
一、CAP理論在服務注冊與發現中的落地實踐
1.1 CAP三要素的技術權衡
| 要素 | AP模型實現 | CP模型實現 |
|---|---|---|
| 一致性 | 最終一致性(Eureka通過異步復制實現) | 強一致性(ZooKeeper通過ZAB協議保證) |
| 可用性 | 服務節點可獨立響應(支持分區存活) | 分區期間無法保證寫操作(需多數節點可用) |
| 分區容錯性 | 必須支持(分布式系統基本要求) | 必須支持(通過復制協議實現) |
典型場景對比:
- 電商秒殺(AP):允許部分用戶看到舊服務列表,但保證頁面可訪問。
- 銀行轉賬(CP):必須等待服務狀態全局一致,避免資金不一致風險。
二、AP模型深度解析:高可用優先的設計哲學
2.1 核心場景與技術實現
2.1.1 適用場景特征
- 動態伸縮性要求高:
容器化環境中服務實例每分鐘上下線超100次(如Kubernetes集群),AP模型的無主節點架構(如Eureka集群)可避免主節點成為瓶頸。 - 讀多寫少操作:
服務發現請求中查詢占比>90%,寫入(注冊/注銷)頻率低,允許緩存數據短暫不一致。
2.1.2 關鍵技術方案
Eureka架構解析:
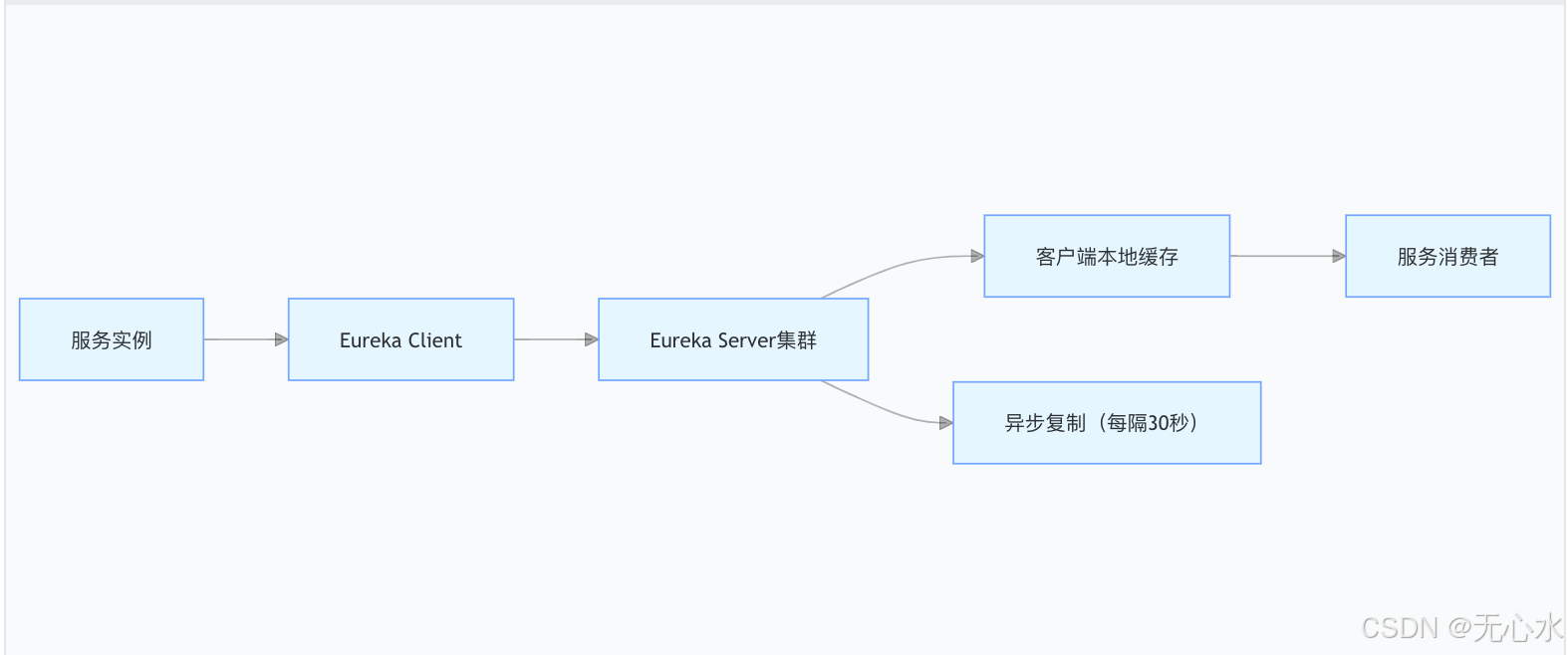
- 心跳機制:服務實例每30秒發送心跳,超時90秒標記為失效。
- 緩存策略:客戶端緩存服務列表,默認30秒更新一次,注冊中心宕機時仍可調用。
- 自我保護模式:當心跳失敗比例>85%,停止剔除服務實例,避免網絡分區誤判。
Consul AP模式配置:
# consul配置文件
datacenter = "dc1"
server = true
bootstrap_expect = 3
# 開啟AP模式(犧牲強一致性換取可用性)
disable_leader = true
disable_gossip = true
三、CP模型深度解析:強一致性優先的設計哲學
3.1 核心場景與技術實現
3.1.1 適用場景特征
- 分布式協調需求:
如Kubernetes的節點注冊(需保證Pod列表實時一致)、分布式鎖(如Redlock)。 - 配置中心場景:
服務配置變更(如限流規則)需秒級同步到所有節點,避免部分節點使用舊配置導致故障。
3.1.2 關鍵技術方案
ZooKeeper一致性實現:
- ZAB協議:
寫請求由Leader節點處理,通過二階段提交確保多數節點持久化后才返回成功。 - Watcher機制:
服務消費者監聽節點變更事件,配置更新時主動推送通知(延遲<500ms)。
Etcd Raft協議流程:
// Etcd節點狀態機
type NodeState int
const (Follower NodeState = iotaCandidateLeader
)// 選舉流程
func (n *Node) startElection() {n.currentTerm++n.votedFor = n.idn.resetTimeout()// 向所有節點發送投票請求for _, peer := range n.peers {go n.sendRequestVote(peer, n.currentTerm, n.id)}
}
四、AP與CP的綜合對比與選型框架
4.1 核心維度對比表
| 維度 | AP模型(Eureka) | CP模型(ZooKeeper) |
|---|---|---|
| 一致性級別 | 最終一致性(可能返回舊數據) | 強一致性(寫操作等待多數節點確認) |
| 可用性 | 高(分區期間仍可讀) | 中(分區時無法保證寫可用性) |
| 吞吐量 | 高(無鎖機制,支持橫向擴展) | 中(受限于Leader節點性能) |
| 典型QPS | 10萬+/秒(集群規模>10節點) | 1萬+/秒(集群規模≤5節點) |
| 節點規模限制 | 無(理論支持無限節點) | ≤7節點(Raft協議最佳實踐) |
| 運維復雜度 | 低(無主節點,自動負載均衡) | 高(需維護Leader選舉與數據復制) |
4.2 三維度選型框架
4.2.1 業務容忍度維度
- 一致性容忍閾值:
- 允許數據不一致時間<10秒 → 選AP(如商品詳情頁服務發現)。
- 必須實時一致 → 選CP(如金融交易路由)。
- 可用性SLA:
- 99.99% → AP(通過多活數據中心實現)。
- 99.9% → 可接受CP(如內部管理系統)。
4.2.2 系統規模維度
- 服務實例數:
- >1000個 → AP(Eureka/Consul更適合大規模動態節點)。
- <100個 → CP(ZooKeeper/Etcd管理成本低)。
- 網絡分區概率:
- 云原生環境(跨可用區部署)→ AP(分區概率高,需快速 failover)。
- 單數據中心 → CP(分區概率低,優先保證一致性)。
4.2.3 技術生態維度
- Kubernetes場景:
首選CP(Etcd作為默認注冊中心,支持K8s強一致性需求)。 - Spring Cloud場景:
可選AP(Eureka已停更,推薦Consul混合模式)。
五、現代架構中的混合策略與優化方案
5.1 分層設計:核心服務與邊緣服務分離
graph TBA[業務系統] --> B[核心服務層(CP)]A --> C[邊緣服務層(AP)]B --> D[Etcd(強一致性)]C --> E[Consul(AP模式)]D --> F[支付/交易服務]E --> G[推薦/營銷服務]
- 核心層:支付、用戶中心等使用Etcd,保證交易路由實時一致。
- 邊緣層:推薦服務、靜態資源服務使用Consul AP模式,提升高并發下的可用性。
5.2 服務網格(Service Mesh)方案
Istio + Etcd架構:
graph LRA[客戶端] --> B[Envoy Sidecar]B --> C[Istio Pilot(控制平面)]C --> D[Etcd(CP存儲)]B --> E[服務實例]C --> F[定期同步服務列表(AP優化)]
- 數據平面:Envoy Sidecar緩存服務列表,注冊中心宕機時仍可路由(AP特性)。
- 控制平面:Istio Pilot從Etcd獲取實時數據(CP特性),保證配置變更強一致。
5.3 動態切換方案(Nacos)
# Nacos配置中心動態切換模式
from nacos import NacosConfigClientclient = NacosConfigClient(server_addresses="127.0.0.1:8848")# 切換為CP模式(適用于配置發布)
client.set_mode("CP")
client.publish_config(data_id="service-routing", group="DEFAULT_GROUP", content="strict-consistency")# 切換為AP模式(適用于服務發現)
client.set_mode("AP")
六、高可用設計的三大支柱與最佳實踐
6.1 服務端崩潰檢測優化
6.1.1 心跳機制調優
| 指標 | AP模型(Eureka) | CP模型(ZooKeeper) |
|---|---|---|
| 心跳間隔 | 30秒(可配置) | 2秒(默認) |
| 超時閾值 | 90秒(3次心跳失敗) | 6秒(3次心跳失敗) |
| 網絡抖動容忍 | 開啟自我保護模式 | 無(直接標記為失效) |
6.1.2 故障轉移策略
// 客戶端重試邏輯(Java示例)
public class ServiceClient {private static final int MAX_RETRIES = 3;private static final long RETRY_INTERVAL = 500; // 500ms間隔public Object invoke(ServiceInstance instance) {for (int i = 0; i < MAX_RETRIES; i++) {try {return doInvoke(instance);} catch (Exception e) {if (i == MAX_RETRIES - 1) {circuitBreaker.open(); // 觸發熔斷}Thread.sleep(RETRY_INTERVAL);instance = loadBalancer.choose(); // 切換節點}}throw new ServiceUnavailableException();}
}
6.2 客戶端容錯體系
6.2.1 本地緩存策略
# Python客戶端緩存實現(使用Redis)
import redis
import timeclass ServiceRegistryCache:def __init__(self):self.redis = redis.Redis(host='localhost', port=6379)self.ttl = 30 # 緩存有效期30秒def get_instances(self, service_name):instances = self.redis.get(f"sr:{service_name}")if instances:return json.loads(instances)# 緩存失效時查詢注冊中心instances = self.query_registry(service_name)self.redis.setex(f"sr:{service_name}", self.ttl, json.dumps(instances))return instances
6.2.2 主動健康探測
// Go語言實現客戶端主動探測
func healthProbe(instance string) bool {timeout := time.Duration(2) * time.Secondctx, cancel := context.WithTimeout(context.Background(), timeout)defer cancel()req, err := http.NewRequestWithContext(ctx, "GET", instance+"/health", nil)if err != nil {return false}resp, err := http.DefaultClient.Do(req)return err == nil && resp.StatusCode == http.StatusOK
}
6.3 注冊中心集群優化
6.3.1 AP集群橫向擴展
Eureka集群部署架構:
# 負載均衡配置
upstream eureka_servers {server eureka-node1:8761;server eureka-node2:8762;server eureka-node3:8763;least_conn; # 最小連接數負載均衡
}server {listen 80;location /eureka/ {proxy_pass http://eureka_servers;proxy_http_version 1.1;proxy_set_header Connection "";}
}
6.3.2 CP集群節點規劃
Etcd集群最佳實踐:
- 節點數:3/5/7(奇數,滿足多數派原則)。
- 部署方式:跨可用區(如2AZ部署5節點,3+2分布)。
- 硬件配置:SSD磁盤(保證寫入性能),萬兆網絡(降低復制延遲)。
七、面試高頻考點與答題模板
7.1 注冊中心崩潰應急處理
問題:當注冊中心整體不可用時,微服務系統如何保證可用性?
答題模板:
- 客戶端本地緩存:依賴之前緩存的服務列表繼續調用(AP模型默認支持,CP模型需手動開啟)。
- 靜態路由兜底:預先配置關鍵服務的IP列表(如數據庫連接),通過環境變量注入。
- 熔斷與降級:關閉服務發現功能,直接訪問已知存活節點,非核心業務返回默認值。
- 注冊中心恢復策略:優先恢復讀接口(AP模型可快速恢復),再逐步恢復寫操作(CP模型需重新選舉Leader)。
7.2 心跳機制設計權衡
問題:心跳間隔設置為1秒和30秒各有什么優缺點?
答題模板:
- 1秒間隔:
- 優點:故障檢測速度快(3秒內發現節點宕機)。
- 缺點:網絡負載高(每個節點每秒發送心跳),可能引發流量風暴(如1000個節點每秒產生1000次請求)。
- 30秒間隔:
- 優點:網絡開銷低(Eureka默認配置),適合大規模集群。
- 缺點:故障恢復延遲長(90秒后才標記為失效),可能導致大量請求失敗。
- 優化方案:采用動態心跳機制(如初始30秒,連續3次失敗后改為5秒間隔)。
7.3 AP與CP的本質區別
問題:從CAP理論角度,說明AP和CP注冊中心的核心差異?
答題模板:
- AP模型:
- 放棄強一致性,保證分區期間服務可讀寫(如Eureka在網絡分區時,各分區獨立維護服務列表)。
- 適用于“最終一致性”場景,通過異步復制實現數據收斂。
- CP模型:
- 放棄可用性,保證分區期間只有多數節點存活時才能寫(如ZooKeeper在分區時無法響應寫請求)。
- 適用于“強一致性”場景,通過共識協議(如ZAB/Raft)保證數據全局一致。
八、行業案例:不同場景下的選型實踐
8.1 電商平臺(AP優先)
場景:雙11大促期間,每秒新增200個容器實例,服務發現QPS峰值達50萬次/秒。
方案:
- 注冊中心:Consul AP模式(支持動態擴縮容)。
- 優化點:
- 客戶端緩存TTL從30秒降至10秒,提升數據新鮮度。
- 開啟Consul的Gossip協議優化,減少廣播風暴。
- 效果:服務發現成功率>99.9%,故障恢復時間<30秒。
8.2 金融交易系統(CP優先)
場景:跨境支付服務,要求服務路由實時一致,每日交易筆數>100萬。
方案:
- 注冊中心:Etcd集群(3節點,Raft協議)。
- 優化點:
- 啟用預寫日志(WAL)持久化,保證數據不丟失。
- 客戶端采用長連接監聽節點變更(Watch機制),配置更新延遲<1秒。
- 效果:交易路由錯誤率<0.001%,滿足PCI-DSS合規要求。
九、總結:黃金選型法則與行動建議
9.1 黃金選型法則
- 80%原則:80%的互聯網應用選擇AP模型(如Eureka/Consul),僅20%強一致性場景選CP(如金融/分布式協調)。
- 混合模式優先:優先考慮支持AP/CP切換的中間件(如Nacos),避免技術棧鎖定。
- 成本驅動:小規模團隊優先AP(運維簡單),大型團隊可投入CP(滿足復雜需求)。
9.2 落地行動建議
- 壓力測試:
- 模擬網絡分區,測試AP模型的最終一致性時間(如Eureka自我保護模式下的恢復時間)。
- 模擬節點宕機,測試CP模型的Leader選舉耗時(如Etcd<200ms)。
- 監控指標:
- AP模型:監控緩存命中率、心跳失敗率、自我保護模式觸發次數。
- CP模型:監控Leader節點延遲、復制滯后時間、節點投票耗時。
- 應急預案:
- 準備靜態路由配置,應對注冊中心長時間不可用。
- 定期演練注冊中心切換(如從AP切CP),確保災備流程可行。






)

)




/ 并發 GET解決思路)





