文章目錄
- 前言
- 一、Cypher簡介
- 二、數據庫操作
- 1. 創建數據庫
- 2. 查看數據庫
- 3. 刪除數據庫
- 4. 切換數據庫
- 三、節點、關系及屬性操作
- 1. 創建節點與關系
- 1.1 語法
- 1.2 示例
- 2. 查詢數據
- 2.1 語法
- 2.2 示例
- 3. 更新數據
- 3.1 語法
- 3.2 示例
- 4. 刪除節點與關系
- 4.1 語法
- 4.2 示例
- 5. 合并數據
- 5.1 語法
- 5.2 示例
前言
本文將系統介紹 Cypher 的核心語法與操作邏輯,涵蓋數據庫管理、節點與關系的創建、查詢、更新及刪除等基礎操作,同時結合具體示例演示如何利用 Cypher 解決實際場景中的數據問題。通過理論與實踐的結合,幫助讀者快速掌握圖數據庫的核心操作范式,為進一步探索圖技術在大數據分析、人工智能等領域的應用奠定基礎。
一、Cypher簡介
Cypher 是一種聲明式圖數據庫查詢語言,由 Neo4j 公司開發,用于高效地查詢和更新圖數據庫中的數據。它使得開發者可以通過簡潔、直觀的語法來操作圖數據庫,而無需關心底層實現細節。Cypher 的設計目標是為了讓圖數據的操作變得簡單且強大,使非技術用戶也能輕松理解并使用。
Cypher 主要特點
- 模式匹配:Cypher 提供了強大的模式匹配能力,允許用戶通過圖形結構而非僅基于屬性或索引來查詢數據。
- 易于閱讀和編寫:其語法設計接近自然語言,尤其是對于那些具有圖形化思維的人來說更加直觀。
- 靈活的數據查詢與更新:無論是簡單的查詢還是復雜的圖形遍歷,Cypher 都能提供支持。
- 高效的執行計劃:Neo4j 會根據 Cypher 查詢自動生成高效的執行計劃,以確保快速的數據檢索速度。
使用場景
- 社交網絡分析:利用 Cypher 可以很容易地找到人與人之間的關系網,比如朋友的朋友等。
- 推薦系統:通過分析用戶的行為和偏好,為用戶提供個性化的產品或內容推薦。
- 路徑查找:在運輸和物流行業,可以用來查找兩點之間的最優路徑。
- 風險管理與欺詐檢測:通過分析實體間的關系,識別潛在的風險或欺詐行為。
Cypher 作為圖數據庫 Neo4j 的核心查詢語言,極大地簡化了圖數據的管理和分析過程,使得圖數據庫技術更易于被廣泛接受和應用。
二、數據庫操作
在 Neo4j 中,數據庫操作包括創建、查看和刪除數據庫等。不過需要注意的是,Neo4j 的社區版(Community Edition)通常只支持單個默認數據庫,即 neo4j 數據庫,并不支持創建多個數據庫。但是,從 Neo4j 4.0 版本開始,企業版支持多數據庫特性,允許用戶創建和管理多個數據庫實例。
1. 創建數據庫
要創建一個新的數據庫,可以使用以下 Cypher 命令。
CREATE DATABASE database_name
例如,如果你想創建一個名為 mydatabase 的新數據庫,你可以運行:
CREATE DATABASE mydatabase
注意:這個命令僅適用于 Neo4j 企業版。
2. 查看數據庫
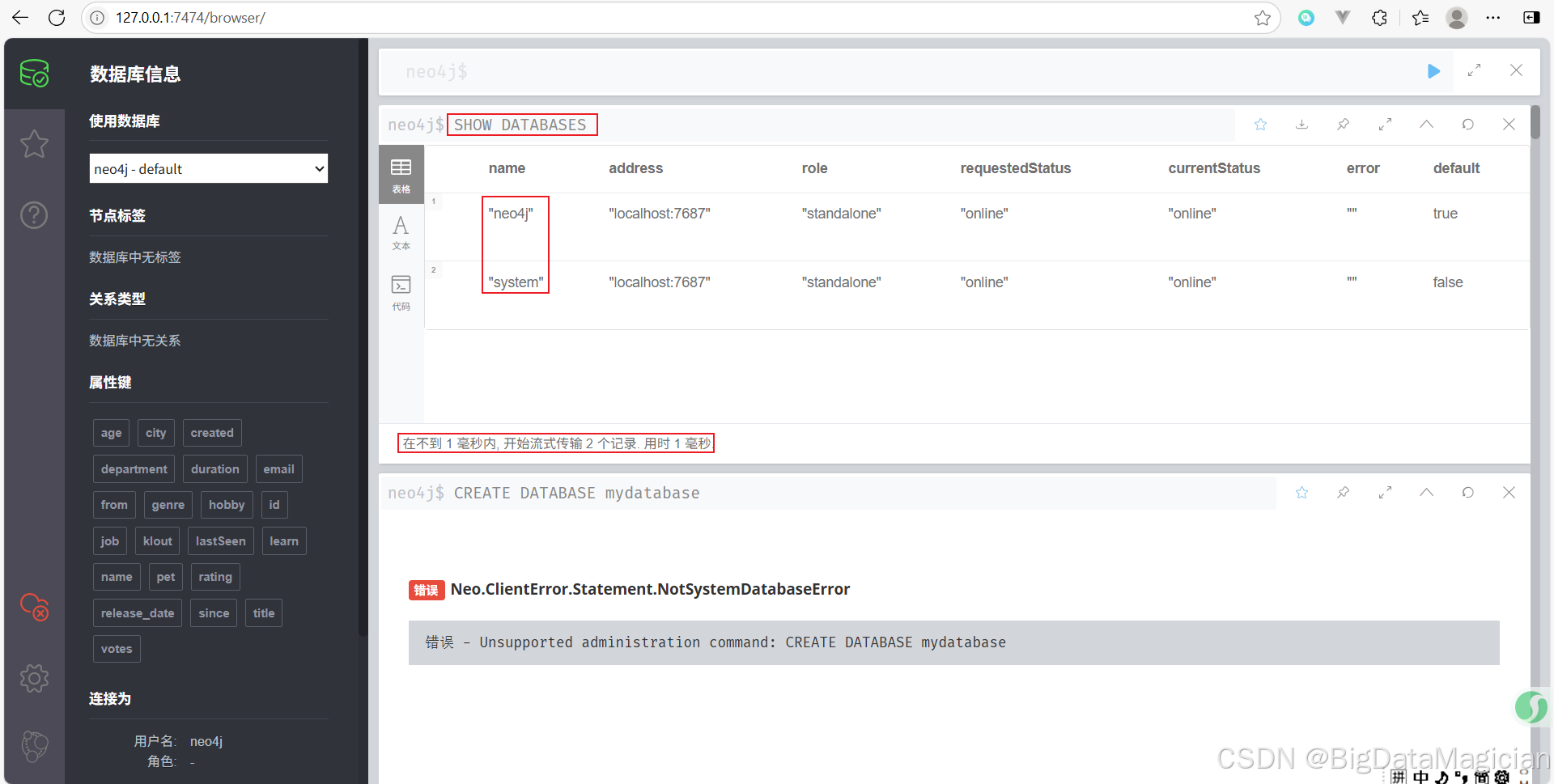
查看當前系統中存在的所有數據庫,可以使用如下命令。
SHOW DATABASES
這將列出所有數據庫的信息,包括名稱、狀態(如在線或離線)、是否為主數據庫等。
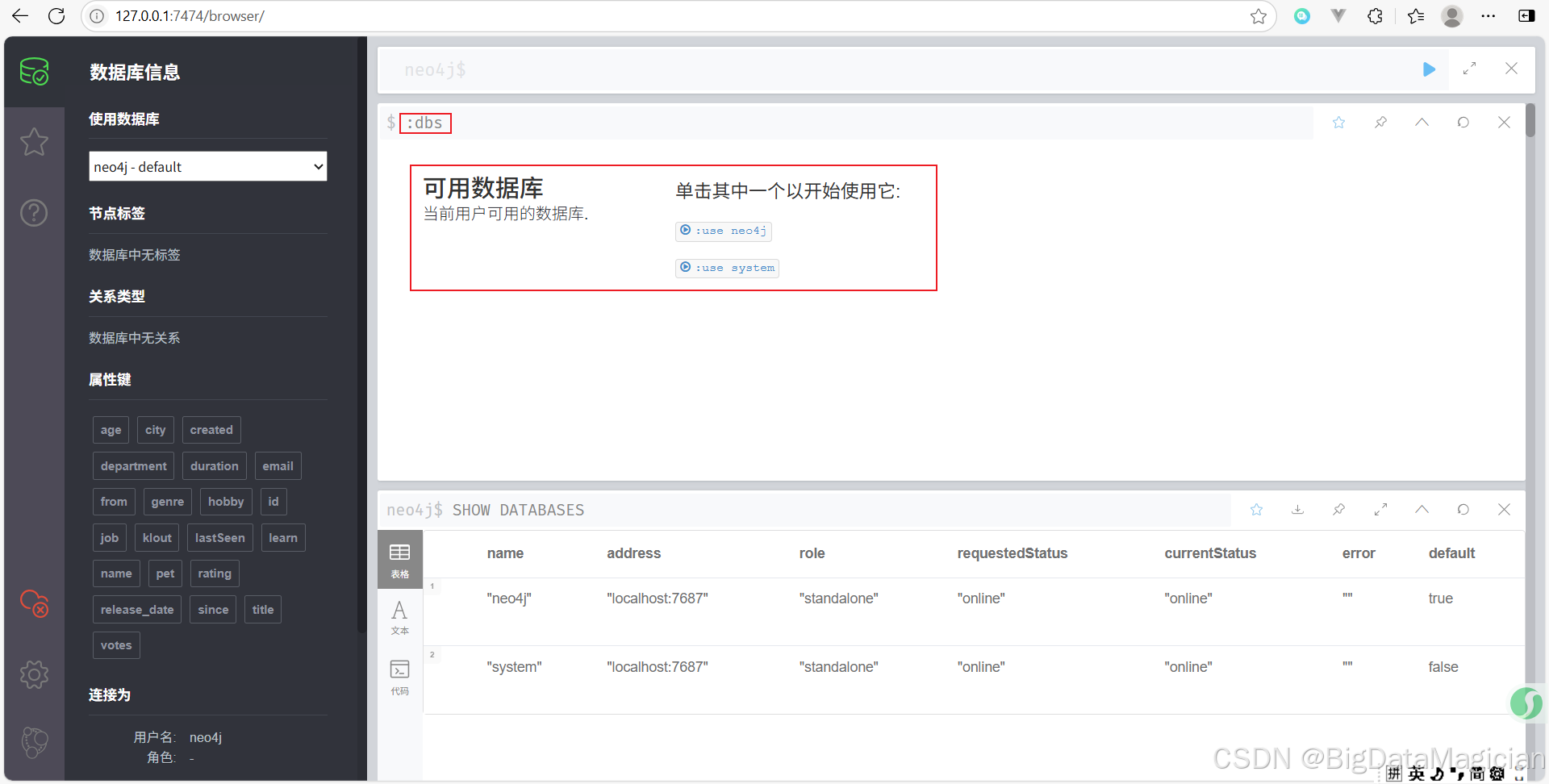
也可以使用如下命令查看可用數據庫。
:dbs
3. 刪除數據庫
如果需要刪除一個數據庫,可以使用以下命令:
DROP DATABASE database_name
例如,刪除名為 mydatabase 的數據庫:
DROP DATABASE mydatabase
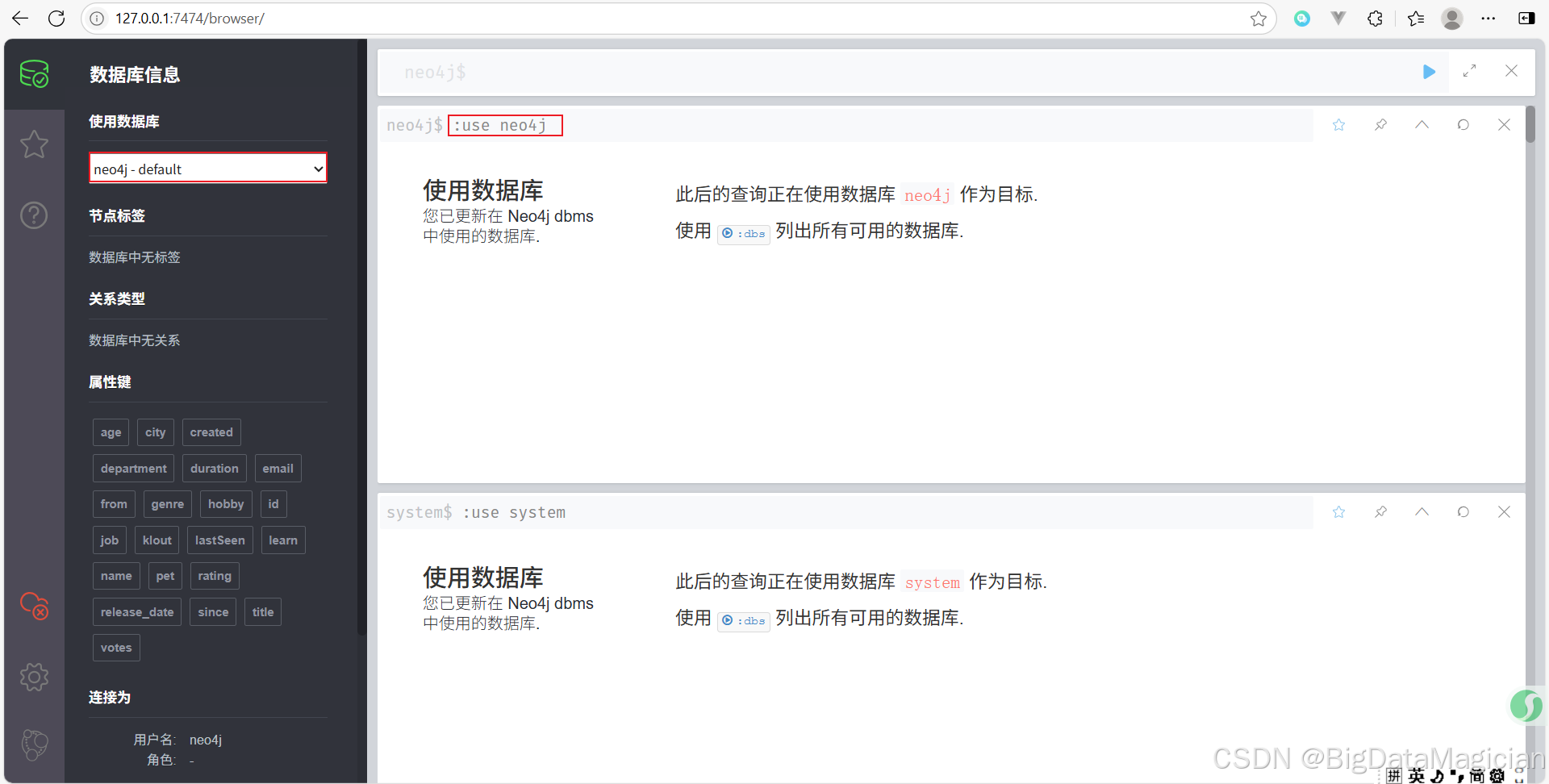
4. 切換數據庫
切換到數據庫neo4j。
:use neo4j
三、節點、關系及屬性操作
1. 創建節點與關系
在 Cypher 中,圖數據庫中的基本元素是 節點(Node) 和 關系(Relationship)。使用 CREATE 命令可以創建節點和關系。
1.1 語法
創建節點的語法如下:
CREATE (variableName:Label {property1: value1, property2: value2, ...})
Label是節點的標簽,用于分類。{property1: value1}是節點的屬性集合,可選。variableName是標簽變量,用于后續操作中引用該節點。
創建關系的語法如下:
CREATE (node1)-[relVariable:RELATIONSHIP_TYPE {prop: value}]->(node2)
relVariable是關系變量。RELATIONSHIP_TYPE是關系類型,表示兩個節點之間的連接方式,關系類型是自定義的。- 箭頭方向表示關系的方向(
->表示從 node1 到 node2,<-表示反向)。
1.2 示例
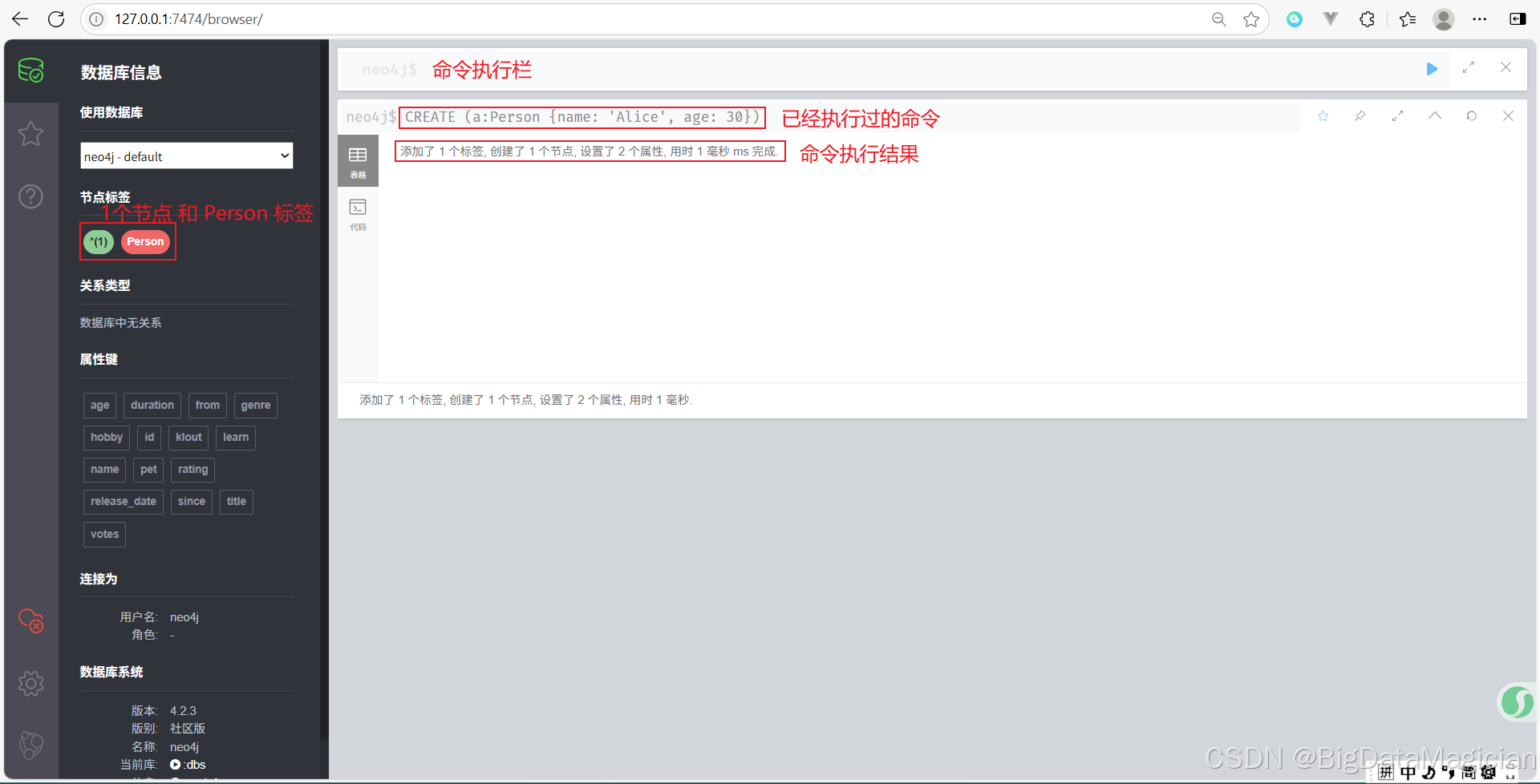
示例 1:創建一個簡單的節點
CREATE (a:Person {name: 'Alice', age: 30})
- 這個命令創建了一個帶有
Person標簽的節點,并賦予它兩個屬性:name和age。 - 節點變量為
a,可以在后續查詢中引用這個節點。
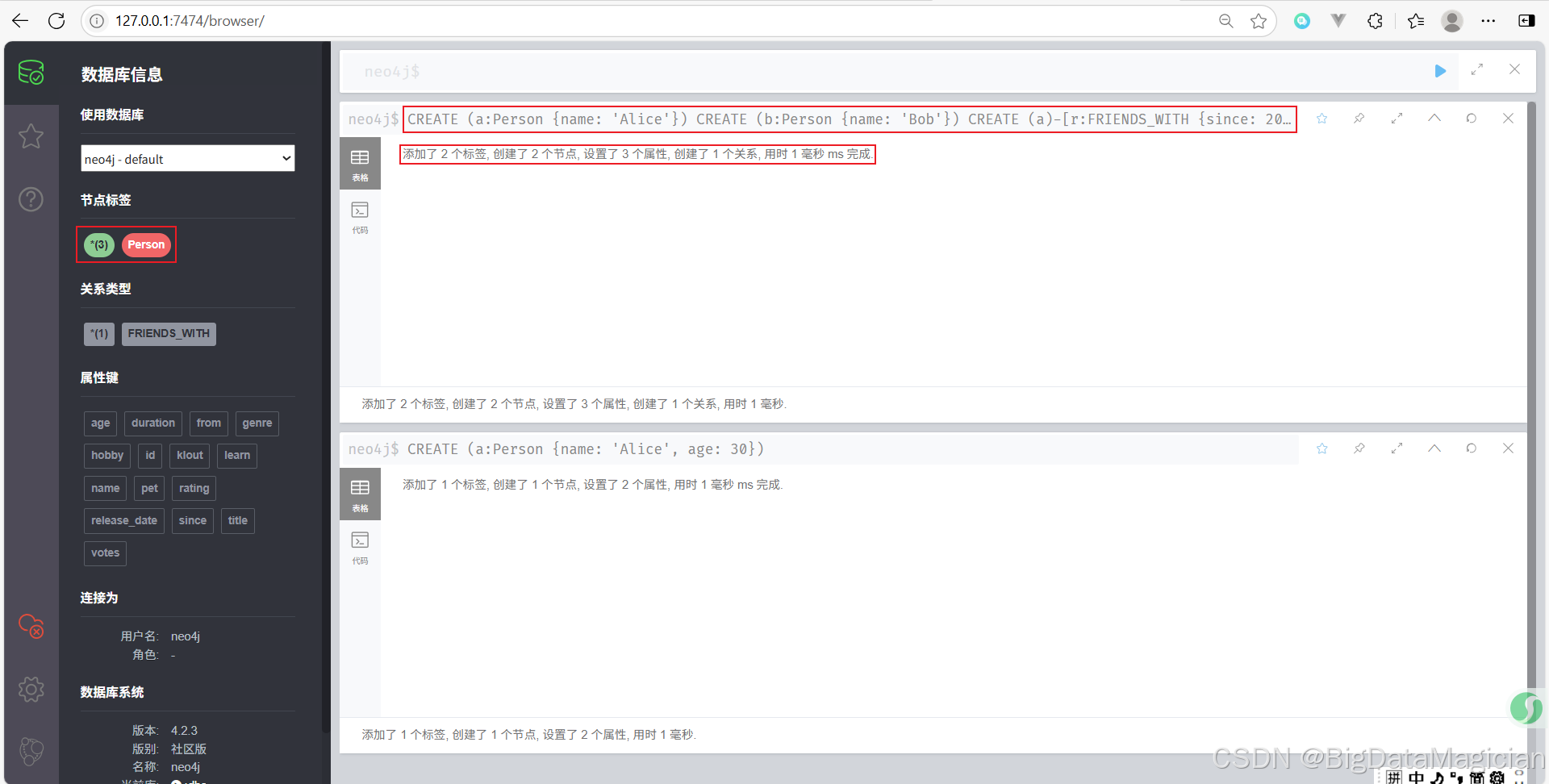
示例 2:創建兩個節點并建立關系
// 創建第一個節點 Alice
CREATE (a:Person {name: 'Alice'})
// 創建第二個節點 Bob
CREATE (b:Person {name: 'Bob'})
// 在 Alice 和 Bob 之間創建 FRIENDS_WITH 關系
CREATE (a)-[r:FRIENDS_WITH {since: 2020}]->(b)
- 這組命令首先創建了兩個
Person節點,分別代表 Alice 和 Bob。 - 然后在這兩個節點之間創建了一個類型為
FRIENDS_WITH的關系,并設置了關系屬性since,表示他們成為朋友的時間是 2020 年。 - 關系變量為
r,可以用于進一步操作或查詢這條關系。
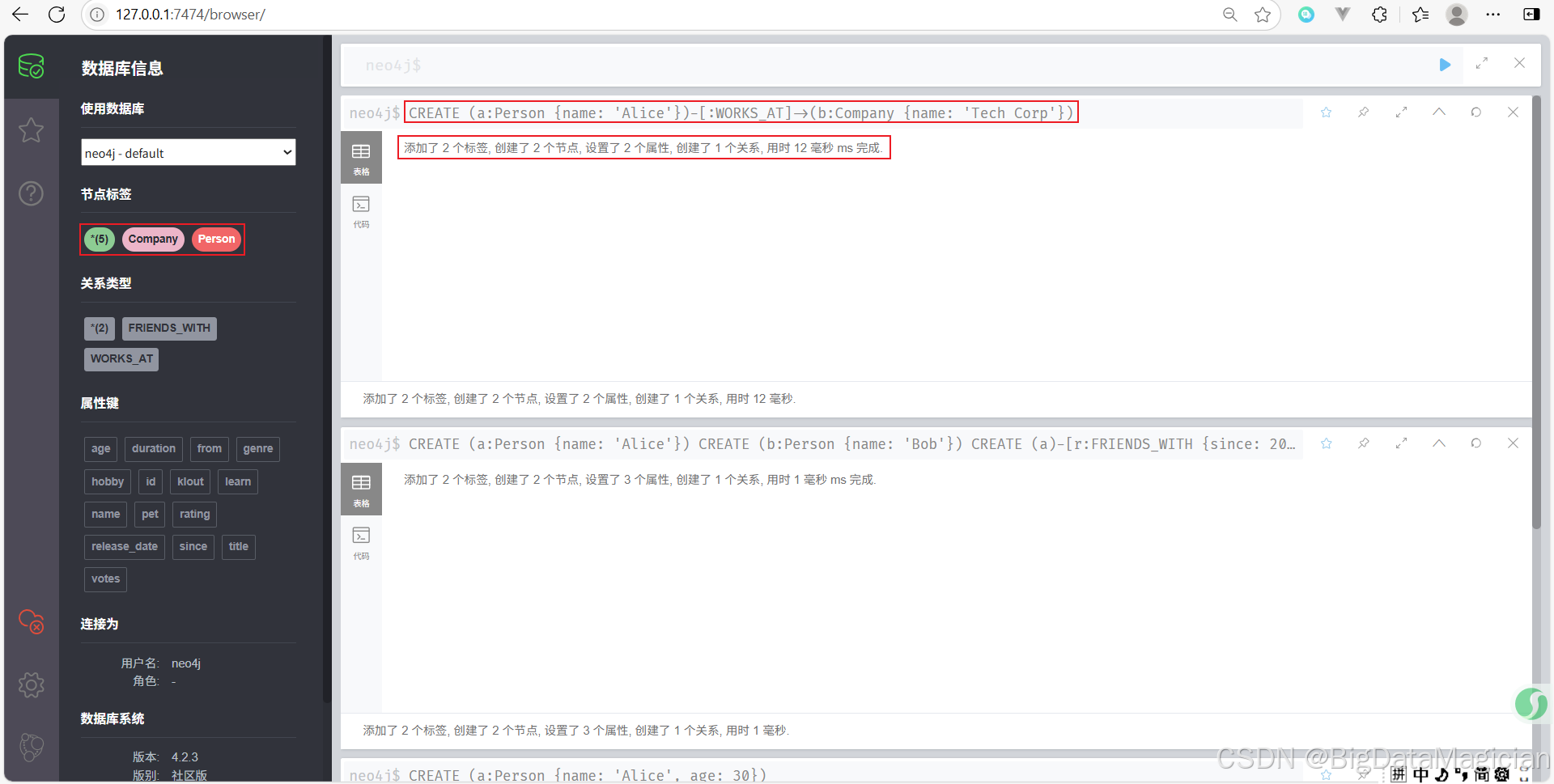
示例 3:在一個命令中創建節點和關系
CREATE (a:Person {name: 'Alice'})-[:WORKS_AT]->(b:Company {name: 'Tech Corp'})
- 此命令同時創建了兩個節點(一個
Person節點和一個Company節點)以及它們之間的WORKS_AT關系。 - 注意這里沒有給關系指定變量,這意味著我們不能直接引用這條關系進行后續操作,除非再次通過查詢找到它。
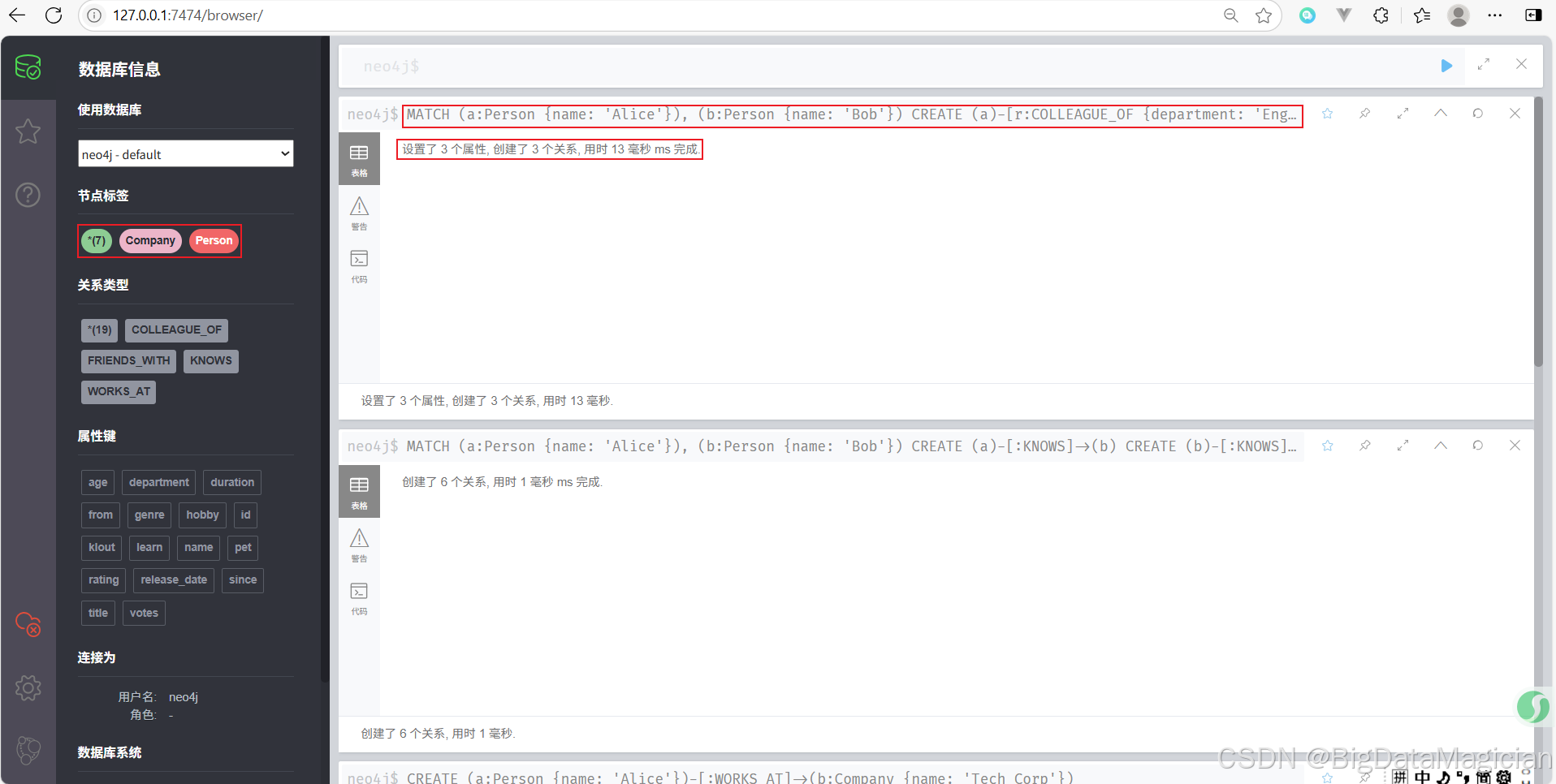
示例 4:使用已存在的節點創建關系
MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'})
CREATE (a)-[r:COLLEAGUE_OF {department: 'Engineering'}]->(b)
- 首先通過
MATCH查找數據庫中名為 Alice 和 Bob 的節點。 - 然后在找到的這兩個節點之間創建了一個
COLLEAGUE_OF類型的關系,并添加了一個department屬性說明他們在同一個部門工作。 - 給關系指定了變量
r,方便之后對這條關系進行修改或查詢。
示例 5:創建雙向關系
雖然在 Cypher 中默認定義的關系是有方向性的,但可以通過創建兩條相反方向的關系來模擬雙向關系:
MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'})
CREATE (a)-[:KNOWS]->(b)
CREATE (b)-[:KNOWS]->(a)
- 這段代碼創建了兩個
KNOWS關系,一條從 Alice 到 Bob,另一條從 Bob 到 Alice,從而實現了雙向關系的效果。
2. 查詢數據
在 Neo4j 中,MATCH 是用于查詢圖數據的核心命令。它通過模式匹配(Pattern Matching) 來查找符合特定結構的節點、關系及其屬性。
2.1 語法
基本語法結構如下:
MATCH (variable1:Label1 {property1: value1})
RETURN variable1
(variable1:Label1 {property1: value1}):表示一個帶有標簽和屬性的節點。RETURN:指定你想返回的數據內容。
匹配帶關系的結構語法如下:
MATCH (variable1:Label1)-[:RELATIONSHIP_TYPE]->(variable2:Label2)
RETURN variable1, variable2
-[:RELATIONSHIP_TYPE]->:表示兩個節點之間的關系,方向可變(->或<-)。RELATIONSHIP_TYPE:是你定義的關系類型,如KNOWS,WORKS_AT等。
使用 WHERE 進行過濾語法如下:
MATCH (n:Person)
WHERE n.age > 30
RETURN n.name
WHERE子句用于添加條件過濾查詢結果。
2.2 示例
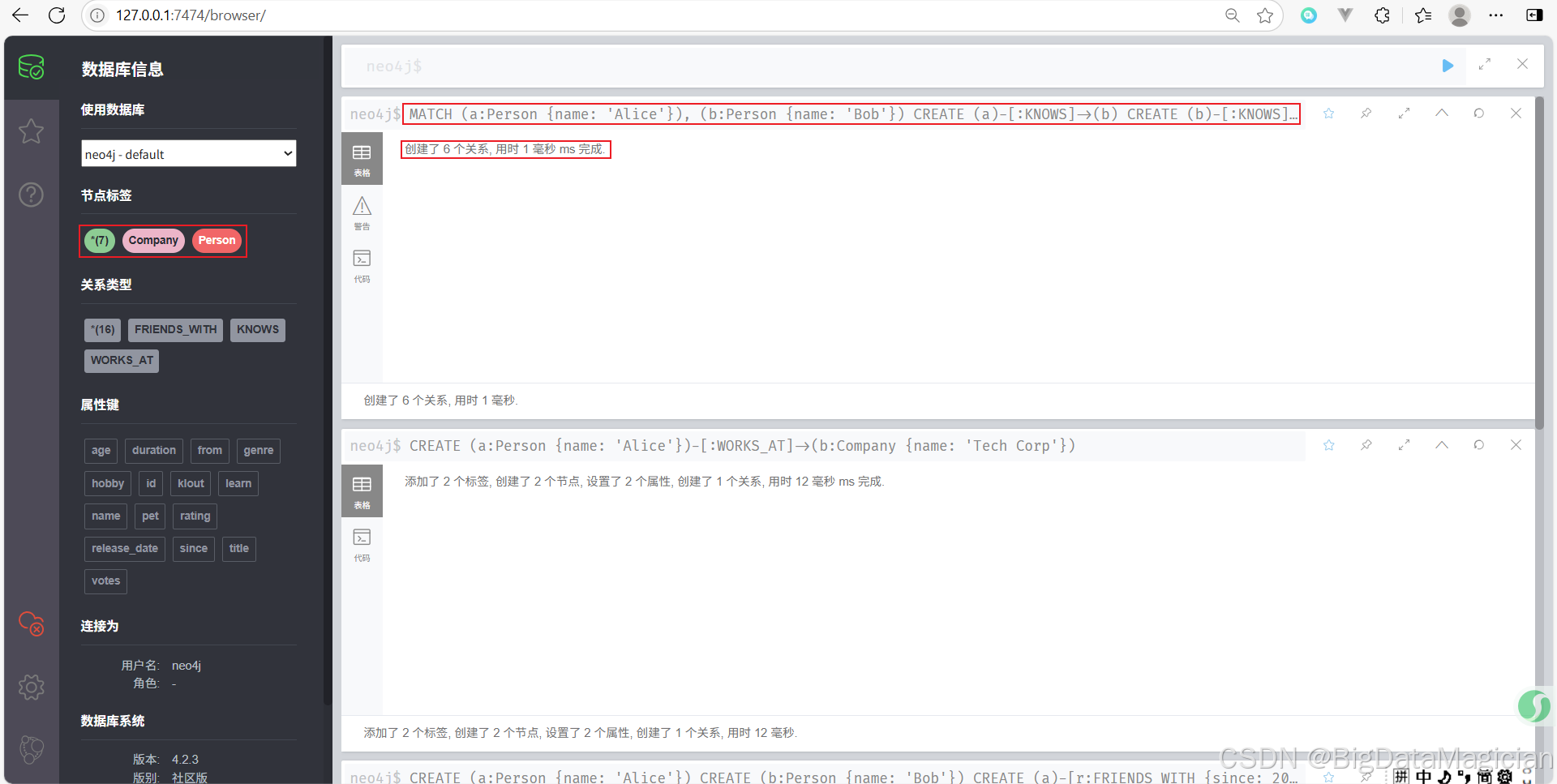
示例 1:查詢所有 Person 節點
MATCH (p:Person)
RETURN p
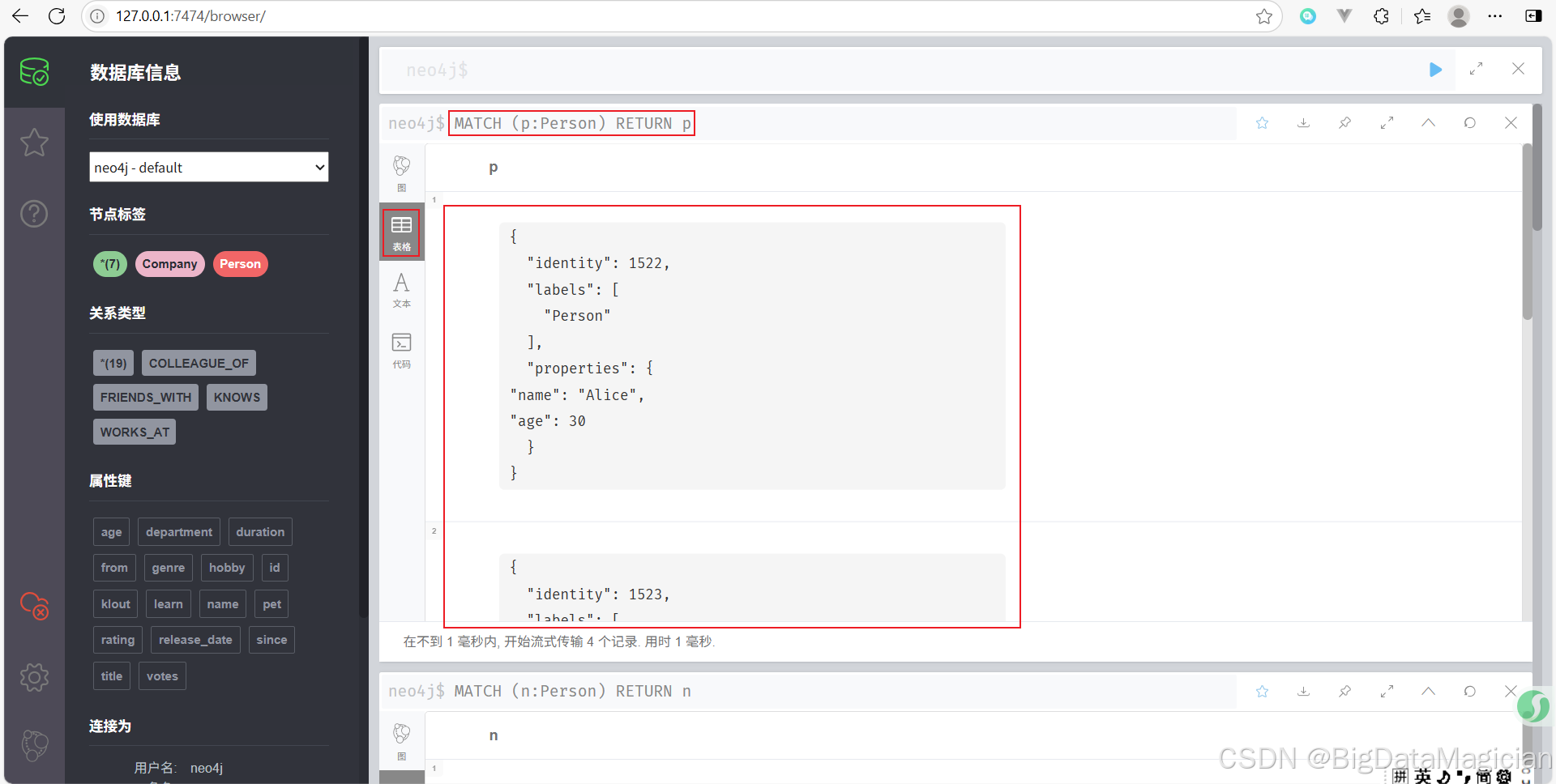
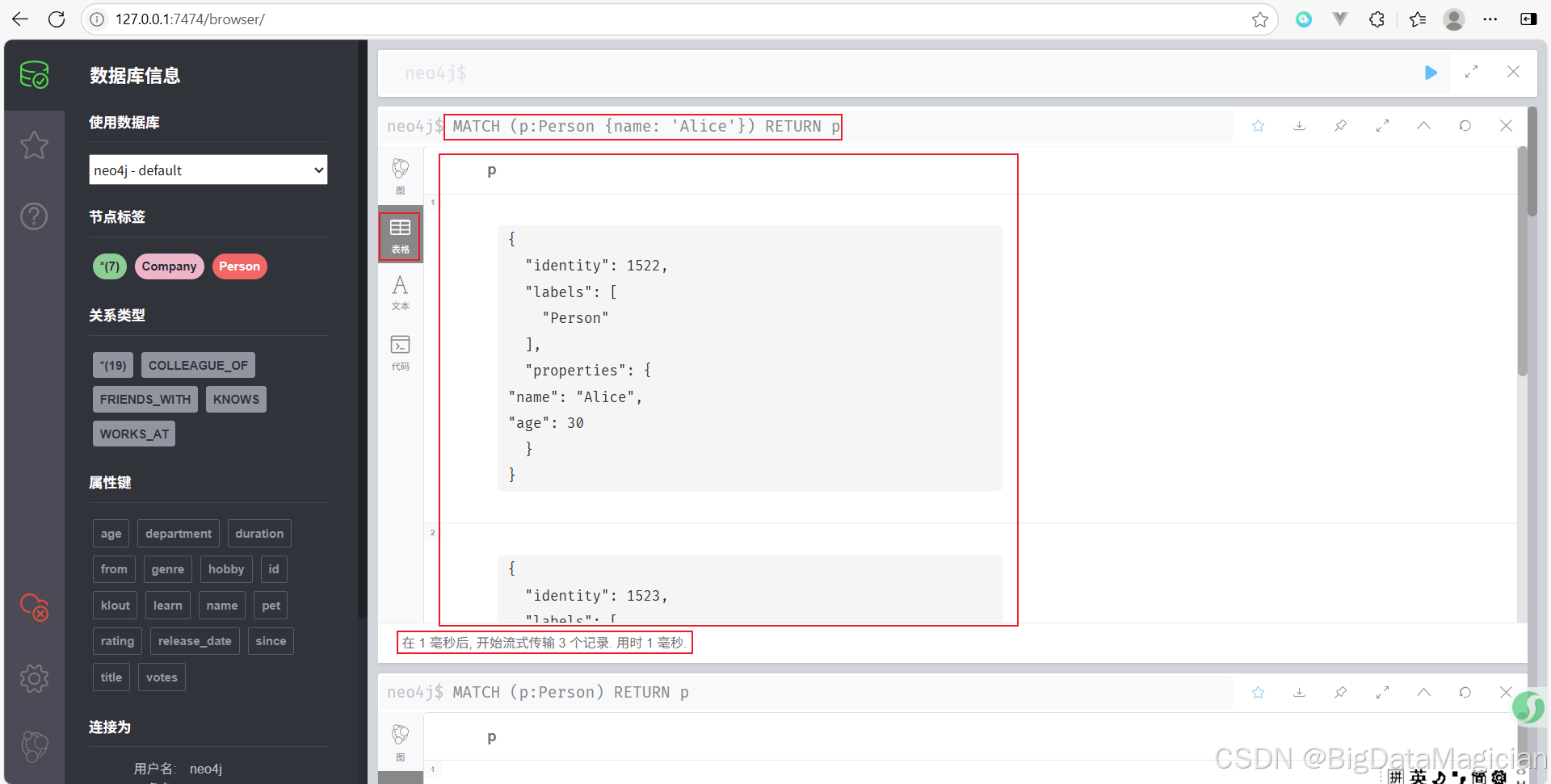
示例 2:查詢具有特定屬性的節點
查找名字為 Alice 的 Person 節點。
MATCH (p:Person {name: 'Alice'})
RETURN p
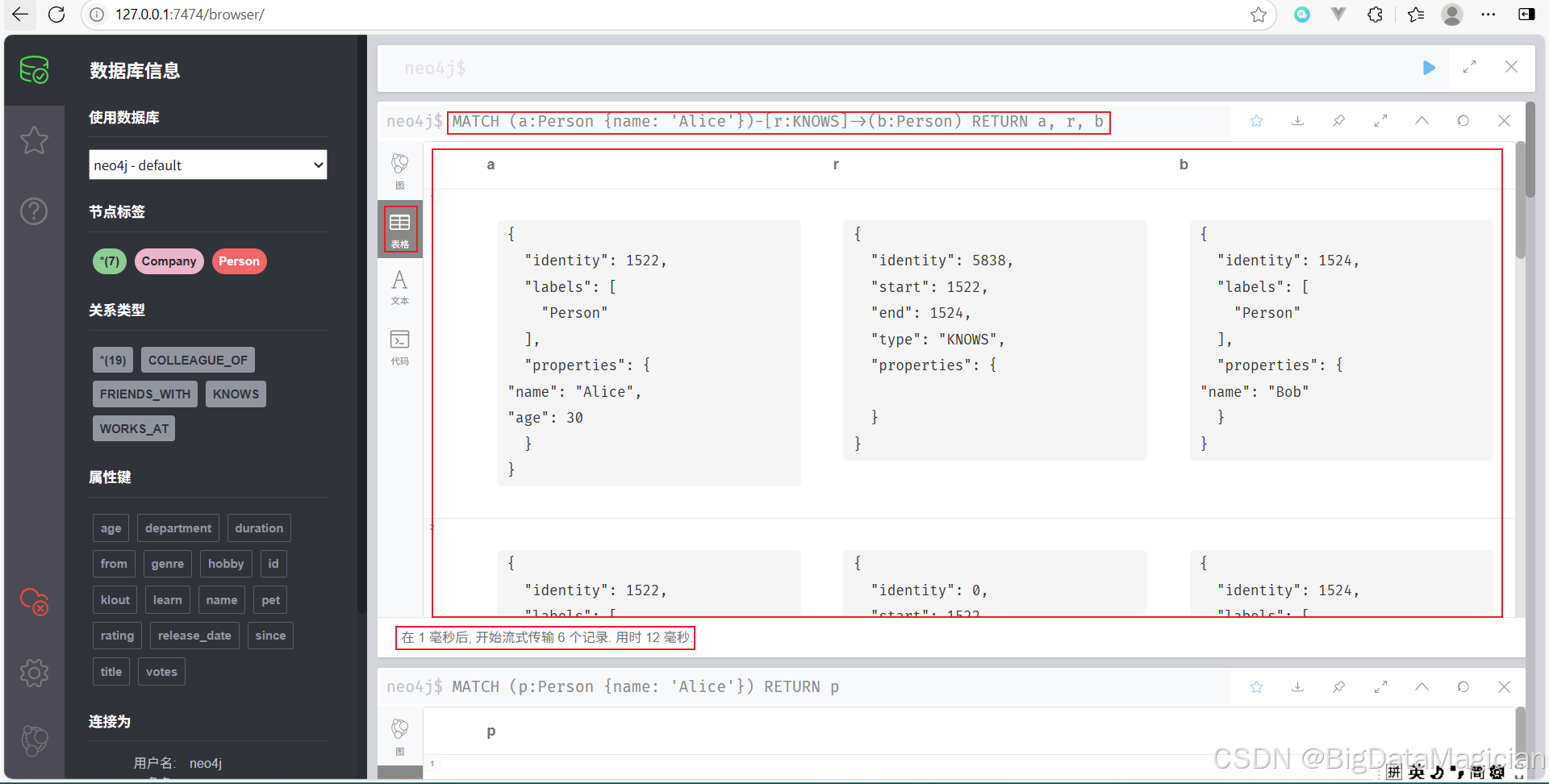
示例 3:查詢節點和其關系
查找 Alice 所認識的所有人,并返回 Alice、KNOWS 關系以及對方節點。
MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person)
RETURN a, r, b
示例 4:僅返回某些字段或屬性
只返回 Person 節點的 name 和 age 屬性。
MATCH (p:Person)
RETURN p.name, p.age
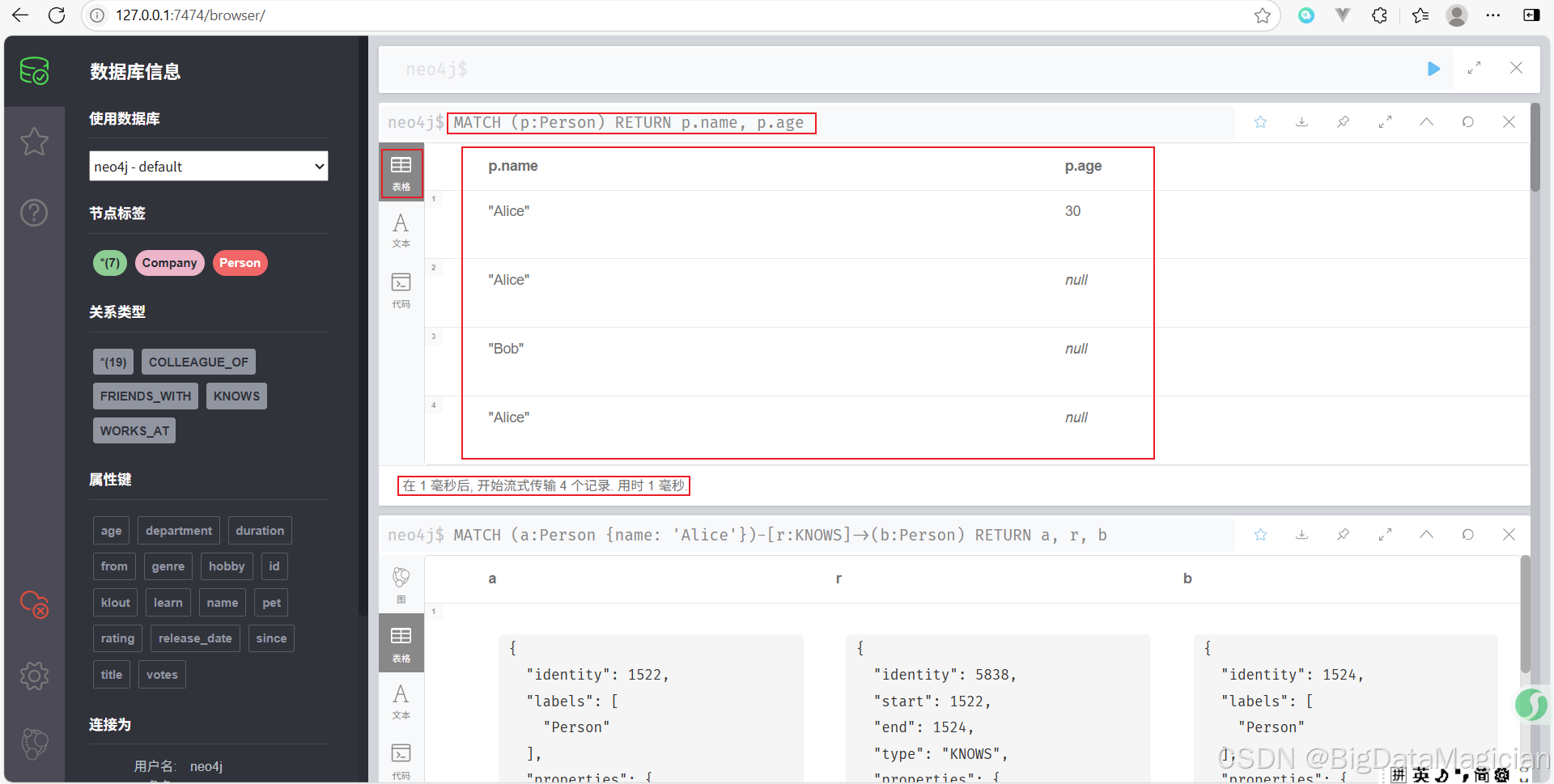
示例 5:使用 WHERE 過濾年齡大于 30 的人
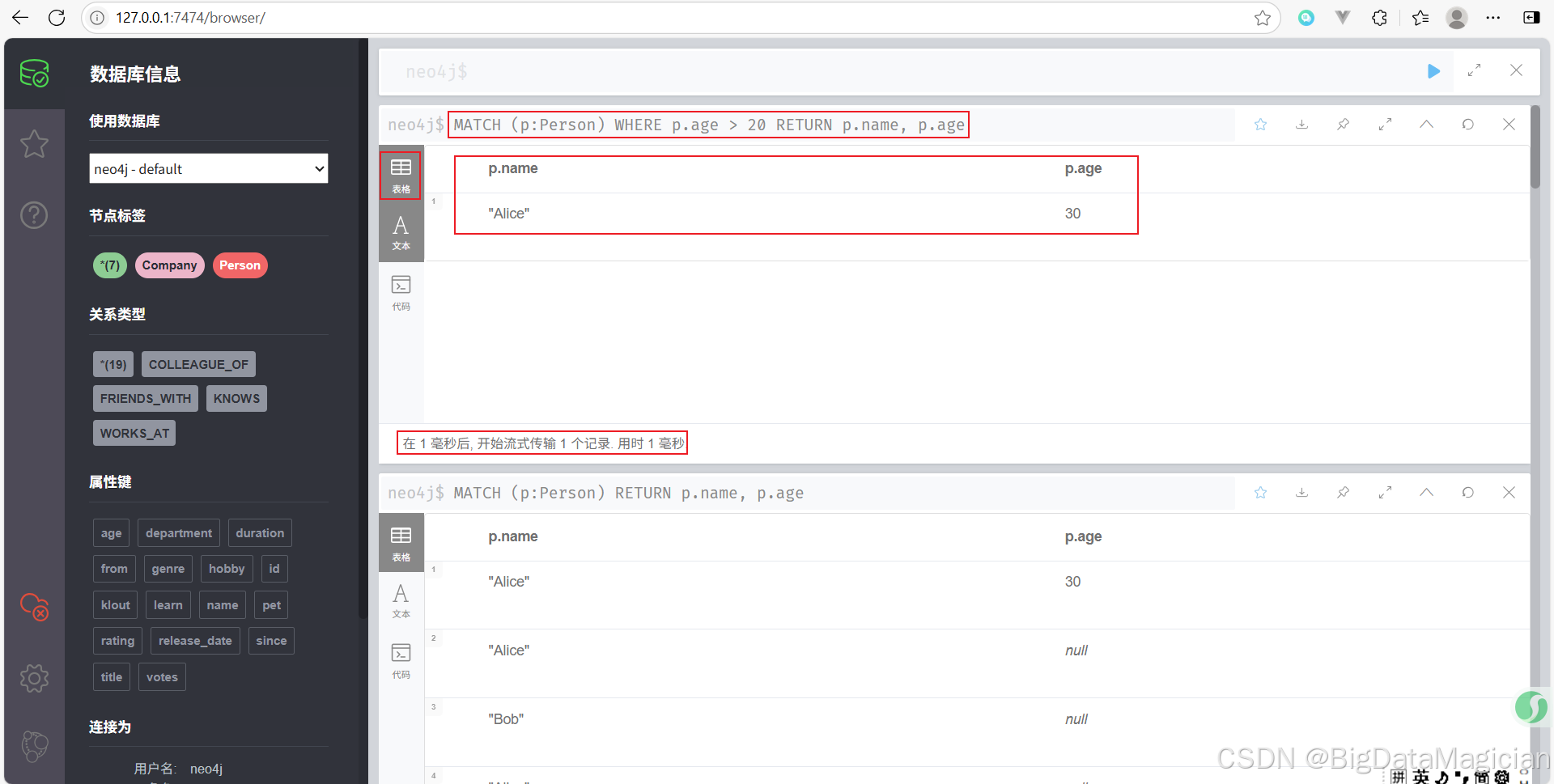
查找并返回年齡大于 20 的人。
MATCH (p:Person)
WHERE p.age > 20
RETURN p.name, p.age
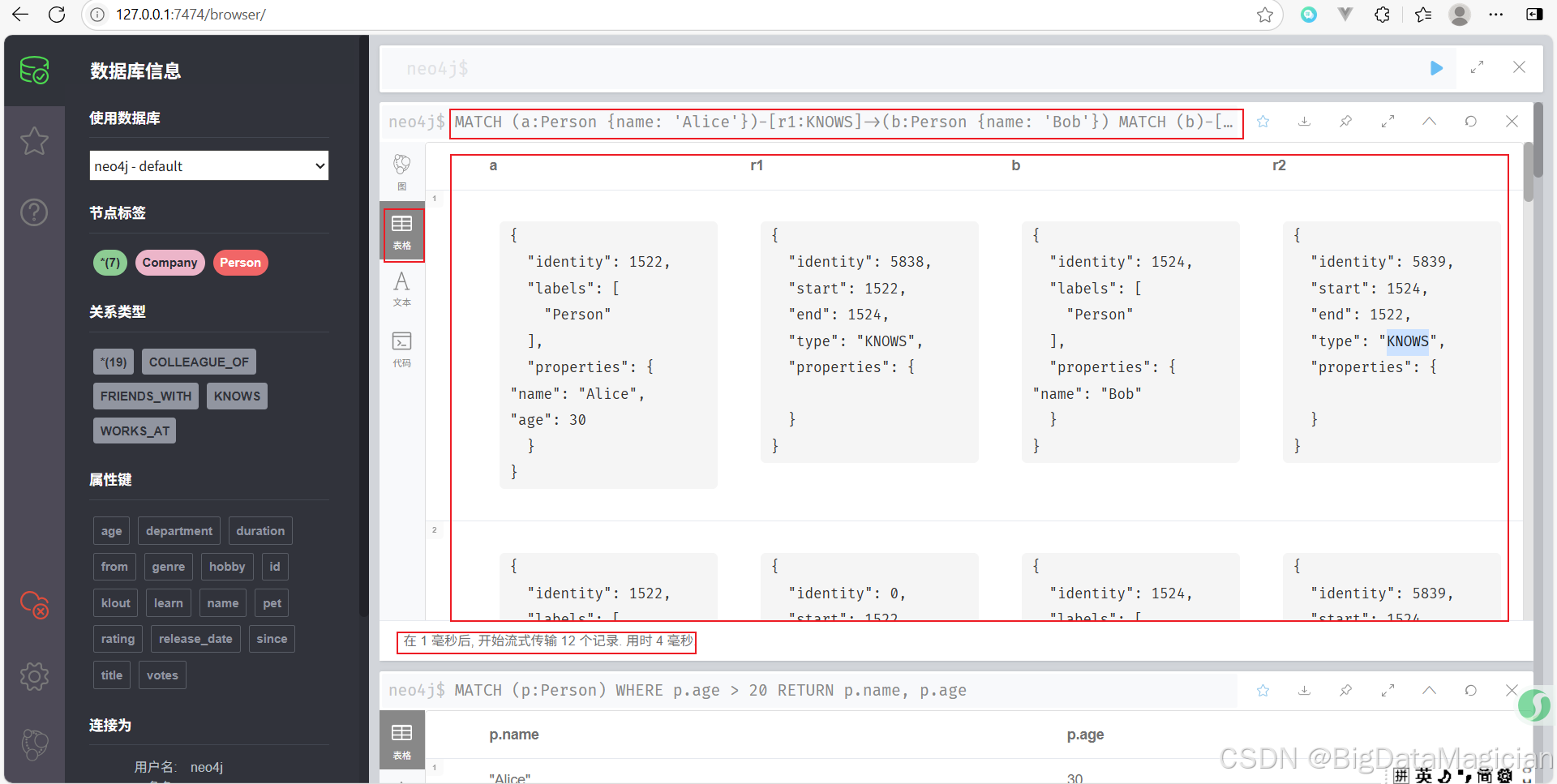
示例 6:查找雙向關系(比如互為好友)
MATCH (a:Person {name: 'Alice'})-[r1:KNOWS]->(b:Person {name: 'Bob'})
MATCH (b)-[r2:KNOWS]->(a)
RETURN a, r1, b, r2
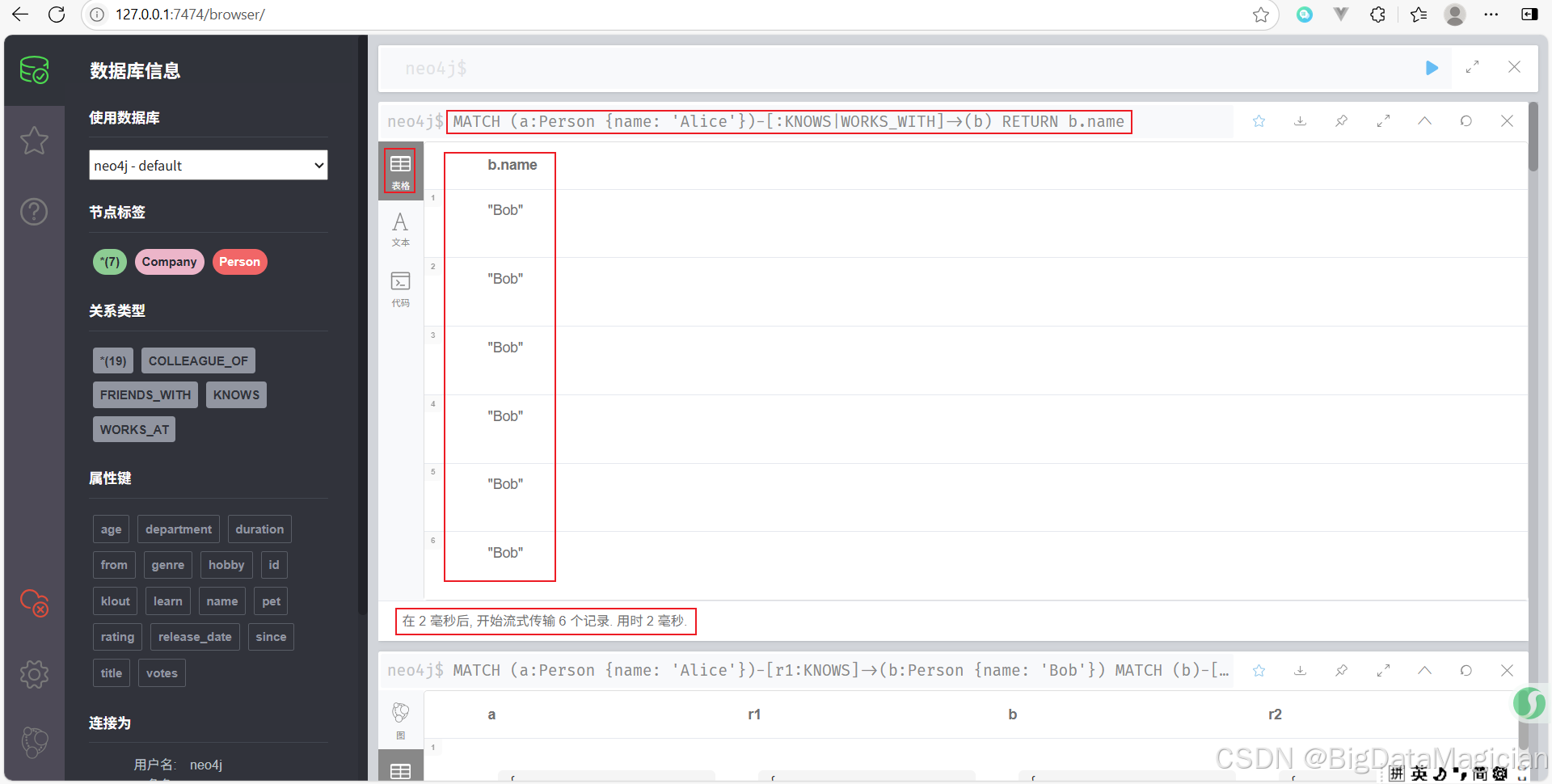
示例 7:模糊匹配多個關系類型
查找 Alice 認識或一起工作的人。
MATCH (a:Person {name: 'Alice'})-[:KNOWS|WORKS_WITH]->(b)
RETURN b.name
示例 8:限制返回數量
最多只返回 3 個 Person 的名字。
MATCH (p:Person)
RETURN p.name
LIMIT 3
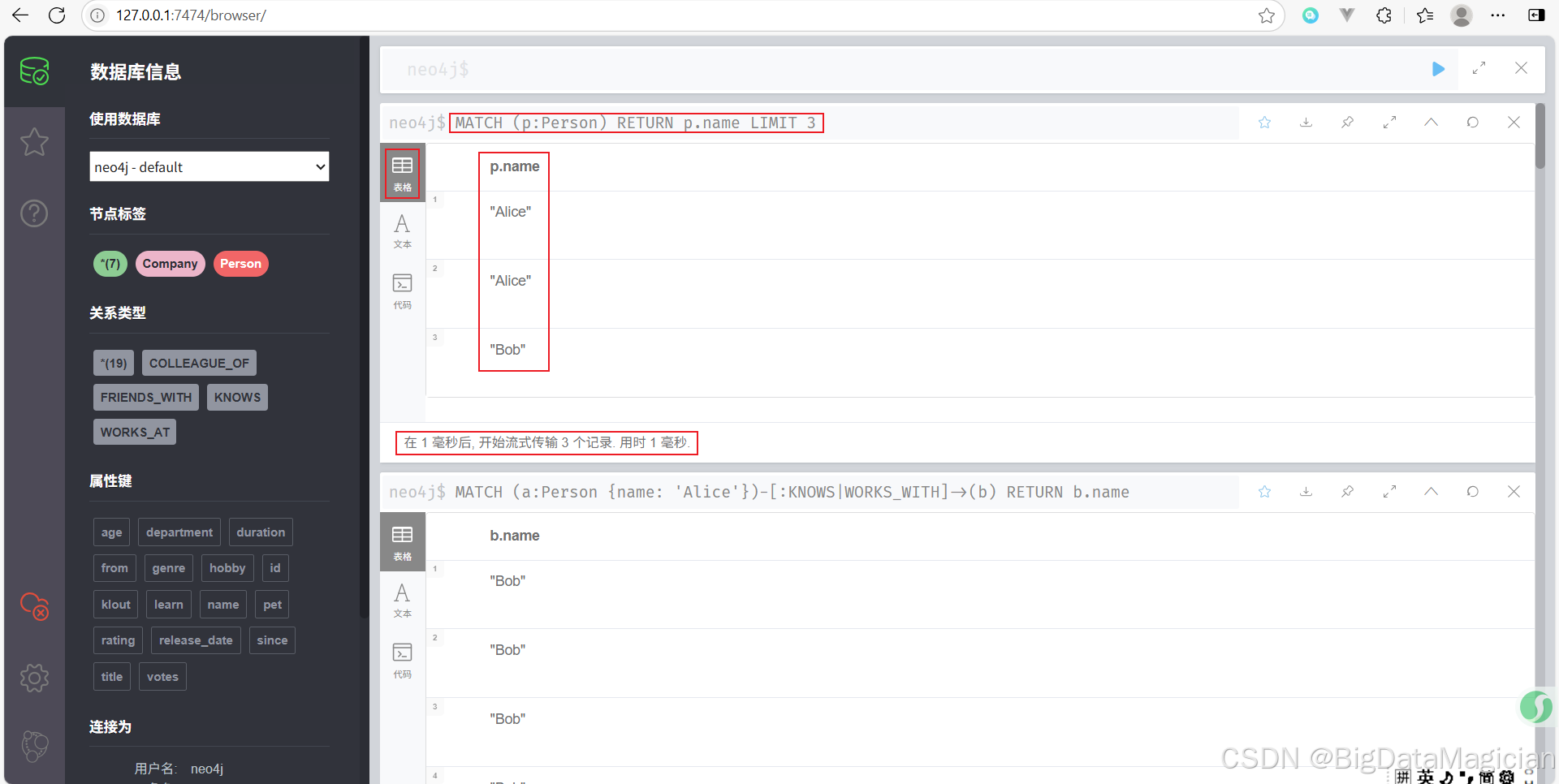
跳過 1 個查詢結果并最多返回 3 個 Person 的名字。
MATCH (p:Person)
RETURN p.name
LIMIT 3
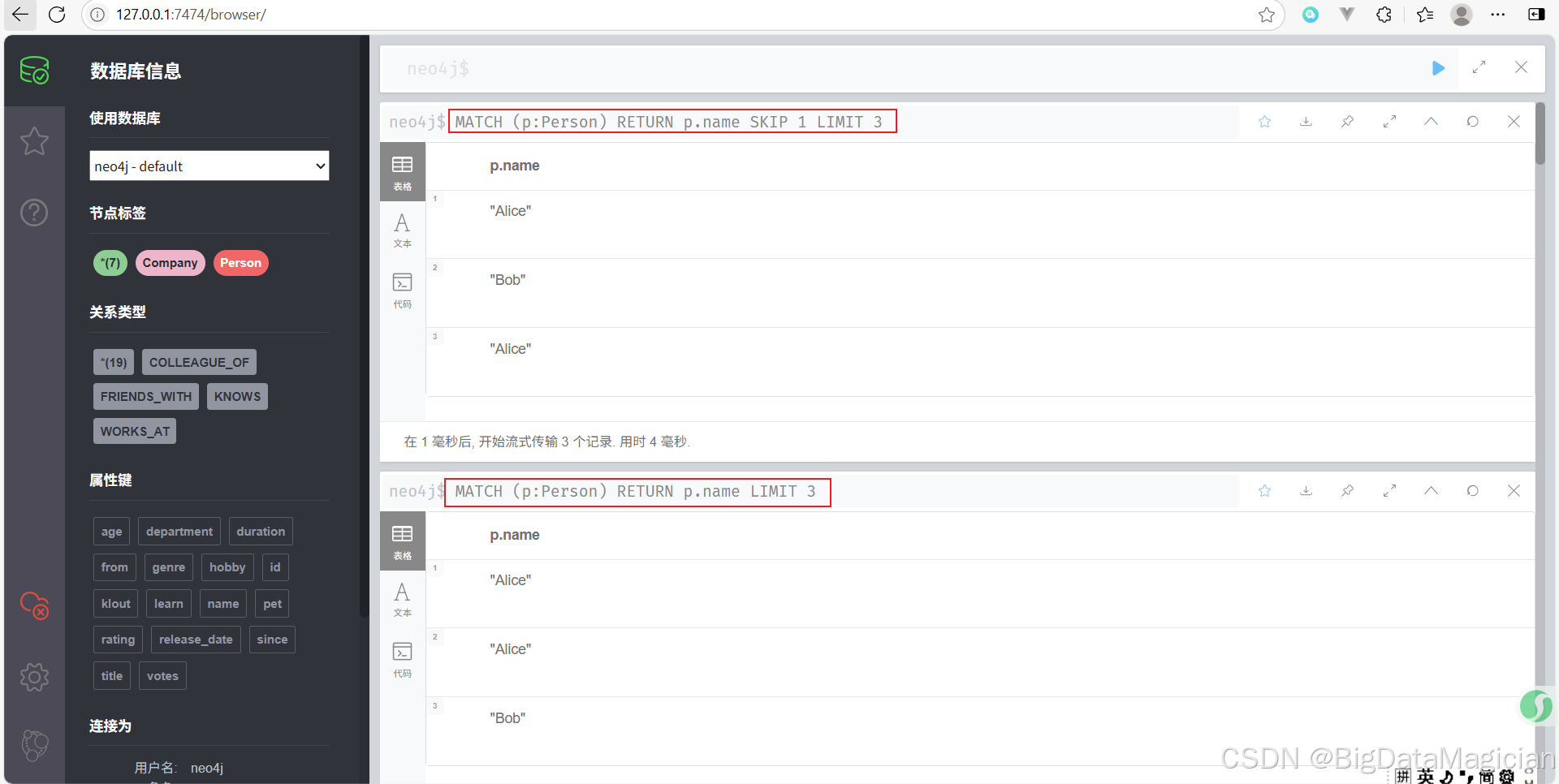
3. 更新數據
在 Neo4j 中,使用 Cypher 可以方便地更新圖數據庫中的節點(Node)和關系(Relationship)的屬性值;可以使用 SET、REMOVE 等命令進行更新操作。
3.1 語法
更新節點屬性的語法如下:
MATCH (n:Label {property: value})
SET n.propertyName = newValue
RETURN n
MATCH:查找要更新的節點。SET:設置或修改某個屬性的值。RETURN:返回更新后的結果(可選)。
刪除屬性或標簽語法如下:
MATCH (n:Person {name: 'Alice'})
REMOVE n.age
RETURN n
REMOVE命令可以刪除節點或關系的屬性或標簽。
更新關系屬性語法如下:
MATCH ()-[r:RELATIONSHIP_TYPE]->()
SET r.newProperty = 'value'
RETURN r
3.2 示例
示例 1:更新節點的屬性
將名為 Alice 的 Person 節點的年齡改為 31 歲。
MATCH (n:Person {name: 'Alice'})
SET n.age = 31
RETURN n
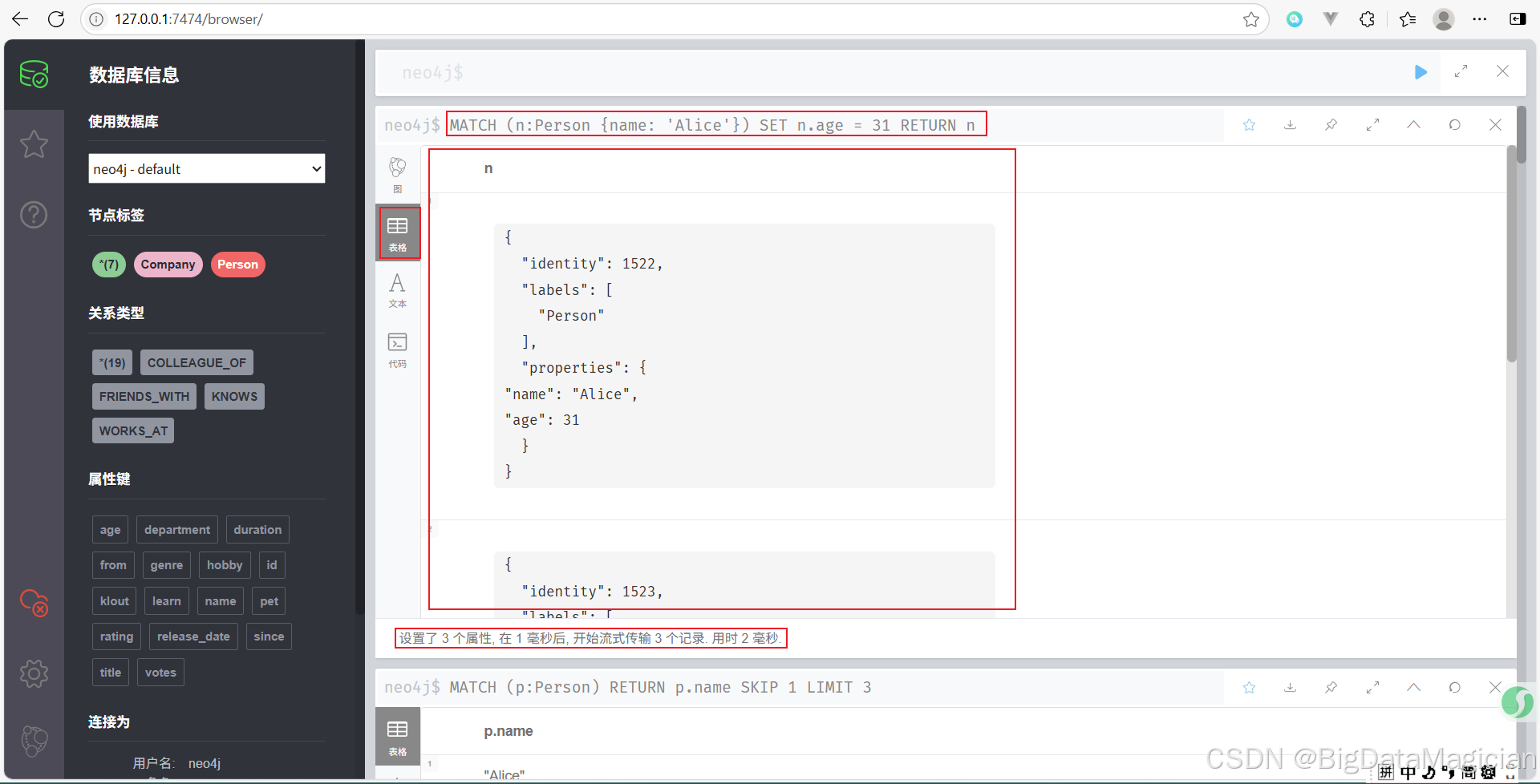
示例 2:添加新的屬性
為名為 Bob 的 Person 添加一個新屬性 email。
MATCH (n:Person {name: 'Bob'})
SET n.email = 'bob@example.com'
RETURN n
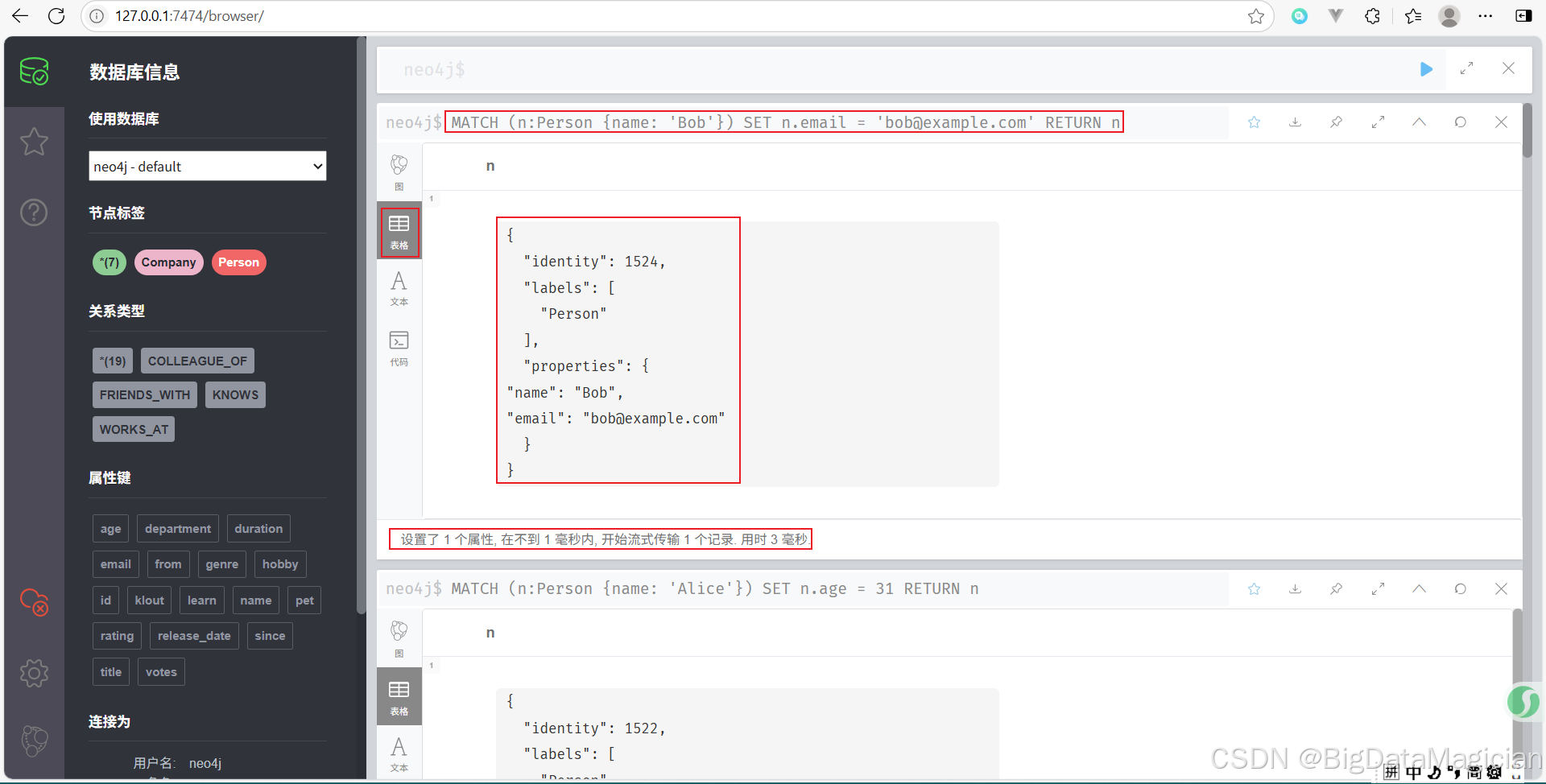
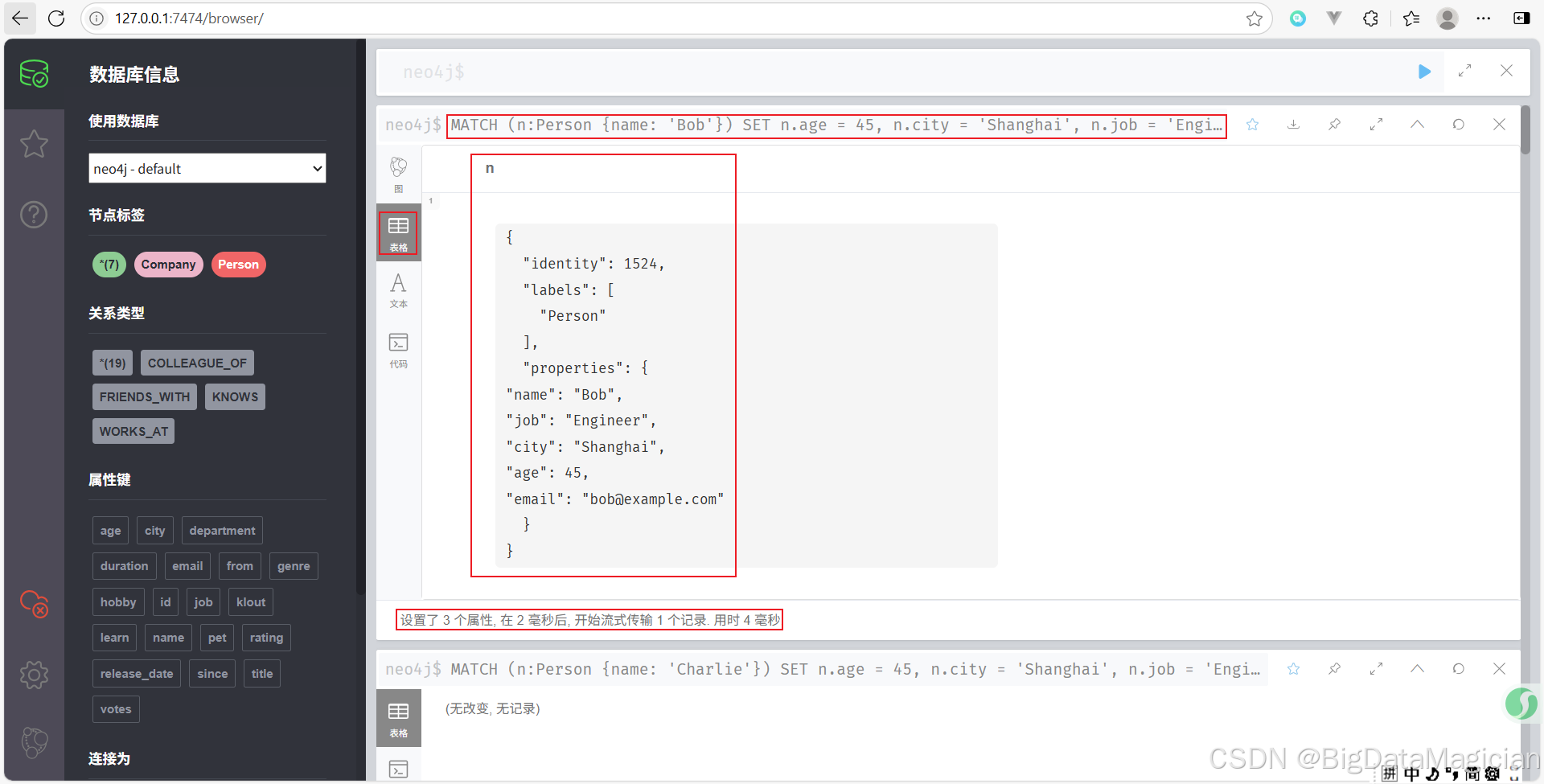
示例 3:一次性設置多個屬性
可以在一條 SET 語句中同時設置多個屬性。
MATCH (n:Person {name: 'Bob'})
SET n.age = 45, n.city = 'Shanghai', n.job = 'Engineer'
RETURN n
示例 4:刪除節點的某個屬性
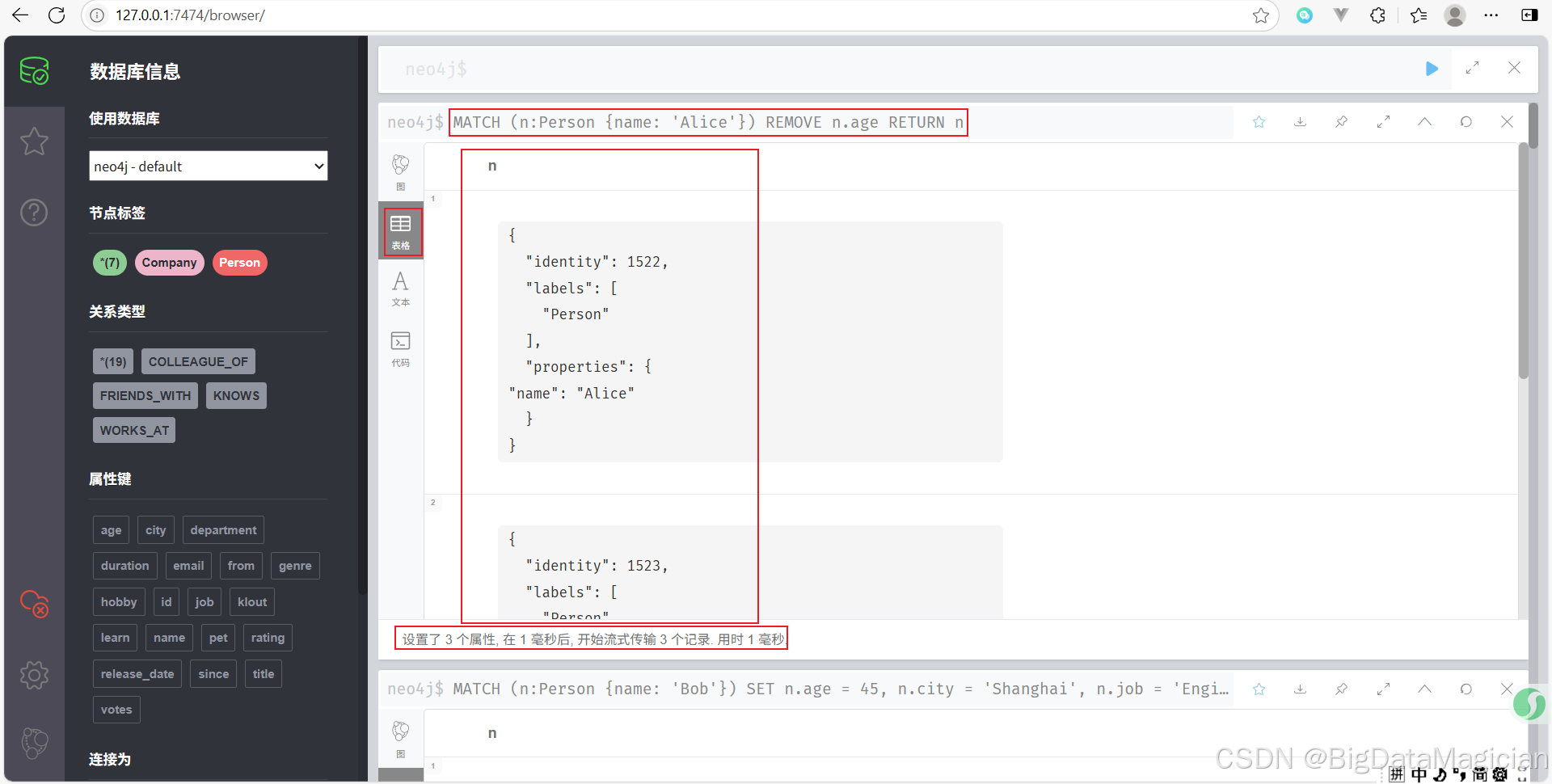
刪除名為 Alice 的 Person 的 age 屬性。
MATCH (n:Person {name: 'Alice'})
REMOVE n.age
RETURN n
示例 5:刪除節點的標簽
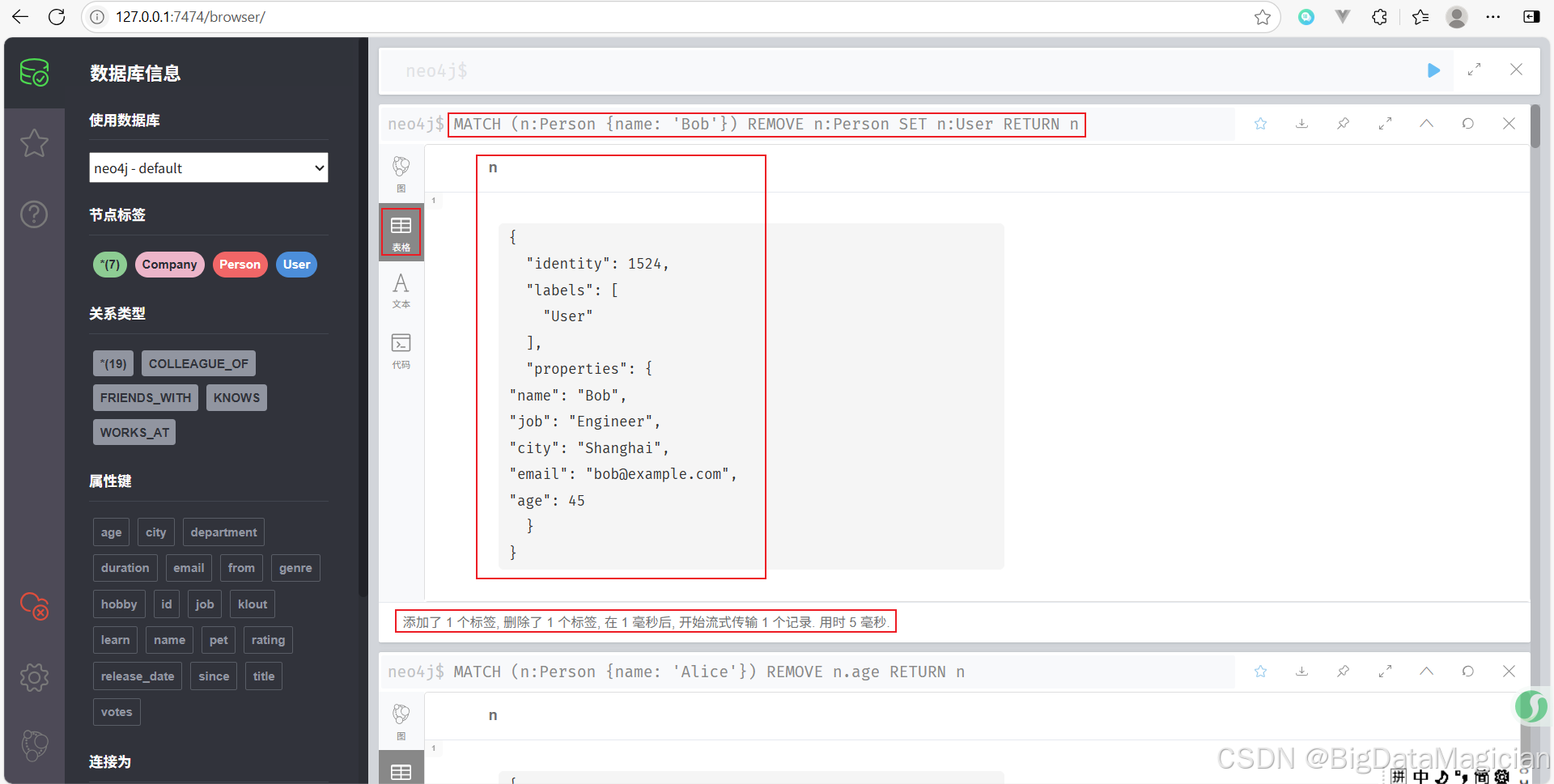
將名為 Bob 的 Person 節點的標簽從 Person 改為 User。
MATCH (n:Person {name: 'Bob'})
REMOVE n:Person
SET n:User
RETURN n
?? 注意:Neo4j 不支持直接重命名標簽,只能通過先移除再添加的方式來“更改”標簽。
示例 6:更新關系屬性
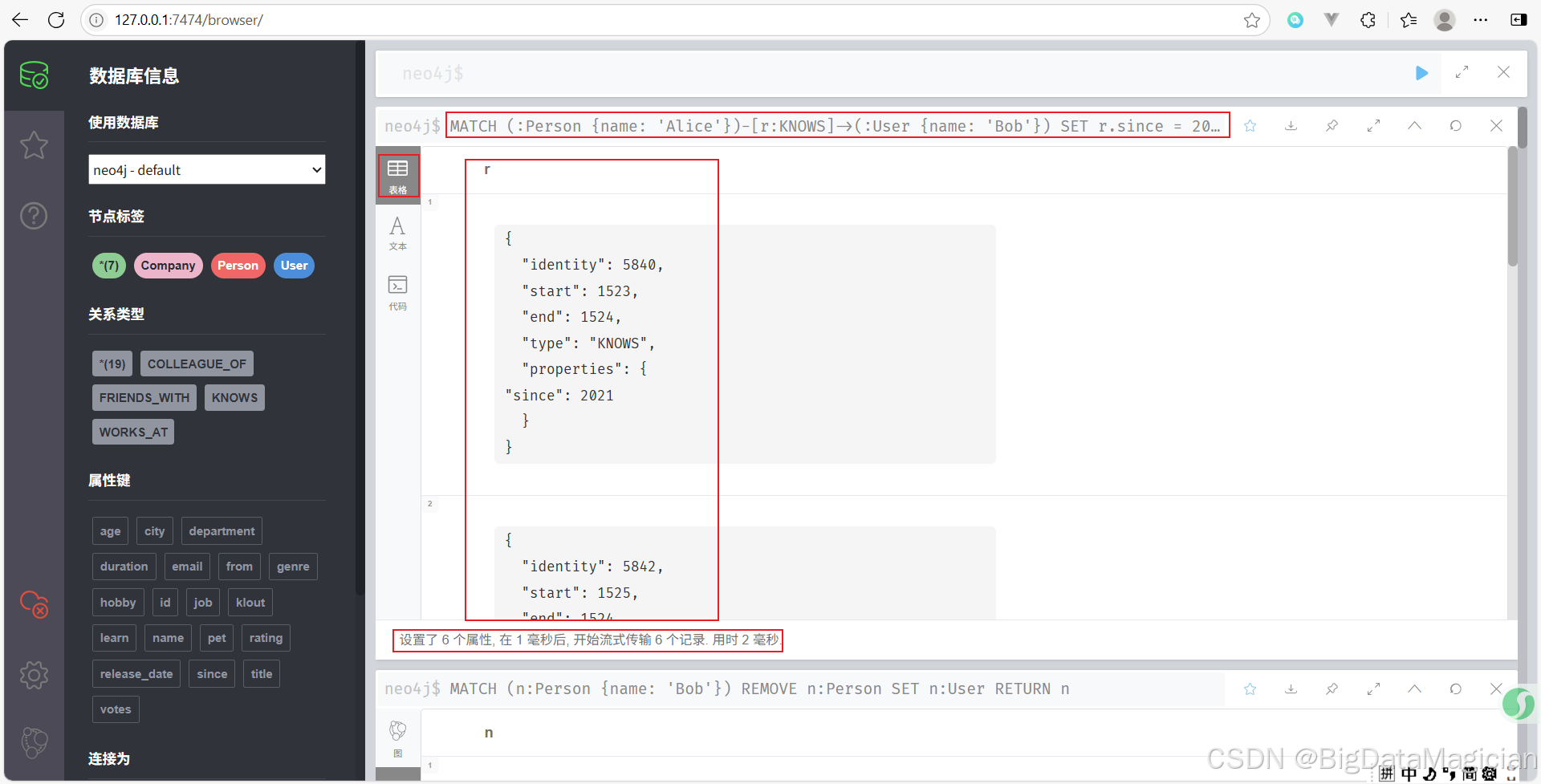
更新Alice和Bob的 KNOWS 關系的 since 屬性。
MATCH (:Person {name: 'Alice'})-[r:KNOWS]->(:User {name: 'Bob'})
SET r.since = 2021
RETURN r
4. 刪除節點與關系
在 Neo4j 中,刪除圖數據庫中的 節點(Node) 和 關系(Relationship) 是常見的操作。Cypher 提供了 DELETE 和 DETACH DELETE 等命令來完成這些任務。
由于 Neo4j 的圖結構特性:一個節點不能有未刪除的關系存在,因此在刪除節點前必須先刪除它關聯的所有關系,否則會報錯。
4.1 語法
刪除關系的語法如下:
MATCH ()-[r:RELATIONSHIP_TYPE]->()
DELETE r
- 使用
MATCH找到要刪除的關系。 - 使用
DELETE刪除匹配到的關系。
刪除節點的語法(需先刪除關系)如下:
MATCH (n:Label {property: value})
DELETE n
?? 如果該節點還有關系存在,將拋出錯誤。
推薦方式:使用 DETACH DELETE
MATCH (n:Label {property: value})
DETACH DELETE n
DETACH DELETE會自動刪除節點及其所有關聯的關系,無需手動先刪除關系。- 這是最安全、最常用的刪除節點的方式。
4.2 示例
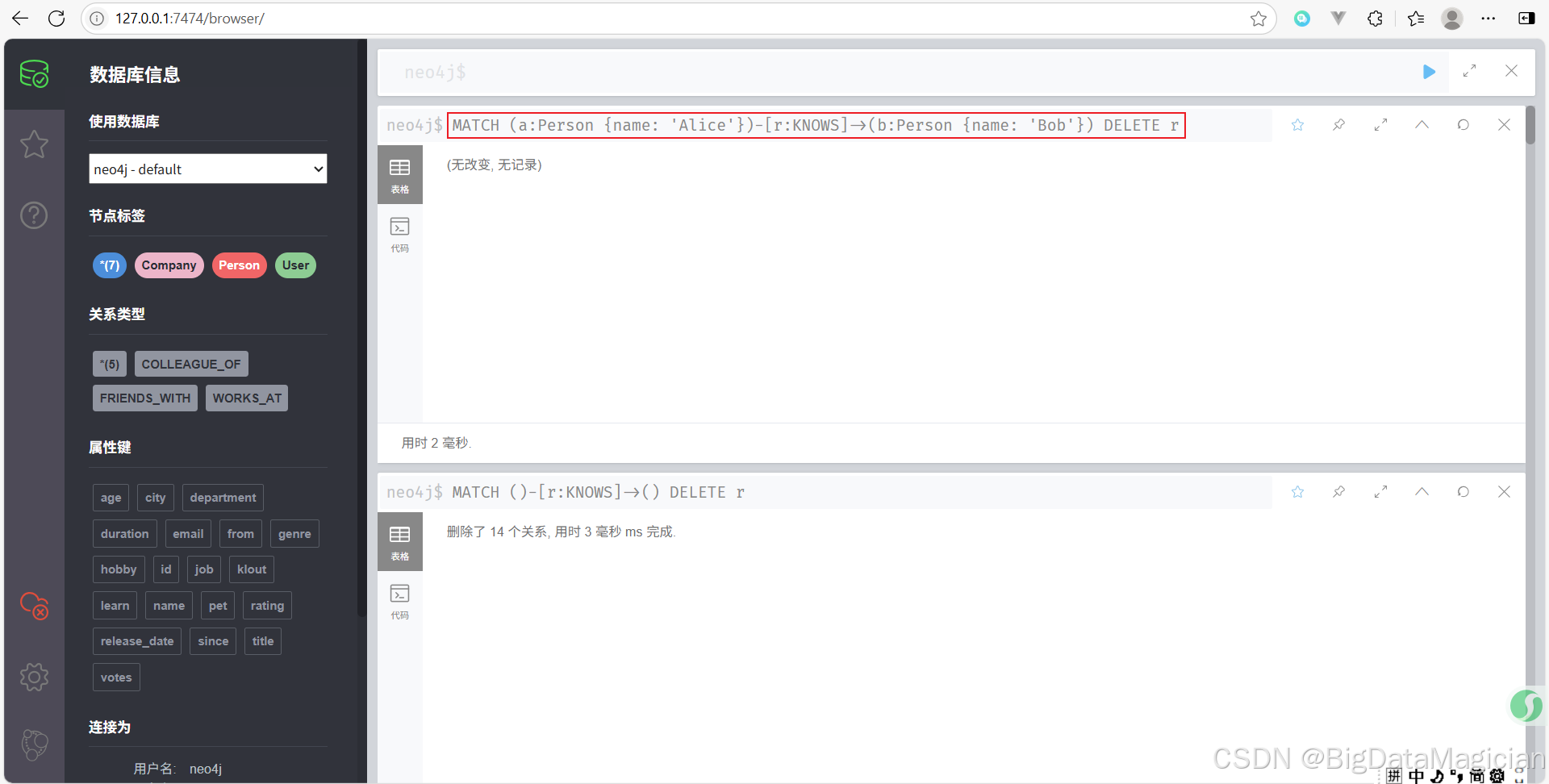
示例 1:刪除兩個特定節點之間的關系
刪除 Alice 和 Bob 之間的 KNOWS 關系。
MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person {name: 'Bob'})
DELETE r
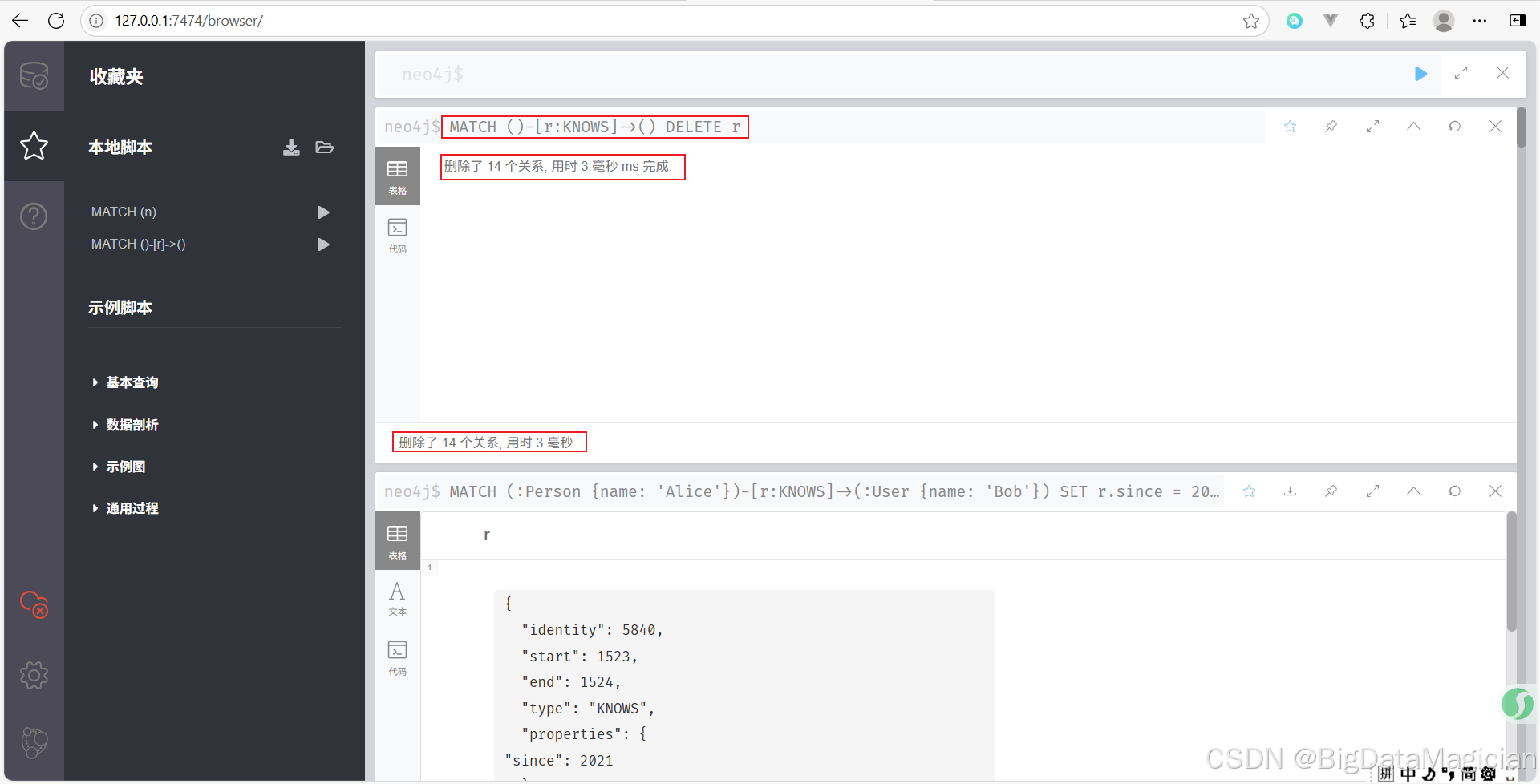
示例 2:刪除特定類型的關系
刪除所有的 KNOWS 類型關系。
MATCH ()-[r:KNOWS]->()
DELETE r
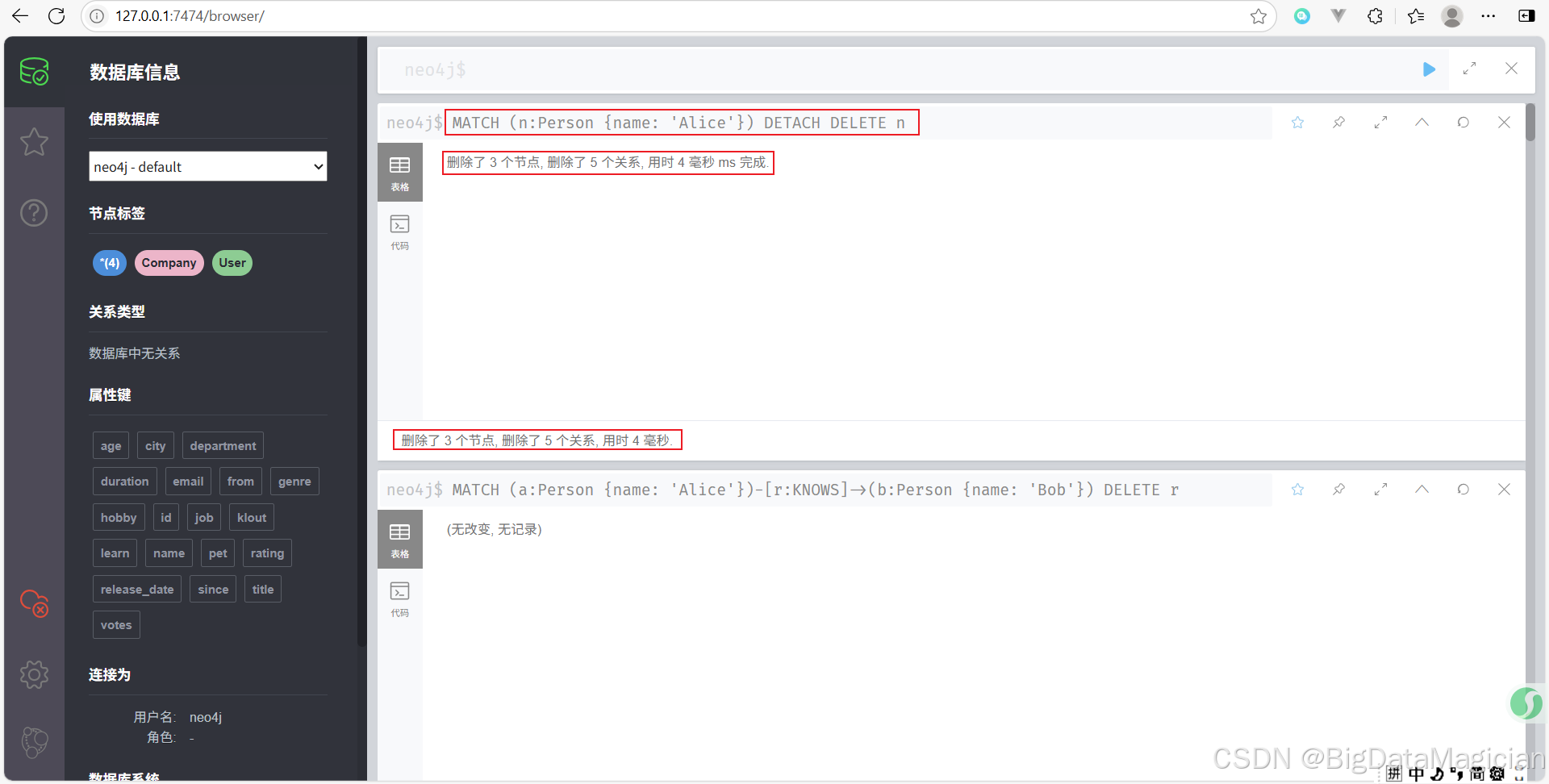
示例 3:刪除某個特定節點(先刪除關系)
刪除名為 Alice 的 Person 節點及其所有關系。
MATCH (n:Person {name: 'Alice'})
DETACH DELETE n
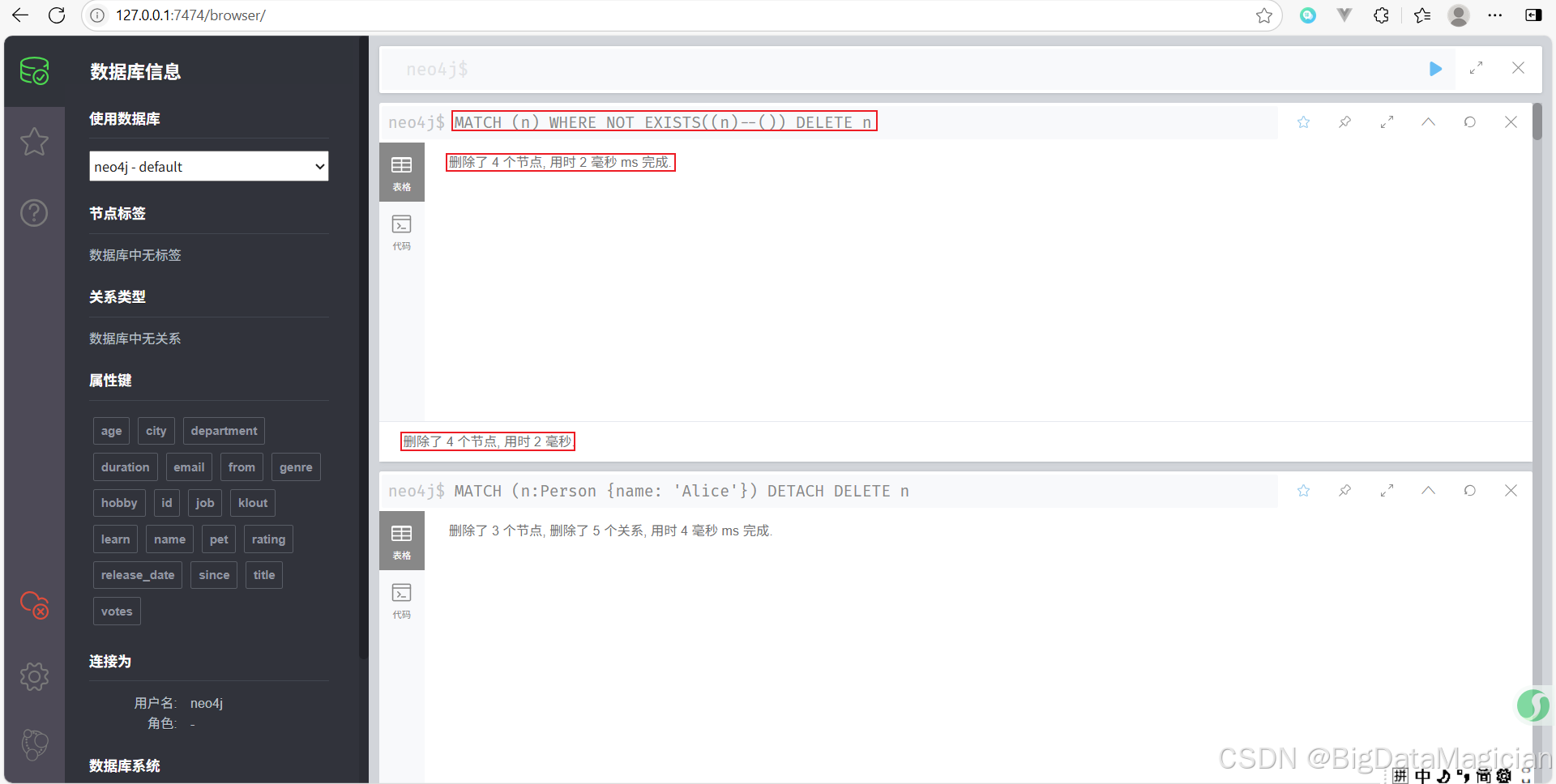
示例 4:刪除沒有關系的孤立節點
刪除“孤立”的節點(即沒有關系連接的節點)。
MATCH (n)
WHERE NOT EXISTS((n)--())
DELETE n
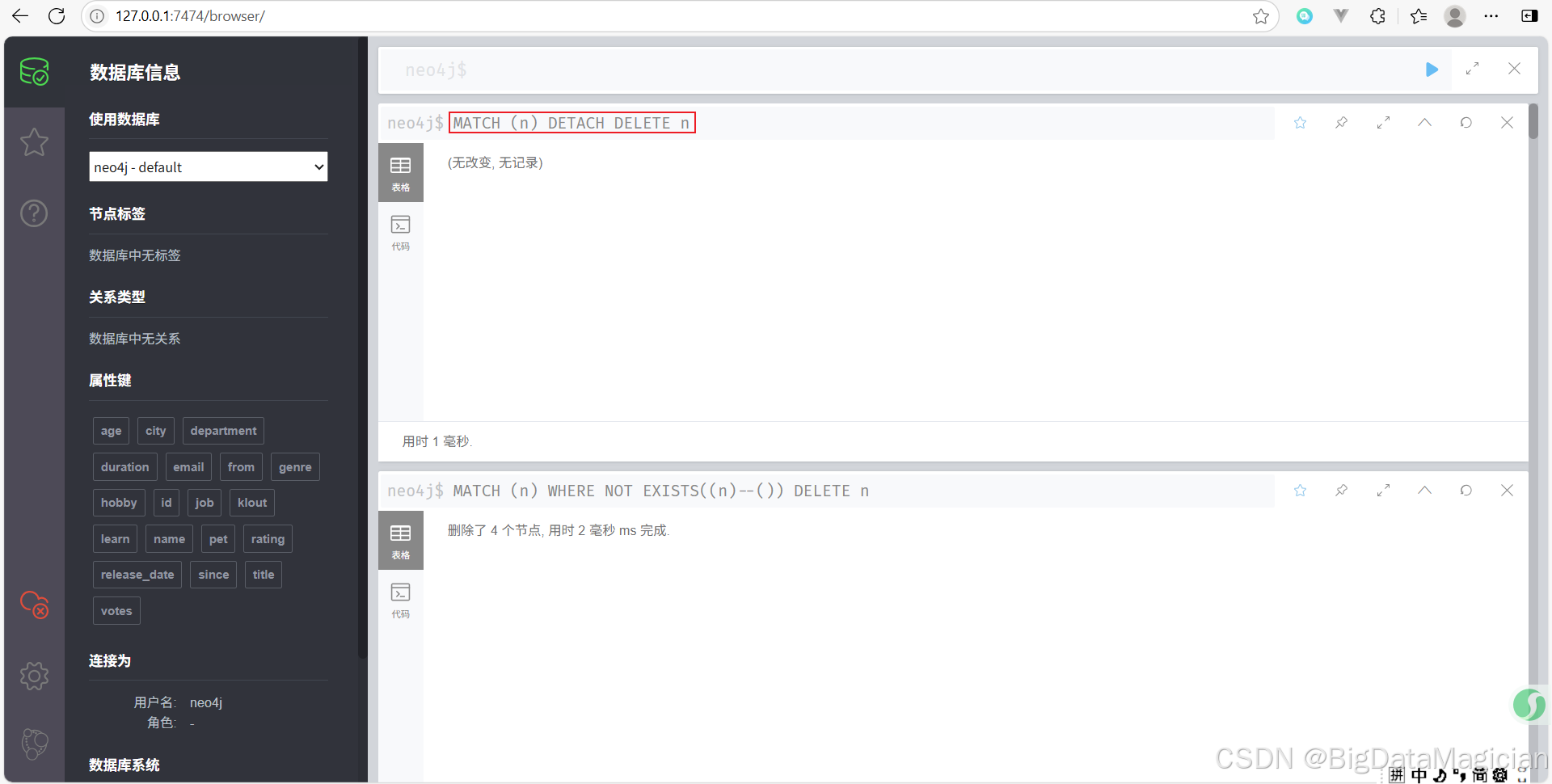
示例 5:刪除所有節點和關系(清空整個圖數據庫)
刪除數據庫中所有的節點和它們的關系。
MATCH (n)
DETACH DELETE n
5. 合并數據
合并數據用于創建或更新節點或關系,不存在則創建,存在則更新。為了避免數據重復插入,可以使用
MERGE替代CREATE。
在 Neo4j 中,MERGE 是一個非常強大的命令,它用于確保某個圖模式存在。如果該模式不存在,則會創建它;如果已經存在,則不會執行任何操作(也可以選擇更新某些屬性)。這非常適合用來避免重復插入相同的數據。
5.1 語法
基本語法如下:
MERGE (n:Label {uniqueProperty: value})
SET n.otherProperty = otherValue
RETURN n
MERGE:嘗試匹配指定的模式(節點或關系)。- 如果沒有找到匹配項,則創建新的節點或關系。
- 可以結合
ON CREATE SET和ON MATCH SET來分別設置創建時和匹配到時的操作。
使用 ON CREATE 和 ON MATCH 的完整語法:
MERGE (n:Label {uniqueProperty: value})
ON CREATE SET n.created = timestamp()
ON MATCH SET n.lastAccessed = timestamp()
RETURN n
ON CREATE SET:僅當節點是新創建的時候才執行。ON MATCH SET:僅當節點已存在時才執行。
5.2 示例
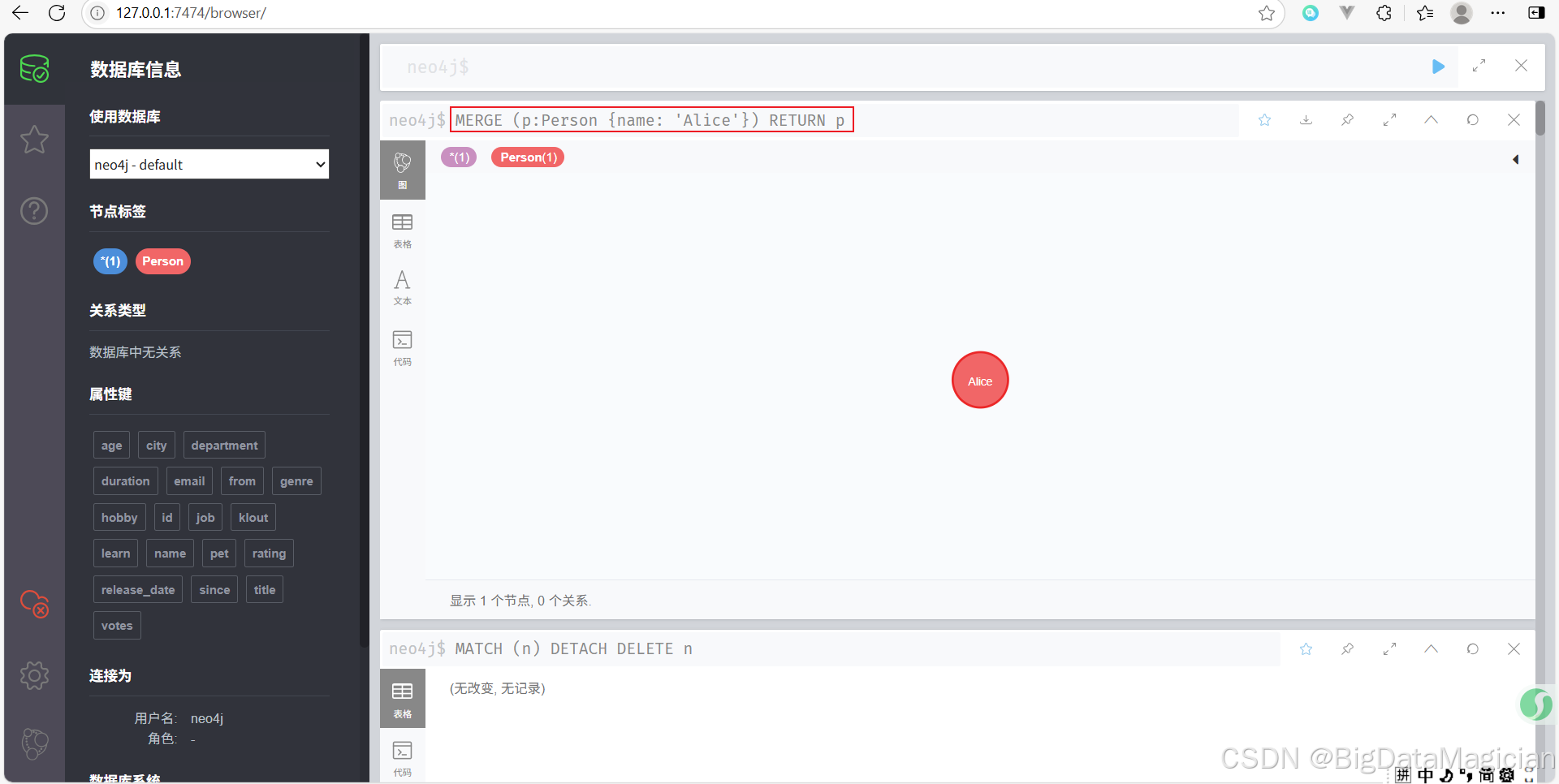
示例 1:確保某節點存在(若不存在則創建)
MERGE (p:Person {name: 'Alice'})
RETURN p
如果數據庫中沒有名為 Alice 的 Person 節點,則創建一個;如果有,則返回已存在的節點。
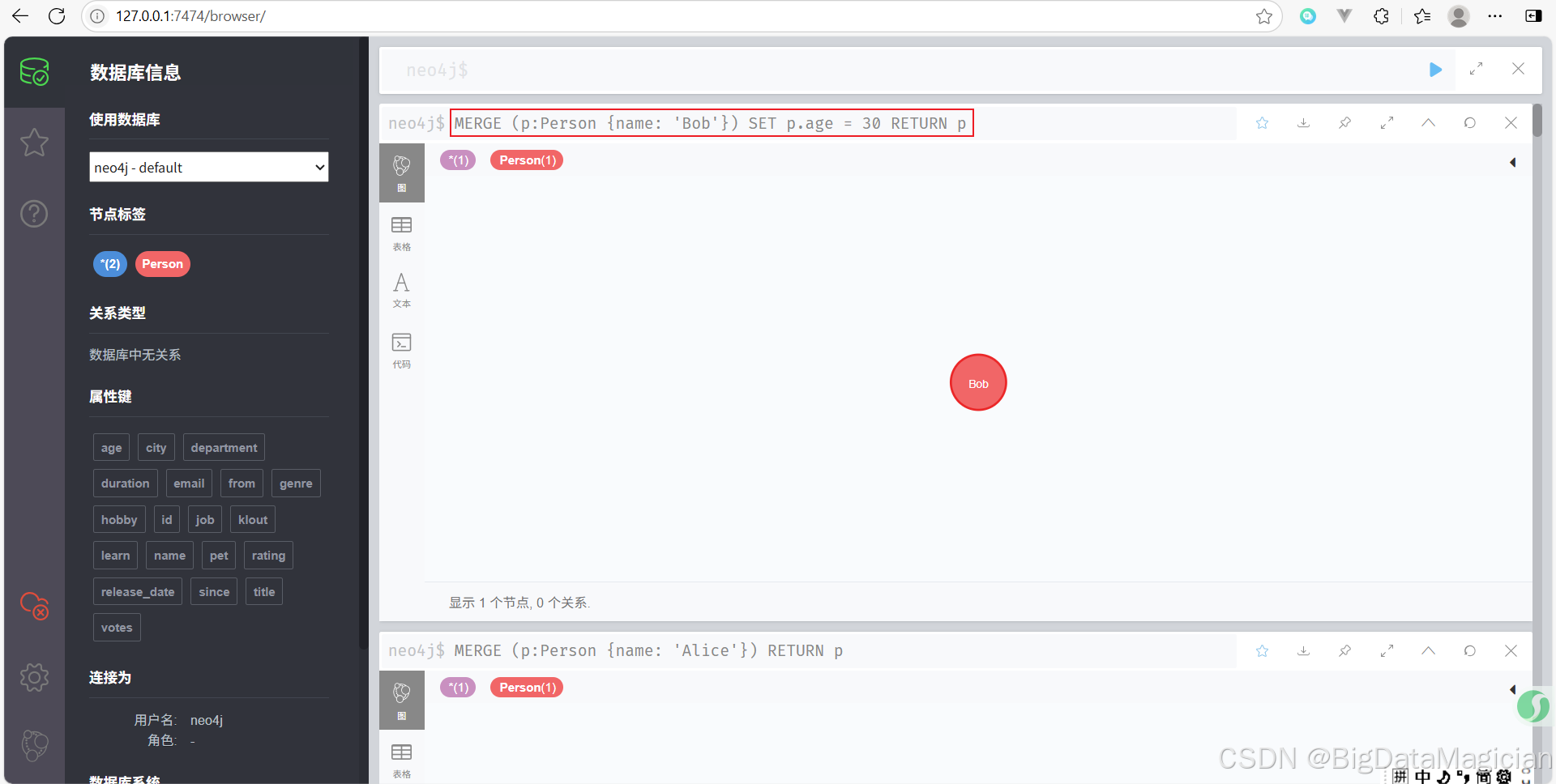
示例 2:確保節點存在,并設置額外屬性
MERGE (p:Person {name: 'Bob'})
SET p.age = 30
RETURN p
確保 Bob 存在,并將他的年齡設為 30。如果 Bob 已經存在,則覆蓋其 age 屬性。
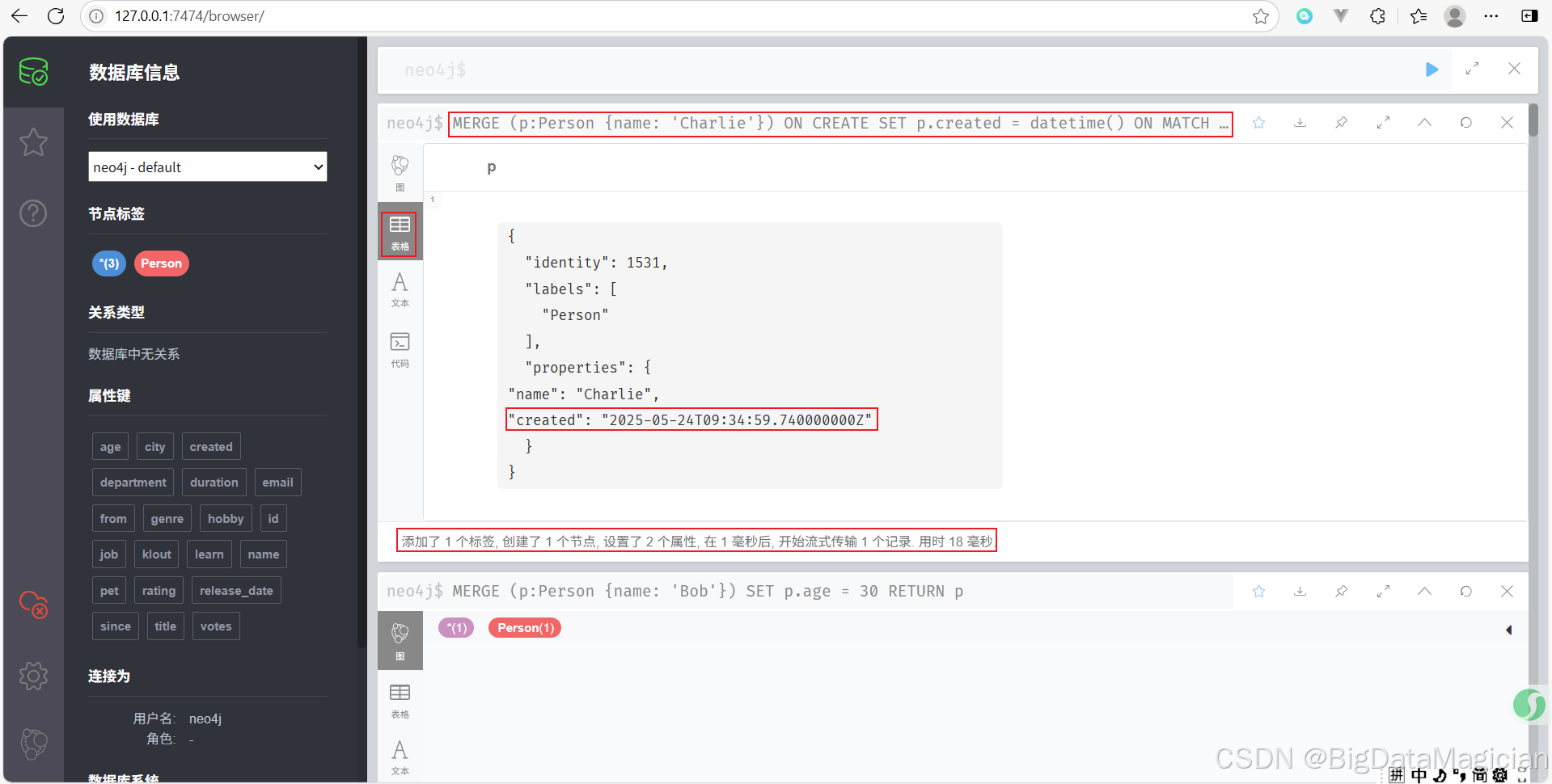
示例 3:使用 ON CREATE 和 ON MATCH 區分創建與更新操作
MERGE (p:Person {name: 'Charlie'})
ON CREATE SET p.created = datetime()
ON MATCH SET p.lastSeen = datetime()
RETURN p
- 如果 Charlie 是第一次出現,則設置
created時間;- 如果已存在,則更新
lastSeen時間。
示例 4:合并關系(確保兩個節點之間有某種關系)
MERGE (a:Person {name: 'Alice'})
MERGE (b:Person {name: 'Bob'})
MERGE (a)-[r:FRIENDS_WITH]->(b)
RETURN a, r, b
確保 Alice 和 Bob 存在,并且他們之間有一條 FRIENDS_WITH 關系。如果已經存在這條關系,則不重復創建。
示例 5:合并帶屬性的關系
MERGE (a:Person {name: 'Alice'})
MERGE (b:Person {name: 'Bob'})
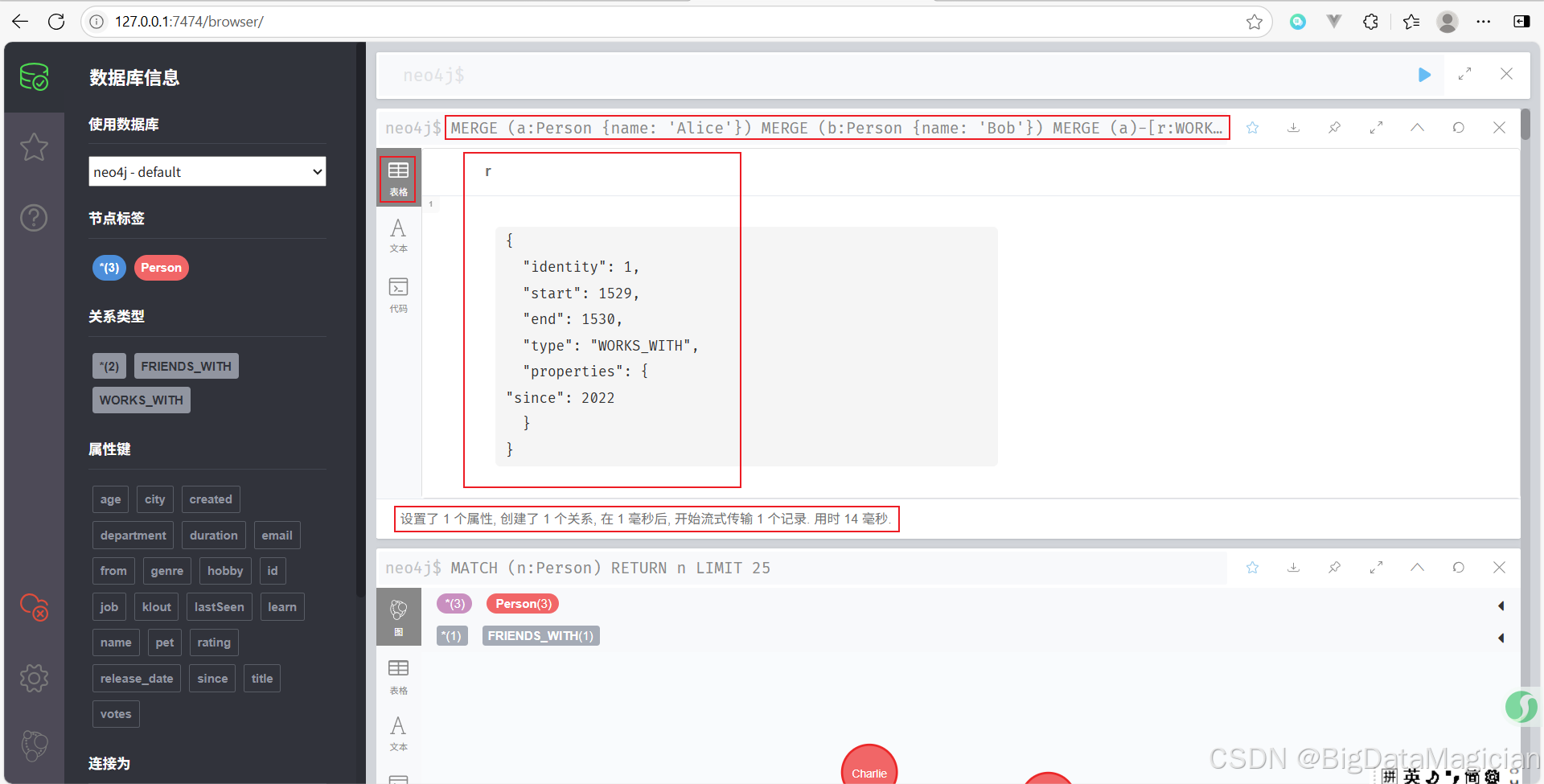
MERGE (a)-[r:WORKS_WITH {since: 2022}]->(b)
RETURN r
確保 Alice 和 Bob 之間有一條 WORKS_WITH 類型的關系,并帶有屬性
since: 2022。