文章目錄
- 附近商鋪
- GEOSEARCH 實現
- 語法
- 參數解釋
- GEORADIUS 實現
- 基本語法
- 參數詳解
- 必選參數
- 可選參數
- 參數詳解
- 必選參數
- 代碼實現
- 用戶簽到
- Bitmap
- Redis 中 Bitmap 基本操作
- 1. 設置位值
- 2. 獲取位值
- 3. 統計位值為 1 的數量
- 4. 位圖運算
- Spring Data Redis 中操作 Bitmap
- 1. 操作示例
- (1) 設置某一位的值
- (2) 獲取某一位的值
- (3) 統計位圖中值為1的位數
- (4) 位運算(AND/OR/XOR/NOT)
- 實現簽到
- 實現簽到統計
- 另一種實現方法
- UV統計
- 基本定義
- HyperLoglog
- 應用場景
- 基本原理
- Redis 中 HyperLogLog 命令
- 1. `PFADD`
- 2. `PFCOUNT`
- 3. `PFMERGE`
- Spring Data Redis 操作 HyperLogLog
- add
- size
- union
- HyperLogLog的優勢
- 內存占用極少
- 計算速度快
- 近似精度可控
附近商鋪
GEOSEARCH 實現
GEOSEARCH 是 Redis 6.2 及以上版本引入的一個命令,用于在有序集合(ZSet)中根據地理位置信息進行搜索。它可以基于給定的經緯度坐標和半徑范圍,查找符合條件的元素,同時還能按距離排序并返回距離信息。
語法
GEOSEARCH key
[FROMLONLAT longitude latitude | FROMMEMBER member]
[BYRADIUS radius m|km|ft|mi | BYBOX width height m|km|ft|mi]
[ASC|DESC]
[COUNT count [ANY]]
[WITHDIST]
[WITHCOORD]
[WITHHASH]
參數解釋
-
key:包含地理位置信息的有序集合的鍵名。 -
FROMLONLAT longitude latitude:指定搜索的中心點經緯度。 -
FROMMEMBER member:指定搜索的中心點為有序集合中的某個成員。 -
BYRADIUS radius m|km|ft|mi:以中心點為圓心,指定半徑范圍進行搜索,單位可以是米(m)、千米(km)、英尺(ft)或英里(mi)。 -
BYBOX width height m|km|ft|mi:以中心點為中心,指定矩形區域進行搜索。 -
ASC|DESC:指定結果按距離升序或降序排列。 -
COUNT count [ANY]:限制返回結果的數量,ANY 表示在找到 count 個結果后立即返回,不繼續遍歷。 -
WITHDIST:返回結果中包含元素與中心點的距離。 -
WITHCOORD:返回結果中包含元素的經緯度坐標。 -
WITHHASH:返回結果中包含元素的 Geohash 值。
GEORADIUS 實現
GEORADIUS 是 Redis 中用于基于地理位置信息進行范圍查詢的命令,它可以找出以給定經緯度為圓心、指定半徑范圍內的所有地理位置元素。下面詳細分析其參數。
基本語法
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count] [STORE key] [STOREDIST key]
參數詳解
必選參數
key- 描述:存儲地理位置信息的有序集合的鍵名。在 Redis 里,地理位置信息是以有序集合(
ZSet)的形式存儲的,每個元素代表一個地理位置,其成員是地理位置的名稱,分數是對應的 Geohash 值。 - 示例:
shops:geo表示存儲店鋪地理位置信息的有序集合。
- 描述:存儲地理位置信息的有序集合的鍵名。在 Redis 里,地理位置信息是以有序集合(
longitude和latitude- 描述:查詢的中心點的經緯度。經度范圍是 -180 到 180,緯度范圍是 -85.05112878 到 85.05112878。
- 示例:
116.404和39.915表示北京的大致經緯度。
radius- 描述:查詢的半徑大小。
- 示例:
2表示半徑為 2 個單位。
m|km|ft|mi- 描述:半徑的單位,可選項有米(
m)、千米(km)、英尺(ft)、英里(mi)。 - 示例:
km表示半徑單位為千米。
- 描述:半徑的單位,可選項有米(
可選參數
WITHCOORD- 描述:返回結果中包含元素的經緯度信息。
- 示例:
GEORADIUS shops:geo 116.404 39.915 2 km WITHCOORD,返回結果會包含每個店鋪的經緯度。
WITHDIST- 描述:返回結果中包含元素與中心點的距離,距離單位和查詢半徑的單位一致。
- 示例:
GEORADIUS shops:geo 116.404 39.915 2 km WITHDIST,返回結果會包含每個店鋪與中心點的距離。
WITHHASH- 描述:返回結果中包含元素的 Geohash 值。Geohash 是一種將經緯度編碼為字符串的方法。
- 示例:
GEORADIUS shops:geo 116.404 39.915 2 km WITHHASH,返回結果會包含每個店鋪的 Geohash 值。
ASC|DESC- 描述:指定返回結果按距離升序(
ASC)或降序(DESC)排列。 - 示例:
GEORADIUS shops:geo 116.404 39.915 2 km WITHDIST ASC,返回結果按距離中心點由近到遠排列。
- 描述:指定返回結果按距離升序(
COUNT count- 描述:限制返回結果的數量,
count是一個正整數。 - 示例:
GEORADIUS shops:geo 116.404 39.915 2 km WITHDIST ASC COUNT 5,只返回距離最近的 5 個店鋪。
- 描述:限制返回結果的數量,
STORE key- 描述:將查詢結果的元素名稱存儲到指定的有序集合中,存儲的分數是元素與中心點的距離。原查詢結果不會返回,而是返回存儲的元素數量。
- 示例:
GEORADIUS shops:geo 116.404 39.915 2 km STORE nearby_shops,將符合條件的店鋪名稱存儲到nearby_shops有序集合中。
STOREDIST key- 描述:將查詢結果的元素名稱和距離存儲到指定的有序集合中,存儲的分數是元素與中心點的距離。原查詢結果不會返回,而是返回存儲的元素數量。
- 示例:
GEORADIUS shops:geo 116.404 39.915 2 km STOREDIST nearby_shops_with_dist,將符合條件的店鋪名稱和距離存儲到nearby_shops_with_dist有序集合中。
在 Spring Data Redis 里,GEORADIUS 命令通過 stringRedisTemplate.opsForGeo().radius() 方法實現,下面詳細分析相關參數。
radius() 方法重載形式
主要有兩種重載形式:
GeoResults<RedisGeoCommands.GeoLocation<String>> radius(String key, Circle within);
GeoResults<RedisGeoCommands.GeoLocation<String>> radius(String key, Circle within, RedisGeoCommands.GeoRadiusCommandArgs args);
參數詳解
必選參數
key
含義:存儲地理位置信息的有序集合的鍵名,對應 Redis GEORADIUS 命令中的 key。
示例:
String key = “shops:geo”;
Circle within
含義:定義查詢范圍,包含中心點和半徑。Circle 由 Point 和 Distance 組成,Point 表示中心點經緯度,Distance 表示半徑及單位。對應 Redis GEORADIUS 命令中的 longitude、latitude、radius 和 m|km|ft|mi。
代碼實現
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {// 1.判斷是否需要根據坐標查詢if (x == null || y == null) {// 不需要坐標查詢,按數據庫查詢// 根據類型分頁查詢Page<Shop> page = query().eq("type_id", typeId).page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));// 返回數據return Result.ok(page.getRecords());}// 2.計算分頁參數int begin = (current - 1) * SystemConstants.MAX_PAGE_SIZE;int end = begin + SystemConstants.MAX_PAGE_SIZE;// 3.查詢redis、按照距離排序、分頁。結果:shopId、distanceString key = SHOP_GEO_KEY + typeId;// GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE// 構建GEO查詢參數RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().sortAscending().limit(end);// 查詢店鋪信息GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo().radius(key, new Circle(new Point(x, y), new Distance(5000)), args);// 結果為空返回空集合if (results == null) {return Result.ok(Collections.emptyList());}// 解析出distance,跳過begin以前Map<Long,Distance> distanceMap = results.getContent().stream().skip(begin).collect(Collectors.toMap(result ->Long.valueOf(result.getContent().getName()),GeoResult::getDistance,(existing, replacement) -> existing,LinkedHashMap::new));if (distanceMap.size() == 0) {return Result.ok(Collections.emptyList());}// 解析出id// keySet<Long> ids = distanceMap.keySet();String idsStr = StrUtil.join(",", ids);// 根據id查詢店鋪// sql: select * from tb_shop where id in (?, ?, ?) order by field(id, ?, ?, ?)List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idsStr + ")").list();// 遍歷店鋪,設置距離for (Shop shop : shops) {shop.setDistance(distanceMap.get(shop.getId()).getValue());}return Result.ok(shops);
}
用戶簽到
Bitmap
Bitmap 即位圖,在 Redis 里是一種特殊的數據類型,它借助字符串類型來實現位操作,本質上是二進制數組。每個位只能存儲 0 或 1,非常適合處理大量的布爾值,如用戶簽到、在線狀態等場景。下面介紹 Redis 中 Bitmap 的基本用法,同時給出 Spring Data Redis 里操作 Bitmap 的示例。
Redis 中 Bitmap 基本操作
1. 設置位值
使用 SETBIT 命令可以設置指定偏移量上的位值。
SETBIT key offset value
key:位圖的鍵名。offset:位的偏移量,從 0 開始。value:位的值,只能是 0 或 1。
示例:
SETBIT user:sign:1 0 1
上述命令將 user:sign:1 這個位圖在偏移量 0 處的值設置為 1。
2. 獲取位值
使用 GETBIT 命令可以獲取指定偏移量上的位值。
GETBIT key offset
key:位圖的鍵名。offset:位的偏移量,從 0 開始。
示例:
GETBIT user:sign:1 0
該命令會返回 user:sign:1 位圖在偏移量 0 處的值。
3. 統計位值為 1 的數量
使用 BITCOUNT 命令可以統計位圖中值為 1 的位的數量。
BITCOUNT key [start end]
key:位圖的鍵名。start和end(可選):指定字節范圍,用于統計該范圍內值為 1 的位的數量。
示例:
BITCOUNT user:sign:1
此命令會統計 user:sign:1 位圖中值為 1 的位的總數。
4. 位圖運算
使用 BITOP 命令可以對多個位圖進行邏輯運算,支持 AND、OR、XOR 和 NOT 操作。
BITOP operation destkey key [key ...]
operation:邏輯運算類型,如AND、OR、XOR、NOT。destkey:存儲運算結果的位圖鍵名。key [key ...]:參與運算的位圖鍵名。
示例:
BITOP AND result:and user:sign:1 user:sign:2
該命令對 user:sign:1 和 user:sign:2 兩個位圖進行邏輯與運算,并將結果存儲在 result:and 位圖中。
Spring Data Redis 中操作 Bitmap
1. 操作示例
(1) 設置某一位的值
@Autowired
private RedisTemplate<String, Object> redisTemplate;// 設置指定偏移量(offset)的位為 1 或 0
public void setBit(String key, long offset, boolean value) {redisTemplate.opsForValue().setBit(key, offset, value);
}// 示例:用戶ID=1001在2023-10-01簽到(標記為1)
setBit("sign:2023-10:1001", 0, true); // 第0位表示某一天
(2) 獲取某一位的值
public Boolean getBit(String key, long offset) {return redisTemplate.opsForValue().getBit(key, offset);
}// 示例:檢查用戶ID=1001在2023-10-01是否簽到
Boolean isSigned = getBit("sign:2023-10:1001", 0);
(3) 統計位圖中值為1的位數
public Long bitCount(String key) {return redisTemplate.execute((RedisCallback<Long>) conn -> conn.bitCount(key.getBytes()));
}// 示例:統計用戶ID=1001在2023-10月的簽到總天數
Long signCount = bitCount("sign:2023-10:1001");
(4) 位運算(AND/OR/XOR/NOT)
public void bitOp(RedisStringCommands.BitOperation op, String destKey, String... srcKeys) {redisTemplate.execute((RedisCallback<Long>) conn -> conn.bitOp(op, destKey.getBytes(), Arrays.stream(srcKeys).map(k -> k.getBytes()).toArray(byte[][]::new)));
}// 示例:計算兩個用戶簽到記錄的交集(AND)
bitOp(RedisStringCommands.BitOperation.AND, "sign:result", "sign:user1", "sign:user2");
通過以上操作,你可以在 Redis 和 Spring Data Redis 中使用 Bitmap 處理布爾值相關的業務場景。
實現簽到
@Override
public Result sign() {// 獲取當前登錄用戶Long userId = UserHolder.getUser().getId();// 當前日期LocalDateTime now = LocalDateTime.now();// keyString key = USER_SIGN_KEY + userId + ":" + now.getYear() + ":" + now.getMonth();// 獲取今天是本月的第幾天int dayOfMonth = now.getDayOfMonth();// 簽到,寫入redisstringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);return Result.ok();
}
實現簽到統計
@Override
public Result signCount() {// 獲取當前登錄用戶Long userId = UserHolder.getUser().getId();// 當前日期LocalDateTime now = LocalDateTime.now();// keyString key = USER_SIGN_KEY + userId + ":" + now.getYear() + ":" + now.getMonth();// 獲取今天是本月的第幾天int dayOfMonth = now.getDayOfMonth();// 簽到,寫入redis// BITFIELD key u4 0List<Long> result = stringRedisTemplate.opsForValue().bitField(key,BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));if (result == null || result.isEmpty()){return Result.ok(0);}Long num = result.get(0);if (num == null || num == 0) {return Result.ok(0);}int count = 0;while(num!=0){if((num&1)==1){count++;}num>>=1;}return Result.ok(count);
}
另一種實現方法
@Override
public Result signCount() {// 獲取當前登錄用戶Long userId = UserHolder.getUser().getId();// 當前日期LocalDateTime now = LocalDateTime.now();// keyString key = USER_SIGN_KEY + userId + ":" + now.getYear() + ":" + now.getMonth();// 獲取今天是本月的第幾天int dayOfMonth = now.getDayOfMonth();// 簽到,寫入redis// BITFIELD key u4 0Long cnt = stringRedisTemplate.execute((RedisCallback<Long>) conn -> conn.bitCount(key.getBytes()));return cnt;
}
UV統計
UV 是 Unique Visitor 的縮寫,即獨立訪客,UV 統計是互聯網領域中用于衡量網站、應用程序或特定頁面訪問量的重要指標,用于統計在一定時間內訪問某個站點或應用的不同用戶數量。下面從多個方面詳細介紹 UV 統計的相關概念。
基本定義
獨立訪客指的是在特定時間段內,訪問某一網站或應用的不同自然人。同一用戶在該時間段內多次訪問,僅計算為一個獨立訪客。比如,在一天內,用戶 A 訪問了某網站 5 次,用戶 B 訪問了 3 次,此時該網站當天的 UV 為 2。
HyperLoglog
在 Spring Data Redis 中使用 HyperLogLog (HLL) 進行 UV 統計,可以通過以下步驟實現。HyperLogLog 提供了一種高效且內存友好的方式來處理大規模獨立訪客統計,盡管存在約 0.81% 的誤差,但適用于大多數場景。
HyperLogLog 是一種概率型數據結構,由 Philippe Flajolet 及其同事在 2007 年提出,2011 年被集成到 Redis 中。它主要用于在犧牲一定精度的前提下,以極小的空間復雜度來統計海量數據的基數(集合中不同元素的個數)。下面從多個方面詳細介紹 HyperLogLog。
應用場景
在互聯網場景中,很多時候需要統計獨立訪客數(UV)、獨立 IP 數、搜索關鍵詞數量等,這些數據量可能非常龐大。若使用傳統數據結構(如 Set)來統計,隨著數據量增長,內存占用會急劇上升。而 HyperLogLog 能在保證一定精度的情況下,用極少的內存完成基數統計。
基本原理
HyperLogLog 基于伯努利試驗和概率統計原理。簡單來說,它把元素通過哈希函數映射為二進制串,記錄每個二進制串中從第一個位開始連續 0 的最大個數。根據這些最大 0 個數的統計信息,運用概率公式估算出集合的基數。
Redis 中 HyperLogLog 命令
1. PFADD
用于向 HyperLogLog 中添加元素。
PFADD key element [element ...]
key:HyperLogLog 的鍵名。element [element ...]:要添加的元素。
示例:
PFADD myhyperloglog user1 user2 user3
2. PFCOUNT
用于獲取 HyperLogLog 中元素的基數估計值。
PFCOUNT key [key ...]
key [key ...]:要統計的 HyperLogLog 鍵名,可以指定多個鍵,此時會返回這些鍵對應 HyperLogLog 合并后的基數估計值。
示例:
PFCOUNT myhyperloglog
3. PFMERGE
用于將多個 HyperLogLog 合并為一個。
PFMERGE destkey sourcekey [sourcekey ...]
destkey:合并后的 HyperLogLog 鍵名。sourcekey [sourcekey ...]:要合并的 HyperLogLog 鍵名。
示例:
PFMERGE mergedhyperloglog myhyperloglog1 myhyperloglog2
Spring Data Redis 操作 HyperLogLog
add
/*** 向 HyperLogLog 中添加元素* @param key HyperLogLog 鍵名* @param elements 要添加的元素*/
public void addElements(String key, String... elements) {stringRedisTemplate.opsForHyperLogLog().add(key, elements);
}
size
/*** 獲取 HyperLogLog 中元素的基數估計值* @param keys 要統計的 HyperLogLog 鍵名* @return 基數估計值*/
public Long getCount(String... keys) {return stringRedisTemplate.opsForHyperLogLog().size(keys);
}
union
/*** 合并多個 HyperLogLog* @param destKey 合并后的 HyperLogLog 鍵名* @param sourceKeys 要合并的 HyperLogLog 鍵名*/
public void mergeHyperLogLogs(String destKey, String... sourceKeys) {stringRedisTemplate.opsForHyperLogLog().union(destKey, sourceKeys);
}
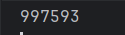
測試結果顯示997593條數據,HyperLoglog統計存在誤差,但是可以極大減少儲存空間的消耗同時增加查詢的性能。
HyperLogLog的優勢
內存占用極少
- 固定內存開銷:無論要統計的數據量有多大,HyperLogLog 在 Redis 中最多只需要 12KB 的內存空間。相比傳統的數據結構,如
Set或List,隨著數據量的增加,它們的內存占用會線性增長。而 HyperLogLog 能夠以恒定的內存來處理海量數據,例如統計每天訪問網站的獨立用戶數,即使訪問量達到百萬甚至千萬級別,內存占用也不會大幅上升。 - 空間效率高:在需要統計大量基數的場景下,使用 HyperLogLog 能顯著減少內存使用。例如,統計一個大型電商平臺的日活用戶數,若使用
Set存儲每個用戶的唯一標識,當用戶量達到億級時,內存占用會非常巨大;而使用 HyperLogLog 僅需 12KB,大大節省了內存資源。
計算速度快
- 操作復雜度低:HyperLogLog 的插入和查詢操作的時間復雜度都是 O(1)。插入元素時,只需對元素進行哈希計算并更新相應的統計信息;查詢基數時,直接根據統計信息進行估算,無需遍歷整個數據集。這使得在處理大量數據時,操作速度極快,能滿足高并發場景下的實時統計需求。
- 高效處理大數據:在高并發的互聯網應用中,需要實時統計大量的獨立元素,如實時統計在線用戶數、實時計算搜索關鍵詞的數量等。HyperLogLog 能夠快速完成插入和查詢操作,不會成為系統的性能瓶頸。
近似精度可控
- 合理的誤差范圍:HyperLogLog 雖然是概率型數據結構,返回的是基數的近似值,但誤差是可控的。在 Redis 中,HyperLogLog 的標準誤差約為 0.81%,在大多數實際應用場景下,這個誤差是可以接受的。例如,在統計網站的 UV 時,少量的誤差不會影響對網站流量整體趨勢的判斷。
- 滿足業務需求:對于一些對精度要求不是特別高的場景,如宏觀的流量統計、大致的用戶行為分析等,HyperLogLog 能在保證一定精度的前提下,提供高效的基數統計方案,滿足業務對數據快速獲取和分析的需求。





)



一塊轉為PDF)
)




)



