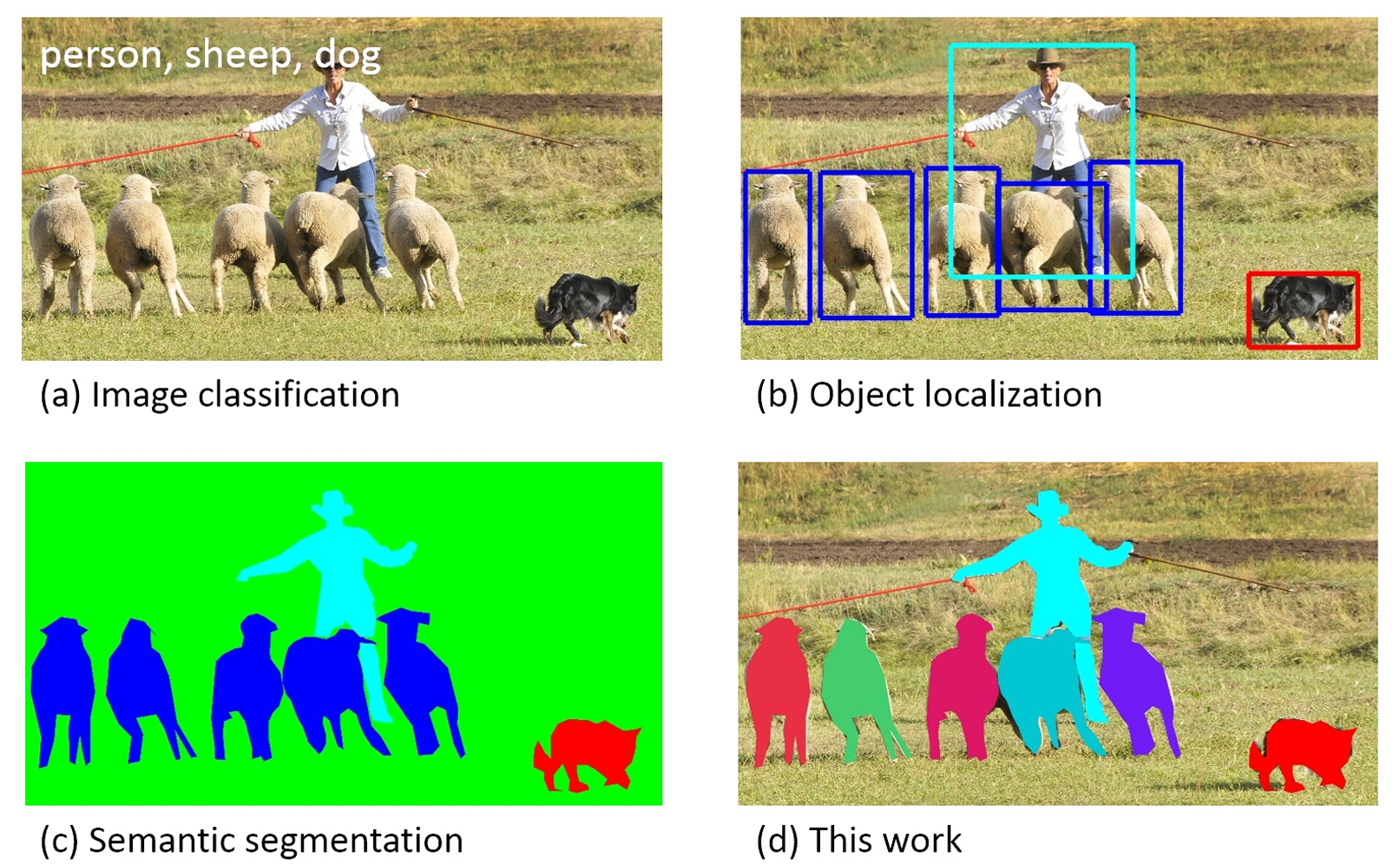
一、MS COCO數據集
COCO 是一個大規模的對象檢測、分割和圖像描述數據集。COCO有幾個 特點:
????????Object segmentation:目標級的分割(實例分割)
????????Recognition in context:上下文中的識別(圖像情景識別)
????????Superpixel stuff segmentation:超像素分割
????????330K images (>200K labeled):330K 圖像(>200K 已經做好標記)
????????1.5 million object instances:150 萬個對象實例
????????80 object categories:80 個目標類別
????????91 stuff categories: 91 個場景物體類別 (stuff中包含沒有明確邊界 的材料和對象,比如天空)
????????5 captions per image:每張圖片 5 個情景描述(標題)
????????250,000 people with keypoints:250,000 人體的關鍵點標注
注意:80 object categories 是 91 stuff categories 的子集
????????80 object categories 是傳統意義上的“物體”,通常是可以單獨識別和分 割的具體對象。它們通常具有明確的邊界,可以用邊界框(bounding box)和分割掩碼(segmentation mask)進行標注。例如:人 (person)、自行車(bicycle) 這些物體類別在圖像中通常是離散的,可 以被獨立標注和識別。
????????91 Stuff Categories 是“場景物體”或“背景物體”,通常是一些沒有明確邊 界的區域,通常作為背景存在。它們不容易被單獨識別,因為它們的邊界 通常是連續的。這些類別在圖像中通常覆蓋大面積,且沒有清晰的邊界。 例如:草(grass)、天空(sky) 這些場景物體類別的標注通常用于場景 解析任務,例如場景分割(scene segmentation),而不是對象檢測。
官方:
????????COCO - Common Objects in Context
論文
????????[1405.0312] Microsoft COCO: Common Objects in Context?
二、與Pascal VOC對比
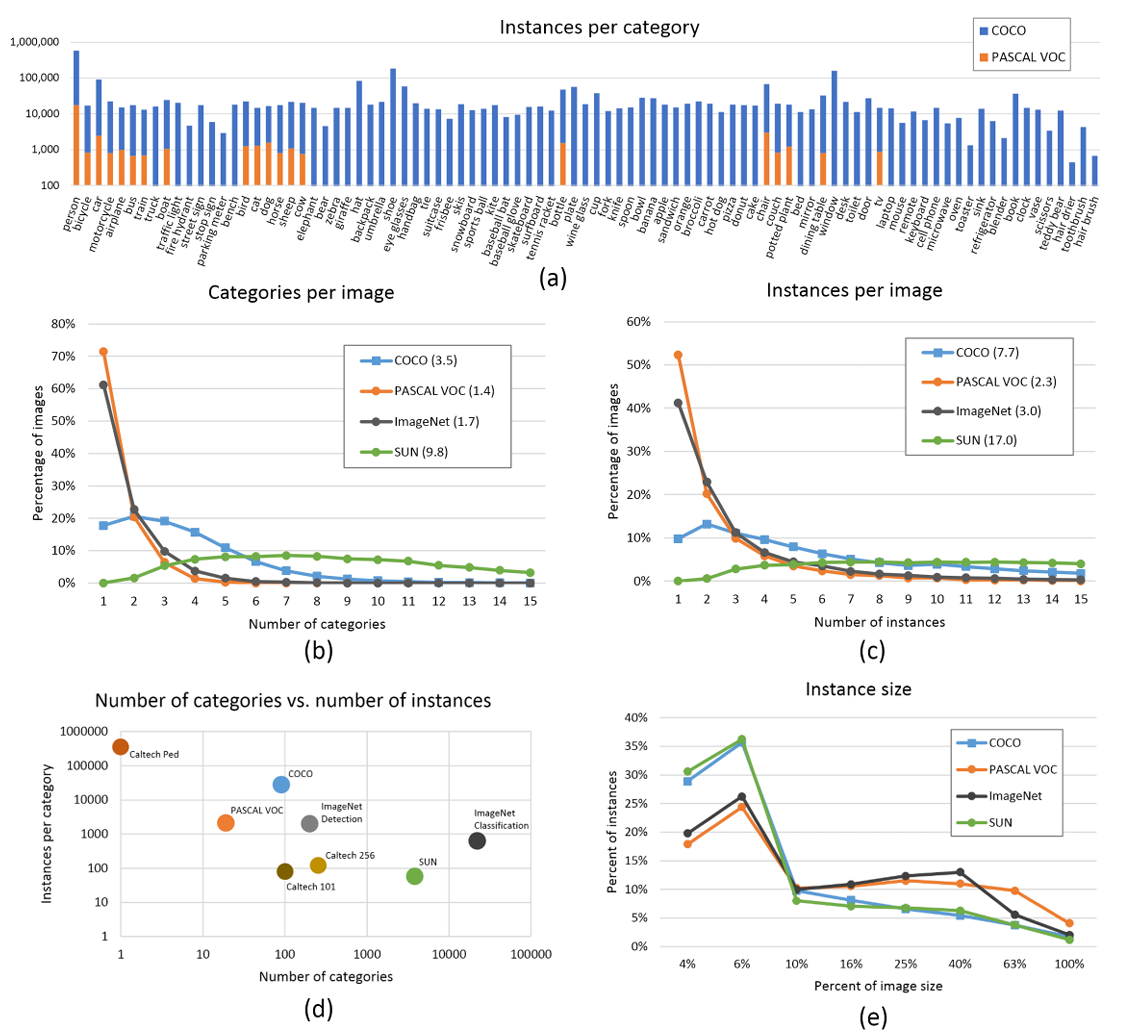
????????橙色是Pascal VOC包含的類別,藍色是COCO包含的類別。縱坐標是標注 的數量。 很
????????多模型的預訓練模型(模型文件)都是COCO數據集上訓練出來的,然后我們自己去做遷移學習進行訓練。
????????注意:COCO數據集訓練非常耗時,一般單塊GPU(如 NVIDIA V100): 通常需要數天到數周的訓練時間。
三、目標檢測需要的文件?
2017 Train images [118K/18GB]:訓練過程中使用到的所有圖像文件
2017 Val images [5K/1GB]:驗證過程中使用到的所有圖像文件
2017 Train/Val annotations[241MB]:對應訓練集和驗證集的標注json文 件
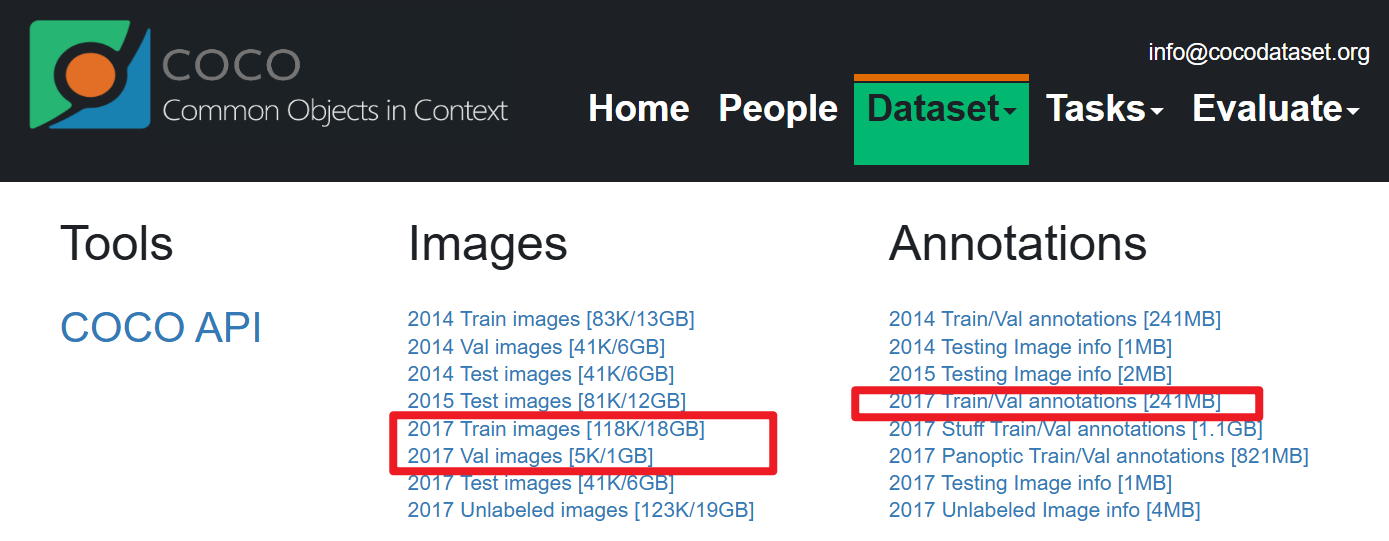
train2017:所有訓練圖像文件夾(118287張)
val2017:所有驗證圖像文件夾(5000張)
annotations:對應標注文件夾
????????|—instances train2017.json:對應目標檢測、分割任務的訓練集標注 文
????????|—instances_val2017.json:對應目標檢測、分割任務的驗證集標注文 件
????????|—captions train2017.json:對應圖像描述的訓練集標注文件
????????|—captions_va12017.json:對應圖像描述的驗證集標注文件
????????|—person keypoints train2017.json:對應人體關鍵點檢測的訓練集 標注文件
????????|—person_keypoints_val2017.json:對應人體關鍵點檢測的驗證集標 注文件夾
四、讀取COCO數據集的JSON
import jsonlabels =json.load(open("../annotations_trainval2017/annotations/instances_train2017.json","r"))
print(labels)?直接打印的話,打印不全,同時格式很亂,所以使用debug。

?其中:labels中有5個字典:分別是info、licenses、Images、 annotations、categories。
4.1、info

這個字典包含了關于數據集的基本信息。
????????description : 數據集的描述,這里是 "COCO 2017 Dataset"。
????????url : 數據集的URL鏈接,即官網地址,這里是 "https://cocodataset.org/"。
????????version : 數據集的版本號,這里是 "1.0"。
????????year : 數據集創建的年份,這里是 2017。
????????contributor : 數據集的貢獻者,這里是 "COCO Consortium"。
????????date_created : 數據集創建的日期,這里是 "2017/09/01"。
4.2、licenses

這個字典列表包含了數據集所用到的不同許可證的信息。
每個字典表示一種許可證,包含以下鍵:
????????id : 許可證的唯一標識符。
????????name : 許可證的名稱。
????????url : 許可證的詳細信息鏈接。
例如: id: 1 , name: Attribution-NonCommercial-ShareAlike License 代表此許可證。
4.3、images
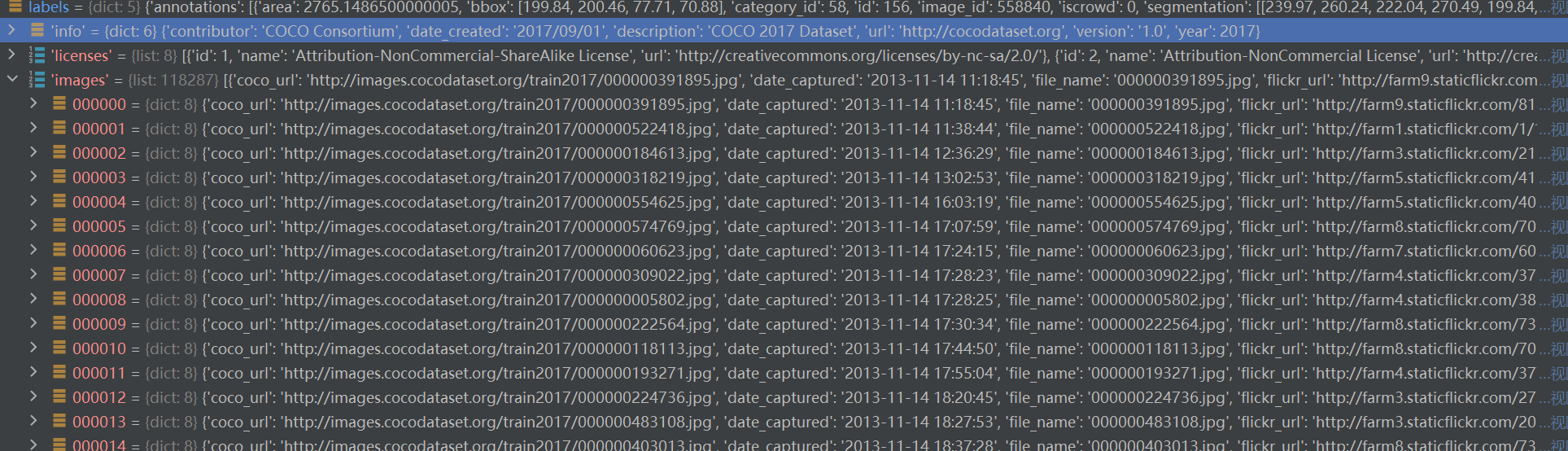
這個字典列表包含了數據集中所有圖像的信息。
每個字典表示一張圖像,包含以下鍵:
????????id : 圖像的唯一標識符。
????????coco_url : 圖像的COCO數據集URL。
????????其他可能包含的信息如文件名、高度、寬度等。
4.4、annotations
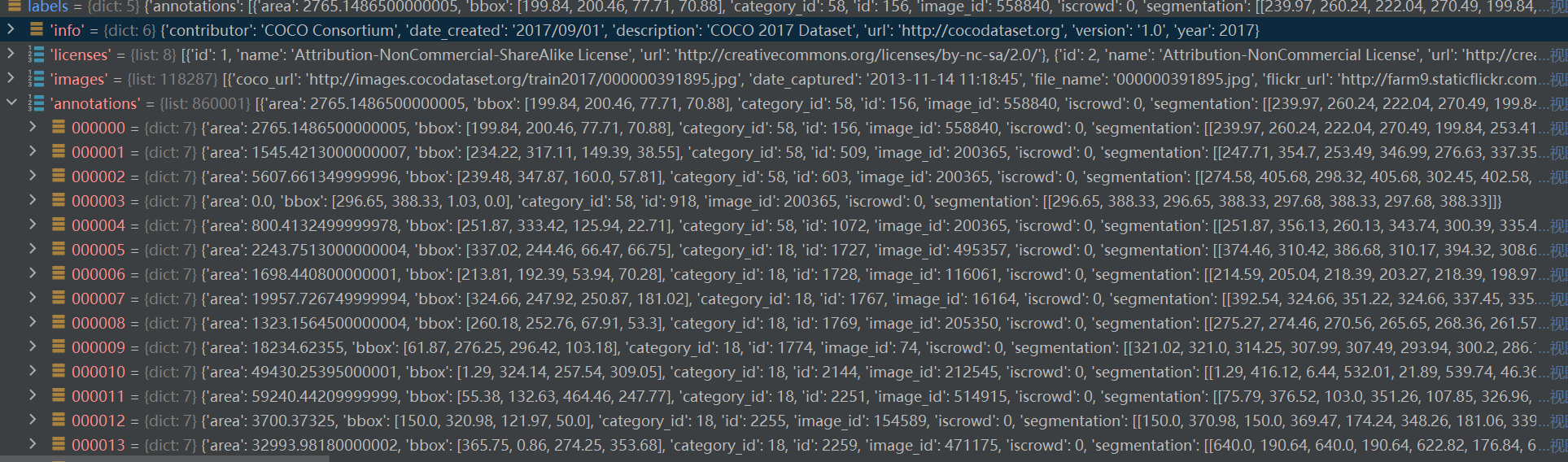
這個字典列表包含了數據集中所有標注的信息。
每個字典表示一個標注,包含以下鍵:
????????id : 標注的唯一標識符。
????????image_id : 該標注所屬圖像的唯一標識符。
????????category_id : 該標注所屬類別的唯一標識符(91 stuff categories的 索引)。
????????area : 標注區域的面積。
????????bbox : 標注的邊界框(bounding box),通常用一個四元組表示(x, y, width, height)。
????????segmentation : 分割標注的信息,通常是一個多邊形的點集。
????????其他標注信息如分數(score)、關鍵點(keypoints)等。
4.5、categories
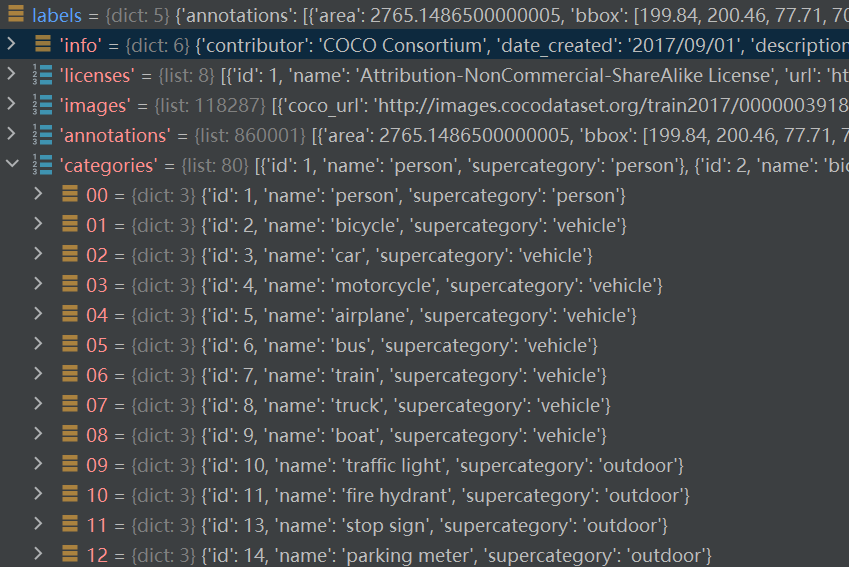
這個字典列表包含了數據集中所有類別的信息(91 stuff categories,使用 80 object categories時需要映射)。
每個字典表示一個類別,包含以下鍵:
????????id : 類別的唯一標識符。
????????name : 類別的名稱(如 "person", "bicycle" 等)。
????????supercategory : 類別的上一級分類(超類)。
例如:
????????id: 1 , name: person , supercategory: person 代表 "person" 類 別。
五、使用pycocotools讀取COCO數據集
5.1、安裝pycocotools
python -m pip install pycocotools-windows==2.0.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
5.2、讀取COCO數據集并顯示目標檢測的第一張
import os
import json
from PIL import Image, ImageDraw
from pycocotools.coco import COCO# COCO數據集的路徑
annotation_path = "./instances_val2017.json"
img_path = "./val2017/val2017"# 加載COCO數據集,打斷點
coco = COCO(annotation_path)
# 查看5000張圖像# 獲取所有圖像的ID
img_ids = coco.getImgIds()
# 看到所有5000張圖像的索引# 處理前5張圖像
for img_id in img_ids[:1]:# 獲取圖像信息,可以看到397133這章圖片的信息img_info = coco.loadImgs(img_id)[0]img_file = os.path.join(img_path, img_info['file_name'])# 打開圖像img = Image.open(img_file)draw = ImageDraw.Draw(img)# 獲取該圖像的所有標注# getAnnIds 函數可以接受多個參數,例如 imgIds、catIds 和 areaRng,以便根據圖像ID、類別ID或面積范圍來篩選標注。# 這個函數會返回一個標注ID列表,這些標注ID對應于指定圖像ID的所有標注。ann_ids = coco.getAnnIds(imgIds=img_id)anns = coco.loadAnns(ann_ids)for ann in anns:# 獲取類別名稱category_id = ann['category_id']category_name = coco.loadCats(category_id)[0]['name']# 獲取邊界框bbox = ann['bbox']x, y, w, h = bbox# 繪制邊界框draw.rectangle([x, y, x + w, y + h], outline="red", width=2)# 繪制類別名稱draw.text((x, y - 10), category_name, fill="red")# 顯示圖像img.show()


)






:ROS入門指南 —— 核心解析與版本演進)


進程(2))







