YOLOv1深度解析:單階段目標檢測的開山之作
一、YOLOv1概述
提出背景:
2016年由Joseph Redmon等人提出,全稱"You Only Look Once",首次將目標檢測視為回歸問題,開創單階段(One-Stage)檢測范式。相比兩階段檢測(如Faster R-CNN),YOLOv1無需生成候選區域(Region Proposal),直接通過卷積網絡回歸邊界框和類別,速度極快(45 FPS),適合實時場景(如視頻監控、自動駕駛)。
核心思想:
將輸入圖像劃分為 S×S網格(Grid),每個網格負責檢測中心落在該網格內的目標。每個網格輸出 B個邊界框(Bounding Box) 和 C個類別概率,最終通過非極大值抑制(NMS)生成檢測結果。
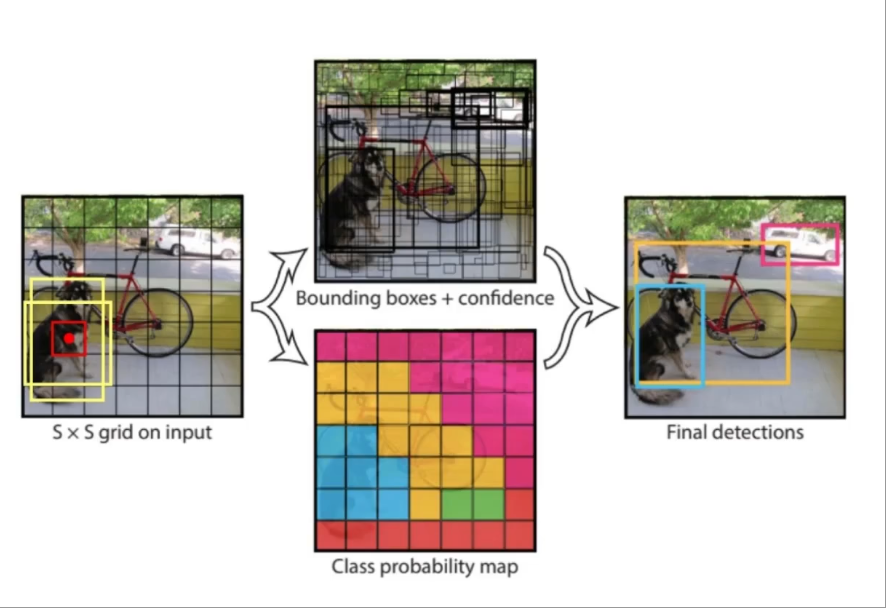
二、網絡架構與輸入輸出
1. 輸入
- 固定尺寸:448×448×3(RGB圖像),經縮放預處理后輸入。
- 目的:擴大感受野,提升小目標檢測能力(盡管YOLOv1對小目標效果仍有限)。
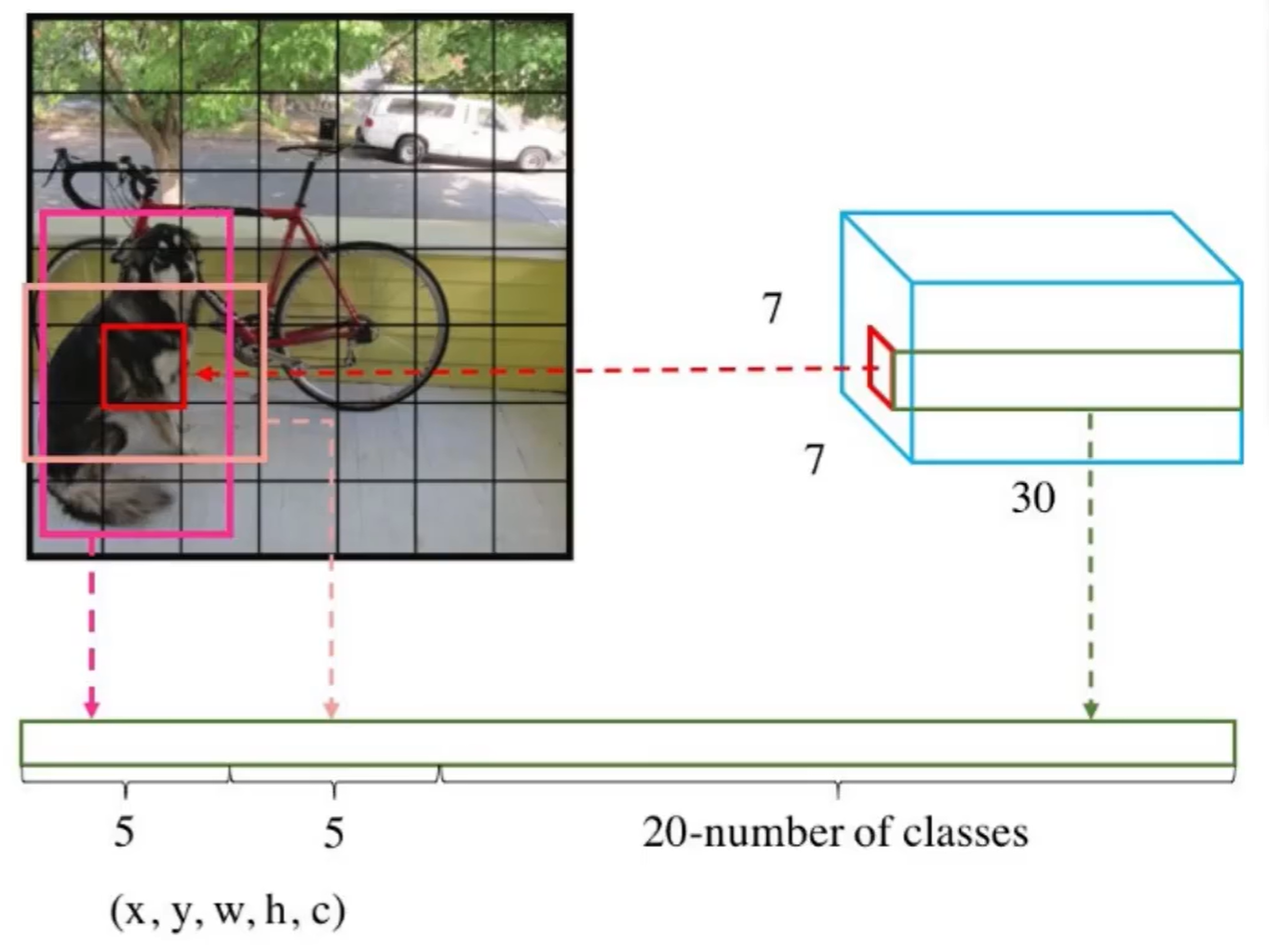
2. 網格劃分(S×S)
-
經典配置:S=7,即7×7網格,共49個網格單元。
-
每個網格輸出:
- B個邊界框(Bounding Box):每個框包含5個參數 → (x, y, w, h, confidence)
- (x, y):邊界框中心坐標,相對于網格左上角,歸一化到[0,1]。
- (w, h):邊界框寬高,相對于整幅圖像,歸一化到[0,1]。
- confidence:置信度 = Pr(Object) × IOUpredtruth,即“包含目標的概率”與“預測框與真實框的交并比”的乘積。
- C個類別概率:Pr(Class_i | Object),即網格內存在目標時,屬于各類別的條件概率,網格共享一組類別概率(非每個框獨立預測)。
- B個邊界框(Bounding Box):每個框包含5個參數 → (x, y, w, h, confidence)
-
參數總量:
每個網格輸出 → B×5 + C 個參數。
若取 B=2(YOLOv1默認),C=20(VOC數據集類別數),則總輸出為:
7×7×(2×5 + 20) = 7×7×30 = 1470維向量。
3. 網絡結構
基于 GoogLeNet 改進,包含 24個卷積層 和 2個全連接層,架構如下:
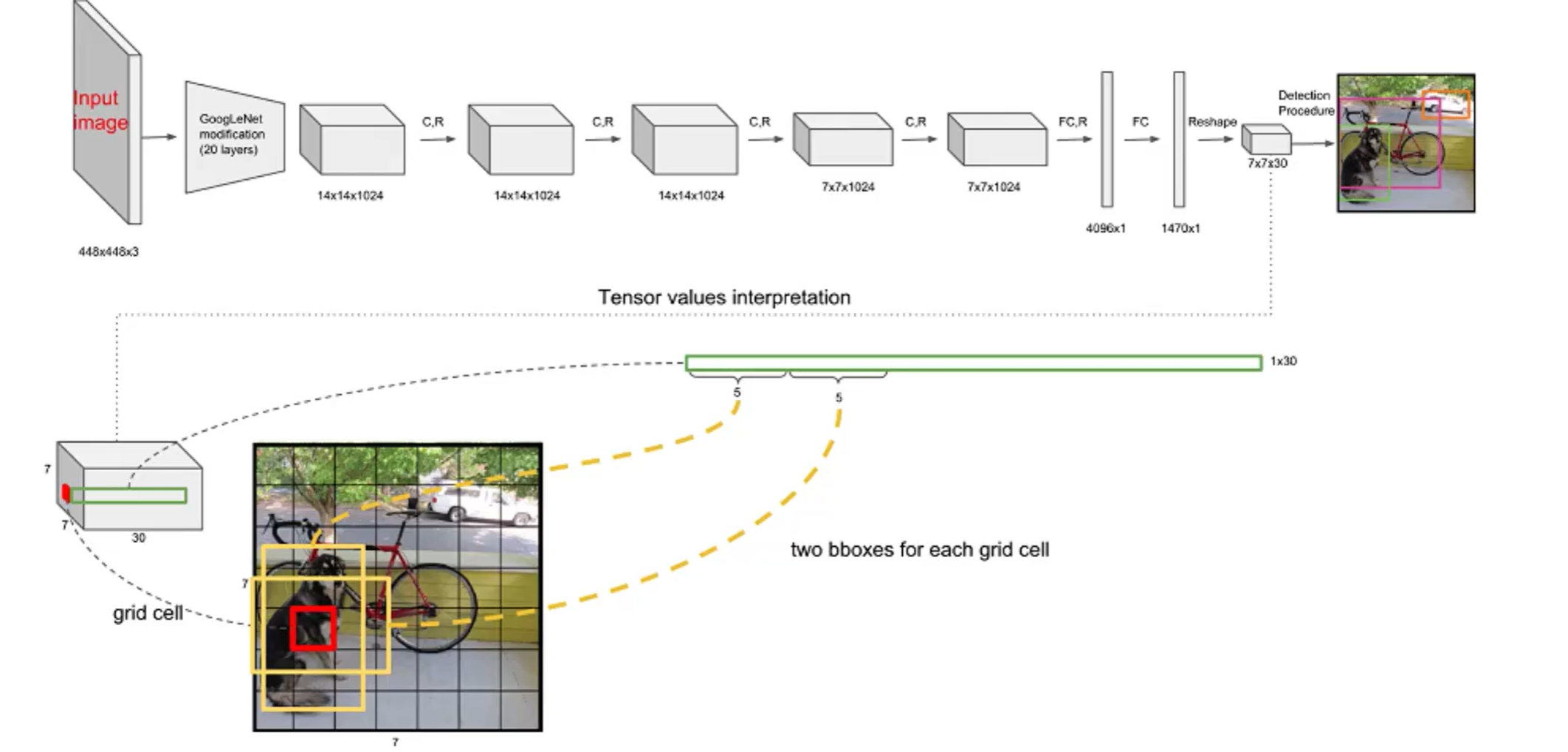
輸入 (448×448)
→ 卷積層:7×7×64,步長2×2, padding=3 → 輸出224×224×64(最大池化2×2,步長2)
→ 卷積層:3×3×192,步長1×1, padding=1 → 輸出112×112×192(最大池化2×2,步長2)
→ 卷積層:1×1×128, 3×3×256, 1×1×256, 3×3×512(重復4次)→ 輸出28×28×512(最大池化2×2,步長2)
→ 卷積層:1×1×512, 3×3×1024(重復2次)→ 輸出14×14×1024(最大池化2×2,步長2)
→ 卷積層:3×3×1024,步長1×1, padding=1 → 輸出7×7×1024
→ 全連接層: flatten后接4096維全連接 → 再接7×7×30維全連接 → 輸出預測結果
- 特點:
- 卷積層主導特征提取,全連接層負責坐標和類別的回歸。
- 大量使用 1×1卷積 降維,減少計算量(如從192→128通道)。
- 無錨框(Anchor Box)設計,邊界框尺寸直接通過網絡學習(后續YOLOv2引入錨框)。
三、損失函數設計
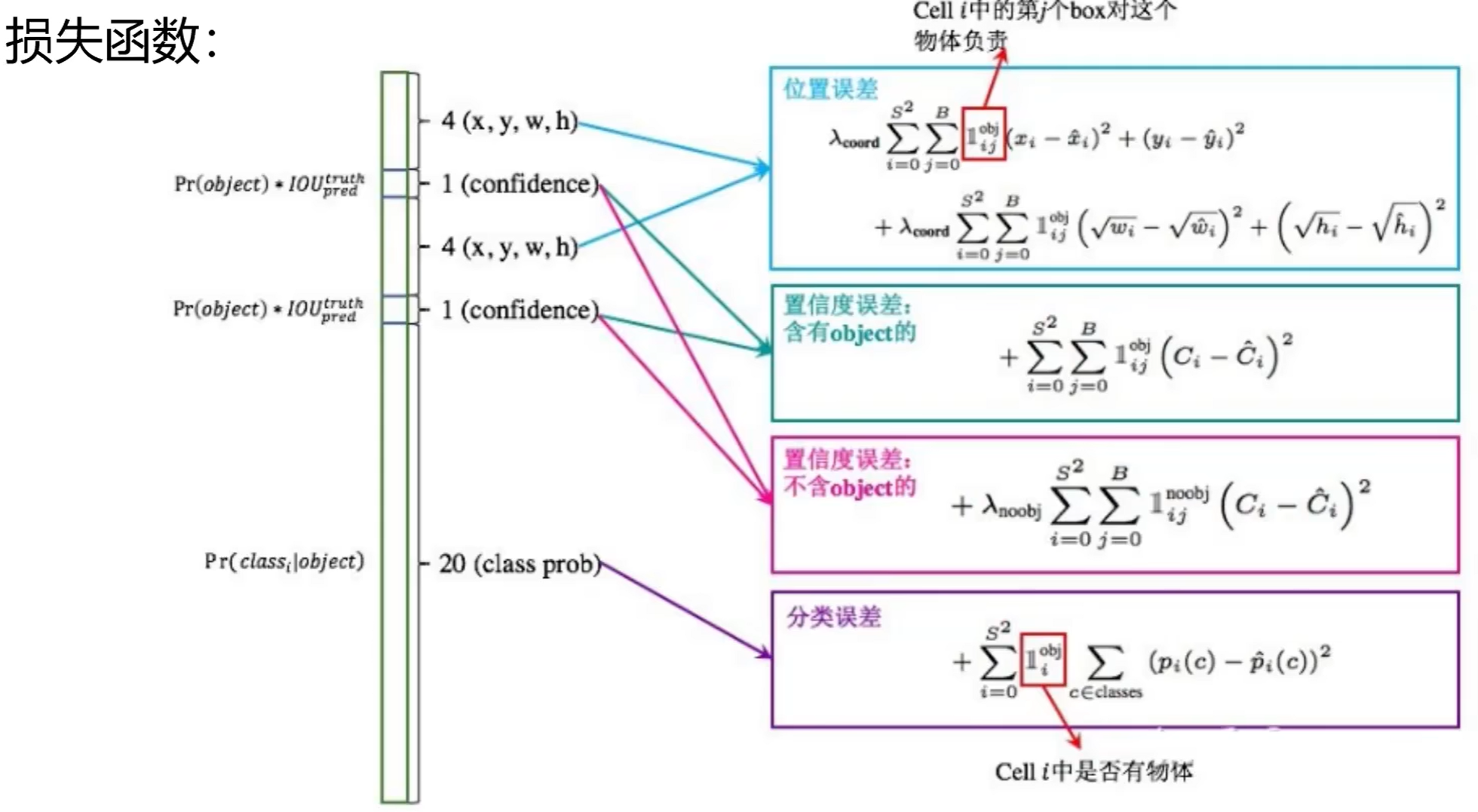
YOLOv1采用 均方誤差(MSE) 作為損失函數,但針對不同任務(坐標、置信度、類別)設計了加權因子,以解決樣本不平衡和尺度敏感問題。損失函數公式如下:
L l o s s = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j [ ( x i ? x i ^ ) 2 + ( y i ? y i ^ ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j [ ( w i ? w i ^ ) 2 + ( h i ? h i ^ ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j ( C i ? C i ^ ) 2 + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i , j n o o b j ( C i ? C i ^ ) 2 + ∑ i = 0 S 2 1 i o b j ∑ c ∈ c l a s s e s ( p i ( c ) ? p i ^ ( c ) ) 2 L_{loss} = \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^{B} 1_{i,j}^{obj} \left[ (x_i - \hat{x_i})^2 + (y_i - \hat{y_i})^2 \right] + \\ \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^{B} 1_{i,j}^{obj} \left[ (\sqrt{w_i} - \sqrt{\hat{w_i}})^2 + (\sqrt{h_i} - \sqrt{\hat{h_i}})^2 \right] + \\ \sum_{i=0}^{S^2} \sum_{j=0}^{B} 1_{i,j}^{obj} (C_i - \hat{C_i})^2 + \lambda_{noobj} \sum_{i=0}^{S^2} \sum_{j=0}^{B} 1_{i,j}^{noobj} (C_i - \hat{C_i})^2 + \\ \sum_{i=0}^{S^2} 1_i^{obj} \sum_{c \in classes} (p_i(c) - \hat{p_i}(c))^2 Lloss?=λcoord?∑i=0S2?∑j=0B?1i,jobj?[(xi??xi?^?)2+(yi??yi?^?)2]+λcoord?∑i=0S2?∑j=0B?1i,jobj?[(wi???wi?^??)2+(hi???hi?^??)2]+∑i=0S2?∑j=0B?1i,jobj?(Ci??Ci?^?)2+λnoobj?∑i=0S2?∑j=0B?1i,jnoobj?(Ci??Ci?^?)2+∑i=0S2?1iobj?∑c∈classes?(pi?(c)?pi?^?(c))2
各部分解析:
-
坐標誤差(前兩行):
- 權重: λ c o o r d = 5 \lambda_{coord}=5 λcoord?=5(增大坐標回歸的權重,因邊界框位置是檢測的核心指標)。
- 寬高平方根: w , h \sqrt{w}, \sqrt{h} w?,h? 替代直接回歸 w , h w, h w,h,緩解大框和小框的誤差不平衡(小框的絕對誤差對IOU影響更大)。
- 掩碼: 1 i , j o b j 1_{i,j}^{obj} 1i,jobj? 表示第 i i i個網格的第 j j j個框是否負責真實目標(即該框與真實框的IOU最大)。
-
置信度誤差(中間兩行):
- 有目標的框: 1 i , j o b j 1_{i,j}^{obj} 1i,jobj? 對應權重為1,直接監督置信度與真實IOU的接近程度。
- 無目標的框: 1 i , j n o o b j 1_{i,j}^{noobj} 1i,jnoobj? 對應權重為 λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj?=0.5(降低負(背景)樣本的置信度損失,因負樣本數量遠多于正樣本)。
-
類別誤差(最后一行):
- 權重:默認1,僅在網格 i i i包含真實目標時( 1 i o b j = 1 1_i^{obj}=1 1iobj?=1)計算類別損失。
四、訓練策略
1. 預訓練與微調
- 預訓練:在ImageNet分類數據集上訓練前20個卷積層+1個全連接層,輸入尺寸224×224,學習目標為1000類分類。
- 微調:
- 新增4個卷積層和2個全連接層,輸入尺寸擴大至448×448。
- 凍結前20層卷積層,訓練新增層;后期解凍所有層,整體微調。
2. 數據增強
- 隨機翻轉、裁剪、縮放(尺度因子0.5~1.5)。
- 顏色抖動(調整亮度、對比度、飽和度)。
- 高斯噪聲注入,提升模型魯棒性。
3. 多尺度訓練
- 每隔一定迭代次數(如10 batches),隨機將輸入圖像尺寸調整為{320, 352, …, 608}(32的倍數),迫使模型適應不同尺度的目標,增強泛化能力。
五、推理過程
-
邊界框解碼:
- 網格 i , j i,j i,j的左上角坐標為 ( i , j ) (i, j) (i,j)(假設網格尺寸為1×1,實際需根據圖像尺寸縮放)。
- 預測的 ( x , y ) (x, y) (x,y)是相對于網格的偏移量,真實坐標為:
x p r e d = ( i + x ) × W S , y p r e d = ( j + y ) × H S x_{pred} = (i + x) \times \frac{W}{S}, \quad y_{pred} = (j + y) \times \frac{H}{S} xpred?=(i+x)×SW?,ypred?=(j+y)×SH?
其中 W , H W, H W,H為輸入圖像寬高, S = 7 S=7 S=7。 - 寬高 ( w , h ) (w, h) (w,h)直接乘以圖像寬高:
w p r e d = w × W , h p r e d = h × H w_{pred} = w \times W, \quad h_{pred} = h \times H wpred?=w×W,hpred?=h×H
-
置信度過濾與NMS:
- 對每個邊界框,計算 類別置信度 = 類別概率 × 置信度,過濾低于閾值(如0.2)的框。
- 對同一類別,使用NMS去除重疊框,保留高置信度的框。
六、優缺點分析
優點
- 速度快:端到端檢測,45 FPS(GPU),可實時處理視頻流。
- 結構簡單:單網絡完成特征提取和預測,無需候選區域生成,訓練和部署便捷。
- 全局視野:直接從全圖預測,不易漏檢背景中的目標(兩階段模型可能因候選區域局限漏檢)。
缺點
-
小目標檢測差:
- 7×7網格分辨率低,小目標在特征圖中占比小,信息不足。
- 每個網格僅預測2個框,小目標可能因重疊導致IOU低而被抑制。
-
邊界框預測不準:
- 無錨框先驗,全靠網絡學習寬高比例,對非常規比例目標(如狹長物體)泛化能力弱。
- 直接回歸寬高,缺乏尺度不變性(YOLOv2通過錨框和對數空間回歸改進)。
-
密集目標漏檢:
- 同一網格內多個目標(如人群)僅能輸出2個框,易漏檢。
-
類別不平衡:
- 無目標的網格(負樣本)占多數,雖通過權重緩解,但仍影響置信度學習。
七、YOLOv1的影響與后續改進
-
對檢測領域的貢獻:
- 開創單階段檢測范式,推動實時檢測發展(如YOLO系列、SSD、RetinaNet)。
- 證明“全局特征建模”在檢測中的有效性,啟發后續模型融合上下文信息。
-
后續YOLO版本的改進方向:
- YOLOv2(2017):引入錨框、批歸一化、多尺度訓練,使用Darknet-19,精度和速度提升。
- YOLOv3(2018):多尺度預測(FPN結構)、Darknet-53、二元交叉熵損失(適用于多標簽分類)。
- YOLOv4/YOLOv5(2020年后):集成數據增強、注意力機制、模型輕量化等技術,進一步提升性能。
八、與兩階段檢測的對比
| 維度 | YOLOv1 | Faster R-CNN |
|---|---|---|
| 檢測流程 | 單階段(直接回歸框和類別) | 兩階段(先候選區域,再分類/回歸) |
| 速度 | 快(45 FPS) | 慢(~7 FPS) |
| 精度(mAP) | 較低(VOC 2007: ~63.4%) | 較高(VOC 2007: ~78.8%) |
| 設計哲學 | 速度優先,適合實時場景 | 精度優先,適合高要求場景 |
九、總結
YOLOv1以其顛覆性的單階段設計,重新定義了目標檢測的速度與實時性標準。盡管存在小目標檢測弱、框預測不準等缺陷,但其開創的“端到端回歸”思路為后續檢測模型奠定了基礎。通過理解YOLOv1的核心原理(網格劃分、損失函數設計、訓練策略),可深入把握單階段檢測的本質,并更好地理解后續YOLO版本的改進邏輯。


















)
