫
碼云:https://gitee.com/qiangesoft/boot-business/tree/master/boot-business-pdf



)










)


)


