相關爬蟲專欄:JS逆向爬蟲實戰??爬蟲知識點合集??爬蟲實戰案例
引言:爬蟲與HTTP的不解之緣
- 爬蟲作用:模擬瀏覽器請求網頁
- 為何要懂HTTP:http是網絡通信的基石,爬蟲抓取數據就是通過HTTP協議進行的,了解http有助于我們更好的構筑爬蟲,解決問題。
一、什么是HTTP協議
- HTTP (HyperText Transfer Protocol) 超文本傳輸協議,是互聯網上應用最為廣泛的一種網絡協議。所有 WWW 文件都必須遵守這個標準。
- 特點:
- 客戶端-服務器端間建立通訊連接:請求-響應
- 無狀態:每次請求獨立,服務器不保留連接狀態(需要cookie/session來保存信息)
- 靈活簡單:支持多種數據類型。
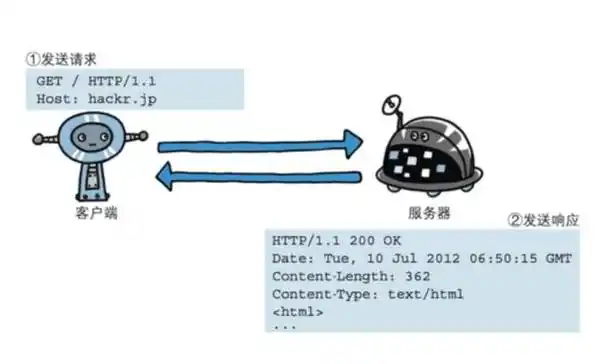
二、請求與響應機制
1. 客戶端發送請求:
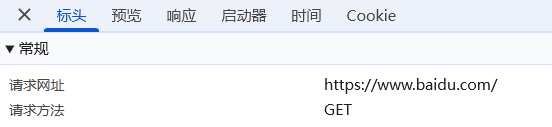
-
請求行
- 請求方法 (Method): GET、POST、PUT、DELETE、HEAD、OPTIONS 等,重點講解爬蟲常用的 GET 和 POST。
- 請求 URL (Uniform Resource Locator): 要訪問的資源路徑。
- HTTP 版本: 如 HTTP/1.1,HTTP/2.0。
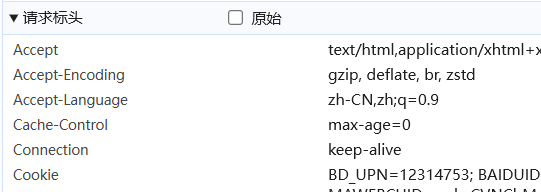
-
請求頭
User-Agent: 標識客戶端類型,爬蟲偽裝瀏覽器最常用的頭信息。Referer: 防盜鏈,此條請求的來源頁面。Cookie: 保持會話狀態的關鍵。Host: 目標服務器的主機名。Accept: 客戶端可接受的媒體類型。Accept-Encoding: 客戶端接受的編碼方式(如 gzip, deflate)。Connection: 連接狀態(如 Keep-Alive)。Content-Type: 請求體的數據類型和長度,常用來檢查數據是json型還是text型。- 自定義請求頭: 爬蟲中可能添加的自定義頭。
-
請求體
- 主要用于POST請求,攜帶提交的數據(表單數據,JSON數據等)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? --? 載荷中寫著請求載荷/表單數據:
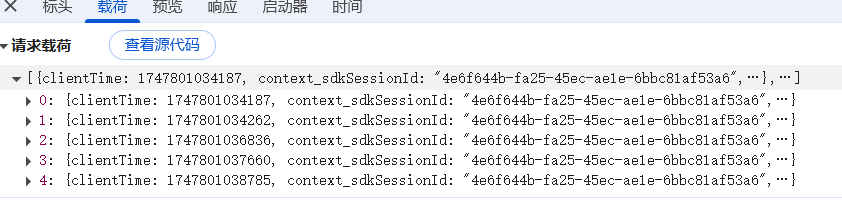
- 主要用于POST請求,攜帶提交的數據(表單數據,JSON數據等)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? --? 載荷中寫著請求載荷/表單數據:
2. 服務器端返回響應:
-
狀態行
- HTTP 版本。
- 狀態碼 (Status Code):
2xx(成功):200 OK(最常見)。3xx(重定向--即跳轉訪問到另一個頁面):301(永久),302(臨時),304(未修改)。4xx(客戶端錯誤):400(請求錯誤),403(禁止訪問),404(未找到)。5xx(服務器錯誤):500(內部錯誤),502(網關錯誤)。
- 狀態信息: 對狀態碼的文字描述。
-
響應頭
Set-Cookie: 服務器設置 Cookie 給客戶端。Location: 重定向 URL。Server: 服務器軟件信息。Content-Type: 響應體的數據類型(如 text/html, application/json)。Content-Length: 響應體的長度。Vary: 告知緩存機制哪些請求頭會影響響應。
-
響應體
- 實際返回的數據,如 HTML、JSON、圖片等。

- 實際返回的數據,如 HTML、JSON、圖片等。
三、HTTP協議與反爬機制的攻防戰
在爬蟲上,HTTP協議不光是信息傳輸的通道,更是爬蟲與反爬雙方攻防的主戰場。網站會通過檢查HTTP請求各個訪問信息來確定其是正常或爬蟲訪問。而理解這些反爬策略與HTTP的關系就成了我們學習進階爬蟲的必修課。
1. 身份識別:User-Agent與Referer的偽裝
UA與Referer是常見的請求頭中檢查的對象:前者為身份識別,后者為防盜鏈(訪問該請求前是從哪個鏈接跳轉過來的)
二者處理都是設置一個合法真實的對象即可。其中UA在遭遇更高級別的反爬檢查時,可能需要備一個UA池。
2. 會話保持:Cookie/Seesion的設置
HTTP 協議本身是無狀態的,這意味著服務器不會記住每次請求之間的信息。但為了實現用戶登錄、購物車、個性化推薦等功能,網站會使用 Cookie 和 Session 來維持會話狀態。
詳情了解見爬蟲知識之Cookie與Session。通過requests.session的方式可以有效管理相關會話并規避吸納檢測請求頻率的反爬。
3. 訪問頻率限制:IP限制與HTTP頻率限制
網站為了防止服務器過載/資源濫用,一般會限制同IP/同用戶的請求數量。
- IP限制:服務器記錄當前請求的IP地址,如果短時間訪問量過大,就會暫時或永久封禁該ip。
- HTTP請求頻率限制:不僅ip,也有可能看用戶id,cookie等分析來限制。
- 爬蟲應對方法:
- 延時:每次請求時加一個固定或隨機的的延時(time.sleep),模擬人類瀏覽行為,降低請求頻率。
- 代理IP池:使用大量的代理IP地址,分散請求來源,避免單一IP封禁。適用于大型爬蟲項目。
- 分布式爬蟲:利用多臺機器與多個IP同時爬取,進一步分散請求壓力。
- 爬蟲應對方法:
四、總結
HTTP協議的特性與爬蟲緊密相關,對HTTP協議了解足夠深入,能更有效的幫助我們爬取各個網站內容。


】:使用 Django REST Framework 構建項目與模塊 CRUD API)








)





算法?)

