abstract
預訓練視覺語言模型(VLMs)已成為各種下游任務中遷移學習的優秀基礎模型。然而,針對少樣本泛化任務對VLMs進行微調時,面臨著“判別性—泛化性”困境,即需要保留通用知識,同時對任務特定知識進行微調。如何精確識別這兩類表示仍然是一個挑戰。在本文中,我們為VLMs提出了一種多模態適配器(MMA),以改善文本和視覺分支表示之間的對齊。MMA將不同分支的特征聚合到一個共享特征空間中,以便梯度可以跨分支傳遞。為了確定如何融入MMA,我們系統地分析了視覺和語言分支中跨不同數據集的特征的判別性和泛化性,發現:(1)高層包含可辨別的數據集特定知識,而低層包含更具泛化性的知識;(2)語言特征比視覺特征更具判別性,并且兩種模態的特征之間存在較大的語義鴻溝,尤其是在低層。因此,我們僅在Transformer的少數高層中融入MMA,以實現判別性和泛化性之間的最佳平衡。我們在三個任務上評估了我們方法的有效性:新類別泛化、新目標數據集泛化和域泛化。與許多最先進的方法相比,我們的MMA在所有評估中均取得了領先的性能。代碼位于https://github.com/ZjjConan/Multi-Modal-Adapter。
Introduction
研究背景與挑戰
視覺語言模型(VLMs)的潛力:
- CLIP等VLMs通過大規模圖像-文本對預訓練,能夠將視覺和語言特征映射到共享空間,在多種下游任務中表現出色。
- 然而,其龐大的參數量(如CLIP有數億參數)導致少樣本微調困難:
- 過擬合風險: 直接微調所有參數容易在小樣本數據上過擬合。
- 計算成本高: 全參數微調需要大量資源,不適用于實際應用。
現有方法的局限性
當前主流方法(如提示學習、單模態適配器)存在不足:
- 提示工程(Prompt Engineering):
- 依賴人工設計文本提示,需專業知識且難以優化。
- 單模態適配器:
- 獨立優化視覺或文本分支的適配器,未考慮跨模態特征對齊,導致任務特定知識學習不充分。
核心問題:區分性與泛化性困境
關鍵矛盾:
- 少樣本場景下,模型需同時滿足:
- 區分性(Discrimination): 學習任務相關的細粒度特征。
- 泛化性(Generalization): 保留預訓練獲得的通用知識。
現有方法的缺陷:
- 現有適配器(如AdaptFormer)在所有層添加模塊,可能破壞低層的通用特征,導致泛化能力下降。
作者的新發現
通過系統分析CLIP模型的視覺和文本編碼器特征,作者得出兩個關鍵觀察:
- 層次特性:
- 高層特征(靠近輸出的層) 具有更強的數據集特異性(高區分性),適合微調。
- 底層特征(靠近輸入的層) 包含更多跨任務通用知識(高泛化性),應盡量保留。
- 模態差異:
- 文本特征比視覺特征更具區分性,尤其在低層存在顯著跨模態語義鴻溝,導致對齊困難。
解決方案:多模態適配器(MMA)
基于上述發現,作者提出:
- 分層適配策略: 僅在高層Transformer塊(如ViT的5-12層)插入適配器,保留底層的通用性。
- 跨模態共享投影:
- 設計獨立投影層處理視覺和文本特征,并通過共享投影層促進跨模態梯度傳播,增強特征對齊。
主要貢獻
- 方法論創新:
- 提出首個針對VLMs的多模態適配器,通過共享投影層實現跨模態特征對齊。
- 基于層次分析的適配器插入策略,平衡區分性與泛化性。
- 實驗驗證:
- 在少樣本場景下的三大任務(新類識別、跨數據集遷移、域泛化)中,MMA均達到SOTA性能。
- 開源代碼:
- 提供完整實現代碼,促進后續研究。
2. Related Work
視覺語言模型(Vision-Language Models, VLMs)
代表性模型: 包括CLIP、ALIGN、FILIP、Florence、LiT和Kosmos等。
核心方法: 通過對比學習(如CLIP的對比損失)在大規模圖像-文本對(如CLIP的4億對,ALIGN的10億對)上進行自監督訓練,學習跨模態的聯合表示。
優勢與挑戰:
- 優勢: 預訓練模型在零樣本任務中表現優異,無需微調即可應用于多種下游任務。
- 挑戰: 直接微調所有參數在少樣本場景下會導致過擬合,且難以平衡任務特定知識與預訓練通用知識。
VLMs的高效遷移學習(Efficient Transfer Learning)
作者將現有方法分為兩類:提示學習(Prompt Learning) 和 適配器(Adapters),并分析其優缺點:
2.1 提示學習(Prompt Learning)
目標: 通過設計輸入提示(如文本模板)引導模型輸出,避免全參數微調。
典型工作:
- 單模態提示:
- CoOp: 優化連續的文本提示向量。
- CoCoOp: 根據圖像實例動態生成提示。
- LASP: 通過文本到文本的損失對齊提示與預訓練知識。
- 多模態提示:
- MaPLe: 在視覺和文本編碼器中同時插入可學習的提示,并通過耦合函數對齊跨模態特征。
局限性:
- 提示設計依賴人工經驗,優化過程可能過擬合到特定任務。
- 多模態提示研究較少,且未充分挖掘跨模態交互。
2.2 適配器(Adapters)
目標: 在預訓練模型中插入輕量級模塊(如小網絡),僅優化新增參數。
典型工作:
- 單模態適配器:
- Clip-Adapter/Tip-Adapter: 在圖像編碼器后添加適配層。
- AdaptFormer: 在Transformer塊中插入適配模塊。
- 多模態適配器:
- 如文本-視頻檢索中的跨模態適配器,但未深入分析特征層次特性。
局限性:
- 大多數適配器僅針對單模態設計,未考慮跨模態對齊。
- 適配器插入位置缺乏理論指導(如是否應覆蓋所有層)。
現有工作的不足與本文切入點
問題1:跨模態對齊不足
- 現有方法(如單模態提示或適配器)未有效利用視覺與文本特征的交互,導致模態間語義鴻溝。
問題2:特征特性未系統分析
- 缺乏對不同層次特征的區分性(discriminability)和泛化性(generalizability)的研究,導致適配策略(如插入層數)依賴經驗。
3 Method
3.1 Preliminary(CLIP模型基礎)
- CLIP結構:CLIP由文本編碼器(Text Encoder, T \mathcal{T} T)和圖像編碼器(Image Encoder, V \mathcal{V} V)組成,通過對比損失在大規模圖像-文本對上預訓練,使相關樣本的特征在共享空間中接近。
- 圖像編碼器流程:
圖像經 PatchEmbed 分割為固定大小的補丁并投影為特征 x 0 x_0 x0?,與可學習的類別標記 c 0 c_0 c0? 拼接后,通過 L L L 層 Transformer 塊 V i \mathcal{V}_i Vi? 提取特征,最終由 PatchProj 投影為圖像特征 x x x。 - 文本編碼器流程:
文本經 TextEmbed 分詞并投影為詞嵌入 w 0 j w_0^j w0j?,通過 L L L 層 Transformer 塊 T i \mathcal{T}_i Ti? 提取特征,最終由 TextProj 投影為文本特征 w w w。
- 圖像編碼器流程:
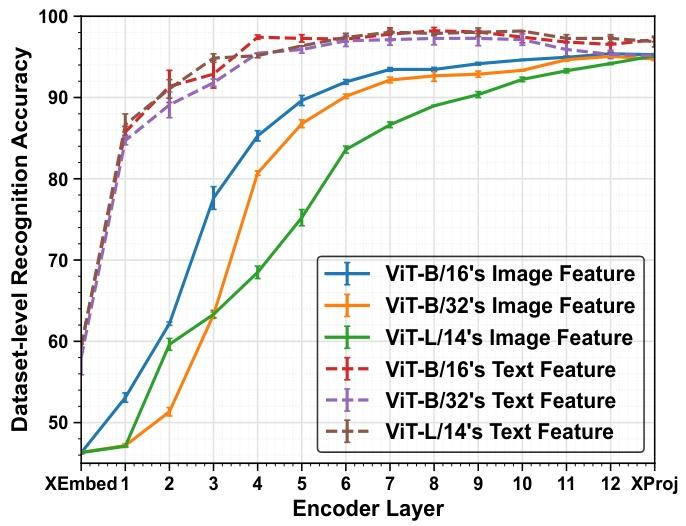
圖1. 各種基于Transformer的CLIP模型中不同層的數據集級識別準確率。本實驗旨在識別樣本所屬的數據集。我們使用不同隨機種子運行三次,并報告各層識別準確率的平均值和標準差。XEmbed指Transformer塊(即自注意力層和前饋層[13])之前的文本或圖像嵌入層,而\(X Proj\)指文本或圖像投影層。請注意,本實驗僅使用所有數據集的訓練樣本進行評估。
3.2 MMA: Multi-Modal Adapter(多模態適配器設計)
特征分析:判別性與泛化性
- 通過 數據集級識別實驗(Dataset-level Recognition)分析CLIP各層特征的特性:
- 高層特征(Transformer高層)包含更多 數據集特定的判別性知識,適合微調;低層特征更具 跨數據集的泛化性,需凍結以保留通用知識。
- 文本特征比 視覺特征更具判別性,且 低層模態間語義鴻溝更大,對齊難度更高,因此僅在高層引入適配器。
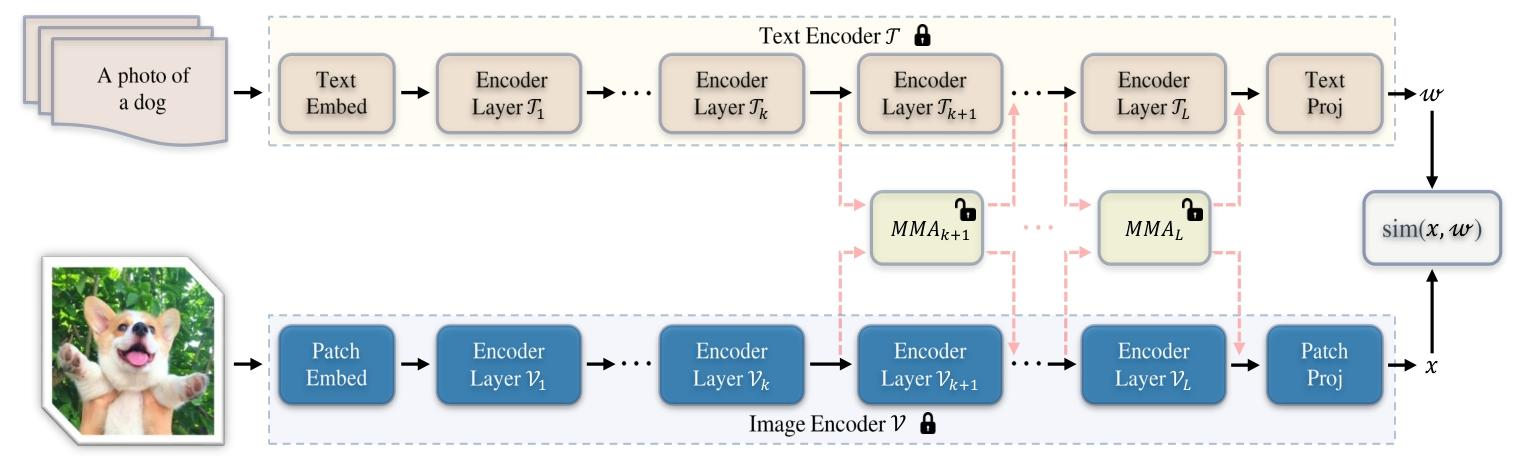
圖2. 針對基于Transformer的CLIP模型提出的多模態適配器(MMA)架構圖。我們的MMA對圖像編碼器和文本編碼器同時進行調優。訓練過程中僅優化額外添加的適配器,而整個預訓練CLIP模型的參數保持凍結。基于我們的分析,為了在判別性與泛化性困境之間取得良好平衡,我們的方法僅對每個編碼器的少數較高層(≥k)進行調優。此外,MMA在圖像和文本表示之間共享權重,以從不同分支學習共享線索。通過這一設計,MMA消除了每對圖像-文本對之間特征層面的交互[85],大大降低了計算成本。
宏觀設計:僅在高層引入適配器
- 適配器位置:僅在圖像和文本編碼器的 高層 Transformer 塊(從第 k k k 層到最后一層)中添加適配器 A v \mathcal{A}^v Av 和 A t \mathcal{A}^t At,低層保持凍結。
- 圖像編碼器:
{ [ c i , x i ] = V i ( [ c i ? 1 , x i ? 1 ] ) , i = 1 , 2 , … , k ? 1 [ c j , x j ] = V j ( [ c j ? 1 , x j ? 1 ] ) + α A j v ( [ c j ? 1 , x j ? 1 ] ) , j = k , … , L \begin{cases} \left[c_i, x_i\right] = \mathcal{V}_i\left(\left[c_{i-1}, x_{i-1}\right]\right), & i=1,2,\dots,k-1 \\ \left[c_j, x_j\right] = \mathcal{V}_j\left(\left[c_{j-1}, x_{j-1}\right]\right) + \alpha \mathcal{A}_j^v\left(\left[c_{j-1}, x_{j-1}\right]\right), & j=k,\dots,L \end{cases} {[ci?,xi?]=Vi?([ci?1?,xi?1?]),[cj?,xj?]=Vj?([cj?1?,xj?1?])+αAjv?([cj?1?,xj?1?]),?i=1,2,…,k?1j=k,…,L?
其中 α \alpha α 為縮放因子,平衡預訓練知識與任務特定知識。 - 文本編碼器:
{ [ w i j ] = T i ( [ w i ? 1 j ] ) , i = 1 , 2 , … , k ? 1 [ w j j ] = T j ( [ w i ? 1 j ] ) + α A j t ( [ w i ? 1 j ] ) , j = k , … , L \begin{cases} \left[w_i^j\right] = \mathcal{T}_i\left(\left[w_{i-1}^j\right]\right), & i=1,2,\dots,k-1 \\ \left[w_j^j\right] = \mathcal{T}_j\left(\left[w_{i-1}^j\right]\right) + \alpha \mathcal{A}_j^t\left(\left[w_{i-1}^j\right]\right), & j=k,\dots,L \end{cases} ? ? ??[wij?]=Ti?([wi?1j?]),[wjj?]=Tj?([wi?1j?])+αAjt?([wi?1j?]),?i=1,2,…,k?1j=k,…,L?。
- 圖像編碼器:
微觀設計:跨模態對齊的共享投影層
- 獨立投影層:圖像和文本分支分別通過獨立的 “Down” 和 “Up” 投影層( W k d v , W k u v W_{kd}^v, W_{ku}^v Wkdv?,Wkuv? 和 W k d t , W k u t W_{kd}^t, W_{ku}^t Wkdt?,Wkut?)提取任務特定特征。
- 共享投影層:通過共享權重 W k s W_{ks} Wks? 聚合雙模態特征,促進跨模態梯度傳播和語義對齊,公式為:
A k v ( z k ) = W k u v ? δ ( W k s ? δ ( W k d v ? z k ) ) \mathcal{A}_k^v(z_k) = W_{ku}^v \cdot \delta\left(W_{ks} \cdot \delta\left(W_{kd}^v \cdot z_k\right)\right) Akv?(zk?)=Wkuv??δ(Wks??δ(Wkdv??zk?))
其中 z k z_k zk? 為圖像或文本分支的輸入特征, δ \delta δ 為激活函數。
4. Experiments
4.1 實驗設置
任務與數據集
-
新類別泛化(Base-to-Novel Generalization)
- 評估模型從基類(Base Classes)遷移到新類(Novel Classes)的能力。
- 數據集:11個圖像分類數據集,包括ImageNet、Caltech101(通用目標)、OxfordPets、StanfordCars(細粒度)、SUN397(場景)等。
- 配置:16-shot設置(每類16個訓練樣本),僅在基類訓練,測試基類與新類準確率。
-
跨數據集評估(Cross-Dataset Evaluation)
- 模型在ImageNet上訓練后,直接遷移到其他10個數據集(如DTD紋理、EuroSAT衛星圖像等)進行測試,評估零樣本遷移能力。
-
域泛化(Domain Generalization)
- 測試模型在分布外(Out-of-Distribution)數據集上的魯棒性,使用ImageNet的4種變體:ImageNet-V2(視覺偏差)、ImageNet-Sketch(草圖)、ImageNet-A(對抗樣本)、ImageNet-R(真實擾動)。
實現細節
- 模型基礎:基于CLIP的ViT-B/16架構,凍結預訓練參數,僅優化MMA適配器。
- 適配器配置:
- 新類別泛化:從第5層(k=5)開始添加適配器,共享層維度32,訓練5個 epoch,批次大小128(ImageNet)/16(其他數據集)。
- 跨數據集與域泛化:k=9,訓練1個 epoch,使用SGD優化器,余弦學習率調度。
- 基線與對比方法:包括CLIP零樣本、文本提示學習(CoOp、CoCoOp)、多模態提示學習(MaPLe)、適配器方法(LASP、RPO)等。
4.2 主要結果
1. 新類別泛化(表1)
- 性能對比:
- MMA在11個數據集上的平均調和均值(HM)為79.87%,顯著優于SOTA方法(如LASP-V的79.48%、MaPLe的78.55%)。
- 基類準確率(83.20%)與新類準確率(76.80%)均領先,表明其有效平衡了判別性與泛化性。
- 關鍵發現:
- 文本提示方法(如CoOp)在新類表現較差(63.22%),因缺乏跨模態對齊;MMA通過共享投影層提升對齊,新類準確率提升超3%。
2. 跨數據集評估(表2)
- 零樣本遷移能力:
- MMA在10個目標數據集上的平均準確率為66.61%,優于MaPLe(66.30%)、LASP(63.88%)等,尤其在細粒度(如StanfordCars)和遙感數據(EuroSAT)上優勢明顯。
- 在源數據集ImageNet上,MMA準確率與CoOp相當,但遷移到其他數據集時更魯棒。
3. 域泛化(表3)
- 分布外魯棒性:
- MMA在3/4個數據集(ImageNet-V2、ImageNet-A、ImageNet-R)上性能最優,準確率分別為64.33%、51.12%、77.32%,顯著優于CLIP和提示學習方法。
- 結果表明,MMA通過高層適配器保留了預訓練模型的泛化性,對域 shift 更魯棒。
4.3 消融實驗
1. 適配器層數選擇(圖4)
- k值影響:
- 當k=5時,HM達到最高79.87%。k<5時(如k=1),低層特征泛化性強但判別性不足,新類準確率下降;k>5時(如k=9),高層特征過度擬合基類,新類性能降低。
- 結論:高層適配器(k=5)最佳,平衡了數據集特定知識與通用知識。
2. 共享投影層的重要性(表4a)
- 對比實驗:
- 移除共享投影層(No SharedProj)導致HM從79.87%降至79.20%,驗證跨模態對齊的必要性。
- 僅單模態適配器(Only V-Adapter/Only L-Adapter)性能低于雙模態,表明融合文本與視覺特征的重要性。
3. 共享層維度與縮放因子α(表4b、4c)
- 維度影響:
- 維度32時性能最佳(HM=79.87%),過大維度(如128)因參數過多導致過擬合,新類準確率下降。
- α的平衡作用:
- α=0.001時,HM最高。α過大會偏向基類擬合(如α=0.01時新類74.32%),過小則難以學習任務特征(α=0.0001時基類79.40%)。



:ROS入門指南 —— 核心解析與版本演進)


進程(2))











原理與應用)
