簡介
MTT S4000 是基于摩爾線程曲院 GPU 架構打造的全功能元計算卡,為千億規模大語言模型的訓練、微調和推理進行了定制優化,結合先進的圖形渲染能力、視頻編解碼能力和超高清 8K HDR 顯示能力,助力人工智能、圖形渲染、多媒體、科學計算與物理仿真等復合應用場景的計算加速。
MTT S4000 全面支持大語言模型的預訓練、微調和推理服務,MUSA 軟件棧專門針對大規模集群的分布式計算性能進行了優化,適配主流分布式計算加速框架, 包括 DeepSpeed, Colossal AI,Megatron 等,支持千億參數大語言模型的穩定預訓練。
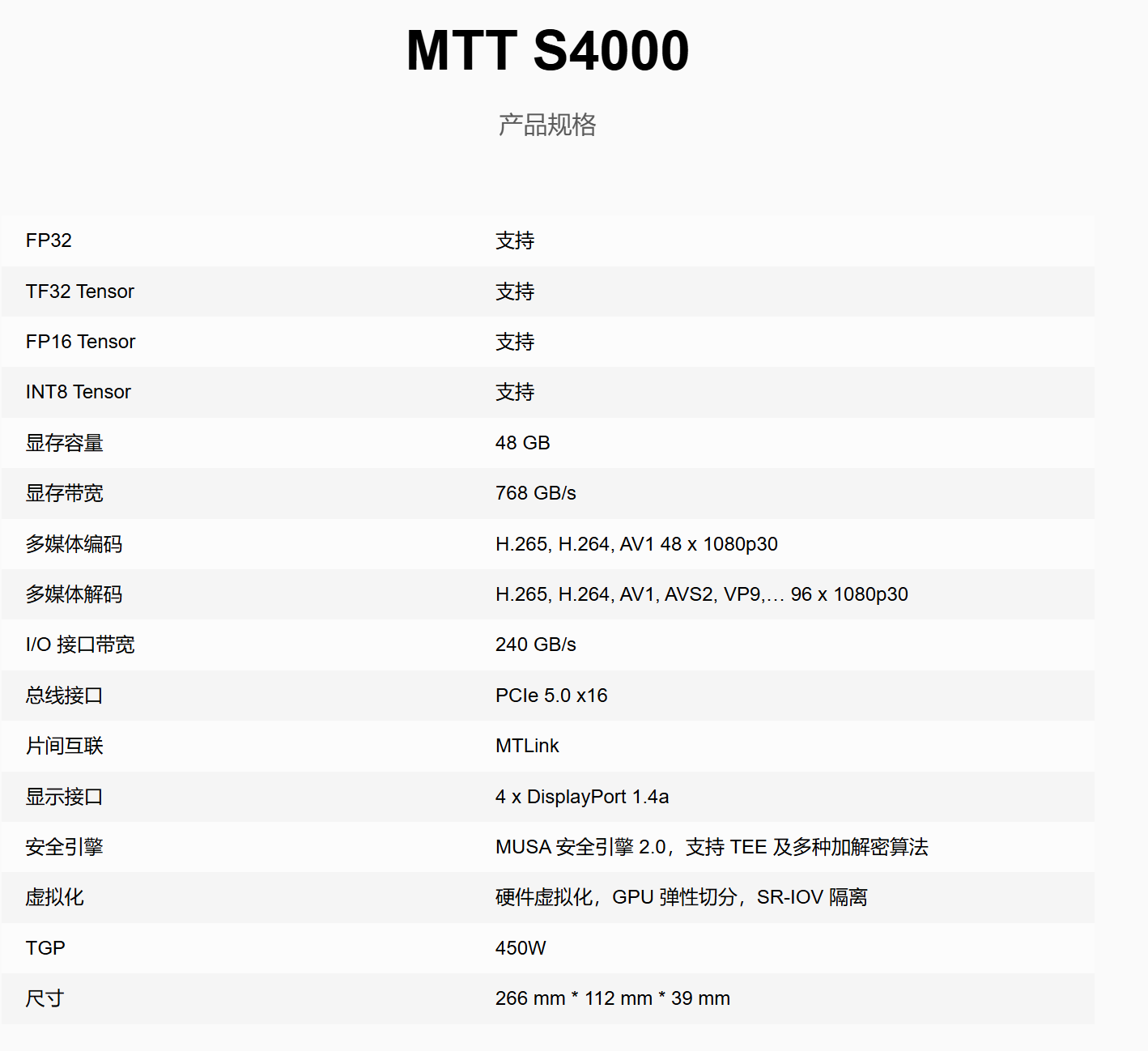
官方參數如下
運行環境
本次運行環境為AutoDL云中的鏡像環境,系統環境如下

常用命令
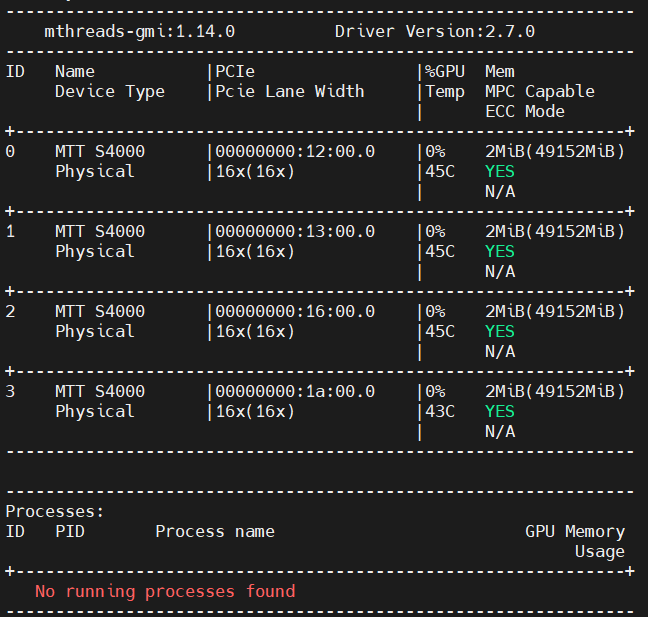
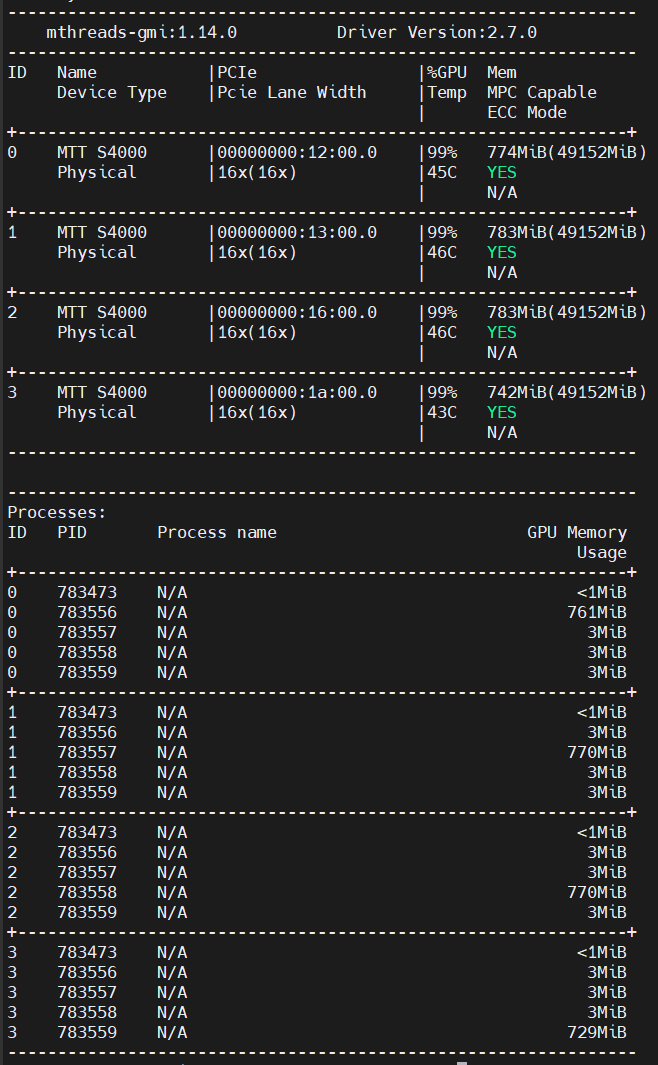
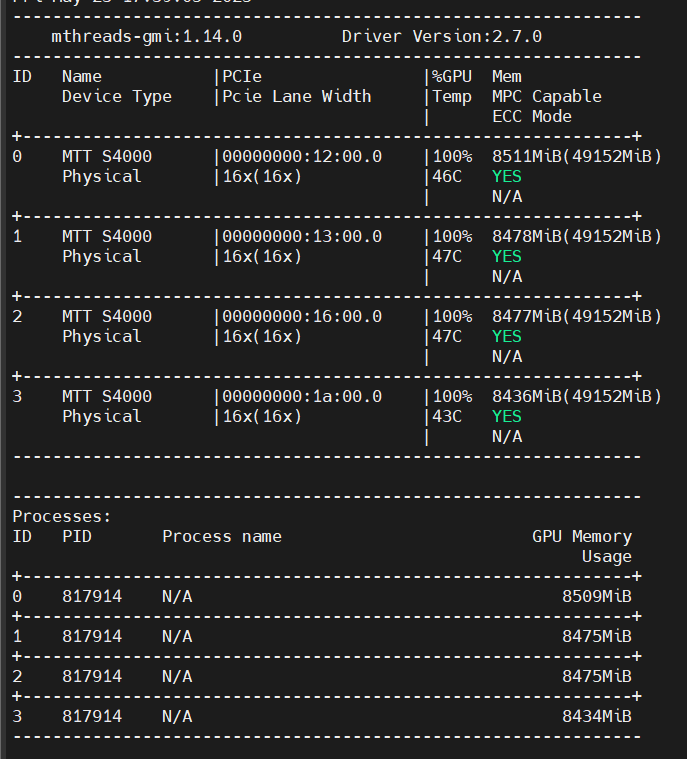
顯卡運行狀態
輸入如下命令
mthreads-gmi
即可查看當前顯卡運行狀態
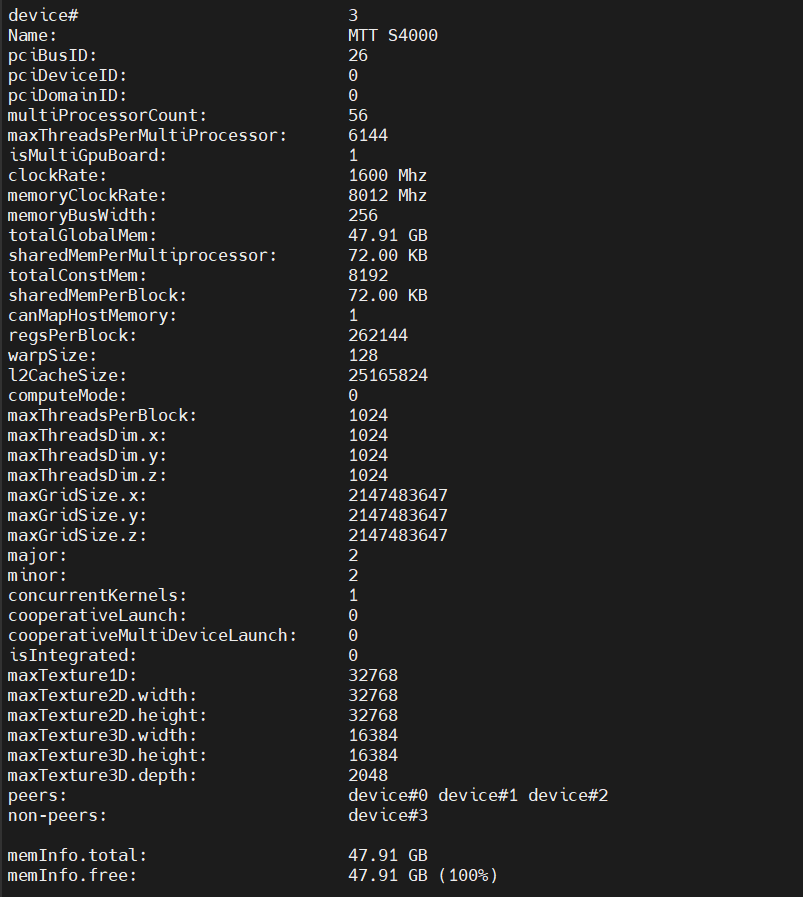
查看當前GPU詳細信息
輸入
musaInfo即可
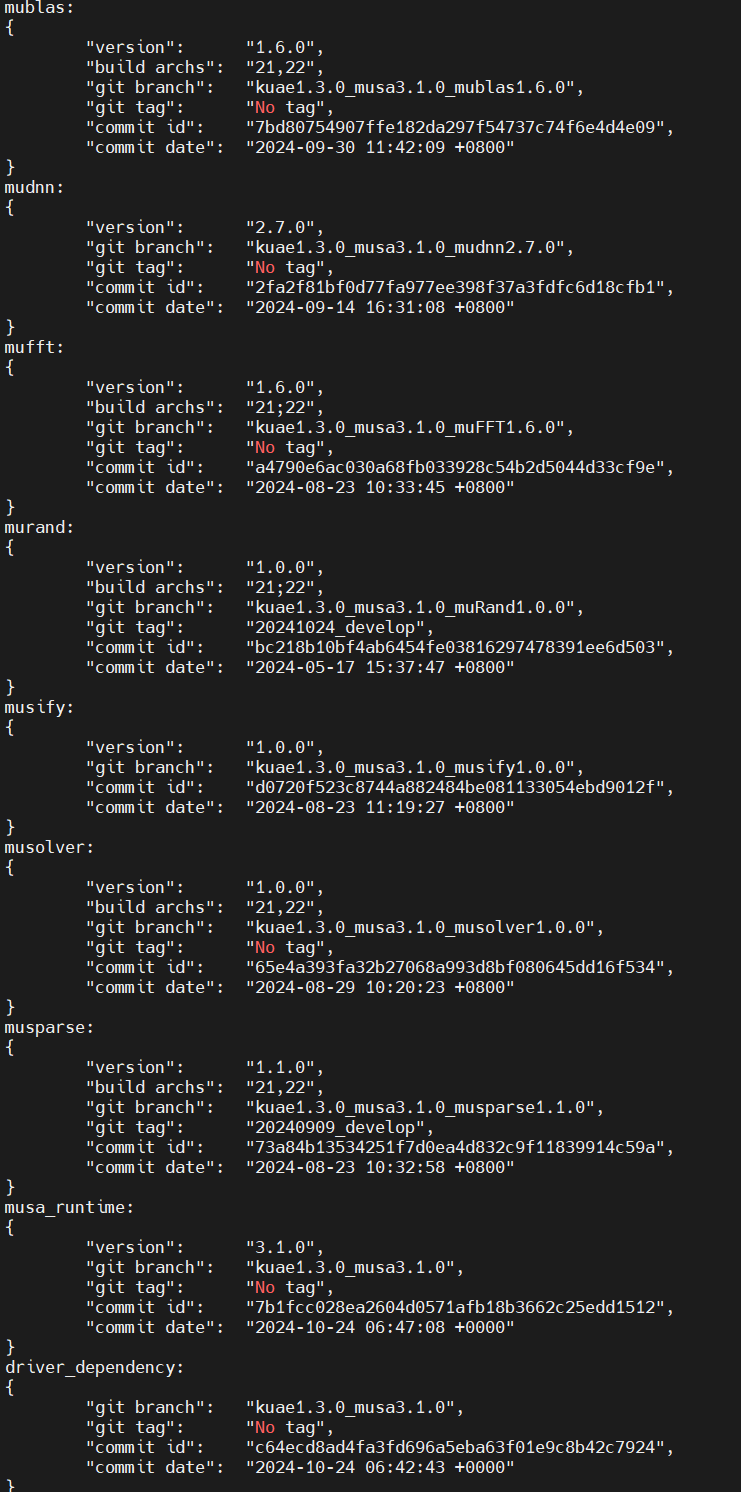
查看當前運行環境版本
輸入
musa_version_query
即可查看當前運行環境版本
Pytorch部分
轉義
根據官網介紹,對于pytorch代碼,只需要正確import torch_musa的拓展插件,并且將代碼中的所有cuda->musa,將所有的nccl->mccl即可。

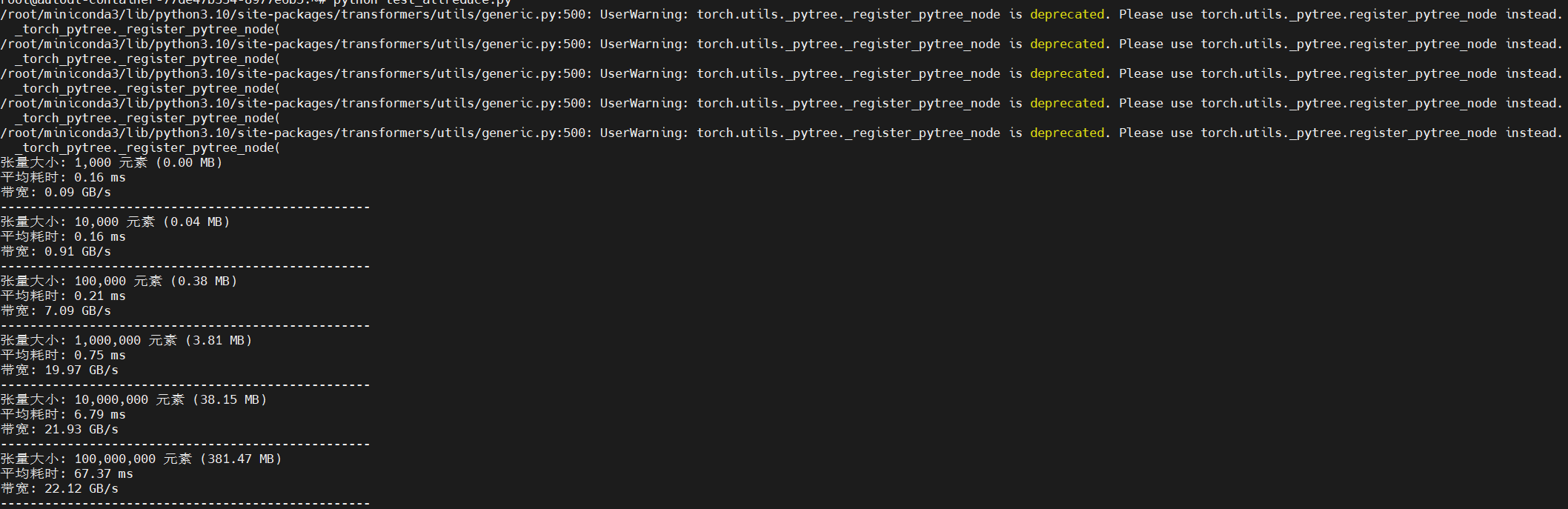
實測
作者使用豆包隨機生成了一個測試allreduce的pytorch代碼,代碼如下,在經過上述轉譯后能正常運行
import os
import time
import argparse
import torch
import torch_musa
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDPdef setup(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'# 初始化MUSA分布式環境dist.init_process_group("mccl", rank=rank, world_size=world_size)torch.musa.set_device(rank)def cleanup():dist.destroy_process_group()def run_benchmark(rank, world_size, sizes, num_iters=100, warmup=20):setup(rank, world_size)for size in sizes:# 創建隨機張量(使用MUSA設備)tensor = torch.rand(size, device=f'musa:{rank}')# 預熱for _ in range(warmup):dist.all_reduce(tensor)torch.musa.synchronize()# 測量時間start_time = time.time()for _ in range(num_iters):dist.all_reduce(tensor)torch.musa.synchronize()end_time = time.time()# 計算統計信息total_time = end_time - start_timeavg_time = total_time / num_iterssize_mb = size * 4 / (1024 * 1024) # float32是4字節bandwidth = (size_mb * world_size) / avg_time # MB/sif rank == 0:print(f"張量大小: {size:,} 元素 ({size_mb:.2f} MB)")print(f"平均耗時: {avg_time * 1000:.2f} ms")print(f"帶寬: {bandwidth / 1024:.2f} GB/s")print("-" * 50)cleanup()def main():parser = argparse.ArgumentParser()parser.add_argument('--sizes', type=int, nargs='+',default=[1000, 10000, 100000, 1000000, 10000000, 100000000],metavar='N',help='測試的張量大小列表')parser.add_argument('--num-iters', type=int, default=100,help='每個大小的迭代次數')parser.add_argument('--warmup', type=int, default=20,help='預熱迭代次數')args = parser.parse_args()world_size = torch.musa.device_count()if world_size != 4:raise ValueError("此腳本需要4個MUSA GPU,但發現 {} 個GPU".format(world_size))import torch.multiprocessing as mpmp.spawn(run_benchmark,args=(world_size, args.sizes, args.num_iters, args.warmup),nprocs=world_size,join=True)if __name__ == "__main__":main()
MUSA編程
p2p通信部分
代碼參考
筆者按照英偉達cudasamples倉庫中的p2pbandwidthtest 代碼,cuda-samples/Samples/5_Domain_Specific/p2pBandwidthLatencyTest at master · NVIDIA/cuda-samples · GitHub
并且參考相應的musa event api與mublasapi
https://docs.mthreads.com/musa-sdk/musa-sdk-doc-online/api/mcc_um.zh-CN
編寫了一個適用于摩爾線程的p2p通信檢測驗證程序
代碼部分
#include <cstdio>
#include <vector>
#include <musa_runtime.h> // 假設 MUSA 頭文件using namespace std;const char *sSampleName = "P2P (Peer-to-Peer) GPU Bandwidth Latency Test";typedef enum {P2P_WRITE = 0,P2P_READ = 1,
} P2PDataTransfer;typedef enum {CE = 0,SM = 1,
} P2PEngine;P2PEngine p2p_mechanism = CE; // 默認使用 Copy Engine// 錯誤檢查宏
#define musaCheckError() \{ \musaError_t e = musaGetLastError(); \if (e != musaSuccess) { \printf("MUSA failure %s:%d: '%s'\n", __FILE__, __LINE__, musaGetErrorString(e)); \exit(EXIT_FAILURE); \} \}// 延遲內核
__global__ void delay(volatile int *flag, unsigned long long timeout_clocks = 10000000)
{// 等待應用程序通知我們它已經完成了實驗的排隊,或者超時并退出,允許應用程序繼續執行long long int start_clock, sample_clock;start_clock = clock64();while (!*flag) {sample_clock = clock64();if (sample_clock - start_clock > timeout_clocks) {break;}}
}// P2P 復制內核
__global__ void copyp2p(int4 *__restrict__ dest, const int4 *__restrict__ src, size_t num_elems) {size_t globalId = blockIdx.x * blockDim.x + threadIdx.x;size_t gridSize = blockDim.x * gridDim.x;#pragma unroll 5 // 移除括號for (size_t i = globalId; i < num_elems; i += gridSize) {dest[i] = src[i];}
}// 打印幫助信息
void printHelp(void) {printf("Usage: p2pBandwidthLatencyTest [OPTION]...\n");printf("Tests bandwidth/latency of GPU pairs using P2P and without P2P\n");printf("\n");printf("Options:\n");printf("--help\t\tDisplay this help menu\n");printf("--p2p_read\tUse P2P reads for data transfers between GPU pairs\n");printf("--sm_copy\tUse SM intiated p2p transfers instead of Copy Engine\n");printf("--numElems=<NUM_OF_INT_ELEMS> Number of integer elements for p2p copy\n");
}// 檢查P2P訪問
void checkP2Paccess(int numGPUs) {for (int i = 0; i < numGPUs; i++) {musaSetDevice(i);musaCheckError();for (int j = 0; j < numGPUs; j++) {if (i != j) {int access;musaDeviceCanAccessPeer(&access, i, j);musaCheckError();printf("Device=%d %s Access Peer Device=%d\n", i, access ? "CAN" : "CANNOT", j);}}}printf("\n***NOTE: Devices without P2P access fall back to normal memcpy.\n");
}// 執行P2P復制
void performP2PCopy(int *dest, int destDevice, int *src, int srcDevice,size_t num_elems, int repeat, bool p2paccess,musaStream_t streamToRun) {int blockSize, numBlocks;musaOccupancyMaxPotentialBlockSize(&numBlocks, &blockSize, copyp2p);musaCheckError();if (p2p_mechanism == SM && p2paccess) {for (int r = 0; r < repeat; r++) {copyp2p<<<numBlocks, blockSize, 0, streamToRun>>>((int4*)dest, (int4*)src, num_elems/4);}} else {for (int r = 0; r < repeat; r++) {musaMemcpyPeerAsync(dest, destDevice, src, srcDevice,sizeof(int)*num_elems, streamToRun);musaCheckError();}}
}// 輸出帶寬矩陣
void outputBandwidthMatrix(int numElems, int numGPUs, bool p2p, P2PDataTransfer p2p_method) {int repeat = 5;volatile int *flag = NULL;vector<int *> buffers(numGPUs);vector<int *> buffersD2D(numGPUs);vector<musaEvent_t> start(numGPUs);vector<musaEvent_t> stop(numGPUs);vector<musaStream_t> stream(numGPUs);musaHostAlloc((void **)&flag, sizeof(*flag), musaHostAllocPortable);musaCheckError();for (int d = 0; d < numGPUs; d++) {musaSetDevice(d);musaStreamCreateWithFlags(&stream[d], musaStreamNonBlocking);musaMalloc(&buffers[d], numElems * sizeof(int));musaMemset(buffers[d], 0, numElems * sizeof(int));musaMalloc(&buffersD2D[d], numElems * sizeof(int));musaMemset(buffersD2D[d], 0, numElems * sizeof(int));musaCheckError();musaEventCreate(&start[d]);musaCheckError();musaEventCreate(&stop[d]);musaCheckError();}vector<double> bandwidthMatrix(numGPUs * numGPUs);for (int i = 0; i < numGPUs; i++) {musaSetDevice(i);for (int j = 0; j < numGPUs; j++) {int access = 0;if (p2p) {musaDeviceCanAccessPeer(&access, i, j);if (access) {musaDeviceEnablePeerAccess(j, 0);musaCheckError();musaSetDevice(j);musaDeviceEnablePeerAccess(i, 0);musaCheckError();musaSetDevice(i);musaCheckError();}}musaStreamSynchronize(stream[i]);musaCheckError();// 阻塞流,直到所有工作排隊完成*flag = 0;delay<<<1, 1, 0, stream[i]>>>(flag);musaCheckError();musaEventRecord(start[i], stream[i]);musaCheckError();if (i == j) {performP2PCopy(buffers[i], i, buffersD2D[i], i, numElems, repeat, access, stream[i]);}else {if (p2p_method == P2P_WRITE) {performP2PCopy(buffers[j], j, buffers[i], i, numElems, repeat, access, stream[i]);}else {performP2PCopy(buffers[i], i, buffers[j], j, numElems, repeat, access, stream[i]);}}musaEventRecord(stop[i], stream[i]);musaCheckError();// 釋放排隊的事件*flag = 1;musaStreamSynchronize(stream[i]);musaCheckError();float time_ms;musaEventElapsedTime(&time_ms, start[i], stop[i]);double time_s = time_ms / 1e3;double gb = numElems * sizeof(int) * repeat / (double)1e9;if (i == j) {gb *= 2;}bandwidthMatrix[i * numGPUs + j] = gb / time_s;if (p2p && access) {musaDeviceDisablePeerAccess(j);musaSetDevice(j);musaDeviceDisablePeerAccess(i);musaSetDevice(i);musaCheckError();}}}printf(" D\\D");for (int j = 0; j < numGPUs; j++) {printf("%6d ", j);}printf("\n");for (int i = 0; i < numGPUs; i++) {printf("%6d ", i);for (int j = 0; j < numGPUs; j++) {printf("%6.02f ", bandwidthMatrix[i * numGPUs + j]);}printf("\n");}for (int d = 0; d < numGPUs; d++) {musaSetDevice(d);musaFree(buffers[d]);musaFree(buffersD2D[d]);musaCheckError();musaEventDestroy(start[d]);musaCheckError();musaEventDestroy(stop[d]);musaCheckError();musaStreamDestroy(stream[d]);musaCheckError();}musaFreeHost((void *)flag);musaCheckError();
}// 輸出雙向帶寬矩陣
void outputBidirectionalBandwidthMatrix(int numElems, int numGPUs, bool p2p) {int repeat = 5;volatile int *flag = NULL;vector<int *> buffers(numGPUs);vector<int *> buffersD2D(numGPUs);vector<musaEvent_t> start(numGPUs);vector<musaEvent_t> stop(numGPUs);vector<musaStream_t> stream0(numGPUs);vector<musaStream_t> stream1(numGPUs);musaHostAlloc((void **)&flag, sizeof(*flag), musaHostAllocPortable);musaCheckError();for (int d = 0; d < numGPUs; d++) {musaSetDevice(d);musaMalloc(&buffers[d], numElems * sizeof(int));musaMemset(buffers[d], 0, numElems * sizeof(int));musaMalloc(&buffersD2D[d], numElems * sizeof(int));musaMemset(buffersD2D[d], 0, numElems * sizeof(int));musaCheckError();musaEventCreate(&start[d]);musaCheckError();musaEventCreate(&stop[d]);musaCheckError();musaStreamCreateWithFlags(&stream0[d], musaStreamNonBlocking);musaCheckError();musaStreamCreateWithFlags(&stream1[d], musaStreamNonBlocking);musaCheckError();}vector<double> bandwidthMatrix(numGPUs * numGPUs);for (int i = 0; i < numGPUs; i++) {musaSetDevice(i);for (int j = 0; j < numGPUs; j++) {int access = 0;if (p2p) {musaDeviceCanAccessPeer(&access, i, j);if (access) {musaSetDevice(i);musaDeviceEnablePeerAccess(j, 0);musaCheckError();musaSetDevice(j);musaDeviceEnablePeerAccess(i, 0);musaCheckError();}}musaSetDevice(i);musaStreamSynchronize(stream0[i]);musaStreamSynchronize(stream1[j]);musaCheckError();// 阻塞流,直到所有工作排隊完成*flag = 0;musaSetDevice(i);// 無需阻塞 stream1,因為它會在 stream0 的事件上阻塞delay<<<1, 1, 0, stream0[i]>>>(flag);musaCheckError();// 強制 stream1 在 stream0 開始之前不啟動,以確保 stream0 上的事件完全涵蓋所有操作所需的時間musaEventRecord(start[i], stream0[i]);musaStreamWaitEvent(stream1[j], start[i], 0);if (i == j) {// 對于 GPU 內操作,執行 2 次內存復制 buffersD2D <-> buffersperformP2PCopy(buffers[i], i, buffersD2D[i], i, numElems, repeat, access, stream0[i]);performP2PCopy(buffersD2D[i], i, buffers[i], i, numElems, repeat, access, stream1[i]);}else {if (access && p2p_mechanism == SM) {musaSetDevice(j);}performP2PCopy(buffers[i], i, buffers[j], j, numElems, repeat, access, stream1[j]);if (access && p2p_mechanism == SM) {musaSetDevice(i);}performP2PCopy(buffers[j], j, buffers[i], i, numElems, repeat, access, stream0[i]);}// 通知 stream0 stream1 已完成,并記錄總事務的時間musaEventRecord(stop[j], stream1[j]);musaStreamWaitEvent(stream0[i], stop[j], 0);musaEventRecord(stop[i], stream0[i]);// 釋放排隊的操作*flag = 1;musaStreamSynchronize(stream0[i]);musaStreamSynchronize(stream1[j]);musaCheckError();float time_ms;musaEventElapsedTime(&time_ms, start[i], stop[i]);double time_s = time_ms / 1e3;double gb = 2.0 * numElems * sizeof(int) * repeat / (double)1e9;if (i == j) {gb *= 2;}bandwidthMatrix[i * numGPUs + j] = gb / time_s;if (p2p && access) {musaSetDevice(i);musaDeviceDisablePeerAccess(j);musaSetDevice(j);musaDeviceDisablePeerAccess(i);}}}printf(" D\\D");for (int j = 0; j < numGPUs; j++) {printf("%6d ", j);}printf("\n");for (int i = 0; i < numGPUs; i++) {printf("%6d ", i);for (int j = 0; j < numGPUs; j++) {printf("%6.02f ", bandwidthMatrix[i * numGPUs + j]);}printf("\n");}for (int d = 0; d < numGPUs; d++) {musaSetDevice(d);musaFree(buffers[d]);musaFree(buffersD2D[d]);musaCheckError();musaEventDestroy(start[d]);musaCheckError();musaEventDestroy(stop[d]);musaCheckError();musaStreamDestroy(stream0[d]);musaCheckError();musaStreamDestroy(stream1[d]);musaCheckError();}musaFreeHost((void *)flag);musaCheckError();
}// 輸出延遲矩陣
void outputLatencyMatrix(int numGPUs, bool p2p, P2PDataTransfer p2p_method) {int repeat = 100;int numElems = 4; // 執行 1 個 int4 傳輸volatile int *flag = NULL;vector<int *> buffers(numGPUs);vector<int *> buffersD2D(numGPUs); // 用于 D2D(即 GPU 內復制)的緩沖區vector<musaStream_t> stream(numGPUs);vector<musaEvent_t> start(numGPUs);vector<musaEvent_t> stop(numGPUs);musaHostAlloc((void **)&flag, sizeof(*flag), musaHostAllocPortable);musaCheckError();for (int d = 0; d < numGPUs; d++) {musaSetDevice(d);musaStreamCreateWithFlags(&stream[d], musaStreamNonBlocking);musaMalloc(&buffers[d], sizeof(int) * numElems);musaMemset(buffers[d], 0, sizeof(int) * numElems);musaMalloc(&buffersD2D[d], sizeof(int) * numElems);musaMemset(buffersD2D[d], 0, sizeof(int) * numElems);musaCheckError();musaEventCreate(&start[d]);musaCheckError();musaEventCreate(&stop[d]);musaCheckError();}vector<double> gpuLatencyMatrix(numGPUs * numGPUs);vector<double> cpuLatencyMatrix(numGPUs * numGPUs);for (int i = 0; i < numGPUs; i++) {musaSetDevice(i);for (int j = 0; j < numGPUs; j++) {int access = 0;if (p2p) {musaDeviceCanAccessPeer(&access, i, j);if (access) {musaDeviceEnablePeerAccess(j, 0);musaCheckError();musaSetDevice(j);musaDeviceEnablePeerAccess(i, 0);musaSetDevice(i);musaCheckError();}}musaStreamSynchronize(stream[i]);musaCheckError();// 阻塞流,直到所有工作排隊完成*flag = 0;delay<<<1, 1, 0, stream[i]>>>(flag);musaCheckError();musaEventRecord(start[i], stream[i]);if (i == j) {// 執行 GPU 內的 D2D 復制performP2PCopy(buffers[i], i, buffersD2D[i], i, numElems, repeat, access, stream[i]);}else {if (p2p_method == P2P_WRITE) {performP2PCopy(buffers[j], j, buffers[i], i, numElems, repeat, access, stream[i]);}else {performP2PCopy(buffers[i], i, buffers[j], j, numElems, repeat, access, stream[i]);}}musaEventRecord(stop[i], stream[i]);// 現在工作已經排隊完成,釋放流*flag = 1;musaStreamSynchronize(stream[i]);musaCheckError();float gpu_time_ms;musaEventElapsedTime(&gpu_time_ms, start[i], stop[i]);gpuLatencyMatrix[i * numGPUs + j] = gpu_time_ms * 1e3 / repeat;if (p2p && access) {musaDeviceDisablePeerAccess(j);musaSetDevice(j);musaDeviceDisablePeerAccess(i);musaSetDevice(i);musaCheckError();}}}printf(" GPU");for (int j = 0; j < numGPUs; j++) {printf("%6d ", j);}printf("\n");for (int i = 0; i < numGPUs; i++) {printf("%6d ", i);for (int j = 0; j < numGPUs; j++) {printf("%6.02f ", gpuLatencyMatrix[i * numGPUs + j]);}printf("\n");}for (int d = 0; d < numGPUs; d++) {musaSetDevice(d);musaFree(buffers[d]);musaFree(buffersD2D[d]);musaCheckError();musaEventDestroy(start[d]);musaCheckError();musaEventDestroy(stop[d]);musaCheckError();musaStreamDestroy(stream[d]);musaCheckError();}musaFreeHost((void *)flag);musaCheckError();
}// 主函數
int main(int argc, char **argv) {int numGPUs, numElems = 40000000;P2PDataTransfer p2p_method = P2P_WRITE;musaGetDeviceCount(&numGPUs);musaCheckError();// 處理命令行參數for (int i = 1; i < argc; i++) {if (strcmp(argv[i], "--help") == 0) {printHelp();return 0;} else if (strcmp(argv[i], "--p2p_read") == 0) {p2p_method = P2P_READ;} else if (strcmp(argv[i], "--sm_copy") == 0) {p2p_mechanism = SM;} else if (strncmp(argv[i], "--numElems=", 11) == 0) {numElems = atoi(argv[i] + 11);}}printf("[%s]\n", sSampleName);// 輸出設備信息for (int i = 0; i < numGPUs; i++) {musaDeviceProp prop;musaGetDeviceProperties(&prop, i);printf("Device: %d, %s, pciBusID: %x, pciDeviceID: %x, pciDomainID:%x\n",i, prop.name, prop.pciBusID, prop.pciDeviceID, prop.pciDomainID);}checkP2Paccess(numGPUs);// 輸出P2P連接矩陣printf("P2P Connectivity Matrix\n");printf(" D\\D");for (int j = 0; j < numGPUs; j++) {printf("%6d", j);}printf("\n");for (int i = 0; i < numGPUs; i++) {printf("%6d\t", i);for (int j = 0; j < numGPUs; j++) {if (i != j) {int access;musaDeviceCanAccessPeer(&access, i, j);printf("%6d", (access) ? 1 : 0);} else {printf("%6d", 1);}}printf("\n");}// 輸出各種測試結果printf("Unidirectional P2P=Disabled Bandwidth Matrix (GB/s)\n");outputBandwidthMatrix(numElems, numGPUs, false, P2P_WRITE);printf("Unidirectional P2P=Enabled Bandwidth (P2P Writes) Matrix (GB/s)\n");outputBandwidthMatrix(numElems, numGPUs, true, P2P_WRITE);if (p2p_method == P2P_READ) {printf("Unidirectional P2P=Enabled Bandwidth (P2P Reads) Matrix (GB/s)\n");outputBandwidthMatrix(numElems, numGPUs, true, p2p_method);}printf("Bidirectional P2P=Disabled Bandwidth Matrix (GB/s)\n");outputBidirectionalBandwidthMatrix(numElems, numGPUs, false);printf("Bidirectional P2P=Enabled Bandwidth Matrix (GB/s)\n");outputBidirectionalBandwidthMatrix(numElems, numGPUs, true);printf("P2P=Disabled Latency Matrix (us)\n");outputLatencyMatrix(numGPUs, false, P2P_WRITE);printf("P2P=Enabled Latency (P2P Writes) Matrix (us)\n");outputLatencyMatrix(numGPUs, true, P2P_WRITE);if (p2p_method == P2P_READ) {printf("P2P=Enabled Latency (P2P Reads) Matrix (us)\n");outputLatencyMatrix(numGPUs, true, p2p_method);}printf("\nNOTE: Results may vary when GPU Boost is enabled.\n");return 0;
}
編譯
參考mcc編譯手冊,此時代碼中引用的庫為musa_runtime,則編譯是-l參數后跟musart
mcc p2p.mu -o p2p -lmusart
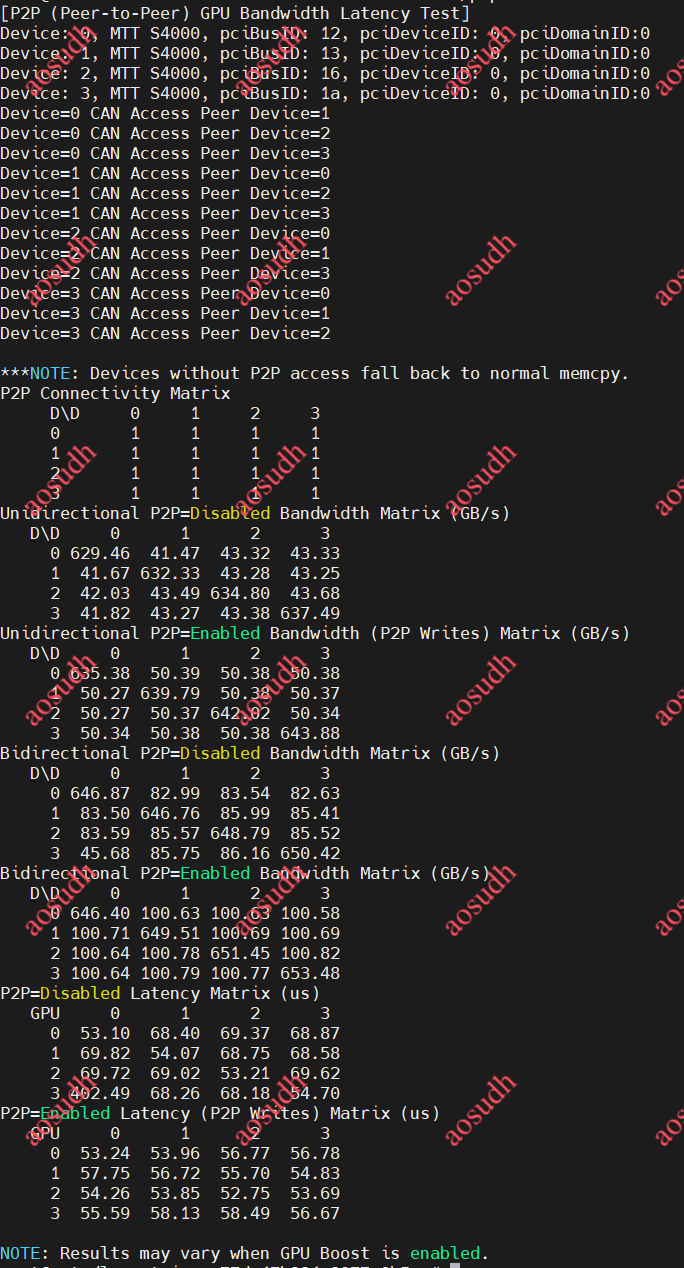
結果
可以看到p2p已經正確開啟,但是延遲測試有問題,后續改進
基于musa編程的allreduce測試
代碼參考
主要參考了NCCLtest中的allreduce部分邏輯
GitHub - NVIDIA/nccl-tests: NCCL Tests
并且參考了mublas api設計
https://docs.mthreads.com/musa-sdk/musa-sdk-doc-online/api/mublas_api
代碼部分
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "musa_runtime.h"
#include "mccl.h"
#include <inttypes.h> // 必須包含此頭文件// 宏定義(所有標識符在此處聲明)
#define MIN_SIZE_B 16ULL // 最小測試尺寸(16字節)
#define MAX_SIZE_B (4096ULL * 1024ULL * 1024ULL) // 最大測試尺寸(4096MB)
#define STEP_FACTOR 2ULL // 尺寸增長因子(每次翻倍)
#define WARMUP_ITERS 5 // 熱身迭代次數
#define TEST_ITERS 20 // 測試迭代次數
#define ROOT_RANK -1 // 根節點(-1表示全歸約)
#define DATA_TYPE mcclFloat // 數據類型
#define REDUCTION_OP mcclSum // 歸約操作
#define FLOAT_SIZE sizeof(float) // float類型字節數(4字節)// 錯誤檢查宏
#define MUSACHECK(cmd) do { \musaError_t err = cmd; \if (err != musaSuccess) { \printf("MUSA Error at %s:%d: %s\n", __FILE__, __LINE__, musaGetErrorString(err)); \exit(EXIT_FAILURE); \} \
} while(0)#define MCCLCHECK(cmd) do { \mcclResult_t res = cmd; \if (res != mcclSuccess) { \printf("MCCL Error at %s:%d: %s\n", __FILE__, __LINE__, mcclGetErrorString(res)); \exit(EXIT_FAILURE); \} \
} while(0)// 帶寬計算函數
void calculate_bandwidth(size_t count, int type_size, double time_sec, double* alg_bw, double* bus_bw, int nranks) {if (time_sec <= 0 || count == 0) {*alg_bw = 0.0;*bus_bw = 0.0;return;}double data_size_gb = (double)(count * type_size) / 1e9;*alg_bw = data_size_gb / time_sec;double factor = (nranks > 1) ? (2.0 * (nranks - 1)) / nranks : 1.0;*bus_bw = *alg_bw * factor;
}int main(int argc, char* argv[]) {int nDev = 4; // 設備數量int devs[4] = {0, 1, 2, 3}; // 設備ID列表mcclComm_t comms[4]; // MCCL通信器musaStream_t streams[4]; // 流數組float** sendbuff = NULL; // 發送緩沖區float** recvbuff = NULL; // 接收緩沖區size_t current_size_b = MIN_SIZE_B; // 當前測試尺寸(字節)double alg_bw, bus_bw; // 算法帶寬和總線帶寬int test_wrong = 0; // 錯誤計數// 初始化MCCL通信器MCCLCHECK(mcclCommInitAll(comms, nDev, devs));// 分配設備內存并創建流sendbuff = (float**)malloc(nDev * sizeof(float*));recvbuff = (float**)malloc(nDev * sizeof(float*));for (int i = 0; i < nDev; ++i) {MUSACHECK(musaSetDevice(i));MUSACHECK(musaMalloc(&sendbuff[i], MAX_SIZE_B)); // 分配最大尺寸內存MUSACHECK(musaMalloc(&recvbuff[i], MAX_SIZE_B));MUSACHECK(musaStreamCreate(&streams[i])); // 創建獨立流}// 打印結果表頭printf("| %10s | %10s | %5s | %4s | %14s | %13s | %13s | %13s | %5s |\n","size (B)", "count", "type", "root", "warmup_time (us)", "test_time (us)", "alg_bw (GB/s)", "bus_bw (GB/s)", "#wrong");printf("|------------|------------|-------|------|------------------|----------------|---------------|---------------|--------|\n");// 尺寸循環測試while (current_size_b <= MAX_SIZE_B) {size_t element_count = current_size_b / FLOAT_SIZE; // 元素數量// 跳過非對齊尺寸if (current_size_b % FLOAT_SIZE != 0) {current_size_b *= STEP_FACTOR;continue;}// 初始化設備數據(通過主機內存正確賦值為1.0f)for (int i = 0; i < nDev; ++i) {MUSACHECK(musaSetDevice(i));float* host_buf = (float*)malloc(current_size_b);for (size_t j = 0; j < element_count; ++j) host_buf[j] = 1.0f;MUSACHECK(musaMemcpy(sendbuff[i], host_buf, current_size_b, musaMemcpyHostToDevice));free(host_buf);MUSACHECK(musaMemset(recvbuff[i], 0, current_size_b));}// 熱身迭代(包含流同步)for (int warmup = 0; warmup < WARMUP_ITERS; ++warmup) {MCCLCHECK(mcclGroupStart());for (int i = 0; i < nDev; ++i) {MCCLCHECK(mcclAllReduce(sendbuff[i], recvbuff[i], element_count, DATA_TYPE, REDUCTION_OP,comms[i], streams[i]));}MCCLCHECK(mcclGroupEnd());for (int i = 0; i < nDev; ++i) {MUSACHECK(musaSetDevice(i));MUSACHECK(musaStreamSynchronize(streams[i]));}}// 事件計時(僅在主設備0操作)musaEvent_t start, stop;MUSACHECK(musaSetDevice(0));MUSACHECK(musaEventCreate(&start));MUSACHECK(musaEventCreate(&stop));MUSACHECK(musaEventRecord(start, streams[0]));// 測試迭代(包含完整Group操作)MCCLCHECK(mcclGroupStart());for (int iter = 0; iter < TEST_ITERS; ++iter) {for (int i = 0; i < nDev; ++i) {MUSACHECK(musaSetDevice(i));MCCLCHECK(mcclAllReduce(sendbuff[i], recvbuff[i], element_count, DATA_TYPE, REDUCTION_OP,comms[i], streams[i]));}}MCCLCHECK(mcclGroupEnd());MUSACHECK(musaEventRecord(stop, streams[0]));MUSACHECK(musaEventSynchronize(stop));// 計算平均時間float total_time_ms;MUSACHECK(musaEventElapsedTime(&total_time_ms, start, stop));double avg_time_us = (total_time_ms / TEST_ITERS) * 1000;// 計算帶寬calculate_bandwidth(element_count, FLOAT_SIZE, avg_time_us / 1e6, &alg_bw, &bus_bw, nDev);// 驗證結果(允許浮點精度誤差)test_wrong = 0;float expected = (float)nDev;for (int i = 0; i < nDev; ++i) {MUSACHECK(musaSetDevice(i));float* h_recv = (float*)malloc(current_size_b);MUSACHECK(musaMemcpy(h_recv, recvbuff[i], current_size_b, musaMemcpyDeviceToHost));for (size_t j = 0; j < element_count; ++j) {if (fabs(h_recv[j] - expected) > 1e-6) test_wrong++;}free(h_recv);}// 打印結果printf("| %10" PRIu64 " | %10" PRIu64 " | %4s | %4d | %16.3f | %14.3f | %13.3f | %13.3f | %6d |\n",(uint64_t)current_size_b, (uint64_t)element_count, "float", ROOT_RANK, 0.0, avg_time_us, alg_bw, bus_bw, test_wrong);// 銷毀事件MUSACHECK(musaSetDevice(0));MUSACHECK(musaEventDestroy(start));MUSACHECK(musaEventDestroy(stop));// 增大測試尺寸current_size_b *= STEP_FACTOR;}// 釋放資源for (int i = 0; i < nDev; ++i) {MUSACHECK(musaSetDevice(i));MUSACHECK(musaFree(sendbuff[i]));MUSACHECK(musaFree(recvbuff[i]));MUSACHECK(musaStreamDestroy(streams[i]));mcclCommDestroy(comms[i]);}free(sendbuff);free(recvbuff);printf("AllReduce Test Completed Successfully\n");return 0;
}編譯
因為代碼用了musa_runtime與mccl兩個庫,因此編譯選項也會有所改變
mcc allreduce.mu -o allreduce -lmusart -lmccl
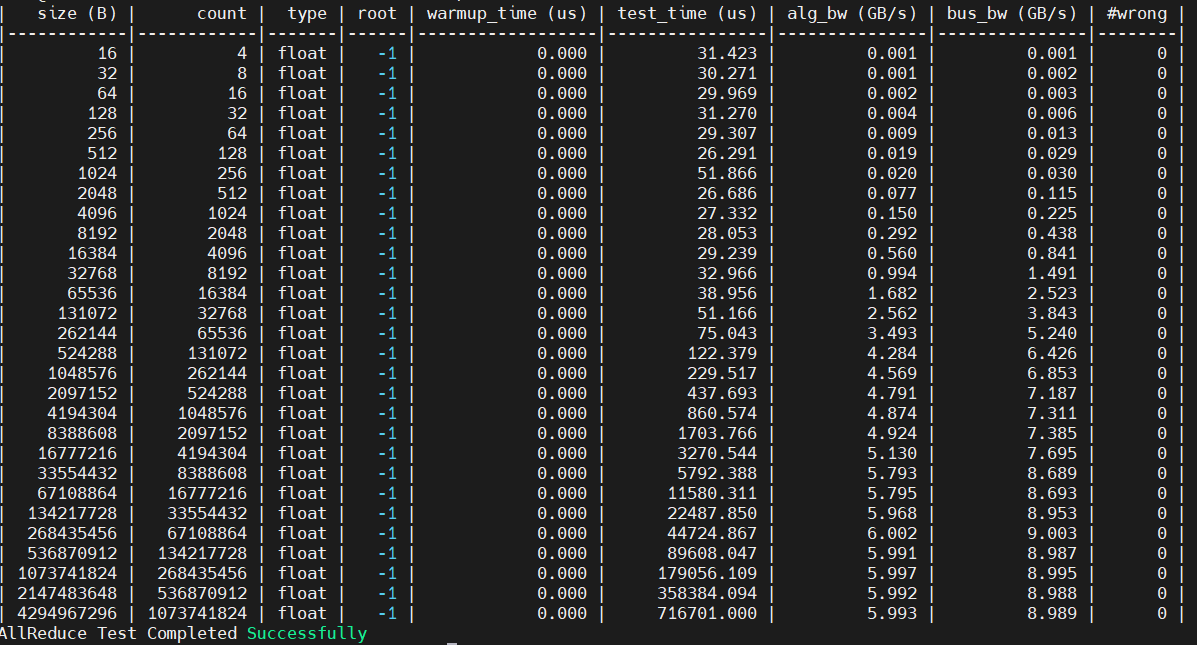
結果
不知道為什么結果測出來和用pytorch測出來結果相差不小,目測是因為musa event打點計時函數沒使用正確(在p2p測試的自交中也有體現,不管什么情況都是50us左右),這個需要后續再看下

)






)

)






:ROS入門指南 —— 核心解析與版本演進)

