各位帥哥美女點點關注,有關注才有動力啊
網絡爬蟲
引言
我們平時都說Python爬蟲,其實這里可能有個誤解,爬蟲并不是Python獨有的,可以做爬蟲的語言有很多例如:PHP、JAVA、C#、C++、Python。
為什么Python的爬蟲技術會異軍突起呢?
Python火并不是因為爬蟲技術,而是AI人工智能、數據分析(GoogleAlphaGo)等等功能;這些Java其實也能做,而選擇Python做爬蟲是因為Python相對來說比較簡單,而且功能比較齊全。
什么是網絡爬蟲
網絡爬蟲(英語:web crawler),也叫網絡蜘蛛(spider),是一種用來自動瀏覽萬維網的網絡機器人。通俗來講,網絡爬蟲就是模擬瀏覽器發送網絡請求,接收請求響應,一種按照一定的規則,自動地抓取互聯網信息的程序。
原則上,只要是瀏覽器(客戶端)能做的事情,爬蟲都能夠做。
為什么要學習網絡爬蟲
互聯網大數據時代,給予我們的是生活的便利以及海量數據爆炸式的出現在網絡中。過去,我們通過書籍、報紙、電視、廣播或許信息,這些信息數量有限,且是經過一定的篩選,信息相對而言比較有效,但是缺點則是信息面太過于狹窄了。不對稱的信息傳導,以致于我們視野受限,無法了解到更多的信息和知識。 互聯網大數據時代,我們突然間,信息獲取自由了,我們得到了海量的信息,但是大多數都是無效的垃圾信息。 例如新浪微博,一天產生數億條的狀態更新,而在百度搜索引擎中,隨意搜一條就有成千上百萬條信息。 在如此海量的信息碎片中,我們如何獲取對自己有用的信息呢? 答案是篩選! 通過某項技術將相關的內容收集起來,在分析刪選才能得到我們真正需要的信息。 這個信息收集分析整合的工作,可應用的范疇非常的廣泛,無論是生活服務、出行旅行、金融投資、各類制造業的產品市場需求等等……都能夠借助這個技術獲取更精準有效的信息加以利用。 網絡爬蟲技術,雖說有個詭異的名字,讓能第一反應是那種軟軟的蠕動的生物,但它卻是一個可以在虛擬世界里,無往不前的利器。
瀏覽網站時所能看見的數據都可以通過爬蟲程序保存下來,例如:文字、圖片、音頻和視頻。
應用場景
-
數據展示:將爬取的數據展示到網頁或者APP上,比如:百度新聞、今日頭條
-
數據分析:從數據中尋找一些規律,比如:慢慢買(價格對比)、TIOBE排行等
-
自動化測試:比如想要測試一個前端頁面的兼容性、前端頁面UI是否有bug,只需要模擬執行表單提交、鍵盤輸入等頁面操作
網絡爬蟲是否合法
爬蟲作為一種計算機技術就決定了它的中立性,因此爬蟲本身在法律上并不被禁止,但是利用爬蟲技術獲取數據這一行為是具有違法甚至是犯罪的風險的。所謂具體問題具體分析,正如水果刀本身在法律上并不被禁止使用,但是用來捅人,就不被法律所容忍了。
爬蟲技術與反爬蟲技術
爬蟲目前能造成的技術上影響在于野蠻爬取,即多線程爬取,從而導致網站癱瘓或不能訪問,這也是大多數網絡攻擊所使用的方法之一。
由于爬蟲會批量訪問網站,因此許多網站會采取反爬措施。例如:1.IP頻率、流量限制;2.請求時間窗口過濾統計;3.識別爬蟲等。
但這些手段都無法阻止爬蟲開發人員優化代碼、使用多IP池等方式規避反爬措施,實現大批量的數據抓取。由于網絡爬蟲會根據特定的條件訪問頁面,因而爬蟲的使用將占用被訪問網站的網絡帶寬并增加網絡服務器的處理開銷,甚至無法正常提供服務。
Robots協議
robots(也稱為爬蟲協議、機器人協議等)稱是“網絡爬蟲排除標準”是網站跟爬蟲間的一種協議(國際互聯網界通行的道德規范),用簡單直接的txt格式文本方式告訴對應的爬蟲被允許的權限,也就是說robots.txt是搜索引擎中訪問網站的時候要查看的第一個文件。
參考地址:https://www.zhihu.com/robots.txt
-
以Allow開頭的URL地址:允許某爬蟲引擎訪問
-
以Disallow開頭的URL地址:不允許某爬蟲引擎訪問
總之,盜亦有道,君子之約。
網絡爬蟲步驟及相關技術
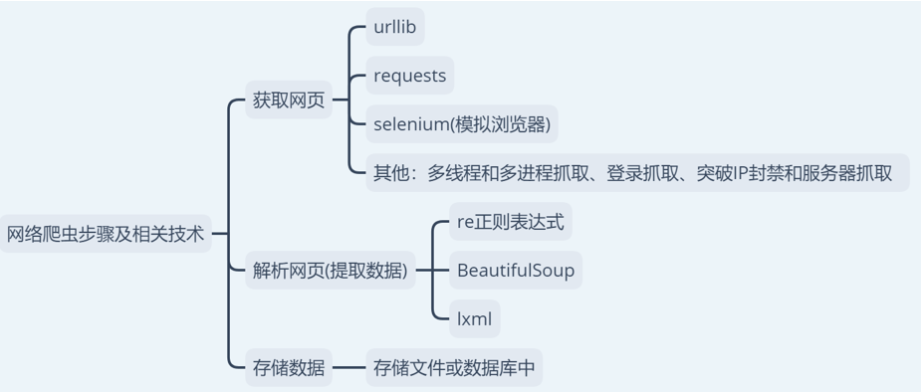
抓包
-
瀏覽器抓包(僅能抓取瀏覽器的數據包)
-
抓包工具fiddler(基本用于抓取HTTP)
cookie與session的區別與連系?
User-Agent: 瀏覽器信息
HTTP與HTTPS
-
HTTP 與 HTTPS 有哪些區別?
(1)HTTP 是超文本傳輸協議,信息是明文傳輸,存在安全風險的問題。HTTPS 則解決 HTTP 不安全的缺陷,在 TCP 和 HTTP 網絡層之間加入了 SSL/TLS 安全協議,使得報文能夠加密傳輸。
(2)HTTP 連接建立相對簡單, TCP 三次握手之后便可進行 HTTP 的報文傳輸。而 HTTPS 在 TCP三次握手之后,還需進行 SSL/TLS 的握手過程,才可進入加密報文傳輸。
(3) HTTP 的端口號是 80,HTTPS 的端口號是 443。
(4)HTTPS 協議需要向 CA(證書權威機構)申請數字證書,來保證服務器的身份是可信的。
-
HTTPS 解決了 HTTP 的哪些問題?
HTTP 由于是明文傳輸,所以安全上存在以下三個風險:
竊聽風險,比如通信鏈路上可以獲取通信內容,用戶號容易沒。
篡改風險,比如強制植入垃圾廣告,視覺污染,用戶眼容易瞎。
冒充風險,比如冒充淘寶網站,用戶錢容易沒。
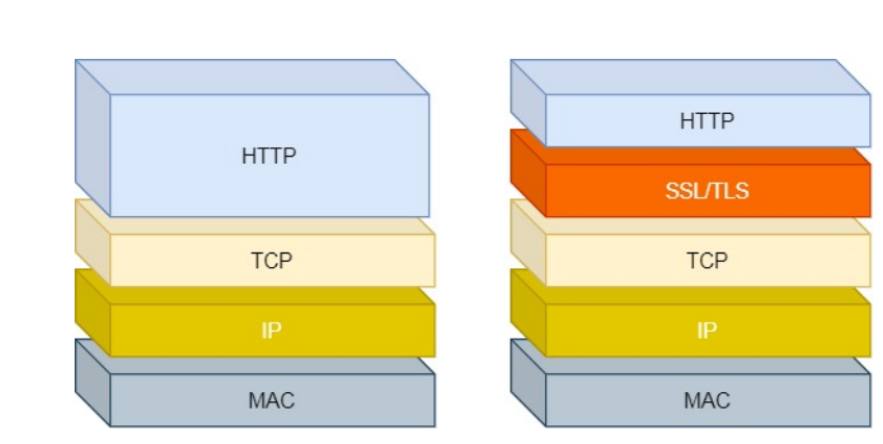
HTTPS 在 HTTP 與 TCP 層之間加入了 SSL/TLS 協議,可以很好的解決了上述的風險:
信息加密:交互信息無法被竊取,但你的號會因為「自身忘記」賬號而沒。
校驗機制:無法篡改通信內容,篡改了就不能正常顯示,但百度「競價排名」依然可以搜索垃圾
廣告。
身份證書:證明淘寶是真的淘寶網,但你的錢還是會因為「剁手」而沒。
可見,只要自身不做「惡」,SSL/TLS 協議是能保證通信是安全的。
-
HTTPS 是如何解決上面的三個風險的?
混合加密的方式實現信息的機密性,解決了竊聽的風險。
摘要算法的方式來實現完整性,它能夠為數據生成獨一無二的「指紋」,指紋用于校驗數據的完
整性,解決了篡改的風險。
將服務器公鑰放入到數字證書中,解決了冒充的風險。
快速入門
安裝requests
pip 是 Python 包管理工具,該工具提供了對Python 包的查找、下載、安裝和卸載的功能,現在大家用到的所有包不是自帶的就是通過pip安裝的。Python 2.7.9 + 或 Python 3.4+ 以上版本都自帶 pip 工具。
前端:npm install
后端:maven
-
顯示版本和路徑
pip --version
-
安裝指定版本的requests
pip install requests ? ? ? ? # 最新版本 pip install requests==2.11.0 # 指定版本 pip install requests>=2.11.0 # 最小版本
由于所有請求都需要經過fiddler這個抓包軟件進出。所以如果requests與fiddler一起使用,請不要使用requests最新版本,不然直接會卡死,降版本使用即可。
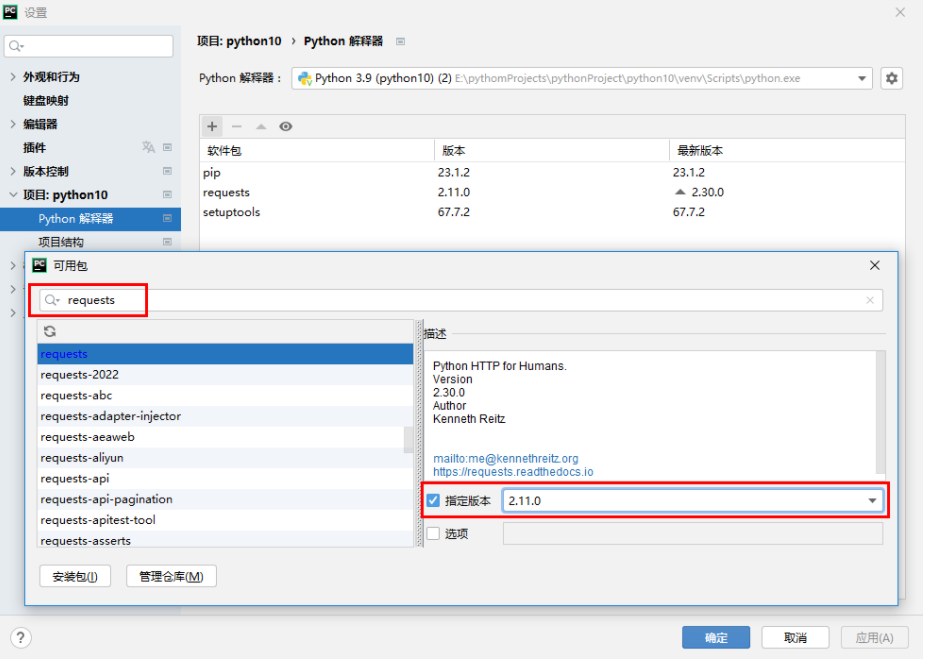
也可以直接通過PyCharm來安裝requests模塊,點擊File -> Settings -> 項目: python10,選擇Python解釋器,點擊 + 號,輸入選擇requests模塊并指定安裝版本號(例如:2.11.0),最后點擊 安裝包(I) 按鈕即可。
案例演示
創建純python項目,新建demo.py并導入requests模塊
# 導入模塊 import requests # 通過requests模塊模擬發送get請求,并得到響應對象response resp = requests.get(url)
response響應對象屬性介紹:
| 屬性 | 說明 |
|---|---|
| encoding | 文本編碼。例如:resp.encoding="utf-8" |
| status_code | 響應狀態碼。 200 -- 請求成功 4XX -- 客戶端錯誤 5XX -- 服務端響應錯誤 |
| text | 響應體。 |
| content | 字節方式響應體,會自動解碼gzip和deflate編碼的響應數據 |
| url | 響應的URL地址。 |
-
案例一:快速入門,爬取百度官網并保存到本地
請結合fiddler抓包工具進行以下代碼測試。
resp = requests.get("http://www.baidu.com/")
定制請求頭headers,請結合知乎網的Robots協議進行設置。偽裝User-Agent
resp = requests.get("http://www.zhihu.com/signin?next=%2F",headers={"User-agent": "bingbot"})
定制請求頭headers,模擬使用瀏覽器的User-Agent值。
resp = requests.get("http://www.baidu.com/",headers={"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"})
保存文件的方式可使用pathlib和open等兩種方式。
-
案例二:傳遞URL參數
POST和GET請求方式在傳遞URL參數時,稍有不同。
| GET方式 | POST方式 |
|---|---|
| params={"key1":"value1","key2":"value2"} | data={"key1":"value1","key2":"value2"} |
| response=requests.get(url,params=params) | response=requests.post(url,data=data) |
爬取必應搜索“中國”之后的網頁,保存為“中國.html”
resp = requests.get("https://cn.bing.com/search",headers={"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"},params={"q":"中國"})
requests缺點:不能爬取ajax動態加載的數據

:ROS入門指南 —— 核心解析與版本演進)


進程(2))











原理與應用)


