文章目錄
- 摘要
- 1 引言
- 2 相關工作
- 3 方法
- 3.1 HmSDF 表示
- 3.2 區域聚合
- 3.3. 變形場
- 3.4. 遮擋感知可微分渲染
- 3.5 訓練
- 3.5.1 訓練策略
- 3.5.2 重建損失
- 3.5.3 正則化限制
- 4. 實驗
- 4.1 定量評估
- 4.2 定性評價
- 4.3 消融研究
- 4.4 應用程序
- 5 結論

摘要
我們介紹 D 3 D^{3} D3人,一種從單目視頻中重建動態解耦數字人體幾何的方法。過去的單目視頻人體重建主要集中在重建未解耦的衣服人體或僅重建服裝,使得其難以直接應用于動畫制作等應用中。重建解耦的衣服和身體的挑戰在于衣服對身體造成的遮擋。為此,在重建過程中必須確保可見區域的細節和不可見區域的合理性。我們提出的方法結合顯式和隱式表示對解耦的衣服人體進行建模,利用顯式表示的魯棒性和隱式表示的靈活性。具體來說,我們將可見區域重建為SDF,并提出一種新穎的人類流形符號距離場(hmSDF)來分割可見衣服和可見身體,然后合并可見和不可見身體。廣泛的實驗結果表明,與現有的重建方案相比, D 3 D^{3} D3可以實現人體穿著不同服裝的高質量解耦重建,并可以直接應用于服裝轉移和動畫。
1 引言
衣著人體重建長期以來一直是圖形學和計算機視覺領域的研究熱點,在虛擬現實、增強現實、全息通信、電影制作、游戲開發等諸多領域有著廣泛的應用。相比需要眾多攝像機和藝術家進行建模的電影級重建,從單目視頻中重建高質量的衣著人體對一般用戶來說更具實用價值。在遠程呈現和虛擬試穿等場景中,使用的3D化身應該易于訪問、視覺逼真且易于編輯,包括對服裝和姿勢的修改。因此,如何利用單目視頻重建高保真、解耦的衣著人體表示仍然是一個長期存在的研究問題。**通過解耦重建,**可以將服裝與人體分離,從而實現對不同服裝風格、姿勢和體型的高效調整和編輯。這種解耦不僅增強了三維重建的靈活性和實用性,還提高了細節特征的真實感,為虛擬角色的個性化和動態交互提供了更大的潛力。
我們的目標是開發一種從單眼視頻中解耦和重建穿著衣服的人體的方法。然而,這是一項非常具有挑戰性的任務,因為1)單目視頻僅提供單視圖2D圖像信息,缺乏直接的3D深度感知,2)真實拍攝的視頻包含各種服裝樣式、不規則紋理和復雜的人體姿勢,3)被衣服遮擋的身體部位在輸入視頻中不可見,這也對重建提出了很大的挑戰。現有方法可分為顯式表達方法和隱式表達方法。其中,顯式表達方法通常依賴于預先獲取的模板。一些方法[15、16、56]使用掃描儀,而其他方法[2、28、41]依賴于參數模型[19、34],重建質量主要取決于模型的表示能力。隱式表示方法[9,14,20,22,42]使用NeRF[37]或SDF[40]來模擬穿著衣服的人體,但它們通常會產生不可分割的整體或表現出平均的幾何質量。
我們提出了一種解耦的人體重建方案,命名為 D 3 D^{3} D3-人類(動態解耦數字人類),它結合了顯式和隱式表示來解決模板生成的主要挑戰和動態變形。在解耦的人體重建中,生成服裝模板特別具有挑戰性。傳統方法,例如基于參數模型[28]或特征線[45]的方法,嚴重依賴先驗,限制了它們可以表示的服裝類型。雖然隱式無符號距離場(UDF)表示[5,13,31,33]提供了一些解決方案,但當單視圖監督受到限制時,它們的表現不佳(參見實驗4.3)。對于可見區域,受GShell[32]和DMTet[52]的啟發,我們在非解耦的衣服人體表面上定義了一個可優化的人體流形有符號距離場(hmSDF),以將服裝與身體分開。據我們所知,這是第一種可以在沒有任何3D服裝先驗的情況下從單目動態人體視頻中重建服裝幾何形狀的方法,僅使用易于獲得的2D人體解析分割[46]。對于身體的不可見區域,我們采用SMPL[34]模型的相應區域的顯式表示,以確保身體形狀的合理性以及與可見區域的無縫集成。這種方法能夠對穿著衣服的人體進行詳細和解耦的重建。
我們基于單目視頻重建穿著各種服裝的不同人體,以展示我們方法的能力。與現有的需要一天多[20,45,54]進行重建的方法相比, D 3 D^{3} D3-人類在更短的時間(約20分鐘)內重建了服裝和身體的解耦模板,并在幾個小時內完成了完整的序列,實現了具有競爭力的重建精度。此外,我們展示了動畫制作和服裝轉移中的應用示例,以展示廣泛的應用解耦表示的可復制性。總之,本文的貢獻包括以下幾個方面:
-
提出了一種結合顯式和隱式表示的混合重建方法,能夠從單目視頻中重建高質量、解耦的服裝和人體。
-
對于可見區域的穿著衣服的人體,我們引入了一種新穎的表示,hmSDF,它可以通過易于獲得的 2D 人體解析準確地分割 3D 衣服和身體,而無需任何 3D 衣服先驗。
-
重建的解耦服裝和人體可以輕松應用于動畫制作和服裝轉移應用,提供逼真和詳細的幾何質量。
提出想法算貢獻、實現想法算貢獻、解決了什么實際問題,能夠應用哪些領域算貢獻
2 相關工作
衣服人體的解耦表示。大多數方法將穿著衣服的人體幾何形狀重建為一個整體,包括像網格 [2,3]、點云 [36,57]、SDF [6,20,39] 和占用 [48,49] 這樣的表示。這些重建方法在可見區域保持了良好的細節,但對于動畫和服裝轉移等應用不方便。更有效的方法是獨立地表示衣服和身體,將它們建模為解耦的、分層的表示。GALA [27] 和 ClothCap [44] 利用 3D 分割分別從 3D 和 4D 掃描中獲得單獨的衣服和身體網格,這種方法受到獲取掃描數據的高成本的限制。神經 ABC [5] 基于 UDF(無符號距離函數)表示構建了解耦的人體和衣服參數化模型,但其對細節的重建是有限的。SCARF [9] 從視頻序列中重建了穿著衣服的人體的混合表示,但是 NeRF [37] 對衣服的表示在幾何效果上是有限的。其他一些方法專注于重建衣服 [7,8,19,47,58],這允許通過使用 SMPL [34] 作為底層身體來解耦;然而,這些方法中的身體通常缺乏細節。
從單視圖圖像重建。傳統方法通過在參數空間 [24,29,30] 內通過優化或回歸將參數化人體模型擬合到單視圖圖像進行重建。擬合的有效性在很大程度上取決于參數化模型的表示能力。像 SMPL [34] 和 SCAPE [4] 這樣的模型可以在沒有衣服的情況下重建底層身體。一些方法 [7,8,19] 可以重建衣服并使用 SMPL 模型來表示底層身體,實現了穿著衣服的人體的完整重建。還有一些模型同時代表衣服和底層身體,包括統一建模 [6,39] 和分層建模 [5] 的方法。基于參數的重建方法可以很容易地產生看似合理的穿著衣服的人體形象,但一般缺乏細節。針對單個圖像的方法可以逐幀重建視頻;然而,它們往往無法確保幀間一致性,例如缺乏幀到幀的一致性,或者可能導致結果不流暢。
從單目視頻重建。從視頻輸入中重建3D穿衣人體通常依賴于運動和變形線索來恢復可變形的3D表面。早期的作品獲得了特定于演員的操縱模板[15,16,56]或使用參數模型作為先驗[2]。許多努力[9,22,41-43,54],基于NeRF[37]和3DGS[25],從動態視頻中重建可動畫的人體化身,主要側重于渲染效果,但幾何重建的質量并不理想。[14,20,53]重建了高質量的穿衣人體幾何形狀,但服裝和下面的身體是不可分離的。DGarment[28]和REC-MV[45]重建了動態服裝,不包括身體。我們的方法可以在確保幾何質量的同時重建解耦的服裝和下面的身體。
3 方法
給定一個包含N幀的單目視頻,它描繪了一個穿著衣服的人在運動, I t ∣ t = 1 , . . . , N {I_{t} | t=1, ..., N} It?∣t=1,...,N D 3 D^{3} D3-人類的目標是在不使用3D服裝模板先驗的情況下重建高保真、解耦和時空連續的服裝和底層身體網格 G t ∣ t = 1 , . . . , N {G_{t} | t=1, ..., N} Gt?∣t=1,...,N。為了實現最大的真實感,視頻捕獲的觀察區域,如暴露的頭部和衣服,應該非常詳細地重建;模糊的區域,如被衣服覆蓋的身體部位或被身體遮擋的身體部位,應該盡可能合理地重建。(有些細節、有些粗糙)
為了實現這些目標,我們將隱式表示的靈活性與顯式表示的魯棒性和快速渲染能力相結合,以達到最佳效果。值得注意的是,可以通過閉合曲線將水密穿著衣服的人的表面分割成衣服和身體部位。因此,我們首先利用圖像和人類解析分割序列信息來重建可見區域中分離的衣服和身體網格。然后,在SMPL[34]的幫助下,我們完成了不可見的身體區域,并生成解耦的衣服和身體模板。最后,額外使用正常信息來共同優化衣服和身體,以增強細節。圖2說明了我們方法的整體管道。
3.1 HmSDF 表示
在本節中,我們定義了服裝模板 G c G_{c} Gc?和身體模板 G b G_{b} Gb?在規范空間中。考慮到被服裝遮擋的身體部位在視頻中是不可見的,我們進一步將服裝和身體分為可見的身體 S b S_{b} Sb?、不可見的身體 U b U_{b} Ub?和可見的服裝 S c S_{c} Sc?。通過偵察后的分割獲得可見的身體 S b S_{b} Sb?利用SMPL模型構建整體衣身,同時完成不可見體 M b M_{b} Mb?,可見體和不可見體合并形成體模板 G b G_{b} Gb?
可見的服裝和身體由混合表示[52]表示,它結合了四面體網格網格 ( V T , T ) (V_{T}, T) (VT?,T)和神經隱式有符號距離函數 s η ( x ) s_{\eta}(x) sη?(x),其中 x ∈ V T x \in V_{T} x∈VT?和 s η ( x ) s_{\eta}(x) sη?(x)是具有可學習權重n的神經網絡, S b ∪ S c S_{b} \cup S_{c} Sb?∪Sc?的表面可以用 S η = x ∈ R 3 ∣ s η ( x ; η ) = 0 S_{\eta}={x \in \mathbb{R}^{3} | s_{\eta}(x ; \eta)=0} Sη?=x∈R3∣sη?(x;η)=0表示,網格可以使用遵循GShell[32]的方法提取。
由于重構的水密布人體 S η = S b ∪ S c S_{\eta}=S_{b} \cup S_{c} Sη?=Sb?∪Sc?,我們在 S η S_{\eta} Sη?上定義一個連續可微的映射 ν : S η → R \nu: S_{\eta} \to \mathbb{R} ν:Sη?→R來表征一個點是否屬于 S b S_{b} Sb?或 S c S_{c} Sc?:
ν ( x ) = { < 0 , ? x ∈ I n t e r i o r ( S b ) , = 0 , ? x ∈ λ , > 0 , ? x ∈ I n t e r i o r ( S c ) , \nu(x)= \begin{cases}<0, & \forall x \in Interior\left(S_{b}\right), \\ =0, & \forall x \in \lambda, \\ >0, & \forall x \in Interior\left(S_{c}\right),\end{cases} ν(x)=? ? ??<0,=0,>0,??x∈Interior(Sb?),?x∈λ,?x∈Interior(Sc?),?
其中λ表示 S b S_{b} Sb?和 S c S_{c} Sc?之間的邊界線。我們將2表示為人類流形有符號距離場,稱為hmSDF。這不同于GShell中mSDF的定義,它只考慮位于開放表面內的點。相比之下,我們的方法考慮hmSDF(可見服裝和身體)兩側的點。
3.2 區域聚合
理想情況下,一個優化的hmSDF函數2應該準確地分割可見的服裝 S c S_{c} Sc?和身體 S b S_{b} Sb?,但是由于每一幀的人類解析掩碼中的不準確以及幀之間的不一致,不準確可能發生在邊界線λ,如圖3所示。當不準確發生在 ν ( x ) = 0 \nu(x)=0 ν(x)=0的鄰域時,它會導致 S b ′ S_{b}' Sb′?和 S c ′ S_{c}' Sc′?的分割區域包含孔,并創建不希望的分割區域 S b ′ ′ S_{b}^{\prime \prime} Sb′′?和 S c ′ ′ S_{c}^{\prime \prime} Sc′′?。 S b ′ ′ S_{b}^{\prime \prime} Sb′′?和 S c ′ ′ S_{c}^{\prime \prime} Sc′′?中包含的小片段不可避免地與其他子圖斷開連接。
我們從輸入圖像中獲取每個類別的連通分支個數,由于錯誤分類的連通分支的頂點通常較少,因此可以通過使用深度優先搜索方法計算每個連通分支的頂點個數來確定每個子圖的類別 S b ′ S_{b}' Sb′?、 S c ′ S_{c}' Sc′?、 S b ′ ′ S_{b}^{\prime \prime} Sb′′?和 S c ′ ′ S_{c}^{\prime \prime} Sc′′?,通過如下聚合可以獲得正確的 S b S_{b} Sb?和 S c S_{c} Sc?:
S b = m e r g e ( S b ′ , S c ′ ′ ) , ( 1 ) S_{b}=merge\left(S_{b}', S_{c}''\right), (1) Sb?=merge(Sb′?,Sc′′?),(1)
S c = m e r g e ( S c ′ , S b ′ ′ ) . ( 2 ) S_{c}=merge\left(S_{c}', S_{b}''\right) . (2) Sc?=merge(Sc′?,Sb′′?).(2)
3.3. 變形場
我們在算法1中演示了 S b S_{b} Sb?和 S c S_{c} Sc?的聚合過程。
與以前的方法[20,45]類似,我們使用基于SMPL的線性混合蒙皮(LBS)方法來建模大型基于骨骼運動的變形,并采用非剛性變形場來模擬細微變形。然而,一個關鍵的區別是服裝和身體遵循不同的運動規則。因此,我們使用兩個獨立的非剛性變形場來分別模擬服裝和身體的非剛性變形。
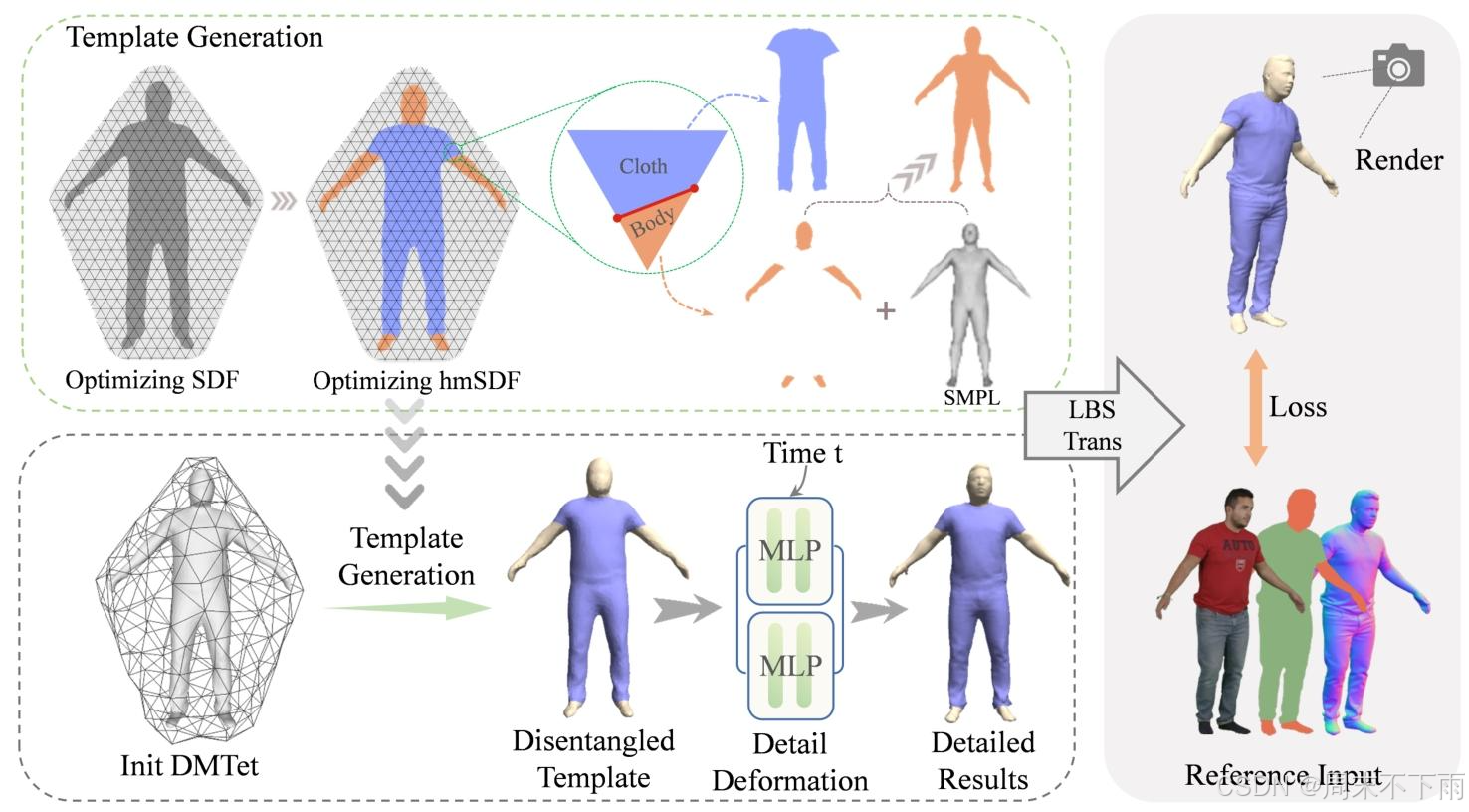
圖2. D 3 D^{3} D3概述-人類。優化過程分為兩個步驟:模板生成和詳細變形。對象被初始化為DMTet[52]表示,并被優化以形成一個完整的穿著衣服的人。一個可優化的HmSDF函數,分別為身體和衣服網格的每一幀建模詳細變形。最后,使用前向LBS變形將網格轉換到觀察到的空間,由圖像、法線貼圖監督,并使用可微渲染器解析蒙版。分離衣服和身體區域,缺失的部分由SMPL填充。生成解開的模板后,我們使用兩個MLP
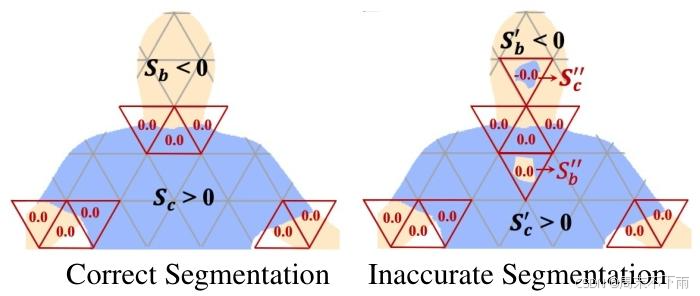
分割結果, S b S_{b} Sb?和 S c S_{c} Sc?正確分割身體和圖3。區域聚合示意圖。對于正確的分割布。對于不準確的分割結果, S c ′ ′ S_{c}^{\prime \prime} Sc′′?應該與 S b ′ S_{b}' Sb′?合并, S b ′ ′ S_{b}^{\prime \prime} Sb′′?應該與 S c ′ S_{c}' Sc′?合并
| 步驟 | 操作(區域聚合算法) |
|---|---|
| 輸入 | 直接從X獲得的初始分割 S b 0 S^0_b Sb0?和 S c 0 S^0_c Sc0?; S b S_b Sb?和 S c S_c Sc?正確的子圖數量分別為 o 1 o_1 o1?和 o 2 o_2 o2? |
| 1 | 計算 S b 0 S^0_b Sb0?的所有連通子圖 Q b Q_b Qb? |
| 2 | 計算 S c 0 S^0_c Sc0?的所有連通子圖 Q c Q_c Qc? |
| 3 | 根據頂點數量對 Q b Q_b Qb?進行排序 |
| 4 | 根據頂點數量對 Q c Q_c Qc?進行排序 |
| 5 | 根據 o 1 o_1 o1?從 Q b Q_b Qb?中提取 S b ′ S'_b Sb′?和 S b ′ ′ S''_b Sb′′? |
| 6 | 根據 o 2 o_2 o2?從 Q c Q_c Qc?中提取 S c ′ S'_c Sc′?和 S c ′ ′ S''_c Sc′′? |
| 7 | 通過公式(1)和(2)得到 S b S_b Sb?和 S c S_c Sc?,并過濾掉重復點 |
| 輸出 | 無孔洞和碎片的 S b S_b Sb?和 S c S_c Sc? |
非剛性變形。由于自由度有限,LBS變形只能模擬大變形,無法表示較小的細節,如衣服的褶皺。因此,對于細節變形,我們使用兩個MLP來模擬服裝和人體的非剛性變形。D是非剛性變形的MLP:
x t = D ( x , h t , E ( x ) ; ? ) , x^{t}=D\left(x, h^{t}, E(x) ; \phi\right), xt=D(x,ht,E(x);?),
其中x是正則空間中的點, x t x^{t} xt是t幀中變形后的點, h t h^{t} ht是t幀對應的潛碼,和?是需要優化的網絡參數,對于服裝和身體,網絡和參數是獨立獨立的。
LBS變形。線性混合蒙皮(LBS)變形模型基于骨骼變形從規范空間到觀察空間的轉換。給定SMPL形狀參數β和位姿參數 θ t \theta_{t} θt?,LBS變形W可以寫成:
G ′ ( β , θ t ) = W ( D ( x ) , β , θ t , W ( x ) ) , G'\left(\beta, \theta_{t}\right)=W\left(D(x), \beta, \theta_{t}, \mathcal{W}(x)\right), G′(β,θt?)=W(D(x),β,θt?,W(x)),
其中 D ( x ) D(x) D(x)表示服裝和身體的非剛性變形, W ( x ) W(x) W(x)是基于SMPL計算x的蒙皮權重的方法,我們參考一些服裝模擬方法[11,51]計算蒙皮權重,對于服裝和身體兩者,我們使用共享蒙皮變形模型。
3.4. 遮擋感知可微分渲染
可微分渲染用于將觀察空間中的幾何圖形渲染為2D,這允許在2D監督下計算損失。遵循一些可微分渲染方法[17,32,38],我們利用可微分光柵化方法來渲染網格。與體積渲染方法相比,基于光柵化的渲染支持顯式網格的可微分渲染,并提供更好的時間和內存效率。
對于穿著衣服的身體,身體和衣服之間可能會發生遮擋,這會導致在從同一視點渲染衣服的可見區域時發生遮擋。因此,僅渲染衣服網格以獲得服裝蒙版可能會產生與監督信號不一致的結果,如圖4所示。為了解決這個問題,我們標記了衣服和身體的面部,同時渲染它們。然后我們使用光柵化生成遮擋感知2D標簽,其中身體標簽的有效區域是身體蒙版 M b M_{b} Mb?,而衣服標簽的有效區域是衣服蒙版 M c M_{c} Mc?

圖4.面罩遮擋顯示從左到右:捕獲的衣著人的彩色圖像,從SAM2獲得的完整衣著身體面罩[46],從SAM2獲得的衣著面罩,僅渲染服裝網格獲得的面罩,渲染完整衣著身體網格后有效服裝區域的面罩。
3.5 訓練
3.5.1 訓練策略
我們的方法由兩個階段組成:模板生成和細節變形優化。在模板生成階段,我們利用hmSDF直接從面具監督中學習服裝模板,而不依賴于3D服裝先驗。在這個階段,僅通過LBS實現變形,并通過RGB損失、面具損失、Eikonal損失、鼓勵開孔和正則化孔來優化參數。在細節變形階段,我們引入了一個額外的感知法向損失作為重建項,而正則化通過碰撞懲罰和幾何正則化來優化非剛性變形。
3.5.2 重建損失
我們通過以下目標最小化渲染結果和輸入圖像之間的差異:
RGB損失。在渲染的RGB圖像和監督圖像之間計算 L 1 L_{1} L1?。我們計算所有有效像素P如下,
L c o l o r = 1 ∣ P ∣ ∑ p ∈ P ( 1 b ( p ) ? L m s e ( I b , I ^ b ) + 1 c ( p ) ? L m s e ( I c , I ^ c ) ) , \begin{aligned} L_{color }=\frac{1}{|P|} \sum_{p \in P} & \left(1_{b}(p) \cdot L_{mse}\left(I_{b}, \hat{I}_{b}\right)\right. \\ & \left.+1_{c}(p) \cdot L_{mse}\left(I_{c}, \hat{I}_{c}\right)\right), \end{aligned} Lcolor?=∣P∣1?p∈P∑??(1b?(p)?Lmse?(Ib?,I^b?)+1c?(p)?Lmse?(Ic?,I^c?)),?
其中 1 ( p ) \mathbb{1}(p) 1(p)表示當前像素點P所屬的類別,當 1 b ( p ) \mathbb{1}_{b}(p) 1b?(p)為真時,像素p屬于本體;當 1 c ( p ) \mathbb{1}_{c}(p) 1c?(p)為真時,像素p屬于布料。 1 b ( p ) \mathbb{1}_{b}(p) 1b?(p)和 1 c ( p ) \mathbb{1}_{c}(p) 1c?(p)可以同時為真,也可以只有一個為真,具體取決于用于監督的掩模。 I b I_{b} Ib?為本體渲染的RGB圖像, I c I_{c} Ic?為服裝渲染的RGB圖像, I ^ b \hat{I}_{b} I^b?為本體實況RGB圖像, I ^ c \hat{I}_{c} I^c?為服裝的地面實況RGB圖像。
蒙版丟失。雖然在RGB圖像監督中已經刪除了不相關的背景,但獨立添加的蒙版損失會進一步限制邊緣的準確性,正如,
L m a s k = 1 ∣ P ∣ ∑ p ∈ P ( 1 b ( p ) ? L m s e ( M b , M ^ b ) + 1 c ( p ) ? L m s e ( M c , M ^ c ) ) , \begin{aligned} L_{mask }= & \frac{1}{|P|} \sum_{p \in P}\left(\mathbb{1}_{b}(p) \cdot L_{mse}\left(M_{b}, \hat{M}_{b}\right)\right. \\ & \left.+\mathbb{1}_{c}(p) \cdot L_{mse}\left(M_{c}, \hat{M}_{c}\right)\right), \end{aligned} Lmask?=?∣P∣1?p∈P∑?(1b?(p)?Lmse?(Mb?,M^b?)+1c?(p)?Lmse?(Mc?,M^c?)),?
其中 M ^ b \hat{M}_{b} M^b?是身體的地面實況面罩, M ^ c \hat{M}_{c} M^c?是服裝的地面實況面罩。
感知法線損失。我們通過Sapiens[26]獲得圖像的法線作為地面實況,以利用在大規模人體數據上訓練的先驗信息。渲染法線和監督法線需要歸一化并與觀察空間對齊。我們使用感知損失[18,23]以進一步增強渲染法線的有效性。
L p e r = ∑ i ∥ ? i ( N ) ? ? i ( N ^ ) ∥ 2 , L_{per }=\sum_{i}\left\| \phi_{i}(\mathcal{N})-\phi_{i}(\hat{\mathcal{N}})\right\| ^{2}, Lper?=i∑? ??i?(N)??i?(N^) ?2,
其中N是渲染法線, N ^ \hat{N} N^是地面實況法線, ? i ( ? ) \phi_{i}(*) ?i?(?)表示MobileNetV2網絡中第i層的激活[50]。
3.5.3 正則化限制
Eikonal損失。為了確保合理的有符號距離場,我們在優化SDF時在每個四面體頂點的SDF值的梯度9中添加一個Eikonal項[12]:
L e i k = ∑ u ∈ V T ( ∥ g u ∥ 2 ? 1 ) 2 . L_{eik}=\sum_{u \in V_{T}}\left(\left\| g_{u}\right\| _{2}-1\right)^{2} . Leik?=u∈VT?∑?(∥gu?∥2??1)2.
鼓勵開孔。在視點有限的情況下,有必要僅使用圖像信息來識別開口位置。我們通過采用類似于[32]的正則化術語來鼓勵hmSDF開口,
L h o l e = ∑ u : ν ( u ) ≥ 0 L h u b e r ( ν ( u ) ) . L_{hole }=\sum_{u: \nu(u) \geq 0} L_{huber }(\nu(u)) . Lhole?=u:ν(u)≥0∑?Lhuber?(ν(u)).
孔洞正則化。為了避免過大的開口,我們對當前視點可見的所有點施加約束
L r e g ? h o l e = ∑ u : ν ( u ) = 0 L h u b e r ( ν ( u ) ? ? 1 ) , L_{reg-hole }=\sum_{u: \nu(u)=0} L_{huber }\left(\nu(u)-\epsilon_{1}\right), Lreg?hole?=u:ν(u)=0∑?Lhuber?(ν(u)??1?),
其中 ? 1 \epsilon_{1} ?1?是正標量。
碰撞懲罰。這確保了衣服不會穿透下面的身體,靈感來自[11,51]。我們將其實施為
L c o l l i s i o n = ∑ v e r t i c e s k c o l l i s i o n m a x ( ? 2 ? d ( x ) , 0 ) 3 . ( 9 ) L_{collision }=\sum_{vertices } k_{collision } max \left(\epsilon_{2}-d(x), 0\right)^{3} . (9) Lcollision?=vertices∑?kcollision?max(?2??d(x),0)3.(9)
特別是,當兩層之間的距離太近時,渲染會產生計算錯誤,因此 ? 2 \epsilon_{2} ?2?的值設置為0.005。
幾何正則化。為了確保優化受到約束,我們鼓勵生成平滑變形的結果。受Worchel等人[55]的啟發,我們添加了正態一致性項 L n c o n s i s t L_{n_consist } Lnc?onsist?和拉普拉斯項 L a p l a c i a n Laplacian Laplacian
4. 實驗
我們進行定性和定量實驗來證明 D 3 D^{3} D3的有效性。對于定性實驗,我們使用來自PeopleSnapshot[2]和SelfRecon[20]的受試者。對于定量實驗,我們使用SelfRecon構建的合成數據集。它為網格提供準確的地面實況。此外,我們對UDF和hmSDF的討論以及感知法向損失的有效性進行了消融研究,并展示了在服裝轉移和基于物理的動畫制作中的應用。
4.1 定量評估
由于沒有公開的真實數據集可用于評估從單目視頻中解耦的衣著人重建的幾何質量,我們使用了SelfRecon[20]提供的四個合成數據集,每個數據集包含幾何地面實況和渲染的視頻。由于這些處理后的數據不是REC-MV[45]的開源數據,我們手動標記分割點并使用官方工具生成特征線。我們還使用CLO3D[1]將衣服和身體從源數據中分離出來進行定量評估。我們報告每個方法結果的衣服、身體和完整的衣著人的倒角距離(CD)。對于不支持解耦的方法,我們只報告完整的衣著人的CD。我們在圖5中展示了定量比較的可視化,并在表1中報告了指標。結果表明,我們的方法在指標中取得了最佳結果,提供了詳細準確的視覺效果,并且能夠正確地將人體和服裝解耦。
4.2 定性評價
我們將我們的方法與能夠從圖像序列中重建穿著衣服的人體的方法進行比較,使用來自PeopleSnapshot[2]數據集的幾個序列和來自SelfRecon[20]的一個序列來包括裙裝類別。對于所有方法,我們從完全旋轉中提取連續幀,并呈現圖8中第一幀的比較結果。補充材料中提供了額外的順序結果和討論。
正如我們所看到的,REC-MV[45]可以準確地重建服裝,但缺乏我們的方法所實現的詳細級別。由于REC-MV中缺乏對身體的進一步優化,直接使用SMPL導致網格穿透。BCNet[19]重建了可以直接使用SMPL作為底層身體的服裝;然而,它只支持具有一致服裝類別的重建,并且幾乎缺乏所有細節。DELTA[10]增強了基于SCARF[9]的頭部細節,并允許直接解耦重建服裝和身體。但是,由于它對服裝使用了NeRF[37]表示,因此無法提取平滑的幾何形狀,導致服裝幾何形狀中出現大量偽影。SelfRecon[20]使用SDF表示來重建具有正確形狀但缺乏細節的穿著衣服的人體。GoMAvata[54]采用了Gaussian-on-Mesh表示,從而產生相對粗糙的網格。這兩種方法都無法實現衣服與身體的解耦。
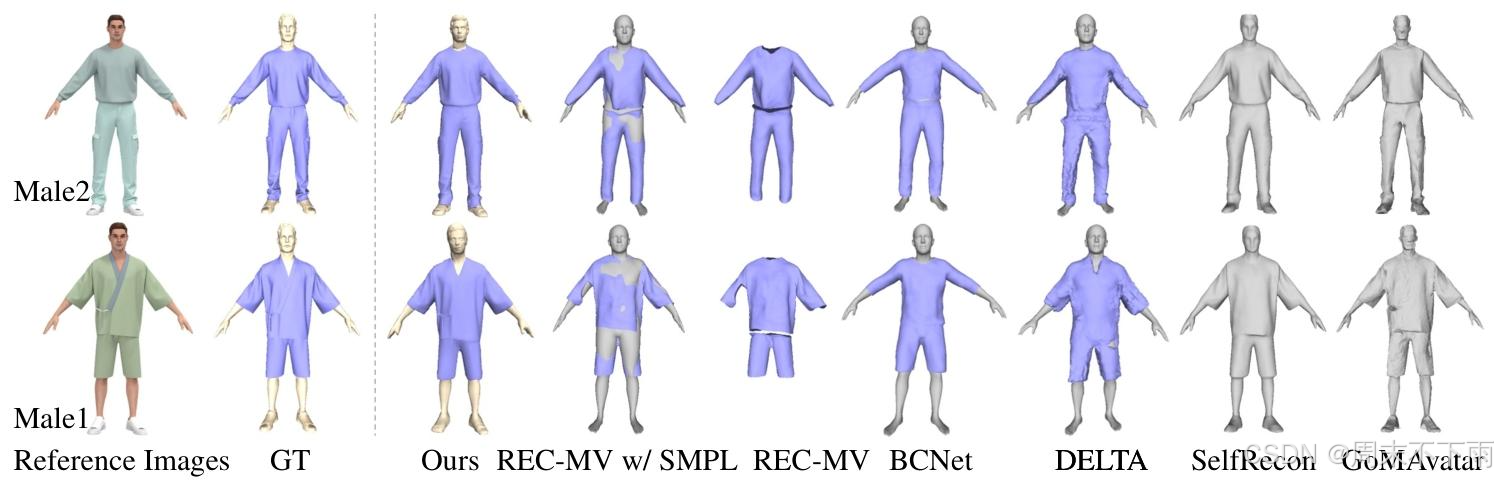
圖5.所提出方法與REC-MV[45]、BCNet[19]、DELTA[10]、SelfRecon[20]和GoMAvata[54]的定量比較我們使用紫色來可視化可以與身體脫鉤的服裝,對于REC-MV和BCNet,添加了SMPL[34]作為身體,以顯示穿著衣服的人的完整重建。
表1.跨四個合成序列的定量比較。我們報告重建表面(cm)與地面實況之間的倒角距離(CD)。對于REC-MV、BCNet、DELTA和我們的方法,我們分別報告服裝、身體和全衣人體的CD。對于SelfRecon和GoMavator,我們只報告全衣人體的CD。單位為 e ? 3 e^{-3} e?3。我們突出最佳值和次最佳值。我們在圖5中顯示了Male1和Male2,在補充材料中顯示了Women ale1和Women ale3。
| Method | Female1 | Female1 | Female1 | Female3 | Female3 | Female3 | Male1 | Male1 | Male1 | Male2 | Male2 | Male2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clothing | Body | All | Clothing | Body | All | Clothing | Body | All | Clothing | Body | All | |
| REC-MV [ 45 ] | 1.416 | 1.789 | 1.148 | 0.930 | 2.082 | 1.461 | 0.614 | 1.945 | 0.619 | 0.693 | 1.201 | 0.616 |
| BCNet [ 19 ] | 1.685 | 10.252 | 5.561 | 4.571 | 10.112 | 5.681 | 2.589 | 6.236 | 4.802 | 2.007 | 4.109 | 2.853 |
| DELTA [ 10 ] | 2.177 | 0.973 | 1.388 | 2.173 | 0.820 | 0.915 | 1.327 | 1.498 | 1.702 | 1.884 | 1.073 | 1.132 |
| SelfRecon [ 20 ] | - | - | 3.420 | - | - | 2.249 | - | - | 1.310 | - | - | 1.454 |
| GoMavatar [ 54 ] | - | - | 7.319 | - | - | 5.058 | - | - | 2.382 | - | - | 3.163 |
| Ours | 1.065 | 0.966 | 0.959 | 1.109 | 0.742 | 0.636 | 0.478 | 0.321 | 0.270 | 0.355 | 0.325 | 0.279 |
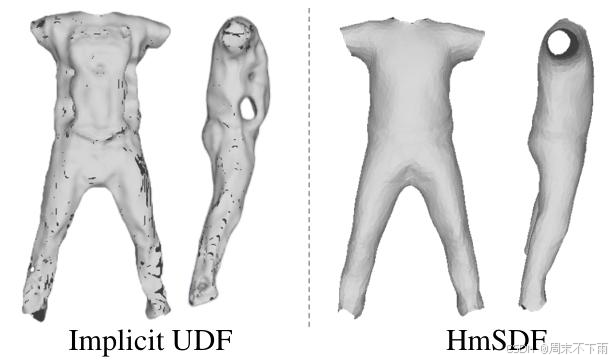
圖6.使用具有變形場[21]和hmSDF的隱式UDF[33]對服裝重建的消融研究,應用于來自PeopleSnapshot[2]數據集的男性3-休閑數據。
與這些方法相比,我們的方法成功地將服裝與身體分離,同時保持更豐富的詳細級別。
4.3 消融研究
隱式UDF還是hmSDF?幾篇文章[5,8,32,33]通過使用隱式無符號距離字段(UDF)來表示具有未定義類別的服裝來演示結果,利用來自網格或多視圖圖像的密集監督。然而,我們發現,由于單視圖動態人體重建提供的監督有限,UDF難以產生穩健的結果,如圖6所示。UDF重建導致許多小洞,腹部區域的一個大洞,并且未能在袖口處創建開口。相比之下,hmSDF實現了準確的服裝形狀。

圖7.正常損耗的消融研究。參考輸入包括法線和圖像。頂行顯示渲染的法線,底行顯示渲染的網格。類別,利用來自網格或多視圖圖像的密集監督。然而,我們發現,由于單視圖動態人體重建提供的監督有限,UDF難以產生穩健的結果,如圖6所示。UDF重建導致許多小洞,腹部區域的一個大洞,并且未能在袖口處創建開口。相比之下,hmSDF實現了準確的服裝形狀。
盡管UDF使用網絡對形狀和pos進行建模UDF具有較強的表示能力,但仍存在一定的問題:(1)UDF在0級集是不可微的。雖然已經針對網格提取和多視圖重建問題提出了幾種解決方案[13,31,33],但UDF在0級集附近仍然敏感,監督信號差的區域可能會導致偵察構造失敗。(2)隱式UDF提取曲面的能力有限。隱式UDF[13]的曲面提取僅限于流形曲面[35],隱式表示中非流形的區域可能無法提取。(3)UDF強大的表示能力降低了其抗噪聲能力;例如,腹部區域的大洞是由服裝面罩中的遮擋引起的。遮擋的一個例子如圖4所示。
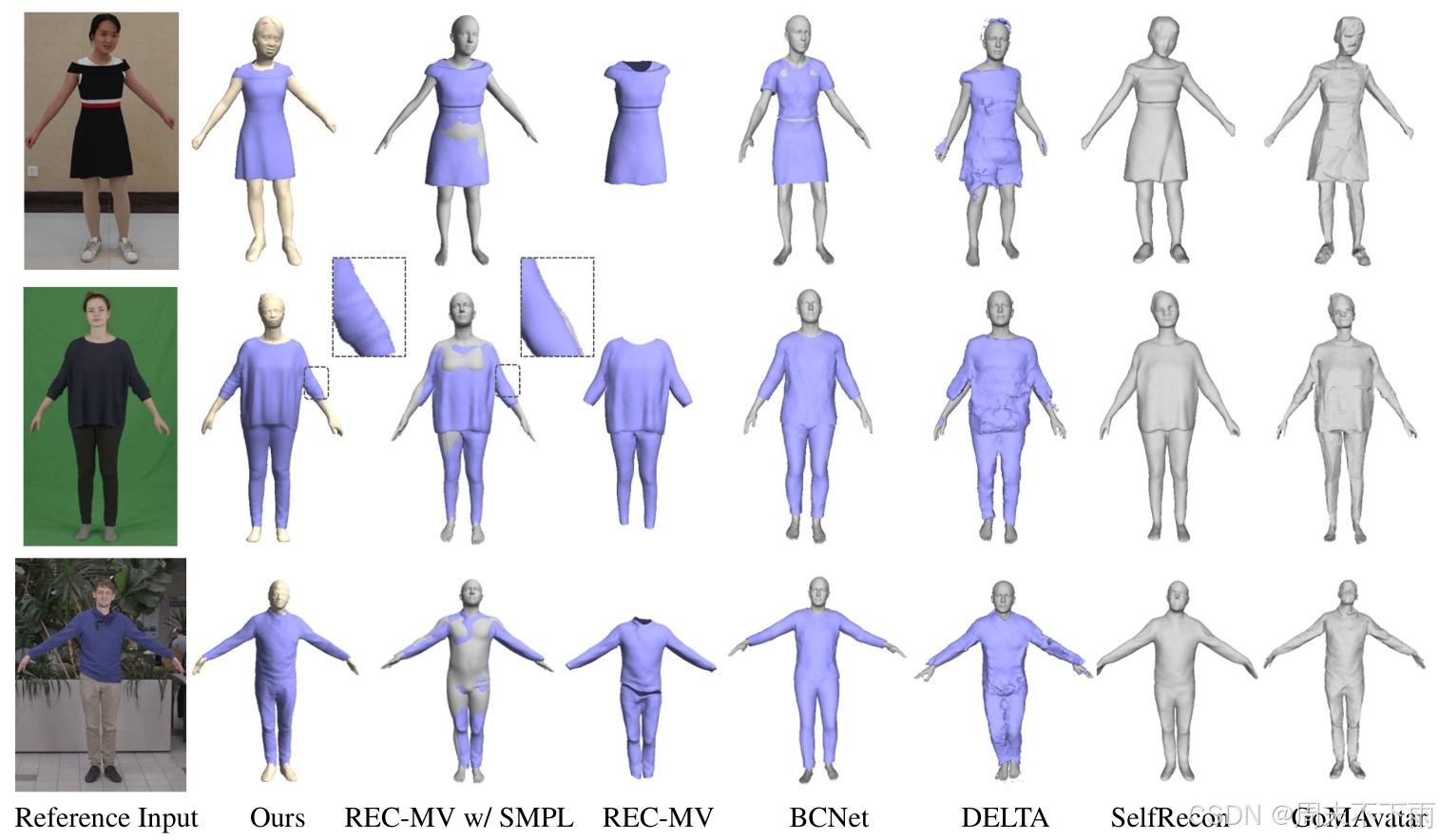
圖8.定性比較。我們的方法與真實圖像序列上的其他方法的比較。
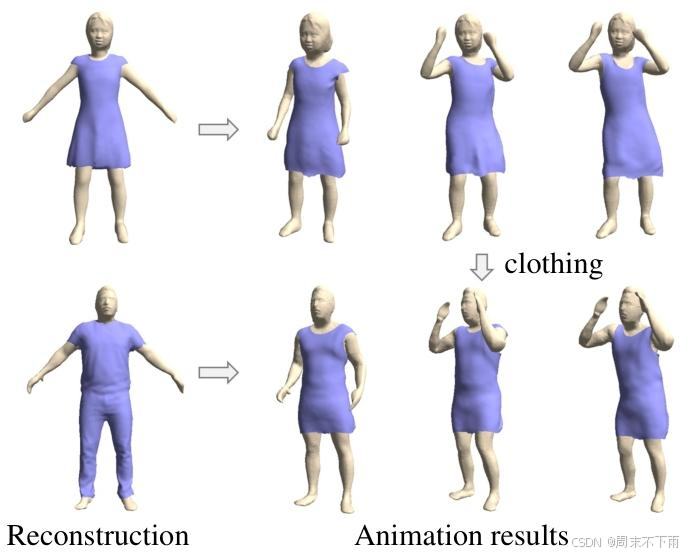
圖9.解耦重建應用程序。重建的服裝和身體可以使用物理模擬方法進行動畫處理。此外,服裝可以輕松交換以創建具有不同服裝的動畫。
感知法向損失。我們試圖去除法向一致性損失,并用均方誤差和角誤差代替它。雖然法向一致性損失側重于特征一致性,并可以產生感知一致的結果,但均方誤差和角誤差側重于點向特征,這可能會導致不太平滑的結果。我們在圖7中顯示了正常渲染結果。計算渲染法線和參考法線之間的余弦或MSE損失會導致粗糙和嘈雜的重建。另一方面,使用感知法向損失會產生更平滑的結果,從而保留參考圖像的特征和細節。
4.4 應用程序
我們演示了解耦重建后的服裝轉移和基于物理的動畫的應用。結果如圖9所示。
服裝轉移。由于我們的模型能夠重新構建解耦的服裝和人體,服裝轉移可以通過分別重建兩個穿著衣服的人體并交換他們的服裝來實現。
基于物理的動畫。重建的服裝和身體幾何形狀可以與基于物理的模擬方法一起使用,以創建更逼真的動畫。與非解耦重建[20]相比,這使得服裝和身體之間的運動難以建立,我們使用HOOD[11]來創建更真實的服裝細節。
5 結論
我們引入了 D 3 D^{3} D3人,一種可以直接從短的單目視頻中重建解耦的服裝和身體的方法。通過利用顯式表示的魯棒性和隱式表示的靈活性, D 3 D^{3} D3人確保了詳細特征的重建,同時保持了被服裝遮擋的身體部位的合理性。為了實現3D服裝與身體的分離,我們提出了一種定義在人體上的名為hmSDF的新穎表示,它能夠僅使用2D人體解析獲得3D分割,而沒有任何3D服裝先驗。由于這種新穎的方法,我們能夠以更少的計算時間實現具有競爭力的重建精度,同時確保了服裝和身體的解耦。解耦的重建結果可以很容易地用于詳細的動畫制作和服裝轉移。我們的 D 3 D^{3} D3-人類只需使用一臺相機即可創建高質量且易于編輯的人體幾何圖形,為廣泛采用許多應用提供了技術基礎,例如高度可編輯的數字頭像創建、全息通信。
看下來就是做了一個單目視頻的人體分割重建,對于不可見部分使用SMLP進行補全。對于定性定量,定性就是使用一堆模型的結果對比圖,定量就是對參數性能的比較情況。
對于分割還是使用的是gshell那一套









使用方法,優勢,注意點)



 - 使用Cypher操作Neo4j)





