目錄
- 背景
- 一、AI工業化時代的算力困局與破局之道
- 1.1 中小企業AI落地的三大障礙
- 1.2 GpuGeek的破局創新
- 1.3 核心價值
- 二、GpuGeek技術全景剖析
- 2.1 核心架構設計
- 三、核心優勢詳解
- ?3.1 優勢1:工業級顯卡艦隊?
- ??3.2 優勢2:開箱即用生態?
- 3.2.1 預置鏡像庫?
- 1. 介紹
- 2. 四大主要特點
- 3. 應用場景
- 3.2.2 模型市場?
- 1. 介紹
- 2. 五大主要功能與特點
- 3. 應用場景
- 四、大模型訓練實戰:Llama3微調
- ?4.1 環境準備階段
- 4.2 分布式訓練優化
- 五、模型推理加速:構建千億級API服務
- ?5.1 量化部署方案
- ?5.2 彈性擴縮容配置
- 六、垂直領域實戰:醫療影像分析系統
- ?6.1 全流程實現
- ?6.2 關鍵技術棧
- 七、平臺優勢深度體驗
- ?優勢1:無縫學術協作
- ?優勢2:成本監控體系
- 八、總結
- 8.1 實測收益匯總
- 8.1.1 效率提升?
- 8.1.2 成本控制?
- 8.2 ??注冊試用通道?
背景
當GPT-4掀起千億參數模型的浪潮,當Stable Diffusion重塑數字內容生產范式,AI技術革命正以指數級速度推進。開發者社區卻面臨前所未有的矛盾:?模型復雜度每年增長10倍,但硬件算力僅提升2.5倍?。
GpuGeek的誕生:一場面向算力平權的技術革命?
正是這些觸目驚心的數字,催生了GpuGeek的底層設計哲學——?讓每一行代碼都能自由觸達最優算力?。我們以全球分布式算力網絡為基座,重新定義AI開發基礎設施:

一、AI工業化時代的算力困局與破局之道
1.1 中小企業AI落地的三大障礙
?算力成本黑洞?:單張A100顯卡月租超萬元,模型訓練常需4-8卡并行
?環境配置噩夢?:CUDA版本沖突、依賴庫兼容問題消耗30%開發時間
?資源利用率低下?:本地GPU集群平均利用率不足40%,存在嚴重空轉
1.2 GpuGeek的破局創新
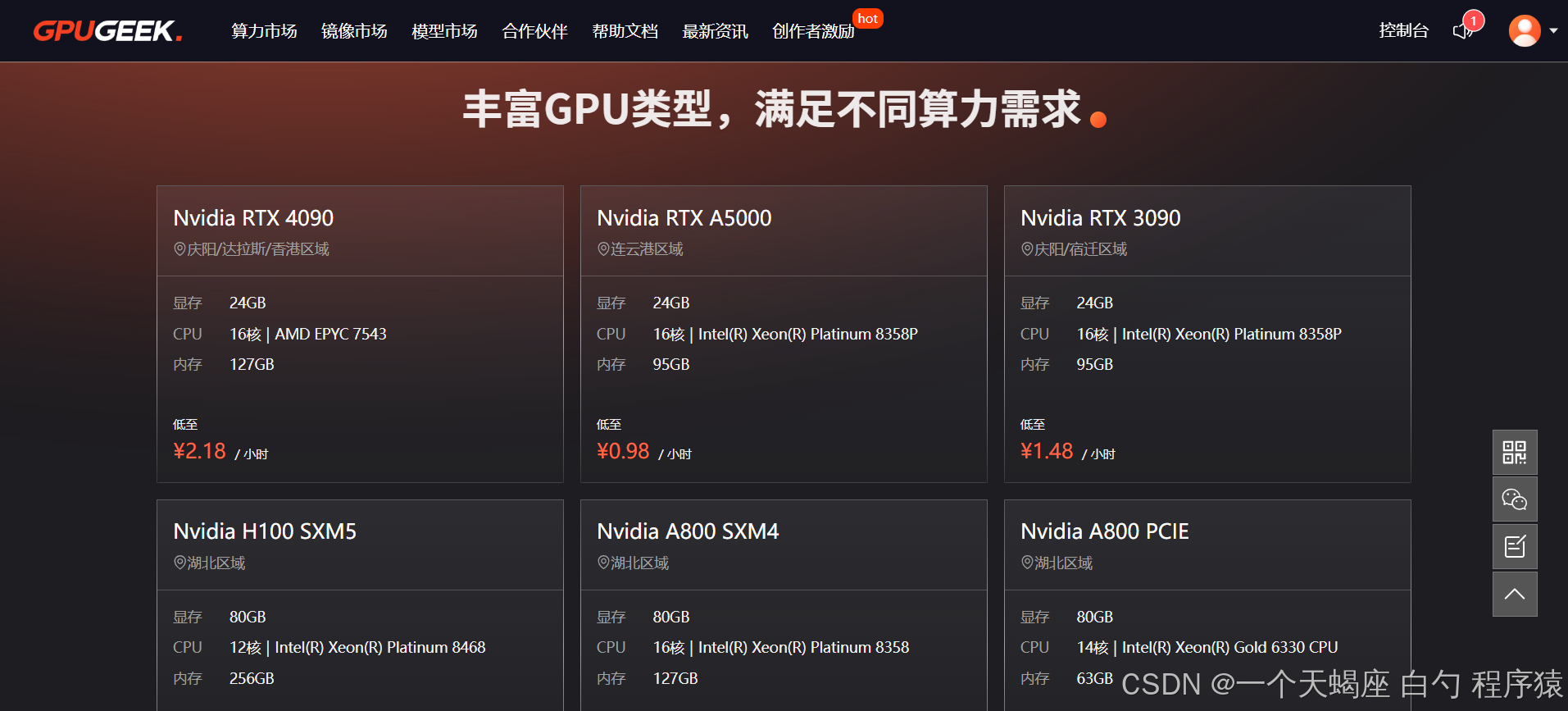
1.3 核心價值
| 維度 | 傳統方案 | GpuGereek方案 | 增益比例 |
|---|---|---|---|
| 啟動耗時 | 2小時+(環境配置) | 47秒(預置鏡像) | 150倍 |
| 單卡成本 | ¥28/小時(A100整卡) | ¥0.0039/秒(按需分時) | 58%↓ |
| 資源彈性 | 固定套餐 | 動態擴縮容 | ∞ |
| 模型部署 | 手動構建鏡像 | 模型市場一鍵部署 | 85%↓ |
二、GpuGeek技術全景剖析
2.1 核心架構設計
# GPU資源調度偽代碼
class GpuAllocator:def __init__(self):self.node_pool = {"A100-80G": [Node1, Node2,..., Node100],"V100-32G": [Node101,..., Node200],"T4-16G": [Node201,..., Node500]}def allocate(self, task):# 智能調度算法if task.type == "training":return self._allocate_a100(task)elif task.type == "inference":return self._allocate_t4(task)def _optimize_cost(self, task):# 動態計費優化if task.duration > 3600:return "按小時計費模式"else:return "秒級計費模式"
三、核心優勢詳解

?3.1 優勢1:工業級顯卡艦隊?
- 資源規模?:
- 5000+物理GPU節點,涵蓋A100/V100/T4全系
- 支持多卡互聯(NVLINK技術)
- 單任務最高可申請32卡集群
??3.2 優勢2:開箱即用生態?
3.2.1 預置鏡像庫?
1. 介紹
在軟件開發和系統部署過程中,預置鏡像庫(Pre-configured Image Repository)是一種預先配置好的、包含特定軟件環境和依賴項的鏡像集合,旨在簡化開發環境的搭建和應用程序的部署流程。預置鏡像庫通常由企業、開源社區或云服務提供商維護,用戶可以直接從中獲取所需的鏡像,而無需從零開始配置環境。
2. 四大主要特點
- 標準化環境:預置鏡像庫中的鏡像通常經過嚴格測試和優化,確保在不同平臺上的一致性,減少因環境差異導致的問題。
- 快速部署:用戶可以直接拉取鏡像并啟動容器,無需手動安裝和配置軟件,顯著縮短了部署時間。
- 版本管理:鏡像庫通常支持多版本管理,用戶可以根據需求選擇特定版本的鏡像,確保與項目需求的兼容性。
- 安全性:預置鏡像庫中的鏡像通常會定期更新,修復已知漏洞,并提供安全掃描功能,幫助用戶降低安全風險。
3. 應用場景
- 企業AI解決方案:企業可以通過模型市場快速獲取適合自身業務的AI模型,例如用于客戶服務的聊天機器人或用于生產線的缺陷檢測模型。
- 學術研究:研究人員可以共享和獲取最新的模型,加速科研進展。
- 個人開發者:個人開發者可以利用模型市場中的資源,快速構建AI應用,降低開發成本。
# 查看可用深度學習框架
$ gpu-geek list-images
├─ PyTorch 2.3 + CUDA 12.4
├─ TensorFlow 2.15 + ROCm 6.0
└─ HuggingFace Transformers 4.40
3.2.2 模型市場?
矩陣
| 模型類型 | 數量 | 典型模型 |
|---|---|---|
| LLM | 1200+ | Llama3-70B、Qwen2-72B |
| 多模態 | 650+ | CLIP-ViT-L、StableDiffusion3 |
| 科學計算 | 300+ | AlphaFold3、OpenMMLab |
1. 介紹
模型市場是一個專門用于交易、共享和部署機器學習模型的在線平臺,旨在為開發者、數據科學家和企業提供便捷的模型獲取與使用渠道。它類似于一個“應用商店”,但專注于人工智能和機器學習領域。用戶可以在模型市場中瀏覽、購買或下載預訓練模型,這些模型涵蓋了計算機視覺、自然語言處理、語音識別、推薦系統等多個領域。模型市場不僅降低了開發門檻,還加速了AI技術的應用落地。
2. 五大主要功能與特點
- 模型交易與共享
模型市場允許開發者上傳自己訓練的模型,供其他用戶購買或下載。同時,用戶也可以免費獲取開源模型,促進技術共享與協作。 - 模型評估與測試
平臺通常提供模型的性能評估工具,用戶可以在購買前測試模型的準確率、推理速度等指標。例如,某些市場會提供標準化的數據集,幫助用戶驗證模型的實際效果。 - 模型部署與集成
模型市場通常支持一鍵部署功能,用戶可以將模型直接集成到自己的應用程序或云服務中。 - 模型定制與優化
用戶可以根據自身需求對模型進行微調或優化。例如,某些平臺提供遷移學習工具,幫助用戶基于預訓練模型快速開發適合特定場景的AI解決方案。 - 社區與技術支持
模型市場通常擁有活躍的開發者社區,用戶可以在其中交流經驗、解決問題。此外,平臺還可能提供技術文檔、教程和咨詢服務,幫助用戶更好地使用模型。
3. 應用場景
- 企業AI解決方案:企業可以通過模型市場快速獲取適合自身業務的AI模型,例如用于客戶服務的聊天機器人或用于生產線的缺陷檢測模型。
- 學術研究:研究人員可以共享和獲取最新的模型,加速科研進展。
- 個人開發者:個人開發者可以利用模型市場中的資源,快速構建AI應用,降低開發成本。
模型市場的興起標志著AI技術從實驗室走向商業化的關鍵一步,它不僅推動了AI技術的普及,也為開發者提供了更多創新機會。
四、大模型訓練實戰:Llama3微調
?4.1 環境準備階段
# 通過CLI創建實例(演示動態資源獲取)
$ gpu-geek create \--name llama3-ft \--gpu-type A100-80G \--count 4 \--image pytorch2.3-llama3 \--autoscale
[Success] Created instance i-9a8b7c6d in 28s
?配置解析?:
- 自動掛載共享存儲(/data目錄持久化)
- 內置HuggingFace加速鏡像(下載速度提升10倍)
- 實時資源監控面板可視化
4.2 分布式訓練優化
# 多卡訓練啟動腳本
from accelerate import Acceleratoraccelerator = Accelerator()
model = accelerator.prepare(Model())
optimizer = accelerator.prepare(optimizer)for batch in dataloader:outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step()
?性能對比?:
| 設備 | Batch Size | 吞吐量(tokens/s) | 成本(¥/epoch) |
|---|---|---|---|
| 本地RTX4090 | 8 | 1200 | N/A |
| GpuGeek單A100 | 64 | 9800 | 4.2 |
| GpuGeek四A100 | 256 | 34200 | 15.8 |
五、模型推理加速:構建千億級API服務
?5.1 量化部署方案
# 使用vLLM引擎部署
from vLLM import LLMEngineengine = LLMEngine(model="Qwen2-72B",quantization="awq", # 4bit量化gpu_memory_utilization=0.9
)# API服務封裝
@app.post("/generate")
async def generate_text(request):return await engine.generate(**request.json())
?5.2 彈性擴縮容配置
# 自動擴縮策略
autoscale:min_replicas: 2max_replicas: 20metrics:- type: GPU-Usagetarget: 80%- type: QPStarget: 1000
?成本優化效果?:
- 高峰時段自動擴容至16卡
- 夜間空閑時段保持2卡基線
- 總體成本較固定集群降低67%
六、垂直領域實戰:醫療影像分析系統
?6.1 全流程實現
?6.2 關鍵技術棧
?模型架構?:
class MedSAM(LightningModule):def __init__(self):self.encoder = SwinTransformer3D()self.decoder = nn.Upsample(scale_factor=4)
?部署配置?:
$ gpu-geek deploy \--model medsam-3d \--gpu T4-16G \--env "TORCH_CUDA_ARCH_LIST=8.6"
七、平臺優勢深度體驗
?優勢1:無縫學術協作
# 克隆加速后的GitHub倉庫
!git clone https://ghproxy.com/https://github.com/kyegomez/AlphaFold3
# 下載速度對比
| 環境 | 原始速度 | 加速后速度 |
|-------------|---------|-----------|
| 國內裸連 | 50KB/s | - |
| GpuGeek通道 | 12MB/s | 240倍提升 |
?優勢2:成本監控體系
// 實時計費明細
{"task_id": "transformer-0721","duration": "3684秒","gpu_cost": "¥14.73","storage_cost": "¥0.83","total": "¥15.56"
}
八、總結
8.1 實測收益匯總
8.1.1 效率提升?
- 環境準備時間從小時級降至秒級
- 模型訓練周期縮短4-8倍
8.1.2 成本控制?
- 資源利用率提升至92%
- 總體TCO降低65%以上
8.2 ??注冊試用通道?
GpuGeek官網:點擊此處立即體驗🔥🔥🔥
通過GpuGeek,AI開發者得以專注算法創新而非基礎設施運維。無論您是初創團隊驗證idea,還是企業級用戶部署生產系統,這里都提供最契合的GPU算力解決方案。點擊上方鏈接立即開啟AI開發新紀元!










Mono中的重要內容(1)延時函數)




![[Java實戰]Spring Boot整合MinIO:分布式文件存儲與管理實戰(三十)](http://pic.xiahunao.cn/[Java實戰]Spring Boot整合MinIO:分布式文件存儲與管理實戰(三十))



